






Tiange Luo 1 , 2 { }^{1,2} 1,2 Lajanugen Logeswaran 2 , † { }^{2, \dagger} 2,† Justin Johnson 1 , † { }^{1, \dagger} 1,† Honglak Lee 1 , 2 , † { }^{1,2, \dagger} 1,2,† 密歇根大学 1 { }^{1} 1 LG AI 研究所 2 { }^{2} 2 † { }^{\dagger} † 共同指导
摘要
我们引入了RegionFocus,这是一种用于视觉语言模型代理的视觉测试时扩展方法。由于GUI图像的视觉复杂性和大量界面元素的存在,理解网页具有挑战性,这使得准确的动作选择变得困难。我们的方法通过动态聚焦相关区域来减少背景干扰并提高定位准确性。为了支持这一过程,我们提出了一种图像即地图机制,该机制在每一步可视化关键地标,提供透明的动作记录,并使代理能够有效选择动作候选者。即使采用简单的区域选择策略,我们在Screenspot-pro和WebVoyager基准测试中观察到相对于两个最先进的开放视觉语言模型代理(UI-TARS和Qwen2.5VL)性能提高了28%以上和24%以上,这突显了交互环境中视觉测试时扩展的有效性。通过将RegionFocus应用于Qwen2.5VL-72B模型,我们在ScreenSpotPro基准测试中实现了61.6%的新最先进定位性能。我们的代码将在https://github.com/tiangeluo/RegionFocus公开发布。
1. 引言
图形用户界面(GUI)代理在现代计算中变得越来越重要,从自动网络浏览到直观的操作系统导航都有应用 [1, 21]。随着大规模视觉语言模型(VLMs)的普及,研究人员试图利用文本和视觉信息构建更强大的交互系统 [2]。虽然许多现有框架严重依赖基于文本的推理 [39, 46] 或简单的视觉定位 [11, 22],但现实世界的GUI通常包含大量的无关元素——如菜单栏、广告和多余的按钮——这些可能会压倒纯文本或幼稚的视觉方法。这种文本重推理与GUI视觉复杂性之间的不匹配导致频繁错误(例如,点击错误的按钮或导航到非预期部分)。由于这些任务通常是高级别的,
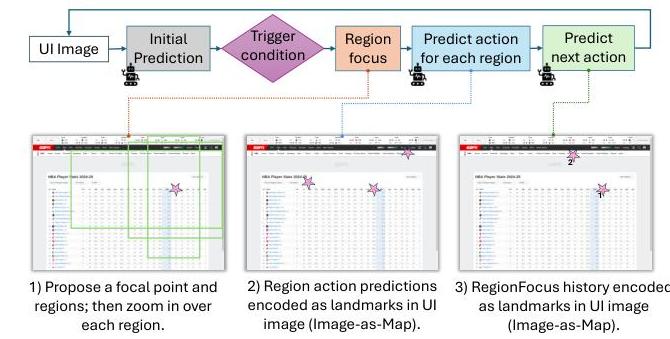
图1. 概述。当GUI代理遇到执行错误时,我们指示模型专注于特定的兴趣点并提取该焦点周围的多个子区域(1)。然后,代理为每个子区域独立生成候选动作。与特定坐标交互的动作用粉色星号地标标记(例如,“点击”),以视觉方式指示相关位置(2)。我们保留粉色星号地标以跟踪RegionFocus的交互历史,以便进行多样化的探索(3)。
这种低级错误会累积起来,最终导致更高的失败率和整体较差的表现。
最近关于GUI代理的研究通常分为两大类:一类依赖文本线索进行规划和推理,另一类通过VLMs结合视觉信息。基于文本的方法通常为每个视觉元素生成文本标签或边界框以引导代理动作 [22, 46]。然而,它们在视觉纠缠的任务中可能表现不佳,其中文本描述模糊、不完整或无法捕捉关键视觉特征(例如,浮动窗口),即使使用可访问性树也是如此。另一方面,基于视觉的管道 [11, 28] 通常严重依赖VLM对视觉元素的定位能力。我们观察到许多错误是由于无意点击空或错误的接口组件引起的,这凸显了现有单推断视觉定位方法使用VLM的局限性。一旦发生错误,就没有反馈循环来纠正它,导致错误在整个过程中累积。
受这些缺点的启发,我们提出了一个视觉测试时扩展框架,称为RegionFocus,旨在在执行错误发生或其他条件触发时,将GUI模型的注意力缩小到显著的接口区域。具体来说,如图1(1)所示,我们利用VLM识别兴趣点的能力,并将其与固定比例掩码或SAM [16]等分割模型生成的边界框建议相结合。对于每个子区域,代理仅基于局部上下文独立预测动作(图1(2)),随后聚合顶级候选动作以形成细化的单步响应。此外,与网络或操作系统接口的交互允许我们的方法放大目标区域,增强选定区域的分辨率以进行更仔细的检查。RegionFocus作为GUI代理的模块化插件工作,不会影响原始工作流程。
为了跟踪RegionFocus访问的区域,我们引入了一种图像即地图机制来记录时间信息。在这种方法中,代理之前考虑过的元素在UI截图中标注了视觉地标(例如,图1 (3)中的粉星)。这些地标防止代理重新访问它已经检查过的区域,并引导代理走向未探索的区域。这些标记不会干扰模型的常规推理过程,该过程利用未修改的网页截图,只在RegionFocus组件中使用。一旦代理导航到新页面,所有地标都会刷新以获得新的RegionFocus历史。
除了表示RegionFocus历史外,我们还在动作聚合过程中(图1 (2))利用图像即地图,其中候选动作使用地标表示以选择最佳动作。我们发现图像即地图在表示时间信息(例如,之前访问的区域)和空间信息(例如,多个动作候选者)方面比其他表示(例如,仅以文本形式表示的元素坐标)更为有效。这对于区分近距离屏幕元素尤为重要,仅基于坐标的文本表示难以推理。
通过我们提出的视觉测试时扩展框架,我们帮助现有模型——如UI-TARS [28] 和 QWen2.5-VL [3] ——在基于网络和桌面的接口中实现更好的性能。特别是,我们在OS级别的GUI导航(例如 ScreenSpot-Pro [18])以及浏览器自动化(例如 WebVoyager [13])基准测试中展示了显著的性能提升。通过我们的实验,我们显示即使是一个简单的固定比例边界框生成方法也能显著优于基线系统,这突显了将模型的注意力集中在视觉相关区域上的有效性。我们的实证研究进一步表明,图像即地图在VLM代理中始终优于基于文本的表示。总的来说,我们的研究结果强调了视觉测试时扩展作为现有VLM基础GUI代理的一个简单而强大的扩展的价值。
2. 相关工作
2.1. GUI代理
