






D. Sculley
1
{ }^{1}
1 Will Cukierski
2
{ }^{2}
2 Phil Culliton
2
{ }^{2}
2 Sohier Dane
2
{ }^{2}
2 Maggie Demkin
2
{ }^{2}
2 Ryan Holbrook
2
{ }^{2}
2
Addison Howard
2
{ }^{2}
2 Paul Mooney
2
{ }^{2}
2 Walter Reade
2
{ }^{2}
2 Megan Risdal
2
{ }^{2}
2 Nate Keating
2
{ }^{2}
2
摘要
在本文中,我们观察到生成式人工智能(GenAI)的实证评估正处于危机之中,因为传统的机器学习(ML)评估和基准测试策略不足以满足评估现代GenAI模型和系统的需求。造成这种情况的原因有很多,其中包括这些模型通常具有几乎无限的输入和输出空间,通常没有明确的真值目标,并且通常基于先前模型输出的上下文表现出强烈的反馈循环和预测依赖性。除了这些关键问题外,我们认为泄漏和污染问题是GenAI评估中最重要和最难以解决的问题。有趣的是,AI竞赛领域已经发展出有效的措施和实践来对抗作弊行为,特别是在竞赛环境中防止不良行为者作弊。这使得AI竞赛成为一种特别有价值的(但未被充分利用的)资源。现在是时候让该领域将AI竞赛视为生成式AI评估中实证严谨性的黄金标准,并以适当的价值利用其结果。
1. 引言
随着生成式人工智能(GenAI)模型如大型语言模型(LLMs)在该领域和整个世界中变得越来越重要,已经清楚地表明对这些模型和方法进行严格和全面的经验评估是非常困难的。这种困难当然不是由于研究人员缺乏努力或专业知识造成的。事实上,大量的努力和资源已经被投入到创建众多的基准测试和测试案例中(Chiang等,2024b;Fourrier等,2024;
Hendrycks等,2021;Cobbe等,2021;Zellers等,2019;Chen等,2021b)。然而,即使考虑到这些许多重要的努力和成就,我们的观点是当前的评估状态不足以满足这一时刻在GenAI领域的需求。
在我们看来,这种不足的根本原因是GenAI模型的评估需求从根本上打破了传统基准测试的范式,而这种范式在过去几十年中为机器学习(ML)领域取得了显著进展。这种破坏不仅超出了定义LLM训练数据中究竟包含什么内容的熟悉难度。在我们看来,我们需要对GenAI的泛化概念进行更广泛的思考,超越从平稳分布中独立抽取新样本的概念,而是指在模型从未见过的任务上表现良好。这一更高的标准植根于人类智能的常识标准(Chollet, 2019; Dennett, 1991),但具有深远的影响,最显著的是它意味着数据泄漏和污染问题是最紧迫的关注点。
综上所述,这些因素表明,严格且稳健地评估GenAI模型需要一个持续提供新颖任务的来源,这些任务结构化以避免泄漏、污染和其他形式的无意“作弊”。幸运的是,AI竞赛——例如Kaggle及其类似平台上举办的竞赛——提供了一个现成的解决方案,为评估提供持续的新任务来源,并有显著的结构来避免泄漏及相关问题。
1.1. 总结我们的立场
我们的立场可以总结为以下几点:
- 传统的机器学习评估范式无法满足GenAI评估的需求。
-
- 泄漏应被视为领域中评估时最重要的陷阱。
-
- GenAI评估一旦在线共享或通过网络发送即应被视为已泄露。
1 { }^{1} 1 在Kaggle完成的工作 2 { }^{2} 2 Kaggle, Inc. 对应联系人: D. Sculley d@sculley.ai, Nate Keating natekeating@kaggle.com, Megan Risdal meg@kaggle.com。
- GenAI评估一旦在线共享或通过网络发送即应被视为已泄露。
- 如果我们在GenAI评估中必须在可重复性和稳健性之间做出选择,我们应该优先考虑稳健性。
-
- 我们应该用可重复的过程和程序取代可重复的静态基准的概念。
-
- 领域应该使用已建立的AI竞赛平台作为新颖评估任务的可再生流。
-
- 帮助AI竞赛防范作弊的标准和实践应被视为评估实证严谨性的黄金标准。
-
- 元分析应在AI领域中受到与医学等领域相同的重视程度。
1.2. 本文结构
在本文其余部分中,我们将首先回顾传统机器学习评估中最典型的结构和假设,并讨论为什么它不足以用于GenAI评估。我们将考察GenAI的泛化本质,以及这如何导致围绕泄漏的具体关注,并进一步展示评估中的可重复性和稳健性目标可能根本上相互冲突。然后,我们将通过一些简短的案例研究展示即使是传统机器学习评估中的泄漏问题也有多么困难,并审视当前旨在克服泄漏和污染的GenAI基准。我们以AI竞赛如何解决这些问题结束全文,讨论我们的建议,并考察其他观点。我们的目标是为AI竞赛确实为评估GenAI模型提供了实证严谨性的黄金标准提供令人信服的支持,并强调该领域应对其结果给予相应的高度重视。
2. 背景:重新审视基准测试
传统的机器学习基准测试建立在测试-训练拆分的概念之上,评估过程包括从给定的一部分训练数据中从头开始训练模型,然后在保留的一组测试数据上评估该训练好的模型(Mitchell, 1997)。这个基本概念结构对于现代机器学习实践如此基础,以至于有时可能会被理所当然地接受而没有仔细审查。因此,让我们花一点时间反思这个基本结构及其含义。
在经典的监督机器学习中,最常见的传统设置是评估模型 f ( x ) → y f(\mathbf{x}) \rightarrow y f(x)→y,其中 x ∈ ℜ d \mathbf{x} \in \Re^{d} x∈ℜd 是某些 d d d 维特征空间中的特征向量, y ∈ Y y \in Y y∈Y 是可能标签的空间,例如二分类的 { 0 , 1 } \{0,1\} {0,1} 或回归概率的 ( 0 , 1 ) (0,1) (0,1)。假设标记示例 ( x , y ) (\mathbf{x}, y) (x,y) 来自某个分布 D D D。训练集 D train D_{\text {train }} Dtrain 和测试集 D test D_{\text {test }} Dtest 各自独立同分布(IID)地从 D D D 中抽取,只有训练集中的示例用于拟合模型 f ( x ) f(\mathbf{x}) f(x),只有测试集中的示例用于评估模型(Mitchell & Mitchell, 1997)。
对测试-训练拆分的IID要求在实践中往往被视为脚注,但实际上它是此设置稳健性的基石。这是因为我们从根本上希望我们的评估能够解释为我们模型的泛化能力的陈述:我们想知道模型在未来的、以前未见过的数据上的表现如何。但是,实现这一点比听起来要难得多,因为所涉及的机器学习模型通常是极高维度的,因此可能容易过拟合。
评估泛化能力的一种方法存在于经典统计学习理论文献中,提供了基于模型的VC维数和训练期间观察到的误差等特性的泛化边界,这些边界不需要使用额外的保留集(Vapnik, 1999)。然而,这些理论边界不幸的是过于宽松,无法具有实际价值——尤其是在如今模型规模越来越大的时代更是如此。
