






黄成凯,黄宏涛,余通,谢凯格,吴俊达,张帅,朱利安·麦克莱,迪特马尔·扬纳赫,姚丽娜
摘要
推荐系统(RS)已在信息过滤和个性化内容提供中变得至关重要。传统上,RS 技术依赖于建模用户与项目之间的交互以及使用特定任务模型的内容特征。随着基础模型(FMs)的出现,如在大量数据上训练的大规模模型 GPT、LLaMA 和 CLIP,推荐范式正在被重塑。本综述全面概述了用于推荐系统的基础模型(FM4RecSys),涵盖了其在三种范式中的集成:(1)基于特征的表示增强,(2)生成式推荐方法,(3)代理式交互系统。我们首先回顾了 RS 的数据基础,从传统的显式或隐式反馈到多模态内容来源。然后介绍 FMs 及其在自然语言理解、多模态推理中的能力。本文核心讨论了 FMs 如何在基于特征的范式(改进特征表示)、生成式范式(直接生成推荐或相关内容)和代理式范式(实现自主推荐代理和模拟器)下增强 RS。随后,我们检查了 FM 在各种推荐任务中的应用:Top-N 推荐、序列化推荐、零/少样本场景、对话式推荐和新项目/内容生成。通过分析最近的研究,我们强调了已实现的关键机会(例如,改进的泛化能力、更好的解释、推理能力)以及遇到的挑战(例如,跨域泛化、可解释性、公平性和多模态整合)。最后,我们概述了下一代 FM4RecSys 的开放研究方向和技术挑战,如多模态推荐代理、检索增强框架、面向长期用户序列的终身学习、效率和成本问题等。本综述不仅回顾了最前沿的方法,还对特征、生成和代理范式之间的权衡进行了批判性分析,并明确了关键的开放问题和未来研究方向。
索引术语 - 基础模型,推荐系统,多模态表示,调查。
1 引言
推荐系统(RSs)在多个领域中变得至关重要,从电子商务和社交媒体到医疗保健和教育 [1],[2]。它们旨在通过捕捉用户偏好、项目特性和上下文信号来提供个性化内容。过去十年间,得益于深度学习架构的进步和大规模用户行为数据的可用性增加,该领域取得了显著进展。尽管如此,传统 RS 仍面临捕捉微妙用户偏好、处理冷启动场景以及提供透明、情境丰富的解释的持续挑战。这些问题限制了纯粹特定领域或小规模模型在提供准确和多样化推荐方面的有效性。
与此同时,基础模型(FMs)在诸如自然语言处理、计算机视觉和多模态任务等领域取得了重大进展 [3]。最近,FMs 开始重塑推荐系统架构,提升性能,启用新型用户交互模式,并展现出在捕捉复杂用户-项目关系和跨更广泛推荐任务泛化方面强大的潜力。具体来说,推荐系统的基础模型(FM4RecSys)指的是利用预训练知识和推荐数据集来捕获丰富的用户偏好、项目特征和上下文变量表示,从而改善推荐任务中的个性化和预测准确性。同时,基础模型(FMs)是大规模、预训练且具有强大任务泛化能力的模型,为各种下游推荐任务提供了统一而灵活的建模范式 [4]。与依赖精心设计的特征或窄架构的传统方法不同,FMs 利用广泛的预训练语料库,实现更强的泛化能力和整合各种信号的能力(文本、图像、音频、知识图谱等)。这种灵活性可以产生更丰富的用户/项目表示,并帮助克服传统协同过滤中存在的数据稀疏性和冷启动问题。除了提升预测准确性之外,基础模型(FMs)还解锁了新功能,包括自然语言解释、交互式对话界面,甚至代理决策。特别是,代理框架利用 FMs 在动态环境中通过结合迭代用户反馈和实时上下文理解来自主规划、推理和适应。接下来,我们将深入探讨现有工作中将基础模型融入推荐系统的动机,以加深对 FMs 如何应用及其在不同推荐任务中的影响的理解。
1.1 动机
我们列举了推动 FM4RecSys 领域发展的主要动机,旨在提供对促进和采用 FM 驱动 RS 的因素的全面理解。
增强的泛化能力。基础模型旨在从大规模数据中学习,使它们能够理解复杂的模式。FMs 可以更好地泛化到新的、未见过的数据 [5]。在 RS 的背景下,这意味着 FMs 可以更准确地预测用户偏好和行为,特别是在稀疏数据或新项目(在某些论文中定义为零样本/少样本推荐 [6]-[8])的情况下。通过零样本/少样本推断用户偏好和项目属性,FMs 能够在缺乏广泛交互历史的情况下提供有效的推荐。
提升的推荐体验。基础模型促进了推荐系统接口范式的转型,显著改变了用户体验交互方式。例如,对话式 RS 是一个经典用例,之前的对话式推荐系统(CRSs)[9],[10] 主要依赖于预先建立的对话模板,这种依赖往往限制了用户参与的广度和适应性。相比之下,FMs 引入了向更动态和非结构化的对话交互转变的范式,提供更高的互动性和灵活性。交互式设计允许用户以更吸引人和自然的方式与系统进行互动。用户可以通过对话沟通他们的偏好、提问并接收定制化推荐。
改进的解释和推理能力。基础模型增强了推荐系统的解释和推理能力。虽然传统推荐系统主要从简单的来源如用户评论或基本用户行为中衍生解释,包括共同购买的项目或同行购买,但这些解释往往缺乏深入的逻辑和背景 [11]。相反,基础模型具备生成富含常识和用户特定上下文的解释的能力 [12]。这些模型利用一系列数据,包括用户偏好、历史交互和独特项目特性,生成更加连贯和逻辑合理的解释。利用基础模型深入解读用户行为序列和兴趣,可以显著提高复杂场景下未来推荐系统的有效性 [13],有望推进医学和医疗领域的知情和负责任决策过程,例如治疗和诊断推荐。
鉴于这些优势,一波研究已经开始探索 FM4RecSys。由于传统 RS 在数据稀疏和刚性特征提取等问题上的挣扎,FMs 的出现承诺了更广泛的泛化能力。然而,在实际应用中实现这一潜力带来了新的挑战,如实时适应、计算效率和互操作性等问题尚未充分探索。为了更好地理解机会和局限性,我们提供了对 FM4RecSys 的全面和批判性评估,围绕三个核心范式和一系列推荐任务展开。
1.2 FM 驱动推荐系统的范式
如何将 FMs 集成到推荐系统中?我们在当前研究中确定了三种集成范式:基于特征、生成式和代理式。这些范式在基础模型在 RS 流程中扮演的角色上有所不同(从被动特征提供者到主动决策者)。图 1 提供了这三种范式的高级比较示例。
基于特征的范式:此方法将基础模型作为特征提取器,生成高质量的用户、项目或交互嵌入。例如,文本基础模型(如 BERT)[14] 将项目描述或用户评论编码为语义向量,而视觉语言模型(如 CLIP)[15] 对齐多模态特征(文本、图像)以实现跨域推荐。尽管有效,这种范式通常将 FMs 限制在辅助角色,与核心推荐逻辑脱钩。
生成式范式:这种方法利用了 FMs 的生成能力(如 GPT),此范式直接将推荐综合为生成输出 [16]。例子包括生成个性化解释 [17]、创建虚拟项目(如广告标语、产品设计)或通过自回归标记预测预测用户偏好。然而,这些系统在可控性和与用户意图的对齐方面面临挑战,因为生成可能优先考虑流畅性而非相关性。
代理式范式:新兴的代理式范式重新构想了由 FMs 赋能的自主 RS [18]。这些代理动态地与用户交互(如通过自然语言)、推理长期偏好,甚至采取行动(如探询问题、多步规划)以优化推荐。与静态模型不同,代理系统表现出目标驱动的行为,利用工具(如搜索引擎、数据库)和反馈循环以适应不断变化的环境。
虽然基于特征和生成式的范式已经提高了推荐的准确性和多样性,代理范式代表了向主动、可解释和符合人类需求的系统转变。通过整合推理、工具使用和多轮交互,代理式 FMs 解决了传统 RS 的关键局限性:(i)动态适应:代理根据实时反馈连续更新用户画像,缓解冷启动和数据稀疏问题。(ii)多模态情境化:它们统合文本、语音和视觉输入以捕捉细腻的偏好(如解释用户的商品截图)。(iii)伦理一致性:近期研究探索了宪法 AI 技术 [19],通过将预定义的伦理原则或人类一致规则纳入生成过程来引导模型行为,以平衡个性化与公平性和透明性。大型语言模型(LLM)代理(如 AutoGPT T { }^{\mathrm{T}} T,Meta 的 CICERO [20])和检索增强生成(RAG)框架的快速进展进一步证明了该范式的可行性。
1.3 与最近基于 LLM 的 RS 综述的区别
FM4RecSys 研究正在加速,最近有几篇综述回顾了这一新兴交叉领域的部分内容。刘等人 [21] 深入探讨了语言建模范式适配推荐器的训练策略和学习目标,而吴等人 [22] 从判别和生成的角度提供了关于基于语言模型的推荐系统(LLM4Rec)的见解。林等人 [4] 引入了两个正交视角:在哪里以及如何在推荐系统中适配 LLMs。范等人 [23] 概述了基于 LLMs 的推荐系统,集中于预训练、微调和提示等范式。林等人 [24] 总结了生成式推荐的当前进展,并按不同的推荐任务进行了组织。
差异和关键贡献:与以前的综述相比,我们的综述视野更广:我们涵盖了超越仅 LLMs 的基础模型,包括视觉和多模态模型,并按照涵盖数据、集成范式、任务和开放挑战的新分类法进行讨论。特别是,我们强调了一个三范式框架——基于特征、生成式和代理式——以理解 FMs 如何在推荐系统中得到利用,并介绍了已被 FMs 应对的各种下游推荐任务。如图 2 所示,我们系统地勾勒出使用基础模型(FMs)进行推荐系统(FM4RecSys)的框架,涵盖从推荐数据的特性到具体下游任务的所有内容。我们从不同角度分析了现有出版物并引入了新的见解。最后,我们进一步探讨了该领域最新的未解决问题和潜在机会。
论文收集标准:我们收集了超过 150 篇与推荐系统相关的基础模型论文。最初,我们在顶级会议和期刊如 ICLR、NeurIPS、WWW、WSDM、SIGIR、KDD、ACL、EMNLP、NAACL、RecSys、CIKM、TOIS、TORS 和 TKDE 中搜索了最近的工作。我们搜索的主要关键词包括推荐系统的大规模语言模型、生成式推荐、大规模语言模型、多模态推荐和推荐代理。
本综述的贡献:本综述的目的是对推荐系统的基础模型(FM4RecSys)的进展进行全面审查。它提供了一个全面的概览,使读者能够快速掌握和参与基础模型驱动的推荐领域。本综述奠定了创新 RS 的基础,并探索了这一研究领域的深度。它旨在为对 RS 感兴趣的研究人员和从业者提供指南,帮助他们选择适合解决推荐任务的 FMs。总之,本综述的关键贡献有三个方面:(1)详细回顾了基础模型在推荐中的应用,并引入了一种分类方案以组织和定位当前工作;(2)提供了现状的概述和总结;(3)讨论了挑战、开放问题,并识别了该研究领域的新趋势和未来方向,以扩展 FM4RecSys 研究的视野。
本文其余部分结构如下:第 2 节通过对比传统来源(如用户交互、顺序行为和网络连接)的基础方面与多模态数据的新兴重要性,探讨了 RS 数据的特性。第 3 节介绍了 FMs 的最新进展,突出了这些模型的优势和局限性,从其可扩展性和泛化能力到其在不同任务中的能力。第 4 节讨论了 FMs 在 RS 中的表示学习,分析了用于导出封装 RS 数据表示的技术。第 5 节考察了 FM4RecSys 的集成方法,重点是将基础模型纳入 RS 流程的策略。第 6 节详细介绍了 FM4RecSys 模型设计解决的具体任务,包括 Top-n 排名等,同时识别特定任务的挑战和当前解决方案。第 7 节回顾了与 FM4RecSys 机会和观察到的影响相关的实证发现,包括其在增强可扩展性、效率和减少偏见方面的潜力。在第 8 节中,我们讨论了 FM4RecSys 的开放挑战和未来研究方向,突出了解决模型鲁棒性、可解释性和计算效率等未解决的问题,并提出了推进这一新兴领域的发展方向。最后,第 9 节通过总结基础模型对 RS 的贡献来结束本文。
2 传统 RS 数据特性
本节探讨了 RS 领域使用的各种类型的数据。传统 RS 依赖于结构化来源,如用户人口统计、明确反馈和行为历史,通过顺序和网络数据捕捉动态交互模式 [1],[2]。相比之下,最近的进展涉及整合多模态数据,包括文本、图像、音频和视频,这扩展了理解和用户偏好及项目属性的范围。一起,这些多样化的来源为解决各种推荐任务提供了坚实的基石 [25]。
2.1 传统 RS 数据
用户和项目信息:在传统推荐系统中,用户和项目信息构成了建模偏好和生成推荐的基础。用户信息通常包括人口属性(例如年龄、性别、位置)、明确偏好(例如评分、喜欢和评论)以及行为历史(例如购买记录和浏览日志)[1]。另一方面,项目信息包括元数据如类别、品牌、价格和文本描述,以及从图像、视频或音频派生的多模态特征 [1],[2]。此外,用户-项目交互矩阵在基于协同过滤的方法中起着至关重要的作用。隐式反馈,如点击、停留时间和购买行为,特别有价值,因为它反映了用户自然参与模式而不需明确评分。侧面信息,包括知识图谱和属性嵌入,进一步丰富了用户和项目的表示,特别是在稀疏交互场景中提高了推荐质量。
顺序信息:顺序信息在 RS 中起关键作用,捕捉用户与项目的时序交互序列 [26]。当用户标识符可用时,此类数据特别有用,允许构建利用个人历史行为的个性化推荐模型。在没有用户标识符的情况下,可以使用会话数据来建模单一会话内的交互,使其适用于涉及匿名用户或冷启动问题的场景。此外,基于兴趣点(POI)签到的位置数据 [27] 可以集成以提供情境感知推荐,这在移动和基于位置的服务中特别有效。
网络数据:网络数据是指实体之间的复杂关系,如用户、项目、社交连接和引用,RS 可以利用这些关系来提高推荐准确性 [2]。引用网络通过学术论文间的引用映射它们的关系,常用于学术推荐系统 [28]。社交网络捕捉用户间的交互和连接,使 RS 能够基于社交接近度和共享兴趣推荐朋友、内容或群体 [29]。
2.2 多模态 RS 数据
文本数据:文本数据代表 RS 中另一常见的信息来源。多种形式的文本内容,包括标签、新闻文章、评论等,用于得出丰富的上下文洞察。标签,经常在社交媒体中使用,有助于类似内容的聚类,并对推荐相关项目很有用 [30]。新闻文章和标题可以分析以向用户提供与其阅读兴趣一致的推荐 [31]。用户生成的评论提供了对用户偏好和项目属性的深刻洞察,这对基于内容的推荐方法至关重要,增强了推荐的个性化 [32]。
视觉数据:视觉数据在 RS 中的应用日益增多,尤其是在项目美学品质重要的领域。从图像中提取的视觉特征,如颜色、形状和纹理,用于推荐具有相似视觉特性的项目。这种方法在时尚、设计和艺术等领域尤为宝贵,其中视觉相似性在用户偏好中起着中心作用 [33]。
音频数据:音频数据,尤其是音乐形式,是 RS 的另一个关键输入。音频特征,包括类型、节奏和情绪,被分析以生成与用户的听歌历史和偏好一致的推荐。这个数据源对音乐流媒体服务至关重要,其中个性化的播放列表和曲目推荐基于复杂的音频特征分析 [34]。
视频数据:视频数据为 RS 提供了丰富的信息来源,特别是在多媒体内容推荐的背景下。从视频中提取的特征,如视觉风格、类型和内容类型,用于建议相似视频或增强内容发现机制 [35]。这个数据源对于视频流媒体平台尤为重要,其中用户的参与很大程度上依赖于及时和相关的推荐内容。
多模态融合:从先前的多源和多模态数据在 RS 中的研究来看,多模态融合被认为是 FM4RecSys 的关键组成部分。最近的文献探索了几种融合范式。早期融合在输入或表示级别组合模态特定特征;例如,来自产品图像和文本描述的嵌入可能被串联并联合处理 [36],使模型从一开始就捕捉模态间的相关性。相反,后期融合独立处理每个模态,并在其后阶段合并输出,通常通过平均、加权求和或门控机制 [37],提供灵活性但可能错过细粒度交互。混合融合通过在中间或输出阶段引入交互层来平衡这些策略,同时保留模态特定路径。例如,NOVA [36] 采用一种非侵入式的混合策略,维持协作和内容特征的独立分支,最终在预测层融合以保留基于 ID 的信号。基于注意力的融合已成为适应性集成的主导范式,其中注意力机制根据上下文相关性动态分配权重给模态或其内部组件(如文本标记或图像块)。共注意力或跨模态注意力机制在对齐模态方面特别有效;例如,CMBF [38] 使用共注意力对齐图像和文本表示,捕捉产品视觉和描述之间的互补语义。这些技术通常集成到基于变压器的架构中。在此基础上,跨模态变压器通过利用自注意力和跨注意力层进一步增强多模态融合,学习跨模态的联合表示,并成功应用于顺序和静态推荐任务 [39],[40]。此外,模态感知门控和基于图的融合提供了进一步的增强。基于图的方法将用户-项目交互建模为图,其中项目节点通过多模态内容丰富,允许模态特定消息传递和协作信号传播。例如,MMGCN [37] 和 MGAT [41] 利用注意力或门控机制自适应整合模态信号,而像 MARIO [42] 中使用的门控网络则根据用户偏好或上下文信号动态调整每个模态的影响,实现个性化和情境感知融合。
关键区别:传统和多模态 RS 数据
- 传统 RS 数据主要依赖于基本的用户和项目信息,如人口统计、明确偏好和行为历史,而多模态 RS 数据整合了多种模态,如文本、图像、音频和视频,显著拓宽了信息景观。
-
- 传统 RS 数据通常以清晰格式结构化,如用户-项目交互矩阵和定义的属性,而多模态 RS 数据通常是非结构化或半结构化的,需要专门的特征提取和投影到统一的潜在空间。
-
- 多模态 RS 数据由于需要整合异构模态,比传统 RS 数据需要更复杂的融合技术。
3 最近的基础模型进展
在本节中,我们将简要介绍 FMs、多模态基础模型和基础模型代理的最新进展。
3.1 基础模型
基础模型是指在广泛数据(通常使用大规模自监督)上训练的模型,可以适应(例如微调)到广泛的下游任务;当前的例子包括 BERT [14]、GPT-3 [43] 和 CLIP [15]。然而,过去几年基础模型的规模和范围极大地拓展了我们的想象力;例如,GPT-3 拥有 1750 亿个参数,并可通过自然语言提示在许多任务上表现良好,尽管它并未针对许多这些任务进行明确训练。基于 GPT-3 的成功,它是第一个包含超过 1000 亿个参数的模型,激发了一系列值得注意的模型,包括 GPT-J [44]、BLOOM [45]、OPT [46]、Chinchilla [47] 和 LLaMA [48]。这些模型遵循与 GPT-3 类似的 Transformer 解码器结构,并在各种数据集组合上进行训练。由于它们庞大的参数数量,针对特定任务(如 RS)微调大语言模型(LLMs)通常被认为不切实际。因此,已建立了两种主流的 LLM 应用方法:上下文学习(ICL)[49] 和高效参数微调 [50]。ICL 是 LLMs 的一种新兴能力,使它们能够基于提供的输入上下文理解并提供答案,而不是仅仅依赖于其预训练知识。这种方法只需在自然语言中制定任务描述和演示,然后作为输入提供给 LLM。值得注意的是,ICL 不需要参数调整。此外,通过采用链式思维提示,即涉及多个演示(描述链式思维示例)来引导模型的推理过程,可以进一步增强 ICL 的效果。ICL 是将 LLMs 应用于信息检索中最常用的方法。高效参数微调旨在减少可训练参数的数量,同时保持令人满意的性能。LoRA [50] 已被广泛应用于开源 LLMs(如 LLaMA 和 BLOOM)以实现此目的。最近,QLoRA [51] 提出了一种通过利用冻结的 4 位量化 LLM 进行梯度计算来进一步减少内存使用的方法。尽管在各种 NLP 任务中探索了高效参数微调,但在 RS 任务中的实施仍然相对有限,代表着未来研究的一个潜在方向。
3.2 多模态基础模型
最近,多模态基础模型(MFMs)取得了实质性进展,主要通过经济高效的训练策略增强了标准 FMs,使其能够容纳多模态输入和输出环境 [52]。MM-FMs 利用大型语言模型(LLMs)作为多模态任务中语义理解和推理的核心组件。随着营销模型如 GPT-4(Vision) [53] 和 Gemini [54],[55] 展现出卓越的多模态理解和生成能力,研究人员对多模态基础模型的兴趣激增。初期研究主要围绕多模态内容理解和文本生成展开。这包括图像-文本理解,如突破性项目 BLIP-2 [56]、BLIP-3 [57]、LLaVA [58]、MiniGPT4 [59] 和 OpenFlamingo [60]。VideoChat [61]、Video-ChatGPT [62] 和 LLaMA-VID [63] 进一步通过视频-文本理解扩展了这一领域。MM-LLMs 的音频-文本理解能力也在 QwenAudio [64] 和 Qwen-Audio2 [65] 等项目中得到了广泛探索。后续研究扩大了 MM-LLMs 的能力,包括特定模态输出。图像到文本输出任务通过 Kosmos-G [66]、Emu [67] 和 MiniGPT-5 [68] 等努力得以实现,而 SpeechGPT [69] 和 AudioPaLM [70] 则标志着语音/音频文本输出的到来。近期,研究焦点转向模仿人类任何模态转换,展示了迈向人工通用智能的潜在路径。一些尝试通过结合 LLMs 和外部工具实现了全面的多模态理解和生成,如 VisualChatGPT [71]、HuggingGPT [72] 和 AudioGPT [73] 所展示的那样。相比之下,为了最小化系统中的级联错误,开发了新颖的举措如 NExT-GPT [74]、CoDi-2 [75] 和 ModaVerse [76]。这些提供端到端 MM-LLMs 并覆盖整个模态范围,标志着在 RS 领域有效建模多模态内容的有希望步骤。