大型语言模型(LLMs)和视觉语言模型(VLMs)的最新进展显著增强了GUI自动化,使代理能够通过文本和视觉模态有效地与各种图形环境互动 [8, 11, 15, 21, 24, 27, 31, 33, 34, 38, 40]。先前的研究通常采用两种不同的方法:(1) 基于文本的推理,利用HTML或可访问性树等结构化表示 [5, 17, 47],提取结构化界面信息 [22, 43] 和补充文本细节以输入到LLMs/VLMs [46]; 和 (2) 基于视觉的推理,依靠VLM直接解释GUI元素 [11, 28]。尽管基于文本的技术可以高效处理结构化信息,但在处理视觉复杂或模糊的界面时常遇到困难 [13, 18, 36],导致不准确和可靠性降低。类似观察在[39]中也有报道。相反,视觉定位方法可能因过于宽泛的视觉关注而意外与无关或空白区域互动。与之前使用整个界面屏幕作为输入的方法不同 [6, 14, 29],我们的方法通过新颖的视觉测试时扩展框架明确分离规划与视觉定位。该框架通过精确的边界框建议选择性地针对显著的GUI区域,并集成创新的“图像即地图”策略,保持整个交互过程中的上下文连贯性。
2.2. AI代理中的测试时扩展
测试时扩展涉及在推理期间动态调整计算资源以增强模型性能 [32, 35, 41, 42]。这种方法允许AI代理为具有挑战性的任务分配额外的处理能力,从而改进决策和准确性。受测试时扩展用于LLMs的进展启发,几项研究已将类似原则扩展至GUI代理。例如,在推理过程中,[45] 利用中间动作历史,[25] 在推理期间收集外部信息,而 [44] 将反思机制纳入AI代理。尽管这些方法在改进性能方面取得成功,但它们并未充分利用视觉信息的独特优势。本文中,我们提出了初步的视觉测试时扩展方法,动态调整图像焦点区域,并采用“图像即地图”技术编码历史信息以实现更有效的GUI代理推理。
2.3. 视觉图像注意
视觉图像注意机制有着丰富的历史,能够使AI模型有选择地关注视觉输入中的相关区域 [9, 12, 20, 37]。这种机制
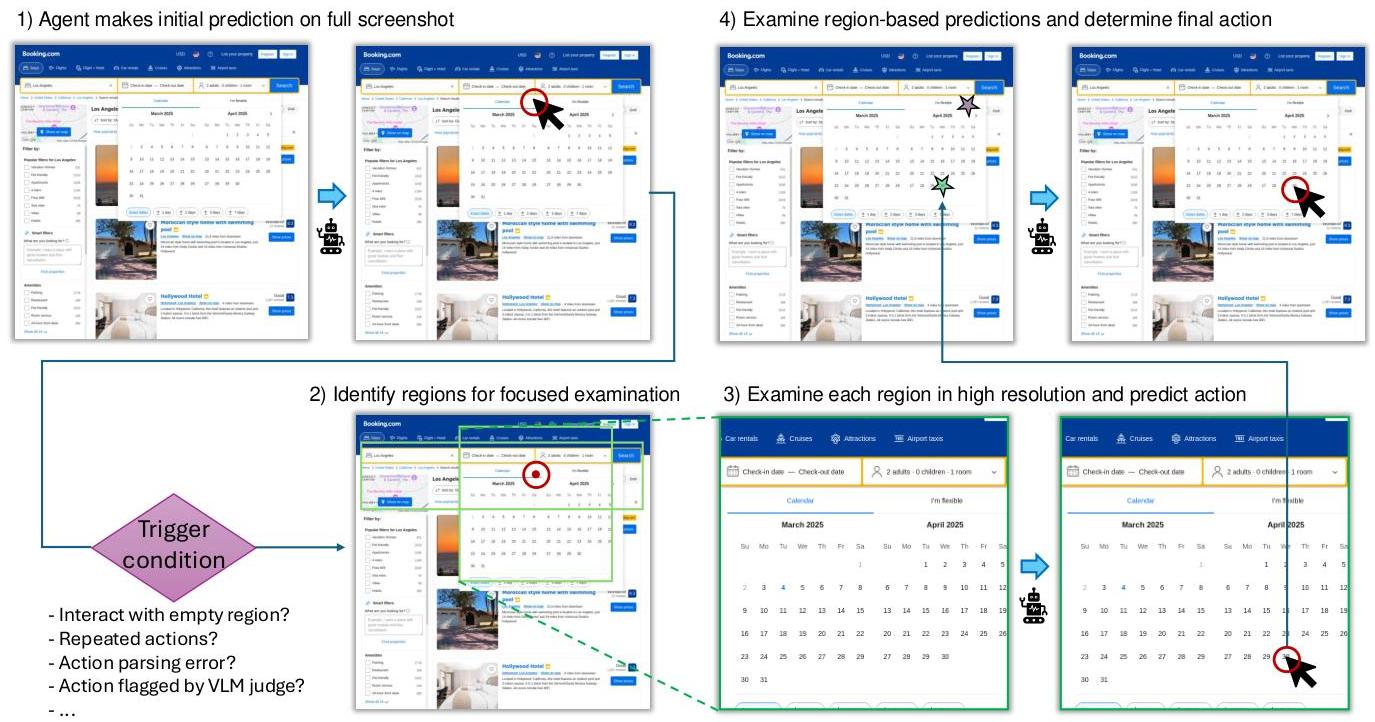
图2. 将RegionFocus整合到GUI代理管道的概述。标准推理过程(蓝色箭头)接收输入信息并持续预测后续动作。当GUI代理遇到错误时,RegionFocus(绿色箭头)被激活,提出焦点以提取目标子区域。然后为这些子区域单独预测动作,并将所有动作聚合为单一细化动作以供标准推理使用。
特别关键的是基于GUI的代理,其中在视觉混乱的环境中准确识别和与界面元素互动是至关重要的。我们提出的方法引入了一种利用预定义边界框的区域聚焦机制,通过历史记录逐步精炼其注意力,逐渐更精确地集中于目标元素。这种迭代精炼与之前的递归模型 [4, 23] 在概念上有相似之处;然而,我们的方法利用VLM来实现精炼 [26],独特地将此过程直接集成到GUI代理的测试时扩展中。通过VLM直接生成这些注意力区域仍然是未来研究的一个开放方向。
3. 方法
为了解决当前GUI代理框架的局限性,我们提出了一种视觉测试时扩展方法,增强了VLM代理与复杂图形用户界面交互的鲁棒性和准确性。与传统方法不同,传统方法统一对待所有界面元素,而我们的方法通过选择性地强调视觉显著区域动态调整模型的焦点,无论何时检测到潜在错误。这种方法显著减少了误点击和导航错误。
至关重要的是,我们的框架完全在推理时间运行,能够轻松集成到现有的VLM代理中,无需重新训练或架构修改。在以下章节中,我们首先描述我们的管道与现有GUI代理的集成过程,接着详细解释每个组件的设计原则和实现。
3.1. 概述
图2展示了我们提出的管道。在标准交互管道的基础上,我们的方法引入了一个由错误触发的细化机制。具体来说,当代理遇到触发条件——如点击非交互元素(例如,选择空白空间而不是预期的日期选项)或重复不成功的动作(例如,反复输入“洛杉矶”而未能成功点击正确的按钮)——RegionFocus组件被激活。
在此细化阶段,代理最初预测一个靠近目标元素的焦点。基于这个近似位置,它生成一个可能包含目标元素的边界框(第3.2节)。对于由边界框定义的每个区域,代理独立预测候选动作。最后,代理根据每个区域的预测汇总一个要执行的单一动作。
此外,我们使用图像即地图表示法维护在相同UI图像上先前检查的焦点的历史记录(第3.3节)。这种视觉历史记录引导代理避免冗余搜索,并帮助它逐步聚焦于正确的目标。涉及特定坐标的交互预测被视觉标记(例如,使用粉色星号地标)以帮助模型验证其选择的正确性。
3.2. 视觉区域聚焦
我们管道的核心是一种在推理期间激活的动态视觉适应机制。当初始动作预测导致错误——如点击非交互或空白区域——模型动态调整其视觉注意力。具体来说,它通过在视觉显著区域周围生成边界框建议来细化注意力,从而实现更精确的单步动作。
触发条件 我们定义了两种主要类型的触发条件。第一种依赖于从与动态GUI环境的直接交互中获得的环境反馈,如交互式网页。像点击非交互元素这样的错误可以根据环境反馈轻松检测(例如,网页变化)。第二种触发条件发生在无法进行环境交互的情况下,我们处理静态截图(例如 ScreenSpot-Pro [19] 情景)。在这里,VLM评估预测的动作,将其角色从仅仅做预测转变为明确评估动作的正确性。尽管VLM的判断并不总是完全准确,但它们在我们的实验中显著帮助识别和减轻错误。
边界框建议 实验表明,VLM代理可靠地产生靠近目标元素的焦点点,但在直接预测准确的边界框方面存在困难 [10]。因此,我们从这些焦点点派生边界框,而不是直接预测它们。尽管先进的分割模型(例如,SAM [16])可以提供更精确的边界框,但我们目前专注于利用GUI代理本身。这确保了未来GUI代理的改进能直接惠及我们的方法。
我们采用一种启发式方法,定义围绕焦点点的边界框,具有固定的尺寸和纵横比(例如,宽度0.5 x 高度0.5)。如果边界框超出图像边界,则调整使其完全保留在截图内。这种简单而有效的策略在准确性和计算效率之间取得了良好的平衡。
动作候选预测 给定从前一阶段提取的边界框确定的区域,代理为每个区域预测一个动作。如果代理可以与环境交互(例如,在网页情况下),则向代理提供该区域的放大高分辨率视图。在这种情况下,至少可以通过放大使该区域的一侧与原始全图像分辨率相匹配。如果无法进行环境交互,我们只是从初始图像裁剪该区域并对其进行上采样以进行预测。
