






詹自富
a
^a
a,周双
b
^b
b,周晓山
c
^c
c,肖永康
d
^d
d,王军
b
^b
b,邓家文
e
^e
e,朱赫
f
^f
f,侯宇
b
^b
b,张锐
b
,
∗
^{b,*}
b,∗
a
^a
a 美国明尼苏达大学电气与计算机工程系,200 Union St SE, 明尼阿波利斯,55455,MN,美国
b
^b
b 美国明尼苏达大学外科系计算健康科学部,516 Delaware St SE, 明尼阿波利斯,55455,MN,美国
c
^c
c 美国密歇根大学土木与环境工程系,2350 Hayward Street, 安阿伯,48109,MI,美国
d
^d
d 美国明尼苏达大学健康信息学研究所,516 Delaware Street SE, 明尼阿波利斯,55455,MN,美国
e
^e
e 美国明尼苏达大学计算机科学与工程系,200 Union St SE, 明尼阿波利斯,55455,MN,美国
f
^f
f 美国明尼苏达大学化学工程与材料科学系,421 Washington Ave. SE, 明尼阿波利斯,55455,MN,美国
摘要
目标:我们旨在动态检索信息丰富的示例,以增强多模态大语言模型(MLLMs)在疾病分类中的上下文学习。方法:我们提出了一种检索增强上下文学习(RAICL)框架,该框架将检索增强生成(RAG)和上下文学习(ICL)相结合,自适应地选择具有相似疾病模式的示例,从而提高MLLMs的ICL效果。具体来说,RAICL检查来自不同编码器的嵌入,包括ResNet、BERT、BioBERT和ClinicalBERT,以检索适当的示例,并构建优化的ICL对话提示。我们在两个真实世界的多模态数据集(TCGA和IU Chest X-ray)上评估了该框架,评估其在多个MLLMs(Qwen、Llava、Gemma)、嵌入策略、相似性度量和不同数量的示例下的性能。结果:RAICL显著提高了分类性能。在TCGA上的准确率从0.7854提高到0.8368,在IU Chest X-ray上的准确率从0.7924提高到0.8658。多模态输入优于单模态输入,仅文本输入比单独图像更强。每种模态中包含的信息丰富程度决定了使用哪种嵌入模型可以获得更好的结果。少样本实验表明,增加检索示例的数量进一步提高了性能。在不同的相似性度量下,欧几里得距离达到了最高的准确率,而余弦相似性获得了更好的宏观F1分数。RAICL在各种MLLMs中表现出一致的改进,证实了其稳健性和通用性。结论:RAICL为增强MLLMs在多模态疾病分类中的上下文学习提供了一种高效且可扩展的方法。
关键词:检索增强生成,多模态大语言模型,上下文学习,疾病分类。
1. 引言
多模态疾病分类利用患者的各种信息来源,例如医学影像和临床记录,从一组相关疾病中推断出最可能的诊断,提供了重要的临床价值 [1, 2, 3]。整合多种临床数据模态可以全面描绘患者的健康状况,从而提高诊断的准确性和可靠性 [4]。例如,医学影像(如组织病理切片和X光片)提供了关于病理性细胞发展或结构异常的详细视觉见解 [5, 6]。同时,临床报告和病理记录提供了补充的文本信息,如患者病史、症状和背景细节,这些信息有助于解读视觉发现并揭示可能被忽略的细微模式 [7, 8]。这些模态的协同整合确保了对患者病情更全面的理解 [ 9 , 10 ] [9,10] [9,10]。
已经提出了各种多模态疾病分类模型,取得了显著的性能表现,特别是在监督学习环境中 [1, 11, 12]。早期研究主要依赖于大量标注数据来训练能够有效整合多模态输入的模型。例如,CheXpert [13] 利用超过224,316张带标签的胸部X光片及其配对的放射学报告,训练深度学习模型进行多标签胸腔疾病分类,肺炎分类的AUROC达到0.93。另一项重要研究 MedFuse [14] 整合了超过10,000个标注样本的病理图像和临床笔记中的多模态信息,提高了皮肤癌分类的诊断准确性,相较于仅使用图像的模型提升了8% 的准确率。尽管取得了这些成功,但在实践中往往无法获得大量的(例如几十万)高质量标注的多模态样本,例如成对的图像-文本数据。这一限制突显了需要替代方法,在减少标注数据的同时保持高性能。
最近在多模态大语言模型(MLLMs)方面的进展 [15, 16],如GPT40 [17]、DeepSeek [18] 和 Qwen [19],展示了通过两项关键优势解决上述问题的巨大潜力。首先,MLLMs擅长整合患者临床数据中的视觉和文本信息,促进更全面的临床决策制定 [10]。其次,这些模型支持提示方法 [20, 21, 22],只需少量示例即可实现上下文学习,从而减少了对大量标注数据的依赖,同时保持卓越的性能 [23]。鉴于临床场景中通常只有少量标注数据 [24],MLLMs在多模态疾病分类中的应用正受到越来越多的关注。例如,Ferber等人 [25] 展示了上下文学习使GPT-4V能够在匹配甚至超越专门神经网络训练任务的性能时,仅需最少的示例。他们的评估集中在三个关键的癌症组织病理学任务上:结直肠癌的组织亚型分类、结肠息肉亚型分类以及乳腺肿瘤在淋巴结切片中的检测。同样,Jiang等人 [26] 在涵盖多类、多标签和细粒度疾病分类的10个数据集上基准测试了GPT-4o和Gemini 1.5 Pro,并发现提示中提供更多示例始终比提供较少示例带来更好的性能。
尽管取得了这些进展,当前的努力仍存在一个关键局限性,这使得任务表现次优。具体而言,MLLMs的上下文长度通常受到限制 [27, 28],而现实世界中的患者数据(如临床笔记)往往冗长。这种差异使得很难在提示中包含所有相关的示例。鉴于这一约束条件,现有研究通常随机选择一部分示例用于上下文学习 [26, 29]。然而,示例的选择会显著影响MLLMs在临床决策中的表现 [30, 31]。直观上,具有类似疾病特征的示例样本(如临床笔记中匹配的症状和体征或类似的病理细胞形态)可能会作为更有用的参考,积极影响模型的预测。这一观点得到了相关研究的支持 [32, 33]。例如,Peng等人 [32] 表明示例的表现与其对模型理解测试样本的贡献呈正相关。而Xu等人 [33] 结论指出根据文本相似性选择的示例提高了MLLMs的性能。因此,从可用的标注数据中识别和选择“适当”的示例有望改善在多模态疾病分类中提示MLLMs的有效性。然而,这一挑战尚未得到充分探索,值得进一步研究。
为了弥补这一差距,我们提出了一种检索增强上下文学习(RAICL)框架,该框架动态检索针对测试样本定制的信息示例,以实现有效的上下文学习。核心思想是利用嵌入相似性作为一种代理来识别有用参考,假设语义相似度高的样本呈现类似的疾病模式。具体来说,RAICL系统地检查了广泛使用的编码器,包括ResNet、BERT、BioBERT和ClinicalBERT,分别生成图像和文本数据的语义嵌入。它进一步研究了多种相似性度量以测量嵌入相似性。在两个真实世界的数据集(即TCGA [36] 和 IU Chest X-ray [37])上,对Qwen [19]、Llava [34] 和 Gemma [35] 等各种MLLMs进行了广泛的实验,验证了RAICL在多模态疾病分类中的有效性。值得注意的是,该框架在少量样本设置下表现出稳健的性能,突显了其在有限标注数据场景中的适应性和弹性。总体而言,我们总结了以下重要意义陈述。
| 重要性陈述 | |
|---|---|
| 问题 | MLLMs在多模态疾病分类中的上下文学习选择合适示例的研究领域尚待深入探讨。 |
| 已知内容 | 提示中示例选择可能会影响MLLMs的性能。 |
| 本文贡献 | 我们提出了一种新颖的RAICL框架,将RAG和ICL与定制的对话提示相结合,检索信息丰富的示例,有效引导MLLMs进行疾病分类。 |
| 谁能从本文的新知识中受益 | 利用MLLMs促进临床决策的研究人员。 |
2. 方法
2.1. 任务公式化