3.3 基础模型代理
大型语言模型(LLM)为基础的人工智能的迅速发展推动了 Agent AI 的显著进步,从根本上改变了系统与复杂环境的交互方式。近年来,研究人员为 LLM 代理配备了核心组件——记忆、规划、推理、工具使用和行动执行——这些组件对于自主决策和动态交互至关重要 [77]。
单一代理系统利用将多个相互依赖模块集成的统一模型。记忆组件充当结构化存储库,存储和检索上下文相关信息,如用户偏好和历史交互 [78]。这种持久记忆对于保持连贯的长期交互至关重要,并构成了推荐设置中个性化的基础。规划模块与先进的推理能力密切相关。最近的研究确定了诸如任务分解、多计划选择、外部模块辅助规划、反思和改进、记忆增强规划等方法 [79]。这些技术使代理能够分解复杂任务,根据不断变化的上下文选择和改进策略,并利用外部知识源。集成推理进一步通过允许系统动态适应新场景来增强决策。框架如 ReAct [80] 和 Reflexion [81] 展示了如何通过插入具体行动(如网页浏览或工具调用)与推理相结合,显著提高系统稳健性和适应性。除了内部认知过程外,这些代理越来越依赖工具使用来与外部数据和服务接口。WebGPT [82] 系统展示了使用外部模块(如网络搜索引擎)检索实时信息的有效性。其他工作如 Retroformer [83] 和 AvaTaR [84] 分别通过策略梯度优化和对比推理进一步优化这些交互,以微调工具使用并随着时间的推移提高性能。
相比之下,基于 LLM 的多代理系统强调不同自主代理之间的协作。这些系统旨在通过促进代理间通信、任务专业化和协调决策来模仿复杂的人类工作流程。框架如 CAMEL [85] 和 AutoGen 展示了如何通过具有不同角色的代理相互作用来更有效地解决问题。通过分配从构思到规划再到评估的专门功能,这些框架实现了劳动分工,增强了整体系统能力和灵活性。更进一步的进展体现在 MetaGPT [86] 和 AgentLite [87] 中,它们结合了元编程技术和轻量级库,以动态分配角色并协调复杂的工作流程。这些结构化的交互不仅提高了任务效率,还在动态问题解决环境中提供了稳健性。最近的发展还包括 ChatEval [88] 和 ChatDev [89] 系统,这些系统利用代理间辩论和评估反馈生成更细致和可靠的输出。这种代理之间的人类样讨论在开放式自然语言生成任务和复杂的软件开发过程中特别有益。
4 表示学习
在基础模型时代之前,RS 严重依赖于用户和项目的一热编码表示进行深度学习模型。随着 FM4RecSys 的到来,出现了向更多样化输入转变的趋势,如用户配置文件、项目侧信息和外部知识库(如维基百科),以提高推荐性能。具体来说,许多工作 [90],[91] 指出,构建基于 FM 的推荐系统的关键在于弥合 FM 预训练和推荐任务之间的差距。为了缩小这一差距,现有工作通常将推荐数据表示为自然语言,以便在 FMs 上进行微调 [92]。在此过程中,每个用户/项目由唯一标识符(如用户配置文件、项目标题或数字 ID)表示,随后将用户的交互历史转化为标识符序列。FMs 可以在这些标识符上进行微调,以学习它们的表示,从而在推荐任务中表现出色。当前的推荐数据表示方法可分为基于 ID 的表示、多模态表示、图表示和混合表示。
4.1 基于 ID 的表示
在 FM 环境下,最近关于基于 ID 的表示的研究利用像 “[前缀]+[ID]”(如 “user_123” 或 “item_57”)这样的数值 ID 来表示用户和项目,有效捕捉项目的独特性 [93],[94]。然而,数值 ID 缺乏语义,无法充分利用 FMs 中的丰富知识。此外,FMs 需要足够的交互来微调每个 ID 表示,限制了它们在大规模、冷启动和跨域推荐中的泛化能力。此外,ID 索引需要更新词汇表以处理词汇表外(OOV)问题和 FMs 参数更新带来的额外计算成本,凸显了对更具信息量的表示的需求。同时,顺序 ID 索引 [94] 被用来直观地捕捉协作信息。
4.2 多模态表示
另一种有前途的方式是利用多模态侧信息,包括使用图像 [95](如项目视觉),文本内容 [96]-[101](包括项目标题、描述和评论),多模态元素 [102]-[105](如短视频片段和音乐),以及外部知识源 [106]-[108](如维基百科中详细说明的项目关系)。袁等人 [109] 强调了多模态 RS 相较于基于 ID 的对应物的优势,指出性能提升,强调更丰富的用户和项目侧信息可以在跨域和冷启动推荐场景中提高性能。
然而,纯项目侧信息与用户-项目交互之间的一致性可能并不总是存在 [92],[110]。换句话说,具有相似视觉或文本特征的两个项目不一定与用户共享相似的交互模式。因此,很自然地利用结合 ID 和多模态侧信息的混合表示来实现独特性和语义丰富性。例如,TransRec [111] 利用结合 ID、标题和属性的多面标识符,以实现项目表示的独特性和语义丰富性。CLLM4Rec [92] 通过硬提示和软提示将用户/项目 ID 标记与用户-项目评论文本信息对齐,使得能够准确建模用户/项目协作信息和内容语义。
4.3 图表示
此外,用户-项目交互中固有的图形结构使得图表示成为一种自然的方式来利用用户-项目图中的结构化信息,从而增强推荐系统对复杂交互和用户偏好的建模能力 [112]。基于 LLM 的图表示主要分为两类。第一类涉及使用图神经网络(GNNs/HGNNs)对实体 ID(包括用户 ID、项目 ID 和属性 ID)进行编码以获得图表示。然后,使用 LLMs 对实体本身的文本描述进行编码以获得语义文本表示。这两种表示随后融合形成混合表示 [113]-[116]。Ren 等人 [117] 通过结合通过 LLMs 获得的辅助文本信号并与协作关系图信号对齐语义空间,提升了对用户/项目协作信息和内容语义的准确建模。
| 表示学习方法 | 适合的 FM 范式 | 适合的推荐任务 | 主要优点 | 挑战 |
|---|---|---|---|---|
| 基于 ID 的表示 | > 主要是基于特征 | > Top-N 推荐 > 基本顺序推荐 | > 高效性和可扩展性 > 易于与现有管道集成 | > 缺乏语义深度 > 在复杂场景中适应性有限 |
| 多模态表示 | > 与基于特征和生成式互补 | > 跨域推荐 > 项目/内容生成 > 对话式推荐 | > 来自不同来源的丰富语义上下文 > 改进冷启动问题的处理 | > 增加了预处理的复杂性 > 对齐问题和潜在噪声 |
| 图表示 | > 最适合生成式和代理框架 | > 顺序推荐 > 跨域推荐 > 对话式推荐 | > 捕捉丰富的关系和上下文信息 > 通过交互建模实现动态适应 | > 计算成本高 > 在大规模图中可扩展性问题 |
| 混合表示 | > 在基于特征、生成式和代理框架中均适用 | > 包括 Top-N、顺序、对话、跨域和项目/内容生成在内的广泛任务适用 | > 在效率与丰富的语义表达之间取得平衡 > 充分利用多种模态的互补优势 | > 增加了模型复杂性 > 在有效融合和对齐方面存在挑战 |
表格 1
不同表示学习方法的比较分析。该表显示了每种方法对特定 FM 范式(第 5 节)和推荐任务(第 6 节)的适用性,以及其主要优点和挑战。
第二类首先使用 LLMs 提取实体的文本表示。然后,基于实体之间的关系,使用 GNNs/HGNNs 进行编码以获得图表示。Damianou 等人 [118] 在物品-物品图上训练 HGNN,如果物品被同一用户共同交互,则它们相连。每个节点与从 LLMs 应用于物品描述的文本嵌入节点特征相关联。最终表示将物品的语义信息与其物品-物品关系表示相结合。这些集成旨在利用 LLMs 在自然语言理解和 GNNs 在关系数据处理中的优势,从而构建一个更强大的推荐系统,能够理解和推荐物品。
总结而言,表 1 提供了对本节讨论的各种表示学习方法的全面比较分析。该表将基于 ID、多模态、基于图和混合表示分类,并将其与三大 FM 范式——基于特征、生成式和代理式——对齐,进一步将它们映射到具体的推荐任务,如 Top-N、顺序、对话、跨域和项目/内容生成。该概述表明,基于 ID 的表示在 Top-N 推荐等快速、可扩展的应用中高度有效,而多模态方法提供了有利于跨域和内容生成任务的丰富语义上下文。同样,基于图的方法在捕捉顺序和对话推荐中至关重要的关系和动态用户-项目交互方面表现出色,而混合方法旨在结合这些优势,以在效率和表达能力之间取得平衡。总体而言,这张表不仅强调了每种表示策略相关的权衡,还为理解其在后续章节中概述的集成框架中的作用奠定了基础。
5 FM4RecSys:集成方法
如第 1.2 节所述,我们确定了当前研究中的三种集成范式:基于特征、生成式和代理式。表 2 从不同角度对这些范式进行了详细比较。接下来,我们将深入探讨每个范式,调查代表性方法并讨论其优缺点。
5.1 基于特征的范式:基础模型作为特征增强器
如图 3 所示,现有研究可以分为两个方向:(i) FM 嵌入用于 RS,其中 FMs 作为特征编码器生成高质量的用户/项目嵌入以供传统推荐模型使用;(ii) FM 标记用于 RS,其中 FMs 生成语义感知标记或索引来促进推荐中的标记级生成和检索。
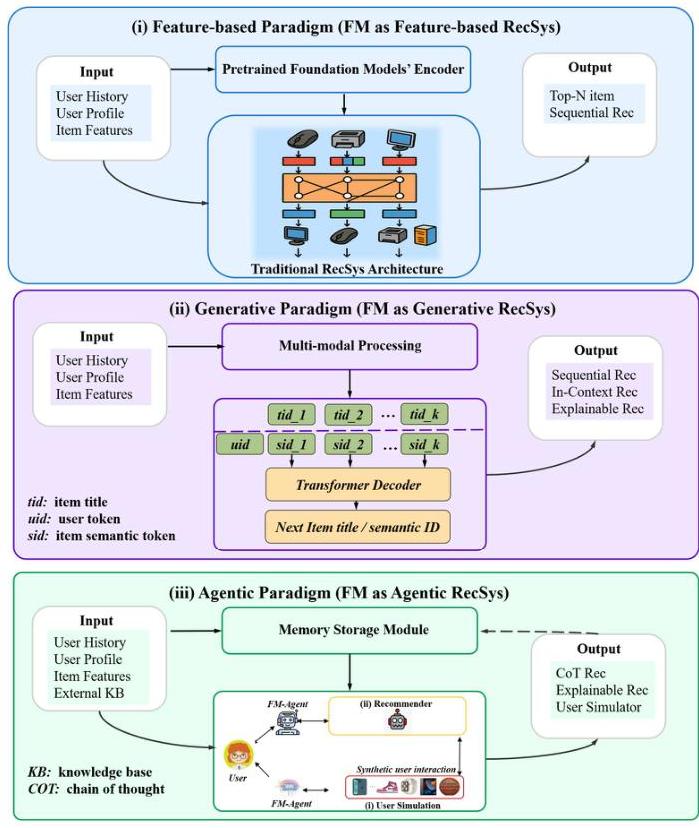
图 1. FM 驱动推荐系统的三种范式
FM 嵌入用于 RS:此建模范式将语言模型视为特征提取器,将项目和用户的特征输入到 LLMs 中并输出相应的嵌入。传统的 RS 模型可以利用知识感知嵌入来完成各种推荐任务。RLMRec [117] 将 LLMs 视为文本编码器,将项目或用户映射到语义空间,并将语义空间与协作关系建模对齐以改进表示学习。他们利用 LLMs 高级的文本理解能力来捕捉用户行为和偏好的细微语义方面。AlphaRec [119] 使用线性映射将项目标题的语言表示投影到行为空间以进行推荐。那些语言表示被转化为高质量的行为表示,从而实现了出色的推荐性能。LLMRec [120] 使用 LLMs 进行图增强 RecSys,通过增强用户-项目交互边、项目节点属性和用户节点配置文件来解决隐式反馈信号稀缺的问题。该工作通过使 LLMs 显式推理用户-项目交互模式来应对这一挑战。BinLLM [121] 通过将协作信息文本化为 LLMs 提供的推荐系统,将协作嵌入转换为二进制序列。具体而言,BinLLM 将来自外部模型的协作嵌入转换为二进制序列,这是一种与 LLMs 兼容的文本格式,从而可以直接以文本形式利用协作信息。iDreamRec [122] 进一步结合了 LLMs 嵌入与扩散模型 [123] 用于推荐任务,通过整合来自 LLMs 的文本嵌入来准确建模项目分布。特别是,给定关于项目的元数据(例如标题),这项工作提示 GPT 生成详细的文本描述,提供比简单项目 ID 更丰富的内容。
FM 标记用于 RS:此建模范式根据输入项目的和用户的特征生成标记。生成的标记通过语义挖掘捕捉潜在偏好,并可集成到推荐系统的决策过程中。最近的研究引入了一些方法,其中项目由具有语义意义的标记表示,从而实现更准确和情境感知的推荐。例如,TIGER 框架 [16] 提出了一种生成检索方法,自回归解码项目标识符。在此框架中,每个项目被分配一个语义 ID——从项目内容特征中派生的编码词组,从而使系统能够基于先前交互预测用户可能交互的下一个项目。类似地,LC-Rec 模型 [124] 通过整合语言和协作语义解决了大语言模型和推荐系统之间的语义差距。它采用基于学习的向量量化方法分配有意义的项目索引,使语言模型能够直接从未定义候选项目集中生成项目。其他框架进一步扩展了这些想法。例如,ColaRec [125] 在统一的序列到序列生成框架中结合内容信息和协作信号,而 EAGER 框架 [126] 通过双流生成架构整合行为和语义信息。此外,COBRA 框架 [127] 采用级联方法,在稀疏语义 ID 和密集向量之间交替以捕捉用户-项目交互中的语义洞察和协作信号。OneRec [128] 探索了相关技术,通过大型语言模型生成标记来进一步增强推荐系统,从而突显了该领域中语义标记化的潜力。
5.2 生成范式:基础模型作为推荐生成器
不同于基于特征的范式,生成范式将推荐视为生成任务,提供多样化的推荐以满足用户偏好。具体来说,它将预训练的生成模型转化为强大的端到端推荐系统。FMs 的输入通常包括不同的用户偏好信息,如个人资料描述、行为提示和任务指令,而输出则期望生成合理的推荐。在本节中,我们主要关注如何将 FM 转化为推荐系统,并因此将相关研究工作分为三类:(1) 预训练 FM4RS,(2) 非微调 FM4RecSys,以及 (3) 微调 FM4RecSys,如图 4 所示。
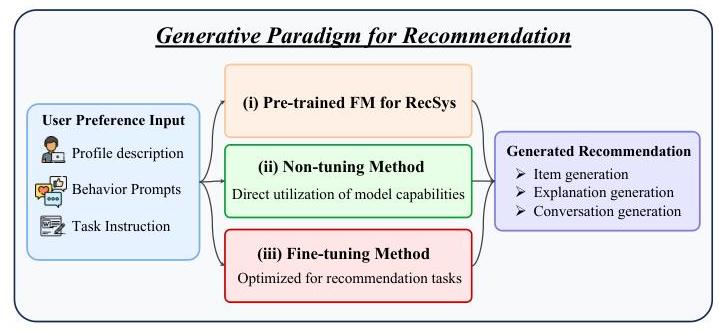
图 4. 推荐生成的生成范式说明。利用用户偏好输入(如个人资料描述、行为提示和任务指令)引导预训练的基础模型(FM)进行 RS。该模型可以通过直接利用其能力或通过特定任务微调以非微调方式使用,产生多种形式的生成推荐,如项目生成、解释生成和对话生成。
预训练 FM4RecSys:少数工作如 M6 Rec [129]、PTUM [130] 和 RecGPT [131] 通过对大规模推荐数据集进行预训练,采用基于 Transformer 的模型进行下一项预测,并应用不同的语言建模任务,如掩码语言建模、排列语言建模等。这条研究路线通常需要大量的领域数据进行 RS,导致高训练成本。
非微调 FM4RecSys:基础模型(FMs)在许多任务上表现出强大的零样本和少样本能力 [43],[132],[133]。因此,近期研究表明 FMs 内在具备推荐能力,并通过使用定制提示激活这些能力,而 FMs 参数保持不变。由于丰富的文本侧信息,使用 LLMs 提示已显示出强大的推荐能力。非微调 FM4RecSys 专注于设计适当的提示以刺激 LLMs 的推荐能力。Liu 等人 [134] 提出了一个提示构建框架,评估 ChatGPT 在五种常见推荐任务上的能力,提供了零样本和少样本版本的每种提示类型。He
等人 [8] 不仅使用提示评估 LLMs 在顺序推荐中的能力,还引入了注重最近性的提示和上下文学习策略以减轻 LLMs 的顺序感知和位置偏差问题。最近,一些工作 [17] 专注于为 FM4RecSys 设计新颖的提示结构。Yao 等人 [135] 包括自然语言中的项目属性启发式提示,以及通过文本模板和知识图谱推理路径呈现的协同过滤信息。同样,Rahdari 等人 [136] 制定了分层提示结构,封装了推荐项目的相关信息和用户交互历史中排名前 k 的相似项目信息。Hou 等人 [8] 利用 LLMs 的零样本和上下文学习能力构建提示,用于顺序电影推荐。然而,仅依赖上下文学习而不进行预训练或微调的 LLMs 在顺序任务上仍落后于传统的监督方法,如 SASRec [137]。主要原因在于 LLMs 对历史交互序列顺序的感知能力有限。随着这些序列长度的增加,LLMs 推荐性能往往会下降。因此,优化 LLMs 的长序列建模能力为提高其在推荐场景中的有效性提供了潜在机会。
微调 FM4RecSys:这一研究方向通常需要大量的领域特定数据来重新训练 FMs,导致额外的计算成本。尽管 FMs 通常表现出强大的零样本和少样本能力,但不难理解,它们可能无法超越针对特定任务的数据专门训练的推荐模型。因此,一种直接的方法是使用任务特定数据对包含世界知识的强大 FMs 进行微调,以完成下游推荐任务。最近,对大型语言模型(LLMs)进行微调以执行推荐任务进行了广泛的探索。TCF [138] 采用并微调 LLMs 来创建推荐任务的通用项目表示,这与日益流行的使用 ChatGPT 的基于提示的方法形成对比。不幸的是,尽管使用了数十亿参数的项目编码器,它仍然需要重新适应新数据以实现最佳推荐。此外,这种类型的模型尚未展示出预期的强迁移能力,表明构建大规模基础推荐模型可能比 CV 和 NLP 领域更具挑战性。InstructRec [139] 设计了丰富的指令进行微调,包括带有偏好、意图、任务形式和用户上下文的 39 个手动设计模板。经过指令微调后,LLMs 可以理解和遵循不同的推荐指令。TallRec [140] 使用 LoRA [141],一种参数高效的微调方法,处理 LLMs 的两阶段微调。首先在 Alpaca [142] 的一般数据上进行微调,然后进一步利用用户的历史信息进行微调。它以项目标题作为输入,对冷启动推荐有效。BIGRec [143] 强调 LLMs 难以整合诸如流行度和协同过滤之类的统计数据,因为它们存在固有的语义偏差。为了解决这个问题,BIGRec 通过指令微调 LLMs 来生成象征项目的标记。然而,将 LLM 输出与现实世界的项目对齐具有挑战性。随后,BIGRec 将这些生成的标记与推荐数据库中的实际项目对齐,通过结合诸如项目流行度之类的统计数据。DEALRec [144] 引入了一种数据修剪方法,采用两个分数:影响分数,通过一个小替代模型估计样本移除对性能的影响;努力分数,优先考虑对 LLMs 具有挑战性的样本。这种方法可以高效地微调 LLMs,从而提高效率和准确性。
同时,扩散模型(DMs)[123],[145] 是另一种最近开始应用于定制不同用户最佳视觉推荐内容的生成基础模型。考虑到用户潜在的偏好,基于历史和上下文信息,以及内容的视觉连贯性和相关性并不容易。视觉基础模型的出现,特别是 Stable Diffusion [145],为自动化甚至个性化物品展示内容生成提供了有希望的方向。DiFashion [146] 不仅可以生成互补时尚物品,还可以根据用户偏好从头生成个性化服装图像。该模型通过微调最新的 Stable Diffusion 模型确保生成的时尚图像具有高保真度、兼容性和个性化。AdBooster [147] 引入了生成创意优化任务,并利用 Stable Diffusion 的外画技术通过用户兴趣信号个性化广告创意生成。后续工作 CG4CTR [148] 通过引入新的自动化创意生成方法进一步改进解决方案,以优化点击率(CTR)优化管道。具体而言,它使用 Stable Diffusion 的修复模式生成背景图像,同时保留主要产品细节。最近,DynaPIG [149] 利用扩散模型生成视觉吸引人的个性化产品图像,增强了用户参与推荐的效果。然而,由于扩散模型主要设计用于视觉任务,它们并不天然适合项目推荐。许多最近的扩散模型工作 [150]-[153] 倾向于从零开始训练生成推荐器以应对特定领域的任务。尽管取得了这些进展,有效地整合扩散模型的优势与更广泛的推荐框架之间仍存在显著差距。为了弥补这一差距,研究人员已经开始探索基础模型不仅作为生成模型,而且作为自主系统核心组件的可能性,从而实现更加动态和互动的推荐体验。
5.3 代理范式:基础模型作为交互式推荐代理
在 FM 驱动的自主代理系统中,FMs 作为代理的大脑,辅以关键组件如规划、记忆和工具使用 [154]。有许多鼓舞人心的工作,如 AutoGPT 和 BabyAGI 证明了基于 FM 的代理的潜力。这些代理可以存储过去的经历并为未来的行为做出更好的决策。在 RS 场景中,代理通常表现为用户模拟器或推荐系统本身,如图 5 所示。
