







 本教程详细讲解如何利用Druid的Kafka索引服务将数据从Kafka流实时摄入到Druid中。首先确保Druid已在本地运行,然后下载并启动Kafka 2.1.0版本。通过Kafka命令行工具创建名为wikipedia的主题。由于假设Druid和Kafka共用ZooKeeper,可以直接进行数据传输。此教程适合已了解Druid基础的读者。
本教程详细讲解如何利用Druid的Kafka索引服务将数据从Kafka流实时摄入到Druid中。首先确保Druid已在本地运行,然后下载并启动Kafka 2.1.0版本。通过Kafka命令行工具创建名为wikipedia的主题。由于假设Druid和Kafka共用ZooKeeper,可以直接进行数据传输。此教程适合已了解Druid基础的读者。
本教程演示了如何使用Druid的Kafka索引服务将数据从Kafka流加载到Apache Druid中。
假设你已经完成了 快速开始 页面中的内容或者下面页面中有关的内容,并且你的 Druid 实例已使用 micro-quickstart 配置在你的本地的计算机上运行了。
到目前,你还不需要加载任何数据。
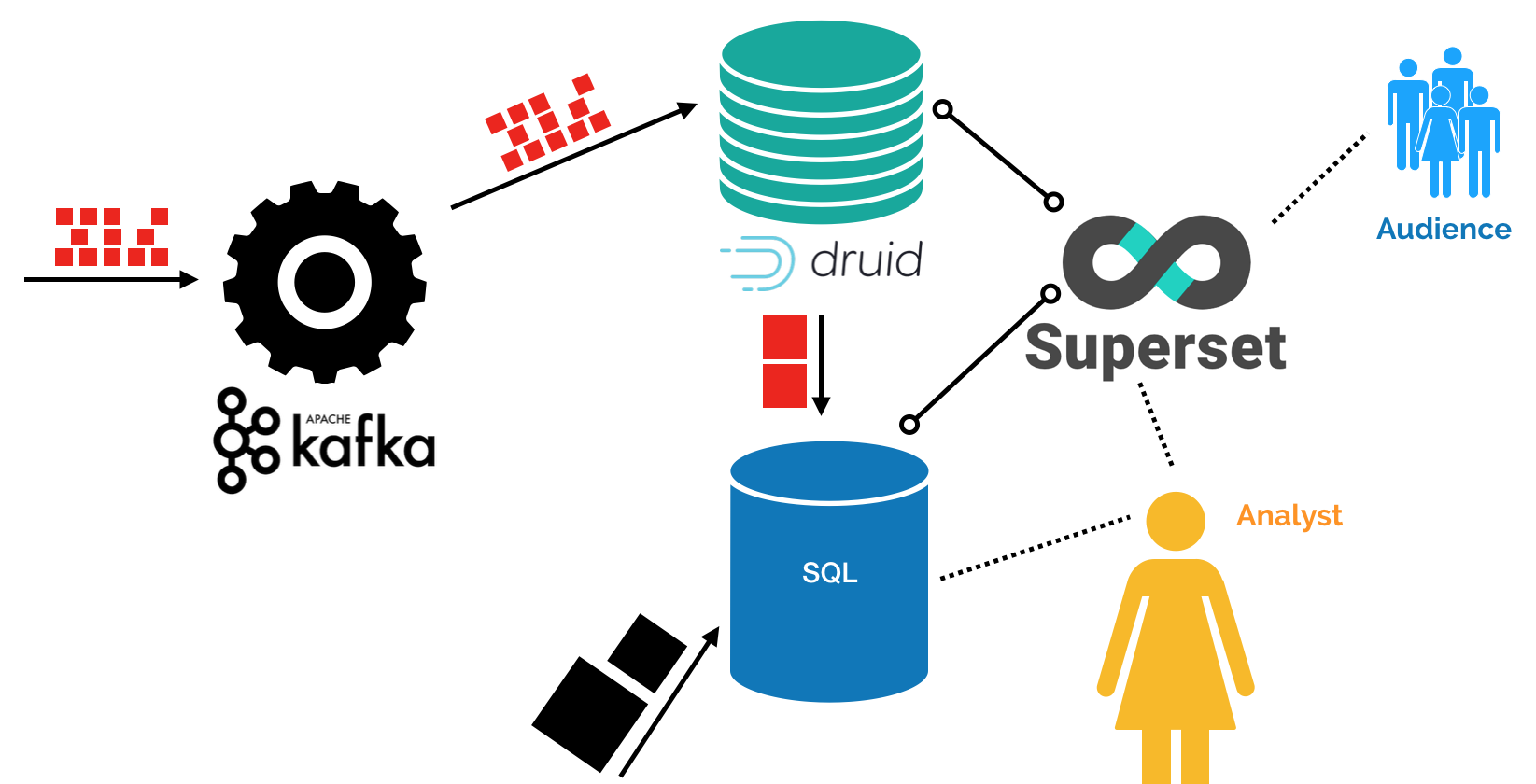
下载和启动 Kafka
Apache Kafka 是一个高吞吐量消息总线,可与 Druid 很好地配合使用。
在本指南中,我们将使用 Kafka 2.1.0 版本。下载 Kafka 后,在你的控制终端上运行下面的命令:
curl -O https://archive.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgz
tar -xzf kafka_2.12-2.1.0.tgz
cd kafka_2.12-2.1.0
如果你需要启动 Kafka broker,你需要通过控制台运行下面的命令:
./bin/kafka-server-start.sh config/server.properties
使用下面的命令在 Kafka 中创建一个称为 wikipedia 的主题,这个主题就是你需要将消息数据发送到的主题:
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wikipedia
需要注意的是,我们假设你的 Kafka 和 Druid 的 ZooKeeper 使用的是同一套 ZK。
















 3367
3367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