一个数据样本表示为 s = ( x , r ) s=(x, r) s=(x,r),其中 x ∈ R H × W × D x \in \mathbb{R}^{H \times W \times D} x∈RH×W×D表示一个通用的医学图像张量, H , W H, W H,W, 和 D D D分别代表高度、宽度和通道数。 r r r是一个伴随的自由文本描述,提供额外的上下文或临床笔记。
给定一个数据集 D = { ( x i , r i , y i ) } i = 1 N \mathcal{D}=\left\{\left(x_{i}, r_{i}, y_{i}\right)\right\}_{i=1}^{N} D={(xi,ri,yi)}i=1N,其中 x i x_{i} xi是第 i i i个图像, r i r_{i} ri是相应的文本描述, y i y_{i} yi是真实标签(例如,分类结果),多模态大语言模型 G G G的目标是参数化为 θ \theta θ,生成一个标签字符串
y ^ = f ( G θ ( x , r ) ) \hat{y}=f\left(G_{\theta}(x, r)\right) y^=f(Gθ(x,r))
其中 G θ ( x , r ) G_{\theta}(x, r) Gθ(x,r)表示给定图像和文本作为输入时模型的输出, f ( ⋅ ) f(\cdot) f(⋅)是一个解码或后处理函数,将模型的原始输出映射到离散的标签字符串。期望的预测标签 y ^ \hat{y} y^应完全匹配真实标签 y y y。
2.2. 数据集
第一个数据集使用的是癌症基因组图谱(TCGA)集合 [36] 的子集,特别是乳腺癌(BRCA)、子宫内膜癌(UCEC)、低级别胶质瘤(LGG)、肺腺癌(LUAD)和膀胱癌(BLCA)项目。该数据集由从多个机构收集的高分辨率组织病理学全切片图像(WSIs)组成,每个图像都标注了详细的癌症类型诊断。这些WSIs通常以20倍至40倍的放大倍数扫描,捕捉了对疾病特征至关重要的精细组织形态。TCGA为疾病分类中的多模态大语言模型提供了一个宝贵的资源,因为组织学复杂性和患者间变异性挑战了模型提取和推理视觉模式的能力。此外,癌症类型的多样性使得可以在不同的病理领域评估模型的泛化能力。
第二个数据集是印第安纳大学胸部X光片(IU-CXR)集合 [37],包含7,470张胸部X光片和3,955份相应的放射学报告。该数据集包括前后位和侧位视图,涵盖了结构化文本发现和印象中记录的广泛胸腔状况。每个图像-报告对都被注释为几个常见疾病类别,允许进行多类预测设置。IU-CXR非常适合基于MLLM的疾病分类任务,因为它自然结合了自由文本临床描述和医学成像,要求模型整合异构模态。此外,该数据集反映了现实世界的诊断变异性和不确定性,提供了一个现实的基准来评估临床场景中多模态生成的鲁棒性。我们过滤掉了缺少图像、文本或有多种疾病的的数据。
2.3. RAICL框架
RAICL框架的结构如图1所示。在推理过程中,对于每个输入查询,其余的图像-对数据被视为外部数据库。输入查询的嵌入通过基于图像的嵌入模型或基于文本的嵌入模型获得,而外部数据库中所有数据点的嵌入则使用相同的方法生成。然后主要基于余弦相似性计算查询与数据库条目之间的相似性得分,以检索一个或多个最相似的
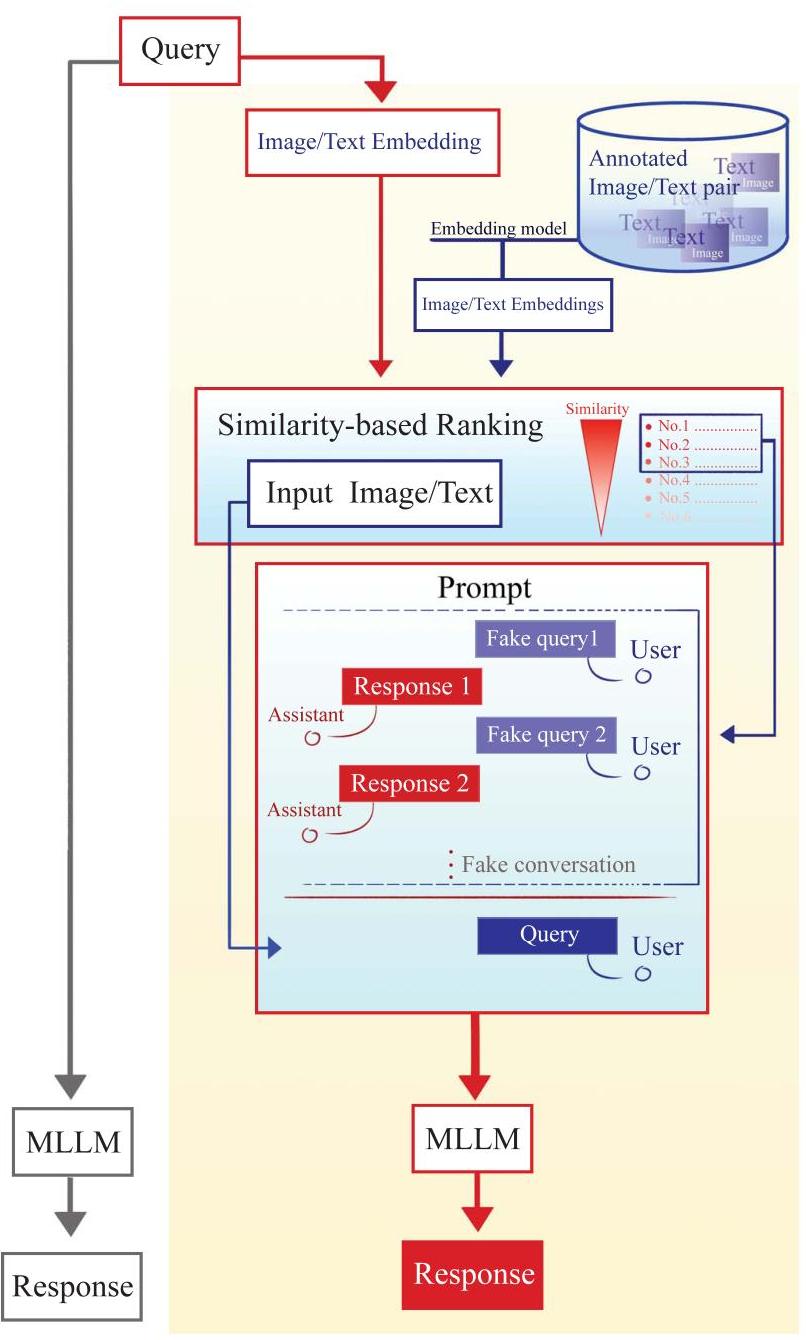
图1: 检索增强上下文学习(RAICL)框架概览。
表1: 本研究中使用的数据集摘要。
| 类别 | 样本数量 |
|---|---|
| TCGA 数据集 | |
| BRCA | 900 |
| UCEC | 479 |
| LGG | 435 |
| LUAD | 429 |
| BLCA | 342 |
| IU 胸部X光数据集 | |
| 正常 | 1197 |
| 钙化肉芽肿 | 72 |
| 钙化症 | 33 |
| 浸润 | 28 |
| 脊柱侧弯 | 24 |
| 心脏扩大 | 24 |
| 椎骨增生 | 20 |
| 肉芽肿性疾病 | 18 |
| 骨折 | 16 |
| 骨刺 | 15 |
| 结节 | 11 |
| 外来物体 | 11 |
| 动脉粥样硬化 | 10 |
| 瘢痕 | 9 |
| 肉芽肿 | 5 |
| 肺不张 | 5 |
示例。这些检索到的示例被纳入精心设计的提示中,生成的响应作为最终的分类结果。在本研究中,我们在Qwen2.5-VL-7B [19]、Qwen2.5-VL-3B [19]、LLaVA-v1.6-Mistral-7B [34]、Gemma-34B [35]、Gemma-3-12B [35] 上测试了我们的框架。有关如何获取嵌入、如何计算相似性以及如何设计提示的详细信息将在以下小节中提供。
2.3.1. 嵌入模型
为了获取图像的嵌入,我们使用了ResNet-18/50/101 [38] 模型。每个图像转换为三通道RGB格式,调整大小为 224 × 224 224 \times 224 224×224,并缩放到范围 [ 0 , 1 ] [0,1] [0,1]。张量通过ImageNet [39] 统计值标准化(均值 [0.485, 0.456, 0.406],标准差 [0.229, 0.224, 0.225 ] 0.225] 0.225]),添加批次维度后移动到GPU进行推理。然后将其传递通过一个ResNet-18/50/101 [38],其最后一个全连接层被替换为恒等映射;全局平均池化生成一个512维特征,最后通过L2归一化到单位超球面上以便直接进行余弦相似性计算。
对于每个对应的文本,字符串通过BERT [40] / BioBERT [41] / ClinicalBERT [42] 分词器进行分词,截断或填充到512个标记,并送入冻结的模型到GPU。提取[CLS]标记的隐藏状态作为一个768维句子嵌入。之后
收集所有非空嵌入,并进行L2归一化以进行进一步的相似性计算。
2.3.2. 相似性度量
为了说明我们框架的高兼容性,我们采用了几种广泛使用的相似性和距离度量来衡量输入嵌入和示例嵌入之间的相似性。具体来说,我们考虑了余弦相似性、内积、欧几里得距离、曼哈顿距离和切比雪夫距离,它们的形式定义如下。
给定两个嵌入向量 u , v ∈ R d \mathbf{u}, \mathbf{v} \in \mathbb{R}^{d} u,v∈Rd :
-
余弦相似性:
cosine ( u , v ) = u ⊤ v ∣ ∣ u ∣ ∣ ∣ v ∣ \operatorname{cosine}(\mathbf{u}, \mathbf{v})=\frac{\mathbf{u}^{\top} \mathbf{v}}{|\mid \mathbf{u}||\mid \mathbf{v}|} cosine(u,v)=∣∣u∣∣∣v∣u⊤v -
内积:
inner ( u , v ) = u ⊤ v \operatorname{inner}(\mathbf{u}, \mathbf{v})=\mathbf{u}^{\top} \mathbf{v} inner(u,v)=u⊤v -
欧几里得距离:
euclidean ( u , v ) = ∥ u − v ∥ 2 = ∑ i = 1 d ( u i − v i ) 2 \operatorname{euclidean}(\mathbf{u}, \mathbf{v})=\|\mathbf{u}-\mathbf{v}\|_{2}=\sqrt{\sum_{i=1}^{d}\left(u_{i}-v_{i}\right)^{2}} euclidean(u,v)=∥u−v∥2=i=1∑d(ui−vi)2 -
曼哈顿距离(也称为 L 1 L_{1} L1距离):
