









前一篇文章有说到对Md5加密算法的一些自我理解,Md5其实也算是哈希算法的一类;
哈希算法在日常编程中我们自身使用的其实不多,但是在一些中间件、源码上面它的应用范围其实是很广的,正好在写一个关于推荐平台AB实验分类的小case,有用到哈希算法,便展开一说,自我总结,天天向上!
一、说明
也称为散列算法数字指纹,是可以将任意长度的消息压缩为一个小的固定长度的二进制值算法。
常见哈希算法
- SHA1【过时】
- SHA2,一系列算法的统称,包括sha256等【SHA-1的延续,只是增加了复杂度】
- md5:现已不够安全
- 安全性:SHA-256比MD5更安全。MD5已经被证明存在碰撞攻击,即不同的输入可以生成相同的哈希值,从而导致安全问题。SHA-256则没有这个问题,目前还没有被证明存在碰撞攻击。
- 哈希值长度:SHA-256的哈希值长度为256位,比MD5的128位更长。这意味着SHA-256的哈希值空间更大,哈希冲突的可能性更小。
- 计算速度:MD5比SHA-256计算速度更快。但是,这并不意味着MD5更好,因为计算速度越快,越容易受到暴力破解和彩虹表攻击。
- 应用场景:SHA-256通常用于需要更高安全性的场景,如数字签名、密码学和区块链等,而MD5则适用于需要快速计算哈希值的场景,如文件完整性检查和密码验证等。
综上所述,SHA-256比MD5更安全,但计算速度可能稍慢。在选择哈希算法时,应根据实际应用场景和安全需求进行选择。
二、主要特点
1.固定长度输出:无论输入数据的长度如何,哈希算法都生成一个固定长度的输出。这种特性使得哈希算法适用于各种应用,如密码学、数据完整性验证等。【长度固定意味着用来结合取模算法,做负载定向会非常nice】
2.高效计算:哈希算法应该能够在合理的时间内计算出哈希值。这对于大规模数据集或实时应用非常关键。【很关键,这也是为什么很多场景会用到重点】
3.均匀分布:良好的哈希算法应该能够使不同的输入均匀地映射到哈希空间中,减小碰撞(多个不同输入映射到相同哈希值)的可能性。【比较吃key的分布,可能数据有倾斜】
4.不可逆性:一个好的哈希算法应该是单向的,即从哈希值无法逆向还原出原始输入数据。这是确保数据安全性和隐私的重要特性。【不可破解,密码验证和数字签名绝佳】
5.碰撞防御:碰撞是指两个不同的输入数据映射到相同的哈希值。好的哈希算法应该在实际应用中极小化碰撞的可能性,因为碰撞可能导致信息丢失或者不正确的操作。【结合散列表或者哈希表理解】
6.散列值的变动性:输入数据的微小变化应该导致哈希值的显著变化,这样可以防止故意构造冲突。【不可预测,也很关键】
关于哈希冲突【我自己补充延伸的】
哈希算法有一种数据结构:哈希表;
因为这个算法是将不限定长度的字符串===》定长的字符串;就意味着哈希冲突是哈希表中不可避免的问题,但通过合理的设计和处理方法,可以有效地管理和解决冲突,从而保持哈希表的高性能表现。
这位老哥写的比较全面:https://cloud.tencent.com/developer/article/2389650,我就不分心去CV占大篇幅了
拉链法
这种方法将所有关键字为同义词的结点链接在同一个单链表中。拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短。拉链法的优点还包括适合于造表前无法确定表长的情况,节省空间,且删除结点的操作易于实现。

再哈希法
