






通过使用实时分析,企业可以快速有效地对用户行为模式做出反应。这使他们能够利用可能错过的机会,防止问题变得更糟。
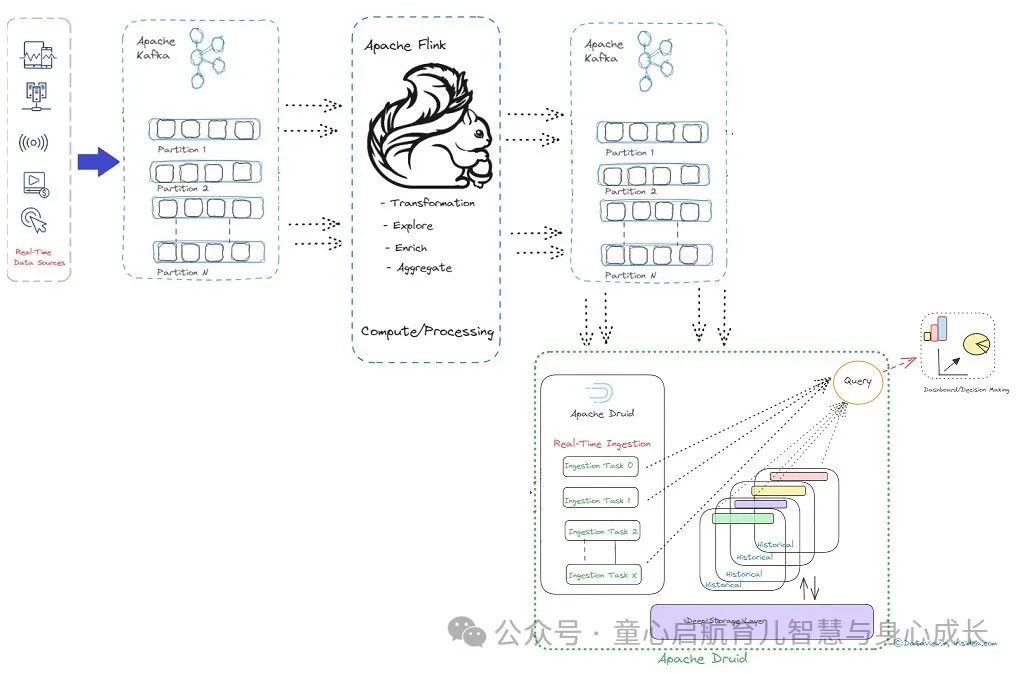
Apache Kafka 是一个流行的事件流平台,可用于实时摄取从多个垂直领域(如物联网、金融交易、库存等)的各种来源生成的数据/事件。然后,这些数据可以流式传输到多个下游应用程序或引擎中,以便进一步处理和最终分析,以支持决策。
Apache Flink 是一个强大的引擎,用于在到达 Kafka 主题时通过修改、丰富或重组流数据来优化或增强流数据。从本质上讲,Flink 是一个下游应用程序,它持续消耗来自 Kafka 主题的数据流进行处理,然后将处理后的数据摄取到各个 Kafka 主题中。最终,可以集成 Apache Druid,以使用来自 Kafka 主题的处理后的流数据进行分析、查询和做出即时业务决策。
点击这里查看大图
在我之前的文章中,我解释了如何将 Flink 1.18 与 Kafka 3.7.0 集成。在本文中,我将概述将处理后的数据从 Flink 1.18.1 传输到 Kafka 2.13-3.7.0 主题的步骤。几个月前,我们发表了一篇单独的文章,详细介绍了如何将 Kafka 主题中的流数据引入 Apache Druid 进行分析和查询。你可以在这里阅读。
执行环境
我们配置了一个多节点集群(三个节点),其中每个节点至少有 8 GB RAM 和 250 GB SSD 以及 Ubuntu-22.04.2 amd64 作为操作系统。
OpenJDK 11 在每个节点上都安装了环境变量配置。
JAVA_HOMEPython 3 或 Python 2 以及 Perl 5 在每个节点上都可用。
三节点 Apache Kafka-3.7.0 集群已启动并运行 Apache Zookeeper -3.5.6。在两个节点上。
Apache Druid 29.0.0 已在集群中尚未为 Kafka 代理安装 Zookeeper 的节点上安装和配置。Zookeeper 已在其他两个节点上安装和配置。Leader 代理已启动并运行在运行 Druid 的节点上。
使用 Datafaker 库开发了一个模拟器,每隔 10 秒生成一次实时虚假的金融交易 JSON 记录,并将其发布到创建的 Kafka 主题中。下面是模拟器生成的 JSON 数据馈送。
JSON的
{"timestamp":"2024-03-14T04:31:09Z ","upiID":"9972342663@ybl","name":"Kiran Marar","note":" ","amount":"14582.00","currency":"INR","geoLocation":"Latitude: 54.1841745 Longitude: 13.1060775","deviceOS":"IOS","targetApp":"PhonePe","merchantTransactionId":"ebd03de9176201455419cce11bbfed157a","merchantUserId":"65107454076524@ybl"}解压 Druid 和 Kafka 的 leader broker 未运行的节点上的 Apache Flink-1.18.1-bin-scala_2.12.tgz 的存档
在 Flink 中运行流式处理作业
我们将深入研究从 Kafka 主题中提取数据的过程,其中传入的消息是从模拟器发布,在其上执行处理任务,然后将处理后的数据重新集成回多节点 Kafka 集群的其他主题。
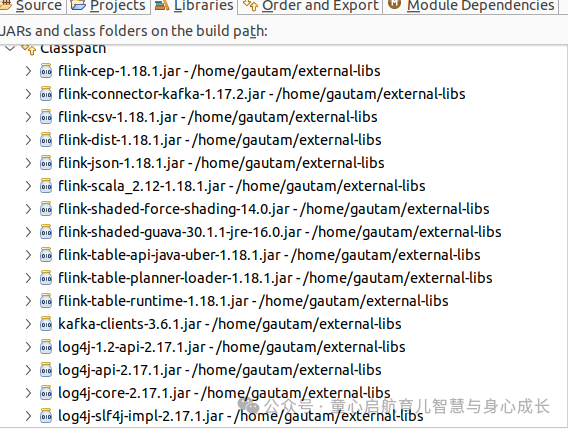
我们开发了一个 Java 程序 (),作为作业提交给 Flink 来执行上述步骤,考虑 2 分钟的窗口,并计算模拟 UPI 事务数据流上同一手机号码 () 的平均交易金额。以下 jar 文件列表已包含在项目构建或类路径中。StreamingToFlinkJob.javaupi id
使用下面的代码,我们可以在开发的 Java 类中得到 Flink 执行环境。
爪哇岛
Configuration conf = new Configuration();
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);现在,我们应该读取模拟器已经发布到 Java 程序内 Kafka 主题的消息/流。这是代码块。
爪哇岛
KafkaSource kafkaSource = KafkaSource.<UPITransaction>builder()
