







一、环境说明:
jdk version :1.6
Hadoop version : 1.1.2
模式:伪分布模式
Linux环境:Centos 6.4
HDFS文件目录结构: / /home /user /user/root
二、实现流程
1.启动hadoop并查看相应进程是否启动
①start-all.sh ——启动hadoop
终端输出以下信息:
starting namenode, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-namenode-hadoop1.out
localhost: starting datanode, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-datanode-hadoop1.out
localhost: starting secondarynamenode, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-secondarynamenode-hadoop1.out
starting jobtracker, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-jobtracker-hadoop1.out
localhost: starting tasktracker, logging to /usr/local/hadoop/libexec/../logs/hadoop-root-tasktracker-hadoop1.out
说明hadoop已成功启动
②jps ——查看相应的进程是否全部启动
2958 TaskTracker
3130 Jps
2838 JobTracker
2645 DataNode
2549 NameNode
2755 SecondaryNameNode
说明所有的进程都已成功启动
2.Streaming实现WordCount
执行以下命令:
bin/hadoop jar contrib/streaming/hadoop-streaming-1.1.2.jar -input /user/root/inputdir -output output -mapper /bin/cat -reducer /usr/bin/wc
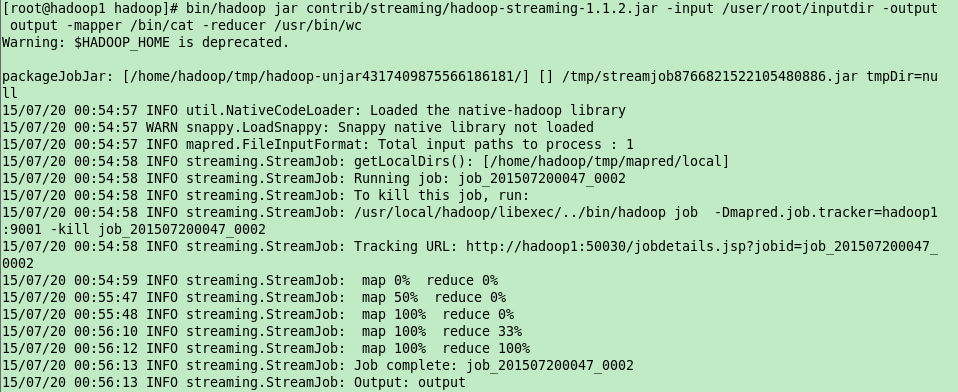
输入文件夹的目录结构如下(hadoop fs -ls /user/root/inputdir):
-rw-r–r– 1 root supergroup 37667 2015-07-17 23:25 /user/root/inputdir/install.log
输出文件夹的目录结构如下(hadoop fs -ls /user/root/output):
-rw-r–r– 1 root supergroup 0 2015-07-20 00:56 /user/root/output/_SUCCESS
drwxr-xr-x - root supergroup 0 2015-07-20 00:54 /user/root/output/_logs
-rw-r–r– 1 root supergroup 25 2015-07-20 00:56 /user/root/output/part-00000
part-00000的内容如下(hadoop fs -cat /user/root/output/part-00000):
873 1757 38541
分别对应文件中
行数 字数(单词数) 字节数















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