代理作为用户模拟器:此范式使用代理来模拟真实世界的推荐用户行为。收集足够的高质量用户行为数据既昂贵又在伦理上有复杂性。此外,真实世界的用户交互数据通常非常稀疏,例如对于冷启动用户的情况。此外,传统方法 [155],[156] 由于模型的能力限制,在模拟复杂的用户行为方面往往面临挑战,而 FMs 已经展示了在这个领域的潜力 [157]。因此,使用由 FMs 赋能的个性化代理来解决 RS 问题成为一种合理且有效的策略。Wang 等人 [157] 将每个用户视为在虚拟模拟器 RecAgent 中的 FM 基础自主代理。该模拟器允许不同代理自由交互、行为和进化,考虑不仅 RS 中的动作(如浏览和点击项目),还包括外部因素如社交互动。Zhang 等人 [158] 进一步研究了 FM 赋能的生成代理是否能准确模拟真实人类行为以进行电影推荐。他们设计了 Agent4Rec,这是一个推荐系统模拟器,拥有 1,000 个 LLM 赋能的生成代理,以逐页的方式与个性化的电影推荐进行各种动作。特别地,Shi 等人 [159] 提出了一个双层可学习 LLM 规划框架(BiLLP),通过结合高层次规划的宏学习和个性化行动的微学习来平衡短期和长期用户满意度。该框架展示了在长期推荐规划中解决问题的巨大潜力。之后,[160] 将用户和项目都视为代理,并启用了一个优化代理间交互的协作学习过程。最近,Zhang 等人 [161] 提出了 USimAgent,它可以利用 LLMs 模拟用户在搜索会话中的查询、点击和停止行为,从而为特定搜索任务生成完整的搜索会话。BASES [162] 利用基于 LLM 的代理进行大规模网络搜索用户模拟,生成多样的用户配置文件和搜索行为。它通过中文和英文基准测试显示了有效性。同时,Huang 等人 [163] 提出了 LLM Interaction Simulator(LLM-InS),根据内容特征模拟用户行为模式。这种方法将冷门项目转化为热门项目,解决了因缺乏历史用户交互而导致的冷门项目推荐难题。具体而言,LLM-InS 模拟器本质上是一个点击率(CTR)模型。它以特定用户和特定项目的相关信息为输入,并预测用户是否会点击该项目。对于冷启动项目,召回一小部分用户,并预测这些用户是否会点击冷启动项目,从而生成交互数据。然后使用这些模拟的交互数据更新项目嵌入。
代理作为 RecSys:此范式利用了 FMs 的强大能力,包括推理、反思和工具使用来进行推荐。RAH [164] 通过结合 FM 基础代理和 Learn-Act-Critic 循环提高了与用户性格的一致性并缓解了偏差。然后,Wang 等人 [165] 首次引入了一种自我激励规划算法,
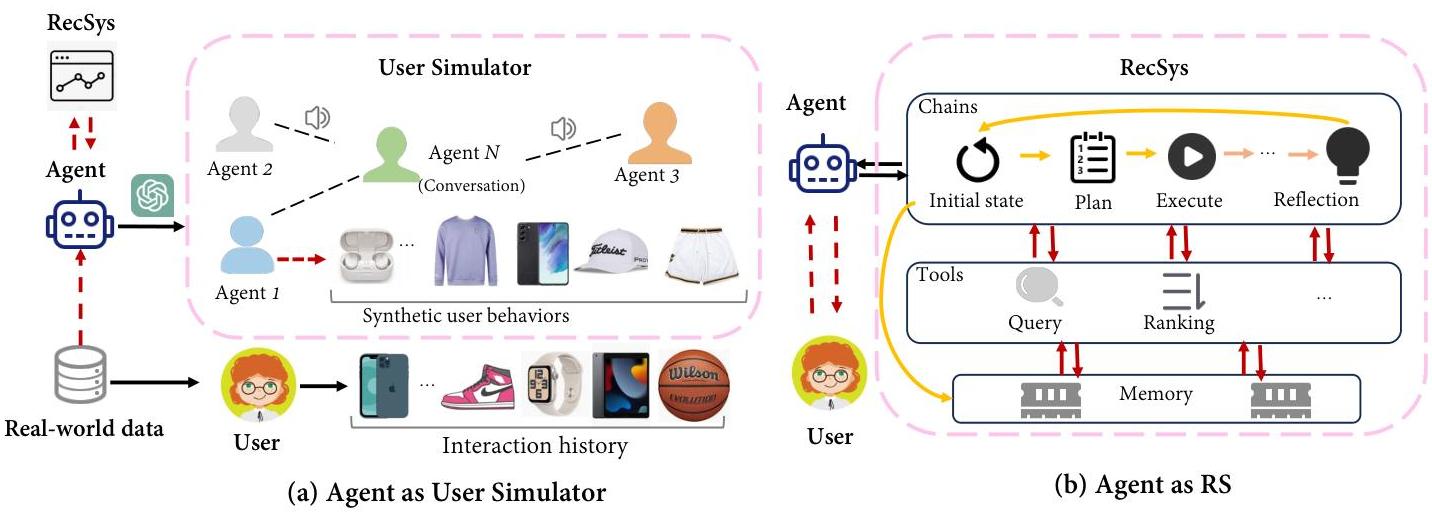
图 5. FM4RecSys 中的两种个性化代理类型:(a) 代理作为用户模拟器和 (b) 代理作为推荐系统。
跟踪所有过去的步骤以帮助生成新状态。在每一步中,代理回顾之前所采取的所有路径,以确定下一步要做什么。这种方法有助于使用数据库、搜索引擎和摘要工具,结合用户数据,生成定制推荐。InteRecAgent [166] 将 FMs 视为大脑,推荐模型作为提供领域特定知识的工具,使 FMs 能够解析用户意图并生成响应。他们指定了 RS 任务所需的核心工具集,包括信息查询、项目检索和项目排名,并引入了候选记忆总线,允许之前的工具访问和修改项目候选池。
代理既作为模拟器又作为 RecSys:最近,为了填补推荐系统中多代理协作的空白,Wang 等人 [167] 引入了 MACRec,这是一个通过管理专家代理(如管理者、用户/项目分析员、反思者、搜索者和任务解释者)的协作来增强推荐任务的框架。MACRec 可以应用于各种任务,包括评分预测、顺序推荐、对话推荐和解释生成,通过多种代理的协作应对推荐任务。Cai 等人 [168] 提出了 PUMA 框架,该框架使用记忆系统检索相关的过去用户交互,增强代理将动作与用户偏好对齐的能力。
总结一下,如表 3 所示,模拟导向的工作侧重于使用代理来模拟 RS 中的用户行为和项目特性。这条研究路线旨在增强对用户偏好的理解,但在 RS 中缺乏整合。推荐导向研究的目标是构建一个具有规划和记忆组件的“推荐代理”来应对推荐任务。
| 模型 | 目标 | 单类型代理 | 多类型代理 | 多样化推荐场景 | 开源 |
|---|---|---|---|---|---|
| RecAgent [157] | 用户模拟 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ||
| Agent4Rec [158] | 用户模拟 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ||
| LLM-Ins [163] | 用户模拟 | ✓ \checkmark ✓ | |||
| PMG [169] | 用户模拟 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ||
| BiLLP [159] | 用户模拟 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ||
| BASES [162] | 用户模拟 | ✓ \checkmark ✓ | |||
| USimAgent [161] | 用户模拟 | ✓ \checkmark ✓ | |||
| AgentCF [160] | U-I 交互模拟 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ||
| WebAgent [168] | U-I 交互模拟 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | |
| RAH [164] | 推荐 | ✓ \checkmark ✓ | |||
| RecMind [165] | 推荐 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ||
| InteRecAgent [166] | 推荐 | ✓ \checkmark ✓ | |||
| MACRec [167] | 推荐 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
表格 3
用于 RecSys 的基础模型代理比较。请注意,单类型代理表示所有代理担任相同角色(例如用户),而多类型代理指代理具有多个角色和能力(例如管理者、反思者)。
5.4 关键分析
基于特征的 RecSys:在基于特征的框架中,基础模型主要用于生成高质量的嵌入以改进用户和
项目表示。这种方法得益于利用大量的预训练知识,提高了表示质量和在 Top-N 推荐和顺序推荐等任务中的排序效果。然而,一个关键缺陷是这些模型起辅助作用,并且很大程度上与核心推荐决策过程脱钩。这种分离限制了系统动态适应上下文变化或用户特定反馈的能力。此外,使用大规模基础模型进行嵌入提取所带来的计算开销在实际场景中可能成为一个问题。尽管模块化和易于集成使得基于特征的方法在增强现有系统时具有吸引力,但其有限的推理和交互能力限制了其在更复杂、动态环境中的应用。
生成式的 RecSys:生成式框架通过将推荐转化为端到端的自然语言生成问题重新定义了推荐。这种方法利用了基础模型天生能够生成个性化推荐、自然语言解释甚至新项目的能力,在零样本或少样本设置中证明是有益的。尽管前景广阔,生成式范式在输出可控性和与用户意图的一致性方面面临着重大挑战。模型对流畅性的重视有时会导致推荐不够精确或相关(例如 OOV 问题:生成的项目超出了词汇范围),并且生成内容的定性性质使得使用标准排序指标评估性能变得困难。此外,生成方法中的训练和推理过程往往资源密集,从而引发了对实际应用中延迟和可扩展性的担忧。因此,虽然生成方法在个性化和解释方面提供了创新途径,但必须解决输出质量控制和计算成本方面的挑战,以确保其在实际推荐系统中的可行性。
代理式的 RecSys:代理框架将推荐系统视为一个能够进行交互式决策、记忆保留和实时计划的自主代理。这种范式通过多轮对话、纳入反馈,甚至利用外部工具来细化推荐,承诺带来重大进步。然而,其复杂性带来了显著挑战。将记忆和计划组件集成进来,虽然理论上能够实现动态适应,但也引入了关于可扩展性和实时性能的问题。自主决策的不可预测性可能导致推荐质量的不一致,而在维持长期用户满意度的同时保持即时响应是一个非平凡的问题。此外,较高的计算负担和设计稳健评估方法的困难也是值得注意的障碍。尽管如此,代理方法对于创造更接近人类推理和决策的个性化体验尤其有前途。
比较讨论
- 基于特征的框架:在简单性和生成高质量语义嵌入方面表现突出,但在动态适应能力和交互推理方面有所欠缺。
-
- 基于生成的框架:提供个性化和上下文丰富的输出,但在输出可控性方面遇到困难,并涉及高昂的计算成本。
-
- 基于代理的框架:提供先进的交互能力和实时适应能力,但由于复杂性和可扩展性问题受到限制。
6 FM4RecSys - 任务
在本节中,我们首先回顾主要推荐任务的一般公式,包括 Top-N 推荐、顺序推荐、对话推荐和跨域推荐,随后介绍 FM4RecSys 的最新进展。
6.1 Top-N 推荐
Top-N 推荐任务旨在为用户生成最相关的项目的排名列表,通常代表基于用户偏好的最合适的 Top-N 项目 [217]。然而,如果用户信息(包括元信息和项目交互历史)过于冗长,可能会超出基础模型的输入长度容量。为了解决这个问题,一种方法是利用基于特征的范式,使用基础模型的嵌入代替传统的用户和项目嵌入以执行 Top-N 推荐 [4],[207]。然而,这种方法的局限性在于它常常忽略了丰富的上下文语义,并缺乏生成能力以推广到未见过的用户或项目。另一种方法是基础模型使用只包含用户信息的提示,要求基础模型直接为这些用户生成推荐 [93],[212]。在多模态和生成表示方法的情况下,生成的推荐项目可以通过与排名候选者的多模态表示进行相似性计算 [215]。此外,一些方法 [213],[214] 遵循 NLP 领域的做法。它们选择 K 个负样本或困难样例,并将它们与用户提示一起输入到 FMs 中,获得最终排名。然而,这些方法针对理想化的实验场景,可能不适用于具有数百万项目的实际推荐系统。最近,Llama4Rec [216] 框架通过数据和提示增强策略以及自适应聚合模块协同整合 ID 和文本表示,从而显著提升了推荐性能。
6.2 顺序推荐
提出了各种基于 FM 的方法来利用其在上下文感知推荐中的能力。不仅 FM 中广泛的世界知识可以用作项目的丰富背景信息来源 [207],而且 FM 的推理能力可以增强对下一个项目的预测 [107],[208]。Jesse 等人 [207] 首先探讨了三种利用基础模型知识的方法来进行上下文感知推荐,基于 FM 语义相似性、
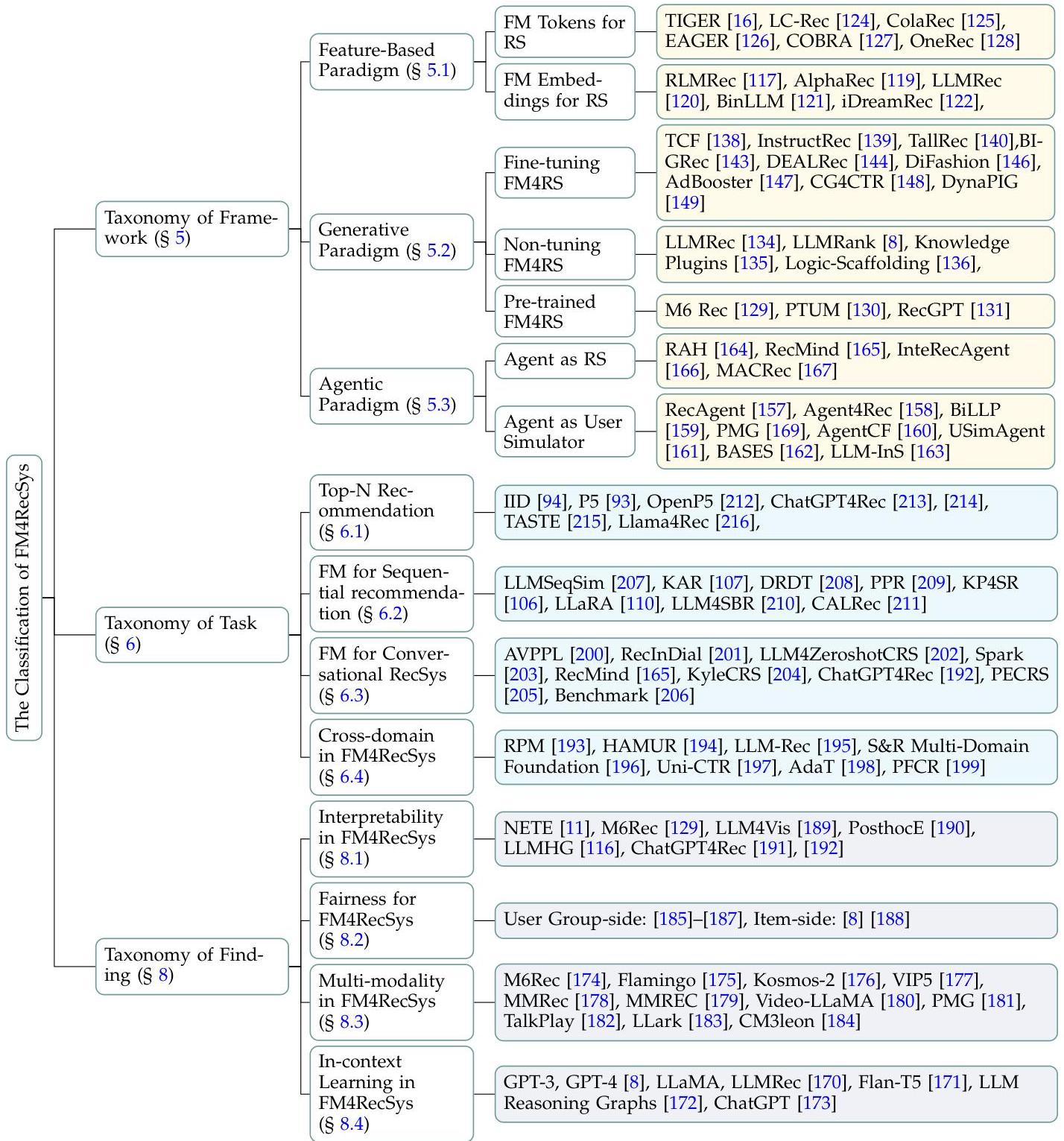
图 6. 基础模型(FM)用于推荐系统(FM4RecSys)的分类。与以往的综述相比,我们的方法引入了一个独特的视角,从数据特征到开放问题和机会来考察 FM4RecSys 的交叉点,详见第 1.3 节。
FM 提示微调、BERT4Rec 初始化为 FM 语义嵌入。之后,Artun 等人 [218] 提出了三种正交方法:LLMSeqSim、LLMSeqPrompt 和 LLM2Sequential,用于利用 FMs 进行顺序推荐,同时还提出了基于项目流行度和会话上下文结合它们优势的混合策略。在多个数据集上的广泛实验证明,LLM 增强模型显著改善了
准确性、多样性和覆盖率,其中微调后的 GPT3.5 在下一项目预测任务中明显优于 PaLM 2。Wu 等人 [209] 使用用户配置文件知识生成个性化软提示,并采用提示导向的对比学习进行有效训练。之后,Zhai 等人 [106] 引入了知识提示调整方法,用于顺序推荐,该方法有效整合了外部知识库与 FMs,将结构化知识转化为提示以通过弥合语义差距和减少噪声来改进推荐。与此同时,Liao 等人 [110] 采用混合方法在输入提示中表示项目,结合传统推荐器的基于 ID 的项目嵌入和文本项目特征,通过适配器弥合传统推荐系统和 FMs 之间的模态差距,并促进用户行为知识向 FM 输入空间的转移。LLM4SBR [210] 框架将会话数据转化为文本和行为的双模态形式,利用大型语言模型(LLMs)进行增强推理和对齐。同时,Wang 等人 [208] 利用基础模型(FMs)的推理能力,引入了协作上下文演示检索方法,抽象出高层次用户偏好并减少噪声,无需 FM 微调即可改进推荐过程。最近,Li 等人 [211] 提出了 CALRec,一种对比对齐生成框架,通过数据和提示增强策略及自适应聚合模块将 LLMs 适应于顺序推荐。它采用了两阶段微调:首先是在多域数据上使用对比损失和语言建模损失的双塔设置;然后在目标域上进行微调。然而,CALRec 在冷启动场景中表现不佳,通常生成从训练中学到的项目描述。
6.3 对话推荐
对话推荐的目标不仅是通过多轮交互向用户推荐项目,还要提供类似人类的响应以实现偏好细化、知识讨论或推荐理由解释 [219],[220]。FMs 的出现无疑对对话推荐系统,尤其是 CRS 相关研究产生了影响。He 等人 [202] 提供了实证证据,表明即使没有微调,FMs 在零样本设置中也能超越现有的对话推荐模型。之后,一系列工作 [165],[192],[203],[204] 采用角色扮演提示引导 ChatGPT/GPT-4 模拟与对话推荐代理的用户交互。这些工作通过 RAG 和链式思维(CoT)等技术增强了 FMs 的能力。同时,一些研究建立在知识图谱对话推荐的前期工作 [221] 上。例如,Wang 等人 [201] 引入了一个框架,将预训练语言模型(如 DialoGPT)与知识图谱相结合生成对话并推荐项目,展示了 FM 的生成能力如何用于对话推荐。Zhang 等人 [200] 探索了一种以用户为中心的方法,强调通过基于图的推理和强化学习使 FMs 适应用户的不断变化的偏好。然而,大多数方法依赖于外部知识图谱,需要额外的数据标注,并可能遭受训练效率低下和语义错位问题。相比之下,Mathieu 等人 [205] 提出了 PECRS,一种统一且参数高效的对话推荐系统(CRS)。PECRS 将 CRS 视为自然语言处理任务,直接利用一个预训练 FM 来编码项目、理解用户意图、进行项目推荐和生成对话。最近,Wang 等人 [206] 批评了当前对话 RS 的评估
协议并引入了一种基于 FM 的用户模拟方法 iEvaLM,显著提高了评估的准确性和可解释性。然而,FMs 在对话推荐中仍然受到流行度偏差和对地理区域敏感性的影响 [222]。同时,在多轮对话推荐中,确定人类-RS 交互过程中状态转换的适当时机是一个重要挑战。例如,在某个时刻决定是继续与用户对话还是进行推荐至关重要。一个需要解决的关键问题是如何有效利用 FM 构建状态检查器以处理这些决策。
6.4 跨域推荐
在现实场景中,数据稀疏性是协同过滤(CF)推荐系统的一个普遍问题,因为用户很少对广泛的项目进行评分或评论,尤其是新项目。跨域推荐(CDR)通过利用来自知情源域的大量数据来增强目标域中的推荐,解决了这一问题。多域推荐(MDR)通过利用多个域中的辅助信息来推荐特定用户在这些域中的项目 [223]。然而,域冲突仍然是一个重要障碍,可能限制推荐的有效性。预训练于各种领域大量数据的基础模型的出现及其跨域类比推理能力 [193] 提供了应对这些挑战的有希望的解决方案。
HAMUR [194] 设计了一个特定于域的适配器以集成到现有模型中,并设计了一个共享的超网络动态生成适配器参数,以解决以前模型中的相互干扰和缺乏适应性问题。Tang 等人 [195] 讨论了 FMs 在多域推荐系统中的应用,通过混合不同域的用户行为、将项目标题信息串联成句子以及使用预训练语言模型建模用户行为,展示了其在多样化数据集上的有效性。S&R(搜索与推荐)多域 FM [196] 利用 FMs 改进查询和项目文本特征,从而在新用户或项目场景中提高 CTR 预测。KAR [107] 进一步利用 FMs 的开放世界推理和事实知识提取能力,并引入了全面的三阶段流程,涵盖知识、推理和生成、适应以及后续利用。基于 S&R 多域 FM,Uni-CTR [197] 使用独特的提示策略将特征转化为 FM 可使用的提示序列,以捕捉不同域间的共性并通过特定于域的网络学习域特定特征。最近,Fu 等人 [198] 探讨了适配器学习在 CDR 中的有效性,该方法旨在利用原始项目模态特征(如文本和图像)进行推荐。他们进行了实证研究以基准现有的适配器,并检查影响其性能的关键因素。然而,值得一提的是,CDR 在现有 FM4RecSys 方法中面临域隐私泄露和无效知识迁移的挑战。为了解决这些问题,Guo 等人 [199] 提出了 PFCR 框架,该框架引入了一种使用本地客户端交互和梯度加密的隐私保护联合学习方案。该框架通过描述文本建模项目,在通用特征空间中,并通过提示微调策略利用联合内容表示。
6.5 项目和内容生成以进行推荐
FM 在 RS 中的一项前瞻性应用是项目生成——创建可以推荐给用户的全新内容。这超出了传统 RS 的范畴,后者通常从现有项目中选择。然而,通过生成模型,推荐现有项目与生成专为用户定制的新项目之间的界限可能变得模糊。主要任务如下:
捆绑生成:在电子商务中,捆绑推荐对于提高平均订单价值至关重要。BundleGen [224] 引入了一种基于扩散的框架,条件于种子项目和用户偏好生成项目捆绑包。与检索共同购买的项目不同,它通过在项目嵌入空间中进行去噪过程,学习生成一组兼容且风格一致的项目。该模型通过迭代地将随机噪声精炼为有意义的捆绑包,优化了捆绑包内兼容性和个性化。与自回归模型相比,扩散模型在高维项目空间中提供了更好的多样性控制和全局结构控制。
播放列表生成:在音乐推荐中,播放列表生成正从基于启发式的排序转向完全生成范式。最近的工作,如 MusicGen [225],通过对 GPT-2 等预训练语言模型进行微调,自回归生成歌曲 ID 序列,条件于用户历史或意图提示(例如“晚上放松爵士乐”)。这些模型将播放列表生成视为一个语言建模任务,灵活地融入用户意图、进行项目推荐和生成对话。最近,Wang 等人 [208] 利用基础模型(FMs)的推理能力,引入了一种协作上下文演示检索方法,抽象出高层次用户偏好并减少噪声,从而在不需要 FM 微调的情况下改进推荐过程。更近一步,Li 等人 [211] 提出了 CALRec,一种对比对齐生成框架,用于将 LLMs 适应到顺序推荐。它采用了两阶段微调:首先是一个双塔设置,结合对比损失和语言建模损失在多域数据上;然后在目标域上进行微调。然而,CALRec 在冷启动场景中表现不佳,经常生成从训练中记忆的项目描述。
6.6 讨论
在本节中,我们分析了三种集成框架对各种推荐任务的适用性。通过比较基于特征、生成和代理范式的内在能力,我们可以识别出最适合每种任务的框架以及可能有益的混合方法的位置。
对于 Top-N 推荐任务,主要涉及基于用户偏好的排名和匹配,基于特征的框架具有明显优势。这种方法专注于提取高质量的嵌入,捕捉语义相似性,从而实现高效和准确的排名。尽管生成方法也可以在零样本或少样本设置中运行,但它们通常面临输出可控性问题,而当任务不需要动态交互或多轮反馈时,代理系统往往会引入不必要的复杂性。
对于顺序推荐,目标是建模用户随时间的行为并捕捉偏好的演变本质。基于特征的方法通过学习顺序数据中的潜在模式,在这个领域仍然有效。然而,代理框架通过整合记忆和计划能力展现了前景,能够更好地处理长期依赖并适应用户行为的变化。生成方法可能通过链式思维提示等技术贡献于顺序建模,但通常面临保持交互自然顺序的挑战。对于对话推荐,这本质上依赖于多轮对话和情境感知交互,生成和代理范式均表现出色。生成模型的自然语言生成能力使其能够生成个性化和上下文丰富的响应,而代理系统通过动态管理交互、纳入反馈和在整个对话过程中调整推荐增添了价值。此任务
从这两种方法的结合中受益最大,其中对话流畅性和交互推理是关键。跨域推荐任务需要系统能够在不同数据源和领域中泛化。在这里,基于特征的框架在利用多模态嵌入捕捉不同领域之间的语义相似性时特别有效。生成方法可以通过生成上下文连接来桥接数据稀疏性,尽管它们可能缺乏可靠的领域迁移所需的连贯性。代理框架可以通过动态整合外部数据进一步完善跨域推荐,但除非需要适应性实时调整,否则其附加复杂性可能并非必要。最后,对于项目/内容生成,需要生成新的内容如项目描述、图像或创造性输出,生成框架天生最为合适。其优势在于能够直接生成新颖、高质量的内容。代理方法可能通过迭代计划和反馈纳入来补充此任务,但核心生成任务最好由擅长灵活、创造性输出的方法处理。
