






Azam Ikram*
Purdue University
Xiang Li*
Purdue University
摘要
大型语言模型(LLMs)的快速发展推动了对更高效服务策略的需求。在此背景下,效率指的是满足其服务水平目标(SLOs)的请求数量比例,特别是首次生成时间(TTFT)和标记间时间(TBT)。然而,现有系统往往在优化一个指标时牺牲另一个。
我们介绍了Ascendra,一种设计用于同时满足TTFT和TBT SLOs的LLM服务系统。Ascendra的核心洞察是,随着请求接近其截止时间,其紧迫性会发生变化。为了利用这一点,Ascendra将GPU资源划分为两种实例类型:低优先级和高优先级。低优先级实例通过不按到达顺序处理请求来最大化吞吐量,但存在请求饥饿的风险。为了解决这个问题,Ascendra使用性能模型预测可能错过其SLO的请求,并主动将其卸载到高优先级实例上。高优先级实例针对低延迟执行进行了优化,处理接近截止时间的紧急请求。这种分区架构使Ascendra能够有效地平衡高吞吐量和低延迟。广泛的评估表明,与vLLM和SarathiServe相比,Ascendra可以将系统吞吐量提高至1.7倍,同时满足TTFT和TBT SLOs。
1 引言
近年来,大型语言模型(LLMs)已成为各种应用的重要组成部分,从回答用户查询到辅助软件开发。随着对LLM驱动服务需求的不断增长,各家公司正在竞相将LLM功能集成到他们的平台上。在研究方面,大量努力被投入到使LLM服务更加高效。近期的研究集中在提高执行速度[4, 7]、优化I/O访问模式[8]以及确保并发请求间的公平性[20]。本文中,我们研究了高效的LLM服务问题,并提出了一种能够在不依赖昂贵网络互连的情况下实现高吞吐量并尊重延迟服务水平目标(SLOs)的系统。
LLM推理通常包括两个阶段:预填充和解码。在预填充阶段,模型处理输入提示并生成第一个标记;从请求到达到这个标记的时间被称为首次标记时间(TTFT)。在解码阶段,模型自回归地生成后续标记,标记间时间(TBT)测量两个连续标记生成之间的延迟。现实世界的应用通常对TTFT和TBT都施加严格的SLOs。服务系统的有效性通过其有效吞吐量来评估——即满足这两个SLO的请求比例。
若干先前的工作探讨了优化TTFT和TBT之间的权衡。例如,vLLM [8] 优先进行预填充以减少TTFT,但增加了生成停滞的可能性。最近,Sarathi-Serve [1] 引入了分块预填充,通过交错解码与预填充来改进TBT,但由于频繁的I/O访问导致较高的TTFT。另一种方法,DistServe [29],通过在不同的GPU上运行它们来分离预填充和解码。尽管简单,这种分离会导致资源利用率低下——预填充计算密集但内存轻,而解码计算轻但内存重——并且需要昂贵的硬件(如NVLink、NVSwitch、InfiniBand)在GPU和节点之间传输大量数据(KV缓存)。
在这项工作中,我们提出了一种混合方法,在不依赖昂贵网络互连的情况下实现高有效吞吐量。我们提出了三个关键观察结果:(1) 请求在违反其TTFT SLO之前可容忍的延迟取决于提示长度和请求在系统中的时间长短,(2) 先进先出 (FCFS) 调度会导致队首阻塞,(3) 解码请求的连续执行对于满足TBT目标至关重要。基于这些见解,我们设计了Ascendra,一个系统,它:(1) 根据请求接近违反TTFT SLO的程度动态分配优先级,(2) 启用非顺序执行以避免队首阻塞,使用当前优先级作为调度策略,(3) 利用两种不同类型的实例——每种实例分别针对吞吐量或延迟进行了优化——根据工作负载特征专门化执行。这种分离使得工作负载感知资源分配和更好的SLO遵守成为可能。
为了说明这些见解的影响,考虑一个包含五个请求和TTFT SLO为五个时间单位的例子,如图1a所示。在vLLM下,前四个请求在 t = 0 t=0 t=0到达,并以轮询方式分布在两个GPU上。由于vLLM严格按照FCFS顺序处理请求,第五个请求(E)在 t = 1 t=1 t=1到达时必须等待所有较早的请求完成,才能开始执行,从而产生四单位的延迟。当请求E开始其预填充时,它只剩下一时间单位来满足其TTFT SLO。然而,由于E的预填充预计需要两个时间单位,E不可避免地会违反其TTFT目标。
相比之下,考虑相同的场景在Ascendra下,GPU资源被划分为低优先级(LP)和高优先级(HP)实例。只有当HP实例的队列为空时,才会接受新请求;否则,请求会被路由到LP实例。LP实例使用内部值函数来确定执行顺序,优化吞吐量而不是严格遵循到达顺序。在 t = 1 t=1 t=1时,请求E被转发到空闲的HP实例。在 t = 3 t=3 t=3时,LP实例持有请求C和D,并选择执行D,同时将C卸载到HP,因为如果延迟,C预计会错过其TTFT SLO。这种主动卸载确保了紧急请求得到及时处理,同时LP实例保持高吞吐量。我们在图1中验证了这种行为,显示Ascendra通过灵活管理延迟敏感请求提高了吞吐量和有效吞吐量。
在本文中,我们做出了以下贡献:
- 我们识别出现有LLM服务系统中的关键挑战,强调以FCFS方式处理延迟敏感工作负载的低效性。我们对TTFT-TBT权衡进行了深入分析。
-
- 我们设计并实现了一种混合服务架构,该架构将GPU资源划分为专用实例类型。我们引入了一种优先级感知调度策略,该策略以批量粒度动态分配请求优先级。这一设计通过确保紧急请求的及时服务同时保持高系统吞吐量显著提高了有效吞吐量。
-
- 我们广泛评估了我们的系统在不同模型和数据集上的表现,展示了Ascendra相对于最先进的基线在不需要额外硬件资源的情况下提高了有效吞吐量。
2 背景
2.1 LLM推理阶段
LLM服务通常涉及两个不同的阶段:预填充阶段和解码阶段。在接收到请求后,模型会对整个输入提示进行一次前向传递,生成键值(KV)缓存并生成第一个标记——这是预填充阶段。在随后的解码阶段,模型自回归地生成一个标记,每个生成的标记都会附加到输入中并再次通过模型以生成下一个。解码阶段将持续进行,直到达到停止条件,例如达到标记限制或遇到序列结束标记。
最近的研究[1,19,29]表明,这两个阶段在资源需求上有所不同:预填充是计算密集型的,而解码是内存密集型的。在预填充过程中,模型并行处理所有提示标记,这暴露了高度的并行性,可以完全饱和GPU计算资源,使其高度计算密集。相反,解码阶段需要读取之前生成的KV缓存并一次生成一个标记,需要频繁的内存访问,这引入了内存带宽瓶颈并限制了计算利用率。
2.2 LLM调度策略
现有的LLM调度策略可以根据其主要设计目标大致分为三类:优先预填充、优先解码和基于分解的策略。
像vLLM [8]和Orca [26]这样的LLM推理服务器采用了一种优先预填充策略,通过确保第一个标记的生成来强调响应性,从而最小化TTFT。然而,频繁中断正在进行的解码操作以服务新的预填充请求可能会导致生成停滞[1],可能降低吞吐量。
在另一端,像TensorRT-LLM [16]和FasterTransformer [15]这样的推理框架采用了优先解码调度。这些系统通过完全解码一批请求后再接受新的请求来优先考虑吞吐量。虽然这对批处理执行效率很高,但这种方法可能会导致较长的调度延迟,因为新请求必须等待当前请求完成。为了缓解这一点,Sarathi-Serve [1]引入了分块预填充,允许在每个解码批次末尾附加部分预填充请求。虽然这种搭便车机制避免了停滞并保持了标记生成的连续性,但它会产生过多的内存流量并在预填充和解码阶段之间造成干扰,延长了两者的执行时间。由于这种额外的延迟会在所有排队请求中累积,最终会导致TTFT升高,损害低TBT保证,因为请求必须同时满足TTFT和TBT SLO才能计入有效吞吐量。
DistServe [29]通过分解采取了一种正交的方法,跨不同机器分离预填充和解码阶段。这消除了节点内的资源竞争,使两者都能在没有生成停滞的情况下实现高吞吐量和低延迟。然而,这种设计引入了新的挑战:预填充阶段生成的KV缓存——每个请求通常有几个千兆字节——必须在节点间传输。为了支持这种级别的高吞吐量数据移动,需要专用的互连设备,如NVLink和NVSwitch。更重要的是,由于机器现在专用于单个阶段,每个阶段都会成为一个瓶颈——预填充节点面临增加的计算负载,而解码节点则面临高内存压力,可能导致潜在的利用率不足或新的可扩展性限制。
2.3 键值缓存管理
在LLM推理的解码阶段,必须反复访问为提示和生成标记计算的键值对,直到请求完成。为了最小化内存访问延迟,这些KV对必须驻留在GPU上的高带宽内存(HBM)中。然而,即使是最先进的GPU,如A100和H100,也受到80 GB HBM容量的限制。例如,存储LLaMA3-8B中单个标记的KV缓存大约需要512 KB —— 计算为 2(键和值)× 4096(隐藏维度)× 32(层数)× 2 字节(FP16精度)。如果没有有效的内存管理,仅仅几十个并发请求就可能迅速耗尽HBM。
为了解决这个问题,vLLM引入了PagedAttention [8],一种将GPU内存划分为固定大小块的内存管理机制。这些块会随着请求解码长度的增长动态分配给请求,显著减轻内存碎片化。Llumnix [21]进一步发展了这一设计,支持跨推理实例的实时KV迁移。这种方法在实例级别平衡内存使用,减少抢占引起的开销,并提高整体端到端性能。
2.4 请求抢占
当GPU内存耗尽且无法继续解码时,会发生请求抢占。为了缓解内存压力并让其他请求取得进展,一些正在进行的解码任务必须暂时暂停并从GPU HBM中驱逐。这通常通过两种策略之一来处理。
第一种方法,用于vLLM和SarathiServe [1,8]等系统中,通过将生成的标记附加到提示并将其放回等待队列中来驱逐请求,并释放相关联的内存。当请求重新调度时,必须从头重新计算其KV缓存,导致重新计算开销。第二种方法,由DistServe [29]采用,则选择卸载内存而不是重新计算。当内存压力较高时,一些正在进行的请求会暂时暂停,其KV缓存会被转移到主机CPU内存中。一旦有足够的GPU内存可用,这些请求及其关联的KV数据将被重新加载,解码恢复。
