






Nada Shahin
1
,
2
{ }^{1,2}
1,2, Leila Ismail
1
,
2
,
3
∗
{ }^{1,2,3 *}
1,2,3∗
1
{ }^{1}
1 Intelligent Distributed Computing and Systems (INDUCE) Lab, Department of Computer Science and Software Engineering, College of Information Technology, United Arab Emirates University, Al Ain, Abu Dhabi, United Arab Emirates
2
{ }^{2}
2 National Water and Energy, United Arab Emirates University, Al Ain, Abu Dhabi, United Arab Emirates
3
{ }^{3}
3 Emirates Center for Mobility Research, United Arab Emirates University, Al Ain, Abu Dhabi, United Arab Emirates
通讯作者邮箱: Leila@uaeu.ac.ae
摘要
当前的手语机器翻译系统依赖于识别手势、面部表情和身体姿势以及自然语言处理,以将手语转换为文本。最近的方法使用Transformer架构通过位置编码来建模长距离依赖关系。然而,它们在识别以高帧率捕获的手势之间细微的短时间依赖关系时缺乏准确性。此外,其高计算复杂度导致训练效率低下。为了解决这些问题,我们提出了自适应Transformer(ADAT),它通过引入增强特征提取和自适应特征加权的门控机制,在强调上下文相关特征的同时减少训练开销并保持翻译准确性。为了评估ADAT,我们引入了MedASL,这是第一个公开的医疗美国手语数据集。在符号到词汇再到文本的实验中,ADAT优于编码器-解码器Transformer,在PHOENIX14T上将BLEU-4准确率提高了 0.1 % 0.1 \% 0.1%,同时减少了 14.33 % 14.33 \% 14.33%的训练时间,在MedASL上减少了 3.24 % 3.24 \% 3.24%的训练时间。在符号到文本的实验中,它在PHOENIX14T上将准确率提高了 8.7 % 8.7 \% 8.7%,并将训练时间减少了 2.8 % 2.8 \% 2.8%,在MedASL上实现了 4.7 % 4.7 \% 4.7%更高的准确率和 7.17 % 7.17 \% 7.17%更快的训练。与仅编码器和仅解码器基线相比,尽管由于其双流结构最多慢了 12.1 % 12.1 \% 12.1%,但ADAT在符号到文本任务上的准确率至少高出 6.8 % 6.8 \% 6.8%。
关键词:人工智能,自然语言处理,神经机器翻译,神经网络,手语翻译,Transformers
1. 引言
手语机器翻译(SLMT)已成为自然语言处理(NLP)中的一个基础研究领域,旨在减少聋人和听障人士(DHH)社区的沟通障碍。预计到2050年,超过7亿人将经历听力损失,并且全球存在300多种不同的手语,这使得可访问性成为一个重大挑战。合格的手语译员短缺进一步限制了实时通信,尤其是在医疗保健和应急响应等关键情况下,有效沟通直接影响个人福祉和安全。因此,迫切需要开发可扩展、自动化的高效SLMT系统,以促进实时通信,同时确保准确性、效率和包容性。
机器翻译(MT)的最新进展改善了通用多模态表示;然而,现有的SLMT研究带来了独特的挑战。这是因为手语具有独特的语法结构、复杂的时空特性以及动态的视觉表示。为了实现准确和高效的翻译,SLMT系统必须捕捉短程和远程依赖关系,考虑必要的手语组件,如动作序列、手形和位置、面部表情和身体姿势。然而,随着手语的不断演变,SLMT模型必须频繁重新训练以保持准确性。现有模型往往在这方面挣扎,需要大量的计算资源和漫长的训练时间。此外,注释手语数据的稀缺性仍然是一个根本障碍,需要能够高效训练同时保持准确性的方法。
一些SLMT工作采用了Transformer架构[5-7],鉴于其在语言翻译中的最先进性能。Transformer通过位置嵌入和注意力机制有效地建模长程依赖关系。然而,其二次计算复杂度在训练期间带来了挑战,因为它们无法高效地捕捉精细的短程时间依赖关系——这对于处理通常以每秒30-60帧记录的高帧率数据至关重要。这些低效性限制了SLMT系统的可扩展性,特别是在逐帧分析中,使得开发实时应用和快速适应新数据变得困难。
在本研究中,我们通过提出自适应Transformer(ADAT),填补了这一空白。这是一种新型架构,旨在通过动态捕捉细粒度的短程和远程时空特征来增强SLMT,同时提高训练速度。这是通过整合多个关键组件实现的:卷积层提取局部签名特征,LogSparse 自注意力(LSSA)减少计算开销,通过关注对数间隔的过去签名帧,以及一种自适应门控机制选择性保留关键时间依赖关系。通过结合这些元素,ADAT有效地捕捉了短程和远程时间依赖关系,提高了训练效率,允许更快地适应新数据和进化的手语。与Vaswani等人提出的Transformer相比,ADAT优化了注意力计算,减少了不必要的开销,从而更有效地进行手语翻译。
我们将SLMT系统分为两个核心过程:1)手语识别(SLR),即符号到词汇(S2G),将符号视频序列转换为词汇,这些是保留手语语言学的象征性表示;2)手语翻译(SLT),从识别的符号生成口语文本。SLT可以通过直接符号到文本(S2T)翻译或符号到词汇到文本(S2G2T)翻译实现。
我们在S2T和S2G2T方面对ADAT与三种Transformer基线(编码器-解码器、仅编码器和仅解码器)进行了比较评估。我们的评估使用了两个基准数据集:RWTH-PHOENIX-Weather-2014(PHOENIX14T)和MedASL,这是我们的医疗美国手语(ASL)数据集,解决了在医疗保健中准确翻译的关键需求,其中沟通障碍可能对患者安全和福祉产生重大影响。我们的结果突显了ADAT在推进SLMT系统和缩小聋人群体与更广泛社会之间的沟通差距方面的潜力,特别是在医疗保健等关键领域。
本文的主要贡献如下:
- 我们提出了一种自适应Transformer(ADAT),这是一种新颖的基于Transformer的模型,可以动态捕捉短程和远程时间依赖关系,同时优化计算效率。
-
- 我们对ADAT与编码器-解码器、仅编码器和仅解码器Transformer基线进行了比较评估。实验结果表明,ADAT在S2G2T和S2T的准确性和训练时间方面优于基线。
-
- 我们使用两个不同特性和手语的数据集对ADAT进行了评估:最大的公共德国天气相关的PHOENIX14T数据集和MedASL,这是一个新的连续ASL医疗相关数据集,由我们引入。
- 本文其余部分组织如下:第2节概述了相关工作。第3节描述了所提出的自适应Transformer。第4节讨论了所提出的MedASL数据集。第5节介绍了实验设置。数值实验和比较性能结果在第6节提供。第7节总结了本文,并指出了未来的研究方向。
2. 相关工作
我们将相关工作分为两类:1)S2G2T 和 2)S2T,如表1所示。
几项研究探讨了S2G2T
1
,
10
,
19
−
25
.
