






张军磊
⋆
⋄
⋆
{ }^{\star} \diamond \star
⋆⋄⋆ 丁志辰* 马畅
Δ
{ }^{\Delta}
Δ 陈子杰
⋄
⋆
{ }^{\diamond \star}
⋄⋆ 孙启澍
Δ
{ }^{\Delta}
Δ
兰振忠* 何俊贤*
浙江大学 *西湖大学 *上海人工智能实验室
Δ
{ }^{\Delta}
Δ 香港大学
⋆
\star
⋆ 香港科技大学
摘要
图形用户界面(GUI)代理为跨平台自动化复杂数字任务提供了解决方案,具有显著的潜力来改变生产力工作流程。然而,其性能通常受到高质量轨迹数据稀缺性的限制。为了解决这一局限性,我们提出在专用的中程训练阶段对视觉语言模型(VLMs)进行数据丰富、推理密集型任务的训练,然后研究将这些任务纳入中程训练阶段如何促进对GUI规划场景的泛化。具体来说,我们探索了一系列具有现成指令调整数据的任务,包括GUI感知、多模态推理和文本推理。通过跨越11个中程训练任务的广泛实验,我们证明:(1) 任务泛化非常有效,在大多数设置下产生了显著改进。例如,多模态数学推理使AndroidWorld的性能提高了绝对值6.3%。值得注意的是,仅基于文本的数学数据显著提升了GUI网络代理的性能,在WebArena上达到了5.6%的改进,在AndroidWorld上达到了5.4%的改进,强调了从基于文本到视觉领域的显著跨模态泛化;(2) 与之前的假设相反,GUI感知数据——以前被认为与GUI代理任务紧密相关并被广泛用于训练——对最终性能的影响相对有限;(3) 基于这些见解,我们确定了最有效的中程训练任务,并策划了优化的混合数据集,结果在WebArena上实现了绝对8.0%的性能提升,在AndroidWorld上实现了12.2%的性能提升。我们的工作为GUI代理的跨领域知识迁移提供了有价值的见解,并为解决该新兴领域中的数据稀缺挑战提供了一种实用的方法。代码、数据和模型可在https://github.com/hkust-nlp/GUIMid获得。
1 引言
与图形用户界面(GUI)交互已成为人类与世界互动的基本部分,从浏览互联网到使用移动应用程序。开发能够无缝与这些界面交互的自主代理作为个人助手,有可能彻底改变日常生活(Xie等,2024;OpenAI,2025;Wu等,2024),使其更加高效和便捷。
构建GUI代理需要结合关键能力:感知——理解和解释GUI截图;接地——将人类指令转化为可执行动作;以及视觉规划——逐步完成任务以实现预期目标(Zheng等,2024b;Xu等,2024b;Ma等,2024)。其中,视觉规划是最具挑战性的(Gur等,2023;Koh等,2024b;Yu等,2024)。它要求将复杂的指令(如“查看我带有最多星标的GitHub存储库”)分解为
*共同第一作者。此工作是在JZ访问香港科技大学期间完成的。联系人:Junlei Zhang (zhangjunlei@westlake.edu.cn) 和 Junxian He (junxianh@cse.ust.hk).

图1:中程训练和微调过程概述。左:我们首先在中程训练数据上训练GUI代理,主要来自非GUI领域,以调查增强的能力是否可以泛化到GUI代理任务;右:我们在GUI轨迹数据上进行后训练。
精确、可操作的步骤。视觉语言模型(VLMs)自然具有作为指导GUI代理规划的策略模型的潜力。通过高级提示技术,它们可以充当GUI代理的基础模型(Zheng等,2024b;Song等,2024)。然而,大多数现有的VLMs缺乏作为有效GUI代理所需的可靠性和稳定性,往往在基准测试中表现不佳(Zhou等,2023;Deng等,2023;Koh等,2024a;Xie等,2024)。例如,gpt4-o(Hurst等,2024)在WebArena(Zhou等,2023)上的成绩仅为15.6%,而Qwen2-VL-7BInstruct(Wang等,2024a)几乎无法生成目标一致的动作。大多数错误源于任务需要多个连续步骤时规划不足。为了应对这一局限性,研究人员尝试通过收集或合成GUI轨迹数据来改进GUI策略VLMs(Xu等,2024b;a;Sun等,2024b;Ou等,2024)。然而,真实世界的GUI轨迹数据并不容易获取,使得获取多样且高质量的GUI数据集成为一个重大挑战。此外,使用大型模型合成轨迹往往会产生低质量输出,因为即使最先进的VLMs也难以在现实的GUI代理任务中有效执行。鉴于这一挑战,我们将研究重点放在一个关键问题上:如何利用更具扩展性的数据源来提高VLMs在GUI任务中的代理能力?
为此,我们引入了一个中程训练阶段,在有限的GUI轨迹子集上微调VLMs之前增强其基础代理能力。中程训练(如图1所示)指的是预训练和微调之间的中间训练阶段,模型在此阶段中通过增强专门能力以更好地适应。
1
{ }^{1}
1 虽然这种方法已在涉及LLMs和VLMs的各种情景中成功应用(Wang等,2024b;Sun等,2024a;Yang等,2025),但尚不清楚哪些类型的任务可以有效地泛化到学习GUI代理,考虑到此类任务的复杂性和通常广泛的上下文。先前探索替代数据源的研究主要集中在GUI特定资源上,如网络教程和GUI字幕(Chen等,2024;Xu等,2024a;Ou等,2024),这不足以代表
1
{ }^{1}
1 中程训练的定义可能有所不同,概念上与我们上下文中持续预训练在指令调整数据上的情况相似。
代理规划能力。在这项工作中,我们研究了一系列多样化的中程训练数据领域,以评估它们对学习GUI代理的影响。这些领域包括一般图像感知、图表理解、多模态推理和基于文本的任务,如数学和编程。
我们在七个多模态和四个文本数据集上进行评估,重点关注推理、知识检索和感知(§3.1)。每个领域都收集样本,分别进行中程训练,然后在GUI轨迹数据集上进行微调。通过将所有数据集标准化,以在接地到动作之前生成高层次的动作思考,我们增强了规划转移。连续优化器确保平稳的训练过渡并最小化遗忘。在移动和网络基准上的分析验证了我们中程训练方法的有效性。纯文本数学数据集显示出最大的收益,使AndroidWorld提高了5.4%,WebArena提高了5.6%,表明推理能力可以在不同领域之间转移。编码数据集在两项任务中均提升了约3.0%的性能。令人惊讶的是,视觉感知数据集带来的收益较小,可能是由于现有VLMs的强大视觉能力。基于这些见解,我们推出了GUIMid,这是一个包含四个最佳表现领域的300k数据集。GUIMid在纯视觉设置下的AndroidWorld上达到SOTA水平,并将Qwen2-VL提升至GPT4-o级别的网络浏览性能,整体收益分别为12.2%和8.0%。
2 基于视觉的GUI代理框架
纯视觉基础的GUI代理。以往的工作(Gur等,2023;Zheng等,2024b;Xie等,2024;Zhou等,2023)主要依赖于基于结构文本的GUI表示,例如HTML或可访问性树。相比之下,我们专注于更具挑战性的纯视觉设置,其中基于视觉的代理以屏幕截图和任务描述作为输入,在像素空间内直接生成基于坐标的动作。这种纯视觉方法提供了关键优势:(1) 它消除了对后端结构的依赖,能够在跨平台操作的同时避免可访问性树中经常存在的噪声;(2) 它更符合人类交互模式,允许无缝集成到实际工作流中。
推理过程可以形式化为部分可观测马尔可夫决策过程(POMDPs)的一个特殊实例,由元组 ⟨ g , S , A , O , T ⟩ \langle g, \mathcal{S}, \mathcal{A}, \mathcal{O}, \mathcal{T}\rangle ⟨g,S,A,O,T⟩表示,其中 g g g表示任务目标, S \mathcal{S} S表示状态空间, A \mathcal{A} A表示动作空间, O \mathcal{O} O表示观测空间(来自屏幕的视觉反馈), T : S × A → S \mathcal{T}: \mathcal{S} \times \mathcal{A} \rightarrow \mathcal{S} T:S×A→S表示状态转移函数。在每个时间步 t t t,代理根据策略 π \pi π执行决策,该策略整合了任务目标 g g g、记忆 m t = { o j , a j , o j + 1 , a j + 1 , … , o t − 1 , a t − 1 } , 0 ≤ j < t m_{t}=\left\{o_{j}, a_{j}, o_{j+1}, a_{j+1}, \ldots, o_{t-1}, a_{t-1}\right\}, 0 \leq j<t mt={oj,aj,oj+1,aj+1,…,ot−1,at−1},0≤j<t(记录了动作和观测的历史)以及当前观测 o t o_{t} ot。代理的轨迹,记为 τ = [ s 0 , a 0 , s 1 , a 1 , … , s t ] \tau=\left[s_{0}, a_{0}, s_{1}, a_{1}, \ldots, s_{t}\right] τ=[s0,a0,s1,a1,…,st],由策略和环境状态转移产生,公式如下:
p π ( τ ) = p ( s 0 ) ∏ t = 0 T π ( a t ∣ g , s t , m t ) T ( s t + 1 ∣ s t , a t ) p_{\pi}(\tau)=p\left(s_{0}\right) \prod_{t=0}^{T} \pi\left(a_{t} \mid g, s_{t}, m_{t}\right) \mathcal{T}\left(s_{t+1} \mid s_{t}, a_{t}\right) pπ(τ)=p(s0)t=0∏Tπ(at∣g,st,mt)T(st+1∣st,at)
然后我们在基于视觉的GUI代理框架中介绍观察和动作空间的具体实现。
动作空间。我们的GUI代理采用基于坐标的动作空间,以确保跨平台兼容性和真实的类人交互。生成动作的策略模型由两个组件组成:规划模型和接地模型。规划模型首先生成一个富含规划思维的高层次动作描述,即“任务指令 <思维> <高层次动作>”。然后接地模型将高层次动作映射到屏幕操作。
例如,在搜索引擎中搜索“GUI agents”,生成的内容为:
