







摘要
本文深入探讨了AI幻觉现象,即大模型在处理超出其知识范围的问题时产生的错误或误导性回答。文章分析了AI幻觉带来的挑战与影响,并介绍了两种主要的解决方案:模型微调和检索增强生成(RAG)。重点对RAG技术进行了详细剖析,包括其原理、实现过程以及Embedding模型在其中的关键作用。通过本文的阐述,读者可以深入了解RAG技术如何解决AI幻觉问题,并展望其在未来AI领域中的应用前景。
一、AI幻觉的缘起
自2024年以来,大模型/AI/人工智能的广泛应用在各生产环节中发挥了巨大作用,显著提升了效率。这些大模型,凭借其强大的数据处理和学习能力,为各行各业带来了前所未有的变革。然而,在利用这些大模型的过程中,我们不难发现一个有趣且略显尴尬的现象:大模型似乎总在“人工智能”与“人工智障”之间游走。当尝试用它们解决具体问题时,若问题超出了模型的知识范围,其回答往往令人啼笑皆非,这种现象我们称之为“AI幻觉”。
以下是一个实例,即便是在进行了联网搜索的情况下,某大模型对于“田豆芽”这一品牌的知识仍然匮乏,从而给出了一个与实际情况大相径庭的回答。这种回答不仅无法解决问题,还可能误导用户,造成不必要的困扰。这也让我们深刻意识到,大模型虽然强大,但并非万能,它们也有其局限性和不足之处。
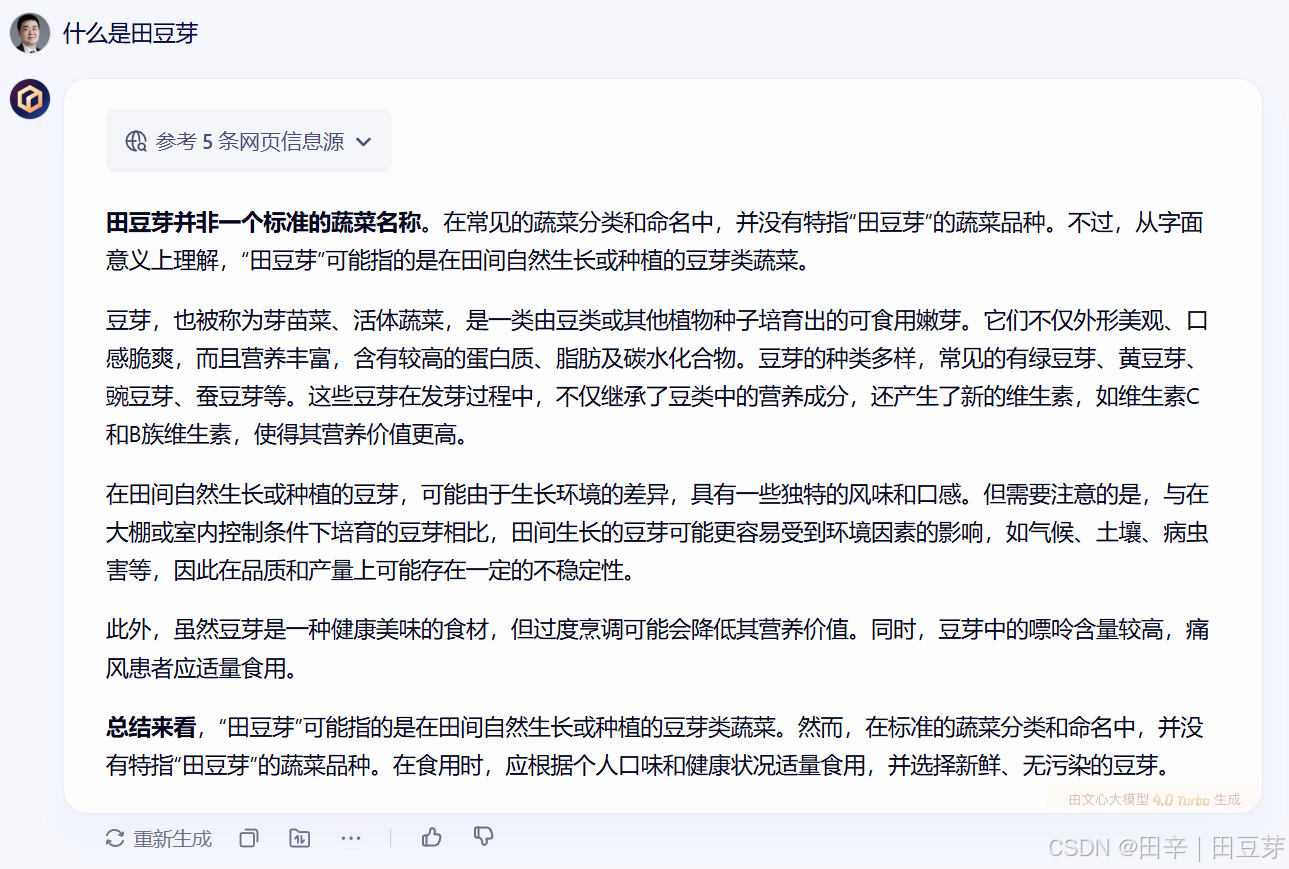
二、AI幻觉带来的挑战与影响
AI幻觉的存在,不仅影响了大模型的准确性和可靠性,也对其应用范围和发展前景造成了一定的制约。在医疗、法律、金融等需要高度准确性和责任性的领域,AI幻觉可能导致严重的后果,甚至危及生命和财产安全。因此,解决AI幻觉问题,提高大模型的准确性和可靠性,成为了当前AI技术发展的重要课题。
三、解决AI幻觉的技术路径
为了克服AI幻觉的问题,业界目前主要采用了两种解决方案:模型微调和检索增强生成(RAG)。
-
模型微调:这是在预训练模型的基础上,结合特定任务的数据集进行进一步训练,使模型在该领域表现更佳。通过微调,模型可以更好地适应特定任务的需求,提高其准确性和可靠性。形象地来说,就像是考前复习,让模型对特定知识更加熟悉,从而在考试中取得更好的成绩。
-
检索增强生成(RAG):在生成回答前,系统会通过信息检索从外部知识库中查找与问题相关的知识,以此增强生成过程中的信息来源,从而提升回答的质量和准确性。RAG技术结合了检索和生成的优势,既保证了回答的准确性,又提高了其多样性和丰富性。这类似于考试时带小抄,但当然是合法且有益的,因为它是在遵循规则和原则的前提下,通过合理利用外部资源来提高自己的表现。