manhattan ( u , v ) = ∥ u − v ∥ 1 = ∑ i = 1 d ∣ u i − v i ∣ \operatorname{manhattan}(\mathbf{u}, \mathbf{v})=\|\mathbf{u}-\mathbf{v}\|_{1}=\sum_{i=1}^{d}\left|u_{i}-v_{i}\right| manhattan(u,v)=∥u−v∥1=i=1∑d∣ui−vi∣ -
切比雪夫距离:
chebyshev ( u , v ) = ∥ u − v ∥ ∞ = max i = 1 , … , d ∣ u i − v i ∣ \operatorname{chebyshev}(\mathbf{u}, \mathbf{v})=\|\mathbf{u}-\mathbf{v}\|_{\infty}=\max _{i=1, \ldots, d}\left|u_{i}-v_{i}\right| chebyshev(u,v)=∥u−v∥∞=i=1,…,dmax∣ui−vi∣
我们在大多数实验中使用余弦相似性,并在消融研究中比较了这些相似性度量。
2.3.3. 提示
在我们的框架中,我们设计了一种对话式的提示结构,如图1所示。无论选择了多少示例,这种提示都可以以一致的方式轻松适应。在提示的底部,我们放置了对应新查询的图像和文本用于疾病分类。在其上方,我们基于示例数量模拟多轮对话:如果只有一个示例,我们假设有一轮先前的对话;如果有十个示例,我们假设有十轮先前的对话。每轮对话对应一个示例,其中用户端提供图像和相应的文本,嵌入在查询中。助手(即MLLM)随后提供准确的响应。重要的是,对话是虚构的。我们模拟了MLLM自行生成每个响应的场景,并且响应是正确的。通过这种设计,所有示例都被自然地嵌入到MLLM接收到的提示中,模型只需要模仿其之前的回答风格来回应新查询。我们将提示的示例以及如何使用多个示例构建提示的内容放在补充材料1中。
2.3.4. 评估指标
我们使用一组综合指标来评估模型性能。具体来说,我们报告整体准确率(Acc),以及微平均精度、召回率和F1分数,这些指标将所有实例视为同等重要,并对类别不平衡敏感。此外,我们通过跨类别平均计算宏平均精度、召回率和F1分数,而不加权,从而反映模型在不同类别中表现的一致性。这种微平均和宏平均指标的组合提供了一个平衡的评价,既关注实例级又关注类别级的性能。
2.3.5. 实验设置
所有实验都在仅推理设置下进行,没有任何模型微调。对于涉及单一示例的实验,我们在单个NVIDIA A100 GPU上进行推理。对于涉及多个示例(尤其是少样本实验)的实验,我们将推理工作负载分布在多个NVIDIA A100 GPU上,以适应增加的计算需求。我们的代码使用Hugging Face Transformers库 [43] 实现,利用其API进行高效的模型加载和生成。在模型生成过程中,我们设置了以下参数:温度 = 1.0 =1.0 =1.0,top_k = 50 =50 =50,do_sample = = = True,num_beams = 1 =1 =1。这些设置确保确定性解码,同时在适当情况下允许模型保持适度的响应多样性。
3. 结果
3.1. 主要结果
表2和表3总结了一项跨越五个最先进的多模态语言模型——Qwen-2.5-VL-7B、Qwen-2.5-VL-3B、LLaVA-v1.6-Mistral-7B、Gemma-3-4B 和 Gemma-3-12B 的全面研究。对于Qwen-2.5-VL-7B模型在两个数据集上的条件对比,有无检索增强示例的结果明显。在两个基准测试中,RAG的效果都很显著:基线准确率低于0.80,而RAG将其提升至TCGA上的0.8368和IU Chest X-ray上的0.8658。每个指标都有所改善,TCGA上的宏F1分数从0.1191大幅提升至0.8454,显示出检索增强上下文学习对多模态大语言模型的强大影响。
表2 报告了TCGA数据集上的结果。使用ResNet-18/50/101图像嵌入选择的示例只带来了适度的收益,而使用文本编码器(BERT、BioBERT 或 ClinicalBERT)获得的示例则在每个模型中都带来了显著的改进,这意味着病理报告中的文本线索携带了大部分区分信号。
表3 展示了IU Chest X-ray语料库上的相应评估。在这里,模式发生了逆转:当检索依赖于ResNet派生的视觉嵌入时,收益最大,而基于文本的检索带来的好处较小。这些互补的趋势表明,最佳检索策略取决于数据集的主要模态,但在所有情况下,RAG框架都增强了性能。
总体而言,引入RAICL使准确率相对于非RAG基线提高了大约十个百分点(或更多),确认了检索上下文示例的一般有效性。
3.2. 单模态 vs. 多模态
我们在TCGA数据集上比较了Qwen-2.5-VL-7B在不同输入模态下的性能。当模型仅接收WSI图像时,准确率显著较低(0.1701),
突出了单纯从幻灯片视觉诊断的困难。仅使用文本则得出更高的分类准确率(0.7764),表明报告中包含更丰富、更具区分性的信息。当两种模态同时提供时,得出最佳结果(准确率为0.7854):将图像与文本结合进一步提升了性能,证实这两种证据来源相互补充。
3.3. 少样本设置下的鲁棒性
为了展示该框架天然适合上下文学习,我们比较了随着检索示例数量(k-shot)增加其性能的变化。表4 报告了Qwen-2.5-VL-7B在TCGA数据集上的结果,示例通过从不同嵌入模型衍生的余弦相似性检索。除了ResNet-50编码器外,每种设置都显示出明显的上升趋势:更多的示例始终转化为更高的准确率。表5 给出了IU Chest X-ray语料库上的相应分析。当使用基于文本的编码器进行检索时,观察到了相同的单调改进。相比之下,基于图像的编码器在5-shot时达到峰值,10-shot不再提供额外的好处,得分几乎相同。
3.4. 不同度量下的鲁棒性
表6 探讨了使用不同相似性度量的影响。在通过ResNet-18或BERT生成嵌入后,我们使用余弦相似性、内积、欧几里得、曼哈顿和切比雪夫距离检索示例,然后在TCGA数据集上进行评估。欧几里得距离提供了最高的准确率,而余弦相似性产生了最佳的宏F1分数,这表明最优度量取决于优先考虑哪个评估标准。
4. 讨论
本研究旨在通过一种新颖的检索增强上下文学习(RAICL)框架来改进疾病分类。RAICL框架利用了两种先进技术-RAG和ICL-显著增强了MLLMs在疾病分类中的能力。本研究最显著的成果之一是使用检索增强示例的有效性,这丰富了提供给模型的上下文。这导致了一个更加稳健和准确的疾病分类系统。例如,RAG的引入在各种嵌入模型(如ResNet和BERT)中大幅提升了Qwen-2.5-VL-7B模型的性能。正如表2和表3所示,将医学图像与临床文本结合始终提供了最佳结果,超过了仅依赖图像的模型。
单模态与多模态模型的比较是本研究的关键方面,如第3.2节所述,图像与文本的结合相比单独使用任何一种模态带来了更好的性能。这表明每种模态——图像和文本——都包含互补的信息,当结合使用时,可以对疾病分类问题提供更全面的理解。具体来说,将组织病理学图像与相应的病理报告结合使用,将准确率从0.1701(仅图像)提高到0.7854(多模态),突显了文本在分类任务中提供的丰富上下文信息。
RAICL与其他最先进的多模态模型(如Qwen-2.5-VL-3B、LLaVA-v1.6-Mistral-7B和Gemma-3模型)的比较揭示了几个重要见解。如表2和表3所示,RAICL框架在所有数据集中持续超越基线模型。
表2: TCGA数据集上代表性MLLMs的一次拍摄性能比较。为简单起见,我们将采用的编码器称为实现的RAICL。
| 模型 | 准确率 | 微平均 | 宏平均 | ||||
|---|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1 | 精确率 | 召回率 | F1 | ||
| Qwen2.5-VL-7B | |||||||
| 基线(无RAG) | 0.7854 | 0.7854 | 0.7854 | 0.7854 | 0.1217 | 0.1245 | 0.1191 |