: 为了在metaseq GitLab仓库中找到未标记的问题,请点击主导航菜单中的“Issues”标签,然后筛选出没有标签的问题。
| 领域 | 能力 | 数据集 | 样本 | 类型 |
|---|---|---|---|---|
| 视觉与语言模态 | ||||
| 图表/文档问答 | 感知 | InfographicVQA (Guo等, 2024) | 2,184 | 指令,思维*, 答案 |
| Ureader QA (Guo等, 2024) | 53,794 | 指令,思维,答案 | ||
| MPDocVQA (Tito等, 2023) | 431 | 指令,思维,答案 | ||
| MathV360k (Liu等, 2024b) | 93,591 | 指令,思维,答案 | ||
| 非GUI感知 | 感知 | Ureader OCR (Ye等, 2023) | 6,146 | 指令,思维*, 答案 |
| DUE (Borchmann等, 2021) | 143,854 | 指令,答案 | ||
| GUI感知 | 感知 | MultiUI (Liu等, 2024a) | 150,000 | 指令,答案 |
| Web截图转代码 | 感知 | Web2Code (Yun等, 2024) | 150,000 | 指令,答案 |
| 多模态数学 | 推理 | Mavis (Zhang等, 2024b) | 150,000 | 指令,思维,答案 |
| 多回合视觉对话 | 互动 | SVIT (Zhao等, 2023) | 150,000 | 指令,思维,答案 |
| 非GUI代理轨迹 | 互动 | AllWorld (Guo等, 2024) | 51,780 | 指令,思维,答案 |
| 语言模态 | ||||
| MathInstruct | 推理 | MathInstruct (Yue等, 2023) | 150,000 | 指令,思维,答案 |
| 奥林匹克数学 | 推理 | NuminaMath (Li等, 2024) | 150,000 | 指令,思维,答案 |
| CodeJO | 推理 | CodeJ/O (Li等, 2025) | 150,000 | 指令,思维,答案 |
| Web知识库 | 知识 | Synatra (Ou等, 2024) | 99,924 | 指令,思维,答案 |
| AgentTrek (Xu等, 2024a) | 50,076 | 指令,思维,答案 |
表1:中程训练中使用的领域及其对应数据集的统计信息,(*) 表示数据集中的一些指令不需要“思维”(例如,“简明回答用一个词或短语。”)。
:
{
“Element Description”: “Click the Issues tab in the main navigation menu”,
“Action”: “click”,
}
: Click [coordinate_x 0.12] [coordinate_y 0.07]
我们使用UGround-V1-7B (Gou等, 2025) 进行接地,并使用我们训练的策略模型生成思维和高层次动作。这种分离不仅可以通过中程训练更好地转移规划能力(详见 $3),还可以灵活地包含新动作。移动端和网页任务的动作空间详细信息请参见表6、7。
观察空间和记忆。在我们的框架中,观察空间是视觉丰富的,包含当前屏幕的截图和简单的元信息(即,网页任务的当前URL)。为了增强代理的记忆,我们还向模型提供了历史动作的记录,使用规划生成的高层次动作的连接输出,例如“第一步:点击‘标题为wikipedia的搜索结果’;第二步:在页面顶部的搜索栏中输入‘GUI Agent’”。
3 通过中程训练突破数据壁垒
尽管视觉语言模型取得了进展,但GUI代理训练因高质量轨迹数据有限而面临挑战。我们引入了一个中程训练阶段,位于通用预训练和特定任务后训练之间。这种方法利用相邻领域(如图像感知、图表理解、多模态推理和编程)的丰富数据,在进行GUI特定适应之前发展基础能力。我们的两步策略包括在可扩展的数据源上进行中程训练 ($3.1),然后在小的GUI轨迹数据集上进行微调 ($3.2)。我们在$3.3中介绍的优化训练程序确保了一致的泛化到GUI代理技能。我们简要介绍这些数据集和训练程序,更多细节请参阅附录B、C。
3.1 中程训练数据
我们为每个领域收集了15万多个不同的训练样本,以研究跨领域泛化。对于非GUI代理领域,我们包含了51k样本,由于
| 领域 | 数据集 | 样本 | 类型 |
|---|---|---|---|
| Web | OS-Genesis (Web) (Sun等, 2024b) | 3,789 | 指令,思维,动作 |
| MM-Mind2Web (Zheng等, 2024a) | 21,542 | 指令,思维,动作 | |
| VisualWebArena (Koh等, 2024a) | 3,264 | 指令,思维,动作 | |
| Mobile | OS-Genesis (Mobile) (Sun等, 2024b) | 4,941 | 指令,思维,动作 |
| Aguvis (Xu等, 2024b) | 22,526 | 指令,思维,动作 |
表2:用于后训练的web/mobile领域及其对应的GUI轨迹数据集的统计数据。
代理轨迹稀缺。
中程训练领域列在表1中。对于视觉语言任务,我们包括:图表/文档问答(Guo等,2024;Tito等,2023)和多模态数学(Zhang等,2024b)用于精细理解和视觉推理;非GUI感知任务(Ye等,2023;Borchmann等,2021)包括文档OCR用于基本视觉理解;Web Screenshot2Code(Yun等,2024)用于结构化网页截图解释;以及来自视觉对话(Zhao等,2023)和非GUI代理轨迹(Guo等,2024)的多轮数据以增强VLM交互能力。
补充这些内容,我们包括纯文本数据,这些数据包含更多的推理密集型和知识丰富的任务,包括从中等到挑战性的数学推理(MathInstruct(Yue等,2023))、奥林匹克数学(LI等,2024)数学推理、通过代码生成发展的程序推理(Li等,2025)和Web知识库(Ou等,2024;Xu等,2024a)注入领域知识。
3.2 后训练GUI轨迹数据
对于后训练,我们使用了来自最新系统的高质量GUI轨迹数据。我们纳入了OS-Genesis(Sun等,2024b)、Aguvis(Xu等,2024b)和MM-Mind2Web(Zheng等,2024a)的web和mobile数据,加上VisualWebArena(Koh等,2024a)的手动注释步骤3.2K。我们的最终数据集包含28K web样本和27K mobile样本,详情见表2。
3.3 训练方法
我们采用两阶段训练方法,包括中程训练和在GUI轨迹数据上的微调。两个阶段都在单一优化器和学习率计划下进行整合。在中程训练阶段,我们将后训练的GUI轨迹数据混入中程训练领域数据(例如ChartQA)以减轻潜在的遗忘问题,我们将在$4.4中进行实证分析。当存在显著的领域差距时,这种混合尤为重要,特别是当中程训练数据主要是基于文本的时候(见图4比较)。附加的训练超参数和细节见附录D。
4 实验
4.1 实验设置
为了探讨非GUI轨迹数据如何增强VLMs的基础代理能力,我们研究了7个多模态领域和4个语言领域(表1)。对于后训练数据,我们收集了56K高质量数据(表2)。按照最新成果(Xu等,2024b;Sun等,2024b;Gou等,2025),我们采用Qwen2-VL-7BInstruct(Wang等,2024a)作为我们的骨干。我们首先在中程训练数据集上训练模型,然后在GUI轨迹上进行微调。为了研究这些独立领域是否可以组合以实现更优的性能,我们从高性能领域中随机抽取总共300K个样例(150K来自MathInstruct,20K来自
Codel
/
O
\operatorname{Codel} / \mathrm{O}
Codel/O,50K来自奥林匹克数学,80K来自多模态数学)创建了一个合并的中程训练数据集,称为GUIMid。在中程训练阶段,我们将GUI轨迹样本混入我们的中程训练数据集中以使训练稳定。

图2:一个案例展示了无中程训练和有中程训练模型在相同任务下的性能对比。中间文本显示模型的思考过程和采取的动作,而左右的截图分别代表动作前后的屏幕状态。经过中程训练的模型(底部)能够反思错误并从错误状态下生成正确动作,而未经中程训练的模型(顶部)则无法从这些状态下恢复。
4.2 评估环境
我们使用AndroidWorld(Rawles等,2024)和WebArena(Zhou等,2023)作为我们的测试平台,因其动态性质使它们成为研究中程训练阶段不同领域影响的理想环境。对于WebArena,我们使用AgentBoard(Ma等,2024)处理的版本。我们选择交互式基准而不是静态基准(Deng等,2023;Li等,2024)基于两个考虑:(1) 静态环境固有地包含标注偏差,其中完成任务存在多种有效路径,但由于标注者的偏好,每一步只有一条路径被标记为正确(例如,通过搜索功能或类别导航查找播放列表);(2) 我们的中程训练方法主要增强基础能力,如推理和感知,而不是领域内的知识——例如,通过探索和反思提高模型在新网站上完成任务的能力。相比之下,逐步步最优动作标注严重依赖于模型对特定网站或应用程序的先验知识。我们在附录E中提供了更多评估细节。
4.3 不同领域结果
我们在Webarena和AndroidWorld上报告了不同领域的中程训练表现(表3)。我们的分析揭示了几项重要发现:
数学数据总体上改进最多:无论是仅基于语言还是视觉语言的数学推理任务,都在基准测试中表现出显著的性能改进。在语言模态中,使用MathInstruct进行中程训练的模型在WebArena上取得了最高的成功率(10.9%),在AndroidWorld上表现强劲(14.4%)。同样,在视觉语言领域,多模态数学在WebArena上表现出色,获得了8.5%的提升,在AndroidWorld上获得了15.3%的提升。这种一致的模式表明,无论输入模态如何,数学推理能力都能提高可有效转移到GUI代理任务的通用推理技能。图2展示了一个使用MathInstruct(Yue等,2023)进行中程训练的模型案例研究。任务要求代理在Reddit网站上发布问题“在纽约市拥有汽车是否必要”。两个代理最初都导航到了错误的页面。然而,经过MathInstruct训练的代理