动作聚合 在GUI代理独立分析每个边界框建议并生成候选动作后,我们基于这些候选动作选择一个单一动作作为推理管道的下一步。对于基于坐标的动作(例如,“点击(x,y)”或“滚动(x,y)向下”),我们在快照上视觉标记候选动作坐标,如图1(2)所示。 1 { }^{1} 1 这个过程显著减少了模型的工作量,简化了文本坐标在图像上的映射和解释方式。经验表明,结合这些视觉标记引导模型更准确地选择动作候选者。
3.3. 图像即地图
当RegionFocus在同一UI图像上被多次触发时,重要的是代理生成多样化的焦点并避免重新访问之前探索过的区域。最初,我们尝试使用文本坐标表示区域焦点历史,但发现这种方法无效,因为代理经常重新访问类似的焦点点,即使有明确提示避免它们。
为了解决这个问题,我们提出了一种图像即地图表示法,其中我们将之前检查过的焦点点作为地标(例如,粉星)直接视觉编码到UI截图上(图3)以记录过去的动作点。与基于文本的历史相比,这种视觉表示更有效地
1 { }^{1} 1 地标注释仅用于涉及与当前视图中的特定点和元素交互的动作。
| 代理模型 | 开发 | 创意 | CAD | 科学 | 办公室 | 操作系统 | 平均 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 文本 | 图标 | 平均 | 文本 | 图标 | 平均 | 文本 | 图标 | 平均 | 文本 | 图标 | 平均 | 文本 | 图标 | 平均 | 文本 | 图标 | 平均 | 文本 | 图标 | 平均 | |
| QwenVL-7B | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.7 | 0.0 | 0.4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 0.0 | 0.1 |
| GPT-4o | 1.3 | 0.0 | 0.7 | 1.0 | 0.0 | 0.6 | 2.0 | 0.0 | 1.5 | 2.1 | 0.0 | 1.2 | 1.1 | 0.0 | 0.6 | 0.0 | 0.0 | 0.0 | 1.3 | 0.0 | 0.8 |
| SeeClick | 0.6 | 0.0 | 0.3 | 1.0 | 0.0 | 0.6 | 2.5 | 0.0 | 1.9 | 3.5 | 0.0 | 2.0 | 1.1 | 0.0 | 0.5 | 2.8 | 0.0 | 1.5 | 1.8 | 0.0 | 1.1 |
| Qwen2-VL-7B | 2.6 | 0.0 | 1.3 | 1.5 | 0.0 | 0.9 | 0.5 | 0.0 | 0.4 | 6.3 | 0.0 | 3.5 | 3.4 | 1.9 | 3.0 | 0.9 | 0.0 | 0.5 | 2.5 | 0.2 | 1.6 |
| OS-Atlas-4B | 7.1 | 0.0 | 3.7 | 3.0 | 1.4 | 2.3 | 2.0 | 0.0 | 1.5 | 9.0 | 5.5 | 7.5 | 5.1 | 3.8 | 4.4 | 5.6 | 0.0 | 3.1 | 5.0 | 1.7 | 3.7 |
| ShowUI-2B | 16.9 | 1.4 | 9.4 | 9.1 | 0.0 | 5.3 | 2.5 | 0.0 | 1.9 | 13.2 | 7.3 | 10.6 | 15.3 | 7.5 | 13.5 | 10.3 | 2.2 | 6.6 | 10.8 | 2.6 | 7.7 |
| CogAgent-18B | 14.9 | 0.7 | 8.0 | 9.6 | 0.0 | 5.6 | 7.1 | 3.1 | 6.1 | 22.2 | 1.8 | 13.4 | 13.0 | 0.0 | 6.5 | 5.6 | 0.0 | 3.1 | 12.0 | 0.8 | 7.7 |
| Aria-UI | 16.2 | 0.0 | 8.4 | 23.7 | 2.1 | 14.7 | 7.6 | 1.6 | 6.1 | 27.1 | 6.4 | 18.1 | 20.3 | 1.9 | 16.1 | 4.7 | 0.0 | 2.6 | 17.1 | 2.0 | 11.3 |
| UGround-7B | 26.6 | 2.1 | 14.7 | 27.3 | 2.8 | 17.0 | 14.2 | 1.6 | 11.1 | 31.9 | 2.7 | 19.3 | 31.6 | 11.3 | 27.9 | 17.8 | 0.0 | 9.7 | 25.0 | 2.8 | 16.5 |
| Claude Comp.Use | 22.0 | 3.9 | 12.6 | 25.9 | 3.4 | 16.8 | 14.5 | 3.7 | 11.9 | 33.9 | 15.8 | 25.8 | 30.1 | 16.3 | 26.2 | 11.0 | 4.5 | 8.1 | 23.4 | 7.1 | 17.1 |
| OS-Atlas-7B | 33.1 | 1.4 | 17.7 | 28.8 | 2.8 | 17.9 | 12.2 | 4.7 | 10.3 | 37.5 | 7.3 | 24.4 | 33.9 | 5.7 | 27.4 | 27.1 | 4.5 | 16.8 | 28.1 | 4.0 | 18.9 |
| UGround-V1-7B | - | - | 35.5 | - | - | 27.8 | - | - | 13.5 | - | - | 38.8 | - | - | 48.8 | - | - | 26.1 | - | - | 31.1 |
| UI-TARS-7B | 58.4 | 12.4 | 36.1 | 50.0 | 9.1 | 32.8 | 20.8 | 9.4 | 18.0 | 63.9 | 31.8 | 50.0 | 63.3 | 20.8 | 53.5 | 30.8 | 16.9 | 24.5 | 47.8 | 16.2 | 35.7 |
| + RegionFocus | 59.7 | 15.9 | 38.5 | 59.6 | 11.9 | 39.6 | 30.5 | 7.8 | 24.9 | 67.4 | 30.0 | 51.2 | 69.5 | 30.2 | 60.4 | 45.8 | 21.3 | 34.7 | 55.2 | 18.7 | 41.2 |