| ResNet-18 | 0.7619 | 0.7619 | 0.7619 | 0.7619 | 0.6825 | 0.6955 | 0.6510 |
| ResNet-50 | 0.7721 | 0.7721 | 0.7721 | 0.7721 | 0.4611 | 0.4687 | 0.4406 |
| ResNet-101 | 0.7576 | 0.7576 | 0.7576 | 0.7576 | 0.5104 | 0.5178 | 0.4857 |
| BERT | 0.8192 | 0.8192 | 0.8192 | 0.8192 | 0.7119 | 0.7329 | 0.6955 |
| ClinicalBERT | 0.8240 | 0.8240 | 0.8240 | 0.8240 | 0.8580 | 0.8856 | 0.8397 |
| BioBERT | 0.8368 | 0.8368 | 0.8368 | 0.8368 | 0.8532 | 0.8862 | 0.8454 |
| Qwen2.5-VL-3B | |||||||
| 基线(无RAG) | 0.4002 | 0.4002 | 0.4002 | 0.4002 | 0.0292 | 0.0157 | 0.0172 |
| ResNet-18 | 0.5581 | 0.5581 | 0.5581 | 0.5581 | 0.2245 | 0.2148 | 0.1811 |
| ResNet-50 | 0.5607 | 0.5607 | 0.5607 | 0.5607 | 0.2007 | 0.1914 | 0.1617 |
| ResNet-101 | 0.5650 | 0.5650 | 0.5650 | 0.5650 | 0.2143 | 0.2043 | 0.1731 |
| BERT | 0.5425 | 0.5425 | 0.5425 | 0.5425 | 0.2293 | 0.2065 | 0.1750 |
| ClinicalBERT | 0.5281 | 0.5281 | 0.5281 | 0.5281 | 0.2122 | 0.1875 | 0.1568 |
| BioBERT | 0.5361 | 0.5361 | 0.5361 | 0.5361 | 0.2459 | 0.2178 | 0.1849 |
| LLaVA-v1.6-Mistral-7B | |||||||
| 基线(无RAG) | 0.7084 | 0.7084 | 0.7084 | 0.7084 | 0.0870 | 0.0785 | 0.0774 |
| ResNet-18 | 0.7014 | 0.7014 | 0.7014 | 0.7014 | 0.1208 | 0.1086 | 0.1077 |
| ResNet-50 | 0.7057 | 0.7057 | 0.7057 | 0.7057 | 0.1256 | 0.1137 | 0.1131 |
| ResNet-101 | 0.6945 | 0.6945 | 0.6945 | 0.6945 | 0.1414 | 0.1271 | 0.1265 |
| BERT | 0.7913 | 0.7913 | 0.7913 | 0.7913 | 0.1615 | 0.1533 | 0.1527 |
| ClinicalBERT | 0.8159 | 0.8159 | 0.8159 | 0.8159 | 0.1715 | 0.1655 | 0.1643 |
| BioBERT | 0.8058 | 0.8058 | 0.8058 | 0.8058 | 0.1427 | 0.1369 | 0.1361 |
| Gemma-3-4B | |||||||
| 基线(无RAG) | 0.4735 | 0.4735 | 0.4735 | 0.4735 | 0.1692 | 0.1688 | 0.1281 |
| ResNet-18 | 0.5078 | 0.5078 | 0.5078 | 0.5078 | 0.0921 | 0.0883 | 0.0689 |
| ResNet-50 | 0.4858 | 0.4858 | 0.4858 | 0.4858 | 0.0717 | 0.0664 | 0.0527 |
| ResNet-101 | 0.4912 | 0.4912 | 0.4912 | 0.4912 | 0.0665 | 0.0614 | 0.0484 |
| BERT | 0.5024 | 0.5024 | 0.5024 | 0.5024 | 0.0970 | 0.0881 | 0.0710 |
| ClinicalBERT | 0.5110 | 0.5110 | 0.5110 | 0.5110 | 0.0914 | 0.0824 | 0.0668 |
| BioBERT | 0.5078 | 0.5078 | 0.5078 | 0.5078 | 0.0836 | 0.0752 | 0.0607 |
| Gemma-3-12B | |||||||
| 基线(无RAG) | 0.6854 | 0.6854 | 0.6854 | 0.6854 | 0.3214 | 0.3230 | 0.2942 |
| ResNet-18 | 0.8919 | 0.8919 | 0.8919 | 0.8919 | 0.7214 | 0.7363 | 0.7244 |
| ResNet-50 | 0.8914 | 0.8914 | 0.8914 | 0.8914 | 0.8650 | 0.8818 | 0.8680 |
| ResNet-101 | 0.8807 | 0.8807 | 0.8807 | 0.8807 | 0.8538 | 0.8743 | 0.8576 |
| BERT | 0.9192 | 0.9192 | 0.9192 | 0.9192 | 0.8950 | 0.8979 | 0.8914 |
| ClinicalBERT | 0.9171 | 0.9171 | 0.9171 | 0.9171 | 0.8932 | 0.8917 | 0.8857 |
| BioBERT | 0.9171 | 0.9171 | 0.9171 | 0.8938 | 0.8928 | 0.8866 | |
| 表3: 不同最先进的MLLMs在IU胸部X光数据集上的一次拍摄性能比较。为简单起见,我们将采用的编码器称为实现的RAICL。 |
| 模型 | 准确率 | 微平均 | 宏平均 | ||||
|---|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1 | 精确率 | 召回率 | F1 | ||
| Qwen2.5-VL-7B | |||||||
| 基线(无RAG) | 0.7924 | 0.7924 | 0.7924 | 0.7924 | 0.3780 | 0.3851 | 0.3564 |
| ResNet-18 | 0.8658 | 0.8658 | 0.8658 | 0.8658 | 0.5027 | 0.4003 | 0.3981 |
| ResNet-50 | 0.8645 | 0.8645 | 0.8645 | 0.8645 | 0.4640 | 0.3906 | 0.3912 |
| ResNet-101 | 0.8578 | 0.8578 | 0.8578 | 0.8578 | 0.4384 | 0.3782 | 0.3773 |
| BERT | 0.8591 | 0.8591 | 0.8591 | 0.8591 | 0.4891 | 0.4211 | 0.4111 |
| ClinicalBERT | 0.8551 | 0.8551 | 0.8551 | 0.8551 | 0.4710 | 0.4085 | 0.4000 |