| 领域 | 观察 | WebArena | AndroidWorld | |
|---|---|---|---|---|
| PR | SR | SR | ||
| 仅GUI后训练 | 图像 | 26.3 | 6.2 | 9.0 |
| 公共基线 | ||||
| GPT-4o-2024-11-20 | 图像 | 36.9 | 15.6 | 11.7 |
| OS-Genesis-7B | 图像 + 可访问性树 | - | - | 17.4 |
| AGUVIS-72B | 图像 | - | - | 26.1 |
| Claude3-Haiku | 可访问性树 | 26.8 | 12.7 | - |
| Llama3-70b | 可访问性树 | 35.6 | 12.6 | - |
| Gemini1.5-Flash | 可访问性树 | 32.4 | 11.1 | - |
| 视觉与语言模态 | ||||
| 图表/ 文档问答 | 图像 | 24.6 | 6.2 | 15.3 |
| 非GUI感知 | 图像 | 28.7 | 7.6 | 14.0 |
| GUI感知 | 图像 | 27.4 | 7.1 | 14.0 |
| Web截图转代码 | 图像 | 28.0 | 6.6 | 9.9 |
| 非GUI代理 | 图像 | 30.8 | 8.5 | 13.5 |
| 多模态数学 ✓ \checkmark ✓ | 图像 | 30.4 | 8.5 | 15.3 |
| 多轮视觉对话 | 图像 | 30.0 | 9.0 | 12.6 |
| 语言模态 | ||||
| MathInstruct ✓ \checkmark ✓ | 图像 | 31.9 | 10.9 | 14.4 |
| 奥林匹克数学 ✓ \checkmark ✓ | 图像 | 31.5 | 8.5 | 13.1 |
| CodeI/O ✓ \checkmark ✓ | 图像 | 29.2 | 9.0 | 14.9 |
| Web知识库 | 图像 | 31.3 | 9.5 | 9.0 |
| 领域组合(从 ✓ \checkmark ✓ 领域采样数据) | ||||
| GUIMid | 图像 | 24.2 | 9.5 | 21.2 |
表3:使用两阶段训练策略的Qwen2-VL-7B-Instruct在各种领域的进度率(PR)和成功率(SR)。使用颜色编码单元格(绿色/红色)来表示相对于仅后训练基线的改进或下降,更深的颜色表示更大的分数变化。
通过思考“然而,屏幕截图并未显示明确的提交按钮,所以我将寻找用于发布评论的按钮”,随后定位到了正确的“提交”按钮。相比之下,没有经过中程训练的基线模型卡在了错误的页面上,徒劳地滚动上下。
强大的跨模态和跨领域迁移:仅基于语言的任务对多模态GUI任务表现出显著效果。奥林匹克数学在WebArena上实现了31.5%的进展和8.5%的成功率,优于大多数视觉语言任务。类似地,CodeI/O在AndroidWorld上达到了14.9%的成功率。Web知识库主要在Web领域表现出有效性,可能是因为它专注于特定于Web的信息而非移动设备。这些结果表明,在仅基于文本的数学、代码和知识数据上进行中程训练可以增强GUI代理的基础能力,即使对于多模态任务也是如此——为应对有限的GUI领域训练数据挑战提供了宝贵见解。
非GUI代理数据尽管规模相对较小(50K样本),却表现出强劲的表现(WebArena上30.8%的进展,8.5%的成功;AndroidWorld上13.5%的成功)。这表明代理交互模式可以在一定程度上转移。多轮视觉对话在基准测试中带来了平衡的改进(WebArena上9.0%,AndroidWorld上12.6%)。图表/文档问答在AndroidWorld上表现良好(15.3%),但在网络环境中表现较差,这表明数字平台有不同的需求。然而,Web截图转代码和GUI感知数据帮助不大,这可能是因为Qwen2-VL-7B-Instruct已经在GUI感知数据上进行了训练。
领域组合结果 我们的动机是利用更大数量的非GUI数据集来增强VLMs的基础能力,从而能够从有限的GUI轨迹数据中更有效地学习。为了验证这一点,我们将顶级表现领域结合起来构建一个组合的中程训练数据集:GUIMid,它由随机采样的数据组成(150K样本来自MathInstruct,20K来自CodeI/O,50K来自奥林匹克数学,80K来自多模态数学)。我们探索GUIMid的扩展规律。具体来说,对于300K样本的中程训练数据集,我们保持非GUI与GUI数据的比例与我们在150K样本实验中的比例相同,以确保训练稳定性。而不是
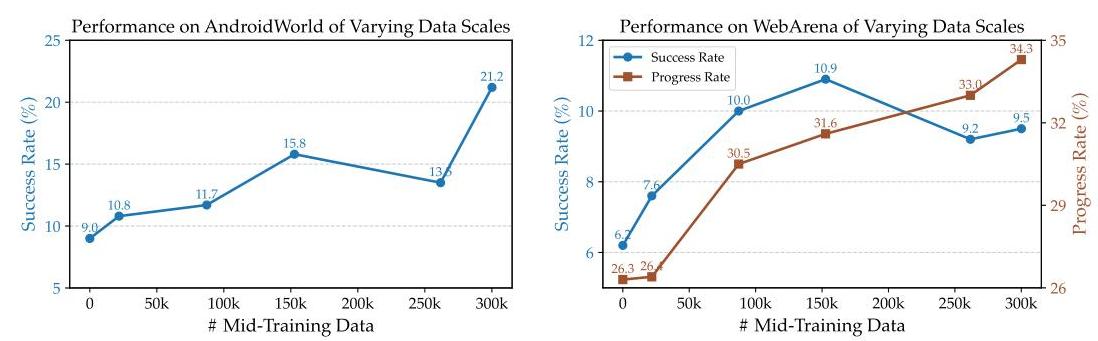
图3:在不同规模上训练GUIMid的模型性能。
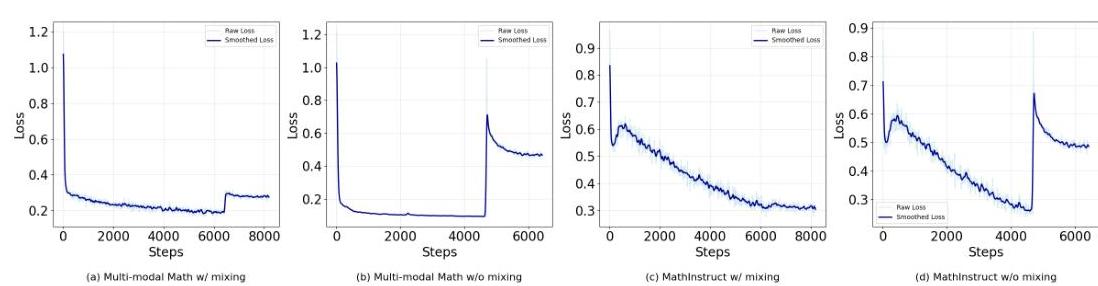
图4:两种训练策略的损失曲线比较:(a)和©显示了在中程训练期间混合GUI轨迹数据的情况,而(b)和(d)则没有混合。
引入新的GUI数据,我们复制现有的GUI轨迹数据。在图3中,x轴表示有效的中程训练数据量,计算为总训练数据量乘以分配给中程训练样本的固定比例。模型在AndroidWorld和WebArena上随着中程训练数据量的增加表现出扩展规律。虽然在300K样本标记处观察到WebArena成功率略有下降,但进度率指标提供了对性能改进更为细致的评估。该指标捕捉了细粒度的能力发展,显示了持续的增长:从21.8K样本时的大约26.4%到152K样本时的31.6%,再到300K样本时的34.3%。这种稳定的向上趋势表明GUIMid扩展规律的有效性。
4.4 消融研究
在中程训练阶段添加GUI轨迹数据的效果。我们比较了混合/不混合GUI轨迹数据进入中程训练阶段时的损失曲线(图4)和性能(表4)。由于中程训练数据和GUI轨迹数据之间的领域差距,领域切换可能会导致损失曲线剧烈波动,导致不稳定(如图4中的(b)和(d)所示),甚至可能导致梯度溢出为NaN值。相比之下,图(a)和©显示在合并数据后训练动力学显著平滑。表4显示,在混合GUI轨迹数据后,MathInstruct和多模态数学都表现出显著的性能改进。在WebArena中,MathInstruct的进度率从24.0增加到33.6。同样,在AndroidWorld中,多模态数学的成功率从14.9增加到15.3。
关于中程训练数据难度的性能 在NuminaMath数据集中采样三个子集,基于它们的难度级别。
| 领域 | 难度 | WebArena | AndroidWorld | |
|---|---|---|---|---|
| PR | SR | SR | ||
| Orca-Math | 简单 | 31.9 | 10.0 | 9.9 |
| 随机采样数据 | 中等 | 30.6 | 9.5 | 10.8 |
| 奥林匹克数学 | 困难 | 31.5 | 8.5 | 13.1 |
表5:中程训练数据数学难度的影响。我们根据难度级别从NuminaMath数据集中采样三个子集。
表5显示,移动环境中的性能通常随着数据难度的增加而提高,而WebArena则没有明显的相关性。这种差异可能源于AndroidWorld使用了具有更多多样化交互模式的真实应用程序。
5 相关工作
GUI代理。近年来GUI代理的发展导致了各种基准的开发。针对web和移动环境的非交互式基准(Mind2web(Deng等,2023),WebLINX(Lu等,2024b),WebVoyager(He等,2024))和移动环境(AITW(Rawles等,2023),AITZ(Zhang等,2024a),AndroidControl(Li等,2024))存在固有的局限性,因为在存在多个有效任务路径时,标注者偏见会导致问题。为了解决这些局限性,出现了跨移动/桌面(OSWorld(Xie等,2024),AndroidWorld(Rawles等,2024))和web环境(WebArena(Zhou等,2023),VisualWebArena(Koh等,2024a),WorkArena(Drouin等,2024),WebCanvas(Pan等,2024))的交互式基准。我们对增强非GUI能力(例如推理)的研究需要在评估框架中进行评估,而不受领域内感知或知识限制的瓶颈。当GUI感知是主要瓶颈时,VisualWebArena的轨迹级成功报告可能会掩盖推理改进。尽管WebCanvas试图解决这个问题,但由于实时网站的更新,其大多数任务都是无效的。因此,我们选择AgentBoard(Ma等,2024)的WebArena和AndroidWorld的子目标标注版本作为我们的评估框架。这种方法使我们能够在其他领域可能存在局限的情况下隔离和测量特定能力的变化。
中程训练。中程训练是指预训练和后训练之间的阶段,旨在增强基础能力(Abdin等,2024),而后训练则优化模型以适应特定下游任务。最近的作品如Phi 3.5(Abdin等,2024),Yi-Lightning(Wake等,2024),OLMo 2(OLMo等,2024)和CodeI/O(Li等,2025)展示了战略性中程训练干预的有效性,使用中程训练来增强诸如上下文长度、多语言知识和代码理解等基础能力。对于GUI代理,高质量轨迹稀缺,中程训练变得特别有价值。然而,目前的研究缺乏系统探索为GUI代理量身定制的领域外中程训练技术的关键空白,我们的工作对此进行了填补。
6 结论
本文提出使用中程训练来增强GUI代理的基础能力,从而能够更有效地从有限的轨迹数据中学习。尽管GUI特定
数据仍然稀缺,但有更多的非GUI数据,例如数学推理和编码。我们探索了11种不同的非GUI任务,首次展示了数学推理数据对GUI任务性能的重大影响,以及仅基于文本的数学推理在改善多模态GUI代理能力方面的惊人效果。我们的研究结果还揭示了非GUI任务(如文本网络知识和实体代理轨迹)如何显著提升GUI代理性能。这些结果为研究社区构建更有效的GUI训练管道提供了宝贵的见解。我们将开源所有数据、模型和训练配方,以促进GUI代理领域的未来研究。