同时构造多个不同的哈希函数,等发生哈希冲突时就使用第二个、第三个等其他的哈希函数计算地址,直到不发生冲突为止。虽然这种方法不易发生聚集,但是增加了计算时间。
建立公共溢出区将哈希表分为基本表和溢出表,将发生冲突的都存放在溢出表中。
开放地址法
这是一种解决哈希冲突的方法,它尝试在数组中寻找下一个可用的位置来存储冲突的键值对。具体的方法有线性探测、二次探测和双重哈希等。
三、使用场景
- 安全加密
哈希算法常用于加密用户密码,如MD5和SHA等哈希函数,因为它们是不可逆的,即使微小的区别也会导致加密结果差异很大,从而提供较好的安全性。这种特性使得哈希算法成为密码存储和验证的理想选择。 - 唯一标识
哈希算法可以将数据(如URL字段或图片字段)转换为固定长度的唯一标识,用于数据库索引构建和查询,以及作为文件的唯一标识,便于快速检索和判定重复文件。 - 数据校验
哈希算法对输入数据非常敏感,即使原始数据只修改了一个Bit,最后的哈希值也会大不相同。这一特性使得哈希算法非常适合用于校验数据的完整性,避免数据在中途被篡改。 - 散列函数
哈希算法在散列函数中的应用关注于散列后的值能否平均分布以及散列函数的执行速度。这种应用场景要求哈希算法能够快速计算散列值,同时确保不同的原始数据得到不同的哈希值。 - 负载均衡
通过哈希算法可以将用户的会话请求路由到同一台机器,以保证数据的一致性。这可以通过用户ID尾号对总机器数取模来实现,将结果值作为机器编号。 - 分布式缓存
哈希算法也用于实现分布式缓存系统中的负载均衡和数据一致性,通过特定的哈希函数将数据分散存储在不同的缓存节点上,提高系统的可扩展性和性能。
再来点实际的使用场景: - md5 之类的哈希函数
- 分库、分表时,使用某个字段的 hash 值对固定数值取模,来确定对应库表
- 一个大量数据的集合,根据某个字段作为拆分键,对数据进行打散处理
- PHP的 HashTable、Go的 map、Python 的 dict 等数据结构实现
- Redis 分片时使用 crc16 对key进行哈希,然后对 16384 取模来确定分片
四、算法增强
通过上面的描述大家伙应该知道这个算法的特性;运算快、不可逆、固定长度是非常突出的优点,被广泛用于做分布式环境下的一些应用,比如负载均衡、批数据存储寻址;
但是它有在某些场景下,有一个很严重的问题。
假设有这么一种场景:我们有三台缓存服务器分别为:node0、node1、node2,有3000万个缓存数据需要存储在这三台服务器组成的集群中,希望可以将这些数据均匀的缓存到三台机器上,你会想到什么方案呢?
我们可能首先想到的方案是:取模算法hash(key)%N,即:对缓存数据的key进行hash运算后取模,N是机器的数量;运算后的结果映射对应集群中的节点。具体如下图所示:
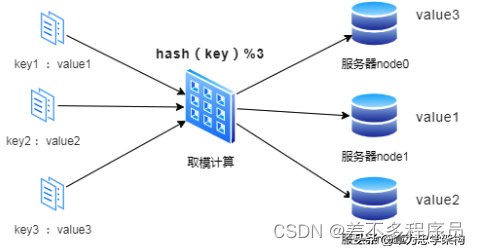
如上图所示,首先对key进行hash计算后的结果对3取模,得到的结果一定是0、1或者2;然后映射对应的服务器node0、node1、node2,最后直接找对应的服务器存取数据即可。看起来很完美!
【问题一】但是,在分布式集群系统的负载均衡实现上,这种模型在集群扩容和收缩时却有一定的局限性:因为在生产环境中根据业务量的大小,调整服务器数量是常有的事,如果N发生变化,那岂不是之前的规则全部都乱套了;
【问题二】如果在某个业务规则下,我生成的key,在通过hash运算后,就是会不均匀的分布,如果这个情况达到了极致,那是不是意味着生产资料的浪费;
因此有人提出了下面的这个概念!