第二种方法是使用额外的数据进行评估。需要注意的一个问题是,尝试评估一个没有具体机制区分相关性与因果因素的模型的泛化能力可能导致极不可靠的性能估计。这是IID假设所解决的问题——当我们知道所有测试数据都是从与训练数据相同的分布中独立同分布地抽取时,我们可以确信所有在训练时存在的相关性将在测试时以相同的特性重现,因此我们可以将保留测试数据上的性能作为泛化能力的合理估计。IID假设在许多方面使现代机器学习作为一个研究领域得以发展,因为它构成了所有评估的理论基础。事实上,众所周知,将机器学习模型从研究转移到部署生产环境之所以困难,正是因为在实践中IID假设常常不成立(Chen等,2021a)。
2.1. 可重复基准的兴起
一个立即成为标准做法的统计捷径是,研究人员不再从
D
D
D 中为每次新评估单独抽取新的训练集和测试集,而是只抽取一次并将其用作规范的训练/测试集。这种方法的主要好处(除了便利之外)是这些配对的测试-训练拆分现在可以用作可重复的基准。所有未来的研究人员都可以复制完全相同的问题
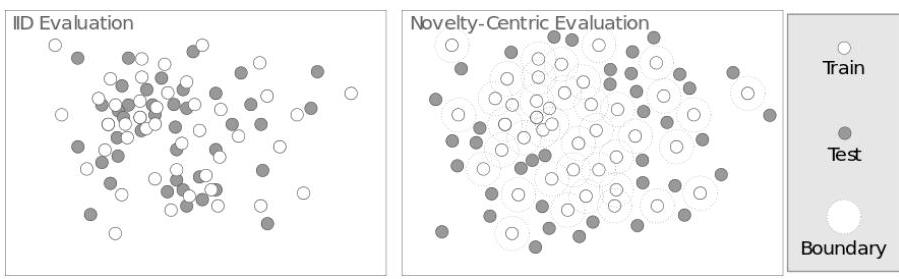
图1. IID评估与创新中心评估的对比。在IID评估中,左侧,训练和测试数据都从相同的分布中抽取,导致每组中的示例有显著重叠。在创新中心版本中,右侧,不允许任何测试示例与任何给定的训练示例过于相似。我们认为这种概念化更接近GenAI评估所需的期望行为,其中泛化预计意味着在完全新颖的输入上有良好的响应能力。
设置,给一个新的未经训练的模型相同的训练数据进行训练,并使用相同的测试数据进行评估,从而实现完全的同类比较。这种方法非常成功,像MNIST(LeCun & Cortes, 2010)和ImageNet(Deng et al., 2009)这样的规范基准负责推动计算机视觉领域的快速发展,例如,还有诸如(Rajpurkar et al., 2016; Marcus et al., 1993; Diemert Eustache, Betlei Artem et al., 2018)之类的基准推动了电子邮件垃圾邮件分类、自然语言处理以及其他领域的进步。像UCI仓库(Kelly et al.)和OpenML(Vanschoren et al., 2014)等网站在这一原因上对该领域有着非凡的价值。
2.2. 出乎意料的是,过拟合并不是主要问题
鉴于在评估模型时的一个基本问题是确保我们能够正确处理泛化并避免过拟合,合理的疑问是,一个领域反复使用相同的基准数据集在数千篇论文中是否会引发过拟合。作为作者,我们对(Roelofs et al., 2019b)的研究深感惊讶,该研究表明,在实践中,这实际上似乎并未成为一个问题。在(Recht et al., 2019)中,这些作者显示,当在全新数据上评估ImageNet模型时,其排名顺序与在基准数据上的排名顺序惊人一致,尽管后者被广泛重复使用。在后续工作中,还证明了在Kaggle竞赛中对公共排行榜数据的评估是私人保留数据排名顺序的一个非常良好的指标,尽管存在数千个团队参与同一挑战时可能过拟合的风险(Roelofs et al., 2019a)。
3. 重新考虑GenAI的泛化
正如我们在上述回忆中提到的,传统机器学习评估中的IID假设给出了泛化的清晰概念:如果模型能准确预测从与模型训练数据相同的固定平稳分布 D D D 中独立同分布(IID)抽取的标记示例 ( x , y ) (\mathbf{x}, y) (x,y) 的真实但隐藏的标签 y y y,则该模型具有良好的泛化能力。这一核心概念允许机器学习领域通过缩小问题范围并启用可处理的统计理论来有效地进展。但是,如果我们反思更广泛的智能概念,包括图灵(Turing, 1950)在其开创性论文中首次提出的那些概念,很明显,这种狭窄但有用的泛化概念并不能充分反映GenAI试图实现的更深层次目标。
相反,我们认为领域最关心的GenAI泛化形式应该是基于新颖性的泛化——也就是说,在训练或开发过程中从未见过的问题和任务上表现良好。
更深入地说,我们发现设计起来最容易的推理和理解评估往往具有解决问题困难(从正式意义上讲)或昂贵,而答案验证显著更容易或更便宜的特点。这种经验在规划、解决数学问题、做编程题、解谜语,甚至撰写文章中都成立,并反映了NP难问题的基本性质。一旦某个问题的答案为某一主体所知,未来再用该问题或与其非常相似的问题对该主体进行评估的能力就从根本上受到了损害。
为了评估基于新颖性的泛化,我们需要基于新颖性的评估。非正式地讲,基于新颖性的评估的目标是确保没有任何评估任务或示例与模型或系统之前已知的实例过于相似(根据某种相似性的定义和某种太近的度量)。我们在图1中直观地展示了基于IID的泛化和基于新颖性的泛化的区别——我们可以想象每个训练示例周围都有一个小的概念环,并确保没有评估实例跨越这些环。
在我们看来,这种基于新颖性的泛化观点已经被许多人隐含地采纳为真正的理想目标,并影响了重要基准的设计,包括LM Arena(Chiang et al., 2024a)等——我们只是将这一事实写下来。我们现在将考察一些影响。
3.1. IID假设已被打破
虽然在现实世界部署的传统机器学习系统中,IID假设在实践中经常被轻微破坏,但我们认为,对于GenAI评估而言,IID假设以及整体的整齐标记示例 ( x , y ) (\mathbf{x}, y) (x,y)框架已无法修复地破裂。特别是,基于新颖性的泛化观点强烈暗示评估示例不应从用于训练的相同分布中抽取,而应明确选择或构建以避免与模型之前接触过的示例或数据高度相似。
我们还注意到,典型GenAI模型本身的性质导致了IID假设被打破的其他方式。特别是,GenAI输出往往远非独立,而是使用先前响应的上下文(例如,在多轮对话式界面中)来指导未来的响应,形成完全打破平稳性概念的反馈循环。最后,由于输入空间和输出空间极为庞大(例如,所有可能长度字符串的空间),测试分布等价性的概念本身可能是空洞的。
3.2. 泄露和污染是最大的隐患
尽管过度拟合的潜在隐患受到广泛关注,从业者长期以来已经认识到泄露是一个同样重要且在实践中往往更难解决的问题(Nisbet等,2009;Kaufman等,2012)。直观来说,泄露是指评估数据构建中的任何问题或结构,使得模型可以通过访问不应该拥有的信息来“作弊”。在第4节中,我们将通过一些案例研究来看泄露有多难预防,以及即使在传统机器学习评估中我们也必须多么警惕以避免这一隐患。在这里,我们指出泄露对于基于新颖性的GenAI评估尤其是一个大问题。这是因为基于新颖性的GenAI评估不仅具有传统机器学习评估的所有泄露风险,还承担了确保新颖性的额外负担。