3 挑战
随着LLM请求通过预填充和解码两个不同阶段,有效地调度和服务它们带来了独特的系统级挑战。
3.1 预填充的挑战
预填充阶段消耗大量的计算资源,因为它需要在单次前向传递中为整个提示生成一个键值(KV)缓存。由于提示长度在请求之间差异很大,执行时间和资源需求不可预测。尽管许多系统试图最小化TTFT,但由于两个核心挑战,它们往往无法满足SLOs:
提示长度不可预测。请求提示长度变化范围很广(图8),从几十到几千个标记不等,这直接影响预填充执行时间。因此,在请求违反其TTFT SLO之前可用的时间不是固定的;它取决于提示长度和请求在系统中等待的时间。尽管存在这种可变性,许多系统仍然依赖于FCFS方法,这可能导致一些请求在其SLO达到之前完成,导致资源利用效率低下,同时延迟其他请求。
相反,我们建议在靠近其TTFT SLO时调度预填充请求。由于提示长度自然可以预测执行时间,因此可以用来推断预填充阶段请求的紧迫性和优先级。通过优先处理长时间运行或接近截止日期的请求,这种方法提高了整体效率和响应能力。注意,我们对紧迫性和优先级的定义与Llumnix [21]的根本不同在于后者根据应用程序级别的SLO分类请求的紧迫性和优先级。这是一个更容易处理的任务,因为具有相似SLO的应用程序请求可以分组并路由到针对相同目标的机器上。相比之下,我们的方法在更细粒度上运行,利用特定提示的特征(即提示长度和它们在系统中的停留时间)而非粗略的应用程序级别SLO。
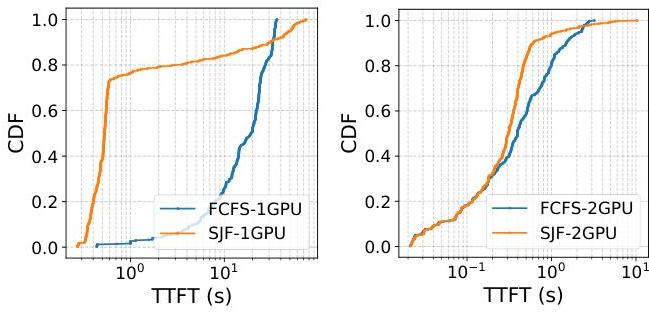
图2. 相比于FCFS,SJF具有较低的延迟,但尾部较长。仅仅增加GPU数量并不能消除尾部。
| Llama-3.1 | Qwen2.5 | DeepSeek-v3 | |||
|---|---|---|---|---|---|
| 模型参数 # | 8B | 70B | 405B | 3B | 37 B 1 37 B^{1} 37B1 |
| KV 缓存大小 | 0.24 GB | 0.61 GB | 0.96 GB | 0.068 GB | 3.25 GB |
表1. 不同模型下FP16格式的2000-token请求的KV缓存内存使用情况。较大模型每请求消耗显著更多的内存。
队首阻塞。由于TTFT主要由提示长度决定,请求的提示长度实际上决定了其预填充执行时间。在FCFS系统中,较长的请求可能会阻塞后来到达的较短请求,这是一种经典的队首阻塞情况。这种低效可能导致即使有足够的计算资源可用,短请求仍会出现重大延迟。解决此问题需要一种能平衡执行顺序与请求紧迫性和资源约束的调度策略。
然而,仅仅采用不同的调度策略并不能完全解决问题。例如,图2比较了vLLM在FCFS和最短作业优先(SJF)下的TTFT。虽然SJF显著改善了大多数请求的TTFT,但引入了明显的长尾效应:较长的请求经常被饿死,导致过度延迟,常常违反其TTFT SLO。因此,有效的服务系统必须在平衡中找到解决方案:优先处理较短的请求以维持高吞吐量,同时确保较长的请求也能及时处理,即使它们可能会带来稍高的计算开销或资源利用率下降。
3.2 解码的挑战
预填充阶段完成后,请求进入解码阶段,模型在这里自回归地生成一个标记,直到序列结束。我们在解码阶段概述了以下挑战。未知的解码迭代次数。与执行时间随提示长度缩放的预填充不同,解码本质上是不可预测的:生成的标记数量差异很大,从几十到几千不等(图8)。这种不确定性使得调度变得困难:系统无法提前确定解码请求将持续多久或引入多少计算和内存开销。此外,解码工作负载必须与新的预填充请求一起管理,这可能会引入额外的需求。鉴于解码通常比TTFT有更严格的SLO,调度程序必须动态平衡持续解码请求和接受新预填充工作负载之间的优先级。
KV缓存增长和内存压力。虽然预填充从提示中创建了一个固定的KV缓存矩阵,但在每个步骤中解码都会追加两个向量(键和值)。累积的KV缓存可能会迅速增长,对于大型模型的长输出,通常会达到几GB(表1),对有限的GPU内存施加持续压力。这种快速扩展施加了内存压力,限制了并发解码请求的数量,并增加了内存碎片化和抢占的风险。
计算资源利用率不足。由于KV缓存使得之前计算的注意力值可以重用,解码所需的每个标记的计算量比预填充少。这种工作负载特性的转变允许调度程序将多个解码请求组合在一起,从而提高吞吐量。然而,由于频繁的KV缓存访问和更新,解码仍然是高度内存带宽密集型和空间密集型的。因此,GPU计算资源倾向于被未充分利用,而内存带宽和容量成为了主要瓶颈,与预填充阶段相反。如图2所示,即使只有两个预填充请求,GPU的计算资源也会被完全饱和,但内存利用率仅保持在20%。相比之下,在解码期间,系统可以最多批处理128个请求,充分使用内存容量,但此时GPU计算使用率约为50%。这表明将预填充和解码放在不同的GPU上并不能解决核心低效问题——内存和计算利用率之间的不平衡。
3.3 见解
我们得出两项关键见解,指导我们设计的服务系统Ascendra以应对上述挑战:
1
{ }^{1}
1 每个标记激活的参数数量。
请求优先级的演变。在预填充阶段,主要目标是满足TTFT SLO。然而,由于请求的提示长度不同,请求在违反其SLO前所能等待的时间也不同。此外,随着请求在系统中等待时间越长,其剩余松弛时间缩短,使其变得越来越紧急。为了考虑这种可变性,我们为每个预填充请求定义了一个动态的优先级或紧迫感概念。那些可以容忍更长延迟的请求被赋予较低的优先级,而那些在接下来几次迭代中可能违反TTFT SLO的请求被赋予较高的优先级。这种优先级随着请求在系统中花费更多时间以批量粒度演变。我们提议,一个调度系统应该使用这种演变的优先级来决定哪些请求应在每个批次中处理。
无序预填充执行。在定义了每个请求的优先级之后,我们进一步观察到高优先级请求应先于低优先级请求处理。由于优先级取决于提示长度和系统中的时间,一个较长的请求可能超越一个较早到达的较短请求。在FCFS系统中,这种不匹配可能会延迟高优先级请求,导致SLO违规。我们提议根据优先级无序执行请求,确保即使它们较晚到达,紧急请求也能满足其SLO。
基于这些见解,我们接下来讨论Ascendra的设计概览。Ascendra的目标是在确保请求满足其SLO的同时,最大化LLM服务系统的吞吐量。
4 设计概览
基于我们的观察,没有单一的调度策略能在所有场景中表现出色。为了解决这个问题,我们提出了一种新颖的调度框架,将服务基础设施划分为两个组件,每个组件由不同的调度策略控制,以实现特定目标——最小化交互请求的延迟(TTFT)和最大化吞吐量。我们引入了实例的抽象概念,定义为能够共同处理单个请求的一组GPU。如果模型适合单个GPU的内存,实例可能只包含一个GPU。然而,通过张量并行(TP)或管道并行(PP)等模型并行技术,实例可以跨越多个GPU。为了优化性能,我们将实例分类为两类:低优先级(LP)和高优先级(HP),形成不同的实例池。这种分离允许调度器做出更精细的决策,例如为延迟敏感请求保留快速路径,同时仍为后台工作负载保持高吞吐量。这种两级实例抽象构成了我们自适应调度机制的基础。
图7展示了Ascendra,它包括一个控制器和两个实例池:HP和LP。控制器作为系统入口点,最初将所有用户API请求

图4. Ascendra概览。绿色箭头表示非紧急请求的流动,而红色箭头代表从LP到HP实例的卸载。控制器默认将传入请求路由到LP实例,并在HP实例可用或请求紧急时将其路由到HP实例。
路由到LP实例。在每个池内,请求以轮询方式分配给实例。LP实例优化吞吐量,但在高负载下可能难以满足SLO。如果LP实例检测到即将发生的SLO违规,它会通知控制器,控制器立即将请求卸载到HP实例。HP实例优先遵守截止时间,减少了SLO违规的可能性,但吞吐量略有降低。
卸载仅在预填充阶段发生,通过仅传输提示来实现无缝迁移,避免KV缓存移动。这最小化了数据传输开销,并消除了对如NVLink等专用高带宽硬件的需求。为了满足TTFT和TBT SLO,LP实例必须在接纳新请求和确保正在进行的解码在TBT截止时间内完成之间取得平衡。然而,在负载过重时,LP实例可能会因繁重的解码工作负载而延迟预填充完成。为了解决这个问题,LP实例将请求卸载到HP实例,HP实例优先处理预填充而非解码。这种策略有助于满足TTFT截止时间,尽管可能会偶尔导致HP实例上的轻微解码停滞。
我们从相关问题中汲取灵感,即私有集群和公共云之间的工作负载分配[11, 24]。私有集群提供成本效益但容量有限,而公共云提供可扩展的计算资源以满足严格的截止时间,但成本更高。类似地,在我们的设置中,LP实例专注于在正常负载下最大化吞吐量同时满足SLO。然而,在高负载下,某些请求可能面临饥饿风险。在这种情况下,系统将这些请求卸载到HP实例,HP实例优先满足TTFT SLO,即使是以稍微降低吞吐量为代价。
通过结合LP和HP实例,我们的框架在吞吐量和延迟之间取得了平衡。这种实例类型的分离使我们可以为每个实例定义专门的目标,整体上优于现有的调度方案。此外,操作员可以根据工作负载特性动态调整HP与LP实例的比例,无论是优先严格的TTFT还是TBT SLO,还是采用平衡的方法。这种适应性使Ascendra在广泛的系统负载下保持稳健的性能。接下来,我们将详细讨论LP和HP实例的设计。
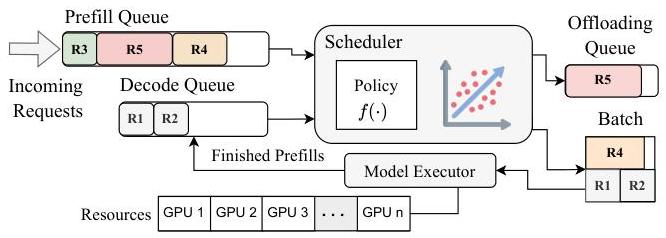
图5. LP实例的详细设计。系统维护单独的队列用于等待的预填充和正在进行的解码请求。在每一步中,调度器使用策略函数和性能模型从两个队列中选择请求并形成一个批次。它还标记处于SLO违规风险的请求,将它们放入卸载队列中,供控制器转移到HP实例。执行完成后,已完成的预填充请求被移到解码队列中。
5 低优先级实例