1
{ }^{1,10,19-25} .{ }^{1}
1,10,19−25.1 提出了第一个端到端的S2G2T模型,该模型基于神经机器翻译。他们的模型学习时空手语表示,同时将词汇映射到口语语言。虽然这项工作是一个重要的进步,但它受限于依赖预训练的AlexNet、在PHOENIX14T上的领域特定评估以及缺乏对时间复杂度的考虑。
10
{ }^{10}
10 应用了带有预训练EfficientNets和连接主义时间分类(CTC)损失的编码器-解码器Transformer。这种方法使词汇识别无需明确的帧到词汇对齐成为可能,因为CTC损失引入了空标记以允许时间灵活性
26
{ }^{26}
26,从而提高了性能。然而,模型评估仅限于PHOENIX14T数据集,限制了其泛化能力。
19
{ }^{19}
19 引入了Sign Back-Translation模型,通过从单语文本生成手语序列来克服手语数据稀缺问题。虽然这改进了模型训练,但它依赖于预训练的CNN特征提取。
20
{ }^{20}
20 使用基于图的模型,将身体部位视为时空节点,使用ResNet-152进行特征提取。然而,与基于Transformer的SLMT不同,这种方法分离了S2G和G2T,需要一个多步骤过程,防止直接翻译优化,导致次优性能。
21
{ }^{21}
21 提出了PiSLTRc,这是一种集成预训练EfficientNets与内容和位置感知时间卷积的Transformer系统。根据阶段间的迁移学习,他们的方法需要分别训练S2G和Gloss2Text(G2T)。这阻止了从文本输出到手语视频输入的反向传播,限制了翻译准确性。
22
{ }^{22}
22 应用对比学习以增强视觉和语义鲁棒性。这种方法引入了更高的计算开销,使S2G2T训练显著更加资源密集。
23
{ }^{23}
23 引入了SLTUNET,这是一个多任务学习框架,集成了S2G、G2T和S2T在一个模型中以共享任务表示。虽然他们采用了迁移学习,但任务干扰会导致更长的微调时间,因为词汇识别中的错误会影响文本翻译。
25
{ }^{25}
25 应用了预训练的S3D进行特征提取,随后是一个轻量级头网络进行时间特征处理,以及CTC损失进行S2G。然后他们将预测的词汇输入到一个基于Transformer的G2T模型中,其中S2G和G2T的性能被单独优化。结果表明,词汇简化了书面手语,丢失了时空视觉信息,因为它只捕捉词级意义而没有手语的重要方面,如面部表情和非手动标记
8
{ }^{8}
8。因此,任何S2G中的不准确都可能导致G2T,导致较低的性能。
24
{ }^{24}
24 提出了SimulSLT,这是一种端到端的同时SLT模型,使用掩码Transformer编码器和等待-k策略。虽然这种方法减少了延迟,但它依赖于预训练模型,需要大量的计算资源。
总之,几项关于S2G2T的工作采用了基于Transformer的模型。然而,这些工作依赖于预训练模型和复杂的计算。未来的研究应考虑多样化的数据集、独立于迁移学习,并提高计算效率。
此外,几项工作调查了S2T翻译
1
,
10
,
19
,
21
,
23
−
25
,
27
−
32
{ }^{1,10,19,21,23-25,27-32}
1,10,19,21,23−25,27−32。虽然这种方法消除了词汇注释,但由于需要跨手语序列和文本输出的长距离依赖,增加了复杂性。这导致了在现实世界中部署SLMT系统比S2G2T翻译更具挑战性和不切实际
1
,
10
,
19
,
21
,
23
−
25
{ }^{1,10,19,21,23-25}
1,10,19,21,23−25。然而,
25
{ }^{25}
25 提出了一种视觉-语言映射器,以保留词汇无法代表的手语视频的时空信息。
27
{ }^{27}
27 引入了一种SLMT框架,结合单词存在验证、条件句子生成和跨模态重排。虽然这提高了翻译准确性,但它依赖于预训练的语言模型。
28
{ }^{28}
28 提出了一种基于Transformer的模型,利用语言记忆存储以提高句子级别的准确性。然而,这种方法依赖于外部语言模型。
29
{ }^{29}
29 开发了SignNet II,一种双学习基于Transformer的模型,优化S2T翻译。这种方法依赖于迁移学习和预训练的姿态估计模型,增加了训练依赖性。
30
{ }^{30}
30 引入了一种基于课程的非自回归解码器,通过并行生成整个句子来减少推理延迟。然而,训练时间未得到优化,需要广泛的微调以保持准确性。
31
{ }^{31}
31 引入了GASLT,一种无词汇的模型,使用词汇注意机制。虽然这种方法消除了词汇依赖,但它需要从预训练的自然语言模型转移语言知识。
32
{ }^{32}
32 引入了另一种无词汇模型,利用对比语言-图像预训练和掩码自监督学习。虽然语义S2T对齐得到了改善,但该模型依赖于预训练模型,缺乏明确优化,需要延长微调周期。
总之,最近关于S2T翻译的工作依赖于迁移学习并引入了高计算成本。这导致了在S2G2T相比下,SLMT的实际部署不切实际。
综上所述,基于Transformer的模型因其上下文学习能力在SLMT中占据主导地位。然而,由于手语数据稀缺,近期研究依赖于迁移学习方法。据我们所知,目前尚无专注于优化SLMT训练效率的研究。为了填补这一空白,我们提出了ADAT,一种新颖的自适应Transformer架构,用于手语翻译,以提高训练效率。此外,由于ADAT具备时间序列意识,因此通过考虑手语的细粒度短程依赖和动态上下文特征,增强了翻译准确性。
表1:文献中手语机器翻译的比较。
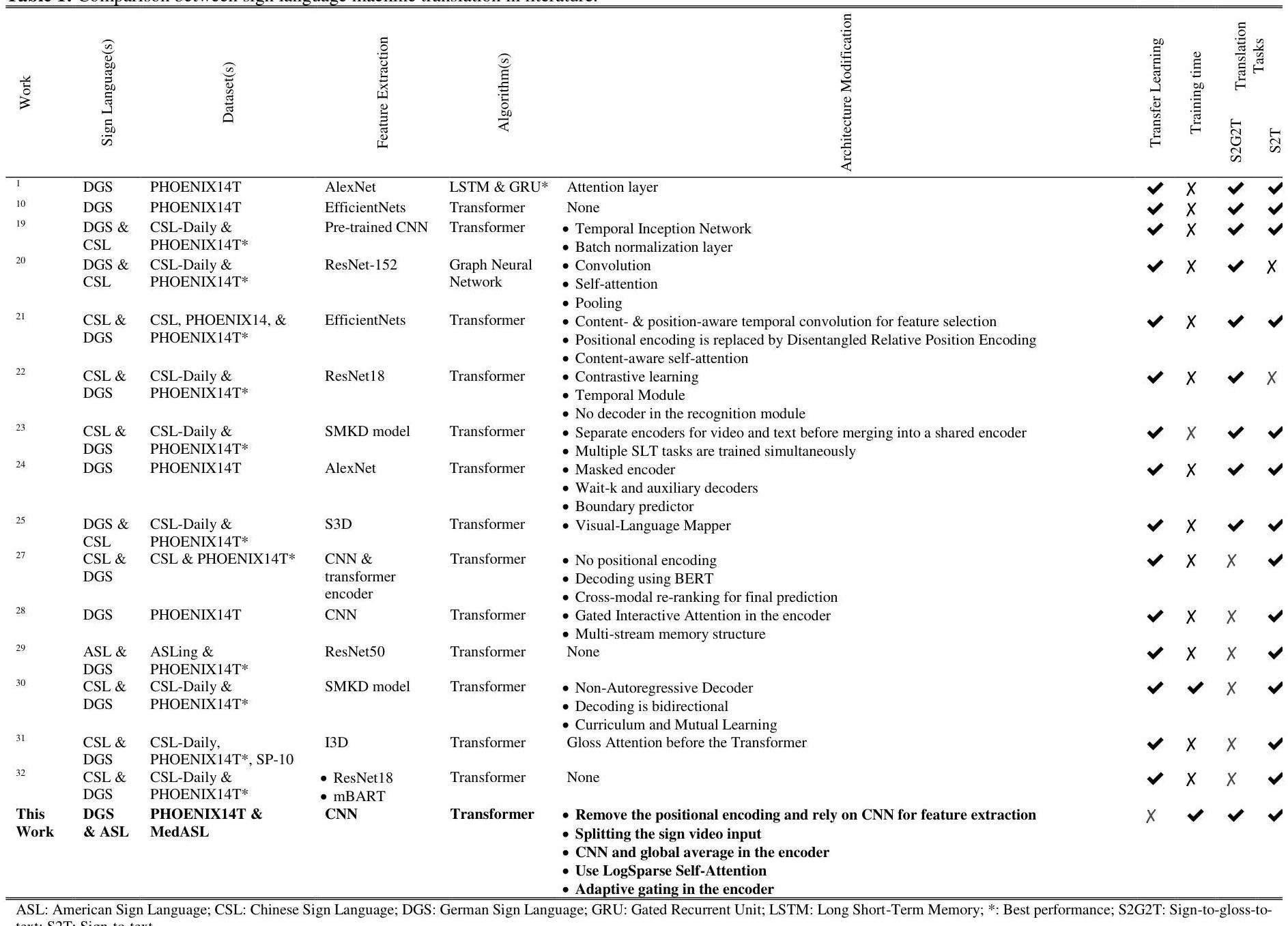
ASL: 美国手语;CSL:中国手语;DGS:德国手语;GRU:门控循环单元;LSTM:长短时记忆;*: 最佳表现;S2G2T:符号到词汇到文本;S2T:符号到文本。
# 3. 提议的ADAT:自适应时间序列Transformer架构
在本节中,我们考虑SLMT框架,该框架以包含F帧
x
=
{
x
f
}
f
=
1
F
x=\left\{x_{f}\right\}_{f=1}^{F}
x={xf}f=1F的符号视频作为输入,并将其翻译成长度为T的口语文本序列作为输出
y
=
{
y
t
}
t
=
1
T
y=\left\{y_{t}\right\}_{t=1}^{T}
y={yt}t=1T。同时考虑到包含G个词汇的中间词汇注释
z
=
{
z
g
}
g
=
1
G
z=\left\{z_{g}\right\}_{g=1}^{G}
z={zg}g=1G。为了解决这个问题,我们引入了一个自适应Transformer(ADAT)来在符号视频和口语文本之间进行映射,同时考虑到词汇注释以实现高效的SLMT系统。图1展示了ADAT架构,其中a)提供了架构的概述,b)详细说明了编码器层。我们在补充材料1中提供了算法1以详细说明ADAT的流程。
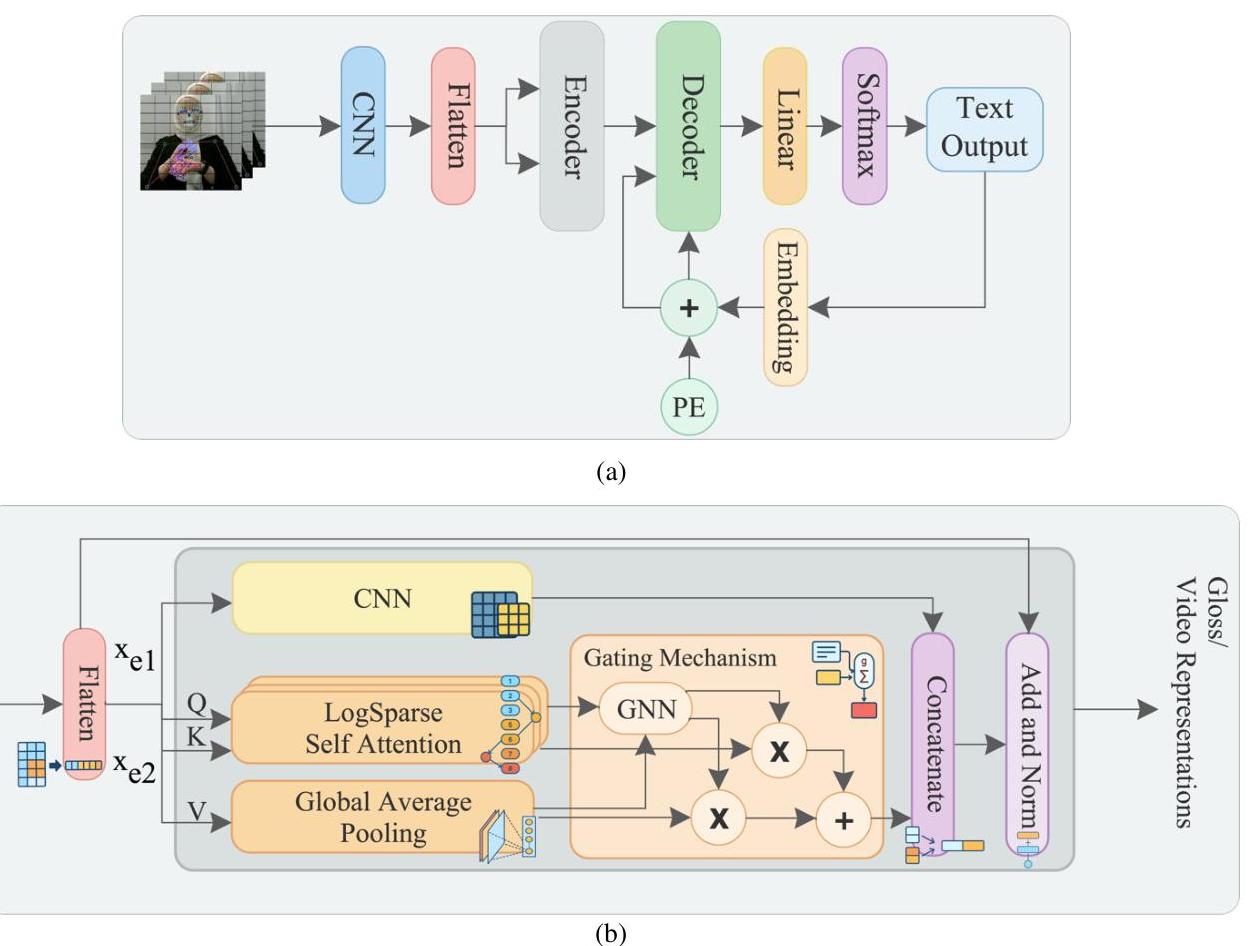
图1:(a) 整体ADAT架构。(b) ADAT编码器层,输出为符号到词汇到文本中的词汇或符号到文本翻译中的视频表示。(PE:位置编码,CNN:卷积神经网络,GNN:门控神经网络。)
提议的ADAT架构是一种新型的Transformer编码器变体,专为SLMT定制。它集成了卷积层、LogSparse Self-Attention(LSSA) 16 { }^{16} 16和自适应门控机制 17 { }^{17} 17,以有效地处理手语的时间和动态方面。此架构的工作流程如下:
3.1. 输入特征提取和维度
我们利用大小为
3
×
3
3 \times 3
3×3的16个滤波器的2D CNN和ReLU激活函数提取输入特征,随后进行
2
×
2
2 \times 2
2×2的最大池化操作。CNN非常适合在异构环境中捕捉局部空间模式,通过将帧转换为更高层次的特征表示,专注于语义相关的模式
33
{ }^{33}
33。最大池化通过减少空间冗余进一步细化特征图,从而优化计算效率
34
{ }^{34}
34。
编码器的输入包括尺寸为
52
×
65
52 \times 65
52×65的手语视频
x
e
x_{e}