| UI-TARS-72B | 63.0 | 17.3 | 40.8 | 57.1 | 15.4 | 39.6 | 18.8 | 12.5 | 17.2 | 64.6 | 20.9 | 45.7 | 63.3 | 26.4 | 54.8 | 42.1 | 15.7 | 30.1 | 50.9 | 17.5 | 38.1 |
| + RegionFocus | 72.1 | 26.9 | 50.2 | 68.7 | 22.4 | 49.3 | 35.5 | 25.0 | 33.0 | 77.1 | 30.9 | 57.1 | 72.9 | 45.3 | 66.5 | 63.6 | 27.0 | 46.9 | 64.0 | 28.0 | 50.2 |
| Qwen2.5-VL-7B | 45.5 | 1.4 | 24.1 | 32.8 | 6.3 | 21.7 | 22.3 | 6.2 | 18.4 | 50.7 | 7.3 | 31.9 | 52.5 | 15.1 | 43.9 | 36.4 | 10.1 | 24.5 | 39.3 | 6.6 | 26.8 |
| + RegionFocus | 52.6 | 4.8 | 29.4 | 42.9 | 7.7 | 28.2 | 31.0 | 3.1 | 24.1 | 56.9 | 10.9 | 37.0 | 64.4 | 26.4 | 55.7 | 43.0 | 15.7 | 30.6 | 48.0 | 9.9 | 33.5 |
| Qwen2.5-VL-72B | 66.2 | 13.8 | 40.8 | 64.6 | 15.4 | 44.0 | 47.7 | 12.5 | 39.1 | 78.5 | 29.1 | 57.1 | 74.6 | 37.7 | 66.1 | 60.7 | 22.5 | 43.4 | 64.9 | 20.2 | 47.8 |
| + RegionFocus | 75.3 | 25.5 | 51.2 | 76.3 | 30.8 | 57.2 | 71.6 | 28.1 | 60.9 | 87.5 | 39.1 | 66.5 | 87.0 | 60.4 | 80.9 | 74.8 | 36.0 | 57.1 | 78.6 | 34.1 | 61.6 |
表1. ScreenSpot-Pro的各种模型比较。[19]. 我们提出的RegionFocus帮助UI-TARS-72B [28]模型实现了
31.8
%
31.8 \%
31.8%的改进,而Qwen2.5-VL-72B [3]获得了
28.9
%
28.9 \%
28.9%的提升,从而达到了最先进的性能。此外,将RegionFocus集成到UI-TARS-7B中使其超越了规模更大的UI-TARS-72B模型的性能。
传达时间信息,允许代理直接在图像上进行推理并避免重新访问相同的区域。请注意,用于动作聚合的地标注释过程也是一种图像即地图策略,捕获空间信息。地标注释的快照仅在RegionFocus过程中使用,而初始动作预测的原始推理管道接收未修改的UI图像。我们维持这些突出显示的地标直到某个动作生效(即引起有意义的状态变化),此时历史记录会被刷新。我们的实证结果显示,这种图像即地图策略在更复杂的多步骤GUI任务中始终优于基于文本的方法。我们还观察到,它有助于代理区分非常接近的两个GUI元素,如图8(2)所示。
4. 实验
在下面的实验部分中,我们将我们提出的管道与UI-TARS [28]和Qwen2.5-VL [3]集成,这两个最近提出的GUI代理模型自主地与GUI截图交互,并在各种GUI任务中表现出色。我们在操作系统操作任务和Web交互中评估我们的管道。在我们的主要实验中,我们采用固定边界框方法(第3.2节),仅使用代理模型本身。我们还包括使用SAM [16]的消融研究,它提供了更准确的边界框。更多的实验细节见附录A。
4.1. ScreenSpot-Pro
ScreenSpot-Pro [19] 是最近推出的一个基准,专门设计用于评估在复杂的高分辨率专业桌面环境中GUI定位能力。这些环境通常涉及大于 3 k × 2 k 3 k \times 2 k 3k×2k 的截图(参见他们论文中的图1(b)获取具体配置详情)。该基准强调精细、大规模的界面,使其成为评估我们提出的管道的理想平台,该管道包含一个机制,可以放大局部区域进行更详细的分析。
具体来说,ScreenSpot-Pro 包含来自五个领域和三个操作系统的23个应用程序的专家标注任务,从而提供了对模型性能的广泛评估。任务按功能领域分类,包括开发、创意、CAD、科学、办公和操作系统,并进一步划分为基于文本和图标/小部件的定位挑战。这种结构促进了对定位能力的细致评估,特别是在需要精确定位和与小或视觉相似的GUI元素交互的任务中。该基准强制执行严格的指标,根据模型预测的位置是否落入目标元素的边界框内来测量定位准确性。
由于ScreenSpot-Pro仅提供静态截图——没有操作系统环境进行交互——我们采用基于VLM的法官来触发RegionFocus。具体来说,当代理预测一个点时,我们会在输入截图中用粉星地标突出该点,并要求模型本身评估该点的正确性。如果判定为不正确,我们就会启动RegionFocus过程。
结果 在表1中,我们总结了各种方法在ScreenSpotPro上的定位准确性报告。为了公平比较,我们使用ScreenSpot-Pro发布的官方测试代码进行评估。我们在表1中报告了UI-TARS论文中的原始数据。
从表1可以看出,与基础模型相比,RegionFocus在文本和图标定位的所有类别中都一致提升了性能。UI-TARS-72B + RegionFocus在基础UI-TARS-72B模型上实现了 31.7 % 31.7 \% 31.7%的改进。此外,UI-TARS-7B + RegionFocus变体总体上超过了UI-TARS-72B模型,证明了我们方法的有效性。此外,RegionFocus进一步帮助QWen2.5-VL-72B实现了最先进的性能,达到 61.6 % 61.6 \% 61.6%。