一致性哈希
一致性哈希(Consistent Hash)算法是1997年提出,是一种特殊的哈希算法,目的是解决分布式系统的数据分区问题:当分布式集群移除或者添加一个服务器时,必须尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对K/n 个关键字重新映射,其中 K是关键字的数量,n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
一致性哈希算法本质上也是一种取模算法。只不过前面介绍的取模算法是按服务器数量取模,而一致性哈希算法是对固定值2^32取模,这就使得一致性算法具备良好的单调性:不管集群中有多少个节点,只要key值固定,那所请求的服务器节点也同样是固定的。其算法的工作原理如下:
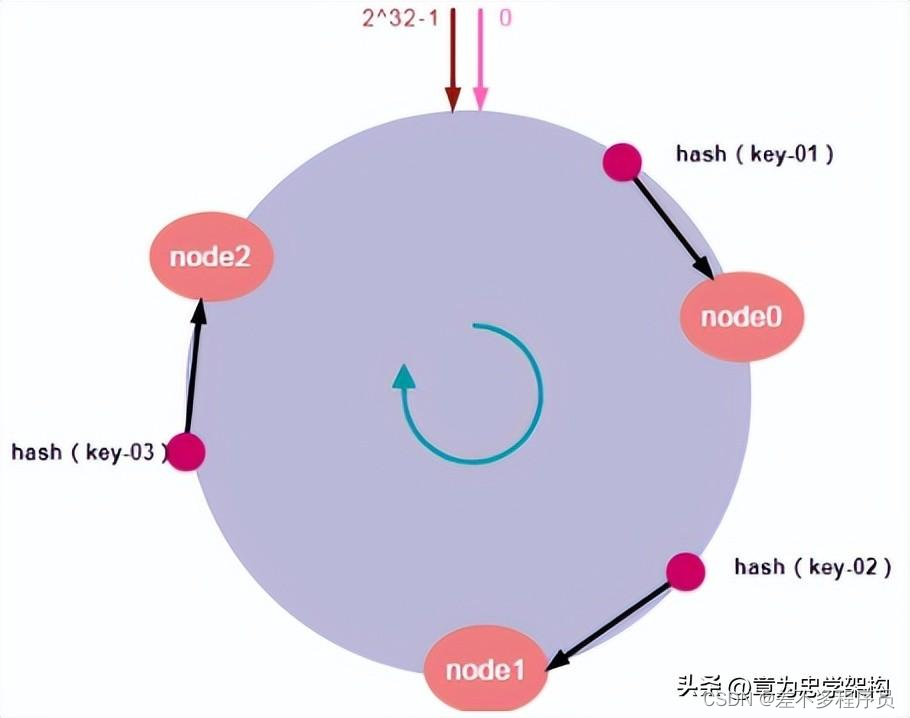
- 一致性哈希算法将整个哈希值空间映射成一个虚拟的圆环,整个哈希空间取值范围为0~2^32-1;
- 计算各服务器节点的哈希值,并映射到哈希环上;
- 将服务发来的数据请求使用哈希算法算出对应的哈希值;
- 将计算的哈希值映射到哈希环上,同时沿圆环顺时针方向查找,遇到的第一台服务器就是所对应的处理请求服务器。
- 当增加或者删除一台服务器时,受影响的数据仅仅是新添加或删除的服务器到其环空间中前一台的服务器(也就是顺着逆时针方向遇到的第一台服务器)之间的数据,其他都不会受到影响。
1.哈希环[扩缩容]
假设我们有“key-01:张三”、“key-02:李四”、“key-03:王五”三条缓存数据。经过哈希算法计算后,映射到哈希环上的位置如下图所示:
服务器缩容
服务器缩容就是减少集群中服务器节点的数量或是集群中某个节点的故障。假设,集群中的某个节点故障,原本映射到该节点的请求,会找到哈希环中的下一个节点,数据也同样被重新分配至下一个节点,其它节点的数据和请求不受任何影响。这样就确保节点发生故障时,集群能保持正常稳定。如下图所示:
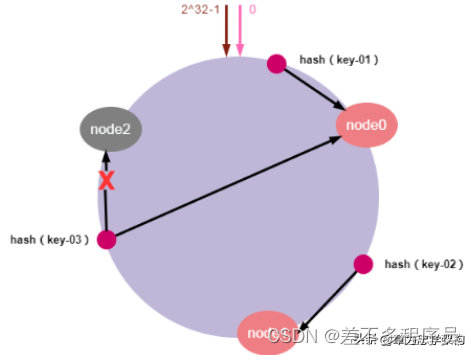
如上图所示:节点node2发生故障时,数据key-01和key-02不会受到影响,只有key-03的请求被重定位到node0。在一致性哈希算法中,如果某个节点宕机不可用了,那么受影响的数据仅仅是会寻址到此节点和前一节点之间的数据。其他哈希环上的数据不会受到影响。
服务器扩容
服务器扩容就是集群中需要增加一个新的数据节点,假设,由于需要缓存的数据量太大,必须对集群进行扩容增加一个新的数据节点。此时,只需要计算新节点的哈希值并将新的节点加入到哈希环中,然后将哈希环中从上一个节点到新节点的数据映射到新的数据节点即可。其他节点数据不受影响,具体如下图所示:
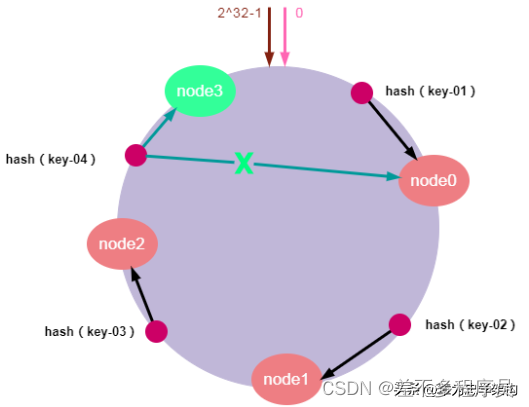
如上图所示,加入新的node3节点后,key-01、key-02不受影响,只有key-03的寻址被重定位到新节点node3,受影响的数据仅仅是会寻址到新节点和前一节点之间的数据。
2.虚拟节点[数据倾斜]
前面说了一致性哈希算法的原理以及扩容缩容的问题。但是,由于哈希计算的随机性,导致一致性哈希算法存在一个致命问题:数据倾斜,,也就是说大多数访问请求都会集中少量几个节点的情况。特别是节点太少的情况下,容易因为节点分布不均匀造成数据访问的冷热不均。这就失去了集群和负载均衡的意义。如下图所示:
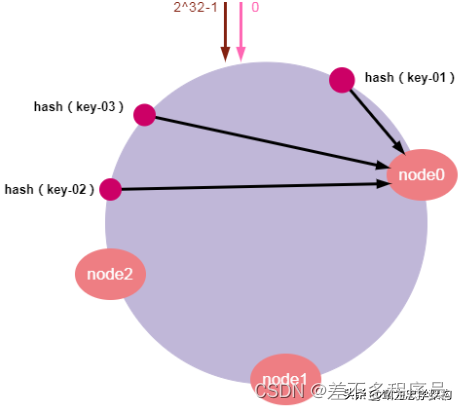
如上图所示,key-1、key-2、key-3可能被映射到同一个节点node0上。导致node0负载过大,而node1和node2却很空闲的情况。这有可能导致个别服务器数据和请求压力过大和崩溃,进而引起集群的崩溃。
为了解决数据倾斜的问题,一致性哈希算法引入了虚拟节点机制,即对每一个物理服务节点映射多个虚拟节点,将这些虚拟节点计算哈希值并映射到哈希环上,当请求找到某个虚拟节点后,将被重新映射到具体的物理节点。虚拟节点越多,哈希环上的节点就越多,数据分布就越均匀,从而避免了数据倾斜的问题。
说起来可能比较复杂,一句话概括起来就是:原有的节点、数据定位的哈希算法不变,只是多了一步虚拟节点到实际节点的映射。具体如下图所示:
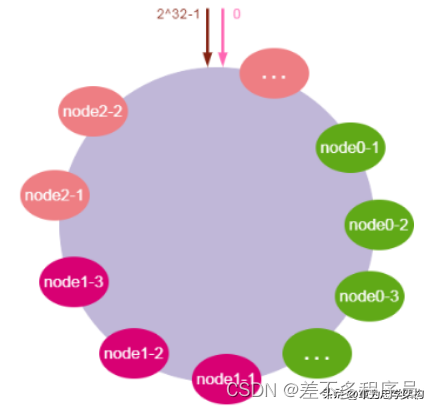
3.实战
代码
参照头条哥们的case,我自己优化了一下它的测试案例case
import java.util.*;
public class ConsistentHash {
private final TreeMap<Integer, Node> hashRing = new TreeMap<>();
public List<Node> nodeList = new ArrayList<>();
/**
* 增加节点
* 每增加一个节点,就会在闭环上增加给定虚拟节点
* 例如虚拟节点数是2,则每调用此方法一次,增加两个虚拟节点,这两个节点指向同一Node
*/
public void addNode(String ip) {