.setBootstrapServers(IKafkaConstants.KAFKA_BROKERS)// IP Address with port 9092 where leader broker is running in cluster
.setTopics(IKafkaConstants.INPUT_UPITransaction_TOPIC_NAME)
.setGroupId("upigroup")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new KafkaUPISchema())
.build();要从 Kafka 中检索信息,在 Flink 中设置反序列化模式对于处理 JSON 格式的事件、将原始数据转换为结构化形式至关重要。重要的是,需要设置为 no.of Kafka 主题分区,否则水印将不适用于源,并且数据不会发布到接收器。setParallelism
爪哇岛
DataStream<UPITransaction> stream = env.fromSource(kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofMinutes(2)), "Kafka Source").setParallelism(1);通过从 Kafka 成功检索事件,我们可以通过合并处理步骤来增强流式处理作业。后续代码片段读取 Kafka 数据,按手机号码 () 进行组织,并计算每个手机号码的平均价格。为了实现这一点,我们开发了一个自定义窗口函数来计算平均值,并实现了水印以有效地处理事件时间语义。下面是代码片段:upiID
爪哇岛
SerializableTimestampAssigner<UPITransaction> sz = new SerializableTimestampAssigner<UPITransaction>() {
@Override
public long extractTimestamp(UPITransaction transaction, long l) {
try {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss'Z'");
Date date = sdf.parse(transaction.eventTime);
return date.getTime();
} catch (Exception e) {
return 0;
}
}
};
WatermarkStrategy<UPITransaction> watermarkStrategy = WatermarkStrategy.<UPITransaction>forBoundedOutOfOrderness(Duration.ofMillis(100)).withTimestampAssigner(sz);
DataStream<UPITransaction> watermarkDataStream = stream.assignTimestampsAndWatermarks(watermarkStrategy);
//Instead of event time, we can use window based on processing time. Using TumblingProcessingTimeWindows
DataStream<TransactionAgg> groupedData = watermarkDataStream.keyBy("upiId").window(TumblingEventTimeWindows.of(Time.milliseconds(2500),
Time.milliseconds(500))).sum("amount");
.apply(new TransactionAgg());最终,在 Flink 内部执行处理逻辑(基于手机号码计算同一 UPI ID 在连续交易流流 2 分钟窗口内的平均价格)。这是 Window 函数的代码块,用于计算每个 UPI ID 或手机号码的平均金额。
爪哇岛
public class TransactionAgg
implements WindowFunction<UPITransaction, TransactionAgg, Tuple, TimeWindow> {
@Override
public void apply(Tuple key, TimeWindow window, Iterable<UPITransaction> values, Collector<TransactionAgg> out) {
Integer sum = 0; //Consider whole number