| BioBERT | 0.8565 | 0.8565 | 0.8565 | 0.8565 | 0.4734 | 0.4174 | 0.4164 |
| Qwen2.5-VL-3B | |||||||
| 基线(无RAG) | 0.8164 | 0.8164 | 0.8164 | 0.8164 | 0.4242 | 0.4557 | 0.4199 |
| Resnet18 | 0.9099 | 0.9099 | 0.9099 | 0.9099 | 0.5466 | 0.6247 | 0.5687 |
| Resnet50 | 0.9092 | 0.9092 | 0.9092 | 0.9092 | 0.4701 | 0.5199 | 0.4771 |
| Resnet101 | 0.9005 | 0.9005 | 0.9005 | 0.9005 | 0.5266 | 0.6008 | 0.5441 |
| BERT | 0.8618 | 0.8618 | 0.8618 | 0.8618 | 0.4385 | 0.4987 | 0.4289 |
| ClinicalBERT | 0.8685 | 0.8685 | 0.8685 | 0.8685 | 0.4321 | 0.5073 | 0.4327 |
| BioBERT | 0.8665 | 0.8665 | 0.8665 | 0.8665 | 0.4807 | 0.5208 | 0.4509 |
| llava-v1.6-mistral-7b | |||||||
| 基线(无RAG) | 0.8785 | 0.8785 | 0.8785 | 0.8785 | 0.2233 | 0.2210 | 0.2069 |
| Resnet18 | 0.9052 | 0.9052 | 0.9052 | 0.9052 | 0.2341 | 0.2121 | 0.2139 |
| Resnet50 | 0.9032 | 0.9032 | 0.9032 | 0.9032 | 0.2194 | 0.1975 | 0.1958 |
| Resnet101 | 0.9012 | 0.9012 | 0.9012 | 0.9012 | 0.2228 | 0.1927 | 0.1943 |
| BERT | 0.9206 | 0.9206 | 0.9206 | 0.9206 | 0.2296 | 0.2165 | 0.2143 |
| ClinicalBERT | 0.9186 | 0.9186 | 0.9186 | 0.9186 | 0.2706 | 0.2505 | 0.2474 |
| BioBERT | 0.9332 | 0.9332 | 0.9332 | 0.9332 | 0.2811 | 0.2488 | 0.2542 |
| Gemma-3-4b | |||||||
| 基线(无RAG) | 0.2570 | 0.2570 | 0.2570 | 0.2570 | 0.3270 | 0.3549 | 0.2900 |
| Resnet18 | 0.7503 | 0.7503 | 0.7503 | 0.7503 | 0.5674 | 0.6720 | 0.5589 |
| Resnet50 | 0.7470 | 0.7470 | 0.7470 | 0.7470 | 0.5308 | 0.6543 | 0.5439 |
| Resnet101 | 0.7623 | 0.7623 | 0.7623 | 0.7623 | 0.4437 | 0.5407 | 0.4455 |
| BERT | 0.4112 | 0.4112 | 0.4112 | 0.4112 | 0.3705 | 0.4299 | 0.3447 |
| ClinicalBERT | 0.4246 | 0.4246 | 0.4246 | 0.4246 | 0.3972 | 0.4582 | 0.3707 |
| BioBERT | 0.4166 | 0.4166 | 0.4166 | 0.4166 | 0.4134 | 0.4844 | 0.3869 |
| Gemma-3-12b | |||||||
| 基线(无RAG) | 0.8812 | 0.8812 | 0.8812 | 0.8812 | 0.5627 | 0.8206 | 0.6417 |
| Resnet18 | 0.9112 | 0.9112 | 0.9112 | 0.9112 | 0.6272 | 0.7539 | 0.6506 |
| Resnet50 | 0.9039 | 0.9039 | 0.9039 | 0.9039 | 0.6029 | 0.7636 | 0.6488 |
| Resnet101 | 0.9072 | 0.9072 | 0.9072 | 0.9072 | 0.6342 | 0.7612 | 0.6583 |
| BERT | 0.8652 | 0.8652 | 0.8652 | 0.8652 | 0.5657 | 0.7618 | 0.6080 |
| ClinicalBERT | 0.8705 | 0.8705 | 0.8705 | 0.8705 | 0.5704 | 0.7686 | 0.6214 |
| BioBERT | 0.8632 | 0.8632 | 0.8632 | 0.8632 | 0.5620 | 0.7656 | 0.6129 |
| 表4: Qwen2.5-VL-7B模型在TCGA数据集上的不同少样本设置的性能。 |
| 编码器 | 设置 | 准确率 | 微平均 | 宏平均 | ||||
|---|---|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1 | 精确率 | 召回率 | F1 | |||
| ResNet-18 | 1-shot | 0.7619 | 0.7619 | 0.7619 | 0.7619 | 0.6825 | 0.6955 | 0.6510 |
| 5-shot | 0.7555 | 0.7555 | 0.7555 | 0.7555 | 0.8531 | 0.8493 | 0.7891 | |
| 10-shot | 0.7774 | 0.7774 | 0.7774 | 0.7774 | 0.8536 | 0.8585 | 0.8058 | |
| ResNet-50 | 1-shot | 0.7721 | 0.7721 | 0.7721 | 0.7721 | 0.4611 | 0.4687 | 0.4406 |
| 5-shot | 0.7464 | 0.7464 | 0.7464 | 0.7464 | 0.7088 | 0.7027 | 0.6511 | |
| 10-shot | 0.7587 | 0.7587 | 0.7587 | 0.7587 | 0.7111 | 0.7083 | 0.6599 | |
| ResNet-101 | 1-shot | 0.7576 | 0.7576 | 0.7576 | 0.7576 | 0.5104 | 0.5178 | 0.4857 |
| 5-shot | 0.7528 | 0.7528 | 0.7528 | 0.7528 | 0.7096 | 0.7047 | 0.6556 | |
| 10-shot | 0.7710 | 0.7710 | 0.7710 | 0.7710 | 0.8551 | 0.8565 | 0.8016 | |
| BERT | 1-shot | 0.8192 | 0.8192 | 0.8192 | 0.8192 | 0.7119 | 0.7329 | 0.6955 |
| 5-shot | 0.8566 | 0.8566 | 0.8566 | 0.8566 | 0.8798 | 0.9084 | 0.8690 | |