Objects.requireNonNull(ip);
Node node = new Node(ip);
nodeList.add(node);
for (Integer virtualNodeHash : node.getVirtualNodeHashes()) {
hashRing.put(virtualNodeHash, node);
System.out.println("虚拟节点hash [" + virtualNodeHash + "] 对应节点=》" + node + ",被添加");
}
}
/**
* 移除节点
*/
public void removeNode(Node node) {
nodeList.remove(node);
}
/**
* 获取缓存数据
* 先找到对应的虚拟节点,然后映射到物理节点
*/
public Object get(Object key) {
Node node = findMatchNode(key);
System.out.println("获取到节点:" + node.getIp());
return node.getCacheItem(key);
}
/**
* 添加缓存
* 先找到hash环上的节点,然后在对应的节点上添加数据缓存
*/
public void put(Object key, Object value) {
Node node = findMatchNode(key);
node.addCacheItem(key, value);
}
/**
* 删除缓存数据
*/
public void evict(Object key) {
findMatchNode(key).removeCacheItem(key);
}
/**
* 获得一个最近的顺时针节点
*
* @param key 为给定键取Hash,取得顺时针方向上最近的一个虚拟节点对应的实际节点
* @return 节点对象
*/
private Node findMatchNode(Object key) {
Map.Entry<Integer, Node> entry = hashRing.ceilingEntry(HashUtils.hashcode(key));
if (entry == null) {
entry = hashRing.firstEntry();
}
return entry.getValue();
}
public void printNodeInfo() {
System.out.println("====================================节点信息====================================");
int total = 0;
for (Node node : this.nodeList) {
int size = node.getCacheMap().keySet().size();
System.out.println(String.format("节点:%s,挂载的虚拟节点:%s,缓存数据量:%s", node.getIp(), node.getVirtualNodeHashes(), size));
total += size;
}
System.out.println("缓存的key总数total=" + total);
System.out.println("====================================节点信息====================================");
}
}
import org.apache.commons.lang.RandomStringUtils;
import org.apache.commons.lang3.RandomUtils;
import javax.swing.*;
import java.util.ArrayList;
import java.util.List;
/**
* @author liulei44
* @date 2024/6/27 10:19 PM
*/
public class ConsistentHashTest {
public static final int CACHE_DATA_SIZE = 100 * 100;
/**
* 模拟要缓存的数据
*/
public static List<String> initCacheData(int size) {
List<String> cacheDataList = new ArrayList<>();
for (int i = 0; i < size; i++) {
cacheDataList.add(RandomStringUtils.randomAlphanumeric(10));
}
return cacheDataList;
}
public static void main(String[] args) {
ConsistentHash consistentHash = new ConsistentHash();
// 初始化10台机器&虚拟节点