图4展示了我们的管道在ScreenSpot-Pro中的工作原理:我们首先让代理判断初始动作预测。如果它是不正确的,我们通过放大代理预测的区域来启动RegionFocus,预测每个区域内的动作,最后将所有动作聚合为单一结果。因为我们使用代理模型本身来判断预测的正确与否,我们的结果显示,尽管VLM可能最初生成不正确的坐标,但它仍然可以在图像即地图的帮助下可靠地判断点击点是否正确。然后,这种不正确的预测可以通过RegionFocus过程进行修正。这种生成-验证差距也在最近的文献中有所提及 [ 7 , 30 ] [7,30] [7,30]。
4.2. WebVoyager
WebVoyager [13] 是一个基准,旨在通过与真实世界网站的多模态交互来评估自主网络代理在执行复杂开放式任务中的能力。不同于以前的网络代理基准,WebVoyager 包括来自15个流行的真实世界网站的643个半自动生成的任务,如Amazon、Apple、ArXiv和Google Maps。这一选择确保了反映日常网络浏览场景的多样化交互。WebVoyager中的任务要求代理处理从渲染的截图中获取的视觉信息和来自网页元素的文本提示,从而使多模态推理和导航技能得到细致评估。此外,该基准引入了利用GPT-4V的自动评估协议,与人类判断的达成率为85.3%,从而提供了对代理性能的可靠评估。
在这种情况下,代理主动与网络环境交互。我们使用Playwright控制的Chrome浏览器导航网页,VLM代理根据每个网页截图确定适当的行动。任务执行后,我们使用官方评估设置,其中GPT评审员审查最后15张截图以及可选的文本响应,以确定任务是否成功完成。
结果 表2展示了各种网络代理在WebVoyager基准测试上的任务成功率。RegionFocus在所有类型的网站上——包括“Booking”和“Search”——持续改善性能,突显了将RegionFocus集成到GUI代理中用于网络浏览的有效性。它也给两个开源模型UI-TARS和Qwen2.5-VL带来了持续的改进。请注意,我们的模型性能受到在线交互约束的影响——如机器人阻止和间歇性的VPN问题。通过解决这些因素,我们可以进一步提升模型的整体性能。
我们在图5和图6中展示了几个WebVoyager性能的定性示例。在图5左图中,代理最初通过点击搜索栏中出现的“成分”按钮失败,尽管在正确的页面上。通过用绿色边界框突出相关的区域,RegionFocus自然过滤掉背景噪音,吸引注意力到主要内容。在图5右图中,RegionFocus放大感兴趣的子区域,放大关键内容,使代理更容易找到目标内容。图6左图展示了一个案例,代理最初点击了一个无关的元素。我们的管道通过提出两个紧密排列的按钮来纠正这个错误。图像即地图机制允许代理区分这些几乎相同的元素,即使它们的坐标只有微小差异。最后,图6右图说明了一个场景,代理错误地点击了靠近所需元素的空白区域。再次,RegionFocus突出了正确的按钮,帮助代理准确选择它。
更多分析 图7显示了组合模型+RegionFo-
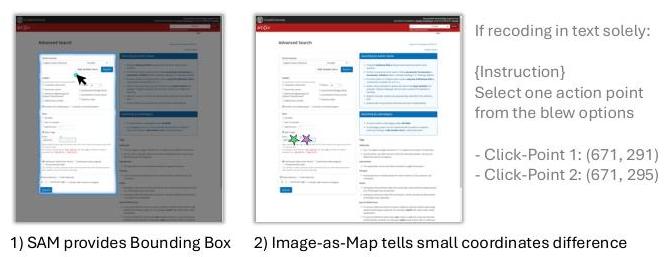
图8. 消融研究。(1)RegionFocus可以直接使用SAM生成边界框。(2)图像即地图如何帮助突出不同GUI元素之间的细微差异。
cus 方法与单独的基础模型在400条轨迹上的步数差异分布。仅计算实际的浏览器交互步骤,排除RegionFocus开销。这里的基础模型是UI-TARS-72B。如图所示,基础模型+RegionFocus通常平均增加了步数(19.74% 步数),与此对应的是整体34.3%的成功率提升。在Web浏览中,RegionFocus平均每条轨迹触发5.8次。平均而言,RegionFocus每条Web浏览轨迹触发5.8次。此外,在32.3%的情况下,RegionFocus仅触发一次,但单次触发就能使这些轨迹的成功率显著提升83.7%。
4.3. 消融研究
我们在整个管道上进行了消融研究,包括我们的“图像即地图”设计选择和基于代理预测点的预定义边界框的使用。我们还演示了通过利用SAM [16]和增加轨迹步骤数量可以进一步提升性能。出于计算原因,我们
| 代理模型 | 总体 |
|---|---|
| 图像即地图 | 43.2 |
| 文本即历史 | 37.2 |
| 固定边界框 | 43.2 |
| 提议区域 | 28.1 |
| SAM | 46.5 |
表3. 消融研究结果。我们在WebVoyager的一个子集上进行了测试,分数越高越好。
使用UI-TARS-7B-DPO模型在WebVoyager基准的一个子集上进行这些消融研究。结果如表3所示,其中“图像即地图”和“固定边界框”指的是启用RegionFocus且最大动作步数限制为100的相同7B模型配置。
基于文本的RegionFocus历史表示 通过使用图像即地图,我们可以直接向代理提供视觉位置信息,帮助它区分甚至是最小的差异,从而增强其感知能力。例如,如图8(2)所示,我们在图像中用颜色编码点击点以表示图像即地图机制,而相应的坐标列在右侧的文本框中。值得注意的是,尽管文本坐标差异仅为五像素,但由此产生的动作可能会有很大差异。在这个消融研究中,我们使用文本表示来进行历史追踪和动作聚合,这与我们的图像即地图表示相比导致了显著的退化。
直接提议区域 在我们的管道(第3节)中,与其让代理模型直接提议一个边界框,我们首先提示它识别一个兴趣点,然后在该点周围生成一个预定义的边界框。这种设计选择源于观察到代理模型通常难以准确预测边界框。为了验证这一点,我们进行了一项实验,要求模型预测左上角和右下角坐标,然后用这些坐标裁剪UI图像。正如“Predict-Region”结果显示的那样,这种方法导致性能显著下降。
SAM 如第3节讨论的那样,我们的管道可以自然地利用接受点输入作为指示器的分割模型,例如SAM [16]。例如,在图8(1)中,我们为RegionFocus提供了一个由模型生成的点,尽管该点本身指向一个非交互的空白区域。然而,SAM能够生成一个包含正确区域的边界框,展示了其在这种情况下的适用性。表3的结果进一步验证了将基于点的分割模型纳入RegionFocus的有效性。