基于新颖性的评估依赖于保证模型从未接触过与评估问题或任务过于相似的数据。虽然这看似显而易见,但在实践中却可能极其困难,因为像LLMs这样的GenAI模型通常是在大量数据上训练的,很难确切知道哪些类似的数据可能或不可能包含在内。事实上,泄露对于GenAI如此重要,以至于其特定形式已被赋予了另一个名称:污染(Magar & Schwartz, 2022; Oren等, 2023; Sainz等, 2023; Balloccu等, 2024)。当评估数据集和基准出现在训练数据中时,就会发生污染。
为了帮助大家理解这一问题的广泛性,请考虑我们迄今为止测试过的每一个主要LLM(无论是开源还是专有)都对Kaggle标准测试数据集的内容显示出广泛的详细知识。考虑LLMs在许多静态基准测试中表现出异常强大的性能,而这似乎并不与其他任务的强大表现相关联(Fourrier等,2024;Muennighoff等,2023;Zheng等,2023)。考虑这个问题:如果一个模型在通常给人类的资格考试中表现特别好,这是因为它获得了强大的专业知识,还是因为示例考试出现在其训练数据中,我们如何能够分辨?考虑梳理确切哪些数据源是或不是公开共享数据集(如广泛使用的Nectar数据集)的一部分的困难(Zhu等,2024),该数据集描述如下:
Nectar的提示来自多种来源,包括lmsys-chat-1M、ShareGPT、Antropic/hh-rlhf、UltraFeedback、Evol-Instruct和Flan。Nectar的每个提示的7个响应主要来源于各种模型,包括GPT-4、GPT-3.5-turbo、GPT-3.5-turbo-instruct、LLama-2-7B-chat和Mistral-7BInstruct,以及其他现有数据集和模型。
综合这些实际现实和考虑,迫使泄露成为任何严肃的GenAI评估必须解决的首要问题之一。
4. 泄露案例研究
由于泄露和污染是GenAI评估中最重要的障碍,深入研究它们是有用的,从传统机器学习评估中的泄露开始。这里,我们借鉴了从超过十年的Kaggle竞赛中学到的教训,在这些竞赛中,通过大量社区的深入审查,识别出了一系列广泛的泄露问题。经验表明,在开放的机器学习挑战基准中,泄露风险被放大,因为团队会(有意或无意地)利用任何能提升排行榜名次的优势。
泄露可能仅仅由于观察值的排序方式而发生。一个极端的例子发生在SETI Breakthrough Listen竞赛(Siemion等,2021)中,当时数据按照其类别标签的顺序进行处理。文件的时间戳没有重置,参赛者发现很容易基于文件元数据进行预测。另一个更微妙的例子发生在TalkingData AdTracking Fraud Detection Challenge(Yin等,2018)中,当时数据错误地按时间戳排序,如果在同一时间戳内存在多个事件,则正标签出现在负标签之后。
讽刺的是,随机化也可能成为泄露的来源。一个例子发生在Predict AI Model Runtime竞赛(Phothilimthana等,2023)中,当时团队需要对5个不同子集的数据运行时间进行排名,每个子集都需要不同的模型。两个桶使用相同的种子进行随机化,团队发现使用一个桶的排序对另一个桶进行改进可以提高他们的得分。
任何合成生成的数据都高度容易出现泄露信息的伪影。再次以SETI Breakthrough Listen竞赛为例,合成创建的“ET”信号被注入真实的射电望远镜信号中。在归一化过程中采取了措施以确保注入信号的均值和标准差与背景信号匹配。创建注入信号的代码使用FP16,而背景信号使用FP32。这在正负样本之间的均值和标准差之间造成了细微差异,但足以仅凭此信息区分类别。
在开放挑战期间,私有评估数据泄露给公众是一种需要考虑的风险。例如,在LANL Earthquake Prediction挑战赛(RL等,2019)中,数据集在一篇研究论文中进行了描述,包括一些汇总统计数据和图表。一些团队发现了这一点并能够加以利用以获得优势。
篇幅限制无法提供更多案例研究,但从业者的经验表明,每个AI竞赛出现问题的可能性大于顺利进行的可能性,因此保持警惕和谨慎是有帮助的做法。除了上述失败模式外,其他广泛类别还包括未来数据泄露、元数据泄露信息的多种方式(例如,医疗设备型号与疾病发病率相关、包含手绘圈标注可疑皮肤病变的医疗图像、图像宽高比、磁盘文件大小等)、未能保密的旧版私有评估数据集、团队能够逆转合成数据生成过程或重新组装被分割的数据、逆向工程数据混淆、训练和测试观测之间的近乎重复等。这些都不是假设情况;它们都在由有能力、细心的团队创建的挑战中发生过,并突显了创建无泄露竞赛和基准的真实困难。
4.1. 可重复性和稳健性之间的冲突
由于泄露的重要性以及确保泄露不影响GenAI评估的实际困难,我们认为最简单和最安全的做法是采用一种泄露规则,即一旦评估被在线共享或通过网络发送,就应视为已泄露。采用这一经验法则大大提高了我们对评估结果的信任能力,并赋予它们更大的稳健性。然而,这也严重削弱了可重复性的概念。本文的观点认为这是一种根本矛盾,类似于量子物理学中的海森堡不确定性原理,我们简单无法拥有一个对泄露稳健的静态基准——无论研究人员的意图多么良好,避免污染并广泛信任此类基准的结果实在太难。
相反,我们必须寻求替代策略和结构来创建防泄露评估。
5. 力求避免泄露的评估
有责任心的研究人员已经意识到GenAI新颖性评估中的泄露问题,并提出了新的基准,试图通过各种设计机制控制或减轻泄露。这里我们回顾关键示例、用于控制泄露的机制,并简要讨论其优缺点。
5.1. 未发布的保留集
SEAL Leaderboards(Scale AI,2024)、ARC-AGI(Chollet,2019)、FrontierMath(Glazer等,2024)和Humanity’s Last Exam(Phan等,2025)基准由领域专家手动创建的私有测试问题组成。测试集、模型响应和评估运行不会公开发布,以防止测试数据泄露。
未发布的保留集可以在一定程度上缓解泄露风险。然而,它们在评估基于专有API的模型时可能存在局限性,因为测试数据必须通过互联网发送到第三方服务器。虽然许多领先的AI模型提供商授予防止记录或存储用户提示的控制权,但这仍需要一定的信任。特别是,提供商必须被信任不改变政策,更重要的是,所有接触评估数据的研究人员必须被信任遵循这些实践而不犯错。
此外,由于保留集和评估运行必须保密,研究人员无法重现结果。为缓解这一点,一些基准采取混合方法。例如,FACTS Grounding Leaderboard(Jacovi等,2025)公开发布了一半的测试集,这使得部分可重复性和更好地理解基准成为可能。模型在私有和公共测试集部分的表现可以进行比较,以识别可能(有意或无意)在测试数据上训练的模型。
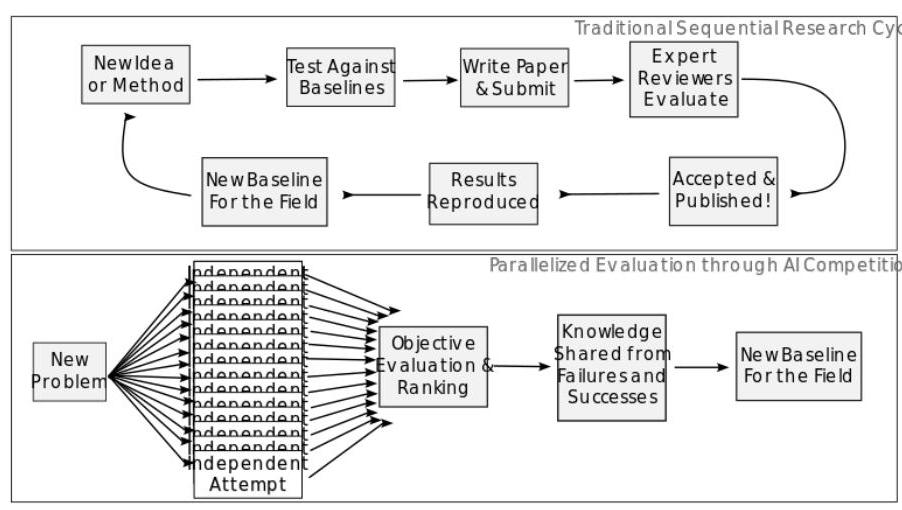
图2. 传统与并行评估结构的比较。在传统研究结构中,顶部,每个新想法以线性序列进行评估,通常单次循环需要几个月。底部的并行结构允许数百或数千种方法同时进行。
5.2. 动态基准