在本节中,我们将详细描述LP(低优先级)实例的设计。一个有效的服务系统必须旨在满足传入请求的SLO。在我们的上下文中,每个请求都受两个SLO组件的约束:TTFT和TBT。现有的服务系统要么对SLO遵从性不提供任何保证(例如,vLLM [8] 或 Sarathi [1] 主要优化TTFT或TBT),要么以显著的GPU利用率不足和专用互连为代价强制执行两个SLO(DistServe [29])。为了解决这个问题,我们将LP实例设计为高吞吐量服务层。LP实例优先考虑在确保每个请求满足TTFT和TBT SLO的同时,最大化每单位时间生成的标记数量(即吞吐量)。
5.1 性能模型
LP实例的一个关键组件是准确估计给定请求的预填充和单次解码迭代的LLM模型执行时间的能力。这种估计对于指导调度决策至关重要。然而,由于批次内的其他作业可能会干扰,实际请求在批次中的运行时间可能与其独立运行的估计值有所偏差,这些干扰可能包括预填充和解码阶段。
由于LLM前向传递的执行时间相对可预测[13, 29, 30],我们构建了一个性能模型来预测单个请求和完整批次的预填充时间的运行时间。我们首先通过分析建模批次处理所需的计算操作(FLOPs)和内存访问来开始。这些数量可以直接从模型架构中得出。给定一个LLM模型(例如LlaMA 3),其隐藏大小为 h \mathbf{h} h,头数为 n \mathbf{n} n,头大小为 s \mathbf{s} s,前馈中间大小为 m \mathbf{m} m和块大小为 b \mathbf{b} b(我们使用flashattention [4]作为注意力计算的后端),我们进行如下分析。为简单起见,我们仅呈现注意力计算的分析,跳过了通用矩阵乘法(GEMM)操作,并将相关的flops和内存访问相关的GEMM操作记为 f f f(GEMM), M M M(GEMM)。有关此分析建模的更多细节,请参阅附录A.4。
假设一个批次由 B p B_{p} Bp个预填充请求和 B d B_{d} Bd个解码请求组成。我们定义 l i l_{i} li为请求 i i i的提示标记数。批次中每个请求在一个注意力头上的内存访问(M)和计算flops(F)可以表示为
M p = ∑ i = 0 B p − 1 2 l i s + 3 l i s ( l i b ) , F p = ∑ i = 0 B p − 1 2 s l i 2 M_{p}=\sum_{i=0}^{B_{p-1}} 2 l_{i} s+3 l_{i} s\left(\frac{l_{i}}{b}\right), F_{p}=\sum_{i=0}^{B_{p-1}} 2 s l_{i}^{2} Mp=i=0∑Bp−12lis+3lis(bli),Fp=i=0∑Bp−12sli2
同样,对于批次中的 B d B_{d} Bd个解码请求,我们定义 l ^ i \hat{l}_{i} l^i为截至当前批次的提示标记和已生成标记的总和,相应的内存访问和计算flops可以表示为
M d = ∑ i = 0 B d − 1 2 l ^ i s + 2 s , F d = ∑ i = 0 B d − 1 2 l ^ i s M_{d}=\sum_{i=0}^{B_{d-1}} 2 \hat{l}_{i} s+2 s, F_{d}=\sum_{i=0}^{B_{d-1}} 2 \hat{l}_{i} s Md=i=0∑Bd−12l^is+2s,Fd=i=0∑Bd−12l^is
因此,要在混合批次上进行推理,一个解码层所需的总内存访问和计算flops可以表示为
M = ( M p + M d ) ⋅ n + M ( G E M M ) F = ( F p + F d ) ⋅ n + F ( G E M M ) \begin{gathered} M=\left(M_{p}+M_{d}\right) \cdot n+M(G E M M) \\ F=\left(F_{p}+F_{d}\right) \cdot n+F(G E M M) \end{gathered} M=(Mp+Md)⋅n+M(GEMM)F=(Fp+Fd)⋅n+F(GEMM)
内存访问所需的时间 t M t_{M} tM和计算所需的时间 t F t_{F} tF可以通过硬件计算能力 F H F_{H} FH和内存带宽能力 M H M_{H} MH(即NVIDIA A100-80G的312 TFLOPS和2 TB/s)推导出来。实际上,只有相关数据从高带宽内存(HBM)传输到SRAM后,计算才能开始。根据工作负载和数据依赖关系,这种数据传输可能会部分或完全与计算重叠。因此,我们使用总和 ( t M + t F ) \left(t_{M}+t_{F}\right) (tM+tF)(表示无重叠)和最大值 max ( t M , t F ) \max \left(t_{M}, t_{F}\right) max(tM,tF)(表示完全重叠)来捕捉两端。连同各个项 t M = M M H , t F = F F H t_{M}=\frac{M}{M_{H}}, t_{F}=\frac{F}{F_{H}} tM=MHM,tF=FHF来进行线性回归,以找到对应的参数 C 1 , C 2 , C 3 , C 4 C_{1}, C_{2}, C_{3}, C_{4} C1,C2,C3,C4和 C 5 C_{5} C5,从而预测一系列模型配置和批次组成的批次延迟。
t = C 1 ⋅ ( M M H + F F H ) + C 2 ⋅ max ( M M H , F F H ) + C 3 ⋅ M M H + C 4 ⋅ F F H + C 5 \begin{gathered} t=C_{1} \cdot\left(\frac{M}{M_{H}}+\frac{F}{F_{H}}\right)+C_{2} \cdot \max \left(\frac{M}{M_{H}}, \frac{F}{F_{H}}\right) \\ +C_{3} \cdot \frac{M}{M_{H}}+C_{4} \cdot \frac{F}{F_{H}}+C_{5} \end{gathered} t=C1⋅(MHM+FHF)+C2⋅max(MHM,FHF)+C3⋅MHM+C4⋅FHF+C5
为了在实践中完善这个模型,Ascendra会在运行时配置实际请求的执行时间。对于每个批次,系统记录预填充和解码标记的数量,以及观察到的执行延迟。然后使用这些信息增量训练和更新性能模型。如图6所示,Ascendra只需要五分钟的数据收集即可构建一个性能模型
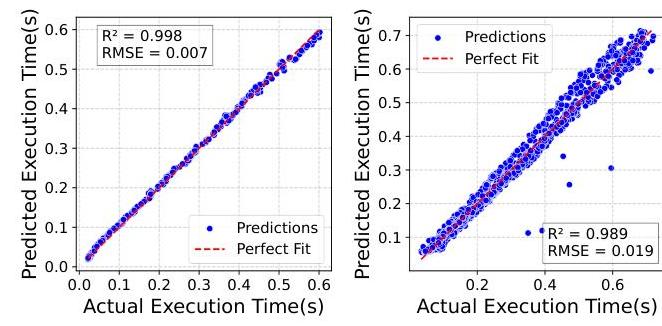
图6. 回归模型预测预填充批次(左)和混合批次(右)执行时间的准确性。预测误差在大多数情况下保持在10%以下。
误差小于10%。这一数据收集过程被整合到正常的服务工作流程中:系统持续从传入请求中收集数据,并定期更新性能模型。
5.2 无序执行
基于前面关于调度低效的讨论,大多数现有的服务系统[1,8,29]以先进先出(FCFS)的方式处理传入请求。然而,严格的FCFS调度并不总是与系统的吞吐量或SLO目标一致。例如,如果目标是将预填充计算推迟到接近其相关截止时间(预填充SLO),那么FCFS可能会过早调度请求,导致GPU利用率低下。
这促使我们在LP实例中采用无序调度。虽然FCFS传统上用于确保公平性,但我们认为,当每个请求都与一个截止时间相关联时,公平性变得不那么重要。事实上,严格的排序可能会通过优先处理低紧急性请求而阻碍整体吞吐量。
为了支持更智能的调度决策,Ascendra使用价值函数而非到达时间来优先处理请求[算法??]。这种优先级支持与系统目标更一致的动态调度策略。Ascendra设计灵活,支持多种策略,包括最短作业优先(SJF)、FCFS和最长作业优先(LJF),或根据操作员偏好的任何自定义策略。在我们的实现中,默认采用最早截止时间优先(EDF)作为调度策略。EDF优先处理接近其SLO截止时间的请求,减少违规可能性并提高整体系统吞吐量。虽然我们的评估重点是EDF,但Ascendra支持可插拔的调度策略以适应多样化的负载。我们在第8.4小节提供了两种不同调度策略的消融研究。
5.3 请求卸载
通过无序调度方案,Ascendra根据请求的优先级选择要执行的请求。然而,这种方法可能导致请求饥饿,其中某些请求由于不断到达的更
算法 1 无序调度
要求:等待队列
(
W
)
(W)
(W),计算预算
(
C
)
(C)
(C),内存
预算
(
M
)
(M)
(M),令牌预算
(
N
)
(N)
(N),价值策略
(
π
)
(\pi)
(π),回归
模型
(
Φ
)
(\Phi)
(Φ)
确保:所选请求列表
对于每个请求
(
w
i
)
(w_{i})
(wi) 在
(
W
)
(W)
(W) 中 do
(
w
i
)
(w_{i})
(wi).val,
(
w
i
.
C
,
w
i
.
M
←
π
(
Φ
,
w
i
)
,
Φ
(
w
i
)
,
Φ
(
w
i
)
)
(w_{i} . C, w_{i} . M \leftarrow \pi\left(\Phi, w_{i}\right), \Phi\left(w_{i}\right), \Phi\left(w_{i}\right))
(wi.C,wi.M←π(Φ,wi),Φ(wi),Φ(wi))
按
(
w
i
)
(w_{i})
(wi).val 的降序排列
(
W
)
(W)
(W)
selected_items
(
←
[
]
)
(\leftarrow[])
(←[])
对于每个请求
(
w
i
)
(w_{i})
(wi) 在
(
W
)
(W)
(W) 中 do
如果
(
C
>
0
,
M
>
0
,
N
>
0
)
(C>0, M>0, N>0)
(C>0,M>0,N>0) 然后
如果
(
C
>
w
i
.
C
,
M
>
w
i
.
M
,
N
>
w
i
)
(C>w_{i} . C, M>w_{i} . M, N>w_{i})
(C>wi.C,M>wi.M,N>wi).prefill then
将
(
w
i
)
(w_{i})
(wi) 添加到 selected_items
(
C
=
C
−
w
i
.
C
)
(C=C-w_{i} . C)
(C=C−wi.C)
(
M
=
M
−
w
i
.
