







当我们说 chunked_pooling_enabled=True 时,并不是把多个 chunk 的“原始文本”合并成一个长文档,而是:
将每个 chunk 的“语义向量”合并成一个最终文档的“语义表示向量”。
📦 什么是 chunk?
设想你有一篇 4000 个 token 的文章,但你的模型最多只能处理 512 个 token,那么你得把文章切成多个小段(chunk):
- chunk 1:前 512 个 token
- chunk 2:第 256 ~ 768(带重叠)
- chunk 3:第 512 ~ 1024
…
这些 chunk 只是从原始文档中截取的片段,每个 chunk 都能独立送入模型去获取“向量表示”。
📐 什么是“语义表示向量”?
每个 chunk 输入到模型后,比如一个 BERT/Transformer 模型,会输出一个向量,比如:
chunk1_embedding = [0.1, 0.2, 0.3, ..., 0.7] # 长度是比如768维
chunk2_embedding = [0.4, 0.3, 0.2, ..., 0.5]
...
这些向量表示的是 chunk 的“语义特征”。
✅ 什么是 “chunked_pooling”?
chunked_pooling 的目的就是:
把多个 chunk 的 embedding 合成为一个“代表整个文档”的 embedding 向量,这样就可以让这个向量和 query 做匹配、排序、打分。
🔧 合成方法有很多种,比如:
| 合成方法 | 含义 | 举例 |
|---|---|---|
| avg pooling | 对每个维度取平均 | [0.1+0.4]/2 = 0.25 |
| max pooling | 每个维度取最大值 | max(0.1, 0.4) = 0.4 |
| attention pooling | 加权平均,重要的 chunk 权重高 | 根据模型打分加权 |
| MLP 聚合 | 通过神经网络学习合适的聚合方式 | 可训练的方式 |
这样就能从多个 [chunk1_embedding, chunk2_embedding, ..., chunkN_embedding]
生成一个最终的 document_embedding。
🤖 举个完整例子
原文档内容:
这是一篇关于人工智能的长文档,分为多个部分:
第一部分讲了ChatGPT的架构;
第二部分讲了Transformer的机制;
第三部分讲了如何应用到医疗;
...
被拆成 3 个 chunk → 送入模型:
| Chunk | 模型向量(简化) |
|---|---|
| C1 | [0.1, 0.2, 0.3] |
| C2 | [0.4, 0.1, 0.6] |
| C3 | [0.3, 0.5, 0.2] |
用 avg_pooling 合成:
document_embedding = avg([C1, C2, C3])
= [ (0.1+0.4+0.3)/3, (0.2+0.1+0.5)/3, (0.3+0.6+0.2)/3 ]
= [0.266, 0.266, 0.366]
这个最终的向量,就代表了整篇文档的语义特征,可用于与查询匹配。
🚫 那么可以直接合成原始 chunk 文本回原文档吗?
不能(或者说不推荐):
- chunk 之间有信息丢失和重叠,不能保证顺序和语义完整;
- 主要任务是“检索”而非“重构”,我们关心的是语义向量是否能代表整篇文档;
- 如果你合并文本再重新送入模型处理,很可能超出模型长度限制。
✅ 总结
| 问题 | 回答 |
|---|---|
| 能否把多个 chunk 合成一个文档? | 文本上不能可靠合并;语义向量可以合并成一个文档表示 |
| chunked_pooling_enabled=True 是干什么的? | 合并多个 chunk 的向量,代表整篇文档 |
| 为什么需要? | 因为单个 chunk 只看一部分内容,合并后能代表整篇文章 |