LiveBench(White等,2024)、LiveCodeBench(Jain等,2024)和SWE-Bench(Jimenez等,2024)基准频繁更新来自随时间自然刷新的来源的测试集。例如,LiveBench测试集每周从arXiv上新发表的文章或论文中更新。通过仅使用最近的数据测试模型,基准可以降低这些数据被纳入模型训练的风险。LiveBench也不会发布最近添加的测试数据,以便始终保留一定比例的问题。
动态基准相比未发布的保留集有一些优势。通过频繁更新数据,较旧的测试集可以公开发布以提高可重复性和信任度。然而,使用互联网上公开可用的数据——即使只是非常近期的数据——也不符合我们在4.1节中的经验法则,仍然是潜在的泄露源。此外,通过频繁更改测试集,基准创建者必须小心确保他们没有“移动目标”。此外,动态基准伴随着更高的维护成本,而且许多领域中不存在经常刷新的数据源,收集这些数据可能是不切实际的。
5.3. 社区基准
LM Arena(Chiang等,2024a),前身为LMSYS Chatbot Arena,是一系列基准集合,依靠社区对LLM在用户提示或任务中的两两对决投票。通过将测试数据收集和评估外包给用户,基准在测试时有一个不断更新的新型测试问题来源。
社区基准难以构建和维护。为了评估多个模型,所需投票的数量可能非常大,需要一个庞大且稳定的投票池。社区基准也不适用于所有任务,例如需要专门知识或可能需要人类花费数天完成的任务,这些任务无法扩展到人类评分。社区基准必然受任何抽样效应的影响;投票者的多样性和分布会影响结果,需要极大的关注和细致的过滤以排除低质量、重复或污染的结果。
6. AI竞赛作为结构性解决方案
像Kaggle及其他平台上的AI竞赛提供了一种“尴尬的并行”结构来进行实证评估,如图2所示,这种结构回溯到了并行计算的经典MapReduce结构(Dean & Ghemawat, 2008)。在这种结构中,独立的研究团队——通常数量达数千——各自竞争解决给定问题,从而在一个大规模并行努力中创建了许多不同方法的评估。这里我们展示这种结构如何为GenAI评估整体提供有益的帮助。
6.1. 并行化提高稳健性
一旦评估被公开共享或评估数据通过网络发送,泄露和污染的风险就开始了。这导致了一个问题:如何公平地比较不同的模型和系统,以确保稳健性并避免因泄露和污染而导致结果无效?
AI竞赛的并行化结构为此问题提供了一个有用的解决方案。基于新颖性的评估可以同时并行进行,确保每个新任务在测试时对数千个模型确实是新颖的。由于独立团队各自追求不同的模型、想法和方法,这种结构提供了直接的同类基准测试和实时结果再现的形式。
此外,像Kaggle这样的竞赛平台可以通过运行隔离代码竞赛充当隐藏测试数据的可信保管者,竞争对手提交的模型在孤立、安全的后端运行,没有互联网访问权限。通过安全离线评估所有模型,竞赛平台可以保证没有隐藏测试数据泄露。
最后,大型社区平台上举办的竞赛提供了额外的非结构性特征,代表了行业应采纳的最佳实践,以进一步提高实证严谨性。竞赛鼓励或通常要求公开分享代码、数据和实验细节,包括成功和失败。这种透明度有助于结果的再现,促进对新基线的信任,并加速知识在研究和从业者社区内的传播。
6.2. 防泄露竞赛结构
尽管防止传统泄露对竞赛风格评估仍然是一项挑战,就像在其他地方一样,但竞赛可以独特地设计以很好地缓解这一问题。此外,拥有成千上万研究团队的竞赛结构确保了当泄露问题发生时,它们会被迅速发现、共享并同时在所有并行进行任务的研究努力中得到解决。
我们提供了一些展示防泄露评估设计可行性的竞赛示例。通过采用前瞻性真实标签、新颖任务生成和截止日期后数据收集等策略,通常结合直接对参赛者不可访问的测试数据,竞赛可以提供一个稳健可靠的平台,用于新颖的GenAI模型评估。这些最佳实践应被视为蓝图,供未来竞赛和基准设计参考和调整。
前瞻性真实标签 前瞻性真实标签是一种泄露缓解策略,其中测试集标签在整个比赛的积极训练阶段对世界完全未知。
Critical Assessment of protein Function Annotation (CAFA) 5挑战(Friedberg等,2023)就是一个使用前瞻性真实标签缓解泄露的竞赛示例。该竞赛将其测试集设定为序列已知但湿实验室尚未确定功能注释的蛋白质。因此,近两千名参与者分布在1625个独立团队中,有效开发了预测一组蛋白质功能的模型,而在活跃训练阶段没有任何人类或模型可以获得真实标签。几个月后,最终评估是在"整理阶段"后基于新发布的蛋白质功能确定的。这种新颖性使竞赛相当防泄露。
新颖任务生成 另一种设计防泄露竞赛的方法是生成全新的任务,其中测试数据不像训练数据,因此需要有意义的泛化。
AI Mathematical Olympiad (AIMO)挑战(XTX Investments, 2024; Frieder等, 2024)旨在激励GenAI系统在人类水平数学推理能力方面的公开进展,采用了这种方法。在这些挑战中,参赛者被要求解决国家级数学挑战。由于许多(如果不是全部)参赛者使用的AI模型是在互联网规模数据上训练的,测试训练泄露在评估其数学推理能力方面构成了重大挑战。因此,由国际数学家团队专门为竞赛创建了全新的数学问题集,使得数据泄露或污染的可能性极低。
截止日期后数据收集 截止日期后数据收集是一种泄露缓解策略,用于一些竞赛中,这些竞赛类似于前瞻性真实标签竞赛,但不是评估新可用标签,而是评估完全新生成的数据。以下是两个这样的竞赛设计示例。
在WSDM Cup - Multilingual Chatbot Arena竞赛(Chiang等,2024a)中,由LMSYS.org主办,参与者被要求根据多语言对话和评级数据构建预测LLM在两两对决中的人类偏好解决方案。与CAFA 5类似,此竞赛设计为一个活跃训练阶段,随后是数据收集阶段,最终模型在提交截止日期后针对全新的对话进行评估,以防止泄露。
Konwinski奖(Konwinski等,2024)是另一种截止日期后数据收集形式。由Andy Konwinski主办的这项竞赛是SWE-Bench的无污染版本,评估LLM在解决现实世界GitHub问题上的能力。它采用基于时间的保留策略,提交的模型冻结三个月,然后在冻结期间收集的新GitHub问题上进行评估。
7. 对该领域的建议
作为一个领域,我们需要彻底改革我们的标准实践,以确保GenAI评估的严谨性和可靠性,并继续被该领域和更广泛的世界视为如此。
远离静态基准,走向常青可重复流程。由于泄露和污染的风险,我们认为静态基准在GenAI评估中的重要性应被弱化。(实际上,从轶事证据来看,研究人员和从业者对这类基准的结果持越来越怀疑的态度。)相反,我们需要一个稳定可再生的新颖任务和问题管道,并需要在每个任务上并行评估数百或数千个模型,以使结果直接可比较并避免后期污染和泄露的风险。因此,评估最好被视为某个时间点的结果,而不是不可变的最终结论。
将AI竞赛的连续流视为领域资源。利用Kaggle等平台上高质量AI竞赛的管道是一种创造可再生任务管道的方式。这些结构已经存在,并在某种程度上被这样使用。然而,作为一个领域,我们可以通过元分析提炼、分析和分享这些竞赛的发现做得更多。事实上,虽然元分析在医学等领域是一种常见且高度认可的学术贡献形式,但在我们的领域中这种论文极为罕见。我们可以通过包括专题研讨会、会议专题、期刊特刊以及在征稿通知中强调元分析价值的语言机制来改变这一点。