M
)
(M=M-w_{i} . M)
(M=M−wi.M)
(
N
=
N
−
w
i
)
(N=N-w_{i})
(N=N−wi).prefill
else
break
返回 selected_items
紧急的请求而被不断延迟。为了避免这种情况,Ascendra包含了一个请求卸载机制,将紧急的未调度请求转移到HP实例。任何尚未开始预填充执行的请求都有资格卸载。
为了主动做出卸载决策,我们考虑了最坏延迟情况下的情景,即HP实例处理具有最大标记数的批次。这有助于估计请求在卸载后是否仍能满足其SLO。系统使用可调阈值来决定请求何时过于接近其SLO而不能保留在LP的等待队列中。如果卸载阈值设置得太低,LP可能会太晚卸载请求,留给它们在HP完成的时间很少,增加了SLO违规的机会。如果阈值太高,LP可能会卸载本可以及时处理的请求,不必要的加重HP实例的负担,影响整体吞吐量。这两者之间的平衡对整体系统性能至关重要。
5.4 进一步设计考虑
为了在LP实例中最大化吞吐量,我们采用了一种混合批处理策略,将一些请求的解码与其他请求的预填充一起处理,这种方法称为搭便车解码[1]。在我们的设计中,一旦请求完成了其预填充阶段,就会被添加到活动解码请求集中。在每次调度迭代中,调度器尽可能多地批处理待处理的解码请求,受批次大小约束限制。如果在添加所有解码请求后批次中仍有剩余空间,我们使用我们的价值函数选择并将预填充请求打包到批次中。这种方法确保了解码的连续进展,防止生成停滞,同时允许新预填充请求的准入。
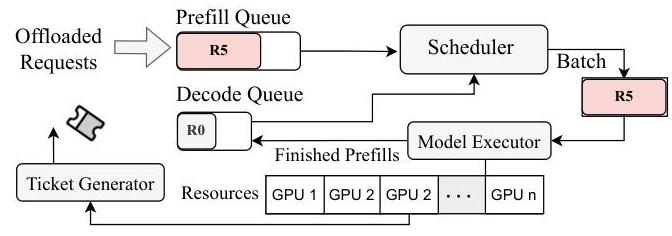
图7. HP实例的详细设计。系统通过在没有待处理预填充时向控制器发出票据,或者接受紧急卸载请求来接纳请求。在每一步中,调度器优先预填充以满足TTFT SLO。一旦请求完成其预填充阶段,它将被移至解码队列以进行进一步处理。
6 高优先级实例
在本节中,我们讨论了HP实例的设计。为了确保及时执行紧急请求,HP实例被配置为处理从LP实例卸载的预填充工作负载。这些请求通常接近其TTFT SLO,需要立即处理。到达后,卸载的请求被放置在最短等待队列中以实现近即时执行。
6.1 票据入口
由于其按需性质,HP实例在轻负载时可能保持未充分利用,这时LP实例可以满足所有SLO。为了提高利用率。为了提高利用率并保持按需响应性,我们引入了一种票据入口机制。当没有请求被卸载到HP实例(即等待队列为空)时,HP实例向控制器发出“票据”,促使其将下一个传入请求直接路由到HP实例。这种机会主义请求有助于保持GPU活跃。为了保留HP对紧急卸载的可用性,一次只允许一个票据请求。如果实际卸载很快到达,它会经历最小的排队延迟——最多一个批次周期。这种票据入口机制可以在轻负载下将HP利用率提高多达50%。
6.2 弹性批次大小
现有的LLM服务系统通常使用固定的可配置批次大小,由于请求特征的变化,这会导致次优性能。小批次大小可能会不必要地延迟预填充请求,尽管有可用的内存和计算资源,增加排队延迟并降低GPU利用率。然而,它提高了对增长的解码标记的弹性,这些标记消耗了大量的GPU内存。相反,大批次大小可以在高系统负载下容纳更多的预填充请求,但存在在随后的解码阶段快速消耗GPU内存的风险,导致频繁的抢占并降低整体系统吞吐量。为了解决这个问题,最优的批处理策略必须动态平衡请求接纳。我们通过在LP实例上保持较小的批次大小(例如128)来实现这一点,以在最小抢占的情况下为解码保留内存。在HP实例上,我们采用弹性批次大小,允许预填充只要GPU内存允许就可以继续。这是通过持续监控解码长度历史并用它来动态调整GPU为解码预留的内存来实现的。尽管这可以让更多的卸载请求达到其TTFT SLO,但在系统承受高压时存在频繁抢占的风险。
6.3 在负载波动下的服务
当负载波动暂时超过系统容量时,FCFS会导致大量SLO违规。这是因为系统花费时间处理已经超出其SLO的积压请求,导致后续请求也错过其截止时间。一个根本的解决方案是通过添加更多实例进行水平扩展。然而,动态扩展GPU节点具有挑战性,特别是考虑到某些框架(即DistServe [29])所需的专用硬件要求(即NVLink、NVSwitch)。我们提议在负载波动暂时超过系统容量时选择性地丢弃请求。这种解决方案已被之前的DNN服务系统(如Shepherd [27])采用。通过允许丢弃请求,系统可以在负载暂时超过系统容量时始终维持其有效吞吐量。
7 实现
我们在开源LLM服务系统vLLM [8] 和Sarathi-Serve[1]之上实现了Ascendra。FlashAttention [4] 和FlashInfer [25] 内核用作注意力计算的后端。我们的实现引入了一个集中式控制器,支持可定制的调度策略并协调LP和HP实例之间的请求路由。在实例级别,我们扩展了调度器以通过可插拔的价值函数支持无序执行。类似于Sarathi-Serve [1],NCCL [14] 用于张量和管道并行通信。整个系统,包括HP和LP实例、实例间通信、调度层、计算和内存估计模块以及编排层,使用4.1千行Python代码实现。此外,我们开发了一个批处理级别的仿真框架,使用2.8千行Python代码来实现细粒度最优配置搜索。
8 评估
8.1 应用和数据集
我们在一系列流行的模型和数据集上评估Ascendra,这些模型和数据集反映了广泛的现实世界服务场景。作为基线,我们与vLLM和Sarathi-Serve(称为Sarathi)进行比较,它们旨在单独优化TTFT或TBT。我们不直接与
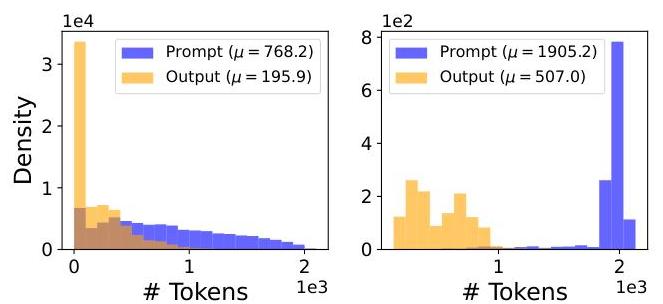
图8. Openchat-ShareGPT4(左)和LongBench(右)数据集的提示和响应长度分布。
| 模型 | 配置 | TTFT (秒) | TBT (秒) | 数据集 |
|---|---|---|---|---|
| Mistral-7B | 3 A100-80G | 1 | 0.15 | ShareGPT [22] |
| Llama3.1-8B | 2.5 | 0.15 | LongBench [2] | |
| Qwen-14B | 3 A100-80G | 1.5 | 0.15 | ShareGPT [22] |
| 3.0 | 0.15 | LongBench [2] |
表2. 评估中的模型、数据集及相应的延迟SLO,以及测试平台设置。
DistServe [29] 和Llumnix [21] 进行直接比较,因为它们依赖于额外的高带宽传输硬件来进行KV缓存转移(如NVLink或NVSwitch)。在本节中,我们讨论主要结果,但也在附录A.5中提供了进一步的结果。
为了模拟真实的LLM工作负载,我们使用两个公开可用的数据集(Openchat-ShareGPT4和Longbench),这些数据集描述了不同的提示和输出标记长度。我们在图8中展示了每个数据集的提示长度和输出长度分布。
Openchat-ShareGPT4 [22] 包含来自ChatGPT-4 [18] 的聊天对话。每个与聊天机器人的交互都被作为一个独立的请求呈现。为了响应性,我们将LLama3.1-8B和Mistral-7B的TTFT SLO设置为1秒,Qwen-14B为1.5秒。TBT SLO设置为0.15秒,对应大约每分钟400词的吞吐量——大约是普通人阅读速度的2到3倍[3]。
LongBench [2] 包含摘要任务。它展示了使用LLMs生成长文档摘要的一个实例。其特点是长提示且输出长度相对变化较小。由于在这种情况下响应性不太关键,我们将LLama3.1-8B和Mistral-7B的TTFT SLO放宽至2.5秒,Qwen-14B放宽至3.0秒,同时继续强制执行严格的TBT SLO以评估吞吐量效率。
为了模拟现实的工作负载到达模式,我们使用具有变化到达率的泊松分布生成请求到达。
环境设置:我们评估三个流行模型Mistral-7B、LLaMA3.1-8B和Qwen-14B。我们使用一个由380个NVIDIA-A100 GPU组成的测试床。节点通过100 Gbps Infiniband/Ethernet连接互联。
8.2 Goodput对比
在LLM服务系统中,TTFT和TBT都是关键性能指标。根据先前的研究[29],我们将goodput定义为满足TTFT SLO并且平均TBT满足TBT SLO的请求数量百分比。我们的目标是确保系统在不同系统负载下至少保持90%的goodput。图9显示了Ascendra与两个基线vLLM和Sarathi-Serve在查询速率增加时的goodput比较评估。我们还分析了这些系统在不同SLO条件下的表现,通过固定查询速率并改变SLO严格程度,展示在严格和宽松SLO设置下的性能。
在第一行中,我们观察到当在ShareGPT上服务Mistral-7B时,Ascendra分别比vLLM和Sarathi-Serve提高了19.1%和17.4%的goodput。对于在LongBench上的LLaMA3.18B,Ascendra相比两个基线实现了15.4%的提升。
性能改进可以归因于几个关键因素。在高负载下,vLLM和Sarathi-Serve使用的FCFS策略引入了显著的调度延迟(图10d),导致许多请求错过其TTFT SLO。相比之下,Ascendra动态重新排序传入请求以优先处理那些TTFT约束更紧的请求。那些等待时间较长且接近违反其TTFT SLO的请求被卸载到HP实例,在那里Ascendra给予它们优先权,最小化由LP实例积压引起的额外延迟。然而,随着请求速率持续上升,HP实例的队列开始堆积,最终导致一些请求错过其TTFT SLO,从而导致goodput下降。尽管如此,即使在极端负载下,Ascendra仍然优于两个基线,因为LP实例始终确保一定数量的请求满足其SLO。
与Mistral-7B和LLaMA3.1-8B相反,我们观察到Qwen-14B模型的行为略有不同。虽然vLLM仅支持最大2.55 QPS的吞吐量,但Sarathi-Serve和Ascendra都维持了2.8 QPS。这是因为服务Qwen-14B时可用的GPU内存有限。该模型的参数数量是Mistral-7B的两倍,留给KV缓存的内存显著减少。此外,每个标记的KV缓存大小从512 KB增加到800 KB,进一步加剧了内存压力。因此,可用的KV缓存块数量减少了88%(从25,000减少到3,000)。