xe。我们选择这个分辨率以降低计算成本,同时保留视觉细节,确保兼容不同分辨率的数据集。我们将提取的特征结构化为
x
e
∈
R
m
×
d
x_{e} \in \mathbb{R}^{m \times d}
xe∈Rm×d,其中
m
m
m是帧的数量,
d
d
d是每帧的特征维度。
d
=
C
×
H
×
W
d=C \times H \times W
d=C×H×W,其中
C
=
3
C=3
C=3(RGB通道)和
H
×
W
H \times W
H×W为
52
×
65
52 \times 65
52×65。然后,我们展平
x
e
x_{e}
xe以与后续层兼容。
3.2. 编码器
我们将输入分成两等分,每一部分捕捉符号视频的不同部分,从而减少计算负载。第一部分 x e 1 x_{e 1} xe1经过卷积运算(Conv)以提取局部特征,例如手型和面部表情。第二部分 x e 2 x_{e 2} xe2在两个并行分支中处理:第一个使用堆叠的LSSA捕捉长程依赖关系,而第二个通过全局平均池化(GAP)计算全局依赖关系。这些组件之后是一个自适应门控机制(Gating),以选择性地整合关键特征 17 { }^{17} 17。
- 自注意力
经典的自注意力机制 13 { }^{13} 13计算每对输入之间的注意力分数,导致复杂度为 O ( L 2 ) O\left(L^{2}\right) O(L2)。这种二次复杂度使其在长序列建模中效率低下且计算成本高昂。为缓解这些限制,我们采用堆叠的LSSA 35 { }^{35} 35,灵感来源于LogSparse Transformer 16 { }^{16} 16。与经典自注意力不同,后者详尽处理所有输入令牌,LSSA选择一组以指数增加步长的前一个补丁的对数间距子集。这种结构稀疏注意力模式将复杂度降低至 O ( L ( log L ) 2 ) O\left(L(\log L)^{2}\right) O(L(logL)2),同时保持长程依赖关系。
在自注意力[12, 14]中,输入补丁表示为查询、键和值矩阵(Q/K/V)。然而,在堆叠的LSSA中,我们专注于 Q / K \mathrm{Q} / \mathrm{K} Q/K矩阵,减少注意力计算的同时保持效率,如公式(1)所示。
L S S A x e 2 ( Q , K ) = Sofmax ( Q q K p T l p 2 l p 2 q 2 ) L S S A_{x_{e 2}}(Q, K)=\operatorname{Sofmax}\left(\frac{\frac{Q_{q} K_{p}^{T}}{l_{p}^{2}}}{\frac{l_{p}^{2}}{q^{2}}}\right) LSSAxe2(Q,K)=Sofmax q2lp2lp2QqKpT
其中
d
d
d是维度,
l
p
j
l_{p}^{j}
lpj是从
j
j
j到
J
+
1
J+1
J+1计算过程中当前补丁
p
p
p可以关注的补丁索引。
这种对数稀疏性通过动态调整感受野平衡效率和性能,增强长程模式识别的同时保留局部性。补充材料2中的定理1证明了对数稀疏自注意力机制的复杂度分析。
- 全局平均池化
我们通过GAP增强位置敏感性,通过平均 x e 2 x_{e 2} xe2中的所有时空信息,这些信息存储在从 Q / K / V 36 \mathrm{Q} / \mathrm{K} / \mathrm{V}{ }^{36} Q/K/V36派生的V矩阵中。这导致每个通道的单个值,简化特征图并仅保留基本的全局特征。公式(2)展示了GAP操作:
G A P x e 2 , d = 1 H × W ∑ i = 1 H ∑ j = 1 W V i , j G A P_{x_{e 2}, d}=\frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} V_{i, j} GAPxe2,d=H×W1i=1∑Hj=1∑WVi,j
其中 H H H和 W W W是特征图的高度和宽度, V i , j V_{i, j} Vi,j是矩阵V位置 ( i , j ) (i, j) (i,j)的值。
- 自适应门控机制
我们结合 L S S A L S S A LSSA和 G A P G A P GAP的输出,使用自适应门控机制来平衡短程和长程依赖关系。该机制包含一个门控神经网络(GNN),通过SoftMax激活函数生成门值( g g g ),形成概率分布 37 { }^{37} 37。因此,它动态评估注意力权重并根据时间依赖关系的相对重要性 17 { }^{17} 17 选择性增强短程或长程依赖关系 38 { }^{38} 38。我们应用门控机制与 L S S A L S S A LSSA和 G A P G A P GAP,以及整个输入的卷积,以替代静态位置编码和经典自注意力,从而使上下文感知的动态适应变化的时间依赖关系更为高效。公式(3)和(4)显示了门控机制公式。
g = Softmax ( w ⋅ L S S A x e 2 + b ) Gating x e 2 = g ⋅ L S S A x e 2 + ( 1 − g ) ⋅ G A P x e 2 \begin{aligned} g & =\operatorname{Softmax}\left(w \cdot L S S A_{x_{e 2}}+b\right) \\ \operatorname{Gating}_{x_{e 2}} & =g \cdot L S S A_{x_{e 2}}+(1-g) \cdot G A P_{x_{e 2}} \end{aligned} gGatingxe2=Softmax(w⋅LSSAxe2+b)=g⋅LSSAxe2+(1−g)⋅GAPxe2
其中 w w w是可学习的权重, b b b是偏置。
3.3. 解码器
解码器遵循经典的Transformer解码器结构,由多头注意力层、前馈层和层归一化组成 13 { }^{13} 13。它接受由编码器生成的词汇表示,并自回归地生成口语文本。
4. 提议的MedASL数据集
表2展示了文献中用于SLR(S2G)或SLT(S2T或S2G2T)的公共数据集概述。虽然几个数据集包含视频、词汇和文本 1 , 39 − 44 { }^{1,39-44} 1,39−44,但它们是为了通用日常交流设计的,只有少数涉及特定领域的交流,例如天气 [1, 20]、紧急情况 40 { }^{40} 40 和公共服务 41 { }^{41} 41。然而,医疗保健作为一个精确交流至关重要的领域,仍然代表性不足。缺乏医学手语数据集限制了SLMT系统在临床环境中的适用性,而无缝和准确的交流可以改善个体护理。因此,引入标注的医疗数据集至关重要。
因此,我们引入了MedASL,这是一个专注于医学交流的ASL语料库,具有词汇和文本注释。它旨在支持研究人员和行业专业人士推进SLMT系统。通过纳入医学术语和先进的数据采集技术,例如Intel RealSense相机,MedASL能够开发准确且情境感知的模型,反映真实世界的医疗场景。数据集包括500条医疗和健康相关的陈述,通过ChatGPT工程提示生成 45 { }^{45} 45 并由ASL专家签署,模拟患者和医疗专业人员之间的现实对话。我们在补充材料3中提供了提示工程设计和数据预处理。
表2:公共手语翻译数据集摘要。
| 数据集 | 年份 | 手语 语言 | 领域 | 视频 | 词汇 | 文本 | 语言 单位 | #视频 | 分辨率 | 采集 |
|---|---|---|---|---|---|---|---|---|---|---|
| BOSTON-104 46 { }^{46} 46 | 2008 | ASL | NR | ✓ \checkmark ✓ | ✓ \checkmark ✓ | X \boldsymbol{X} X | 句子 | 201 | 195 × 165 195 \times 165 195×165 | RGB |
| ASLLVD 47 { }^{47} 47 | 2008 | ASL | 通用 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | X \boldsymbol{X} X | 单词 | + 3 , 300 +3,300 +3,300 | 不同 | RGB |