参考文献
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, 等人. Phi-3 技术报告:一款在手机上本地运行的高度能力建模语言模型。arXiv 预印本 arXiv:2404.14219, 2024.
Łukasz Borchmann, Michał Pietruszka, Tomasz Stanislawek, Dawid Jurkiewicz, Michał Turski, Karolina Szyndler, 和 Filip Graliński. Due: 端到端文档理解基准。第三十五届神经信息处理系统会议数据集和基准轨道(第2轮),2021.
Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, 等人. Guicourse: 从通用视觉语言模型到多功能GUI代理。arXiv 预印本 arXiv:2406.11317, 2024.
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, 和 John Schulman. 训练验证器解决数学文字问题。arXiv 预印本 arXiv:2110.14168, 2021.
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, 和 Yu Su. Mind2web: 朝向网络通用代理。神经信息处理系统进展,36:28091-28114, 2023.
Alexandre Drouin, Maxime Gasse, Massimo Caccia, IssamH Laradji, Manuel Del Verme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, et al. Workarena: 网络代理在解决常见知识工作任务方面的能力如何?arXiv预印本arXiv:2403.07718, 2024.
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, 和 Yu Su. 像人类一样导航数字世界:GUI代理的通用视觉定位。第十三届国际学习表示会议,2025。URL https://openreview.net/forum?id=kxnoqaisCT.
Jarvis Guo, Tuney Zheng, Yuelin Bai, Bo Li, Yubo Wang, King Zhu, Yizhi Li, Graham Neubig, Wenhu Chen, 和 Xiang Yue. Mammoth-VL: 通过大规模指令调整激发多模态推理。2024. URL https://arxiv.org/abs/2412.05237.
Izzeddin Gur, Hiroki Furuta, Austin Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, 和 Aleksandra Faust. 一个具有规划、长上下文理解和程序综合能力的真实世界WebAgent。arXiv预印本arXiv:2307.12856, 2023.
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, 和 Dong Yu. Webvoyager: 使用大型多模态模型构建端到端Web代理。计算语言学协会第六十二届年会论文集(第一卷:长篇论文),pp. 6864-6890, 2024.
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, 等人. GPT-4O系统卡片。arXiv预印本arXiv:2410.21276, 2024.
Kushal Kafle, Brian Price, Scott Cohen, 和 Christopher Kanan. DVQA: 通过问答理解数据可视化。IEEE计算机视觉与模式识别会议论文集,pp. 5648-5656, 2018.
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, 和 Daniel Fried. VisualWebArena: 在真实的视觉网络任务中评估多模态代理。计算语言学协会第六十二届年会论文集(第一卷:长篇论文),pp. 881-905, 2024a.
Jing Yu Koh, Stephen McAleer, Daniel Fried, 和 Ruslan Salakhutdinov. 语言模型代理的树搜索。arXiv预印本arXiv:2407.01476, 2024b.
Jia LI, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, 和 Stanislas Polu. NuminaMath. [https://huggingface.co/Al-MO/NuminaMath-CoT] (https://github.com/project-numina/aimo-progress-prize/blob/main/report/numina_dataset.pdf), 2024.
Junlong Li, Daya Guo, Dejian Yang, Runxin Xu, Yu Wu, 和 Junxian He. CodeI/O: 通过代码输入输出预测凝练推理模式。arXiv预印本arXiv:2502.07316, 2025.
Wei Li, William E Bishop, Alice Li, Christopher Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, 和 Oriana Riva. 数据规模对UI控制代理的影响。神经信息处理系统进展,37:92130-92154, 2024.
Junpeng Liu, Tianyue Ou, Yifan Song, Yuxiao Qu, Wai Lam, Chenyan Xiong, Wenhu Chen, Graham Neubig, 和 Xiang Yue. 利用网页UI进行文本丰富的视觉理解。arXiv预印本arXiv:2410.13824, 2024a.
Wei Liu, Junlong Li, Xiwen Zhang, Fan Zhou, Yu Cheng, 和 Junxian He. 深入研究自进化训练在多模态推理中的应用。arXiv预印本arXiv:2412.17451, 2024b.
Quanfeng Lu, Wenqi Shao, Zitao Liu, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, Yu Qiao, 和 Ping Luo. GUI Odyssey: 跨应用程序GUI导航的全面数据集。arXiv预印本arXiv:2406.08451, 2024a.
Xing Han Lu, Zdeněk Kasner, 和 Siva Reddy. WebLinx: 多轮对话中的真实网站导航。国际机器学习会议论文集,pp. 33007-33056. PMLR, 2024b.
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, 和 Junxian He. Agentboard: 多轮LLM代理的分析评估板。神经信息处理系统进展,37:74325-74362, 2024.
Nitesh Methani, Pritha Ganguly, Mitesh M Khapra, 和 Pratyush Kumar. PlotQA: 推理科学图表。IEEE/CVF冬季计算机视觉应用会议论文集,pp. 1527-1536, 2020.
Arindam Mitra, Hamed Khanpour, Corby Rosset, 和 Ahmed Awadallah. Orca-Math: 解锁SLM在小学数学中的潜力。arXiv预印本arXiv:2402.14830, 2024.
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, 等人. 2 OLMO 2 Furious. arXiv预印本arXiv:2501.00656, 2024.
OpenAI. 计算机使用代理。https://openai.com/index/computer-using-agent/, January 2025.
Tianyue Ou, Frank F. Xu, Aman Madaan, Jiarui Liu, Robert Lo, Abishek Sridhar, Sudipta Sengupta, Dan Roth, Graham Neubig, 和 Shuyan Zhou. SynATRA: 将间接知识转化为数字代理的大规模直接演示。第三十八届年度神经信息处理系统会议,2024. URL https://openreview.net/forum?id=KjNEzWRIqn.
Yichen Pan, Dehan Kong, Sida Zhou, Cheng Cui, Yifei Leng, Bing Jiang, Hangyu Liu, Yanyi Shang, Shuyan Zhou, Tongshuang Wu, 等人. WebCanvas: 在线环境中基准测试Web代理。arXiv预印本arXiv:2406.12373, 2024.
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, 和 Timothy Lillicrap. AndroidIntheWild: 大规模Android设备控制数据集。神经信息处理系统进展,36:59708-59728, 2023.