for (int i = 0; i < 5; i++) {
String ip = "10.2.1." + i;
consistentHash.addNode(ip);
}
// 构建缓存数据集
List<String> cacheDataList = initCacheData(CACHE_DATA_SIZE);
// 将数据放入到缓存中
for (String cacheData : cacheDataList) {
consistentHash.put(cacheData, cacheData);// 为了印证哈希一致性,value是和key一样的,这样好方便下面的测试
}
System.out.println("====================================一致性哈希寻址查值start====================================");
// 存入缓存之后,为了印证哈希算法寻址机器后的value,做个小实验
for (int i = 0; i < 10; i++) {
int index = RandomUtils.nextInt(0, CACHE_DATA_SIZE);
String key = cacheDataList.get(index);
String cache = (String) consistentHash.get(key);
System.out.println("随机索引:" + index + ",key:" + key + ",通过一致性哈希缓存找节点查value=:" + cache + ",value is:" + key.equals(cache));
}
System.out.println("====================================一致性哈希寻址查值end====================================");
// 输出节点及数据分布情况
consistentHash.printNodeInfo();
// 新增一个数据节点
for (String key : cacheDataList) {
consistentHash.evict(key);
}
consistentHash.addNode("10.2.1.10");
consistentHash.printNodeInfo();
// 重新往节点中存放同一批批数据缓存
for (String cacheData : cacheDataList) {
consistentHash.put(cacheData, cacheData);// 为了印证哈希一致性,value是和key一样的,这样好方便下面的测试
}
// 输出节点及数据分布情况
consistentHash.printNodeInfo();
}
}
import lombok.Data;
import java.util.*;
@Data
public class Node {
/**
* 引入虚拟节点数,解决数据倾斜的问题,虚拟节点数越多,分布约均匀
*/
private static final int VIRTUAL_NODE_NO_PER_NODE = 10;
private final List<Integer> virtualNodeHashes = new ArrayList<>(VIRTUAL_NODE_NO_PER_NODE);// 防止重复扩容,先设置size
private final String ip;
private final Map<Object, Object> cacheMap = new HashMap<>();
public Node(String ip) {
this.ip = ip;
// 挂载映射到N个虚拟节点
for (int i = 1; i <= VIRTUAL_NODE_NO_PER_NODE; i++) {
String virtualNodeKey = ip + "#" + i;
virtualNodeHashes.add(HashUtils.hashcode(virtualNodeKey));
}
}
public void addCacheItem(Object key, Object value) {
cacheMap.put(key, value);
}
public Object getCacheItem(Object key) {
return cacheMap.get(key);
}
public void removeCacheItem(Object key) {
cacheMap.remove(key);
}
}
public class HashUtils {
/**
* hashCode方法
*/
public static int hashcode(Object obj) {
final int p = 16777619;
int hash = (int) 2166136261L;
String str = obj.toString();