int count = 0;
String upiID = null ;
for (UPITransaction value : values) {
sum += value.amount;
upiID = value.upiID;
count++;
}
TransactionAgg output = new TransactionAgg();
output.upiID = upiID;
output.eventTime = window.getEnd();
output.avgAmount = (sum / count);
out.collect( output);
}
}我们已经处理了数据。下一步是序列化对象并将其发送到其他 Kafka 主题。在开发的 Java 代码 () 中添加 a,将处理后的数据从 Flink 引擎发送到在多节点 Kafka 集群上创建的不同 Kafka 主题。下面是在将对象发送/发布到 Kafka 主题之前序列化对象的代码片段:KafkaSinkStreamingToFlinkJob.java
爪哇岛
public class KafkaTrasactionSinkSchema implements KafkaRecordSerializationSchema<TransactionAgg> {
@Override
public ProducerRecord<byte[], byte[]> serialize(
TransactionAgg aggTransaction, KafkaSinkContext context, Long timestamp) {
try {
return new ProducerRecord<>(
topic,
null, // not specified partition so setting null
aggTransaction.eventTime,
aggTransaction.upiID.getBytes(),
objectMapper.writeValueAsBytes(aggTransaction));
} catch (Exception e) {
throw new IllegalArgumentException(
"Exception on serialize record: " + aggTransaction, e);
}
}
}而且,下面是用于接收已处理数据的代码块,该数据发送回不同的 Kafka 主题。
爪哇岛
KafkaSink<TransactionAgg> sink = KafkaSink.<TransactionAgg>builder()
.setBootstrapServers(IKafkaConstants.KAFKA_BROKERS)
.setRecordSerializer(new KafkaTrasactionSinkSchema(IKafkaConstants.OUTPUT_UPITRANSACTION_TOPIC_NAME))
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
groupedData.sinkTo(sink); // DataStream that created above for TransactionAgg
env.execute();将 Druid 与 Kafka 主题连接起来
在最后一步中,我们需要将 Druid 与 Kafka 主题集成,以消耗 Flink 持续发布的处理后的数据流。借助 Apache Druid,我们可以直接连接 Apache Kafka,从而可以持续摄取实时数据,然后进行查询,从而在现场做出业务决策,而无需干预任何第三方系统或应用程序。Apache Druid 的另一个优点是,我们不需要配置或安装任何第三方 UI 应用程序来查看登陆或发布到 Kafka 主题的数据。为了精简这篇文章,我省略了将 Druid 与 Apache Kafka 集成的步骤。但是,几个月前,我发表了一篇关于这个主题的文章(本文前面链接)。您可以阅读它并遵循相同的方法。
结语
上面提供的代码片段仅供理解之用。它说明了从 Kafka 主题获取消息/数据流、处理消耗的数据以及最终将修改后的数据发送/推送到其他 Kafka 主题的顺序步骤。这允许 Druid 拾取修改后的数据流进行查询,作为最后一步进行分析。稍后,如果您有兴趣在自己的基础架构上执行整个代码库,我们将在 GitHub 上上传它。
















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