在如此有限的内存下,最佳调度策略转向最小化预填充并优先解码步骤以释放内存供新请求使用。vLLM在这种设置下表现不佳,因为它急切地执行预填充,迅速耗尽内存,要么抢占正在进行的解码,要么延迟待处理的预填充。Sarathi-Serve通过搭便车解码与预填充,允许一些解码完成并释放内存,从而为额外的预填充腾出空间。同样,Ascendra的表现与Sarathi-Serve相当,因为在Ascendra中,LP实例自然优先完成解码请求以提高吞吐量。这个实验表明,即使在极其有限内存的极端场景下,Ascendra依然具有竞争力。
图9的第二行展示了Ascendra在不同SLO约束下的灵活性。在这个实验中,我们将请求到达率固定在Ascendra达到略高于90% goodput的点。然后,我们根据表2中的TTFT和TBT阈值进行调整,应用更严格和更宽松的SLO。在所有模型和数据集中,Ascendra始终比基线保持更高的goodput。在一定的SLO保证(90%)下,Ascendra可以在最多4倍更严格的SLO范围内持续运行。
8.3 LP和HP实例的有效性
Ascendra中的每种实例类型都针对特定目标进行了优化:LP实例优先考虑低TTFT和高吞吐量,而HP实例则尽量减少紧急请求的调度延迟。我们使用表2中的设置评估每种实例实现其设计目标的程度,测量TTFT、TBT、吞吐量和调度延迟(图10)。
如图10a所示,与基线相比,Ascendra显著减少了TTFT违规情况,证明了LP实例在主动将紧急请求卸载到HP实例方面的有效性,即使在高负载下也是如此。这使得Ascendra能够维持稳定的goodput,而不是浪费资源在已经错过其SLO的请求上。图10b进一步显示,LP和HP实例一致地将TBT保持在SLO范围内,有助于整体goodput的提升。
由于HP实例专注于最小化延迟,它们自然实现了更低的调度延迟,如图10d所示,HP请求的等待时间比LP请求少4倍。然而,这以吞吐量为代价,因为HP遵循严格的FCFS,没有LP那样的灵活性来挑选请求。这些结果突显了关键的权衡:HP实例以略微降低吞吐量为代价,实现了及时处理紧急请求。
8.4 重排序策略的选择
为了支持多样化的应用目标和服务水平差异化,我们在第5.2小节中介绍了Ascendra中的可配置重排序策略机制。此功能允许操作员根据应用程序特定的优先级或工作负载特征定制LP实例上排队请求的执行顺序。在图11的左面板中,我们评估了两种策略变体:SJF,
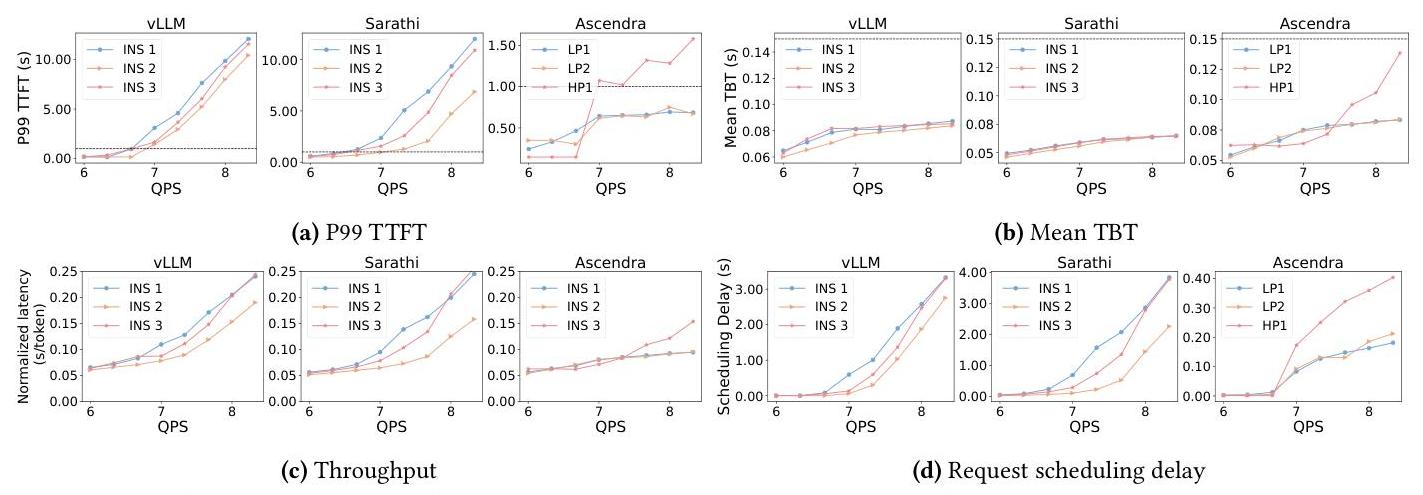
图10. 在ShareGPT数据集上服务Mistral-7B时Ascendra和基线的性能分解。所有系统均部署了三个实例:vLLM和Sarathi-Serve对所有实例使用相同的配置(INS 1, 2, 3),而Ascendra采用异构设置,包含两个LP实例和一个HP实例。我们报告了四个关键指标:(a) P99 TTFT,(b) 平均TBT,© 系统吞吐量,和 (d) 所有实例的请求调度延迟。
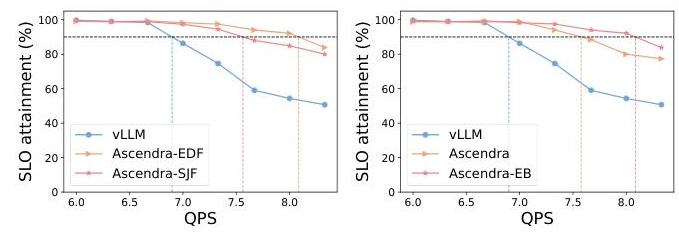
图11. 左:不同的价值函数策略导致不同的非顺序调度方案,进而产生不同的有效吞吐量。右:HP实例上的弹性批次进一步在高QPS下提高了有效吞吐量。
优先处理预期执行时间较短的请求,以及Ascendra中的默认策略EDF,优先处理接近其TTFT截止时间的请求。
我们的结果显示,在这种情况下,Ascendra-EDF比Ascendra-SJF实现了更高的有效吞吐量。这突出了使调度策略与工作负载特性和目标SLO对齐的重要性。更广泛地说,它展示了Ascendra适应不同运营目标的灵活性。例如,操作员可以配置策略以优先处理延迟敏感的应用程序(即严格的TTFT SLO),或者在多租户环境中优先处理高级用户而非免费用户。这种基于策略的适应性使Ascendra能够作为构建公平和高效LLM服务系统的通用基础,适用于各种部署环境。
8.5 弹性批次的有效性
我们展示了弹性批次大小的有效性。为了比较,我们使用相同的设置:2个LP实例和1个HP实例,在ShareGPT数据集上使用Mistral-7B模型。我们比较了启用和未启用
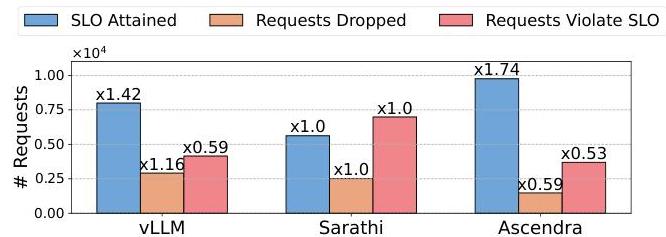
图12. Ascendra在只丢弃少量请求的情况下服务最多的请求符合SLO。
在HP实例上启用弹性批次大小时的系统有效吞吐量。图11(右侧面板)显示动态调整批次大小进一步改善了系统有效吞吐量。这种改进发生是因为当空闲内存超过总内存的10%时,系统可以安全地增加批次大小。较大的批次大小允许HP实例同时接纳和处理更多的预填充请求,从而导致更高比例的请求满足其TTFT SLO,并提高了整体吞吐量。
8.6 在高系统负载下的服务
在实际部署中,系统负载可能会波动并偶尔超出容量。一种常见的防止积压增长的策略是在超过系统容量时丢弃违反SLO的请求[27]。我们通过以略高于系统容量的到达率运行10分钟来评估所有框架。任何超过TTFT SLO仍留在等待队列中的请求都会被丢弃。图12显示了所有基线之间的比较。在相同的负载和时间段内,与基线方法相比,Ascendra在SLO下服务的请求多1.74倍,同时将丢弃的请求数量和违反SLO的请求数量减少了几乎50%。
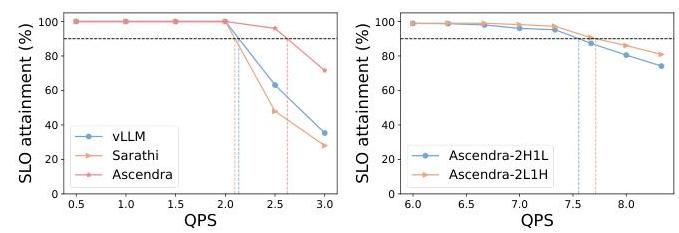
图13. 左:在双实例设置(一个LP实例和一个HP实例)下,Ascendra与基线在LongBench数据集上的良好吞吐量比较。右:三实例设置两种不同配置的良好吞吐量比较:两个LP实例和一个HP实例 vs 一个LP实例和两个HP实例在ShareGPT4数据集上的比较。
8.7 将Ascendra扩展到GPU集群
在本节中,我们讨论如何将Ascendra扩展到大型GPU集群。当跨数百或数千个GPU部署时,搜索最佳系统配置可能既耗时又耗费资源。为了减少配置搜索空间并实现即时可扩展部署,我们使用子组扩展系统。
在图9中,我们展示了对于包含两个LP和一个HP实例(2L1H)的三个实例子组,Ascendra优于现有基线。图13进一步比较了不同子组配置的性能,包括2 H 1 L设置(两个HP和一个LP实例)和包含一个LP和一个HP实例的双实例子组(1L1H)。我们看到对于三个实例的子组,2L1H配置比2H1L表现更好。此外,1L1H子组也比基线表现更好,突出了一般的有效性。这些结果表明,当在大型GPU集群上部署Ascendra时,系统可以划分为包含两个或三个实例的独立子组,以实现可扩展和高效的运行。虽然这些配置优于现有基线,但它们不一定代表全局最优。给定足够的时间和工作负载特性的知识,可以通过我们的模拟器进行组合搜索来发现全局最优配置。
9 相关工作
高效服务LLM带来了多个挑战,包括管理长提示、满足严格的延迟要求(例如TTFT和TBT)以及在内存限制下最大化GPU利用率。已在堆栈的不同层提出了广泛的系统来应对这些挑战。在内核层面上,例如FlashAttention [4] 和Flash-Decoding [7]等系统优化了核心GPU操作以加速推理。这些方法与我们的方法正交,可以集成到大多数服务流水线中。
在基础设施层面,AlpaServe [9] 等系统利用深度神经网络中的并行性来提高吞吐量,而SpotServe [12] 则利用可抢占实例
以降低成本。Orca [26] 引入了连续批处理,允许服务引擎在请求之间交错预填充和解码阶段。vLLM [8] 通过分页注意力引入了系统的内存管理方案。类似地,NanoFlow [30] 通过重叠通信和计算进一步提高吞吐量。ExeGPT [17] 通过输入和输出序列的分布动态确定高吞吐量的最佳执行配置。虽然这些系统专注于最大化GPU利用率和系统吞吐量,但通常不考虑应用级别的TTFT和TBT SLO。
为了更好地满足延迟SLO,SarathiServe [1] 和DeepSpeed-FastGen [6] 等系统引入了分块预填充,将预填充阶段分成更小的部分并在解码时搭便车,以牺牲更高的TTFT为代价改善TBT。为了同时解决TTFT和TBT,DistServe [29]、SplitWise [19] 和Llumnix [21] 支持跨实例迁移请求以减轻预填充-解码干扰,实现横向扩展并缓解内存碎片化。然而,这些方法由于大规模KV缓存传输而产生了显著的通信开销。
另外,一条研究线专注于KV缓存优化。CachedAttention [5] 提出了一种分层存储方案,将KV张量放置在CPU内存或磁盘中。LoongServe [23] 在GPU之间构建分布式KV缓存池以支持更长的提示。ALISA [28] 探讨了在CPU内存中重新计算和存储KV张量之间的权衡,而CacheGen [10] 通过压缩KV张量以减少内存占用为代价降低准确性。虽然这些方法减少了KV缓存大小,我们的方法旨在完全避免KV缓存传输,从而减轻实例间通信开销。这些技术与我们的方法互补,可以集成以进一步提高系统性能。
10 结论
在本文中,我们介绍了Ascendra,这是一种新颖的LLM服务系统,旨在通过两级实例架构——低优先级(LP)和高优先级(HP)实例——最大化在多样化工作负载下的有效吞吐量。LP实例通过可配置的价值函数指导的无序调度形成高效的批次,同时主动将存在违反其截止日期风险的请求卸载到HP实例。反过来,HP实例为紧急请求提供低延迟执行,通过牺牲部分吞吐量以确保SLO合规。这种协作设计使Ascendra能够动态平衡延迟和吞吐量,从而显著提高整体系统有效吞吐量。使用多个开源模型和代表性数据集进行的广泛评估表明,Ascendra始终优于最先进的LLM服务系统。
参考文献
[1] Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. 控制{吞吐量-延迟}权衡在{LLM}推理中的方法{Sarathi-Serve}. 在第18届USENIX操作系统设计与实现研讨会(OSDI 24)上发表。117-134页。
[2] Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, 和 Juanzi Li. 2024. LongBench: 一种用于长上下文理解的双语、多任务基准。在计算语言学协会第62届年会论文集(长篇论文卷1)上发表,由Lun-Wei Ku, Andre Martins, 和 Vivek Srikumar编辑。计算语言学协会出版,泰国曼谷,3119-3137页。