分析显示,结合RegionFocus自然会增加代理采取的步数。受此启发,我们研究了将推理步数限制提高到100以上或完全取消限制是否能带来进一步的性能提升。这里,推理步骤指的是实际的浏览器交互动作,不包括RegionFocus开销。由于计算限制,我们将限制扩展到300步,并评估了10步和50步的较低界限。所有实验均使用UI-TARS-7B模型进行。如图9所示,将最大值增加到300步使7B模型的性能从43.2提升到45.3,尽管大多数轨迹在达到300步上限之前就已终止。此外,随着最大推理步数阈值的增加,增量收益逐渐减少。
5. 结论
我们引入了RegionFocus,这是一种视觉测试时扩展方法,通过动态放大相关接口区域来解决现代GUI的混乱和模糊问题。通过集成标记关键地标的图像即地图机制,我们的方法提供了透明的动作记录并改进了基于坐标的动作预测。在Screenspot-pro和WebVoyager上的实验显示了显著的性能提升——即使采用简单的固定比例边界框策略——突显了视觉测试时扩展在增强交互式AI系统中的强大作用。
6. 致谢
该工作是在Tiange于LG AI Research的兼职实习期间完成的,并得到了通过密歇根大学授予的LG AI Research资助的支持。我们要感谢Jaekyeom Kim和Sungryull Sohn对代码库的讨论和贡献。
参考文献
[1] Peter Anderson, Qi Wu, Damien Teney, Jeffrey Bruce, Mark Johnson, Stephen Gould, 和 Anton van den Hengel. 视觉与语言导航:解释真实环境中的视觉基础导航指令。IEEE计算机视觉与模式识别会议(CVPR)论文集,第3674-3683页,2018年。1
[2] Anthropic. 开发计算机使用模型。https://www.anthropic.com/news/developing-computer-use,2024年。访问日期:2025-03-02。1
[3] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, 和 Junyang Lin. Qwen2.5-VL技术报告。arXiv预印本arXiv:2502.13923,2025年。2, 5, 6
[4] Zhaowei Cai 和 Nuno Vasconcelos. 级联R-CNN:深入高质量目标检测。IEEE计算机视觉与模式识别会议论文集,第6154-6162页,2018年。3
[5] Ruisheng Cao, Fangyu Lei, Haoyuan Wu, Jixuan Chen, Yeqiao Fu, Hongcheng Gao, Xinzhuang Xiong, Hanchong Zhang, Wenjing Hu, Yuchen Mao, 等人. Spider2-V:多模态代理距离自动化数据科学和工程工作流程还有多远?神经信息处理系统进展,37:107703-107744,2025年。2
[6] Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, 和 Zhiyong Wu. SeeClick:利用GUI定位以实现高级视觉GUI代理。arXiv预印本arXiv:2401.10935,2024年。2
[7] Stephen A Cook. 定理证明程序的复杂性。在逻辑、自动机和计算复杂度:Stephen A. Cook的作品中,第143-152页。2023年。7
[8] Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, 和 Yu Su. Mind2web:迈向通用网络代理。神经信息处理系统进展,36:28091-28114,2023年。2
[9] António Farinhas, André F. T. Martins, 和 Pedro M. Q. Aguiar. 多模态连续视觉注意力机制,2021年。2
[10] Yongchao Feng, Yajie Liu, Shuai Yang, Wenrui Cai, Jinqing Zhang, Qiqi Zhan, Ziyue Huang, Hongxi Yan, Qiao Wan, Chenguang Liu, 等人. 视觉语言模型用于目标检测和分割:综述与评估。arXiv预印本arXiv:2504.09480,2025年。4
[11] Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, 和 Yu Su. 模仿人类导航数字世界:GUI代理的通用视觉定位。arXiv预印本arXiv:2410.05243,2024年。1, 2
[12] Meng-Hao Guo, Tian-Xing Xu, Jiang-Jiang Liu, ZhengNing Liu, Peng-Tao Jiang, Tai-Jiang Mu, Song-Hai Zhang, Ralph R Martin, Ming-Ming Cheng, 和 Shi-Min Hu. 计算机视觉中的注意力机制:调查。计算视觉媒体,8(3):331-368,2022年。2
[13] Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, 和 Dong Yu. WebVoyager:使用大规模多模态模型构建端到端网络代理。arXiv预印本arXiv:2401.13919,2024年。2, 6,7
[14] Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, 等人. CogAgent:GUI代理的视觉语言模型。在IEEE/CVF计算机视觉与模式识别会议论文集中,第14281-14290页,2024年。2
[15] Geunwoo Kim, Pierre Baldi, 和 Stephen McAleer. 语言模型可以解决计算机任务。神经信息处理系统进展,36:39648-39677,2023年。2