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, 等人. AndroidWorld: 自主代理的动态基准环境。arXiv预印本arXiv:2405.14573, 2024.
Wenhao Shi, Zhiqiang Hu, Yi Bin, Junhua Liu, Yang Yang, See Kiong Ng, Lidong Bing, 和 Roy Lee. Math-LLaVA: 引导多模态大型语言模型的数学推理。计算语言学协会发现:EMNLP 2024论文集,pp. 4663-4680, 2024.
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, 和 Matthew Hausknecht. ALFWorld: 对齐文本和实体环境以实现交互式学习。国际学习表示会议论文集(ICLR),2021. URL https://arxiv.org/abs/2010.03768.
Yueqi Song, Frank F Xu, Shuyan Zhou, 和 Graham Neubig. 超越浏览:基于API的Web代理。2024.
Qiushi Sun, Zhirui Chen, Fangzhi Xu, Kanzhi Cheng, Chang Ma, Zhangyue Yin, Jianing Wang, Chengcheng Han, Renyu Zhu, Shuai Yuan, 等人. 神经代码智能调查:范式、进展及超越。arXiv预印本arXiv:2403.14734, 2024a.
Qiushi Sun, Kanzhi Cheng, Zichen Ding, Chuanyang Jin, Yian Wang, Fangzhi Xu, Zhenyu Wu, Chengyou Jia, Liheng Chen, Zhoumianze Liu, 等人. OS-Genesis: 通过反向任务合成自动化GUI代理轨迹构建。arXiv预印本arXiv:2412.19723, 2024b.
Rubèn Tito, Dimosthenis Karatzas, 和 Ernest Valveny. 层次多模态转换器用于多页DocVQA。模式识别,144:109834, 2023.
Alan Wake, Bei Chen, CX Lv, Chao Li, Chengen Huang, Chenglin Cai, Chujie Zheng, Daniel Cooper, Fan Zhou, Feng Hu, 等人. Yi-Lightning技术报告。arXiv预印本arXiv:2412.01253, 2024.
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, 等人. Qwen2-VL: 在任意分辨率下增强视觉语言模型的世界感知。arXiv预印本arXiv:2409.12191, 2024a.
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, 和 Heng Ji. 可执行代码动作引发更好的LLM代理。第四十一届国际机器学习会议,2024b.
Zhiyong Wu, Chengcheng Han, Zichen Ding, Zhenmin Weng, Zhoumianze Liu, Shunyu Yao, Tao Yu, 和 Lingpeng Kong. OS-Copilot: 朝向具有自我改进能力的通用计算机代理。arXiv预印本arXiv:2402.07456, 2024.
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Jing Hua Toh, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, 等人. OSWorld: 在真实计算机环境中为开放性任务基准测试多模态代理。神经信息处理系统进展,37:52040-52094, 2024.
Yiheng Xu, Dunjie Lu, Zhennan Shen, Junli Wang, Zekun Wang, Yuchen Mao, Caiming Xiong, 和 Tao Yu. AgentTrek: 通过引导重播合成代理轨迹。arXiv预印本arXiv:2412.09605, 2024a.
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, 和 Caiming Xiong. Aguvis: 统一纯视觉代理用于自主GUI交互,2024b.
Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, 等人. Magma: 多模态AI代理的基础模型。arXiv预印本arXiv:2502.13130, 2025.
Jiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Guohai Xu, Chenliang Li, Junfeng Tian, Qi Qian, Ji Zhang, 等人. Ureader: 使用多模态大语言模型进行无需OCR的通用视觉情境语言理解。arXiv预印本arXiv:2310.05126, 2023.
Xiao Yu, Baolin Peng, Vineeth Vajipey, Hao Cheng, Michel Galley, Jianfeng Gao, 和 Zhou Yu. Exact: 教授AI代理通过反思-MCTS和探索性学习进行探索。arXiv预印本arXiv:2410.02052, 2024.
Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, 和 Wenhu Chen. Mammoth: 通过混合指令调优构建数学通才模型。arXiv预印本arXiv:2309.05653, 2023.
Sukmin Yun, Haokun Lin, Rusiru Thushara, Mohammad Qazim Bhat, Yongxin Wang, Zutao Jiang, Mingkai Deng, Jinhong Wang, Tianhua Tao, Junbo Li, 等人. Web2Code: 一个大规模网页到代码数据集和多模态LLM评估框架。arXiv预印本arXiv:2406.20098, 2024.
Jiwen Zhang, Jihao Wu, Teng Yihua, Minghui Liao, Nuo Xu, Xiao Xiao, Zhongyu Wei, 和 Duyu Tang. Android in the Zoo: GUI代理的行动链思考。计算语言学协会发现:EMNLP 2024论文集,pp. 12016-12031, 2024a.
Renrui Zhang, Xinyu Wei, Dongzhi Jiang, Yichi Zhang, Ziyu Guo, Chengzhuo Tong, Jiaming Liu, Aojun Zhou, Bin Wei, Shanghang Zhang, 等人. Mavis: 数学视觉指令调优。arXiv电子印刷品,pp. arXiv-2407, 2024b.
Bo Zhao, Boya Wu, Muyang He, 和 Tiejun Huang. SVIT: 扩展视觉指令调优。arXiv预印本arXiv:2307.04087, 2023.
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, 和 Yu Su. GPT-4V (ision) 是一个通用网络代理,如果接地的话。arXiv预印本arXiv:2401.01614, 2024a.
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, 和 Yu Su. GPT-4V(ision) 是一个通用网络代理,如果接地的话。第四十一届国际机器学习会议。URL https://openreview.net/forum?id=piecKJ2D1B.
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, 等人. WebArena: 构建自主代理的现实网络环境。arXiv预印本arXiv:2307.13854, 2023.
| 动作 | 描述 |
|---|---|
| click [ [ x ] [ y ] ] [[x][y]] [[x][y]] | 在坐标 ( x , y ) (x, y) (x,y)处点击。 |
| type [ [ x ] [ y ] ] [[x][y]] [[x][y]] [value] | 按坐标在字段中输入内容。 |
| scroll [ [ x ] [ y ] ] [[x][y]] [[x][y]] [value] | 滚动页面或特定元素。 |
| go_back | 导航到上一个屏幕或页面。 |
| go_home | 导航到主屏幕。 |
| long_press[[x] [y]] | 长按某个坐标。 |
| enter | 按下Enter键。 |
| open_app [app_name] | 通过[app_name]打开应用。 |