| 10-shot | 0.8700 | 0.8700 | 0.8700 | 0.8700 | 0.8863 | 0.9174 | 0.8800 | |
| ClinicalBERT | 1-shot | 0.8240 | 0.8240 | 0.8240 | 0.8240 | 0.8580 | 0.8856 | 0.8397 |
| 5-shot | 0.8561 | 0.8561 | 0.8561 | 0.8561 | 0.7347 | 0.7559 | 0.7242 | |
| 10-shot | 0.8764 | 0.8764 | 0.8764 | 0.8764 | 0.8921 | 0.9219 | 0.8861 | |
| BioBERT | 1-shot | 0.8368 | 0.8368 | 0.8368 | 0.8368 | 0.8532 | 0.8862 | 0.8454 |
| 5-shot | 0.8513 | 0.8513 | 0.8513 | 0.8513 | 0.8830 | 0.9082 | 0.8670 | |
| 10-shot | 0.8646 | 0.8646 | 0.8646 | 0.8646 | 0.8865 | 0.9133 | 0.8762 |
表5: Qwen2.5-VL-7B模型在IU胸部X光数据集上的不同少样本设置的性能。
| 编码器 | 设置 | 准确率 | 微平均 | 宏平均 | ||||
|---|---|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1 | 精确率 | 召回率 | F1 | |||
| ResNet-18 | 1-shot | 0.8658 | 0.8658 | 0.8658 | 0.8658 | 0.5027 | 0.4003 | 0.3981 |
| 5-shot | 0.9172 | 0.9172 | 0.9172 | 0.9172 | 0.6849 | 0.5889 | 0.5774 | |
| 10-shot | 0.9166 | 0.9166 | 0.9166 | 0.9166 | 0.6822 | 0.5889 | 0.5862 | |
| ResNet-50 | 1-shot | 0.8645 | 0.8645 | 0.8645 | 0.8645 | 0.4640 | 0.3906 | 0.3912 |
| 5-shot | 0.9172 | 0.9172 | 0.9172 | 0.9172 | 0.6324 | 0.5970 | 0.5882 | |
| 10-shot | 0.9166 | 0.9166 | 0.9166 | 0.9166 | 0.6553 | 0.6040 | 0.5942 | |
| ResNet-101 | 1-shot | 0.8578 | 0.8578 | 0.8578 | 0.8578 | 0.4384 | 0.3782 | 0.3773 |
| 5-shot | 0.9172 | 0.9172 | 0.9172 | 0.9172 | 0.6983 | 0.5795 | 0.5808 | |
| 10-shot | 0.9152 | 0.9152 | 0.9152 | 0.9152 | 0.6502 | 0.5804 | 0.5777 | |
| BERT | 1-shot | 0.8591 | 0.8591 | 0.8591 | 0.8591 | 0.4891 | 0.4211 | 0.4111 |
| 5-shot | 0.9252 | 0.9252 | 0.9252 | 0.9252 | 0.7292 | 0.6709 | 0.6590 | |
| 10-shot | 0.9299 | 0.9299 | 0.9299 | 0.9299 | 0.7191 | 0.7006 | 0.6746 | |
| ClinicalBERT | 1-shot | 0.8565 | 0.8565 | 0.8565 | 0.8565 | 0.4734 | 0.4174 | 0.4164 |
| 5-shot | 0.9319 | 0.9319 | 0.9319 | 0.9319 | 0.7024 | 0.6763 | 0.6577 | |
| 10-shot | 0.9326 | 0.9326 | 0.9326 | 0.9326 | 0.7363 | 0.7066 | 0.6922 | |
| BioBERT | 1-shot | 0.8551 | 0.8551 | 0.8551 | 0.8551 | 0.4710 | 0.4085 | 0.4000 |
| 5-shot | 0.9319 | 0.9319 | 0.9319 | 0.9319 | 0.7214 | 0.7072 | 0.6813 | |
| 10-shot | 0.9352 | 0.9352 | 0.9352 | 0.9352 | 0.7465 | 0.7176 | 0.6991 | |
| 表6: TCGA数据集上不同相似性度量的一次拍摄性能比较。 |
| 编码器 | 相似性度量 | 准确率 | 微平均 | 宏平均 | ||||
|---|---|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1 | 精确率 | 召回率 | F1 | |||
| Resnet18 | 余弦 | 0.7619 | 0.7619 | 0.7619 | 0.7619 | 0.6825 | 0.6955 | 0.651 |
| 内积 | 0.7416 | 0.7416 | 0.7416 | 0.7416 | 0.5036 | 0.5097 | 0.476 | |
| 欧几里得 | 0.7774 | 0.7774 | 0.7774 | 0.7774 | 0.5178 | 0.5278 | 0.4976 | |
| 曼哈顿 | 0.7726 | 0.7726 | 0.7726 | 0.7726 | 0.5175 | 0.5266 | 0.4963 | |
| 切比雪夫 | 0.7598 | 0.7598 | 0.7598 | 0.7598 | 0.5123 | 0.5198 | 0.4876 | |
| BERT | 余弦 | 0.8192 | 0.8192 | 0.8192 | 0.8192 | 0.7119 | 0.7329 | 0.6955 |
| 内积 | 0.7742 | 0.7742 | 0.7742 | 0.7742 | 0.5968 | 0.6081 | 0.569 | |
| 欧几里得 | 0.8240 | 0.8240 | 0.8240 | 0.8240 | 0.4227 | 0.4358 | 0.4167 | |
| 曼哈顿 | 0.8224 | 0.8224 | 0.8224 | 0.8224 | 0.4226 | 0.4351 | 0.4361 | |
| 切比雪夫 | 0.8095 | 0.8095 | 0.8095 | 0.8095 | 0.4640 | 0.4773 | 0.4554 |
本研究最引人注目的发现之一是RAICL框架在少量样本学习设置中的表现能力。如表4和表5所示,增加检索示例的数量导致模型准确率的一致提升。这在现实世界的医疗场景中尤为重要,因为标注数据往往有限。RAICL框架在最小数据下具有良好的泛化能力,使其在涉及罕见或代表性不足疾病的医疗诊断任务中极具价值。此外,文本检索方法的准确性提高表明文本信息在引导模型进行准确分类方面起着关键作用。
来自各种最先进的MLLMs(包括Qwen-2.5-VL-7B、LLaVA-v1.6-Mistral-7B和Gemma-3模型)的结果进一步强调了RAICL框架的稳健性。我们的实验显示,无论底层模型架构如何,RAICL始终比基线模型高出约10个百分点的准确率。这在生物医学应用背景下尤其重要,因为高准确率对临床决策至关重要。该框架在不同模型和任务(例如TCGA和IU胸部X光数据集)中增强性能的能力确认了其多样性和在医疗诊断中广泛应用的潜力。