[16] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hans Marx, Carl Rolland, Laura Gustafson, Tsung-Yi Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, 和 Ross Girshick. 分割任何东西。arXiv预印本arXiv:2304.02643,2023年。2, 4, 5, 8, 9
[17] Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, 和 Daniel Fried. VisualWebArena:在现实视觉网络任务中评估多模态代理。arXiv预印本arXiv:2401.13649,2024年。2
[18] Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, 和 Tat-Seng Chua. ScreenSpot-Pro:专业高分辨率计算机使用的GUI定位,2025年。2
[19] Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, 和 Tat-Seng Chua. ScreenSpot-Pro:专业高分辨率计算机使用的GUI定位。arXiv预印本arXiv:2504.07981,2025年。4, 5
[20] Drew Linsley, Dan Shiebler, Sven Eberhardt, 和 Thomas Serre. 学习关注什么和在哪里。arXiv预印本arXiv:1805.08819,2018年。2
[21] Xiao Liu, Tianjie Zhang, Yu Gu, Iat Long Iong, Yifan Xu, Xixuan Song, Shudan Zhang, Hanyu Lai, Xinyi Liu, Hanlin Zhao, 等人. VisualAgentBench:迈向大型多模态模型作为视觉基础代理。arXiv预印本arXiv:2408.06327,2024年。1, 2
[22] Yadong Lu, Jianwei Yang, Yelong Shen, 和 Ahmed Awadallah. Omniparser for pure vision based GUI agent,2024年。1, 2
[23] Volodymyr Mnih, Nicolas Heess, Alex Graves, 等人. 递归视觉注意力模型。神经信息处理系统进展,27,2014年。3
[24] Shikhar Murty, Hao Zhu, Dzmitry Bahdanau, 和 Christopher D. Manning. NNetNav:通过野外环境交互的无监督学习浏览器代理,2025年。2
[25] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, 等人. WebGPT:带有用户反馈的浏览器辅助问答。arXiv预印本arXiv:2112.09332,2021年。2
[26] Soroush Nasiriany, Fei Xia, Wenhao Yu, Ted Xiao, Jacky Liang, Ishita Dasgupta, Annie Xie, Danny Driess, Ayzaan Wahid, Zhuo Xu, 等人. Pivot:迭代视觉提示激发VLMS的可操作知识。arXiv预印本arXiv:2402.07872,2024年。
[27] Vardaan Pahuja, Yadong Lu, Corby Rosset, Boyu Gou, Arindam Mitra, Spencer Whitehead, Yu Su, 和 Ahmed Awadallah. Explorer:为多模态网络代理扩展探索驱动的网络轨迹合成,2025年。
[28] Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, 等人. UI-TARS:开创性自动化GUI交互本地代理。arXiv预印本arXiv:2501.12326,2025年。1, 2, 5, 6
[29] Peter Shaw, Mandar Joshi, James Cohan, Jonathan Berant, Panupong Pasupat, Hexiang Hu, Urvashi Khandelwal, Kenton Lee, 和 Kristina N Toutanova. 从像素到UI动作:通过图形用户界面遵循指令的学习。神经信息处理系统进展,36:34354-34370,2023年。
[30] Gokul Swamy, Sanjiban Choudhury, Wen Sun, Zhiwei Steven Wu, 和 J Andrew Bagnell. 所有道路通向似然:微调中的强化学习的价值。arXiv预印本arXiv:2503.01067,2025年。
[31] Brandon Trabucco, Gunnar Sigurdsson, Robinson Piramuthu, 和 Ruslan Salakhutdinov. 走向互联网规模训练代理,2025年。
[32] Hieu Tran Bao, Nguyen Cong Dat, Nguyen Duc Anh, 和 Hoang Thanh-Tung. 学会在测试时停止过度思考。arXiv e-prints,arXiv-2502页,2025年。
[33] Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, 和 Jitao Sang. Mobile-Agent-V2:通过多代理协作有效导航的移动设备操作助手。在神经信息处理系统进展(NeurIPS)中,2024年。2
[34] Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, 和 Jitao Sang. Mobile-Agent:具有视觉感知的自主多模态移动设备代理。arXiv预印本arXiv:2401.16158,2024年。