| wait [value] | 等待[value]秒直到屏幕更新。 |
| stop [answer] | 以目标状态或答案停止任务。 |
表6:移动任务的动作空间。
| 动作 | 描述 |
|---|---|
| click [ [ x ] [ y ] ] [[x][y]] [[x][y]] | 在坐标 ( x , y ) (x, y) (x,y)处点击。 |
| type [ [ x ] [ y ] ] [[x][y]] [[x][y]] [value] | 按坐标在字段中输入内容。 |
| clear [ [ x ] [ y ] ] [[x][y]] [[x][y]] | 清除元素的内容。 |
| hover [ [ x ] [ y ] ] [[x][y]] [[x][y]] | 按坐标悬停在一个元素上。 |
| press [keys] | 按下一个键组合(例如Ctrl+v)。 |
| scroll [value] | 滚动页面。 |
| new_tab | 打开一个新标签页。 |
| page_focus [tab_index] | 切换到特定标签页。 |
| close_tab | 关闭当前标签页。 |
| goto [url] | 导航到一个URL。 |
| go_back | 返回上一页。 |
| go_forward | 前进到下一页。 |
| stop [answer] | 当任务被认为完成时发出此动作。 |
表7:网络任务的动作空间。
A GUI代理的详细信息
动作空间。在数据处理阶段,我们分别标准化了移动和网络领域的动作空间,以实现适合联合训练的统一表示。在评估阶段,我们进一步通过将它们映射到相应的标准化动作空间来跨不同基准对齐动作。训练和评估阶段涉及的动作均属于表6中移动领域和表7中网络领域的详细类别。
观察空间。为了模拟真实世界中人类与GUI环境的交互,并更好地研究中间训练数据是否增强了GUI代理的推理能力,本研究中的观察空间仅包含视觉信息。具体来说,在任务执行期间,GUI代理仅接收来自屏幕的视觉反馈和历史动作信息,而不利用环境中的任何额外文本信息(如DOM或可访问性树)。此类文本信息可能会引入额外的信息增益,从而混淆中间训练数据的效果。
B 中程训练数据的详细信息
视觉语言数据通常包括成对的视觉和文本信息,例如图像字幕、带注释的截图和视觉基础指令。考虑到GUI代理的固有多模态性质,利用视觉语言数据可能有助于更好地对齐视觉和文本模态,潜在地提高代理对图形界面的理解和互动能力。我们对视觉语言模态的主要关注点包括:
(1) 图表/文档问答:此类数据增强了模型在结构化图表和文档的视觉表示上执行推理密集型任务的能力。我们的训练数据通过从InfographicVQA和Ureader QA在MAmmoTHVL(Guo等,2024)中随机抽取约56K样本、从MPDocVQA(Tito等,2023)中抽取500样本以及从MathV360k(Liu等,2024b)的热身数据中抽取93.5K样本来构建。总共,这一过程生成了一个包含150K样本的中程训练数据集。
(2) 非GUI感知:此类数据增强了模型对非GUI图像(如海报、表格和文档)的感知能力。鉴于在线数据库中非GUI感知数据集的丰富性(例如文档(Kafle等,2018)、海报(Ye等,2023)和图表(Methani等,2020)),我们研究了利用此类数据是否可以提高GUI相关任务的性能。具体来说,我们通过整合来自Ureader OCR(Ye等,2023)的6.1K样本和从DUE(Borchmann等,2021)中随机选择的143.9K样本,构建了总计150K样本的中程训练阶段。
(3) GUI感知:此类数据旨在增强模型对GUI图像的感知能力。为此,训练数据集通过从MultiUI(Liu等,2024a)中的动作预测、网页问答和图像问答子集中每个随机抽取50K实例来构建,总计为中程训练阶段提供了150K样本。
(4) 多模态数学:数学数据(Cobbe等,2021;Shi等,2024)被广泛用于增强LLMs和VLLMs的推理能力。我们探讨了结合多模态数学数据是否可以进一步增强GUI代理的规划能力。具体来说,我们通过从Mavis数据集(Zhang等,2024b)中随机抽取150K个多模态数学问题来构建训练数据集,该数据集包含高质量数学问题及其详尽的推理过程。
(5) 多轮视觉对话:代理轨迹通常由多个步骤组成,要求模型理解和记住先前的步骤以指导当前决策。多轮视觉对话数据表现出类似特征,因为生成给定回合的响应通常依赖于先前回合的上下文。我们探讨了多回合多模态问答数据是否可以增强GUI代理任务的性能。具体来说,我们通过从SVIT数据集(Zhao等,2023)中随机抽取150K个多回合对话来构建训练数据集,该数据集包括涉及复杂、基于图像推理的多回合问答互动。
(6) Web Screenshot2Code:HTML代码和相应的网页截图容易获取,提供了关于网页元素结构和交互性的丰富信息(例如,图标是否可点击或可悬停)。我们探讨了利用这些易得的数据是否可以增强GUI代理在下游任务上的性能。具体来说,我们通过从Web2Code数据集(Yun等,2024)中随机抽取150K个网页截图-HTML代码对来构建训练数据集。
(7) 非GUI代理轨迹:随着具身AI的快速发展,越来越多的非GUI代理数据在Web以外的领域变得可用,例如家庭任务(Shridhar等,2021)。我们探讨了这些领域的数据是否可以受益于GUI代理任务。具体来说,由于此类数据的可用性有限,我们利用了MAmmoTH-VL(Guo等,2024)子集AlfWorld中的所有51K样本作为实验的中程训练数据。
文本数据相较于视觉语言数据通常更易于获取且更为丰富,广泛可通过互联网等来源获取。我们探讨了纯文本数据是否可以增强GUI代理的能力。对于文本模态,我们的主要关注点包括以下内容:
(1) MathInstruct:基于文本的数学数据集(Cobbe等,2021)通常用于增强模型的推理能力。我们从MathInstruct(Yue等,2023)的CoT类别中随机抽取150K个示例作为中程训练数据。
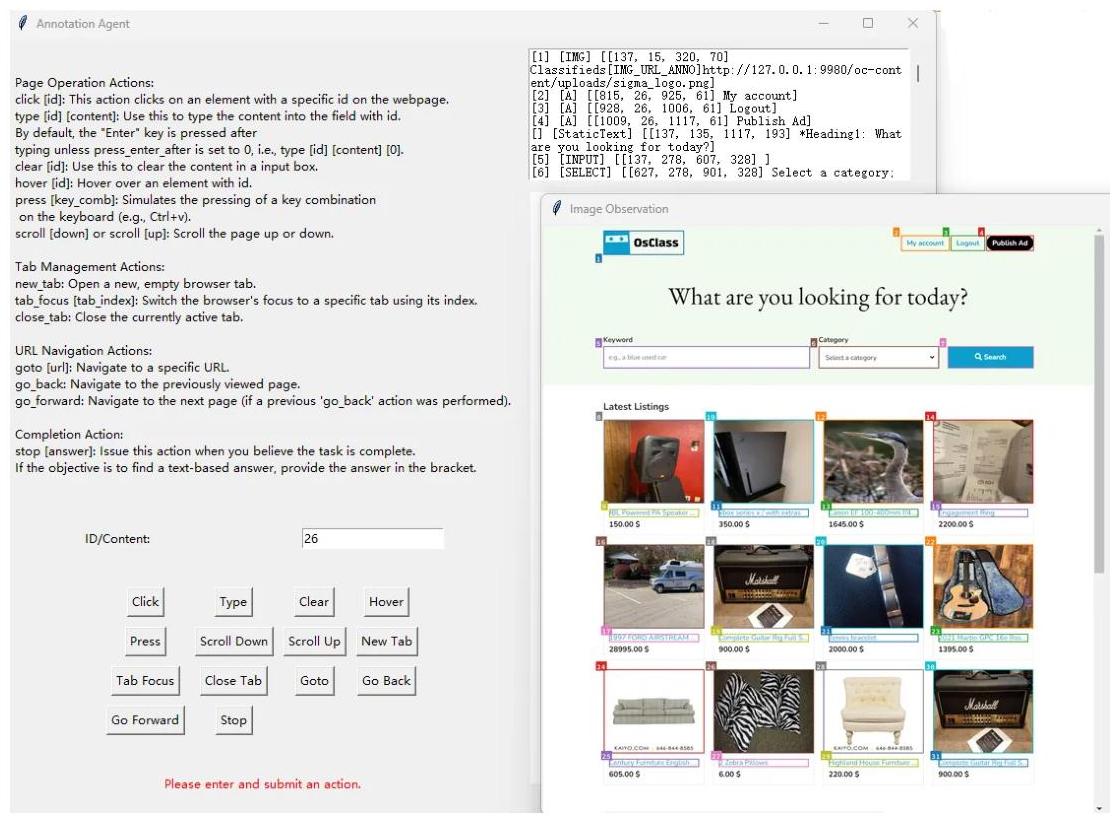
图5:VisualWebArena的标注用户界面。
(2) CodeI/O:CodeI/O(Li等,2025)是一种新颖的方法,将基于代码的推理模式转化为自然语言格式,以增强大型语言模型的推理能力。我们从CodeI/O数据集中随机抽取150K个示例。
(3) Web知识库:可以通过方法如(Ou等,2024;Xu等,2024a)利用教程知识合成基于文本的轨迹。然而,大规模生成多模态数据仍然具有挑战性。在这项工作中,我们探讨了基于文本的轨迹数据是否可以使基于视觉的GUI代理受益。具体来说,我们利用Synatra数据集(Ou等,2024)中的100K条轨迹,并从AgentTrek数据集(Xu等,2024a)中随机抽取50K条轨迹,这两个都是Web领域的数据集,可能潜在增强GUI代理在基于Web的任务中的性能。
(4) 奥林匹克数学:NuminaMath(LI等,2024)是一个全面的数学数据集,涵盖了广泛的题目,包括中国高中数学课程的练习题以及美国和国际数学奥林匹克竞赛的问题。我们特别选择了NuminaMath中分类为奥林匹克的最具挑战性的子集问题,并从中随机抽取150K个示例,以突出高级数学推理中固有的复杂性。
C GUI轨迹数据的详细信息
高质量的GUI轨迹数据对于使GUI代理能够推进数字化自动化至关重要。然而,由于应用场景和标注成本的限制,现有的高质量轨迹数据仍然有限。为了更好地使中程训练模型适应GUI特定任务,我们收集了以下轨迹数据:
(1) OS-Genesis:我们利用OS-Genesis(Sun等,2024b)提供的移动和网络平台轨迹数据,这些数据通过交互驱动方法自动逆向合成。为进一步提高这些轨迹的推理质量,我们使用gpt-4o-mini(Hurst等,2024)对其进行逐步推理增强。具体来说,gpt-4o-mini为每一步生成五组思维链数据并优化它们,以确保与相应动作的一致性。如果不一致持续存在,对应数据将被丢弃。最终,大约收集了4K个高质量的单步轨迹样本用于网络平台,5K个用于移动平台。
(2) MM-Mind2Web:MM-Mind2Web(Zheng等,2024a)是Mind2Web数据集(Deng等,2023)的多模态扩展,旨在开发和评估能够遵循自然语言指令在任意网站上完成复杂任务的通用Web代理。该数据集将每个HTML文档与其对应的Mind2Web原始转储中的网页截图对齐,使得结构和视觉Web信息可以联合建模。我们还使用GPT-4o-mini处理数据,生成带有思维链增强的MM-Mind2Web数据集,包含21K个标注步骤。
(3) VisualWebArena:我们从VisualWebArena(Koh等,2024a)的不同任务模板中随机抽样问题,并使用我们实现的标注工具(图5)标注3,264步数据。为确保标注正确,每个标注轨迹都会被重放并通过任务验证。
(4) Aguvis:Aguvis是一个高质量GUI代理轨迹的合成数据集,建立在并增强了现有的开源数据集,如AitW(Rawles等,2023)、GUI Odyssey(Lu等,2024a)和GUIAct(Chen等,2024)。虽然这些先前的数据集通常包括高层次目标、观测和接地动作,但Aguvis通过纳入详细的中间推理和低层次动作指令来丰富它们。借助VLM,Aguvis生成逐步步内独白,包括观测描述、代理思考和精细动作指令,使GUI代理能够进行更先进的多模态推理和规划。我们从Aguvis中随机抽取22K单步推理数据以支持后训练。