| ASLG-PG12 48 { }^{48} 48 | 2012 | ASL | NR | X \boldsymbol{X} X | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 句子 | NA | NA | NA |
| BSL Corpus 42 { }^{42} 42 | 2013 | BSL | 通用 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 句子 | NR | NR | RGB |
| S-pot 43 { }^{43} 43 | 2014 | Suvi | NR | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 句子 | 5,539 | 720×576 | RGB |
| :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: |
| PHOENIX14 39 { }^{39} 39 | 2015 | DGS | 天气 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 句子 | 6,841 | 210×260 | RGB |
| BosphorusSign 49 { }^{49} 49 | 2016 | TID | 通用 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | X \boldsymbol{X} X | 单词& 句子 | + 22 , 000 +22,000 +22,000 | 1920×1080 | Kinect v2 |
| CSL 50 { }^{50} 50 | 2018 | CSL | 通用 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | X \boldsymbol{X} X | 句子 | 5,000 | 1920×1080 | RGB |
| PHOENIX14T 1 { }^{1} 1 | 2018 | DGS | 天气 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 句子 | 8,257 | 210×260 | RGB |
| KETI 40 { }^{40} 40 | 2019 | KSL | 紧急 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 句子 | 14,672 | 1920×1080 | HD RGB |
| CoL-SLTD 51 { }^{51} 51 | 2020 | LSC | 通用 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | X \boldsymbol{X} X | 单词& 句子 | 1,020 | 448×448 | RGB |
| ASLing 52 { }^{52} 52 | 2021 | ASL | 通用 | ✓ \checkmark ✓ | X \boldsymbol{X} X | ✓ \checkmark ✓ | 句子 | 1,284 | 450×600 | RGB |
| How2Sign 53 { }^{53} 53 | 2021 | ASL | 通用 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | X \boldsymbol{X} X | 单词& 句子 | + 30 , 000 +30,000 +30,000 | 1280×720 | RGB |
| GSL Dataset 41 { }^{41} 41 | 2021 | GSL | 公共 服务 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 句子 | 10,295 | 840×480 | Intel RealSense |
| ISL-CSLTR 44 { }^{44} 44 | 2021 | ISL | 通用 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 句子 | 700 | NR | RGB |
| MedASL (我们的) | 2025 | ASL | 医疗 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 句子 | 500 | 1280×800 | Intel RealSense |
ASL: 美国;BSL: 英国;CSL: 中国;DGS: 德国;GSL: 希腊;ISL: 印度;KSL: 韩国;LSC: 哥伦比亚;Suvi: 芬兰;TID: 土耳其。
NA: 不适用;NR: 未报告。
5. 性能评估
5.1. 实验环境
- 数据集
我们在PHOENIX14T 1 { }^{1} 1 和MedASL上评估我们提出的ADAT模型。PHOENIX14T是一个与德语天气相关的数据集,包含8,257个带符号的视频及其相应的词汇和德语文本。其总词汇量为1,115个词汇和3,000个德语文本。PHOENIX14T数据集已预先划分为训练集、验证集和测试集,而我们将MedASL数据集划分为80%用于5折交叉验证,20%用于测试。
- 评估指标
我们通过计算训练和验证时间(训练时间)以秒为单位来衡量时间效率。我们还使用标准化的BLEU评分 54 { }^{54} 54 来评估准确性,n-gram范围从1到4,如公式(5)和(6)所示。
B L E U = B P ⋅ e ( ∑ n = 1 N w n log ( p n ) ( 5 ) B L E U=B P \cdot e^{\left(\sum_{n=1}^{N} w_{n} \log \left(p_{n}\right)(5)\right.} BLEU=BP⋅e(∑n=1Nwnlog(pn)(5)
其中 p n p_{\mathrm{n}} pn是n-gram的精度, w n w_{\mathrm{n}} wn是每个n-gram大小的权重, B P B P BP是简洁惩罚。
B P = { 1 , if c > r e ( 1 − r c ) , if c ≤ r B P= \begin{cases}1, & \text { if } c>r \\ e^{\left(1-\frac{r}{c}\right)}, & \text { if } c \leq r\end{cases} BP={1,e(1−cr), if c>r if c≤r
其中 c c c是候选机器翻译的长度, r r r是参考语料库的长度。
5.2. 实验
我们在2块NVIDIA RTX A6000 GPU上使用TensorFlow实施ADAT。为了确保在不同数据集上的高效计算,我们将输入帧调整为 52 × 65 52 \times 65 52×65,以标准化分辨率为标准而不进行裁剪操作。
我们对训练ADAT进行了有结构的多阶段超参数搜索,以确定最佳值。在每个阶段,部分超参数被调整,而其他部分固定不变。优化目标是在验证集上最大化BLEU-4,同时重点关注关键架构和训练参数,如表3所示。在所有实验中,我们使用了标签平滑为0.1的稀疏分类交叉熵、Adam优化器、学习率调度,学习率按因子0.5递减至 2 × 1 0 − 6 2 \times 10^{-6} 2×10−6,耐心期为9个epoch,并基于验证损失设置了15个epoch的早期停止。
表3:对正在研究的Transformer架构进行超参数调整。
| 超参数 | 搜索空间 | S2G2T的最佳值 | S2T的最佳值 |
|---|---|---|---|
| 编码器数量 | 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 1,2,3,4,5,6,7,8,9,10,11,12 1,2,3,4,5,6,7,8,9,10,11,12 | 12 | 1 |