虽然RAICL框架显示出有希望的结果,但有几个限制需要考虑。首先,使用大型多模态数据集的计算成本非同小可,特别是
当使用具有70B参数或更多的大型模型时,推理需要大量的计算资源。其次,本研究仅探索了两种模态——图像和文本——而实际应用通常涉及更广泛的模态。因此,需要进一步研究以扩展RAICL的能力,以应对实践中遇到的更复杂、多模态的情景。
未来的研究方向可以进一步增强RAICL框架的性能和适用性。首先,探索使用其他相似性度量,如曼哈顿和欧几里得距离,可以帮助改进检索过程并提高分类准确性(如表6所示)。其次,我们计划研究优化框架效率的方法,特别是在不牺牲准确性的情况下减少计算成本 [44]。量化方法 [45, 46] 和多任务学习 [47, 48] 可能提供使RAICL在资源受限环境中部署更为可行的方向。最后,未来的研究所应探索将RAICL应用于更广泛的模态,如视频、语音和时间序列信号。
5. 结论
在本研究中,我们提出了RAICL框架以增强MLLMs在疾病分类中的应用。通过将RAG与ICL相结合,RAICL有效地利用了视觉和文本模态,为诊断提供了更丰富的上下文。在两个真实世界的数据集(TCGA数据集和IU胸部X光数据集)上进行的广泛实验表明,RAICL在一系列最先进的MLLMs中一致地提高了分类性能。结果突出显示,检索增强示例显著增强了模型的鲁棒性和准确性,文本检索在病理任务中尤为有效,而图像检索则在放射学任务中表现更好。此外,RAICL在少量样本设置中表现出强大的泛化能力,表明其在标记数据有限的临床应用中高效部署的潜力。总体而言,我们的研究结果确立了RAICL作为一种强大且多功能的框架,在无需额外模型微调的情况下为多模态疾病分类带来了显著改进。
6. CRediT作者贡献声明
詹自富:概念化、数据整理、正式分析、调查、方法论、验证、撰写 - 原始草稿、撰写 - 审阅和编辑。周双:概念化、数据整理、方法论、验证、撰写 - 审阅和编辑。周晓山:撰写 - 审阅和编辑。肖永康:撰写 - 审阅和编辑。王军:撰写 - 审阅和编辑。邓家文:撰写 - 审阅和编辑。朱赫:撰写 - 审阅和编辑。侯宇:撰写 - 审阅和编辑。张锐:概念化、资金获取、项目管理、资源、监督、撰写 - 审阅和编辑
7. 利益冲突声明
作者声明他们没有已知的竞争财务利益或个人关系,这些可能会被认为影响本文报告的工作。
8. 数据可用性
读者可以通过以下链接找到我们使用的数据集:
TCGA:https://www.cancer.gov/ccg/research/genome-sequencing/tcga
IU 胸部X光: https://www.kaggle.com/datasets/raddar/chest-xrays-indiana-university
我们将在论文被接受后发布代码。
9. 致谢
本工作得到了国家补充与综合健康中心[资助编号 R01AT009457, U01AT012871];国家老龄化研究所[资助编号 R01AG078154];国家癌症研究所[资助编号 R01CA287413];国家糖尿病与消化与肾脏疾病研究所[资助编号 R01DK115629];以及国家少数族裔健康与健康差异研究所[资助编号 1R21MD01913401]的支持。
10. 关于生成式AI和AI辅助技术在写作过程中的声明
在准备本工作的过程中,作者使用ChatGPT检查语法。使用此工具后,作者根据需要审查和编辑内容,并对已发表文章的内容承担全部责任。
参考文献
[1] B. Yu, H. Chen, C. Jia, H. Zhou, L. Cong, X. Li, J. Zhuang, X. Cong, 多模态多尺度心血管疾病亚型分类使用拉曼图像和病史,专家系统与应用 224 (2023) 119965.
[2] J. Zhang, X. He, Y. Liu, Q. Cai, H. Chen, L. Qing, 阿尔茨海默病诊断的多模态交叉注意力网络与多模态数据,计算机生物学与医学 162 (2023) 107050.
[3] Y. Liu, M. Liu, Y. Zhang, K. Sun, D. Shen, 阿尔茨海默病亚型诊断的渐进单模态到多模态分类框架,国际临床神经影像机器学习研讨会论文集,Springer, 2025, pp. 123-133.
[4] T. Han, L. C. Adams, K. K. Bressem, F. Busch, S. Nebelung, D. Truhn, 多模态大语言模型在临床案例问题上的性能比较分析,JAMA 331 (15) (2024) 1320-1321.
[5] M. N. Gurcan, L. E. Boucheron, A. Can, A. Madabhushi, N. M. Rajpoot, B. Yener, 组织病理学图像分析综述,IEEE生物医学工程评论 2 (2009) 147-171.
[6] T. Drew, K. Evans, M. L.-H. Vö, F. L. Jacobson, J. M. Wolfe, 放射学信息学:单次注视中能看到什么,以及如何指导医学图像中的视觉搜索?放射学图解 33 (1) (2013) 263-274.
[7] T. Nissen, R. Wynn, 临床病例报告:对其优点和局限性的回顾,BMC研究笔记 7 (2014)
1
−
7
1-7
1−7.
[8] P. Adhikari, 通过联合文本-图像表示的多模态临床文档理解,大数据处理、流分析与实时洞察期刊 14 (10) (2024) 16-29.
[9] X. Xu, J. Li, Z. Zhu, L. Zhao, H. Wang, C. Song, Y. Chen, Q. Zhao, J. Yang, Y. Pei, 医疗诊断中多模态数据与人工智能技术协同作用的全面回顾,生物工程 11 (3) (2024) 219.
[10] Q. Niu, K. Chen, M. Li, P. Feng, Z. Bi, L. K. Yan, Y. Zhang, C. H. Yin, C. Fei, J. Liu, et al., 从文本到多模态:探索大语言模型在医疗实践中的演变及其影响,arXiv预印本 arXiv:2410.01812 (2024).
[11] A. Moglia, E. C. Nastasio, L. Mainardi, P. Cerveri, Minigpt-pancreas: 用于胰腺癌分类和检测的多模态大语言模型,arXiv预印本 arXiv:2412.15925 (2024).
[12] S. Kumar, S. Sharma, K. T. Megra, 使用Transformer启用的多模态医疗诊断进行结核病分类,大数据杂志 12 (1) (2025) 5.
[13] J. Irvin, P. Rajpurkar, M. Ko, Y. Yu, S. Ciurea-Ikou, C. Chute, H. Marklund, B. Haghgoo, R. Ball, K. Shpanskaya, et al., CheXpert: 具有不确定性标签的大规模胸部X光数据集及专家比较,AAAI人工智能会议论文集,Vol. 33, 2019, pp. 590-597.
[14] N. Hayat, K. J. Geras, F. E. Shamout, Medfuse: 临床时间序列数据和胸部X光图像的多模态融合,机器学习在医疗保健会议论文集,PMLR, 2022, pp. 479-503.
[15] D. Zhang, Y. Yu, J. Dong, C. Li, D. Su, C. Chu, D. Yu, MM-LHMS: 多模态大语言模型的最新进展,arXiv预印本 arXiv:2401.13601 (2024).