采用并改进AI竞赛的反作弊结构以改进GenAI评估的标准实践。此外,作为一个领域,我们可以从AI竞赛中学习已开发的最佳实践——为对抗不良行为者故意作弊而创建的技术和实践同样有价值,可以创建评估结构来对抗可能使实证结果无效的无意问题,如泄露和污染。一种防作弊结构是为研究人员提供保障,确保他们不会意外作弊自己。我们还需要增强并进一步改进这些结构,例如通过创建全领域标准,主要基于API的模型同意遵循,以明确避免收集或训练可能出现在评估中的数据。
8. 替代观点
所有立场论文都应该考虑反对观点,我们的也不例外。一种合理的替代观点是,当前的基准测试状态正在顺利进行,无需额外干预。许多新的静态基准每天都在Hugging Face、OpenML和Kaggle等平台上出现,可能作为我们描述的领域所需的新颖任务的稳定流。虽然我们赞扬所有创建新基准的努力,但我们从根本上相信,一旦静态基准被发布,就应该被视为实际上已经失效,因此AI竞赛的时间成分提供了独特的附加价值。
另一种合理的观点是,现有的尝试防泄露的基准已经足够。最值得注意的是,通过LMSYS.org的人类评分员产生的基于Elo的并列排名。为社区提供一个开放循环以提供无限制的新输入和判断确实很有吸引力,并且是解决许多这些问题的有力步骤。然而,我们认为,通过匿名群众为基础的任务和问题来源,在新颖性和严谨性方面所能取得的成果有限,而AI竞赛允许注入特定领域的专业知识和精心设计的测试案例,将全面考验下一代GenAI模型。
第三种合理的观点是,对于GenAI模型的学术评估价值来说,船已经驶离了港口。在这种范式下,生产部署中的实际现实世界任务的表现可能提供了对GenAI能力最有效的测试。在这种替代观点中,独立评估几乎没有价值,每个从业者或团体应该完全根据自己的条件进行评估。虽然这种方法在高度专业化的领域和应用中不可避免,但我们确实认为,一般模型的独立评估有令人信服的理由继续进行,因为该领域的历史表明,这些形式的评估以最广泛和最快的方式推动了进展。如果没有受控的、实证研究,我们作为一个领域可能会失去对模型为何在某些任务上表现良好或不佳的广泛共享知识。公开分享这种理解对于解锁在这个快速发展的领域中进一步进步的路径至关重要。
参考文献
Balloccu, S., Schmidtová, P., Lango, M., and Dušek, O. Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source llms, 2024. URL https: //arxiv.org/abs/2402.03927.
Chen, C., Murphy, N. R., Parisa, K., Sculley, D., and Underwood, T. Reliable Machine Learning. “O’Reilly Media, Inc.”, 2021a.
Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H. P., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F. P., Cummings, D., Plappert, M., Chantzis, F., Barnes, E., HerbertVoss, A., Guss, W. H., Nichol, A., Paino, A., Tezak, N., Tang, J., Babuschkin, I., Balaji, S., Jain, S., Saunders, W., Hesse, C., Carr, A. N., Leike, J., Achiam, J., Misra, V., Morikawa, E., Radford, A., Knight, M., Brundage, M., Murati, M., Mayer, K., Welinder, P., McGrew, B., Amodei, D., McCandlish, S., Sutskever, I., and Zaremba, W. Evaluating large language models trained on code, 2021b. URL https://arxiv.org/abs/ 2107.03374.
Chiang, W.-L., Zheng, L., Dunlap, L., Gonzalez, J. E., Stoica, I., Mooney, P., Dane, S., Howard, A., and Keating, N. LMSYS - Chatbot Arena Human Preference Predictions. https://kaggle.com/competitions/ lmsys-chatbot-arena, 2024a. Kaggle.
Chiang, W.-L., Zheng, L., Sheng, Y., Angelopoulos, A. N., Li, T., Li, D., Zhang, H., Zhu, B., Jordan, M., Gonzalez, J. E., and Stoica, I. Chatbot arena: An open platform for evaluating llms by human preference, 2024b. URL https://arxiv.org/abs/2403.04132.
Chollet, F. On the measure of intelligence, 2019. URL https://arxiv.org/abs/1911.01547.
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems, 2021. URL https://arxiv. org/abs/2110.14168.
Dean, J. and Ghemawat, S. Mapreduce: simplified data processing on large clusters. Commun. ACM, 51(1): 107-113, January 2008. ISSN 0001-0782. doi: 10. 1145/1327452.1327492. URL https://doi.org/ 10.1145/1327452.1327492.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, pp. 248-255. IEEE, 2009. URL https://ieeexplore.ieee. org/abstract/document/5206848/.