| 解码器数量 | 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 1,2,3,4,5,6,7,8,9,10,11,12 1,2,3,4,5,6,7,8,9,10,11,12 | 12 | 1 |
| 隐藏单元 | 256, 512, 1024 | 1024 | 512 |
| 注意头数 | 4 , 8 , 16 4,8,16 4,8,16 | 16 | 8 |
| 前馈大小 | 1024, 2048, 4096 | 1024 | 1024 |
| Dropout率 | 0 , 0.1 , 0.2 , 0.4 , 0.5 , 0.6 0,0.1,0.2,0.4,0.5,0.6 0,0.1,0.2,0.4,0.5,0.6 | 0 | 0.1 |
| 学习率 | 1 0 − 3 , 1 0 − 4 , 1 0 − 5 , 2 × 1 0 − 5 , 3 × 1 0 − 5 , 4 × 1 0 − 5 , 5 × 1 0 − 5 10^{-3}, 10^{-4}, 10^{-5}, 2 \times 10^{-5}, 3 \times 10^{-5}, 4 \times 10^{-5}, 5 \times 10^{-5} 10−3,10−4,10−5,2×10−5,3×10−5,4×10−5,5×10−5 | 5 × 1 0 − 5 5 \times 10^{-5} 5×10−5 | 1 0 − 3 10^{-3} 10−3 |
| 权重衰减 | 0 , 0.1 , 1 0 − 2 , 1 0 − 3 0,0.1,10^{-2}, 10^{-3} 0,0.1,10−2,10−3 | 0 | 1 0 − 3 10^{-3} 10−3 |
NA: 不适用;NR: 未报告。
6. 实验结果分析
本节对我们在S2G2T和S2T翻译任务中提出的ADAT模型进行了全面的数值评估。我们将ADAT与几种基于Transformer的基线模型进行比较,使用BLEU分数评估翻译质量、训练时间评估效率以及FLOPs评估计算复杂度。表4总结了在两项任务和数据集上的翻译性能。
表4:符号到词汇到文本和符号到文本翻译模型的比较(分数范围在0到1之间,越高越好)。
| Transformer Model | 数据集 | 验证 | 测试 | |||||
|---|---|---|---|---|---|---|---|---|
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | BLEU-1 | BLEU-2 | BLEU-3 | ||
| 符号到词汇到文本 | ||||||||
| Encoder-Decoder | PHOENIX14T | 0.370 | 0.214 | 0.141 | 0.096 | 0.373 | 0.219 | 0.145 |
| ADAT | 0.371 | 0.210 | 0.139 | 0.097 | 0.374 | 0.219 | 0.145 | |
| Encoder-Decoder | MedASL | 0.583 | 0.483 | 0.421 | 0.352 | 0.314 | 0.193 | 0.122 |
| ADAT | 0.584 | 0.484 | 0.425 | 0.353 | 0.307 | 0.189 | 0.119 | |
| 符号到文本 | ||||||||
| Encoder-Decoder | PHOENIX14T | 0.100 | 0.034 | 0.020 | 0.006 | 0.030 | 0.010 | 0.006 |
| Encoder-Only | 0.133 | 0.052 | 0.034 | 0.025 | 0.130 | 0.060 | 0.042 | |
| Decoder-Only | 0.000 | 0.000 | 0.000 | 0.000 | 0.002 | 0.000 | 0.000 | |
| ADAT | 0.349 | 0.199 | 0.133 | 0.093 | 0.346 | 0.197 | 0.130 | |
| Encoder-Decoder | MedASL | 0.610 | 0.513 | 0.447 | 0.383 | 0.311 | 0.193 | 0.123 |
| Encoder-Only | 0.123 | 0.045 | 0.014 | 0.006 | 0.116 | 0.003 | 0.009 | |
| Decoder-Only | 0.061 | 0.008 | 0.003 | 0.002 | 0.037 | 0.005 | 0.003 | |
| ADAT | 0.636 | 0.551 | 0.490 | 0.430 | 0.317 | 0.202 | 0.123 |
6.1. 符号到词汇到文本
在PHOENIX14T上,ADAT的表现与编码器-解码器基线相当,在所有BLEU分数上差异很小。特别是,ADAT在测试集上实现了略高的BLEU-4分数,表明在较长n-gram生成方面流畅性有所提高。然而,在MedASL上,两个模型之间在验证集和测试集上的表现差距明显,突显了领域转移和泛化挑战。ADAT持续改进验证分数,特别是在BLEU-3和BLEU-4方面。然而,它在测试集上的表现稍逊一筹,表明在未见数据上存在过拟合和鲁棒性降低的问题。
图2展示了两种模型的训练时间。在PHOENIX14T上,ADAT比基线快14.3%,减少了训练成本同时保持翻译质量。在MedASL上,由于数据集规模较小,整体训练时间较低,ADAT仍实现了3.2%的速度提升。这些结果证实,ADAT在提供具有竞争力的翻译性能的同时更加计算高效。
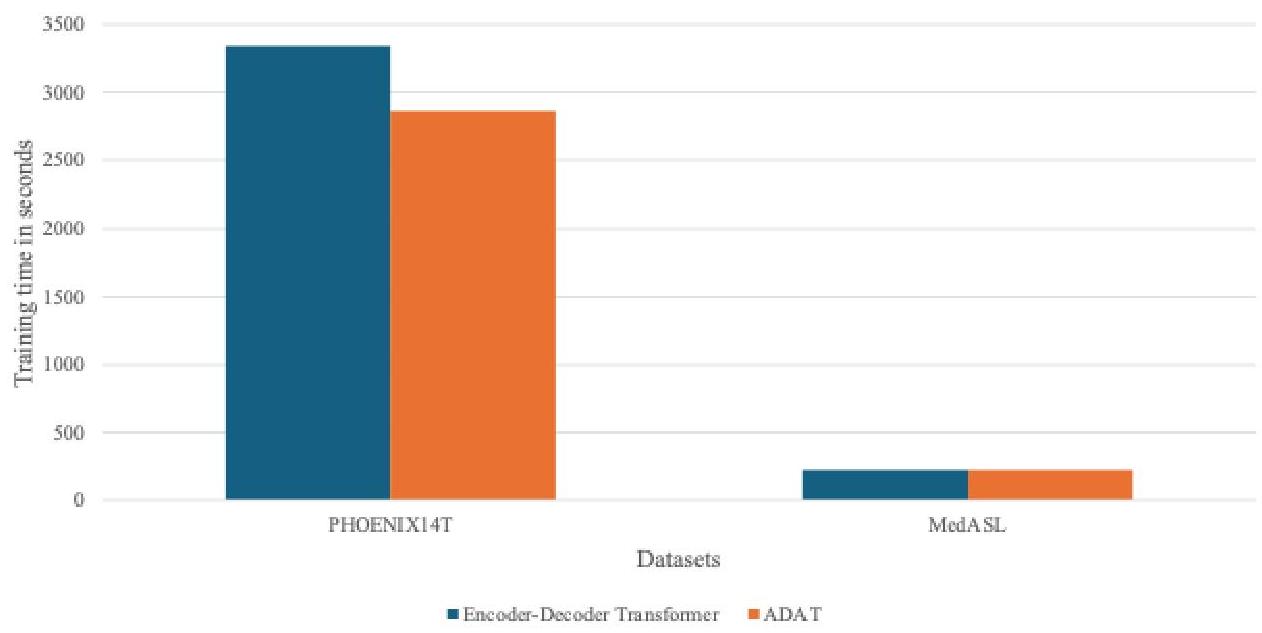
图2:符号到词汇到文本训练时间。
总之,在S2G2T翻译中,ADAT保持了与基线相当或更好的翻译性能,同时显著减少了训练时间——尤其是在较大数据集上,使其成为一个更具可扩展性和效率的选择。
6.2. 符号到文本
在直接S2T翻译中,ADAT在两个数据集上均优于编码器-解码器、仅编码器和仅解码器基线。特别是在PHOENIX14T上,ADAT相对于编码器-解码器基线大幅提高了BLEU-4。另一方面,仅编码器和仅解码器变体的表现显著较差,这凸显了在统一架构中结合词汇接地和语言建模的重要性。在MedASL上,ADAT超越了编码器-解码器基线,而仅编码器和仅解码器变体虽然实现了一定程度的对齐,但其表现仍然显著较低。
图3显示ADAT保持了有竞争力的训练效率。在PHOENIX14T上,它比编码器-解码器基线快2.7%。然而,尽管仅解码器训练更快,但它未能产生有意义的翻译。在MedASL上,ADAT保持其优势,训练时间减少了7.2%,平衡了效率和准确性。
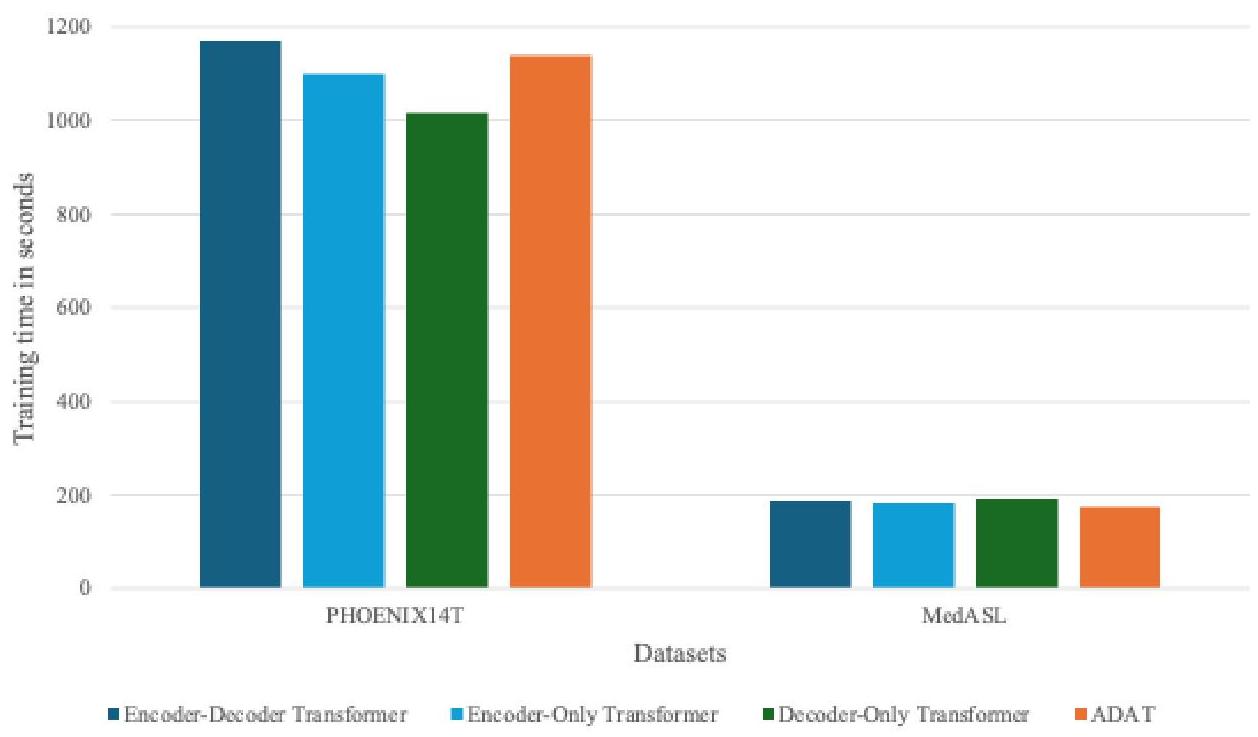
图3:符号到文本训练时间。
总之,ADAT在S2T任务上实现了最先进的翻译质量,同时在两个数据集上保持了有竞争力的训练效率,超越了简化版Transformer变体的准确性和通用性。综上所述,在S2G2T和S2T任务中,ADAT始终表现出强劲的翻译性能,同时相对基线模型提高了训练效率。这些结果表明ADAT能够扩展到更大的数据集,并在不同领域中保持稳健性,为手语翻译提供了一个实用且高效的解决方案。
6.3. 复杂性效率分析
我们进一步通过测量每秒浮点运算次数(FLOPs)来比较ADAT与编码器-解码器Transformer的计算效率,如表5所示。实验在PHOENIX14T上进行,在受控实验设置下使用1个编码器、1个解码器、512个隐藏单元、2048前馈大小、0.1的Dropout率和初始学习率为
5
×
1
0
−
5
5 \times 10^{-5}
5×10−5,按因子0.5递减至最低
2
×
1
0
−
6
2 \times 10^{-6}
2×10−6。我们的分析揭示了编码器输出长度对解码器复杂度的影响,从而影响S2G2T和S2T的整体计算性能。
