







RNN for image caption
v1:只记录整体过程,没有数学推理过程,没有图,写的很随便,全凭刚做完cs231n-assignment3的RNN第一感觉写的
2017-12-31
具体的推导过程和一些细节,后边看心情再补吧
图示
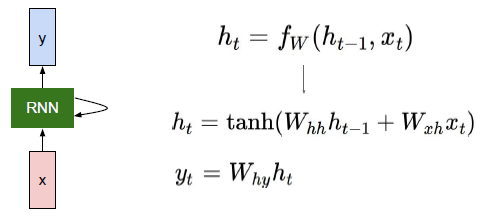
训练
输入
features
多来自卷积神经网络提取的图像特征,如AGG,GoogleNet等其他网络
captions
大多来自手动标注
训练过程
需要训练的变量:
Wxh, Whh, b, Why, bhy
- 与上图基本对应,不过上图把偏置b给省了
- 这些变量在RNN传播中的每一步是共用的
- 所以,这些变量的梯度变化,受每一步的共同影响
- 下边的对应关系:Wxh - Wx,Whh - Wh,b - b,Why - W_vocab, by - vocab
Word embedding matrix:W_emed
- 这是,词跟词向量对应的一个矩阵
- 这个矩阵也是要训练得到的,具体是什么,要跟训练集有关
- 一个图片对应的caption是由一个T维向量构成的,T维向量的每一个元素i,代表的词对应的词向量就是W_emed第i行代表的向量
正向传播
下面是一次输入N个数据集的一次前向传播过程,其中
1. features:NxH
2. caption:T维向量
3. caption_in = caption[0:T-1]
4. caption_out = caption[1:T]
整体框架
#首先对features,和caption进行处理,
#这个仿射变换affine_forward不是太理解,似乎只是多了一步,仿佛是避免让features直接作为输入输入到网络中,但暂时说不出为什么
h0,h0_cache = affine_forward(features, W_proj, b_proj)
#下面就是将每个caption_in中的单词变成词向量,T-1维变成T-1 x H维
#N个数据,就是 N x T-1 变成 N x T-1 x H维
data,word_cache = word_embedding_forward(captions_in,W_embed)#
#下边执行rnn的前向传播过程,再这个过程中,每一步都会有两个输出
#一个是对应的y,也就是这个位置对应的caption的单词,这也是loss的来源
#第二个是输出下一个时间应该接受的状态
hidden_states,cache_rnn_forward = rnn_forward(data,h0,Wx,Wh,b)
#下边两步就是计算损失
#最后输出的loss是损失,dx是 dloss/dscores 也就是loss相对于得分的梯度,是反向传播的起点
scores,cache_affine = temporal_affine_forward(hidden_states,W_vocab, b_vocab)
loss,dx = temporal_softmax_loss(scores, captions_out, mask, verbose=False)* rnn_forward(data,h0,Wx,Wh,b) *
如下图,再每个单元重复执行 rnn_step_forward(x, prev_h, Wx, Wh, b)
1. 其中x是由序列决定的,每次输入当前应该序列轮到的单词
2. prev_h是前一个单元的输出
3. Wx,Wh,b是每个单元公用的直接输入一序列的数据,返回每个隐藏层的状态
def rnn_step_forward(x, prev_h, Wx, Wh, b):
next_h = np.tanh(np.dot(x,Wx) + np.dot(prev_h,Wh) + b)
cache = (Wx, Wh, x,b, prev_h,next_h)
return next_h,cache反向传播
整体框架
流程基本就是正向传播过程每一步都反向来一遍
需要注意的是
1. 反向传播的起点为前向传播给出的dx
2. 由哪些是需要训练的,确定反向传播的终点
#
dhidden_states,grads['W_vocab'], grads['b_vocab'] = temporal_affine_backward(dx,cache_affine)
ddata,dh0,grads['Wx'],grads['Wh'],grads['b'] = rnn_backward(dhidden_states,cache_rnn_forward)
grads['W_embed'] = word_embedding_backward(ddata,word_cache)
_,grads['W_proj'],grads['b_proj'] = affine_backward(dh0,h0_cache)rnn_backward(data,h0,Wx,Wh,b)
如下图,基本是每个单元重复执行 rnn_step_backward(x, prev_h, Wx, Wh, b)
但要注意rnn_backward中dWx、dWh 、db是由每一步的梯度累加得到的,就像前边提到的一样
def rnn_backward(dh, cache):
Wx, Wh, x, b,prev_h ,next_h= cache[0]
#Wx, Wh, x, h0,h,b = cache[0]
N,T,H = np.shape(dh)
D,_ = Wx.shape
dx = np.zeros([N,T,D])
dprev_h = np.zeros_like(prev_h)
dWh = np.zeros_like(Wh)
dWx = np.zeros_like(Wx)
db = np.zeros_like(b)
for i in range(T)[-1::-1]:#dx[:,0,:] == d1
dnext_h = dprev_h + dh[:,i,:]
dx[:,i,:], dprev_h, dWxi, dWhi, dbi = rnn_step_backward(dnext_h, cache[i])
dnext_h = dh[:,i,:]
dWx = dWx + dWxi
dWh = dWh + dWhi
db = db + dbi
dh0 = dprev_h
return dx, dh0, dWx, dWh, db
def rnn_step_backward(dnext_h, cache):
dx, dprev_h, dWx, dWh, db = None, None, None, None, None
Wx, Wh, x, b,prev_h ,next_h= cache
der = 1.0 - next_h**2
middle = der*dnext_h
dx = middle.dot(Wx.T)
dprev_h = middle.dot(Wh.T)
dWx = x.T.dot(middle)
dWh = prev_h.T.dot(middle)
db = middle.sum(axis = 0)
return dx, dprev_h, dWx, dWh, db
测试过程
输入
基本流程就是将,正向传播的过程实现一边
但还有一些细节
后边补充吧















 670
670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