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
}
分析
# 1.第一部分是初始化node,每个node挂载3台虚拟节点
虚拟节点hash [1328444476] 对应节点=》Node(virtualNodeHashes=[1328444476, 952131643, 728714740], ip=10.2.1.0, cacheMap={}),被添加
虚拟节点hash [952131643] 对应节点=》Node(virtualNodeHashes=[1328444476, 952131643, 728714740], ip=10.2.1.0, cacheMap={}),被添加
虚拟节点hash [728714740] 对应节点=》Node(virtualNodeHashes=[1328444476, 952131643, 728714740], ip=10.2.1.0, cacheMap={}),被添加
虚拟节点hash [292893685] 对应节点=》Node(virtualNodeHashes=[292893685, 327940484, 1288580913], ip=10.2.1.1, cacheMap={}),被添加
虚拟节点hash [327940484] 对应节点=》Node(virtualNodeHashes=[292893685, 327940484, 1288580913], ip=10.2.1.1, cacheMap={}),被添加
虚拟节点hash [1288580913] 对应节点=》Node(virtualNodeHashes=[292893685, 327940484, 1288580913], ip=10.2.1.1, cacheMap={}),被添加
虚拟节点hash [360317284] 对应节点=》Node(virtualNodeHashes=[360317284, 1538822281, 569949424], ip=10.2.1.2, cacheMap={}),被添加
虚拟节点hash [1538822281] 对应节点=》Node(virtualNodeHashes=[360317284, 1538822281, 569949424], ip=10.2.1.2, cacheMap={}),被添加
虚拟节点hash [569949424] 对应节点=》Node(virtualNodeHashes=[360317284, 1538822281, 569949424], ip=10.2.1.2, cacheMap={}),被添加
虚拟节点hash [2142680936] 对应节点=》Node(virtualNodeHashes=[2142680936, 626304301, 373514199], ip=10.2.1.3, cacheMap={}),被添加
虚拟节点hash [626304301] 对应节点=》Node(virtualNodeHashes=[2142680936, 626304301, 373514199], ip=10.2.1.3, cacheMap={}),被添加
虚拟节点hash [373514199] 对应节点=》Node(virtualNodeHashes=[2142680936, 626304301, 373514199], ip=10.2.1.3, cacheMap={}),被添加
虚拟节点hash [829814731] 对应节点=》Node(virtualNodeHashes=[829814731, 1697728925, 1872754321], ip=10.2.1.4, cacheMap={}),被添加
虚拟节点hash [1697728925] 对应节点=》Node(virtualNodeHashes=[829814731, 1697728925, 1872754321], ip=10.2.1.4, cacheMap={}),被添加
虚拟节点hash [1872754321] 对应节点=》Node(virtualNodeHashes=[829814731, 1697728925, 1872754321], ip=10.2.1.4, cacheMap={}),被添加
# 2.做一个缓存的寻址查找case测试,验证逻辑
====================================一致性哈希寻址查值start====================================
获取到节点:10.2.1.1
随机索引:8055,key:YMwu46a4v6,通过一致性哈希缓存找节点查value=:YMwu46a4v6,value is:true
获取到节点:10.2.1.3
随机索引:2413,key:dYhHsnJJDn,通过一致性哈希缓存找节点查value=:dYhHsnJJDn,value is:true
获取到节点:10.2.1.2
随机索引:7240,key:DQcqqi69ZT,通过一致性哈希缓存找节点查value=:DQcqqi69ZT,value is:true