[3] Marc Bryshaert. 2019. 我们每分钟读多少单词?关于阅读速度的综述和元分析。记忆与语言杂志 109 (2019), 104047.
[4] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, 和 Christopher Ré. 2022. Flashattention: 快速且内存高效的精确注意机制,具有I/O感知能力。神经信息处理系统进展 35 (2022), 16344-16359.
[5] Bin Gao, Zhuomin He, Paru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, 和 Pengfei Zuo. 2024. {成本高效} 大型语言模型服务于多轮对话使用 {CachedAttention}. 在2024 USENIX年度技术会议 (USENIX ATC 24) 上发表。111-126页。
[6] Connor Holmes, Masahiro Tanaka, Michael Wyatt, Ammar Ahmad Awan, Jeff Rasley, Samyam Rajbhandari, Reza Yazdani Aminabadi, Heyang Qin, Arash Bakhtiari, Lev Kurilenko, 等. 2024. Deepspeed-fastgen: 通过MII和Deepspeed-Inference实现的LLM高吞吐文本生成. arXiv预印本 arXiv:2401.08671 (2024).
[7] Ke Hong, Guohao Dai, Jiaming Xu, Qiuli Mao, Xiuhong Li, Jun Liu, Yuhan Dong, Yu Wang, 等. 2024. FlashDecoding++: 使用异步、扁平GEMM优化和启发式算法实现更快的大语言模型推理. 机器学习与系统会议论文集 6 (2024), 148-161.
[8] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, 和 Ion Stoica. 2023. 使用PagedAttention进行大语言模型服务的高效内存管理. 在第29届操作系统原理研讨会(SOSP 23)论文集上发表. 611-626页.
[9] Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E Gonzalez, 等. 2023. {AlpaServe}: 深度学习服务中的统计复用与模型并行性. 在第17届USENIX操作系统设计与实现研讨会(OSDI 23)上发表. 663-679页.
[10] Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, 等. 2024. Cachegen: 用于快速大语言模型服务的KV缓存压缩与流式传输. 在ACM SIGCOMM 2024会议论文集上发表. 38-56页.
[11] Michael Luo, Siyuan Zhuang, Suryaprakash Vengadesan, Romil Bhardwaj, Justin Chang, Eric Friedman, Scott Shenker, 和 Ion Stoica. 2024. Starburst: 一种面向混合云的成本感知调度器. 在2024 USENIX年度技术会议 (USENIX ATC 24) 上发表. 37-57页.
[12] Xupeng Miao, Chunan Shi, Jiangfei Duan, Xiaoli Xi, Dahua Lin, Bin Cui, 和 Zhihao Jia. 2024. Spotserve: 在可抢占实例上服务生成式大语言模型. 在第29届ACM国际编程语言和操作系统体系结构支持会议论文集上发表, 第2卷. 1112-1127页.
[13] Deepak Narayanan, Keshav Santhanam, Peter Henderson, Rishi Bommasani, Tony Lee, 和 Percy S Liang. 2023. 自回归Transformer模型推理效率指标的廉价估算.
神经信息处理系统进展 36 (2023), 6651866538.
[14] NVIDIA. 2023. NVIDIA Collective Communications Library (NCCL). https://developer.nvidia.com/nccl. 访问日期: 2025-03-29.
[15] NVIDIA. 2025. fastertransformer. https://github.com/NVIDIA/Faster Transformer. 访问日期: 2025-04-04.
[16] NVIDIA. 2025. TensorRT工具箱优化大语言模型推理. https://github.com/NVIDIA/TensorRT-LLM. 访问日期: 2025-04-04.
[17] Hyungjun Oh, Kihong Kim, Jaemin Kim, Sungkyun Kim, Junyeol Lee, Du-seong Chang, 和 Jiwon Seo. 2024. ExeGPT: 考虑约束的大语言模型推理资源调度. 在第29届ACM国际编程语言和操作系统体系结构支持会议论文集(La Jolla, CA, USA)(ASPLOS '24) 中发表. 计算机协会出版社, 纽约, NY, USA, 369-384. https://doi.org/10.1145/3620665.3640383
[18] OpenAI. 2023. ChatGPT. https://chat.openai.com
[19] Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Iñigo Goiri, Saeed Maleki, 和 Ricardo Bianchini. 2024. Splitwise: 使用阶段拆分实现高效生成式LLM推理. 在2024 ACM/IEEE第51届计算机体系结构国际研讨会(ISCA)上发表. IEEE,
118
−
132
118-132
118−132.
[20] Ying Sheng, Shiyi Cao, Dacheng Li, Banghua Zhu, Zhuohan Li, Danyang Zhuo, Joseph E Gonzalez, 和 Ion Stoica. 2024. 大语言模型服务中的公平性. 在第18届USENIX操作系统设计与实现研讨会(OSDI 24)上发表. 965-988.
[21] Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, 和 Wei Lin. 2024. Lhunmic: 大语言模型服务的动态调度. 在第18届USENIX操作系统设计与实现研讨会(OSDI 24)上发表. 173-191.
[22] Guan Wang, Sijie Cheng, Xianyuan Zhan, Xiangang Li, Sen Song, 和 Yang Liu. 2023. Openchat: 使用混合质量数据推进开源语言模型. arXiv预印本 arXiv:2309.11235 (2023).
[23] Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, 和 Xin Jin. 2024. Loongserve: 使用弹性序列并行高效服务长上下文大语言模型. 在ACM SIGOPS第30届操作系统原则研讨会论文集上发表.
640
−
654
640-654
640−654.
[24] Zhanghao Wu, Wei-Lin Chiang, Ziming Mao, Zongheng Yang, Eric Friedman, Scott Shenker, 和 Ion Stoica. 2024. Can’t be late: 在截止日期下优化现货实例节省. 在第21届USENIX网络系统设计与实现研讨会(NSDI 24)上发表. 185-203.
[25] Zihao Ye, Lequn Chen, Ruihang Lai, Yilong Zhao, Size Zheng, Junru Shao, Bohan Hou, Hongyi Jin, Yifei Zuo, Liangsheng Yin, Tianqi Chen, 和 Luis Ceze. 2024. 加速自注意力以服务于大语言模型.
[26] Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, 和 Byung-Gon Chun. 2022. Orca: 一个基于Transformer的生成模型分布式服务系统. 在第16届USENIX操作系统设计与实现研讨会(OSDI 22)上发表. USENIX协会, 卡尔斯巴德, CA, 521-538.
[27] Hong Zhang, Yupeng Tang, Anurag Khandelwal, 和 Ion Stoica. 2023. SHEPHERD: 在野外服务DNNs. 在第20届USENIX网络系统设计与实现研讨会(NSDI 23)上发表. USENIX协会, 波士顿, MA, 787-808.
[28] Youpeng Zhao, Di Wu, 和 Jun Wang. 2024. Alisa: 通过稀疏感知KV缓存加速大语言模型推理. 在2024 ACM/IEEE第51届计算机体系结构国际研讨会(ISCA)上发表. IEEE, 1005-1017.
[29] Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, 和 Hao Zhang. 2024. {DiatServe}: 通过分离预填充和解码优化大语言模型服务的吞吐量. 在第18届USENIX操作系统设计与实现研讨会(OSDI 24)上发表. 193-210.