在S2G2T中,编码器生成一个包含27个标记的词汇序列,而在S2T中,它生成整个视频序列的高维表示,包含371帧。这种差异显著影响了解码器的计算复杂度,尽管在两个模型中采用了相同的解码器。特别是,S2G2T中较短的编码器输出减少了解码期间的计算开销,仅需1.85千兆FLOPs(GFLOPs)在两个模型中。然而,Transformer编码器是最耗计算资源的部分,需要12.74 GFLOPs,而ADAT仅需6.72 GFLOPs。这一优化导致训练时间减少了26.2%。
相反,S2T引入了更显著的计算负担,因为编码器输出长度增加。解码器必须处理371帧序列而不是27个词汇表示,增加了交叉注意力的工作量和整体FLOPs。因此,解码需要5 GFLOPs,高于S2G2T,导致显著的
计算开销。虽然ADAT将编码器FLOPs从12.74减少到2.08 GFLOPs,但由于解码器复杂性的增加,整体训练加速效果有限,仅减少6.8%的训练时间。解码器复杂性的增加限制了编码器优化带来的效率提升,使S2T比S2G2T更具计算密集性。
表5:复杂性效率比较。
| 翻译 | 符号到词汇到文本 | 符号到文本 | ||
|---|---|---|---|---|
| 模型 | Transformer | ADAT | Transformer | ADAT |
| 编码器输入长度 | 371 | 371 | 371 | 371 |
| 解码器输入长度 | 词汇: 27 | 词汇: 27 | 视频: 371 | 视频: 371 |
| 文本: 52 | 文本: 52 | 文本: 52 | 文本: 52 | |
| 编码FLOPs | 12.74 Giga | 6.72 Giga | 12.74 Giga | 2.28 Giga |
| 解码FLOPs | 1.85 Giga | 1.85 Giga | 5 Giga | 5 Giga |
| 总FLOPs | 14.59 Giga | 8.57 Giga | 17.74 Giga | 7.28 Giga |
| 训练时间 | 2428.57 秒 | 1791.67 秒 | 1160.84 秒 | 1081.89 秒 |
总结来说,S2G2T得益于较短的编码器输出,减少了解码器复杂度并显著提高了计算效率。ADAT在S2G2T中的编码器优化显著降低了FLOPs,导致训练时间减少了26.2%。然而,S2T中较长的编码器输出增加了解码复杂度,削弱了ADAT编码器的影响。尽管ADAT实现了显著的FLOP减少,但由于解码器计算较少,S2G2T的训练时间改善更为明显。
7. 结论与未来工作
本研究提出了一种新颖的自适应Transformer(ADAT),通过有效捕捉手语的短程和远程时间依赖关系来改进符号到词汇到文本和符号到文本翻译。我们在RWTH-PHOENIX-Weather-2014(PHOENIX14T)数据集和MedASL上验证了ADAT,这是一个在本研究中引入的新医疗手语数据集,作为评估医疗环境中翻译准确性的基准。我们的对比评估显示,ADAT通过显著减少训练时间同时保持翻译准确性,优于包括编码器-解码器、仅编码器和仅解码器在内的基线Transformer模型。这些发现突显了ADAT在创建高效和可扩展SLMT系统的潜力,弥合沟通障碍并促进聋人群体的包容性。
未来的工作将把多语言组件集成到ADAT架构中。此外,我们旨在开发一种轻量级版本的ADAT,优化部署于边缘设备上,以促进在计算资源受限环境中的实际应用。
参考文献
- Camgoz, N. C., Hadfield, S., Koller, O., Ney, H. & Bowden, R. Neural Sign Language Translation. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 7784-7793 (2018).
-
- World Health Organization. Deafness and hearing loss. World Health Organization https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss (2023).
-
- Kumar, V. K., Goudar, R. H. & Desai, V. T. Sign Language Unification: The Need for Next Generation Deaf Education. Procedia Comput Sci 48, 673-678 (2015).
-
- Registry of Interpreters for the Deaf. Registry. Registry of Interpreters for the Deaf https://rid.org (2023).
-
- Shahin, N. & Ismail, L. From rule-based models to deep learning transformers architectures for natural language processing and sign language translation systems: survey, taxonomy and performance evaluation. Artif Intell Rev 57, 271 (2024).
-
- Ismail, L. & Zhang, L. Information Innovation Technology in Smart Cities. (2018). doi:10.1007/978-981-10-1741-4.
-
- Zhang, Z. et al. Universal Multimodal Representation for Language Understanding. IEEE Trans Pattern Anal Mach Intell 1-18 (2023) doi:10.1109/TPAMI.2023.3234170.
-
- Jay, M. Don’t Just Sign… Communicate!: A Student’s Guide to Mastering ASL Grammar. (Judea Media, LLC, 2011).
-
- Papastratis, I., Chatzikonstantinou, C., Konstantinidis, D., Dimitropoulos, K. & Daras, P. Artificial Intelligence Technologies for Sign Language. Sensors 21, 5843 (2021).
10.10. Camgoz, N., Koller, O., Hadfield, S. & Bowden, R. Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation. in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 10023-10033 (2020).
- Papastratis, I., Chatzikonstantinou, C., Konstantinidis, D., Dimitropoulos, K. & Daras, P. Artificial Intelligence Technologies for Sign Language. Sensors 21, 5843 (2021).
- Jin, T., Zhao, Z., Zhang, M. & Zeng, X. MC-SLT: Towards Low-Resource Signer-Adaptive Sign Language Translation. in Proceedings of the 30th ACM International Conference on Multimedia 4939-4947 (ACM, New York, NY, USA, 2022). doi:10.1145/3503161.3548069.