获取到节点:10.2.1.0
随机索引:7798,key:qFcaTXDUoq,通过一致性哈希缓存找节点查value=:qFcaTXDUoq,value is:true
获取到节点:10.2.1.4
随机索引:9432,key:lzMfgqPlu0,通过一致性哈希缓存找节点查value=:lzMfgqPlu0,value is:true
获取到节点:10.2.1.1
随机索引:3699,key:MeTjZqevEL,通过一致性哈希缓存找节点查value=:MeTjZqevEL,value is:true
获取到节点:10.2.1.1
随机索引:4490,key:7lRSZZ067B,通过一致性哈希缓存找节点查value=:7lRSZZ067B,value is:true
获取到节点:10.2.1.1
随机索引:5416,key:dIqqTN8Y75,通过一致性哈希缓存找节点查value=:dIqqTN8Y75,value is:true
获取到节点:10.2.1.4
随机索引:5865,key:UDovc5wA2O,通过一致性哈希缓存找节点查value=:UDovc5wA2O,value is:true
获取到节点:10.2.1.2
随机索引:4907,key:XfohoFJGma,通过一致性哈希缓存找节点查value=:XfohoFJGma,value is:true
====================================一致性哈希寻址查值end====================================
# 3.输出看下缓存分布在节点的情况
====================================节点信息====================================
节点:10.2.1.0,挂载的虚拟节点:[1328444476, 952131643, 728714740],缓存数据量:1224
节点:10.2.1.1,挂载的虚拟节点:[292893685, 327940484, 1288580913],缓存数据量:3049
节点:10.2.1.2,挂载的虚拟节点:[360317284, 1538822281, 569949424],缓存数据量:2116
节点:10.2.1.3,挂载的虚拟节点:[2142680936, 626304301, 373514199],缓存数据量:1605
节点:10.2.1.4,挂载的虚拟节点:[829814731, 1697728925, 1872754321],缓存数据量:2006
缓存的key总数total=10000
====================================节点信息====================================
# 4.新增一台机器【记得提前清空之前所有节点的缓存】
虚拟节点hash [1634120015] 对应节点=》Node(virtualNodeHashes=[1634120015, 1745651496, 1781834268], ip=10.2.1.10, cacheMap={}),被添加
虚拟节点hash [1745651496] 对应节点=》Node(virtualNodeHashes=[1634120015, 1745651496, 1781834268], ip=10.2.1.10, cacheMap={}),被添加
虚拟节点hash [1781834268] 对应节点=》Node(virtualNodeHashes=[1634120015, 1745651496, 1781834268], ip=10.2.1.10, cacheMap={}),被添加
# 4.看一下节点的缓存情况,验证清空逻辑正常
====================================节点信息====================================
节点:10.2.1.0,挂载的虚拟节点:[1328444476, 952131643, 728714740],缓存数据量:0
节点:10.2.1.1,挂载的虚拟节点:[292893685, 327940484, 1288580913],缓存数据量:0
节点:10.2.1.2,挂载的虚拟节点:[360317284, 1538822281, 569949424],缓存数据量:0
节点:10.2.1.3,挂载的虚拟节点:[2142680936, 626304301, 373514199],缓存数据量:0
节点:10.2.1.4,挂载的虚拟节点:[829814731, 1697728925, 1872754321],缓存数据量:0
节点:10.2.1.10,挂载的虚拟节点:[1634120015, 1745651496, 1781834268],缓存数据量:0
缓存的key总数total=0
====================================节点信息====================================