比较讨论
- Top-N 推荐:由于稳健的嵌入提取和高效的排名,基于特征的方法最为合适;生成和代理框架增加了复杂性,可能对静态排名任务没有必要。
-
- 顺序/对话推荐:顺序任务可以利用基于特征和代理方法捕捉时间依赖性,而对话任务则从生成模型的自然语言生成中大大获益,代理系统增强了交互适应性。
-
- 跨域和项目生成:基于特征的方法在跨域任务中通过提供跨域的语义对齐具有优势,而项目/内容生成则与生成模型最为契合,可能通过代理反馈循环进行实时完善。
7 FM4RecSys 展示:顺序推荐的 FM 实证比较
如表 4 所示,我们对多个顺序推荐数据集上的代表性 FM4RecSys 框架进行了全面的实证研究。总体而言,基于特征的模型在标准基准测试中保持强劲表现,得益于明确的特征工程和历史交互的有效建模。例如,HyperGraph-LLM 和 ReAT 模型在 Beauty、Toys 和 Sports 数据集上持续取得有竞争力的结果。基于生成的模型进一步展示了优越的表现,特别是在用户行为信号稀疏或语义信息丰富的复杂数据集上(如 Yelp、MIND、GoodRead)。POD 和 GenRec 等模型利用强大的语言模型(LMs)作为行为生成器,在多个数据集上实现了最先进的 NDCG@5 分数,突显了它们捕捉复杂用户偏好模式的能力。由于大多数代理方法采用无训练策略,这表明它们在处理交互式和个性化推荐场景方面具有潜力。
此实证比较揭示了几种趋势:(i) 特征模型在结构化推荐任务中仍然是强有力的基线;(ii) 生成模型在多样化的推荐环境中提供了更大的灵活性和泛化能力;(iii) 代理模型为交互式和自主推荐系统开辟了新的研究方向。这些发现为未来 FM4RecSys 模型的发展提供了实用指导,并激励了统一不同 FM 家族优势的混合范式的进一步探索。
8 FM4RecSys:探索的机会和发现
正如上述讨论,FMs 的出现为推进 RS 开辟了前所未有的机会,从根本上重塑了用户偏好和行为的建模、预测和交互方式。然而,将这些强大模型集成到 RS 场景中也带来了需要在多个维度上进行创新解决方案的新挑战。本节概述了旨在提升 FM 时代 RS 能力的关键研究方向和最新进展。我们重点介绍了动态时间推断、多模态代理智能、检索增强生成(RAG)、可解释性、终身个性化以及系统级别的效率和可扩展性。这些新兴领域共同为构建更能适应、可靠并满足复杂现实环境中不断变化的用户需求的 RS 提供了全面路线图。
8.1 解释和解释
增强推荐系统可解释性的一个常见任务是生成自然语言解释 [243]。这涉及到引导推荐系统或外部模型生成一段话或段落,说明为什么向特定用户推荐某项特定项目。例如,给定用户 u u u 和项目 i i i,模型的任务是生成一个连贯且可理解的自然语言解释,阐明为什么向用户 u u u 推荐项目 i i i。一系列工作使用基于 ID 的表示,并利用如“向用户 u u u 解释为什么推荐项目 i i i”这样的提示 [11]。然而,仅在提示中使用 ID 可能导致解释模糊,缺乏对推荐的具体方面的清晰度。为了解决这一问题,Cui 等人 [129] 提出将项目特征作为提示中的提示词整合进来,旨在更有效地引导模型的解释过程。同时,Wang 等人 [189] 引入了 LLM4Vis,这是一种基于 ChatGPT 的可视化推荐方法,利用上下文学习生成可视化和类似人类的解释,避免了传统方法需要大量示例数据集的需求。Ngoc 等人 [190] 结合了
| 参考文献 | 框架 | 主干网络 | 负样本数 | 数据集 NDCG@5 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Beauty | Toys | Sports | Games | CDs | Office | Yelp | MIND | GoodRead | ||||
| SARSRec [137] | - | Transformer | 0 | 0.0249 | 0.0306 | 0.0154 | 0.0365 | - | - | 0.0100 | - | - |
| BertRec [230] | - | Bert | 0 | 0.0124 | 0.0071 | 0.0075 | 0.0311 | - | - | 0.0033 | - | - |
| P5 [93] | 基于特征 | T5 | 0 | 0.0107 | 0.0050 | 0.0041 | - | - | - | - | - | - |
| TIGER [16] | 基于特征/生成 | T5 | 0 | 0.0321 | 0.0371 | 0.0181 | - | - | - | - | - | - |
| LMIndexer [231] | 基于特征 | T5 | 0 | 0.0262 | 0.0268 | 0.0142 | - | - | - | - | - | - |
| HyperGraph-LLM [232] | 基于特征 | GPT-4 | 0 | 0.0376 | 0.0379 | - | - | - | - | - | - | - |
| ReAT [233] | 基于特征 | T5 | 99 | 0.0382 | 0.0390 | 0.0188 | - | - | - | - | - | - |
| LC-Rec [124] | 基于特征/生成 | GPT-3.5 | 随机 | - | - | - | 0.0560 | - | - | - | - | - |
| ONCE [234] | 基于特征 | GPT-3.5 | 4 | - | - | - | - | - | - | - | 0.3872 | 0.7196 |
| EmbSum [235] | 基于特征 | T5 | 4 | - | - | - | - | - | - | - | 0.3675 | 0.5486 |
| LLMHD [236] | 基于特征 | GPT-3.5 | - | - | - | - | - | - | - | 0.0542 | - | - |
| KDA [237] | 基于特征 | GPT-3 | 99 | - | - | - | - | - | 0.3403 | - | - | - |
| POD [238] | 生成 | T5 | 99 | 0.0395 | 0.0599 | 0.0396 | - | - | - | - | - | - |
| GenRec [239] | 生成 | T5 | 0 | 0.0397 | - | 0.0332 | - | - | - | 0.0475 | - | - |
| BIGRec [240] | 生成 | Llama | - | - | - | - | 0.0189 | - | - | - | - | - |
| RDRec [241] | 生成 | T5 | 99 | 0.0461 | 0.0593 | 0.0408 | - | - | - | - | - | - |
| RecGPT [242] | 生成 | GPT-1 | 0 | 0.0143 | 0.0355 | 0.0408 | - | - | - | - | 0.0107 | - |
| RecMind [165] | 代理 | GPT-3.5 | 99 | 0.0289 | - | - | - | - | - | 0.0342 | - | - |
| AgentCF [160] | 代理 | GPT-3.5 | 9 | - | - | - | - | 0.4373 | 0.3589 | - | - | - |
表 4
在多个数据集上的不同 FM4RecSys 框架在顺序推荐任务上的性能比较。N@5 表示 NDCG@5,NS 表示负样本数量。缺失值以 ‘-’ 表示。
| 嵌入式和语义模型结合生成事后解释,利用基于本体的知识图谱来增强可解释性和用户信任。然后,Chu 等人 [116] 将 FMs 的推理能力和 HNNs(超图神经网络)的结构优势结合起来,更好地捕捉和解释个别用户的兴趣。最近,Liu 等人 [191] 利用连续提示向量而非离散提示模板。值得注意的是,发现 ChatGPT 在没有微调的情况下通过上下文学习超越了几种传统的监督方法 [192]。
8.2 FM4RecSys 的公平性
RS 中公平性的紧迫性源于其在决策和满足用户需求中的广泛应用。然而,目前对 RS 中 FMs 所表现的公平性程度以及应对这些模型中不同用户和项目组需求的合适方法尚缺乏理解 [185],[186]。对于用户群体方面,Hua 等人 [185] 提出了基于反事实公平提示技术(CFP)的无偏基础模型用于公平感知推荐(UP5)。之后,Zhang 等人 [186] 构建了衡量两种推荐场景中不同敏感属性的指标和数据集:音乐和电影,并评估了 ChatGPT 在涉及用户侧各种敏感属性时 RS 的公平性。最近,Deldjoo 等人 [187] 提出了 CFaiRLLM,这是一个全面的评估框架,旨在检查和减轻基于 LLM 的 RS 中的偏差,研究推荐结果如何因包含性别和年龄等敏感属性而变化,强调了不同用户画像采样策略对公平结果的影响。然而,他们仅关注年龄和性别,建议未来的研究考虑更广泛的敏感属性,并验证该框架在不同领域的适用性。
对于项目方面,Hou 等人 [8] 使用提示引导 FMs 将推荐任务形式化为条件排名任务以改善项目侧的公平性。此外,Jiang 等人 [188] 研究了历史用户交互和 FMs 内在语义偏差对推荐系统的影响,并引入了一个名为 IFairLRS 的框架,该框架适应传统公平方法以在 FM4RecSys 中提升项目侧公平性而不损害推荐准确性。关于非歧视性和公平性的研究在 FM4RecSys 中仍处于早期阶段,表明需要进一步调查。
8.3 多模态推荐系统
近年来,能够联合处理和理解多种模态的 MFMs 迅速发展。这些基础模型通过启用增强的内容理解和生成能力,在推荐领域开辟了新的前沿。多模态推荐的关键方面是模态融合,结合来自文本(如项目描述)、图像(如产品照片)、音频(如音乐或语音)和视频的信号,以丰富用户和项目的表示。像 M6-Rec [174] 这样的模型通过将多模态输入转化为文本格式,并应用大型 Transformer 模型进行推理和生成,统一了推荐任务(检索、排名、解释、内容创作)。同样,Flamingo [175] 和 Kosmos-2 [176] 采用跨注意力机制,使语言模型能够关注视觉嵌入,从而实现基于视觉情境的少量样本推理。在时尚或家居装饰等领域,加入图像特征已被证明可以显著提高项目匹配和排名质量,尤其是在冷启动场景中 [177]。像 MMRec [178] 和 MMREC [179] 这样的框架支持将预训练的视觉和文本编码器集成到推荐管道中,提供灵活的早期融合、协同训练和混合模型架构。在视频领域,像 VideoLLaMA [180] 这样的模型代表了将视觉帧、音频轨道和文本转录整合到大型语言模型中以实现基于内容的视频推荐和字幕生成的最新突破。这些进展突显了利用原始多模态内容的趋势,而不是仅仅依赖稀疏交互数据或元数据。除了理解现有内容外,多模态基础模型还实现了个性化内容生成,有效模糊了推荐与创作之间的界限。在电子商务中,像 M6-Rec [174] 和 PMG [181] 这样的系统可以根据从交互历史中推断出的用户偏好,从头生成个性化的商品图片或时尚风格。在音乐领域,像 TalkPlay [182] 和 LLark [183] 这样的模型可以直接从音频输入生成文本解释或音乐标签,实现具有更好情境理解的对话式推荐接口和播放列表生成。这种生成能力由 CM3leon [184] 等模型支持,它在解码器仅模型中整合了文本到图像和图像到文本生成,并由检索增强模型动态获取相关内容片段以调节输出生成。这些架构开启了个性化广告、播放列表封面艺术、视频摘要,甚至是针对每个用户的 AI 创建推荐项等使用案例。
该领域进一步的发展将涉及改进多模态基础模型在实时推荐中的效率和可扩展性,开发更稳健的生成推荐质量评估协议,并增强个性化策略以更好地使多模态生成与个体用户意图对齐。随着这些系统的不断成熟,它们预计将支持更智能、自适应和吸引人的推荐体验,统一内容理解和创作。
8.4 上下文学习能力
上下文学习是现代 FMs 的一个标志,指的是在不更新参数的情况下通过包含任务描述和示例的提示来执行任务的能力。在 RS 中,这种能力通过零样本、少样本和基于推理的方法表现出来,允许 LLMs 在通常无需明确监督训练的情况下生成相关的项目建议。近期的工作表明,这一范式为灵活、领域无关和用户友好的推荐开辟了新途径。
零样本和少样本推荐:像 GPT-3、GPT-4 和 LLaMA 这样的 LLMs 在零样本和少样本推荐场景中表现出显著性能。研究人员将下一项预测和 Top-N 推荐公式化为语言建模任务,通过用户历史、候选项目和基于指令的查询提示 LLMs。Hou 等人 [8] 表明,当适当提示时,GPT4 可以作为一个零样本排序器,在基准数据集上表现出有竞争力的排序准确性。同样,Wang 等人 [244] 展示了一个结构化的三步提示可以使 GPT-3 在 MovieLens 上超越一些传统的顺序模型。少样本策略通过在少量注释推荐示例上调节模型进一步增强了性能。像 LLMRec [170] 这样的基准测试显示,尽管 LLMs 在原始推荐指标上比专门模型表现差,但在解释生成和偏好总结方面表现出色——展示了它们整合语义和模拟常识推理的能力。
推理和指令遵循:指令跟随型 LLMs 可以根据自由形式的用户描述或复杂目标生成推荐。例如,Zhang 等人 [171] 将推荐重新定义为一个指令跟随任务,其中用户画像和意图用自然语言描述。他们经过微调的 FlanT5 模型不仅生成相关推荐,还能灵活地跨领域适应。同样,LLM Reasoning Graphs [172] 利用 LLMs 生成连接用户兴趣与项目特征的逻辑链,然后用来指导下游推荐者。在对话推荐中,上下文推理使 LLMs 能够迭代处理反馈。Spurlock 等人 [173] 表明 ChatGPT 可以通过重新提示用户反馈来改进其推荐,从而更好地与用户偏好对齐。这展示了 LLMs 在理解细腻的自然语言和通过多轮推理调整推荐方面的双重优势。
上下文学习使 LLMs 成为可适应、可解释且可转移的推荐者。尽管它们在传统指标上的表现可能落后于专门模型,但它们在语义推理、指令遵循和以人为中心的互动方面的优势使其成为下一代推荐系统的强大工具。持续的研究继续探索如何更好地对齐、提示并将 LLMs 集成到更广泛的推荐架构中。
已探索的机会和发现
- FMs 为 RS 提供了更直观的解释。通过整合丰富的项目特征并利用先进的提示技术,这些模型现在生成的自然语言解释不仅澄清了推荐理由,还提升了用户信任和系统透明度。
-
- 新兴框架专注于公平性,指出了缓解用户和项目两侧偏差的有希望方向。尽管初步努力在处理敏感属性方面显示出令人鼓舞的结果,但仍有机会扩大这些技术,确保在多样化应用领域中的公平性能。
-
- 多模态数据和上下文学习的纳入显著增强了推荐系统的个性化能力。这一进展使得表示更加丰富和动态;然而,它也凸显了可扩展性、评估和计算效率方面的紧迫挑战。
9 FM4RecSys:开放挑战和机遇
虽然取得了显著进展,但基础模型驱动的推荐系统领域仍处于早期阶段。许多挑战仍然存在,并伴随着未来研究的激动人心机会。在本节中,我们将概述一些关键的开放问题和潜在方向,分为三大类:
在线部署、增强推荐系统能力、技术可扩展性和效率以及方法论改进。
9.1 在线部署
基础模型,特别是大语言模型(LLMs),通过改进泛化、自然语言理解和多任务统一对推荐系统表现出有希望的能力。然而,在实时、大规模工业环境中部署这些模型引入了重大的工程和系统设计挑战。一些行业领导者已经采取了初步的集成步骤。例如,阿里巴巴的 M6-Rec [174] 已经在其电子商务平台中作为统一的基础模型部署,涵盖了检索、排名和内容生成。它采用参数高效微调(如前缀微调)和缓存策略以满足延迟约束。亚马逊利用 LLMs 通过生成合成元数据 [228] 来增强冷启动效果,而 Spotify 的 LLark [183] 探索了通过 LLMs 实现音乐理解以进行个性化播放列表生成和自然语言标记。尽管取得这些进展,实际部署仍受到几个瓶颈的限制。首先,延迟和吞吐量构成了主要障碍,因为 LLMs 计算密集且通常与在线系统要求的低于 100 毫秒的推理时间不兼容 [245],[246]。提出了混合两阶段架构(检索 + 重排)[247]、早期退出变压器 [248] 和查询缓存 [249] 等技术以缓解这一问题。其次,规模下的内存和成本效率变得至关重要,LoRA、适配器微调 [177] 和蒸馏 [250] 等方法逐渐被采用以减少服务占用空间。第三,个性化与泛化构成了建模挑战,尽管 LLMs 提供了强大的通用知识,但编码用户特定细微差别而不过拟合或增加内存开销并不简单。轻量级用户特定提示或适配器提供了部分解决方案。此外,将 FMs 集成到现有基础设施中涉及兼容性问题,因为生成模型的输出格式和排名分数可能无法与经典的 CTR 基础管道对齐。生产部署还需要稳健的评估协议,因为传统的指标如 NDCG 可能无法捕捉生成个性化带来的全部影响,因此需要 A/B 测试和用户满意度跟踪。最后,围绕可解释性、信任和模型陈旧性的问题依然存在——LLMs 的幻觉可能会误导用户,而大型模型相比标准推荐器嵌入更难定期更新。尽管面临这些挑战,基础模型在推荐部署中继续获得牵引力,混合、延迟感知架构作为一种实用妥协正在出现,以在规模上解锁其潜力。
9.2 增强推荐系统能力
9.2.1 时间序列外推
近期研究表明,FMs 可以以零样本方式外推时间序列数据,其性能与甚至优于针对特定任务训练的专业模型。这一成功很大程度上归功于 FM 的
捕捉多模态分布的能力及其对简洁和重复的倾向,这与时间序列数据中常见的重复和季节性趋势相呼应。时间序列建模与其他序列建模因其可变尺度、采样率和偶尔的数据缺口而有所不同,尚未充分受益于大规模预训练。为此,LLMTIME2 [252] 利用 LLMs 进行连续时间序列预测,通过将时间序列编码为数值字符串并将预测视为下一个标记预测任务。这种方法通过将标记分布转换为连续密度,促进了 LLMs 在时间序列预测中的轻松应用,而无需专业知识或高计算成本,特别适合资源受限场景。此外,通过将用户偏好数据视为时间序列序列,这些模型可能能够适应长期偏好变化,并随着时间的推移增强个性化和预测准确性,尤其是像 LLMTIME2 这样的零样本方法,能够在无需广泛再训练的情况下快速适应用户偏好变化。
9.2.2 多模态代理 AI 在 RecSys 中的应用
多模态代理 AI 是一个新兴领域,探索能够通过统一理解多模态数据感知和行动的 AI 系统。这些系统利用生成模型和多样数据源进行现实无关的训练,并能在物理和虚拟环境中操作。在 RS 领域,这样的代理可以推断用户偏好、适应实时反馈并提供个性化推荐。值得注意的是,它们有潜力作为模拟器——不仅用于系统模拟,还可用于用户行为模拟,从而实现脱机数据收集和训练,降低现实世界 A/B 测试成本。尽管早期工作展示了概念验证应用,如路径规划和医疗推荐,许多能力仍属理想状态。关键开放挑战包括将多模态感知应用于推荐特定任务、确保与真实用户偏好的一致性以及在实际部署场景中扩展交互代理。
9.2.3 RAG 与 RecSys 的结合
检索增强生成(RAG)是一种在 FMs 中通过整合外部数据检索到生成过程来增强其生成能力的技术 [253]。这种方法提高了 FM 输出的准确性和可信度,特别是在知识密集型任务如信息检索和 RS 中。RAG 致力于解决知识过时、错误信息生成(幻觉)和领域专业知识有限的问题,通过结合 FM 的内部知识和动态外部知识库。RAG 特别适合增强 FM4RecSys,特别是在建模现实世界 RS 环境中的终身用户行为序列 [254]。它有可能确保 RS 随着用户偏好和趋势的持续变化保持最新,这对于精确识别和记录长期行为模式至关重要。例如,考虑到 FM 的输入标记长度限制,RAG 可以选择性提取用户交互历史的相关部分及
关联的外部知识,从而符合模型的输入约束。此外,RAG 可能会降低生成不相关推荐或不存在项目(幻觉)的可能性,从而增强 FM4RecSys 的可靠性。
9.2.4 FM4RecSys 的可解释性和可信性