-
- Shahin, N. & Ismail, L. ChatGPT, Let Us Chat Sign Language: Experiments, Architectural Elements, Challenges and Research Directions. in 2023 International Symposium on Networks, Computers and Communications (ISNCC) 1-7 (IEEE, 2023). doi:10.1109/ISNCC58260.2023.10323974.
-
- Vaswani, A., Shazeer, N., Parmar, N. & Uszkoreit, J. Attention is All You Need. in Advances in Neural Information Processing Systems (2017).
-
- Yang, M., Gao, H., Guo, P. & Wang, L. Adapting Short-Term Transformers for Action Detection in Untrimmed Videos. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 18570-18579 (2024).
-
- Wang, J., Bertasius, G., Tran, D. & Torresani, L. Long-short temporal contrastive learning of video transformers. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 14010 − 14020 ( 2022 ) 14010-14020(2022) 14010−14020(2022).
-
- Li, S. et al. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. in Advances in neural information processing systems (2019).
-
- Chattopadhyay, R. & Tham, C.-K. A Position Aware Transformer Architecture for Traffic State Forecasting. in IEEE 99th Vehicular Technology Conference (IEEE, Singapore, 2024).
-
- Ismail, L. & Buyya, R. Metaverse: A Vision, Architectural Elements, and Future Directions for Scalable and Realtime Virtual Worlds. ArXiv (2023).
-
- Zhou, H., Zhou, W., Qi, W., Pu, J. & Li, H. Improving Sign Language Translation with Monolingual Data by Sign Back-Translation. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 1316-1325 (2021).
- | 20. | Kan, J. et al. Sign Language Translation with Hierarchical Spatio-Temporal Graph Neural Network. in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 3367–3367 (2022). |
- | — | — |
- | 21. | Xie, P., Zhao, M. & Hu, X. PiSLTRc: Position-Informed Sign Language Transformer With Content-Aware Convolution. IEEE Trans Multimedia 24, 3908–3919 (2022). |
- | 22. | Gan, S. et al. Contrastive Learning for Sign Language Recognition and Translation. in Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence 763–772 (International Joint Conferences on Artificial Intelligence Organization, California, 2023). doi:10.24963/ijcai.2023/85. |
- | 23. | Zhang, B., Müller, M. & Sennrich, R. SLTUNET: A Simple Unified Model for Sign Language Translation. in International Conference on Learning Representations (2023). |
- | 24. | Yin, A. et al. SimulSLT: End-to-End Simultaneous Sign Language Translation. in Proceedings of the 29th ACM International Conference on Multimedia 4118–4127 (ACM, New York, NY, USA, 2021). doi:10.1145/3474085.3475544. |
- | 25. | Chen, Y., Wei, F., Sun, X., Wu, Z. & Lin, S. A Simple Multi-Modality Transfer Learning Baseline for Sign Language Translation. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 5120–5130 (2022). |
- | 26. | Graves, A., Fernández, S., Gomez, F. & Schmidhuber, J. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. in Proceedings of the 23rd international conference on Machine learning - ICML ’06 369–376 (ACM Press, New York, New York, USA, 2006). doi:10.1145/1143844.1143891. |
- | 27. | Zhao, J. et al. Conditional Sentence Generation and Cross-Modal Reranking for Sign Language Translation. IEEE Trans Multimedia 24, 2662–2672 (2022). |
- | 28. | Jin, T., Zhao, Z., Zhang, M. & Zeng, X. Prior Knowledge and Memory Enriched Transformer for Sign Language Translation. in Findings of the Association for Computational Linguistics: ACL 2022 3766–3775 (Association for Computational Linguistics, Stroudsburg, PA, USA, 2022). doi:10.18653/v1/2022.findings-acl.297. |
- | 29. | Chaudhary, L., Ananthanarayana, T., Hoq, E. & Nwogu, I. SignNet II: A Transformer-Based Two-Way Sign Language Translation Model. IEEE Trans Pattern Anal Mach Intell 1–14 (2022) doi:10.1109/TPAMI.2022.3232389. |
- | 30. | Yu, P., Zhang, L., Fu, B. & Chen, Y. Efficient Sign Language Translation with a Curriculum-based Non-autoregressive Decoder. in Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence 5260–5268 (International Joint Conferences on Artificial Intelligence Organization, California, 2023). doi:10.24963/ijcai.2023/584. |
- | 31. | Yin, A. et al. Gloss Attention for Gloss-free Sign Language Translation. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2551–2562 (2023). |
- | 32. | Zhou, B. et al. Gloss-free Sign Language Translation: Improving from Visual-Language Pretraining. in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 20871–20881 (2023). |
- | 33. | Ismail, L. & Guerchi, D. Performance evaluation of convolution on the Cell Broadband Engine processor. IEEE Transactions on Parallel and Distributed Systems 22, 337–351 (2011). |
-
- Scherer, D., Müller, A. & Behnke, S. Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition. in 92-101 (2010). doi:10.1007/978-3-642-15825-4_10.
-
- Shen, L. & Wang, Y. TCCT: Tightly-coupled convolutional transformer on time series forecasting. Neurocomputing 480, 131-145 (2022).
-
- Zhou, B., Khosla, A., Lapedriza, A., Oliva, A. & Torralba, A. Learning deep features for discriminative localization. in Proceedings of the IEEE conference on computer vision and pattern recognition 2921-2929 (2016).
-
- Bridle, J. Training stochastic model recognition algorithms as networks can lead to maximum mutual information estimation of parameters. in Advances in neural information processing systems (1989).
-
- Lee, J. Y., Cheon, S. J., Choi, B. J. & Kim, N. S. Memory Attention: Robust Alignment Using Gating Mechanism for End-to-End Speech Synthesis. IEEE Signal Process Lett 27, 2004-2008 (2020).
-
- Koller, O., Forster, J. & Ney, H. Continuous sign language recognition: Towards large vocabulary statistical recognition systems handling multiple signers. Computer Vision and Image Understanding 141, 108-125 (2015).
-
- Ko, S.-K., Kim, C. J., Jung, H. & Cho, C. Neural Sign Language Translation Based on Human Keypoint Estimation. Applied Sciences 9, 2683 (2019).
-
- Adaloglou, N. et al. A Comprehensive Study on Deep Learning-Based Methods for Sign Language Recognition. IEEE Trans Multimedia 24, 1750-1762 (2022).
-
- Schembri, A., Fenlon, J., Rentelis, R., Reynolds, S. & Cormier, K. Building the British sign language corpus. in (University of Hawaii Press, 2013).
-
- Viitaniemi, V., Jantunen, T., Savolainen, L., Karppa, M. & Laaksonen, J. S-pot: a benchmark in spotting signs within continuous signing. in LREC (European Language Resources Association, 2014).
-
- Elakkiya, R. & NATARAJAN, B. ISL-CSLTR: Indian Sign Language Dataset for Continuous Sign Language Translation and Recognition. Mendeley Data 1, (2021).
-
- OpenAI. ChatGPT. https://chat.openai.com (2022).
-
- Dreuw, P., Forster, J., Deselaers, T. & Ney, H. Efficient approximations to model-based joint tracking and recognition of continuous sign language. in 2008 8th IEEE International Conference on Automatic Face & Gesture Recognition 1-6 (IEEE, 2008). doi:10.1109/AFGR.2008.4813439.
-
- Athitsos, V. et al. The American Sign Language Lexicon Video Dataset. in 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops 1-8 (IEEE, 2008). doi:10.1109/CVPRW.2008.4563181.
-
- Othman, A. & Jemni, M. English-asl gloss parallel corpus 2012: Aslg-pc12. in LREC 151-154 (European Language Resources Association (ELRA), 2012).
-
- Camgo’z, N. C. et al. BosphorusSign: A Turkish sign language recognition corpus in health and finance domains. in Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16) 1383-1388 (2016).
-
- Guo, D., Zhou, W., Li, H. & Wang, M. Hierarchical LSTM for Sign Language Translation. in Proceedings of the AAAI Conference on Artificial Intelligence vol. 32 (2018).
-
- Rodriguez, J. et al. Understanding Motion in Sign Language: A New Structured Translation Dataset. in Proceedings of the Asian Conference on Computer Vision (ACCV) (2020).
-
- Ananthanarayana, T. et al. Dynamic Cross-Feature Fusion for American Sign Language Translation. in 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021) 1-8 (IEEE, 2021). doi:10.1109/FG52635.2021.9667027.
-
- Duarte, A. et al. How2Sign: a large-scale multimodal dataset for continuous American sign language. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2735-2744 (2021).
-
- Papineni, K., Roukos, S., Ward, T. & Zhu, W.-J. BLEU: a method for automatic evaluation of machine translation. in Proceedings of the 40th Annual Meeting on Association for Computational Linguistics - ACL '02 311 (Association for Computational Linguistics, Morristown, NJ, USA, 2001). doi:10.3115/1073083.1073135.