D 训练细节
遵循最新研究成果(Xu等,2024b;Sun等,2024b;Gou等,2025),我们使用Qwen2-VL-7B-Instruct(Wang等,2024a)作为我们的骨干模型。在中程训练实验中,中程训练阶段和后训练阶段在单一优化器和学习率计划下集成,我们发现在经验上这对稳定训练过程非常重要。对于图3中展示的扩展规律实验,我们根据训练的中程数据量保存GUIMid上训练模型的检查点。为了评估扩展规律实验中的中间点性能(例如,在训练了50K中程数据样本之后),我们使用相应的检查点,并使用逐渐减少学习率至零的余弦学习率计划继续训练,从检查点记录的学习率值开始。由于硬件限制,我们将每台设备的批量大小限制为1,梯度累积为4。对于扩展到300K样本的结果,我们直接报告表3中的性能。
E 评估细节
AndroidWorld。AndroidWorld通过20个真实世界应用程序中的116个任务评估Android环境中的自主代理。每个任务都结合随机参数以生成多样化场景,从而进行严格评估。成功率(SR)通过系统状态检查确定,而无需修改原始应用程序源代码。由于应用程序可用性的限制,我们的最终评估涵盖111个任务。我们基于AndroidWorld(Rawles等,
| 参数 | 值 |
|---|---|
| 上下文长度 | 8192 |
| GPU数量 | 8 |
| 学习率 | 2 × 1 0 − 5 2 \times 10^{-5} 2×10−5 |
| 训练周期 | 1.0 |
| 每设备批量大小 | 2 |
| 梯度积累 | 2 |
| 学习率调度器 | 余弦 |
| 预热比例 | 0.05 |
| 精度 | bf16 |
表8:表3中使用的训练超参数。
2024),基于AndroidWorld中的M3A代理构建GUI代理,灵感来源于SeeAct-V代理(Gou等,2025)的实现,仅依赖视觉信息,通过移除可访问性树中的SoM图像和文本元素列表,并将基于元素的动作转换为像素级动作。此外,为了确保实验的公平性和严谨性,我们在训练和评估提示中保持一致性,避免使用针对边缘案例精心设计的提示。这表明代理性能的变化主要归因于中程训练数据。
WebArena。我们使用agentboard(Ma等,2024)版本的WebArena(Zhou等,2023),其中包含从原始基准中采样的245个案例,并增强了进度标签,提供成功率和进度率——提供更多粒度的模型能力发展洞察。为确保评估的准确性和一致性,我们在本地基础设施上部署基于Docker的网站,而不是使用公共AWS设置,后者可能导致交叉评估不准确性。由于网站配置问题,排除了与地图相关的任务,留下211个任务。为最大限度保证可靠性,每次评估后我们重启环境以消除测试会话之间的潜在污染。
gpt-4o基线 在缺乏具有相当数据量的7B参数基线的情况下,我们评估了gpt-4o-2024-11-20作为纯视觉基础GUI场景中的规划模型,同时使用UGround-V1-7B(Gou等,2025)作为接地模型。为了确保公平比较,所有模型都使用相同的提示生成输出,如图10,11所示。值得注意的是,SeeAct-V(Gou等,2025)在相同的实验条件下表现出卓越性能。这种优越性能可归因于其精心设计的提示,专门针对AndroidWorld,解决了常见的边缘情况并融入了符合人类直觉的规则。
所有实验均在温度为
0.0
,
top
p
0.0, \operatorname{top} p
0.0,topp为1.0,最大上下文长度为8192的条件下进行。
F 提示
我们列出以下提示:
- 在OS-Genesis(移动)轨迹上生成思维链的提示。
-
- 在OS-Genesis(网络)轨迹上生成思维链的提示。
-
- 在VisualWebArena轨迹上生成思维链的提示。
-
- 在Mind2Web轨迹上生成思维链的提示。
-
- 在AndroidWorld上进行评估的提示。
-
- 在WebArena上进行评估的提示。
-
在OS-Genesis(移动)轨迹上生成CoT的提示
你是一个移动代理。请一步一步地思考并在Android设备上执行一系列动作以完成任务。在每个阶段,你会收到当前截图、之前的动作记录和下一步正确动作的提示。基于这些信息,决定下一个要采取的动作,不要提及提供的正确答案提示。
## 可用动作:
### UI操作:
- ‘click [element]’: 点击一个元素。
-
- ‘type [element] [value]’: 按ID在字段中输入内容。
-
- ‘scroll [element] [value]’: 滚动页面或特定元素。方向可以是’up’、‘down’、‘left’或’right’。滚动整个页面时留空元素。
-
- ‘go_back’: 返回上一页。
-
- ‘go_home’: 导航到主屏幕。
-
- ‘long_press [element]’: 长按一个元素。
-
- ‘enter’: 按下Enter键。
-
- ‘open_app [app_name]’: 按名称打开应用。
-
- ‘wait [value]’: 等待[value]秒直到屏幕更新。
- ### 任务结束:
-
- ‘stop [value]’: 以目标状态或答案停止任务。如果你认为任务已完成或不可行,请将状态设为’success’或’infeasible’。如果任务需要答案,请在此处提供答案。
- ### 思维过程说明:
- 详细描述情况,重点放在目标和当前截图中的相关视觉线索上。确保你的推理与目标一致,基于截图和之前动作预测最合适的动作。
-
- 目标是像解决问题一样推理任务,而不是简单地反思标记结果。
10.3. 以以下格式总结动作。
- 目标是像解决问题一样推理任务,而不是简单地反思标记结果。
最后,以以下动作结束你的思维过程。
总之,下一步动作是:
…
{
“Element Description”: “描述你想交互的元素,包括其身份、类型(例如按钮、输入框、下拉菜单、选项卡)以及任何可见文本。保持描述简洁且不超过30字。如果有相似的元素,请提供细节以区分它们。”,
“Action”: “从以下选项中选择一个动作:{click, type, scroll, go_back, go_home, long_press, enter, open_app, stop}。选择一个;不要留空。”,
“Value”: "根据所选动作提供附加输入:
- 对于’type’: 指定输入文本。
-
- 对于’scroll’: 指定方向(“up”, “down”, “left”, “right”)。
-
- 对于’open_app’: 提供应用名称,格式为: app_name=“应用名称”.
-
- 对于’stop’: 提供"completed", "infeasible"或所需答案。
-
- 对于’wait’: 提供等待时间,格式为: seconds=“5s”。
-
- 对于其他动作: 留空此字段。"
- }
- ### 输入:
- 之前动作: {previous_actions}
- 任务: {intent}
- 正确动作提示: {correct_answer}
图6:在OS-Genesis(移动)轨迹上生成思维链的提示。
在OS-Genesis(网络)轨迹上生成CoT的提示
想象你在模仿人类一步一步进行网络导航以完成任务。在每个阶段,你可以像人类一样通过截图看到网页,并知道基于记录的历史、当前截图和当前网站的元信息的前一动作。你需要决定下一步要采取的动作。
我会提供给你提示答案。请在你的思维过程中不要提到提示答案,而是像自己解决任务一样推理,但确保你的答案与提示答案相同。
## 可用动作:
### 网络操作:
- ‘click [element]’: 点击一个元素。
-
- ‘type [element] [value]’: 按ID在字段中输入内容。
-
- ‘clear [element]’: 清除元素的内容。
-
- 'hover [eleme------
- nt]': 按ID悬停在一个元素上。
-
- ‘press [value]’: 按下一个键组合(例如Ctrl+v)。
-
- ‘scroll [down]’ 或 scroll [up]': 滚动页面。
标签管理:
- ‘new_tab’: 打开一个新标签页。
-
- ‘tab_focus [tab_index]’ : 切换到特定标签页。
-
- ‘close_tab’: 关闭当前标签页。
- ------URL导航:
-
- ‘goto [url]’: 导航到一个URL。
-
- ‘go_back’: 返回上一页。
-
- ‘go_forward’: 前进到下一页。
任务完成:
- ‘stop [answer]’: 当你认为任务已完成时发出此动作。
思维过程说明:
- 详细描述情况,重点放在目标和当前截图中的相关视觉线索上。确保你的推理与目标一致,基于截图和前一动作预测最合适的动作。
-
- 目标是像解决问题一样推理任务,而不是简单地反思标记结果。
-
- 以以下格式总结动作。
-
- 在你的思维过程中不要提到提示答案。相反,独立推理出答案,但确保你的答案与提示答案一致。
最后,以以下动作结束你的思维过程。
总之,下一步动作是:
・.