Dennett, D. C. Consciousness Explained. Penguin Books, 1991.
Diemert Eustache, Betlei Artem, Renaudin, C., and MassihReza, A. A large scale benchmark for uplift modeling. In Proceedings of the AdKDD and TargetAd Workshop, KDD, London, United Kingdom, August, 20, 2018. ACM, 2018.
Fourrier, C., Habib, N., Lozovskaya, A., Szafer, K., and Wolf, T. Open llm leaderboard v2. https://huggingface.co/spaces/ open-1lm-leaderboard/open_1lm_ leaderboard, 2024. Friedberg, I., Radivojac, P., Paolis, C. D., Piovesan, D., Joshi, P., Reade, W., and Howard, A. CAFA 5 Protein Function Prediction. https://kaggle.com/competitions/ cafa-5-protein-function-prediction, 2023. Kaggle.
Frieder, S., Bealing, S., Nikolaiev, A., Smith, G. C., Buzzard, K., Gowers, T., Liu, P. J., Loh, P.-S., Mackey, L., de Moura, L., Roberts, D., Sculley, D., Tao, T., Balduzzi, D., Coyle, S., Gerko, A., Holbrook, R., Howard, A., and Markets, X. Ai mathematical olympiad - progress prize 2. https://kaggle.com/competitions/ ai-mathematical-olympiad-progress-prize-2, 2024. Kaggle.
Glazer, E., Erdil, E., Besiroglu, T., Chicharro, D., Chen, E., Gunning, A., Olsson, C. F., Denain, J.-S., Ho, A., de Oliveira Santos, E., Järviniemi, O., Barnett, M., Sandler, R., Vrzala, M., Sevilla, J., Ren, Q., Pratt, E., Levine, L., Barkley, G., Stewart, N., Grechuk, B., Grechuk, T., Enugandla, S. V., and Wildon, M. Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai, 2024. URL https://arxiv.org/abs/2411. 04872 .
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding, 2021. URL https: //arxiv.org/abs/2009.03300.
Jacovi, A., Wang, A., Alberti, C., Tao, C., Lipovetz, J., Olszewska, K., Haas, L., Liu, M., Keating, N., Bliniarz, A., Saroufim, C., Fry, C., Marcus, D., Kukliansky, D., Tomar, G. S., Swirhun, J., Xing, J., Wang, L., Gurumurthy, M., Aaron, M., Ambar, M., Fellinger, R., Wang, R., Zhang, Z., Goldshtein, S., and Das, D. The facts grounding leaderboard: Benchmarking llms’ ability to ground responses to long-form input, 2025. URL https://arxiv.org/abs/2501.03200.
Jain, N., Han, K., Gu, A., Li, W.-D., Yan, F., Zhang, T., Wang, S., Solar-Lezama, A., Sen, K., and Stoica, I.
Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974, 2024.
Jimenez, C. E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., and Narasimhan, K. Swe-bench: Can language models resolve real-world github issues?, 2024. URL https://arxiv.org/abs/2310.06770.
Kaufman, S., Rosset, S., Perlich, C., and Stitelman, O. Leakage in data mining: Formulation, detection, and avoidance. ACM Transactions on Knowledge Discovery from Data (TKDD), 6(4), December 2012. ISSN 15564681. doi: 10.1145/2382577.2382579. URL https: //doi.org/10.1145/2382577.2382579.
Kelly, M., Longjohn, R., and Nottingham, K. UCI machine learning repository. URL https://archive.ics. uci.edu.
Konwinski, A., Rytting, C., Shaw, J. F. A., Dane, S., Reade, W., and Demkin, M. Konwinski Prize. https://kaggle.com/competitions/ konwinski-prize, 2024. Kaggle.
LeCun, Y. and Cortes, C. MNIST handwritten digit database. 2010. URL http://yann.lecun.com/ exdb/mnist/.
Magar, I. and Schwartz, R. Data contamination: From memorization to exploitation. In Muresan, S., Nakov, P., and Villavicencio, A. (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 157-165, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-short.18. URL https: //aclanthology.org/2022.acl-short.18/.
Marcus, M. P., Santorini, B., and Marcinkiewicz, M. A. Building a large annotated corpus of English: The Penn Treebank. Computational Linguistics, 19(2):313330, 1993. URL https://aclanthology.org/ J93-2004/.
Mitchell, T. M. Machine learning, volume 1. McGraw-hill New York, 1997.
Mitchell, T. M. and Mitchell, T. M. Machine learning, volume 1. McGraw-hill New York, 1997.
Muennighoff, N., Tazi, N., Magne, L., and Reimers, N. MTEB: Massive Text Embedding Benchmark, 2023. URL https://arxiv.org/abs/2210.07316.
Nisbet, R., Elder, J., and Miner, G. Handbook of Statistical Analysis & Data Mining Applications. Elsevier, Inc, 2009.
Oren, Y., Meister, N., Chatterji, N., Ladhak, F., and Hashimoto, T. B. Proving test set contamination in black box language models, 2023. URL https://arxiv. org/abs/2310.17623.