# 5.再次对相同的缓存数据进行存储,观察数据变化
====================================节点信息====================================
节点:10.2.1.0,挂载的虚拟节点:[1328444476, 952131643, 728714740],缓存数据量:1224
节点:10.2.1.1,挂载的虚拟节点:[292893685, 327940484, 1288580913],缓存数据量:3049
节点:10.2.1.2,挂载的虚拟节点:[360317284, 1538822281, 569949424],缓存数据量:2116
节点:10.2.1.3,挂载的虚拟节点:[2142680936, 626304301, 373514199],缓存数据量:1605
节点:10.2.1.4,挂载的虚拟节点:[829814731, 1697728925, 1872754321],缓存数据量:1173
节点:10.2.1.10,挂载的虚拟节点:[1634120015, 1745651496, 1781834268],缓存数据量:833
缓存的key总数total=10000
====================================节点信息====================================
可以很明显的看到,新增的节点【10.2.1.10】这台机器在加入集群后,其他机器的变化情况,基本上只是变动了两台节点的存储数据个数,这就意味着和我们前面说的哈希环的顺时针寻址逻辑是契合的
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性 。
总结
- 哈希算法和一致性哈希,不是一回事儿
- TreeMap 的 ceilingEntry 方法的作用是在 TreeMap 中找到大于或等于指定键值的最小键值对,使用它可以模拟哈希环
- 如果构建了虚拟节点,其实投射到哈希环上的哈希值,都是虚拟节点的哈希值,只不过每个虚拟节点的指向性是一个真实的Node机器,但是这样不妨碍它确实是让数据分布变得更均匀
- 虚拟节点个数挂载的越多,数据分布越均衡,大家可以试一下改一下值,我代码里面设置的是3
- 要感谢头条作者【章为忠学架构】和其他平台的作者,有你们的资料让我更加深刻理解了哈希算法
- 扩缩容的机制,结合着哈希环和虚拟节点的逻辑,如果再增加节点或缩减节点之前,加一些作料,比如数据同步,这会不会中间件的工作模式理解,又更近了一些,且待我后面持续的探究一下
参考文档
- https://cloud.tencent.com/developer/article/1700335
- https://www.toutiao.com/article/7167302615553065511/?app=news_article×tamp=1719492225&use_new_style=1&req_id=202406272043442725118A33FD6026A1D1&group_id=7167302615553065511&share_token=E647A466-F88B-4B8B-A486-AAA9761B2E8B&tt_from=weixin&utm_source=weixin&utm_medium=toutiao_ios&utm_campaign=client_share&wxshare_count=1&source=m_redirect
- https://answer.baidu.com/answer/land?params=n4JUBdfsY0jSEU4yVMWKjzj8PGyWFbrRbEMqbvCONnwSiYZlJ2%2F7V5Jn%2FZfx3w5VSwS%2BBAHr9ChlLwpfJ151%2FX4M3t397f%2FECTNkFqF33bbYUWcWJHASi7LQjx5x2TS%2F4GR5BNDOrlJldoGH0wiUTQ6r%2F3iZZZ1GamRtO0r%2FS1qhYCEVaGTjFks3QK5NK%2F%2FYBYvQf4TvaYKU%2Fd4GiduyA%2FKaFyCMfb2aSFUmrgIEi8g%3D&from=dqa&lid=f9607b5f00068ea1&word=%E5%93%88%E5%B8%8C%E5%86%B2%E7%AA%81%E7%9A%84%E5%8E%9F%E5%9B%A0%E5%92%8C%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95
- https://www.51cto.com/article/682288.html
- https://cloud.tencent.com/developer/article/2389650
- https://blog.csdn.net/bigger_belief/article/details/130644170















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