{
“Element Description”: “描述你想交互的元素,包括其身份、类型(例如按钮、输入框、下拉菜单、选项卡)以及任何可见文本。保持描述简洁且不超过30字。如果有相似的元素,请提供细节以区分它们。”,
“Action”: “从以下选项中选择一个动作:[stop, click, type, scroll, go_back, go_forward, goto, clear, hover, press, new_tab, page_focus, close_tab]. 选择一个动作;不要留空此字段。”,
“Value”: "根据所选动作提供附加输入:
- 在你的思维过程中不要提到提示答案。相反,独立推理出答案,但确保你的答案与提示答案一致。
- 对于’click’: 指定要点击的元素。
-
- 对于’type’: 指定输入文本。
-
- 对于’scroll’: 指定方向(“up”, “down”)。
-
- 对于’goto’: 指定要导航到的URL。
-
- 对于’clear’: 留空此字段。
-
- 对于’hover’: 指定要悬停的元素。
-
- 对于’press’: 指定要按下的键组合。
-
- 对于’tab_focus’: 指定要切换到的标签索引。
-
- 对于’stop’: 提供以下之一:“completed”, "infeasible"或所需答案。
-
- 对于’wait’: 提供等待时间(秒),格式为:seconds=“5s”。
-
- 对于所有其他动作: 留空此字段。"
- }
输入:
之前动作: {previous_actions}
任务: {intent}
正确动作提示: {correct_answer}
图7:在OS-Genesis(Web)轨迹上生成思维链的提示。
在VisualWebArena轨迹上生成CoT的提示
想象你在模仿人类一步一步进行网络导航以完成任务。在每个阶段,你可以像人类一样通过截图看到网页,并知道基于记录的历史、当前截图和当前网站的元信息的前一动作。你需要决定下一步要采取的动作。
我会提供给你提示答案。请在你的思维过程中不要提到提示答案,而是像自己解决任务一样推理,但确保你的答案与提示答案相同。
## 可用动作:
### 网络操作:
- ‘click [element]’: 点击一个元素。
-
- ‘type [element] [value]’: 按ID在字段中输入内容。
-
- ‘clear [element]’: 清除元素的内容。
-
- ‘hover [element]’: 按ID悬停在一个元素上。
-
- ‘press [value]’: 按下一个键组合(例如Ctrl+v)。
-
- ‘scroll [down]’ 或 ‘scroll [up]’: 滚动页面。
### 标签管理:
- ‘scroll [down]’ 或 ‘scroll [up]’: 滚动页面。
- ‘new_tab’: 打开一个新标签页。
-
- ‘page_focus [tab_index]’: 切换到特定标签页。
-
- ‘close_tab’: 关闭当前标签页。
### URL导航:
- ‘close_tab’: 关闭当前标签页。
- ‘goto [url]’: 导航到一个URL。
-
- ‘go_back’: 返回上一页。
-
- ‘go_forward’: 前进到下一页。
### 任务完成:
- ‘go_forward’: 前进到下一页。
- ‘stop [answer]’: 当你认为任务完成时发出此动作。
### 思维过程说明:
- 详细描述情况,重点放在目标和当前截图中的相关视觉线索上。确保你的推理与目标一致,基于截图和前一动作预测最合适的动作。
-
- 目标是像解决问题一样推理任务,而不是简单地反思标记结果。
-
- 以以下格式总结动作。
-
- 在你的思维过程中不要提到提示答案,但确保你的答案与提示答案相同。
最后,以以下动作结束你的思维过程。
总之,下一步动作是:
・.
{
“Element Description”: “描述你想交互的元素,包括其身份、类型(例如按钮、输入框、下拉菜单、选项卡)以及任何可见文本。保持描述简洁且不超过30字。如果有相似的元素,请提供细节以区分它们。”,
“Action”: “从以下选项中选择一个动作:(stop, click, type, scroll, go_back, go_forward, goto, clear, hover, press, new_tab, page_focus, close_tab)。选择一个动作;不要留空此字段。”,
“Value”: "根据所选动作提供附加输入:
- 在你的思维过程中不要提到提示答案,但确保你的答案与提示答案相同。
- 对于’click’: 指定要点击的元素。
-
- 对于’type’: 指定输入文本。
-
- 对于’scroll’: 指定方向(“up”, “down”)。
-
- 对于’goto’: 指定要导航到的URL。
-
- 对于’clear’: 留空此字段。
-
- 对于’hover’: 指定要悬停的元素。
-
- 对于’press’: 指定要按下的键组合。
-
- 对于’page_focus’: 指定要切换到的标签索引。
-
- 对于’stop’: 提供以下之一:“completed”, "infeasible"或所需答案。
-
- 对于’wait’: 提供等待时间(秒),格式为:seconds=“5s”。
-
- 对于所有其他动作: 留空此字段。"
- } 1 \}_{1} }1
- ### 输入:
- 当前URL: {url}
- 之前动作: {previous_actions}
- 任务: {intent}
- 提示动作: {hint_action}
图8:在VisualWebArena轨迹上生成思维链的提示。
在Mind2Web轨迹上生成CoT的提示
你是一个智能且有帮助的视觉助手,擅长操纵网站。你的任务是逐步导航并执行当前屏幕上的动作以完成用户请求。
我会提供给你提示答案。请在你的思维过程中不要提到提示答案,而是像自己解决任务一样推理,但确保你的答案与提示答案相同。
## 指令:
-
你会收到截图和网站信息。
-
- 回顾之前的动作以确定下一步。必要时返回到前一状态。
-
- 特别注意任务的所有具体要求。
## 分析指南
### 之前动作分析:
- 特别注意任务的所有具体要求。
-
你应该分析之前的动作和当前任务的状态。
-
### 截图描述:
-
- 你应该详细描述所有截图,特别是交互元素,如按钮、搜索栏和下拉列表。
-
### 子任务规划:
-
- 根据观察和过去动作分析任务状态,并详细规划合理的未来动作以完成用户请求。
-
- 你应该仔细检查所有具体要求来制定计划。
-
- 必须通过分析当前截图确认最后一个动作是否成功执行。
-
### 关键分析和反思:
-
- 检查历史动作是否完成了用户请求。
-
- 批判过去的动作,决定下一个动作,并决定是否通过诸如"go back", “goto url”, "scroll up"等动作回溯到前一步。
-
- 评估当前子任务和整体任务的可行性,并决定是否修改计划。
最后,以以下动作结束你的思维过程。
总之,下一步动作是:
・.
{
“Element Description”: “描述你想交互的元素,包括其身份、类型(例如按钮、输入框、下拉菜单、选项卡)以及任何可见文本。保持描述简洁且不超过30字。如果有相似的元素,请提供细节以区分它们。”,
“Action”: “从以下选项中选择一个动作:{click, type, scroll, go_back, go_home, long_press, enter, open_app, stop}。选择一个;不要留空。”,
“Value”: "根据所选动作提供附加输入:
- 评估当前子任务和整体任务的可行性,并决定是否修改计划。
-
对于’type’: 指定输入文本。
-
- 对于’scroll’: 指定方向(“up”, “down”, “left”, “right”)。
-
- 对于’open_app’: 提供应用名称,格式为: app_name=“应用名称”.
-
- 对于’stop’: 提供"completed", "infeasible"或所需答案。
-
- 对于’wait’: 提供等待时间(秒),格式为: seconds=“5s”。
-
- 对于其他动作: 留空此字段。"
-
}
-
## 输入:
-
任务: {task}
-
之前动作: {previous actions}
-
提示答案: {hint_answer}
图9:在Mind2Web轨迹上生成思维链的提示。
移动任务评估提示
你是一个移动代理。你需要逐步执行一系列动作以在Android设备上完成任务。在每一步,你会获得当前截图和已采取的前一动作。你需要决定下一步要采取的动作。
可用动作:
UI 操作:
click [element]: 点击一个元素。-
type [element] [value]: 按ID在字段中输入内容。
-
scroll [element] [value]: 滚动页面或特定元素。方向可以是’up’, ‘down’, ‘left’, 或 ‘right’。滚动整个页面时留空元素。
-
go_back: 返回。
-
go_home: 导航到主屏幕。
-
- `long_press [element]': 长按一个元素。
-
enter: 按下Enter键。
-
open_app [app_name]: 按名称打开应用。
-
wait [value]: 等待[value]秒直到屏幕更新。
-
任务完成:
-
stop [value]: 停止任务并设置目标状态或答案。如果你认为任务已完成或不可行,请将状态设为’successful’或’infeasible’。如果任务需要答案,请在此处提供答案。
- 请提供你的详细思维过程并指定你打算执行的动作。该动作应包括要操作的元素的描述、动作类型及相应的值,格式如下:
- …
- {
- “Element Description”: “描述你想交互的元素。”,
- “Action”: “从可用选项中选择一个动作,不要留空。”,
- “Value”: “仅在动作需要时提供值。”
- }
- `.
-
输入:
- 之前动作: {previous_actions}
任务: {intent}
图10:移动任务评估提示。
网络任务评估提示
想象你在模仿人类一步一步进行网络导航以完成任务。
在每个阶段,你可以通过截图看到网页,并知道基于记录的历史、当前截图和当前网站的元信息的前一动作。你需要决定下一步要采取的动作。
可用动作:
网络操作:
click [element]: 点击一个元素。-
type [element] [value]: 按ID在字段中输入内容。
-
clear [element]: 清除元素的内容。
-
hover [element]: 悬停在一个元素上。
-
press [value]: 按下一个键组合(例如Ctrl+v)。
-
scroll [down]或scroll [up]: 滚动页面。
-
标签管理:
-
new_tab: 打开一个新标签页。
-
tab_focus [tab_index]: 切换到特定标签页。
-
close_tab: 关闭当前标签页。
-
URL导航:
-
goto [url]: 导航到一个URL。
-
go_back: 返回上一页。
-
go_forward: 前进到下一页。
-
任务完成:
-
stop [answer]: 当你认为任务完成时发出此动作(值可能是successful, infeasible或所需答案)。
- 请提供你的详细思维过程并指定你打算执行的动作。该动作应包括要操作的元素的描述、动作类型及相应的值,格式如下:
- …
- {
- “Element Description”: “描述你想交互的元素。”,
- “Action”: “从可用选项中选择一个动作。选择一个;不要留空。”,
- “Value”: “仅在动作需要时提供值。”
- }
- …
-
输入:
- 当前URL: {url}
- 之前动作: {previous_actions}
- 任务: {intent}
图11:网络任务评估提示。
参考论文:https://arxiv.org/pdf/2504.10127



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