Phan, L., Gatti, A., Han, Z., Li, N., Hu, J., Zhang, H., Shi, S., Choi, M., Agrawal, A., Chopra, A., Khoja, A., Kim, R., Hausenloy, J., Zhang, O., Mazeika, M., Anderson, D., Nguyen, T., Mahmood, M., Feng, F., Feng, S. Y., Zhao, H., Yu, M., Gangal, V., Zou, C., Wang, Z., Wang, J. P., Kumar, P., Pokutnyi, O., Gerbicz, R., Popov, S., Levin, J.-C., Kazakov, M., Schmitt, J., Galgon, G., Sanchez, A., Lee, Y., Yeadon, W., Sauers, S., Roth, M., Agu, C., Riis, S., Giska, F., Utpala, S., Giboney, Z., Goshu, G. M., of Arc Xavier, J., Crowson, S.-J., Naiya, M. M., Burns, N., Finke, L., Cheng, Z., Park, H., Fournier-Facio, F., Wydallis, J., Nandor, M., Singh, A., Gehrunger, T., Cai, J., McCarty, B., Duclosel, D., Nam, J., Zampese, J., Hoerr, R. G., Bacho, A., Loume, G. A., Galal, A., Cao, H., Garretson, A. C., Sileo, D., Ren, Q., Cojoc, D., Arkhipov, P., Qazi, U., Li, L., Motwani, S., de Witt, C. S., Taylor, E., Veith, J., Singer, E., Hartman, T. D., Rissone, P., Jin, J., Shi, J. W. L., Willcocks, C. G., Robinson, J., Mikov, A., Prabhu, A., Tang, L., Alapont, X., Uro, J. L., Zhou, K., de Oliveira Santos, E., Maksimov, A. P., Vendrow, E., Zenitani, K., Guillod, J., Li, Y., Vendrow, J., Kuchkin, V., Ze-An, N., Marion, P., Efremov, D., Lynch, J., Liang, K., Gritsevskiy, A., Martinez, D., Pageler, B., Crispino, N., Zvonkine, D., Fraga, N. W., Soori, S., Press, O., Tang, H., Salazar, J., Green, S. R., Brüssel, L., Twayana, M., Dieuleveut, A., Rogers, T. R., Zhang, W., Li, B., Yang, J., Rao, A., Loiseau, G., Kalinin, M., Lukas, M., Manolescu, C., Mishra, S., Kamdoum, A. G. K., Kreiman, T., Hogg, T., Jin, A., Bosio, C., Sun, G., Coppola, B. P., Tarver, T., Heidinger, H., Sayous, R., Ivanov, S., Cavanagh, J. M., Shen, J., Imperial, J. M., Schwaller, P., Senthilkuma, S., Bran, A. M., Dehghan, A., Algaba, A., Verbeken, B., Noever, D., V, R. P., Schut, L., Sucholutsky, I., Zheltonozhskii, E., Lim, D., Stanley, R., Sivarajan, S., Yang, T., Maar, J., Wykowski, J., Oller, M., Sandlin, J., Sahu, A., Hu, Y., Fish, S., Heydari, N., Apronti, A., Rawal, K., Vilchis, T. G., Zu, Y., Lackner, M., Koppel, J., Nguyen, J., Antonenko, D. S., Chern, S., Zhao, B., Arsene, P., Goldfarb, A., Ivanov, S., Pošwiata, R., Wang, C., Li, D., Crisostomi, D., Achilleos, A., Myklebust, B., Sen, A., Perrella, D., Kaparov, N., Inlow, M. H., Zang, A., Thornley, E., Orel, D., Poritski, V., Ben-David, S., Berger, Z., Whitfill, P., Foster, M., Munro, D., Ho, L., Hava, D. B., Kuchkin, A., Lauff, R., Holmes, D., Sommerhage, F., Schneider, K., Kazibwe, Z., Stambaugh, N., Singh, M., Magoulas, I., Clarke, D., Kim, D. H., Dias, F. M., Elser, V., Agarwal, K. P., Vilchis, V. E. G., Klose, I., Demian, C., Anantheswaran, U., Zweiger, A., Albani, G., Li, J., Daans, N., Radionov, M., Rozhoň, V., Ma, Z., Stump,
C., Berkani, M., Platnick, J., Nevirkovets, V., Basler, L., Piccardo, M., Jeanplong, F., Cohen, N., Tkadlec, J., Rosu, P., Padlewski, P., Barzowski, S., Montgomery, K., Menezes, A., Patel, A., Wang, Z., Tucker-Foltz, J., Stade, J., Goertzen, T., Kazemi, F., Milbauer, J., Ambay, J. A., Shukla, A., Labrador, Y. C. L., Givré, A., Wolff, H., Rossbach, V., Aziz, M. F., Kaddar, Y., Chen, Y., Zhang, R., Pan, J., Terpin, A., Muennighoff, N., Schoelkopf, H., Zheng, E., Carmi, A., Jones, A., Shah, J., Brown, E. D. L., Zhu, K., Bartolo, M., Wheeler, R., Ho, A., Barkan, S., Wang, J., Stehberger, M., Kretov, E., Sridhar, K., ELWasif, Z., Zhang, A., Pyda, D., Tam, J., Cunningham, D. M., Goryachev, V., Patramanis, D., Krause, M., Redenti, A., Bugas, D., Aldous, D., Lai, J., Coleman, S., Bahaloo, M., Xu, J., Lee, S., Zhao, S., Tang, N., Cohen, M. K., Carroll, M., Paradise, O., Kirchner, J. H., Steinerberger, S., Ovchynnikov, M., Matos, J. O., Shenoy, A., de Oliveira Junior, B. A., Wang, M., Nie, Y., Giordano, P., Petersen, P., Sztyber-Betley, A., Shukla, P., Crozier, J., Pinto, A., Verma, S., Joshi, P., Yong, Z.-X., Tee, A., Andréoletti, J., Weller, O., Singhal, R., Zhang, G., Ivanov, A., Khoury, S., Mostaghimi, H., Thaman, K., Chen, Q., Khánh, T. Q., Loader, J., Cavalleri, S., Szlyk, H., Brown, Z., Roberts, J., Alley, W., Sun, K., Stendall, R., Lamparth, M., Reuel, A., Wang, T., Xu, H., Raparthi, S. G., Hernández-Cámara, P., Martin, F., Malishev, D., Preu, T., Korbak, T., Abramovitch, M., Williamson, D., Chen, Z., Bálint, B., Bari, M. S., Kassani, P., Wang, Z., Ansarinejad, B., Goswami, L. P., Sun, Y., Elgnainy, H., Tordera, D., Balabanian, G., Anderson, E., Kvistad, L., Moyano, A. J., Maheshwari, R., Sakor, A., Eron, M., McAlister, I. C., Gimenez, J., Enyekwe, I., O., A. F. D., Shah, S., Zhou, X., Kamalov, F., Clark, R., Abdoli, S., Santens, T., Meer, K., Wang, H. K., Ramakrishnan, K., Chen, E., Tomasiello, A., Luca, G. B. D., Looi, S.-Z., Le, V.-K., Kolt, N., Mündler, N., Semler, A., Rodman, E., Drori, J., Fossum, C. J., Jagota, M., Pradeep, R., Fan, H., Shah, T., Eicher, J., Chen, M., Thaman, K., Merrill, W., Harris, C., Gross, J., Gusev, I., Sharma, A., Agnihotri, S., Zhelnov, P., Usawasutsakorn, S., Mofayezi, M., Bogdanov, S., Piperski, A., Carauleanu, M., Zhang, D. K., Ler, D., Leventov, R., Soroko, I., Jansen, T., Lauer, P., Duersch, J., Taamazyan, V., Morak, W., Ma, W., Held, W., Huy, T. D., Xian, R., Zebaze, A. R., Mohamed, M., Leser, J. N., Yuan, M. X., Yacar, L., Lengler, J., Shahrtash, H., Oliveira, E., Jackson, J. W., Gonzalez, D. E., Zou, A., Chidambaram, M., Manik, T., Haffenden, H., Stander, D., Dasouqi, A., Shen, A., Duc, E., Golshani, B., Stap, D., Uzhou, M., Zhidkovskaya, A. B., Lewark, L., Vincze, M., Wehr, D., Tang, C., Hossain, Z., Phillips, S., Muzhen, J., Ekström, F., Hammon, A., Patel, O., Remy, N., Farhidi, F., Medley, G., Mohammadzadeh, F., Peñaflor, M., Kassahun, H., Friedrich, A., Sparrow, C., Sakal, T., Dhamane, O., Mirabadi, A. K., Hallman, E., Battaglia, M., Magh-