-
补充信息
补充1:自适应Transformer(ADAT)算法
算法 1 自适应Transformer(ADAT)
阶段 1:特征提取
输入:\(x=\left\{x_{f}\right\}_{f=1}^{p}\)
输出:\(x_{e}\)
对每个\(x_{f}\)执行以下操作:
\(C N N_{\text {Features }}=2 D C N N\left(x_{f}\right)\)
Pooled \(_{\text {Features }}=\operatorname{MaxPooling}\left(C N N_{\text {Features }}\right)\)
Flattened \(=\) Flatten(Pooled \(_{\text {Features }}\) )
将Flattened附加到\(x_{e}\)
阶段 2:编码器处理
输入:\(x_{e}\)
输出:\(x_{e 1}, x_{e 2}\)
沿时间维度将\(x_{e}\)等分为两半:
\(x_{e}=\left[x_{e 1}^{\rho_{1} \times n_{1}} \times n_{1}, x_{e 2}^{\rho_{2} \times n_{2} \times n_{2}}\right]\)
阶段 2.1:卷积路径
输入:\(x_{e 1}\)
输出:\(\operatorname{Conv}_{x_{e 2}}\)
\(\operatorname{Conv}_{x_{e 1}}=\operatorname{Conv}\left(x_{e 1}\right)\)
阶段 2.2:LogSparse Self-Attention (LSSA) 处理
输入:\(x_{e 2}\)
输出:\(L S S A_{x_{e 2}}\)
\(\mathrm{Q}=x_{e 2} \cdot W_{q}, \mathrm{~K}=x_{e 2} \cdot W_{k}, \mathrm{~V}=x_{e 2} \cdot W_{e}\)
对\(x_{e 2}\)中的每个位置p执行以下操作:
\(I_{q}^{j}=\left[p-2^{\left\{\log _{2} p\right\}} ; p-2^{\left\{\log _{2} p\right\}-1}, \ldots, p-2^{\mathrm{q}}, \mathrm{p}\right\}\)
\(L S S A_{p}=\operatorname{Softmax}\left(\left(Q\left[I_{p}^{j}\right] \cdot K\left[I_{p}^{j}\right]^{p}\right) / \sqrt{d / 2}\right)\)
\(\operatorname{LSSA}_{x_{e 2}}=\operatorname{Concat}\left(\operatorname{LSSA}_{p} \mid p \in x_{e 2}\right)\)
阶段 2.3:自适应门控机制
输入:V, \(\operatorname{Conv}_{x_{e 1}}, L S S A_{x_{e 2}}\)
输出:\(y_{e}\)(预测的词汇)
\(G A P_{x_{e 2}}=\) GlobalAveragePooling \((V)\)
\(g=\operatorname{Softmax}\left(w \cdot \operatorname{LSSA}_{x_{e 2}}+b\right)\)
Gating \(_{x_{e 2}}=g \cdot \operatorname{LSSA}_{x_{e 2}}+(1-g) \cdot G A P_{x_{e 2}}\)
\(\mathrm{y}_{e}=\operatorname{LayerNorm}\left(\operatorname{Concat}\left(\operatorname{Conv}_{x_{e 1}}, G a t i n g_{x_{e 2}}\right)\right)\)
阶段 3:解码器处理
输入:\(y_{e}\)
输出:\(y_{d}\)
\(x_{\text {embed }}=\operatorname{Embedding}\left(y_{e}\right)\)
\(x_{d}=\) Positional Encoding \(\left(x_{\text {embed }}\right)\)
\(\mathrm{y}_{d}=\operatorname{TransformerDecoder}\left(x_{d}\right)\)
```
# 补充2:Log-Sparse Self-Attention复杂度分析定理证明
定理 1. 设$n$为序列长度。在经典自注意力中,计算复杂度为$O(L)^{13}$。Log-Sparse Self-Attention(LSSA)${ }^{16}$通过仅关注过去标记的一个对数子集,将复杂度降低到$O\left(L(\log L)^{2}\right)$。
证明。在经典的多头自注意力中,输入序列$L$中的每个位置$p$和嵌入维度$d$都通过查询$\left(L_{q}\right)$和键$\left(L_{k}\right)$对之间的点积关注所有位置。这导致二次缩放$\left(L_{q} \times L_{k}\right)$,时间复杂度为$O\left(L^{2}\right)$每层。对于具有$h$注意头的Transformer,总时间复杂度每层缩放为:$O\left(h \cdot L^{2}\right)$。
LSSA选择一个对数子集的过去帧,其中选定的索引遵循对数间距,而不是关注所有先前的标记。具体来说,每个单元格$p$关注索引定义的单元格:
$$
I_{p}^{j}=\left\{p-2^{\left\{\log _{2} p\right\}}, p-2^{\left\{\log _{2} p\right\}-1}, \ldots, p-2^{0}, p\right\}
$$
其中被关注单元格之间的间距呈指数增长,将每个单元格的关注位置数量减少到$O(\log L)$。这种复杂度的减少显著提高了模型的效率,允许其处理更高帧率的手势视频,同时相比标准Transformer架构降低了计算开销。
## 补充3:提议的MedASL数据集处理
### 3.1 提示工程设计
为了创建MedASL,我们设计并开发了提示,采用以下方法:
- 高级提示结构
我们设计了一个高级提示,以生成真实的医疗对话,格式如下:
"生成一个患者和[医生/护士/药剂师/技师]在医疗环境中的真实医疗互动。对话应涉及常见症状、医疗建议和关于治疗或处方的问题。确保语言清晰、专业且适合现实场景。"
- 细化过程
我们通过将高级提示细化为低级提示来提高生成句子的一致性和相关性,例如:
"生成10条护士在检查患者生命体征时可能说的医疗相关陈述。"
### 3.2 数据预处理
我们使用Intel RealSense以$1280 \times 800$分辨率录制手势视频,并将其存储为".npy"格式。为了准备视频数据进行训练,我们应用了以下预处理步骤:
- 视频帧提取:我们以每秒30帧(fps)采样视频,以保持动作保真度。
- - 帧连接:我们将对应每个句子的视频帧连接成连续序列,以与词汇注释对齐。
- - 填充:我们应用零填充以对齐所有视频的帧长度。
对于手语词汇和口语文本,我们应用了以下额外的预处理步骤:
- 构建词汇表:我们为词汇和文本数据创建唯一的词汇表,包括一个特殊标记<UNK>以代表未知单词。
- - 分配唯一索引:我们为词汇和文本数据中的每个词分配唯一索引以更好地处理。
- - 分词:我们将词汇和文本序列分词为单独的单位,以实现有效的输入表示。
- - 填充:我们对序列应用零填充,确保批量处理的统一长度。
- - 添加特殊标记:我们添加特殊标记<sos>(序列开始)和<eos>(序列结束)以标记序列边界。
- - 词汇对齐:我们将每个词汇注释映射到其对应的口语句子。
- - 数据序列化:我们将预处理后的词汇、文本和视频数据存储在标准化的" .pkl "格式中,以便在模型训练期间高效加载输入。
- 这些预处理步骤,如图S1所示,确保数据集标准化、鲁棒且优化用于训练和评估。表S1提供了原始数据和预处理数据的详细比较。
- 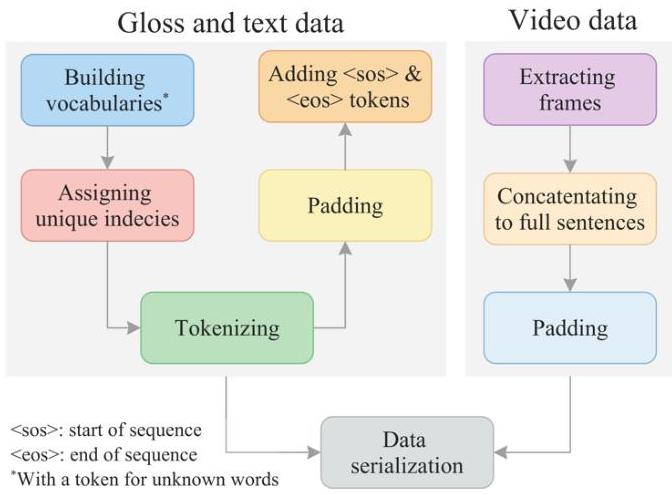
图S1:MedASL数据预处理步骤。
表S1:MedASL数据集的关键统计信息。
| | 原始 | 预处理 |
| :-- | :-- | :-- |
| 词汇表大小 | 833 | 833 |
| 文本词汇表大小 | 912 | 912 |
| 总段数* | 29,793 | 59,000 |
| 总帧数* | 893,790 | $1,770,000$ |
| 总时长(小时) | 8.3 | 16.4 |
| 最大词汇长度 | 10 | 10 |
| 最大文本长度 | 16 | 16 |
| 最大视频长度 | 118 | 118 |
| 手语者人数 | 1 | 1 |
| 独立视频/句子数量 | 500 | 500 |
参考论文:https://arxiv.org/pdf/2504.11942



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