我们简要讨论了 FMs 在 FM4RecSys 上的强大理解和生成能力如何成为一把双刃剑。
从安全性的角度来看,FMs 易受红队攻击的影响,恶意行为者可以通过构造毒化提示来操纵模型生成不良内容。这种内容可以从欺诈性或种族主义材料到虚假信息或不适合年轻观众的内容,可能造成重大社会危害并对用户构成风险 [284],[285]。因此,在 FM4RecSys 中,尤其是在采用对话界面时,使 FMs 与人类价值观对齐变得至关重要。这种对齐涉及收集相关负面数据并采用在线和离线人类偏好训练等监督微调技术 [286],[287]。这些方法可以帮助细化模型,使其更紧密地遵循人类指令
和期望,确保 FM4RecSys 生成的内容安全、可靠且在伦理上合理。
从隐私的角度来看,如果 FMs 直接在大量的敏感用户交互数据上进行训练,第三方可能通过提示注入方法访问特定用户交互历史,从而构建用户画像。在这种意义上,将联邦学习 [288] 和机器遗忘 [289],[290] 等方法融入 FM4RecSys 代表了未来的有希望方向。
10 结论
在本文中,我们对 FM4RecSys 进行了详尽的综述,提供了详细的比较并突出了未来研究路径。我们提出了一种分类方案,用于组织和聚类现有出版物,并讨论了使用基础模型进行推荐任务的优点和缺点。此外,我们详细阐述了一些最紧迫的开放问题和有希望的未来扩展。我们希望本次调查为推荐系统研究社区提供了一个关于基础模型挑战、最新进展、开放问题和机会的概览。
参考文献
[1] F. Ricci, L. Rokach, 和 B. Shapira, “推荐系统:介绍和挑战,” 在《推荐系统手册》中。Springer, 2015, 第 1-34 页。
[2] S. Zhang, L. Yao, A. Sun, 和 Y. Tay, “基于深度学习的推荐系统:综述与新视角,” ACM 计算机调查, 第 52 卷, 第 1 期, 第 5:1-5:38 页, 2019.
[3] C. Li, Z. Gan, Z. Yang, J. Yang, L. Li, L. Wang, J. Gao 等, “多模态基础模型:从专家到通用助手,” 基础趋势和计算机图形学与视觉趋势, 第 16 卷, 第 1-2 期, 第 1-214 页, 2024.
[4] J. Lin, X. Dai, Y. Xi, W. Liu, B. Chen, X. Li, C. Zhu, H. Guo, Y. Yu, R. Tang, 和 W. Zhang, “推荐系统如何受益于大语言模型:综述,” CoRR, 第 abs/2306.05817 卷, 2023.
[5] R. Bommasani, D. A. Hudson, E. Adeli, R. B. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, E. Brynjolfsson, S. Buch, D. Card, R. Castellon, N. S. Chatterji, A. S. Chen, K. Creel, J. Q. Davis, D. Demszky, C. Donahue, M. Doumbouya, E. Durmus, S. Ermon, J. Etchemendy, K. Ethayarajh, L. Fei-Fei, C. Finn, T. Gale, L. Gillespie, K. Goel, N. D. Goodman, S. Grossman, N. Guha, T. Hashimoto, P. Henderson, J. Hewitt, D. E. Ho, J. Hong, K. Hsu, J. Huang, T. Icard, S. Jain, D. Juralsky, P. Kalluri, S. Karamcheti, G. Keeling, F. Khani, O. Khattab, P. W. Koh, M. S. Krass, R. Krishna, R. Kuditipudi 等, “基础模型的机会与风险,” CoRR, 第 abs/2108.07258 卷, 2021.
[6] Y. Gao, T. Sheng, Y. Xiang, Y. Xiong, H. Wang, 和 J. Zhang, “Chat-rec:迈向交互和可解释的大语言模型增强推荐系统,” arXiv preprint arXiv:2303.14524, 2023.
[7] H. Ding, Y. Ma, A. Deeras, Y. Wang, 和 H. Wang, “零样本推荐系统,” CoRR, 第 abs/2105.08318 卷, 2021.
[8] Y. Hou 等人, “大语言模型是推荐系统的零样本排序器,” arXiv preprint arXiv:2402.04521, 2024.
[9] C. Gao, W. Lei, X. He, M. de Rijke, 和 T. Chua, “对话推荐系统中的进展与挑战:综述,” AI Open, 第 2 卷, 第 100-126 页, 2021.
[10] W. Lei, X. He, Y. Miao, Q. Wu, R. Hong, M. Kan, 和 T. Chua, “估计-行动-反思:迈向对话系统和推荐系统之间的深入交互,” 在 WSDM '20:第十三届 ACM 国际网络搜索和数据挖掘会议, Houston, TX, USA. ACM, 2020, 第 304-312 页.
[11] L. Li, Y. Zhang, 和 L. Chen, “为推荐生成神经模板解释,” 在 ACM 第 29 届信息与知识管理国际会议, 虚拟活动, 爱尔兰. ACM, 2020, 第 755-764 页.
[12] J. Sun, C. Zheng, 和其他人, “基础模型推理的综述,” CoRR, 第 abs/2312.11562 卷, 2023.
[13] Y. Wang, Z. Chu, X. Ouyang, S. Wang, H. Hao, Y. Shen, J. Gu, S. Xue, J. Y. Zhang, Q. Cui, L. Li, J. Zhou, 和 S. Li, “通过大语言模型推理图增强推荐系统,” CoRR, 第 abs/2308.10835 卷, 2023.
[14] J. Devlin, M. Chang, K. Lee, 和 K. Toutanova, “BERT:通过语言理解进行双向编码器预训练,” 在 2019 年北美计算语言学协会年会:人类语言技术论文集中, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers). Association for Computational Linguistics, 2019, 第 4171-4186 页.
[15] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, 和 I. Sutskever, “通过自然语言监督学习可迁移的视觉模型,” 在第 38 届国际机器学习会议论文集中, ICML 2021, 18-24 July 2021, Virtual Event, ser. Proceedings of Machine Learning Research, vol. 139. PMLR, 2021, 第 8748-8763 页.
[16] S. Rajput, N. Mehta, A. Singh, R. Hulikal Keshavan, T. Vu, L. Heldt, L. Hong, Y. Tay, V. Tran, J. Samost 等, “带有生成检索的推荐系统,” Advances in Neural Information Processing Systems, 第 36 卷, 第 10:299-10:315 页, 2023.
[17] L. Xu, J. Zhang, B. Li, J. Wang, M. Cai, W. X. Zhao, 和 J. Wen, “为推荐系统提示大语言模型:一个综合框架和实证分析,” CoRR, 第 abs/2401.04997 卷, 2024.
[18] C. Huang, J. Wu, Y. Xia, Z. Yu, R. Wang, T. Yu, R. Zhang, R. A. Rossi, B. Kveton, D. Zhou 等, “多模态大语言模型时代的代理推荐系统展望,” arXiv preprint arXiv:2503.16734, 2025.
[19] Y. Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon 等, “宪法 AI:来自 AI 反馈的无害性, 2022,” arXiv preprint arXiv:2212.08073, 第 8 卷, 第 3 期, 2022.
[20] M. F. A. R. D. T. (FAIR)†, A. Bakhtin, N. Brown, E. Dinan, G. Farina, C. Flaherty, D. Fried, A. Goff, J. Gray, H. Hu 等, “外交游戏的人类水平玩法:通过结合语言模型与战略推理,” Science, 第 378 卷, 第 6624 期, 第 1067-1074 页, 2022.
[21] P. Liu, L. Zhang, 和 J. A. Gulla, “预训练、提示和推荐:推荐系统中语言建模范式的适应综述,” CoRR, 第 abs/2302.03735 卷, 2023.
[22] L. Wu, Z. Zheng, Z. Qiu, H. Wang, H. Gu, T. Shen, C. Qin, C. Zhu, H. Zhu, Q. Liu, H. Xiong, 和 E. Chen, “大语言模型推荐综述,” CoRR, 第 abs/2305.19860 卷, 2023.
[23] W. Fan, Z. Zhao, J. Li, Y. Liu, X. Mei, Y. Wang, J. Tang, 和 Q. Li, “大语言模型时代推荐系统综述,” CoRR, 第 abs/2307.02046 卷, 2023.
[24] L. Li, Y. Zhang, D. Liu, 和 L. Chen, “用于生成推荐的大语言模型:综述与远景讨论,” CoRR, 第 abs/2309.01157 卷, 2023.
[25] S. Zhang, Y. Tay, L. Yao, A. Sun, 和 C. Zhang, “推荐系统的深度学习,” 在《推荐系统手册》中。Springer US, 2022, 第 173-210 页.
[26] S. Wang, L. Hu, Y. Wang, L. Cao, Q. Z. Sheng, 和 M. A. Orgun, “顺序推荐系统:挑战、进展与前景,” 在第二十八届国际人工智能联合会议论文集中, IJCAI 2019, Macao, China, August 10-16, 2019. ijcai.org, 2019, 第 6332-6338 页.
[27] M. A. Islam, M. M. Mohammad, S. S. S. Das, 和 M. E. Ali, “基于深度学习的兴趣点(POI)推荐综述,” Neurocomputing, 第 472 卷, 第 306-325 页, 2022.
[28] J. Beel, B. Gipp, S. Langer, 和 C. Breitinger, “研究论文推荐系统:文献综述,” 国际数字图书馆杂志, 第 17 卷, 第 4 期, 第 305-338 页, 2016.
[29] X. Yang, Y. Guo, Y. Liu, 和 H. Steck, “基于协作过滤的社会推荐系统综述,” 计算机通信, 第 41 卷, 第 1-10 页, 2014.
[30] S. Balineni 和 W. Andreopoulos, “基于图深度学习的 Reels 标签推荐器,” 在第九届 IEEE 国际大数据计算服务与应用会议论文集中, BigDataService 2023, Athens, Greece, July 17-20, 2023. IEEE, 2023, 第 119-126 页.
[31] M. Karimi, D. Jannach, 和 M. Jugovac, “新闻推荐系统 —— 综述与未来发展,” 信息处理与管理, 第 54 卷, 第 6 期, 第 1203-1227 页, 2018.
[32] E. Hasan, M. Rahman, C. Ding, J. X. Huang, 和 S. Raza, “基于评论的推荐系统:方法、挑战和未来视角的综述,” CoRR, 第 abs/2405.05562 卷, 2024.
[33] R. He 和 J. J. McAuley, “VBPR:基于隐式反馈的视觉贝叶斯个性化排序,” 在第三十届 AAAI 人工智能国际会议论文集中, February 12-17, 2016, Phoenix, Arizona, USA. AAAI Press, 2016, 第 144-150 页.
[34] P. Knees 和 M. Schedl, “基于音乐上下文数据的音乐相似性和推荐综述,” ACM 多媒体计算、通信与应用事务, 第 10 卷, 第 1 期, 第 2:1-2:21 页, 2013.
[35] M. Ge 和 F. Persia, “多媒体推荐系统综述:挑战与机遇,” 国际语义计算期刊, 第 11 卷, 第 3 期, 第 411 页, 2017.
[36] Y. Liu, H. Yin, B. Cui, Y. Chen, K. Wang, 和 Z. Huang, “Nova:非侵入式和融合变分自编码器用于带侧信息的推荐,” 在第 27 届 ACM SIGKDD 知识发现与数据挖掘国际会议论文集中, 2021, 第 404-414 页. [37] X. Wei, H. Zhang, L. Cao, L. Nie, Y. Yang, 和 T.-S. Chua, “MMGCN:多模态图卷积网络用于个性化微视频推荐,” 在第 27届 ACM 国际多媒体会议论文集中,2019,第 1437-1445 页。
[38] L. Chen, L. Cao, X. Wei, 和 Y. Yang, “CMBT:用于推荐的共注意力多模态特征融合,” 在第 44 届国际 ACM SIGIR 信息检索研究与发展会议上,2021,第 549-558 页。
[39] W. Chen, J. Zhang, H. Liu, X. Liu, J. Wu, Y. Yang, 和 J. Tang, “MKQFormer:用于推荐的多模态知识图增强变压器,” IEEE 知识与数据工程事务,2022。
[40] M. Jeong, K.-W. Kim, M. Song, 和 H. Park, “CamRec:带有预训练编码器的协同注意多模态推荐,” 在 Web Conference 2024 的会议记录中,2024。
[41] C. Tao, R. Wang, Y. Wang, F. Wu, T. Tan, 和 L. Wang, “MGAT:用于推荐的多模态图注意力网络,” 在第 43 届国际 ACM SIGIR 信息检索研究与发展会议记录中,2020,第 169-178 页。
[42] J. Kim, K. Lee, S. Kim, H. Lim, B. Kim, 和 H. Kim, “Modality-aware Recommendation with Interaction-level Fusion,” 在第 45 届国际 ACM SIGIR 会议记录中,2022,第 149-158 页。
[43] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, 和 R. Lowe, “Training Language Models to Follow Instructions with Human Feedback,” 在 Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022,NeurIPS 2022,New Orleans, LA, USA,November 28 - December 9, 2022 的记录中,2022。
[44] L. Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite, N. Nabeshima, S. Presser, 和 C. Leahy, “The Pile: An 800GB Dataset of Diverse Text for Language Modeling,” CoRR, 第 abs/2101.00027 卷,2021。
[45] T. L. Scao, A. Fan, C. Akiki, E. Pavlick, S. Ilic, D. Hesslow, R. Castagné, A. S. Luccioni, F. Yvon, M. Gallé, J. Tow, A. M. Rush, S. Biderman, A. Welson, P. S. Ammanamanchi, T. Wang, B. Sagot, N. Muennighoff, A. V. del Moral, O. Ruwase, R. Bawden, S. Bekman, A. McMillan-Major, I. Beltagy, H. Nguyen, L. Saulnier, S. Tan, P. O. Suarez, V. Sanh, H. Laurençon, Y. Jernite, J. Launay, M. Mitchell, C. Raffel, A. Gokaslan, A. Simhi, A. Sonsa, A. F. Aji, A. Alfassy, A. Rogers, A. K. Nitzav, C. Xu, C. Mou, C. Emezue, C. Klamm, C. Leong, D. van Strien, D. I. Adelani, 和其他人, “BLOOM: 一个包含 1760 亿参数的开放访问多语言语言模型,” CoRR, 第 abs/2211.05100 卷, 2022.
[46] S. Zhang, S. Roller, N. Goyal, M. Artetse, M. Chen, S. Chen, C. Dewan, M. T. Diab, X. Li, X. V. Lin, T. Mihaylov, M. Ott, S. Shleifer, K. Shuster, D. Simig, P. S. Koura, A. Sridhar, T. Wang, 和 L. Zettlemoyer, “OPT: 开放预训练转换语言模型,” CoRR, 第 abs/2205.01068 卷, 2022.
[47] J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den
Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, 和 L. Sifre, “Training Compute-Optimal Large Language Models,” CoRR, 第 abs/2203.15556 卷, 2022.
[48] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, 和 G. Lample, “Llama: 开放且高效的基语言模型,” CoRR, 第 abs/2302.13971 卷, 2023.
[49] Q. Dong, L. Li, D. Dai, C. Zheng, J. Ma, R. Li, H. Xia, J. Xu, Z. Wu, T. Liu 等人, “关于上下文学习的综述,” arXiv preprint arXiv:2301.00234, 2022.