soudimehrabani, M., Hoang, H., Amit, A., Hulbert, D., Pereira, R., Weber, S., Mensah, S., Andre, N., Peristyy, A., Harjadi, C., Gupta, H., Malina, S., Albanie, S., Cai, W., Mehkary, M., Reidegeld, F., Dick, A.-K., Friday, C., Sidhu, J., Kim, W., Costa, M., Gurdogan, H., Weber, B., Kumar, H., Jiang, T., Agarwal, A., Ceconello, C., Vaz, W. S., Zhuang, C., Park, H., Tawfeek, A. R., Aggarwal, D., Kirchhof, M., Dai, L., Kim, E., Ferret, J., Wang, Y., Yan, M., Burdzy, K., Zhang, L., Franca, A., Pham, D. T., Loh, K. Y., Robinson, J., Gul, S., Chhablani, G., Du, Z., Cosma, A., White, C., Riblet, R., Saxena, P., Votava, J., Vinnikov, V., Delaney, E., Halasyamani, S., Shahid, S. M., Mourrat, J.-C., Vetoshkin, L., Bacho, R., Ginis, V., Maksapetyan, A., de la Rosa, F., Li, X., Malod, G., Lang, L., Laurendeau, J., Adesanya, F., Portier, J., Hollom, L., Souza, V., Zhou, Y. A., Yalın, Y., Obikoya, G. D., Arnaboldi, L., Rai, Bigi, F., Bacho, K., Clavier, P., Recchia, G., Popescu, M., Shulga, N., Tanwie, N. M., Lux, T. C. H., Rank, B., Ni, C., Yakimchyk, A., Huanxu, Liu, Häggström, O., Verkama, E., Narayan, H., Gundlach, H., Brito-Santana, L., Amaro, B., Vajipey, V., Grover, R., Fan, Y., e Silva, G. P. R., Xin, L., Kratish, Y., Łucki, J., Li, W.-D., Xu, J., Scaria, K. J., Vargus, F., Habibi, F., Long, Lian, Rodolà, E., Robins, J., Cheng, V., Grabb, D., Bosio, I., Fruhauff, T., Akov, I., Lo, E. J. Y., Qi, H., Jiang, X., Segev, B., Fan, J., Martinson, S., Wang, E. Y., Hausknecht, K., Brenner, M. P., Mao, M., Jiang, Y., Zhang, X., Avagian, D., Scipio, E. J., Siddiqi, M. R., Ragoler, A., Tan, J., Patil, D., Plecnik, R., Kirtland, A., Montecillo, R. G., Durand, S., Bodur, O. F., Adoul, Z., Zekry, M., Douville, G., Karakoc, A., Santos, T. C. B., Shamseldeen, S., Karim, L., Liakhovitskaia, A., Resman, N., Farina, N., Gonzalez, J. C., Maayan, G., Hoback, S., Pena, R. D. O., Sherman, G., Mariji, H., Pouriamanesh, R., Wu, W., Demir, G., Mendoza, S., Alarab, I., Cole, J., Ferreira, D., Johnson, B., Milliron, H., Safdari, M., Dai, L., Arthornthurasuk, S., Pronin, A., Fan, J., Ramirez-Trinidad, A., Cartwright, A., Pottmaier, D., Taheri, O., Outevsky, D., Stepanic, S., Perry, S., Askew, L., Rodríguez, R. A. H., Dendane, A., Ali, S., Lorena, R., Iyer, K., Salauddin, S. M., Islam, M., Gonzalez, J., Ducey, J., Campbell, R., Somrak, M., Mavroudis, V., Vergo, E., Qin, J., Borbás, B., Chu, E., Lindsey, J., Radhakrishnan, A., Jallon, A., McInnis, I. M. J., Hoover, A., Möller, S., Bian, S., Lai, J., Patwardhan, T., Yue, S., Wang, A., and Hendrycks, D. Humanity’s last exam, 2025. URL https://arxiv.org/abs/2501.14249.
Phothilimthana, M., Abu-El-Haija, S., Perozzi, B., Reade, W., and Chow, A. Google - Fast or Slow? Predict AI Model Runtime. https://kaggle.com/ competitions/predict-ai-model-runtime, 2023. Kaggle.
Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P.
SQuAD: 100,000+ questions for machine comprehension of text, 2016. URL https://arxiv.org/abs/ 1606.05250 .
Recht, B., Roelofs, R., Schmidt, L., and Shankar, V. Do ImageNet classifiers generalize to ImageNet? In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp. 5389-5400. PMLR, 09-15 Jun 2019. URL https://proceedings.mlr.press/v97/ recht19a.html.
RL, B., Pyrak-Nolte, L., Reade, W., and Howard, A. LANL Earthquake Prediction. https://kaggle.com/competitions/ LANL-Earthquake-Prediction, 2019. Kaggle.
Roelofs, R., Fridovich-Keil, S., Miller, J., Shankar, V., Hardt, M., Recht, B., and Schmidt, L. A meta-analysis of overfitting in machine learning. Curran Associates Inc., Red Hook, NY, USA, 2019a.
Roelofs, R., Shankar, V., Recht, B., Fridovich-Keil, S., Hardt, M., Miller, J., and Schmidt, L. A meta-analysis of overfitting in machine learning. In Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019b. URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ ee39e503b6bedf0c98c388b7e8589aca-Paper. pdf.
Sainz, O., Campos, J., García-Ferrero, I., Etxaniz, J., de Lacalle, O. L., and Agirre, E. NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. In Bouamor, H., Pino, J., and Bali, K. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 10776-10787, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp. 722. URL https://aclanthology.org/2023. findings-emnlp.722/.
Scale AI. SEAL leaderboards. https://https:// scale.com/leaderboard, 2024.
Siemion, A., Alonso, D. D., Reade, W., Wang, S., Croft, S., and Chen, Y. SETI Breakthrough Listen - E.T. Signal Search. https://kaggle.com/competitions/ seti-breakthrough-listen, 2021. Kaggle.
Turing, A. M. Computing machinery and intelligence. Mind, 59(236):433-460, 1950. ISSN 00264423. URL http: //www.jstor.org/stable/2251299.
Vanschoren, J., van Rijn, J. N., Bischl, B., and Torgo, L. Openml: networked science in machine learning. CoRR, abs/1407.7722, 2014. URL http://arxiv.org/ abs/1407.7722.
Vapnik, V. The Nature of Statistical Learning Theory. Springer: New York, 1999.
White, C., Dooley, S., Roberts, M., Pal, A., Feuer, B., Jain, S., Shwartz-Ziv, R., Jain, N., Saifullah, K., Naidu, S., Hegde, C., LeCun, Y., Goldstein, T., Neiswanger, W., and Goldblum, M. Livebench: A challenging, contamination-free llm benchmark. 2024. URL arXivpreprintarXiv:2406.19314.
XTX Investments. AI mathematical olympiad - progress prize I. https://kaggle.com/competitions/ ai-mathematical-olympiad-prize, 2024. Kaggle.
Yin, A., Kleinman, J., Yana, T., Reade, W., and Elliott, J. TalkingData AdTracking Fraud Detection Challenge. https://kaggle.com/competitions/ talkingdata-adtracking-fraud-detection, 2018. Kaggle.
Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., and Choi, Y. Hellaswag: Can a machine really finish your sentence?, 2019. URL https://arxiv.org/abs/ 1905.07830 .
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., and Stoica, I. Judging LLM-as-aJudge with MT-bench and Chatbot Arena, 2023. URL https://arxiv.org/abs/2306.05685.
Zhu, B., Frick, E., Wu, T., Zhu, H., and Jiao, J. Nectar. https://huggingface.co/datasets/ berkeley-nest/Nectar, 2024.
参考论文:https://arxiv.org/pdf/2505.00612



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