| 怎么合并? | avg、max、attention 等方式 |
演示 chunk pooling 的实际代码
import numpy as np
import matplotlib.pyplot as plt
# 模拟三个 chunk 的 embedding(每个向量长度为 3)
chunk_embeddings = np.array([
[0.1, 0.2, 0.3], # Chunk 1
[0.4, 0.1, 0.6], # Chunk 2
[0.3, 0.5, 0.2], # Chunk 3
])
# 平均池化 (avg pooling)
avg_pooling = np.mean(chunk_embeddings, axis=0)
# 最大池化 (max pooling)
max_pooling = np.max(chunk_embeddings, axis=0)
# 绘图:展示每个 chunk 向量 + 聚合结果
x = np.arange(len(avg_pooling))
bar_width = 0.2
fig, ax = plt.subplots(figsize=(10, 6))
ax.bar(x - bar_width*1.5, chunk_embeddings[0], width=bar_width, label='Chunk 1')
ax.bar(x - bar_width*0.5, chunk_embeddings[1], width=bar_width, label='Chunk 2')
ax.bar(x + bar_width*0.5, chunk_embeddings[2], width=bar_width, label='Chunk 3')
ax.bar(x + bar_width*1.5, avg_pooling, width=bar_width, label='Avg Pooling', color='orange')
ax.bar(x + bar_width*2.5, max_pooling, width=bar_width, label='Max Pooling', color='green')
ax.set_xlabel('Embedding Dimension')
ax.set_ylabel('Value')
ax.set_title('Chunk Pooling Visualization')
ax.legend()
ax.grid(True)
plt.tight_layout()
plt.show()
结果:
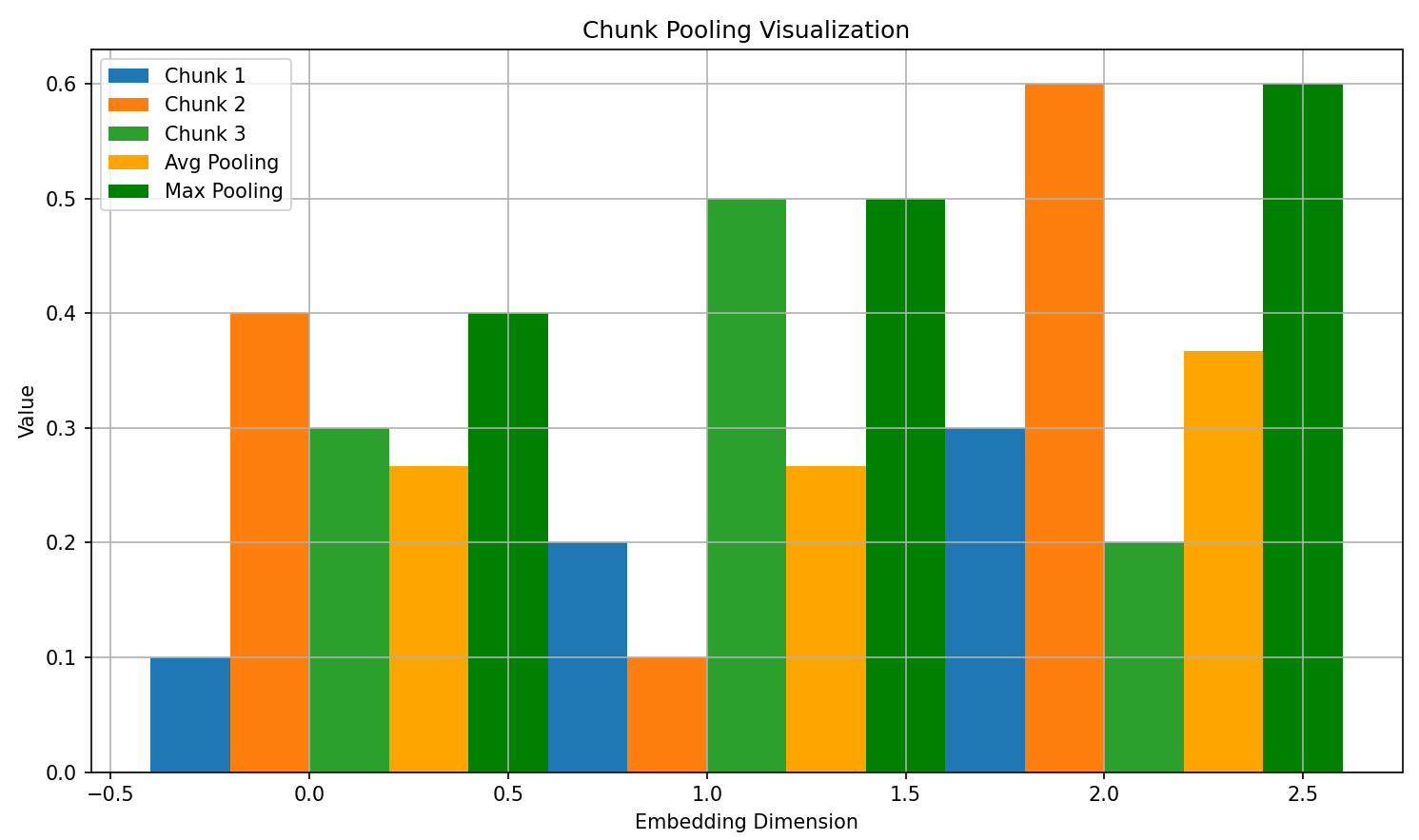
3 组柱状图:
-
分别表示 3 个不同 chunk 的向量(Chunk 1、Chunk 2、Chunk 3),表示不同位置的向量值;
-
右侧的橙色柱状图:表示通过 平均池化 得到的文档整体向量;
-
右侧的绿色柱状图:表示通过 最大池化 得到的文档整体向量;
通俗解释
假设一个文档被分成三段(chunk),每段经过模型处理后得到了一个向量表示:
Chunk 1 = [0.1, 0.2, 0.3]
Chunk 2 = [0.4, 0.1, 0.6]
Chunk 3 = [0.3, 0.5, 0.2]
平均池化:
把同一维度的值加起来取平均,例如第一维是:
(0.1 + 0.4 + 0.3) / 3 = 0.2667
这样得到的新向量是这个文档的“总体表示”。
最大池化:
选择每一维上最大的那个值,比如:
max(0.1, 0.4, 0.3) = 0.4
max(0.2, 0.1, 0.5) = 0.5
max(0.3, 0.6, 0.2) = 0.6
也可以看作是:用每一维中“最显著”的特征来代表整个文档。
总结
“将多个 chunk 合成一个文档表示向量”,就是通过这些策略(平均池化、最大池化等)将多个小段向量整合成一个“能代表整篇文档”的大向量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