[30] Kan Zhu, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Yufei Gao, Qinyu Xu, Tian Tang, Zihao Ye, 等. 2024. Nanoflow: 向最佳大语言模型服务吞吐量迈进. arXiv预印本 arXiv:2408.12757 (2024).
A 附录
A. 1 模型架构和批量请求符号定义
首先,我们定义以下与LLM模型架构相关的符号:
- h: 隐藏层大小
-
- n: 注意头数
-
- s: 注意头大小 ( h = n ⋅ s ) (\mathbf{h}=\mathbf{n} \cdot \mathbf{s}) (h=n⋅s)
-
- m: FFN中间层大小
注意:如果使用张量并行,则 h , n h, n h,n,和 m m m应除以张量并行大小。
- m: FFN中间层大小
其次,我们定义表征要执行的批次的符号:
- B p , B d B_{p}, B_{d} Bp,Bd : 批次中的预填充请求数量,批次中的解码请求数量, B = B p + B d B=B_{p}+B_{d} B=Bp+Bd。
-
- p 0 , p 1 , … , p B p − 1 p_{0}, p_{1}, \ldots, p_{B_{p}-1} p0,p1,…,pBp−1 : 批次中每个预填充请求的输入提示长度。
-
- l 0 , l 1 , … , l B p − 1 l_{0}, l_{1}, \ldots, l_{B_{p}-1} l0,l1,…,lBp−1 : 批次中每个预填充请求当前批次前处理的提示标记数量。
-
- c 0 , c 1 , … , c B p − 1 c_{0}, c_{1}, \ldots, c_{B_{p}-1} c0,c1,…,cBp−1 : 当前批次中要处理的预填充标记数量(块大小)。
-
- l ^ 0 , l ^ 1 , … , l ^ B d − 1 \hat{l}_{0}, \hat{l}_{1}, \ldots, \hat{l}_{B_{d}-1} l^0,l^1,…,l^Bd−1 : 每个解码请求当前批次前的输入提示长度加上已生成的解码标记数量。
-
- t t t : 批次中预填充请求的提示标记总数, t = ∑ i = 0 B p − 1 p i t=\sum_{i=0}^{B_{p}-1} p_{i} t=∑i=0Bp−1pi
-
- b b b : 注意力核中的块大小。此参数在FlashAttention [4]中使用,这是当前LLM服务系统(VLLM,Sarathi-Serve)采用的一种常见的核优化技术。
A. 2 预填充分析(无分块)
我们首先考虑通用矩阵乘法(GEMM)操作。对于一个提示标记长度为 p p p的请求,GEMM相关的计算flops和内存访问如表3所示。我们将从HBM加载数据到SRAM称为内存访问。
对于注意力操作,我们讨论带有FlashAttention [4]优化的注意力操作。给定一个具有 p p p个提示标记的请求,输入 Q , K , V ∈ R p × s \mathbf{Q}, \mathbf{K}, \mathbf{V} \in \mathbb{R}^{p \times s} Q,K,V∈Rp×s,注意力计算表示如下:
S = Q K ⊤ ∈ R p × p , P = softmax ( S ) ∈ R p × p , O = P V ∈ R p × s \mathbf{S}=\mathbf{Q K}^{\top} \in \mathbb{R}^{p \times p}, \mathbf{P}=\operatorname{softmax}(\mathbf{S}) \in \mathbb{R}^{p \times p}, \mathbf{O}=\mathbf{P V} \in \mathbb{R}^{p \times s} S=QK⊤∈Rp×p,P=softmax(S)∈Rp×p,O=PV∈Rp×s
我们参考FlashAttention [4]中的前向传递算法2进行以下IO操作分析。首先,每个
K
,
V
\mathrm{K}, \mathrm{V}
K,V块只会从HBM加载一次到SRAM,这占用了
2
s
p
2 s p
2sp内存读取访问。对于每对K,V块,相应的Q,O块需要加载,执行注意力计算,并写回到O。这占用了
2
s
p
2 s p
2sp内存读取访问和
s
p
s p
sp
内存写入访问。不同于逐个操作K,V对,FlashAttention操作的是块大小为
b
b
b的K,V对块。总的K,V块对数可以表示为
p
/
b
p / b
p/b。因此,提示标记长度为
p
p
p的预填充的总内存访问为
2
s
p
+
3
s
p
⋅
(
p
/
b
)
2 s p+3 s p \cdot(p / b)
2sp+3sp⋅(p/b)。对于flops计算,矩阵
Q
K
T
Q K^{T}
QKT和
P
V
P V
PV的乘法得到
2
p
2
s
2 p^{2} s
2p2s flops。因此,结合GEMM计算和内存访问,包含
B
p
B_{p}
Bp个预填充请求的批次的计算和内存访问可以表示为:
M p = 4 h 2 + 8 ∑ i = 0 B p − 1 p i h + 2 h m + 2 t m + 2 s p + 3 s p ⋅ p b F p = 4 ∑ i = 0 B p − 1 p i h 2 + 2 ∑ i = 0 B p − 1 p i h m + 2 p 2 s \begin{aligned} & M_{p}=4 h^{2}+8 \sum_{i=0}^{B_{p}-1} p_{i} h+2 h m+2 t m+2 s p+3 s p \cdot \frac{p}{b} \\ & F_{p}=4 \sum_{i=0}^{B_{p}-1} p_{i} h^{2}+2 \sum_{i=0}^{B_{p}-1} p_{i} h m+2 p^{2} s \end{aligned} Mp=4h2+8i=0∑Bp−1pih+2hm+2tm+2sp+3sp⋅bpFp=4i=0∑Bp−1pih2+2i=0∑Bp−1pihm+2p2s
A. 3 解码分析
同样,对于解码分析,我们首先考虑GEMM操作。解码的GEMM操作的计算flops和内存访问如表4所示。对于解码的注意力操作,假设一个请求只有一个预填充标记,为了解码第一个标记,需要获取第一个标记的相关 k , v ∈ k, v \in k,v∈ R s R^{s} Rs以及查询向量 q ∈ R s q \in R^{s} q∈Rs;对于第二个生成的标记,我们需要获取第一个生成标记的 k , v ∈ R s k, v \in R^{s} k,v∈Rs以及第二个查询向量 q ∈ R s q \in R^{s} q∈Rs,等等。因此,生成 p p p个标记需要 3 s p 3 s p 3sp内存访问。然而,这只在批次中只有一个解码请求且预填充标记和解码标记总数不超过SRAM容量时才成立。
为了推广这一点,我们考虑存在多个解码请求的批次场景。它们的内存可能超过SRAM容量。因此,为了从一个请求中解码单个标记,可能需要重新加载预填充提示的 k , v ∈ R p × s k, v \in R^{p \times s} k,v∈Rp×s以及之前生成的标记到SRAM。在这种情况下,解码注意力期间的内存访问取决于当前批次中的请求数量及其各自相关的 K , V K, V K,V大小。然而,我们可以推导出这种内存访问的上限。
假设对于每个解码标记的请求,我们需要重新加载其预填充提示的 k , v k, v k,v以及到目前为止生成的所有标记。对于一个具有 l ^ i \hat{l}_{i} l^i个预填充标记和生成标记的请求 i i i,当前批次中所有解码请求的内存访问被 ∑ i = 0 i = B d − 1 2 l ^ i s + 2 s \sum_{i=0}^{i=B_{d}-1} 2 \hat{l}_{i} s+2 s ∑i=0i=Bd−12l^is+2s所限制,其中2 s代表生成标记的 k , v ∈ R s k, v \in R^{s} k,v∈Rs。对于解码批次的flops计算,新的查询向量 q ∈ R s q \in R^{s} q∈Rs需要计算其对所有预填充和生成的 k , v k, v k,v的注意力,可以表示为 ∑ i = 0 i = B d − 1 2 l ^ i s \sum_{i=0}^{i=B_{d}-1} 2 \hat{l}_{i} s ∑i=0i=Bd−12l^is。
因此,结合GEMM计算和内存访问,一个
| GEMM 名称 | M 的形状 | N 的形状 | FLOPs | 内存读取 | 内存写入 |
|---|---|---|---|---|---|
| QKV 线性 | ( t , h ) (t, h) (t,h) | ( h , 3 h ) (h, 3 h) (h,3h) | 3 t h 2 3 t h^{2} 3th2 | t h + 3 h 2 t h+3 h^{2} th+3h2 | 3 t h 3 t h 3th |
| 注意力输出 | ( t , h ) (t, h) (t,h) | ( h , h ) (h, h) (h,h) | t h 2 t h^{2} th2 | t h + h 2 t h+h^{2} th+h2 | t h t h th |
| FFN 输入 | ( t , h ) (t, h) (t,h) | ( h , m ) (h, m) (h,m) | $t ------ | ||
| h m$ | t h + h m t h+h m th+hm | t m t m tm | |||
| FFN 输出 | ( t , m ) (t, m) (t,m) | ( m , h ) (m, h) (m,h) | t h m t h m thm | t m + h m t m+h m tm+hm | t h t h th |
表3. 预填充批次
中的GEMM操作的FLOPs和内存访问。
| GEMM 名称 | M 的形状 | N 的形状 | FLOPs | 内存读取 | 内存写入 |
|---|---|---|---|---|---|