[50] Y. Xu, L. Xie, X. Gu, X. Chen, H. Chang, H. Zhang, Z. Chen, X. Zhang, 和 Q. Tian, “QA-Lora: 大型语言模型的量化感知低秩适应,” 在第十二届国际学习表示会议,ICLR 2024,Vienna, Austria,May 7-11, 2024 的记录中,2024.
[51] T. Dettmers, A. Pagnoni, A. Holtzman, 和 L. Zettlemoyer, “QLora: Efficient Finetuning of Quantized LLMs,” 在 Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023,NeurIPS 2023,New Orleans, LA, USA,December 10 - 16, 2023 的记录中,2023.
[52] D. Zhang, Y. Yu, J. Dong, C. Li, D. Su, C. Chu, 和 D. Yu, “MMLLMs: 最近在多模态大型语言模型方面的进展,” 在计算语言学协会发现中,ACL 2024,Bangkok, Thailand 和虚拟会议,August 11-16, 2024。计算语言学协会,2024,第 12401-12430 页。
[53] OpenAI, “GPT-4 技术报告,” CoRR, 第 abs/2303.08774 卷, 2023.
[54] R. Anil, S. Borgeaud, Y. Wu, J. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican, D. Silver, S. Petrov, M. Johnson, I. Antonoglou, J. Schrittwieser, A. Glaese, J. Chen, E. Pitler, T. P. Lillicrap, A. Lazaridou, O. Firat, J. Molloy, M. Isard, P. R. Barham, T. Hennigan, B. Lee, F. Viola, M. Reynolds, Y. Xu, R. Doherty, E. Collins, C. Meyer, E. Rutherford, E. Moreira, K. Ayoub, M. Goel, G. Tucker, E. Piqueras, M. Krikun, I. Barr, N. Savinov, I. Danihelka, B. Roelofs, A. White, A. Andreassen, T. von Glehn, L. Yagati, M. Kazemi, L. Gonzalez, M. Khalman, J. Sygnowski 和其他, “Gemini: 高能力多模态模型家族,” CoRR, 第 abs/2312.11805 卷, 2023.
[55] M. Reid, N. Savinov, D. Teplyashin, D. Lepikhin, T. P. Lillicrap, J. Alayrac, R. Soricut, A. Lazaridou, O. Firat, J. Schrittwieser, I. Antonoglou, R. Anil, S. Borgeaud, A. M. Dai, K. Millican, E. Dyer, M. Glaese, T. Sottiaux, B. Lee, F. Viola, M. Reynolds, Y. Xu, J. Molloy, J. Chen, M. Isard, P. Barham, T. Hennigan, R. McIlroy, M. Johnson, J. Schalkwyk, E. Collins, E. Rutherford, E. Moreira, K. Ayoub, M. Goel, C. Meyer, G. Thornton, Z. Yang, H. Michalewski, Z. Abbas, N. Schucher, A. Anand, R. Ives, J. Keeling, K. Lenc, S. Haykal, S. Shakeri, P. Shyam, A. Chowdhery, R. Ring, S. Spencer, E. Sezener 和其他, “Gemini 1.5: 解锁数百万上下文标记中的多模态理解,” CoRR, 第 abs/2403.05530 卷, 2024.
[56] J. Li, D. Li, S. Savarese, 和 S. C. H. Hoi, “BLIP-2: 使用冻结图像编码器和大型语言模型引导的语言-图像预训练启动,” 在机器学习国际会议,ICML 2023,23-29 July 2023,Honolulu, Hawaii, USA 的记录中,PMLR, 2023,第 19730-19742 页。
[57] L. Xue, M. Shu, A. Awadalla, J. Wang, A. Yan, S. Purushwalkam, H. Zhou, V. Prabhu, Y. Dai, M. S. Ryoo, S. Kendre, J. Zhang, C. Qin, S. Zhang, C. Chen, N. Yu, J. Tan, T. M. Awalgaonkar, S. Heinecke, H. Wang, Y. Choi, L. Schmidt, Z. Chen, S. Savarese, J. C. Niebles, C. Xiong, 和 R. Xu, “sgen-mm (BLIP-3): 开源大模态模型家族,” CoRR, 第 abs/2408.08872 卷, 2024.
[58] H. Liu, C. Li, Q. Wu, 和 Y. J. Lee, “视觉指令调整,” 在 Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023,NeurIPS 2023,New Orleans, LA, USA,December 10 - 16, 2023 的记录中,2023.
[59] K. Li, Y. He, Y. Wang, Y. Li, W. Wang, P. Luo, Y. Wang, L. Wang, 和 Y. Qiao, “Videochat: 聊天为中心的视频理解,” CoRR, 第 abs/2305.06355 卷, 2023.
[60] A. Awadalla, I. Gao, J. Gardner, J. Hessel, Y. Hanafy, W. Zhu, K. Marathe, Y. Bitton, S. Y. Gadre, S. Sagawa, J. Jitsev, S. Kornblith, P. W. Koh, G. Itharco, M. Wortsman, 和 L. Schmidt, “Openflamingo: 一个开源框架用于训练大型自回归视觉-语言模型,” CoRR, 第 abs/2308.01390 卷, 2023.
[61] K. Li, Y. He, Y. Wang, Y. Li, W. Wang, P. Luo, Y. Wang, L. Wang, 和 Y. Qiao, “Videochat: 聊天为中心的视频理解,” CoRR, 第 abs/2305.06355 卷, 2023.
[62] M. Maaz, H. A. Rasheed, S. Khan, 和 F. Khan, “Video-chatgpt: 通过大规模视觉和语言模型实现详细视频理解,” 在 Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ALI, 2024, Bangkok, Thailand, August 11-16, 2024。计算语言学协会,2024,第 12585-12602 页。
[63] Y. Li, C. Wang, 和 J. Jia, “Llama-vid: 在大规模语言模型中图像值为 2 个令牌,” 在计算机视觉 - ECCV 2024 - 第 18 届欧洲会议,米兰,意大利,September 29-October 4, 2024,Proceedings, Part XLVI,系列 Lecture Notes in Computer Science,卷 15104。Springer,2024,第 323-340 页。
[64] Y. Chu, J. Xu, X. Zhou, Q. Yang, S. Zhang, Z. Yan, C. Zhou, 和 J. Zhou, “Qwen-audio: 通过统一的大规模音频-语言模型推进通用音频理解,” CoRR, 第 abs/2311.07919 卷, 2023.
[65] Y. Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y. Leng, Y. Lv, J. He, J. Lin, C. Zhou, 和 J. Zhou, “Qwen2-audio 技术报告,” CoRR, 第 abs/2407.10759 卷, 2024.
[66] X. Pan, L. Dong, S. Huang, Z. Peng, W. Chen, 和 F. Wei, “Kosmos-g: 使用多模态大语言模型生成上下文中的图像,” 在 The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 的记录中,2024.
[67] Q. Sun, Q. Yu, Y. Cui, F. Zhang, X. Zhang, Y. Wang, H. Gao, J. Liu, T. Huang, 和 X. Wang, “Emu: 多模态生成预训练,” 在 The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 的记录中,OpenReview.net, 2024.
[68] K. Zheng, X. He, 和 X. E. Wang, “Minigpt-5: 通过生成 vokens 实现交错的视觉和语言生成,” CoRR, 第 abs/2310.02239 卷, 2023.
[69] D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y. Zhou, 和 X. Qiu, “Speechgpt: 赋予大型语言模型内在跨模态对话能力,” 在 Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023 的记录中,计算语言学协会,2023,第
15757
−
15773
15757-15773
15757−15773 页。
[70] P. K. Rubenstein, C. Asawaroengchai, D. D. Nguyen, A. Bapna, Z. Borsos, F. de Chaumont Quitry, P. Chen, D. E. Badawy, W. Han, E. Kharitonov, H. Muckenhirn, D. Padfield, J. Qin, D. Rozenberg, T. N. Sainath, J. Schalkwyk, M. Sharifi, M. T. Ramanovich, M. Tagliasacchi, A. Tudor, M. Velimirovic, D. Vincent, J. Yu, Y. Wang, V. Zayats, N. Zeghidour, Y. Zhang, Z. Zhang, L. Zilka, 和 C. H. Frank, “Audiopalm: 可以说话和倾听的大型语言模型,” CoRR, 第 abs/2306.12925 卷, 2023.
[71] C. Wu, S. Yin, W. Qi, X. Wang, Z. Tang, 和 N. Duan, “Visual chatgpt: 使用视觉基础模型进行交谈、绘图和编辑,” CoRR, 第 abs/2303.04671 卷, 2023.
[72] Y. Shen, K. Song, X. Tan, D. Li, W. Lu, 和 Y. Zhuang, “Hugginggpt: 使用 Chatgpt 和 Hugging Face 中的朋友解决 AI 任务,” 在 Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 的记录中,2023.
[73] R. Huang, M. Li, D. Yang, J. Shi, X. Chang, Z. Ye, Y. Wu, Z. Hong, J. Huang, J. Liu, Y. Ren, Y. Zou, Z. Zhao, 和 S. Watanabe, “Audiogpt: 理解和生成语音、音乐、声音和谈话头像,” 在 Thirty-Eighth AAAI Artificial Intelligence Conference, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver, Canada 的记录中,AAAI Press, 2024, 第 23802-23804 页。
[74] S. Wu, H. Fei, L. Qu, W. Ji, 和 T. Chua, “Next-gpt: Any-to-any 多模态 LLM,” CoRR, 第 abs/2309.05519 卷, 2023.
[75] Z. Tang, Z. Yang, M. Khademi, Y. Liu, C. Zhu, 和 M. Bansal, “Codi-2: 上下文中,交错式和交互式的 any-to-any 生成,” 在 IEEE/CVF 计算机视觉与模式识别会议,CVPR 2024, Seattle, WA, USA, June 16-22, 2024 的记录中,IEEE, 2024, 第
27415
−
27424
27415-27424
27415−27424 页。
[76] X. Wang, B. Zhuang, 和 Q. Wu, “Modaverse: 利用 llms 高效转换模态,” 在 IEEE/CVF 计算机视觉与模式识别会议,CVPR 2024, Seattle, WA, USA, June 16-22, 2024 的记录中,IEEE, 2024, 第 26596-26606 页。
[77] Z. Durante, Q. Huang, N. Wake, R. Gong, J. S. Park, B. Sarkar, R. Taori, Y. Noda, D. Terzopoulos, Y. Choi 等人, “Agent ai: 调查多模态互动的地平线,” arXiv preprint arXiv:2401.03568, 2024.
[78] Z. Zhang, X. Bo, C. Ma, R. Li, X. Chen, Q. Dai, J. Zhu, Z. Dong, 和 J.-R. Wen, “大型语言模型代理的记忆机制综述,” arXiv preprint arXiv:2404.13501, 2024.
[79] X. Huang, W. Liu, X. Chen, X. Wang, H. Wang, D. Lian, Y. Wang, R. Tang, 和 E. Chen, “理解 LLM 代理的规划:综述,” arXiv preprint arXiv:2402.02716, 2024.
[80] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, 和 Y. Cao, “React: 语言模型中的推理和行动协同作用,” arXiv preprint arXiv:2210.03629, 2022.
[81] N. Shinn, F. Cassano, B. Labash, A. Gopinath, K. Narasimhan, 和 S. Yao, “Reflexion: 具有口头强化学习的语言代理(2023),” arXiv preprint cs.AI/2303.11366, 2023.
[82] J. Hilton, R. Nakano, S. Balaji, 和 J. Schulman, “Webgpt: 通过网页浏览提高语言模型的事实准确性,” OpenAI Blog, December, 第 16 卷, 2021.
[83] W. Yao, S. Heinecke, J. C. Niebles, Z. Liu, Y. Feng, L. Xue, R. Murthy, Z. Chen, J. Zhang, D. Arpit 等人, “Retroformer: 带策略梯度优化的回顾性大型语言代理,” arXiv preprint arXiv:2308.02151, 2023.
[84] S. Wu, S. Zhao, Q. Huang, K. Huang, M. Yasunaga, K. Cao, V. N. Ioannidis, K. Subbian, J. Leskovec, 和 J. Zou, “Avatar: 优化 llm 代理以进行工具辅助知识检索,” arXiv preprint arXiv:2406.11200, 2024.
[85] G. Li, H. Hammoud, H. Itani, D. Khizbullin, 和 B. Ghanem, “Camel: Communicative Agents for” mind" 探索大型语言模型社会," Advances in Neural Information Processing Systems, 第 36 卷, 第 51991-52008 页, 2023.
[86] S. Hong, X. Zheng, J. Chen, Y. Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou 等人, “Metagpt: 多代理协作框架的元编程,” arXiv preprint arXiv:2308.00352, 2023.
[87] Z. Liu, W. Yao, J. Zhang, L. Yang, Z. Liu, J. Tan, P. K. Choubey, T. Lan, J. Wu, H. Wang 等人, “Agentlite: 构建和推进面向任务的 llm 代理系统的轻量级库,” arXiv preprint arXiv:2402.15538, 2024.
[88] C.-M. Chan, W. Chen, Y. Su, J. Yu, W. Xue, S. Zhang, J. Fu, 和 Z. Liu, “Chateval: 通过多代理辩论构建更好的 llm 基础评估者,” arXiv preprint arXiv:2308.07201, 2023.
[89] C. Qian, X. Cong, C. Yang, W. Chen, Y. Su, J. Xu, Z. Liu, 和 M. Sun, “软件开发的通信代理,” arXiv preprint arXiv:2307.07924, 2023.
[90] K. Bao, J. Zhang, Y. Zhang, W. Wenjie, F. Feng, 和 X. He, “推荐系统中的大型语言模型:进展和未来方向,” 在亚太地区年度国际 ACM SIGIR 信息检索研究与发展会议的记录中,北京,中国。ACM, 2023, 第 306-309 页。
[91] W. Hua, L. Li, S. Xu, L. Chen, 和 Y. Zhang, “推荐系统的大型语言模型教程,” 在第十七届 ACM 推荐系统会议的记录中,新加坡。ACM, 2023, 第 1281-1283 页。
[92] Y. Zhu, L. Wu, Q. Guo, L. Hong, 和 J. Li, “推荐系统的协作大型语言模型,” CoRR, 第 abs/2311.01343 卷, 2023.
[93] S. Geng, S. Liu, Z. Fu, Y. Ge, 和 Y. Zhang, “作为语言处理的推荐(RLP):统一预训练、个性化提示和预测范式(P5),” 在第十六届 ACM 推荐系统会议的记录中,2022, 第 299-315 页。
[94] W. Hua, S. Xu, Y. Ge, 和 Y. Zhang, “如何为推荐基础模型索引项目 ID,” arXiv preprint arXiv:2303.06569, 2023.
[95] R. Sarkar, N. Bodla, M. I. Vasileva, Y. Lin, A. Beniwal, A. Lu, 和 G. Medioni, “Outfittransformer: 学习时尚推荐的服装表示,” 在 IEEE/CVF 冬季计算机视觉应用会议的记录中,Waikoloa, HI, USA。IEEE, 2023, 第 3590-3598 页。
[96] J. Li, M. Wang, J. Li, J. Fu, X. Shen, J. Shang, 和 J. J. McAuley, “文本就是你所需要的:学习顺序推荐的语言表示,” 在第 29 届 ACM SIGKDD 知识发现和数据挖掘国际会议的记录中,Long Beach, CA, USA。ACM, 2023, 第 1258-1267 页。
[97] Z. Zhang 和 B. Wang, “新闻推荐的提示学习,” 在第 46 届国际 ACM SIGIR 信息检索研究和发展会议的记录中
台北,台湾。ACM, 2023, 第 227-237 页。
[98] S. Doddapaneni, K. Sayana, A. Jash, S. S. Sodhi, 和 D. Kuzmin, “个性化语言提示的用户嵌入模型,” CoRR, 第 abs/2401.04858 卷, 2024.
[99] J. Zhou, Y. Dai, 和 T. Joachims, “基于语言的用户画像用于推荐,” CoRR, 第 abs/2402.15623 卷, 2024.
[100] S. Gao, J. Fang, Q. Tu, Z. Yao, Z. Chen, P. Ren, 和 Z. Ren, “生成新闻推荐,” 在 ACM Web Conference 2024 的记录中,WWW 2024, 新加坡,May 13-17, 2024。ACM, 2024, 第 3444-3453 页。
[101] L. Ning, L. Liu, J. Wu, N. Wu, D. Berlowitz, S. Prakash, B. Green, S. O’Banion, 和 J. Xie, “User-LLM: 使用用户嵌入高效上下文化 LLM,” CoRR, 第 abs/2402.13598 卷, 2024.
[102] Y. Shen, L. Zhang, K. Xu, 和 X. Jin, “Autotransition: 学习推荐视频过渡效果,” 在计算机视觉 - ECCV 2022 - 第 17 届欧洲会议,Tel Aviv, Israel,系列 Lecture Notes in Computer Science,卷 13698。Springer, 2022, 第 285-300 页。
[103] K. Youwang, J. Kim, 和 T. Oh, “Clip-actor: 文本驱动的动画人类网格推荐和风格化,” 在计算机视觉 - ECCV 2022 - 第 17 届欧洲会议,Tel Aviv, Israel,系列 Lecture Notes in Computer Science,卷 13663。Springer, 2022, 第 173-191 页。
[104] C. Huang, S. Wang, X. Wang, 和 L. Yao, “双重对比变换器用于分层偏好建模的顺序推荐,” 在第 46 届国际 ACM SIGIR 信息检索研究与发展会议的记录中,SIGIR 2023, Taipei, Taiwan, July 23-27, 2023。ACM, 2023, 第 99-109 页。
[105] 同上, “Modeling temporal positive and negative excitation for sequential recommendation,” 在 Proceedings of the ACM Web Conference 2023 的记录中,WWW 2023, Austin,TX, USA, 30 April 2023 - 4 May 2023。ACM, 2023, 第 1252-1263 页。
[106] J. Zhai, X. Zheng, C. Wang, H. Li, 和 Y. Tian, “知识提示调优用于顺序推荐,” 在第 31 届 ACM 国际多媒体会议的记录中,Ottawa, ON, Canada。ACM, 2023, 第 6451-6461 页。
[107] Y. Xi, W. Liu, J. Lin, J. Zhu, B. Chen, R. Tang, W. Zhang, R. Zhang, 和 Y. Yu, “迈向开放世界的推荐:从大型语言模型获取知识增强,” CoRR, 第 abs/2306.10933 卷, 2023.
[108] W. Luo, C. Song, L. Yi, 和 G. Cheng, “Kellmrec: 增强知识的大型语言模型用于推荐,” CoRR, 第 abs/2403.06642 卷, 2024.
[109] Z. Yuan, F. Yuan, Y. Song, Y. Li, J. Fu, F. Yang, Y. Pan, 和 Y. Ni, “推荐系统下一步何去何从?ID- vs. 模态基础推荐模型重访,” 在第 46 届国际 ACM SIGIR 信息检索研究与发展会议的记录中,Taipei, Taiwan。ACM, 2023, 第 2639-2649 页。
[110] J. Liao, S. Li, Z. Yang, J. Wu, Y. Yuan, 和 X. Wang, “Llara: 对齐大型语言模型与顺序推荐器,” CoRR, 第 abs/2312.02445 卷, 2023.
[111] X. Lin, W. Wang, Y. Li, F. Feng, S. Ng, 和 T. Chua, “多面范式连接大型语言模型与推荐,” CoRR, 第 abs/2310.06491 卷, 2023.
[112] X. Wang, X. He, M. Wang, F. Feng, 和 T. Chua, “神经图协同过滤,” 在 Proceedings of the 42nd International ACM SIGIR 信息检索研究与发展会议的记录中,SIGIR 2019, Paris, France。ACM, 2019, 第 165-174 页。
[113] N. Guo, H. Cheng, Q. Liang, L. Chen, 和 B. Han, “整合大型语言模型与图形会话推荐,” CoRR, 第 abs/2402.16539 卷, 2024.
[114] N. Choudhary, E. W. Huang, K. Subbian, 和 C. K. Reddy, “一种可解释的图和语言模型集成方法,用于提高电子商务搜索相关性,” 在 Companion Proceedings of the ACM Web Conference 2024 的记录中,WWW 2024, 新加坡。ACM, 2024, 第 206-215 页。
[115] Q. Zhao, H. Qian, Z. Liu, G. Zhang, 和 L. Gu, “打破障碍:利用推理知识图谱将大型语言模型应用于工业推荐系统,” CoRR, 第 abs/2402.13750 卷, 2024.
[116] Z. Chu, Y. Wang, Q. Cui, L. Li, W. Chen, S. Li, Z. Qin, 和 K. Ren, “由 LLM 引导的多视图超图学习用于以人为中心的可解释推荐,” CoRR, 第 abs/2401.08217 卷, 2024.
[117] X. Ren, W. Wei, L. Xia, L. Su, S. Cheng, J. Wang, D.Yin, 和 C. Huang, “用于推荐的大语言模型表示学习,” 在 ACM Web Conference 的记录中
2024, WWW 2024, 新加坡,May 13-17, 2024。ACM, 2024, 第
3464
−
3475
3464-3475
3464−3475 页。
[118] A. Damianou, F. Fabbri, P. Gigioli, M. D. Nadai, A. Wang, E. Palumbo, 和 M. LaImas, “迈向个性化图基础模型,” 在 Companion Proceedings of the ACM Web Conference 2024 的记录中,WWW 2024, 新加坡。ACM, 2024, 第 1798-1802 页。
[119] L. Sheng, A. Zhang, Y. Zhang, Y. Chen, X. Wang, 和 T.-S. Chua, “语言模型在推荐中编码协作信号,” arXiv preprint arXiv:2407.05441, 2024.