[16] S. Zhou, Z. Xu, M. Zhang, C. Xu, Y. Guo, Z. Zhan, S. Ding, J. Wang, K. Xu, Y. Fang, et al., 大语言模型在疾病诊断中的应用:范围审查,arXiv预印本 arXiv:2409.00097 (2024).
[17] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al., GPT-4技术报告,arXiv预印本 arXiv:2303.08774 (2023).
[18] D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al., Deepseek-r1: 通过强化学习激励大型语言模型的推理能力,arXiv预印本 arXiv:2501.12948 (2025).
[19] S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, et al., Qwen2.5-VL技术报告,arXiv预印本 arXiv:2502.13923 (2025).
[20] Z. Wu, O. Zhang, X. Wang, L. Fu, H. Zhao, J. Wang, H. Du, D. Jiang, Y. Deng, D. Cao, et al., 通过提示工程利用语言模型进行高级多属性分子优化,自然机器智能 (2024)
1
−
11
1-11
1−11.
[21] C. Chakraborty, M. Bhattacharya, S. Pal, S.-S. Lee, Prompt工程启用的LLM或NLLM和探究性生物信息学为识别和表征重要的SARS-CoV-2抗体逃逸突变铺平道路,国际生物大分子杂志 287 (2025) 138547.
[22] Y. Tai, W. Fan, Z. Zhang, Z. Liu, 链接上下文学习用于多模态LLMs,IEEE/CVF计算机视觉与模式识别会议论文集,2024, pp. 27176-27185.
[23] Z. Zhan, J. Wang, S. Zhou, J. Deng, R. Zhang, MMRAG: 使用大语言模型进行生物医学上下文学习的多模态检索增强生成,arXiv预印本 arXiv:2502.15954 (2025).
[24] S. Pai, D. Bontempi, I. Hadzic, V. Prudente, M. Sokač, T. L. Chaunzwa, S. Bernatz, A. Hosny, R. H. Mak, N. J. Birkhak, 等等., 癌症成像生物标志物的基础模型,自然机器智能 6 (3) (2024) 354367.
[25] D. Ferber, G. Wölflein, I. C. Wiest, M. Ligero, S. Sainath, N. Ghaffari Laleh, O. S. El Nahhas, G. Müller-Franzes, D. Jäger, D. Truhn, 等等., 上下文学习使多模态大语言模型能够对癌症病理图像进行分类,自然通讯 15 (1) (2024) 10104.
[26] Y. Jiang, J. A. Irvin, J. H. Wang, M. A. Chaudhry, J. H. Chen, A. Y. Ng, 多模态基础模型中的多示例上下文学习,ICML 2024 Workshop on In-Context Learning, 2024.
[27] T. Li, G. Zhang, Q. D. Do, X. Yue, W. Chen, 长上下文LLMs在长上下文学习中表现不佳,arXiv预印本 arXiv:2404.02060 (2024).
[28] D. Song, S. Chen, G. H. Chen, F. Yu, X. Wan, B. Wang, Milebench: 在长上下文中基准测试NLLMs,arXiv预印本 arXiv:2404.18532 (2024).
[29] W. Li, H. Fan, Y. Wong, Y. Yang, M. Kankanhalli, 通过多模态组合学习改进多模态大语言模型的情境理解,第四十一届国际机器学习会议,2024.
[30] F. Liu, H. Zhou, B. Gu, X. Zou, J. Huang, J. Wu, Y. Li, S. S. Chen, Y. Hua, P. Zhou, 等等., 大语言模型在医学中的应用,自然评论生物工程 (2025) 1-20.
[31] D. Oniani, X. Wu, S. Visweswaran, S. Kapoor, S. Kooragayalu, K. Polanska, Y. Wang, 通过结合临床实践指南增强大语言模型以支持临床决策,2024 IEEE第12届医疗信息学国际会议 (ICHI),IEEE, 2024, pp. 694-702.
[32] K. Peng, L. Ding, Y. Yuan, X. Liu, M. Zhang, Y. Ouyang, D. Tao, 再探上下文学习中的示例选择策略,arXiv预印本 arXiv:2401.12087 (2024).
[33] N. Xu, F. Wang, S. Zhang, H. Poon, M. Chen, 从内省到最佳实践:多模态上下文学习中示例的原则性分析,arXiv预印本 arXiv:2407.00902 (2024).
[34] H. Liu, C. Li, Y. Li, B. Li, Y. Zhang, S. Shen, Y. J. Lee, LLaVA-Next: 改进的推理、OCR和世界知识 (January 2024).
URL https://llava-vi.github.io/blog/2024-01-30-llava-next/
[35] G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ramé, M. Rivière, 等等., Gemma 3技术报告,arXiv预印本 arXiv:2503.19786 (2025).
[36] J. N. Weinstein, E. A. Collisson, G. B. Mills, K. R. Shaw, B. A. Ozenberger, K. Ellrott, I. Shmulevich, C. Sander, J. M. Stuart, 癌症基因组图谱泛癌分析项目,自然遗传学 45 (10) (2013) 1113-1120.
[37] D. Demner-Fushman, M. D. Kohli, M. B. Rosenman, S. E. Shosohan, L. Rodriguez, S. Antani, G. R. Thoma, C. J. McDonald, 准备用于分发和检索的放射学检查集合,美国医学信息学协会期刊 23 (2) (2016) 304-310.
[38] K. He, X. Zhang, S. Ren, J. Sun, 深度残差学习用于图像识别,IEEE 计算机视觉与模式识别会议论文集,2016, pp. 770-778.
[39] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, L. Fei-Fei, ImageNet: 一个大规模层次化图像数据库,2009年IEEE计算机视觉与模式识别会议论文集,Ieee, 2009, pp. 248-255.
[40] J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, BERT: 用于语言理解的深度双向Transformer预训练,2019年北美计算语言学协会会议论文集,卷1(长篇和短篇论文),2019, pp. 4171-4186.
[41] J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. H. So, J. Kang, BioBERT: 用于生物医学文本挖掘的预训练生物医学语言表示模型,生物信息学 36 (4) (2020) 1234-1240.
[42] E. Alsentzer, J. R. Murphy, W. Boag, W.-H. Weng, D. Jin, T. Naumann, M. McDermott, 公开可用的临床BERT嵌入,arXiv预印本 arXiv:1904.03323 (2019).
[43] T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, 等等., Transformers: 最新自然语言处理进展,2020年经验方法在自然语言处理会议论文集:系统演示,2020, pp. 38-45.
[44] Z. Zhan, S. Zhou, H. Zhou, Z. Liu, R. Zhang, EPee: 朝着高效且有效的生物医学基础模型迈进,arXiv预印本 arXiv:2503.02053 (2025).
[45] Y. Jin, J. Li, Y. Liu, T. Gu, K. Wu, Z. Jiang, M. He, B. Zhao, X. Tan, Z. Gan, 等等., 高效多模态大语言模型:综述,arXiv预印本 arXiv:2405.10739 (2024).
[46] X. Li, Z. Lu, D. Cai, X. Ma, M. Xu, 移动设备上的大语言模型:测量、分析与见解,边缘与移动基础模型研讨会论文集,2024, pp. 1-6.
[47] Z. Zhan, R. Zhang, 朝更好的多任务学习方向发展:一种优化大语言模型数据集组合的框架,arXiv预印本 arXiv:2412.11455 (2024).
[48] Z. Zhan, S. Zhou, M. Li, R. Zhang, RAMIE: 使用大语言模型对膳食补充剂进行检索增强多任务信息提取,美国医学信息学协会期刊 (2025) ocaf002.
参考论文:https://arxiv.org/pdf/2505.02087



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