| QKV 线性 | ( t , h ) (t, h) (t,h) | ( h , 3 h ) (h, 3 h) (h,3h) | 3 t h 2 3 t h^{2} 3th2 | t h + 3 h 2 t h+3 h^{2} th+3h2 | 3 t h 3 t h 3th |
| 注意力输出 | ( t , h ) (t, h) (t,h) | ( h , h ) (h, h) (h,h) | t h 2 t h^{2} th2 | t h + h 2 t h+h^{2} th+h2 | t h t h th |
| FFN 输入 | ( t , h ) (t, h) (t,h) | ( h , m ) (h, m) (h,m) | t h m t h m thm | t h + h m t h+h m th+hm | t m t m tm |
| FFN 输出 | ( t , m ) (t, m) (t,m) | ( m , h ) (m, h) (m,h) | t h m t h m thm | t m + h m t m+h m tm+hm | t h t h th |
表3. 预填充批次中的GEMM操作的FLOPs和内存访问。
| GEMM 名称 | M 的形状 | N 的形状 | FLOPs | 内存读取 | 内存写入 |
|---|---|---|---|---|---|
| QKV 线性 | ( B d , h ) \left(B_{d}, h\right) (Bd,h) | ( h , 3 h ) (h, 3 h) (h,3h) | 3 B d h 2 3 B_{d} h^{2} 3Bdh2 | B d h + 3 h 2 B_{d} h+3 h^{2} Bdh+3h2 | 3 B d h 3 B_{d} h 3Bdh |
| 注意力输出 | ( B d , h ) \left(B_{d}, h\right) (Bd,h) | ( h , h ) (h, h) (h,h) | B d h 2 B_{d} h^{2} Bdh2 | B d h + h 2 B_{d} h+h^{2} Bdh+h2 | B d h B_{d} h Bdh |
| FFN 输入 | ( B d , h ) \left(B_{d}, h\right) (Bd,h) | ( h , m ) (h, m) (h,m) | B d h m B_{d} h m Bdhm | B d h + h m B_{d} h+h m Bdh+hm | B d m B_{d} m Bdm |
| FFN 输出 | ( B d , m ) \left(B_{d}, m\right) (Bd,m) | ( m , h ) (m, h) (m,h) | B d h m B_{d} h m Bdhm | B d m + h m B_{d} m+h m Bdm+hm | B d h B_{d} h Bdh |
表4. 解码批次中的GEMM操作的FLOPs和内存访问。
包含
B
d
B_{d}
Bd个解码请求的批次可以表示为:
M d = 4 h 2 + 8 B h + 2 h m + 2 B m + ∑ i = 0 i = B d − 1 2 l ^ i s + 2 s F d = 4 B h 2 + 2 B h m + ∑ i = 0 i = B d − 1 2 l ^ i s \begin{gathered} M_{d}=4 h^{2}+8 B h+2 h m+2 B m+\sum_{i=0}^{i=B_{d}-1} 2 \hat{l}_{i} s+2 s \\ F_{d}=4 B h^{2}+2 B h m+\sum_{i=0}^{i=B_{d}-1} 2 \hat{l}_{i} s \end{gathered} Md=4h2+8Bh+2hm+2Bm+i=0∑i=Bd−12l^is+2sFd=4Bh2+2Bhm+i=0∑i=Bd−12l^is
A. 4 带分块预填充的混合批次
在带有分块预填充的混合批次中,可以从表 3 & 4 3 \& 4 3&4中分别得出预填充请求和解码请求的GEMM操作。类似地,解码请求的内存访问和flops计算仍然受A.3中推导结果的限制。然而,分块预填充请求的内存访问与每个请求到当前批次为止处理的提示标记数量密切相关。
假设在一个混合批次中有
B
p
B_{p}
Bp个预填充。该批次中处理的总预填充标记数可以表示为
∑
i
=
0
B
p
−
1
c
i
\sum_{i=0}^{B_{p}-1} c_{i}
∑i=0Bp−1ci。为了计算当前批次中每个请求的提示块的注意力,我们需要加载当前批次中每个请求之前处理的所有
k
,
v
∈
R
l
×
s
k, v \in R^{l \times s}
k,v∈Rl×s。这占用了每个请求
2
l
i
s
2 l_{i} s
2lis内存访问。类似于A.2,对于每对
k
,
v
k, v
k,v块,我们需要加载
q
q
q块以计算注意力。但是,与A.2不同的是,我们只需要访问当前块的
q
q
q块。每对
k
,
v
k, v
k,v块的总内存访问为
3
c
i
s
3 c_{i} s
3cis,这占了
q
,
o
q, o
q,o块的内存读写。
k
,
v
k, v
k,v块对的总数等于
l
i
/
b
l_{i} / b
li/b。因此,当前混合批次中预填充标记的内存访问可以表示为
∑
i
=
0
B
p
−
1
2
l
i
s
+
3
c
i
s
(
l
i
/
b
)
\sum_{i=0}^{B_{p-1}} 2 l_{i} s+3 c_{i} s\left(l_{i} / b\right)
∑i=0Bp−12lis+3cis(li/b)。关于flops计数,当前批次中请求
i
i
i的查询
q
∈
R
c
i
×
s
q \in R^{c_{i} \times s}
q∈Rci×s需要对所有之前处理的
l
i
l_{i}
li个
K
,
V
K, V
K,V标记执行注意力。
P
=
q
K
T
P=q K^{T}
P=qKT中的flops数量可以表示为
s
l
i
c
i
,
q
∈
R
c
i
×
s
,
K
∈
R
l
i
×
s
s l_{i} c_{i}, q \in R^{c_{i} \times s}, K \in R^{l_{i} \times s}
slici,q∈Rci×s,K∈Rli×s,
而在
O
=
P
V
O=P V
O=PV中可以表示为
s
l
i
c
i
,
P
∈
R
c
i
×
l
i
,
V
∈
R
l
i
×
s
s l_{i} c_{i}, P \in R^{c_{i} \times l_{i}}, V \in R^{l_{i} \times s}
slici,P∈Rci×li,V∈Rli×s。因此,在当前批次中为请求
i
i
i预填充所有查询标记的总flops可以表示为
2
s
l
i
c
i
2 s l_{i} c_{i}
2slici。所以在一个包含
B
p
B_{p}
Bp个分块预填充请求的混合批次中,flops计数可以表示为
∑
i
=
0
B
p
−
1
2
s
l
i
c
i
\sum_{i=0}^{B_{p}-1} 2 s l_{i} c_{i}
∑i=0Bp−12slici。结合批次中的解码请求
B
d
B_{d}
Bd,我们将混合批次中的总内存访问表示为
M m = 4 h 2 + 2 h m + ( 8 ∑ i = 0 B p − 1 l i h + 2 ∑ i = 0 B p − 1 l i m + ∑ i = 0 B p − 1 2 l i s + 3 c i s l i b ) + ( 8 B d h + 2 B d m + ∑ i = 0 B d − 1 2 l ^ i s + 2 s ) \begin{aligned} M_{m}= & 4 h^{2}+2 h m+\left(8 \sum_{i=0}^{B_{p-1}} l_{i} h+2 \sum_{i=0}^{B_{p-1}} l_{i} m+\sum_{i=0}^{B_{p-1}} 2 l_{i} s\right. \\ & \left.+3 c_{i} s \frac{l_{i}}{b}\right)+\left(8 B_{d} h+2 B_{d} m+\sum_{i=0}^{B_{d}-1} 2 \hat{l}_{i} s+2 s\right) \end{aligned} Mm=4h2+2hm+ 8i=0∑Bp−1lih+2i=0∑Bp−1lim+i=0∑Bp−12lis+3cisbli)+(8Bdh+2Bdm+i=0∑Bd−12l^is+2s)
相应的flops可以表示为
F m = ( ∑ i = 0 B p − 1 ( 4 c i h 2 + 2 c i h m + 2 s l i c i ) ) + ( 4 B d h 2 + 2 B d h m + ∑ i = 0 B d − 1 2 l ^ i s ) \begin{aligned} F_{m}= & \left(\sum_{i=0}^{B_{p}-1}\left(4 c_{i} h^{2}+2 c_{i} h m+2 s l_{i} c_{i}\right)\right) \\ & +\left(4 B_{d} h^{2}+2 B_{d} h m+\sum_{i=0}^{B_{d}-1} 2 \hat{l}_{i} s\right) \end{aligned} Fm= i=0∑Bp−1(4cih2+2cihm+2slici) +(4Bdh2+2Bdhm+i=0∑Bd−12l^is)
A. 5 Goodput比较
图14显示了未在主文中呈现的不同数据集上模型的有效吞吐量性能。
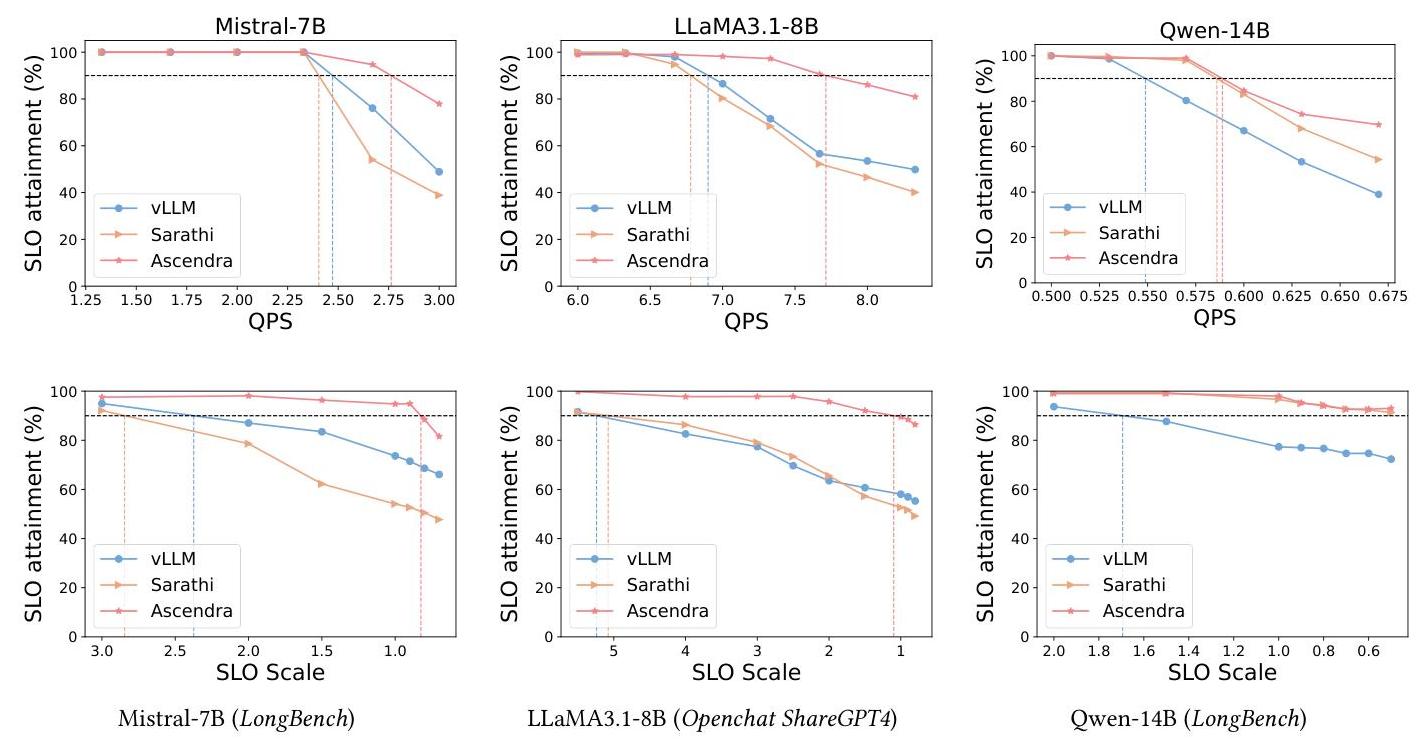
图14. 上排显示了Ascendra、vLLM和Sarathi-Serve在Openchat ShareGPT4和Longbench文本摘要数据集上的有效吞吐量比较。下排显示了Ascendra相对于SLO规模的灵活性。
参考论文:https://arxiv.org/pdf/2504.20828



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