[120] W. Wei, X. Ren, J. Tang, Q. Wang, L. Su, S. Cheng, J. Wang, D. Yin, 和 C. Huang, “Limrec: 带有图增强的大语言模型推荐,” 在第十七届 ACM 国际网络搜索和数据挖掘会议的记录中, 2024, 第 806-815 页。
[121] Y. Zhang, K. Bao, M. Yan, W. Wang, F. Feng, 和 X. He, “用于推荐的大语言模型中的文本样协作信息编码,” arXiv preprint arXiv:2406.03210, 2024.
[122] G. Hu, Z. Yang, Z. Cai, A. Zhang, 和 X. Wang, “生成你所偏好的:由文本引导扩散用于顺序推荐,” arXiv preprint arXiv:2410.13428, 2024.
[123] J. Ho, A. Jain, 和 P. Abbeel, “去噪扩散概率模型,” Advances in neural information processing systems, 第 33 卷, 第 6840-6851 页, 2020.
[124] B. Zheng, Y. Hou, H. Lu, Y. Chen, W. X. Zhao, M. Chen, 和 J.-R. Wen, “通过整合协作语义将大语言模型适应于推荐,” 在 2024 IEEE 第 40 届国际数据工程会议 (ICDE) 的记录中。IEEE, 2024, 第 1435-1448 页。
[125] Y. Wang, Z. Ren, W. Sun, J. Yang, Z. Liang, X. Chen, R. Xie, S. Yan, X. Zhang, P. Ren 等人, “基于内容的协作生成用于推荐系统,” 在第三十三届 ACM 国际信息与知识管理会议的记录中, 2024, 第 2420-2430 页。
[126] Y. Wang, J. Yan, M. Hong, J. Zhu, T. Jin, W. Lin, H. Li, L. Li, Y. Xia, Z. Zhao 等人, “Eager: 行为语义协作的双流生成推荐器,” 在第三十届 ACM SIGKDD 知识发现与数据挖掘会议的记录中, 2024, 第 3245-3254 页。
[127] Y. Yang, Z. Ji, Z. Li, Y. Li, Z. Mo, Y. Ding, K. Chen, Z. Zhang, J. Li, S. Li 等人, “稀疏遇见稠密:统一的生成推荐使用级联稀疏稠密表示,” arXiv preprint arXiv:2503.02453, 2025.
[128] J. Deng, S. Wang, K. Cai, L. Ren, Q. Hu, W. Ding, Q. Luo, 和 G. Zhou, “Onerec: 统一检索和排名使用生成推荐和迭代偏好对齐,” arXiv preprint arXiv:2502.18965, 2025.
[129] Z. Cui, J. Ma, C. Zhou, J. Zhou, 和 H. Yang, “M6-rec: 生成预训练语言模型是开放式的推荐系统,” arXiv preprint arXiv:2305.08084, 2022.
[130] C. Wu, F. Wu, T. Qi, J. Lian, Y. Huang, 和 X. Xie, “Ptum: 通过自监督从未标记用户行为中预训练用户模型,” arXiv preprint arXiv:2010.01494, 2020.
[131] H. Ngo 和 D. Q. Nguyen, “Recgpt: 文本推荐的生成预训练,” arXiv preprint arXiv:2405.12715, 2024.
[132] A. C. Li, M. Prabhudesai, S. Duggal, E. Brown, 和 D. Pathak, “你的扩散模型实际上是一个零样本分类器,” 在 IEEE/CVF 国际计算机视觉会议的记录中, 2023, 第 2206-2217 页。
[133] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, 和 D. Amodei, “语言模型是少量样本学习者,” 在 Advances in Neural Information Processing Systems 的记录中, 第 33 卷。Curran Associates, Inc., 2020, 第 1877-1901 页。
[134] J. Liu, C. Liu, P. Zhou, Q. Ye, D. Chong, K. Zhou, Y. Xie, Y. Cao, S. Wang, C. You, 和 P. S. Yu, “Limrec: 在推荐任务上基准测试大语言模型,” CoRR, 第 abs/2308.12241 卷, 2023.
[135] J. Yao, W. Xu, J. Lian, X. Wang, X. Yi, 和 X. Xie, “知识插件:增强大语言模型进行特定领域推荐,” CoRR, 第 abs/2311.10779 卷, 2023.
[136] B. Rahdari, H. Ding, Z. Fan, Y. Ma, Z. Chen, A. Deoras, 和 B. Kveton, “逻辑支架:使用 llms 进行个性化方面指令推荐解释生成,” CoRR, 第 abs/2312.14345 卷, 2023.
[137] W. Kang 和 J. J. McAuley, “自我注意顺序推荐,” 在 IEEE 数据挖掘国际会议的记录中, ICDM 2018, 新加坡, November 17-20, 2018。IEEE Computer Society, 2018, 第 197-206 页。
[138] R. Li, W. Deng, Y. Cheng, Z. Yuan, J. Zhang, 和 F. Yuan, “探索使用大语言模型进行基于文本的协同过滤的上限:发现与见解,” CoRR, 第 abs/2305.11700 卷, 2023.
[139] J. Zhang, R. Xie, Y. Hou, W. X. Zhao, L. Lin, 和 J. Wen, “作为指令遵循的推荐:一种由大语言模型赋能的推荐方法,” CoRR, 第 abs/2305.07001 卷, 2023.
[140] K. Bao, J. Zhang, Y. Zhang, W. Wang, F. Feng, 和 X. He, “Talbec: 一种有效且高效的调整框架以使大语言模型与推荐对齐,” 在第十七届 ACM 推荐系统会议的记录中, 新加坡。ACM, 2023, 第 1007-1014 页。
[141] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, 和 W. Chen, “Lora: 大语言模型的低秩调整,” 在第十届国际学习表示会议, ICLR, 2022 的记录中。
[142] R. Taori, I. Gulrajani, T. Zhang, Y. Dubois, X. Li, C. Guestrin, P. Liang, 和 T. B. Hashimoto, “斯坦福 alpaca: 一个指令跟随的 llama 模型,” 2023.
[143] K. Bao, J. Zhang, W. Wang, Y. Zhang, Z. Yang, Y. Luo, F. Feng, X. He, 和 Q. Tian, “大语言模型在推荐系统中的双步接地范式,” CoRR, 第 abs/2308.08434 卷, 2023.
[144] X. Lin, W. Wang, Y. Li, S. Yang, F. Feng, Y. Wei, 和 T. Chua, “数据高效微调用于基于 LLM 的推荐,” CoRR, 第 abs/2401.17197 卷, 2024.
[145] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, 和 B. Ommer, “高分辨率图像合成与潜在扩散模型,” 在 IEEE/CVF 计算机视觉和模式识别会议的记录中, 2022, 第 10684-10695 页。
[146] Y. Xu, W. Wang, F. Feng, Y. Ma, J. Zhang, 和 X. He, “扩散模型用于生成性服装推荐,” 在第 47 届国际 ACM SIGIR 信息检索研究与发展会议的记录中, 2024, 第 1350-1359 页。
[147] V. Shilova, L. D. Santos, F. Vasile, G. Racic, 和 U. Tanielian, “Adbooster: 使用稳定扩散外画生成个性化广告创意,” 在时尚和零售推荐系统研讨会的记录中。Springer, 2023, 第 73-93 页。
[148] H. Yang, J. Yuan, S. Yang, L. Xu, S. Yuan, 和 Y. Zeng, “新的点击率生成管道使用稳定扩散模型,” 在 Companion Proceedings of the ACM Web Conference 2024 中, 2024, 第 180-189 页。
[149] Á. T. Czapp, M. Jani, B. Domián, 和 B. Hidasi, “大规模个性化电子商务动态产品图像生成与推荐,” 在第十八届 ACM 推荐系统会议的记录中, 2024, 第 768-770 页。
[150] W. Wang, Y. Xu, F. Feng, X. Lin, X. He, 和 T.-S. Chua, “扩散推荐模型,” 在第 46 届国际 ACM SIGIR 信息检索研究与发展会议的记录中, 2023, 第 832-841 页。
[151] Z. Yang, J. Wu, Z. Wang, X. Wang, Y. Yuan, 和 X. He, “生成你所偏好的:通过引导扩散重塑顺序推荐,” Advances in Neural Information Processing Systems, 第 36 卷, 第 24247-24261 页, 2023.
[152] Z. Li, A. Sun, 和 C. Li, “Diffurec: 用于顺序推荐的扩散模型,” ACM 信息系统事务, 第 42 卷, 第 3 期, 第 1-28 页, 2023.
[153] H. Huang, C. Huang, T. Yu, X. Chang, W. Hu, J. McAuley, 和 L. Yao, “双条件扩散模型用于顺序推荐,” arXiv preprint arXiv:2410.21967, 2024.
[154] L. Weng, “由 LLM 赋能的自主代理,” lilianweng.github.io, Jun 2023. [在线]. 可用: https: //lilianweng.github.io/posts/2023-06-23-agent/
[155] Y. Zhu, H. Li, Y. Liao, B. Wang, Z. Guan, H. Liu, 和 D. Cai, “接下来做什么:通过时间 LSTM 建模用户行为,” 在第二十六届国际人工智能联合会议的记录中, 墨尔本, 2017, 第 3602-3608 页。
[156] E. Ie, C. Hsu, M. Mladenov, V. Jain, S. Narvekar, J. Wang, R. Wu, 和 C. Boutilier, “Recsim: 可配置的推荐系统模拟平台,” CoRR, 第 abs/1909.04847 卷, 2019.
[157] L. Wang, J. Zhang, X. Chen, Y. Lin, R. Song, W. X. Zhao, 和 J.-R. Wen, “Recagent: 一种新颖的推荐系统模拟范式,” 2023.
[158] A. Zhang, L. Sheng, Y. Chen, H. Li, Y. Deng, X. Wang, 和 T. Chua, “关于推荐中的生成代理,” CoRR, 第 abs/2310.10108 卷, 2023.
[159] W. Shi, X. He, Y. Zhang, C. Gao, X. Li, J. Zhang, Q. Wang, 和 F. Feng, “通过两级可学习的大语言模型规划增强长期推荐,” CoRR, 第 abs/2403.00843 卷, 2024.
[160] J. Zhang, Y. Hou, R. Xie, W. Sun, J. J. McAuley, W. X. Zhao, L. Lin, 和 J. Wen, “Agentct: 通过自主语言代理协作学习用于推荐系统,” CoRR, 第 abs/2310.09233 卷, 2023.
[161] E. Zhang, X. Wang, P. Gong, Y. Lin, 和 J. Mao, “Usimagent: 大语言模型用于模拟搜索用户,” CoRR, 第 abs/2403.09142 卷, 2024.
[162] R. Ren, P. Qiu, Y. Qu, J. Liu, W. X. Zhao, H. Wu, J. Wen, 和 H. Wang, “BASES: 使用基于大语言模型的代理进行大规模网络搜索用户模拟,” CoRR, 第 abs/2402.17505 卷, 2024.
[163] F. Huang, Z. Yang, J. Jiang, Y. Bei, Y. Zhang, 和 H. Chen, “大型语言模型交互模拟器用于冷启动项目推荐,” CoRR, 第 abs/2402.09176 卷, 2024.
[164] Y. Shu, H. Gu, P. Zhang, H. Zhang, T. Lu, D. Li, 和 N. Gu, “Rahl recsys-assistant-human: 具有大型语言模型的以人为中心推荐框架,” CoRR, 第 abs/2308.09904 卷, 2023.
[165] Y. Wang, Z. Jiang, Z. Chen, F. Yang, Y. Zhou, E. Cho, X. Fan, X. Huang, Y. Lu, 和 Y. Yang, “Reemind: 具有大型语言模型的推荐代理,” arXiv preprint arXiv:2308.14296, 2023.
[166] X. Huang, J. Lian, Y. Lei, J. Yao, D. Lian, 和 X. Xie, “推荐 AI 代理:集成大型语言模型用于交互式推荐,” CoRR, 第 abs/2308.16505 卷, 2023.
[167] Z. Wang, Y. Yu, W. Zheng, W. Ma, 和 M. Zhang, “多代理协作框架用于推荐系统,” CoRR, 第 abs/2402.15235 卷, 2024.
[168] H. Cai, Y. Li, W. Wang, F. Zhu, X. Shen, W. Li, 和 T.-S. Chua, “大型语言模型赋能个性化网络代理,” arXiv preprint arXiv:2410.17236, 2024.
[169] X. Shen, R. Zhang, X. Zhao, J. Zhu, 和 X. Xiao, “PMG : 使用大型语言模型的个性化多模态生成,” 在 ACM Web Conference 2024 的记录中, WWW 2024, 新加坡, May 13-17, 2024. ACM, 2024, 第 3833-3843 页。
[170] J. Liu 和其他, “Llmrec: 在推荐任务上基准测试大语言模型,” arXiv preprint arXiv:2305.17105, 2023.
[171] J. Zhang 和其他, “作为指令遵循的推荐:一种大语言模型赋能的推荐方法,” arXiv preprint arXiv:2305.17897, 2023.
[172] Y. Wang 和其他, “增强推荐系统的大语言模型推理图,” arXiv preprint arXiv:2310.13476, 2023.
[173] C. Spurlock 和其他, “Chatgpt 用于对话推荐:通过反馈重新提示细化推荐,” arXiv preprint arXiv:2401.10001, 2024.
[174] L. Cui, T. Huang, L. Sun 等人, “M6-rec: 多任务、多模态、多语言和多领域的推荐系统,” 在 KDD 会议记录中, 2022.
[175] J.-B. Alayrac, J. Donahue 和其他, “Flamingv: 用于小样本学习的视觉语言模型,” 在 Advances in Neural Information Processing Systems (NeurIPS) 的记录中, 2022.
[176] B. Peng, X. Lin, Y. Wang 等人, “Kosmos-2: 将多模态大型语言模型接地到世界,” arXiv preprint arXiv:2306.14824, 2023.
[177] S. Geng, Z. Hu 和其他, “Vip5: 用于推荐的视觉指令提示,” 在第 46 届国际 ACM SIGIR 会议的记录中, 2023.
[178] T. Zhou 和其他, “Mmrec: 开源多模态推荐工具包,” arXiv preprint arXiv:2303.02977, 2023.
[179] C. Tian 和其他, “Mmrec: 统一多模态语言模型的多模态推荐,” arXiv preprint arXiv:2403.03412, 2024.
[180] Y. Zhu, C. Wang 和其他, “Video-llama: 用于视频理解的指令调整音频视觉语言模型,” arXiv preprint arXiv:2306.02858, 2023.
[181] H. Shen, Y. Zhang 和其他, “Pmg: 用于推荐的个性化多模态生成,” arXiv preprint arXiv:2402.00302, 2024.
[182] L. He 和其他, “Talkplay: 用于音乐推荐的对话感知多模态语言模型,” arXiv preprint arXiv:2402.06752, 2024.
[183] J. Gardner, S. Durand, D. Stoller 和 R. M. Bittner, “Llark: 用于音乐的多模态指令跟随语言模型,” arXiv preprint arXiv:2310.07160, 2023.
[184] R. Beaumont 和其他, “Cm3leon: 开放基础模型用于多模态理解和生成,” arXiv preprint arXiv:2306.06535, 2023.
[185] W. Hua, Y. Ge, S. Xu, J. Ji, 和 Y. Zhang, “UP5: 面向公平推荐的无偏基础模型,” CoRR, 第 abs/2305.12090 卷, 2023.
[186] J. Zhang, K. Bao, Y. Zhang, W. Wang, F. Feng, 和 X. He, “Chatgpt 是否适合推荐?评估大语言模型推荐的公平性,” 在第十七届 ACM 推荐系统会议的记录中, 新加坡。ACM, 2023, 第 993-999 页。
[187] Y. Deldjoo 和 T. D. Noia, “Cfairllm: 大型语言模型推荐系统中的消费者公平评估,” CoRR, 第 abs/2403.05668 卷, 2024.
[188] M. Jiang, K. Bao, J. Zhang, W. Wang, Z. Yang, F. Feng, 和 X. He, “基于大型语言模型的推荐系统的物品端公平性,” 在 ACM Web Conference 2024 的记录中, WWW 2024, 新加坡, May 13-17, 2024. ACM, 2024, 第 4717-4726 页。
[189] L. Wang, S. Zhang, Y. Wang, E. Lim, 和 Y. Wang, “Llm4vis: 使用 Chatgpt 的可解释可视化推荐,” 在 Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: EMNLP 2023 - Industry Track 的记录中, 新加坡, December 6-10, 2023. Association for Computational Linguistics, 2023, 第 675-692 页。
[190] N. L. Lê, M. Abel, 和 P. Gouspillou, “结合嵌入式和语义模型用于推荐系统的后验解释,” 在 IEEE International Conference on Systems, Man, and Cybernetics 的记录中, SMC 2023, Honolulu, Oahu, HI, USA, October 1-4, 2023. IEEE, 2023, 第 4619-4624 页。
[191] Q. Liu, N. Chen, T. Sakai, 和 X.-M. Wu, “首次观察大语言模型驱动的生成新闻推荐,” arXiv preprint arXiv:2305.06566, 2023.
[192] J. Liu, C. Liu, R. Lv, K. Zhou, 和 Y. Zhang, “Chatgpt 是一个好的推荐系统吗?初步研究,” arXiv preprint arXiv:2304.10149, 2023.
[193] X. Hu, S. Storks, R. L. Lewis, 和 J. Chai, “在上下文中使用预训练语言模型进行类比推理,” 在 Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics 的记录中, Toronto, Canada, July 9-14, 2023. Association for Computational Linguistics, 2023, 第 1953-1969 页。
[194] X. Li, F. Yan, X. Zhao, Y. Wang, B. Chen, H. Guo, 和 R. Tang, “HAMUR: 超适配器用于多域推荐,” 在 Proceedings of the 32nd ACM International Conference on Information and Knowledge Management 的记录中, Birmingham, United Kingdom. ACM, 2023, 第 1268-1277 页。
[195] Z. Tang, Z. Huan, Z. Li, X. Zhang, J. Hu, C. Fu, J. Zhou, 和 C. Li, “One model for all: 大型语言模型是领域无关的推荐系统,” CoRR, 第 abs/2310.14304 卷, 2023.
[196] Y. Gong, X. Ding, Y. Su, K. Shen, Z. Liu, 和 G. Zhang, “用于冷启动场景的统一搜索和推荐基础模型,” 在 Proceedings of the 32nd ACM International Conference on Information and Knowledge Management 的记录中, Birmingham, United Kingdom. ACM, 2023, 第 4595-4601 页。
[197] Z. Fu, X. Li, C. Wu, Y. Wang, K. Dong, X. Zhao, M. Zhao, H. Guo, 和 R. Tang, “通过大型语言模型实现多域 CTR 预测的统一框架,” CoRR, 第 abs/2312.10743 卷, 2023.
[198] J. Fu, F. Yuan, Y. Song, Z. Yuan, M. Cheng, S. Cheng, J. Zhang, J. Wang, 和 Y. Pan, “探索推荐系统中的适配器迁移学习:实证研究和实践见解,” CoRR, 第 abs/2305.15036 卷, 2023.
[199] L. Guo, Z. Lu, J. Yu, Q. V. H. Nguyen, 和 H. Yin, “跨域推荐中的提示增强联邦内容表示学习,” 在 Proceedings of the ACM Web Conference 2024 的记录中, WWW 2024, 新加坡, May 13-17, 2024. ACM, 2024, 第 3139-3149 页。
[200] G. Zhang, “以用户为中心的对话推荐:使用大语言模型适应用户需求,” 在 Proceedings of the 17th ACM Conference on Recommender Systems 的记录中, 新加坡。ACM, 2023, 第 1349-1354 页。
[201] L. Wang, H. Hu, L. Sha, C. Xu, K. Wong, 和 D. Jiang, “知识图谱微调大规模预训练语言模型用于对话推荐,” CoRR, 第 abs/2110.07477 卷, 2021.
[202] Z. He, Z. Xie, R. Jha, H. Steck, D. Liang, Y. Feng, B. P. Majumder, N. Kallus, 和 J. J. McAuley, “大语言模型作为零样本对话推荐者,” 在 Proceedings of the 32nd ACM International Conference on Information and Knowledge Management 的记录中, Birmingham, United Kingdom. ACM, 2023, 第 720-730 页。
[203] G. Lin 和 Y. Zhang, “人工通用推荐(AGR)的火花:ChatGPT 的早期实验,” CoRR, 第 abs/2305.04518 卷, 2023.
[204] K. D. Spurlock, C. Acun, E. Saka, 和 O. Nasraoui, “ChatGPT 用于对话推荐:通过反馈重新提示细化推荐,” CoRR, 第 abs/2401.03605 卷, 2024.
[205] M. Ravaut, H. Zhang, L. Xu, A. Sun, 和 Y. Liu, “参数高效对话推荐系统作为一种语言处理任务,” 在 Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2024 - Volume 1: Long Papers, St. Julian’s, Malta, March 17-22, 2024 的记录中。计算语言学协会, 2024, 第 152-165 页。
[206] X. Wang, X. Tang, W. X. Zhao, J. Wang, 和 J.-R. Wen, “重新思考大语言模型时代的对话推荐评估,” arXiv preprint arXiv:2305.13112, 2023.