[35] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, 和 Denny Zhou. 自我一致性改善语言模型中的思维链推理。arXiv预印本arXiv:2203.11171,2022年。
[36] Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Jing Hua Toh, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, 等人. OSWorld:为真实计算机环境中开放任务基准化多模态代理。神经信息处理系统进展,37:52040-52094,2025年。
[37] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, 和 Yoshua Bengio. 显示、注意并讲述:带视觉注意的神经图像字幕生成。在机器学习国际会议上,第2048-2057页。PMLR,2015年。
[38] An Yan, Zhengyuan Yang, Wanrong Zhu, Kevin Lin, Linjie Li, Jianfeng Wang, Jianwei Yang, Yiwu Zhong, Julian McAuley, Jianfeng Gao, 等人. GPT-4V在仙境:零样本智能手机GUI导航的大规模多模态模型。arXiv预印本arXiv:2311.07562,2023年。
[39] Ke Yang, Yao Liu, Sapana Chaudhary, Rasool Fakoor, Pratik Chaudhari, George Karypis, 和 Huzefa Rangwala. AgentOccam:一个简单而强大的LLM基础网络代理基线,2024年。1, 2
[40] Shunyu Yao, Howard Chen, John Yang, 和 Karthik Narasimhan. WebShop:朝着具有接地语言代理的可扩展真实世界网络交互迈进。神经信息处理系统进展,35:20744-20757,2022年。
[41] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, 和 Karthik Narasimhan. 思维树:用大语言模型进行深思熟虑的问题解决。神经信息处理系统进展,36:11809-11822,2023年。
[42] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, 和 Yuan Cao. React:在语言模型中协同推理和行动。在国际学习表示会议(ICLR)上,2023年。
[43] Wenwen Yu, Zhibo Yang, Jianqiang Wan, Sibo Song, Jun Tang, Wenqing Cheng, Yuliang Liu, 和 Xiang Bai. Omniparser V2:统一视觉文本解析的结构化思维及其在多模态大语言模型中的通用性。arXiv预印本arXiv:2502.16161,2025年。
[44] Xiao Yu, Baolin Peng, Vineeth Vajipey, Hao Cheng, Michel Galley, Jianfeng Gao, 和 Zhou Yu. Exact:教AI代理用反思MCTS和探索性学习进行探索。arXiv预印本arXiv:2410.02052,2024年。
[45] Zhuosheng Zhang 和 Aston Zhang. 你只看屏幕:多模态动作链代理。arXiv预印本arXiv:2309.11436,2023年。
[46] Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, 和 Yu Su. GPT-4V (ision) 是一个通用的网络代理,如果被接地的话。arXiv预印本arXiv:2401.01614,2024年。1, 2
[47] Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, 等人. WebArena:构建自主代理的真实网络环境。ICLR,2024年。
A. 更多实验细节
在本节中,我们提供了更多关于实验设置的详细信息。在我们的主文中,我们检查了UI-TARS-7B-DPO和UI-TARS-72B-DPO模型,以及Qwen2.5-VL-7B-Instruct和Qwen2.5-VL-72B-Instruct。对于WebVoyager,我们使用了UI-TARS模型的1440×1440像素屏幕分辨率和Qwen模型的2240×1260像素分辨率。对于ScreenSpot-Pro和WebVoyager,我们预定义的边界框是输入图像大小的比例,具体为[0.5,0.5],[0.3,0.3],[0.4,0.8]和[0.8,0.4]。我们使用的一些提示如下列出。
动作预测提示 - UI-TARS
你是一个GUI代理。你被给予一个任务、当前网页截图和你在同一页面上之前聚焦点的历史(在截图中由粉星指示)。你的任务是输出与目标最相关的截图中的点。你必须避免粉色标注的坐标并选择一个有效的可点击区域。
其他信息
目标:{objective}
URL:{url}
输出格式
(x1, y1)
其中x1, y1是目标元素的坐标,且必须不同于任何粉色标注的坐标。
注意
- 确保选择的坐标是一个未被截图中粉星明显覆盖的有效可点击区域。
动作预测提示 - UI-TARS
你是一个GUI代理。你被给予一个任务和你的动作历史,附带截图。
你需要执行下一个动作以完成任务。
其他信息
目标:{objective}
URL:{url}
输出格式
‘’‘\nThought: …
Action: …\n’’’
动作空间
click(start_box=’
参考论文:https://arxiv.org/pdf/2505.00684



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