[207] J. Harte, W. Zorgdrager, P. Louridas, A. Katsifodimos, D. Jannach, 和 M. Fragkoulis, “利用大语言模型进行顺序推荐,” 在 Proceedings of the 17th ACM Conference on Recommender Systems 的记录中, 新加坡。ACM, 2023, 第 1096-1102 页。
[208] Y. Wang, Z. Liu, J. Zhang, W. Yao, S. Heinecke, 和 P. S. Yu, “DRDT: 基于 LLM 的顺序推荐动态反思与发散思维,” CoRR, 第 abs/2312.11336 卷, 2023.
[209] Y. Wu, R. Xie, Y. Zhu, F. Zhuang, X. Zhang, L. Lin, 和 Q. He, “个性化提示用于顺序推荐,” CoRR, 第 abs/2205.09666 卷, 2022.
[210] S. Qiao, C. Gao, J. Wen, W. Zhou, Q. Luo, P. Chen, 和 Y. Li, “LLM4SBR: 一种轻量且有效的会话推荐框架,集成大语言模型,” CoRR, 第 abs/2402.13840 卷, 2024.
[211] Y. Li, X. Zhai, M. Alzantot, K. Yu, I. Vulic, A. Korhonen, 和 M. Hammad, “Calrec: 对比对齐生成 LLMs 用于顺序推荐,” CoRR, 第 abs/2405.02429 卷, 2024.
[212] S. Xu, W. Hua, 和 Y. Zhang, “Openp5: 基础模型推荐基准测试,” CoRR, 第 abs/2306.11134 卷, 2023.
[213] X. Li, Y. Zhang, 和 E. C. Malthouse, “ChatGPT 在新闻推荐中的初步研究:个性化、供应商公平性和假新闻,” 在 Proceedings of the International Workshop on News Recommendation and Analytics co-located with the 2023 ACM Conference on Recommender Systems 的记录中, 新加坡, ser. CEUR Workshop Proceedings, vol. 3561. CEUR-WS.org, 2023.
[214] S. Dai, N. Shao, H. Zhao, W. Yu, Z. Si, C. Xu, Z. Sun, X. Zhang, 和 J. Xu, “揭示 ChatGPT 在推荐系统中的能力,” 在 Proceedings of the 17th ACM Conference on Recommender Systems 的记录中, 新加坡。ACM, 2023, 第 1126-1132 页。
[215] Z. Liu, S. Mei, C. Xiong, X. Li, S. Yu, Z. Liu, Y. Gu, 和 G. Yu, “文本匹配通过减少流行偏差改进顺序推荐,” 在 Proceedings of the 32nd ACM International Conference on Information and Knowledge Management 的记录中, Birmingham, United Kingdom。ACM, 2023, 第 1534-1544 页。
[216] S. Luo, Y. Yao, B. He, Y. Huang, A. Zhou, X. Zhang, Y. Xiao, M. Zhan, 和 L. Song, “通过相互增强和自适应聚合将大语言模型集成到推荐中,” CoRR, 第 abs/2401.13870 卷, 2024.
[217] V. W. Anelli, A. Belligín, T. Di Noia, D. Jannach, 和 C. Pomo, “Top-n 推荐算法:追求最先进状态,” 在 Proceedings of the 30th ACM 用户建模、自适应和个性化国际会议的记录中, 2022, 第 121-131 页。
[218] A. Boz, W. Zorgdrager, Z. Kotti, J. Harte, P. Louridas, V. Karakoidas, D. Jannach, 和 M. Fragkoulis, “通过 LLM 改进顺序推荐,” ACM Transactions on Recommender Systems, 2024.
[219] D. Jannach, A. Manzoor, W. Cai, 和 L. Chen, “对话推荐系统综述,” ACM Comput. Surv., 第 54 卷, 第 5 期, 第 105:1-105:36 页, 2022. Y. Sun 和 Y. Zhang, “对话推荐系统,” 在第 41 届国际 ACM SIGIR 信息检索研究与发展会议的记录中,Ann Arbor, MI, USA。ACM, 2018, 第 235-244 页。
[221] K. Zhou, W. X. Zhao, S. Bian, Y. Zhou, J. Wen, 和 J. Yu, “通过知识图谱语义融合改进对话推荐系统,” 在第 26 届 ACM SIGKDD 知识发现与数据挖掘国际会议的记录中,CA, USA。ACM, 2020, 第 1006-1014 页。
[222] J. M. Lichtenberg, A. Buchholz, 和 P. Schwöbel, “大语言模型作为推荐系统:流行偏差研究,” arXiv preprint arXiv:2406.01285, 2024.
[223] F. Zhu, Y. Wang, C. Chen, J. Zhou, L. Li, 和 G. Liu, “跨域推荐:挑战、进展和前景,” 在第三十届国际人工智能联合会议的记录中,虚拟活动 / 蒙特利尔,加拿大。ijcai.org, 2021, 第 4721-4728 页。
[224] K. Zhou, J. Zhang, 和 C. Li, “Bundlegen: 通过扩散模型生成捆绑推荐,” 在 Web Conference 的记录中, 2023.
[225] Y. Wang, M. Zhang, 和 J. Liu, “Musicgen: 使用预训练语言模型进行个性化音乐播放列表生成,” 在第 46 届国际 ACM SIGIR 会议的记录中, 2023.
[226] Y. Yao, C. Xu, 和 J. Wang, “生成新闻推荐与用户兴趣感知文档合成,” 在 EMNLP Findings 中, 2022.
[227] X. Li, L. Wu, 和 F. Liu, “Prompt4newsrec: 基于提示的生成新闻推荐与用户总结,” arXiv preprint arXiv:2305.14520, 2023.
[228] A. Acharya 和 T. Smith, “利用大型语言模型生成冷启动推荐中的项目元数据,” 在 RecSys, 2023.
[229] Y. Huang 和 Y. Zhang, “Coldllm: 通过 LLMs 生成用户-项目交互以进行冷启动推荐,” 在 WSDM, 2024.
[230] F. Sun, J. Liu, J. Wu, C. Pei, X. Lin, W. Ou, 和 P. Jiang, “Bert4rec: 使用双向编码器 Transformer 表示进行顺序推荐,” 在 Proceedings of the 28th ACM 国际信息与知识管理会议的记录中, 2019, 第 1441-1450 页。
[231] B. Jin, H. Zeng, G. Wang, X. Chen, T. Wei, R. Li, Z. Wang, Z. Li, Y. Li, H. Lu 等人, “Language models as semantic indexers,” arXiv preprint arXiv:2310.07815, 2023.
[232] Z. Chu, Y. Wang, Q. Cui, L. Li, W. Chen, Z. Qin, 和 K. Ren, “Llm-guided multi-view hypergraph learning for human-centric explainable recommendation,” arXiv preprint arXiv:2401.08217, 2024.
[233] Y. Cao, N. Mehta, X. Yi, R. Keshavan, L. Heldt, L. Hong, E. H. Chi, 和 M. Sathiamoorthy, “Aligning large language models with recommendation knowledge,” arXiv preprint arXiv:2404.00245, 2024.
[234] Q. Liu, N. Chen, T. Sakai, 和 X.-M. Wu, “Once: Boosting content-based recommendation with both open-and closed-source large language models,” 在 Proceedings of the 17th ACM International Conference on Web Search and Data Mining 的记录中, 2024, 第 452-461 页。
[235] C. Zhang, Y. Sun, M. Wu, J. Chen, J. Lei, M. Abdul-Mageed, R. Jin, A. Liu, J. Zhu, S. Park 等人, “Embsum: 利用大型语言模型的摘要能力进行基于内容的推荐,” 在 Proceedings of the 18th ACM Conference on Recommender Systems 的记录中, 2024, 第 1010-1015 页。
[236] T. Song, W. Chao, 和 H. Liu, “Large language model enhanced hard sample identification for denoising recommendation,” arXiv preprint arXiv:2409.10343, 2024.
[237] S. Yang, W. Ma, P. Sun, Q. Ai, Y. Liu, M. Cai, 和 M. Zhang, “Sequential recommendation with latent relations based on large language model,” in Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, pp. 335-344.
[238] L. Li, Y. Zhang, 和 L. Chen, “Prompt distillation for efficient llm-based recommendation,” in CIKM, 2023.
[239] P. Cao 和 P. Liò, “Genrec: Generative sequential recommendation with large language models,” arXiv preprint arXiv:2407.21191, 2024.
[240] K. Bao, J. Zhang, W. Wang, Y. Zhang, Z. Yang, Y. Luo, C. Chen, F. Feng, 和 Q. Tian, “A bi-step grounding paradigm for large
language models in recommendation systems,” ACM Transactions on Recommender Systems, 2023.
[241] X. Wang, J. Cui, Y. Suzuki, 和 F. Fukumoto, “Rdrec: Rationale distillation for llm-based recommendation,” arXiv preprint arXiv:2405.10587, 2024.
[242] Y. Zhang, W. Yu, E. Zhang, X. Chen, L. Hu, P. Jiang, 和 K. Gai, “Recgpt: Generative personalized prompts for sequential recommendation via chatgpt training paradigm,” arXiv preprint arXiv:2404.08675, 2024.
[243] Y. Zhang 和 X. Chen, “可解释性推荐:综述与新视角,” Found. Trends Inf. Retr., 第 14 卷, 第 1 期, 第
1
−
101
,
2020
1-101,2020
1−101,2020 页。
[244] L. Wang 和 E.-P. Lim, “使用大规模预训练语言模型进行零样本下一项推荐,” arXiv preprint arXiv:2306.06078, 2023.
[245] A. Agrawal, N. Kedia, A. Panwar, J. Mohan, N. Kwatra, B. Gulavani, A. Tumanov, 和 R. Ramjee, “Taming (Throughput-Latency) tradeoff in {LLM} inference with {Sarathi-Serve},” 在 18th USENIX 操作系统设计与实现研讨会 (OSDI 24), 2024, 第 117-134 页。
[246] H. Ghosh, “Enabling efficient serverless inference serving for llm (large language model) in the cloud,” arXiv preprint arXiv:2411.15664, 2024.
[247] J. Lu, K. Hall, J. Ma, 和 J. Ni, “Hyrr: Hybrid infused reranking for passage retrieval,” arXiv preprint arXiv:2212.10528, 2022.
[248] W. Shan, L. Meng, T. Zheng, Y. Luo, B. Li, T. Xiao, J. Zhu 等人, “Early exit is a natural capability in transformer-based models: An empirical study on early exit without joint optimization,” arXiv preprint arXiv:2412.01455, 2024.
[249] Y. An, Y. Cheng, S. J. Park, 和 J. Jiang, “Hyperrag: Enhancing quality-efficiency tradeoffs in retrieval-augmented generation with reranker kv-cache reuse,” arXiv preprint arXiv:2504.02921, 2025.
[250] M. Li 等人, “Recommendation models meet language models: A survey,” arXiv preprint arXiv:2402.00072, 2024.
[251] M. Jin, Q. Wen, Y. Liang, C. Zhang, S. Xue, X. Wang, J. Zhang, Y. Wang, H. Chen, X. Li, S. Pan, V. S. Tseng, Y. Zheng, L. Chen, 和 H. Xiong, “Large models for time series and spatio-temporal data: A survey and outlook,” CoRR, 第 abs/2310.10196 卷, 2023.
[252] N. Gruver, M. A. Finzi, S. Qiu, 和 A. G. Wilson, “Large language models are zero-shot time series forecasters,” 在 Thirty-seventh Conference on Neural Information Processing Systems 的记录中, 2023.
[253] Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, Q. Guo, M. Wang, 和 H. Wang, “Retrieval-augmented generation for large language models: A survey,” CoRR, 第 abs/2312.10997 卷, 2023.
[254] J. Lin, R. Shan, C. Zhu, K. Du, B. Chen, S. Quan, R. Tang, Y. Yu, 和 W. Zhang, “Rella: Retrieval-enhanced large language models for lifelong sequential behavior comprehension in recommendation,” CoRR, 第 abs/2308.11131 卷, 2023.
[255] Y. Zhang, X. Chen 等人, “Explainable recommendation: A survey and new perspectives,” Foundations and Trends® in Information Retrieval, 第 14 卷, 第 1 期, 第 1-101 页, 2020.
[256] I. O. Gallegos, R. A. Rossi, J. Barrow, M. M. Tanjim, S. Kim, F. Dernoncourt, T. Yu, R. Zhang, 和 N. K. Ahmed, “Bias and fairness in large language models: A survey,” CoRR, 第 abs/2309.00770 卷, 2023.
[257] I. O. Gallegos, R. A. Rossi, J. Barrow, M. M. Tanjim, T. Yu, H. Deilamsalehy, R. Zhang, S. Kim, 和 F. Dernoncourt, “Self-debiasing large language models: Zero-shot recognition and reduction of stereotypes,” CoRR, 第 abs/2402.01981 卷, 2024.
[258] Y. Yao, J. Duan, K. Xu, Y. Cai, E. Sun, 和 Y. Zhang, “A survey on large language model (LLM) security and privacy: The good, the bad, and the ugly,” CoRR, 第 abs/2312.02003 卷, 2023.
[259] Z. Wan, A. Cheng, Y. Wang, 和 L. Wang, “Information leakage from embedding in large language models,” CoRR, 第 abs/2405.11916 卷, 2024.
[260] C. Song 和 A. Raghunathan, “Information leakage in embedding models,” 在 CCS '20: 2020 ACM SIGSAC 计算机和通信安全会议, 虚拟活动, 美国, 11月 9-13 日, 2020。ACM, 2020, 第 377-390 页。
[261] S. Wozniak, B. Koptyra, A. Janz, P. Kazienko, 和 J. Kocon, “个性化大语言模型,” CoRR, 第 abs/2402.09269 卷, 2024.
[262] K. Zhang, L. Qing, Y. Kang, 和 X. Liu, “带参数化记忆注入的个性化 LLM 响应生成,” CoRR, 第 abs/2404.03565 卷, 2024.
[263] C. Wang, M. Zhang, W. Ma, Y. Liu, 和 S. Ma, “合唱:具有知识和时间意识的项目建模用于顺序推荐,” 在第 43 届国际 ACM SIGIR 信息检索研究与发展会议的记录中, SIGIR 2020, 虚拟活动, 中国, 2020 年 7 月 25 日 - 30 日。ACM, 2020, 第 109-118 页。
[264] N. Kitaev, L. Kaiser, 和 A. Levskaya, “Reformer: 高效的变压器,” 在国际学习表示会议, 2019.
[265] I. Beltagy, M. E. Peters, 和 A. Cohan, “Longformer: 长文档变压器,” arXiv preprint arXiv:2004.05150, 2020.
[266] J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, 和 Y. Liu, “Roformer: 增强旋转位置嵌入的变压器,” Neurocomputing, 第 568 卷, 第 127063 页, 2024.
[267] OpenAI, “Gpt-4 技术报告,” OpenAI, 2023.
[268] M. R. Glass, A. Gliozzo, R. Chakravarti, A. Ferritto, L. Pan, G. P. S. Bhargav, D. Garg, 和 A. Sil, “Span selection pre-training for question answering,” 在 Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online. Association for Computational Linguistics, 2020, 第 2773-2782 页。
[269] S. M. Xie, S. Santurkar, T. Ma, 和 P. Liang, “Data selection for language models via importance resampling,” CoRR, 第 abs/2302.03169 卷, 2023.
[270] C. Zhou, P. Liu, P. Xu, S. Iyer, J. Sun, Y. Mao, X. Ma, A. Efrat, P. Yu, L. Yu, S. Zhang, G. Ghosh, M. Lewis, L. Zettlemoyer, 和 O. Levy, “LIMA: less is more for alignment,” CoRR, 第 abs/2305.11206 卷, 2023.
[271] Y. Cao, Y. Kang, 和 L. Sun, “Instruction mining: High-quality instruction data selection for large language models,” CoRR, 第 abs/2307.06290 卷, 2023.
[272] Y. Wang, C. Tian, B. Hu, Y. Yu, Z. Liu, Z. Zhang, J. Zhou, L. Pang, 和 X. Wang, “Can small language models be good reasoners for sequential recommendation?” 在 Proceedings of the ACM Web Conference 2024, WWW 2024, 新加坡, May 13-17, 2024 的记录中。ACM, 2024, 第 3876-3887 页。
[273] Y. Hou, Z. He, J. McAuley, 和 W. X. Zhao, “Learning vectorquantized item representation for transferable sequential recommenders,” 在 ACM Web Conference 的记录中, 2023, 第
1162
−
1171
1162-1171
1162−1171 页。
[274] T. Chen, J. Frankle, S. Chang, S. Liu, Y. Zhang, Z. Wang, 和 M. Carbin, “The lottery ticket hypothesis for pre-trained BERT networks,” 在 Advances in Neural Information Processing Systems: Annual Conference on Neural Information Processing Systems 的记录中, virtual, 2020.
[275] X. Jiao, Y. Yin, L. Shang, X. Jiang, X. Chen, L. Li, F. Wang, 和 Q. Liu, “Tinybert: Distilling BERT for natural language understanding,” 在 Findings of the Association for Computational Linguistics: EMNLP 2020 的记录中, Online Event, 16-20 November 2020, ser. Findings of ACL。计算语言学协会, 2020, 第 4163-4174 页。
[276] J. Lin, J. Tang, H. Tang, S. Yang, X. Dang, 和 S. Han, “AWQ: activation-aware weight quantization for LLM compression and acceleration,” CoRR, 第 abs/2306.00978 卷, 2023.
[277] H. Chen, Y. Zhang, Q. Zhang, H. Yang, X. Hu, X. Ma, Y. Yanggong, 和 J. Zhao, “Maybe only
0.5
%
0.5 \%
0.5% data is needed: A preliminary exploration of low training data instruction tuning,” CoRR, 第 abs/2305.09246 卷, 2023.
[278] J. Mu, X. L. Li, 和 N. D. Goodman, “Learning to compress prompts with gist tokens,” CoRR, 第 abs/2304.08467 卷, 2023.
[279] A. Mallen, A. Asai, V. Zhong, R. Das, D. Khashabi, 和 H. Hajishirzi, “When not to trust language models: Investigating effectiveness of parametric and non-parametric memories,” 在 Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada。计算语言学协会, 2023, 第 9802-9822 页。
[280] C. Huang, R. Wang, K. Xie, T. Yu, 和 L. Yao, “Learn when (not) to trust language models: A privacy-centric adaptive model-aware approach,” arXiv preprint arXiv:2404.03514, 2024.
[281] G. E. Hinton, O. Vinyals, 和 J. Dean, “Distilling the knowledge in a neural network,” CoRR, 第 abs/1503.02531 卷, 2015.
[282] Y. Li, Y. Yu, C. Liang, P. He, N. Karampatziakis, W. Chen, 和 T. Zhao, “Loftq: Lora-fine-tuning-aware quantization for large language models,” CoRR, 第 abs/2310.08659 卷, 2023.
[283] K. Kaur 和 C. Shah, “Efficient and responsible adaptation of large language models for robust top-k recommendations,” arXiv preprint arXiv:2405.00824, 2024.
[284] B. Deng, W. Wang, F. Feng, Y. Deng, Q. Wang, 和 X. He, “Attack prompt generation for red teaming and defending large language models,” 在 Findings of the Association for Computational Linguistics 的记录中, 新加坡。计算语言学协会, 2023, 第 2176-2189 页。
[285] J. Zhang, Y. Liu, Q. Liu, S. Wu, G. Guo, 和 L. Wang, “对基于大语言模型的推荐系统的隐秘攻击,” CoRR, 第 abs/2402.14836 卷, 2024.
[286] Y. Wang, W. Zhong, L. Li, F. Mi, X. Zeng, W. Huang, L. Shang, X. Jiang, 和 Q. Liu, “Aligning large language models with human: A survey,” CoRR, 第 abs/2307.12966 卷, 2023.
[287] G. Xu, J. Liu, M. Yan, H. Xu, J. Si, Z. Zhou, P. Yi, X. Gao, J. Sang, R. Zhang, J. Zhang, C. Peng, F. Huang, 和 J. Zhou, “Cvalues: Measuring the values of chinese large language models from safety to responsibility,” CoRR, 第 abs/2307.09705 卷, 2023.
[288] Y. Yu, Q. Liu, L. Wu, R. Yu, S. L. Yu, 和 Z. Zhang, “Untargeted attack against federated recommendation systems via poisonous item embeddings and the defense,” 在 Thirty-Seventh AAAI Artificial Intelligence Conference 的记录中, Washington, DC, USA。AAAI Press, 2023, 第 4854-4863 页。
[289] C. Chen, F. Sun, M. Zhang, 和 B. Ding, “Recommendation unlearning,” 在 ACM Web Conference 的记录中, 虚拟活动, 里昂, 法国。ACM, 2022, 第 2768-2777 页。
[290] H. Wang, J. Lin, B. Chen, Y. Yang, R. Tang, W. Zhang, 和 Y. Yu, “Towards efficient and effective unlearning of large language models for recommendation,” CoRR, 第 abs/2403.03536 卷, 2024.
参考论文:https://arxiv.org/pdf/2504.16420



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