两者的共同点在于,都是为了赋予模型特定领域的知识,以解决大模型的幻觉问题。通过这两种技术,我们可以有效地提高大模型的准确性和可靠性,拓宽其应用范围和发展前景。
四、RAG技术的原理与实现
RAG技术主要包含三个步骤:检索、增强和生成。
-
检索(Retrieval):当用户提出问题时,系统会从外部知识库中检索出与问题相关的内容。这一步是RAG技术的核心之一,它要求系统具备强大的信息检索能力,能够准确、快速地找到与问题相关的知识。
-
增强(Augmentation):系统将检索到的信息与用户输入相结合,扩展模型的上下文。这一步是为了让模型在生成回答时能够充分考虑到外部知识库中的信息,从而提高回答的准确性和多样性。增强后的上下文会传递给生成模型,作为其生成回答的依据。
-
生成(Generation):生成模型基于增强后的上下文生成最终回答。由于回答参考了外部知识库的内容,因此更加准确且可读。这一步是RAG技术的最终输出,它要求生成模型具备强大的自然语言生成能力,能够准确、流畅地表达出回答的内容。
五、Embedding在RAG技术中的角色与作用
那么,什么是Embedding?为什么RAG技术除了大模型外还需要Embedding模型呢?
Embedding是一种将自然语言转化为机器可以理解的高维向量的技术。通过Embedding模型,我们可以将文本中的词汇、句子甚至段落转化为向量表示,从而捕获文本背后的语义信息。这种向量表示不仅方便了机器的处理和理解,还为我们提供了文本之间的相似度度量方法。
在RAG技术中,Embedding模型扮演着至关重要的角色。它负责将用户提问和外部知识库中的内容转化为向量表示,从而方便系统进行相似度匹配和检索。以“田辛”和“田豆芽”为例,如果我们不了解它们的背景信息,就无法理解它们之间的关联性。同样地,RAG技术也需要理解文本之间的关联性,这就需要Embedding模型的帮助。
5.1 检索的详细过程
-
准备外部知识库:首先,我们需要准备一个包含大量知识的外部知识库。这个知识库可以来源于本地文件、搜索引擎结果或API等。知识库的内容应该丰富、准确且及时更新,以保证检索结果的准确性和可靠性。
-
知识库解析:通过Embedding模型对知识库文件进行解析,将自然语言转化为机器可以理解的高维向量。这一步是检索过程的基础,它要求Embedding模型具备强大的自然语言处理能力和向量表示能力。
-
用户提问处理:同样通过Embedding模型,将用户的提问生成一个高维向量。这个向量将作为检索的输入,用于在知识库中查找与问题相关的内容。
-
匹配本地知识库:使用用户输入生成的高维向量,去查询知识库中的相关文档片段。系统会利用相似度度量(如余弦相似度)来判断相似度,从而找到与问题最相关的知识。例如,在海绵宝宝的世界里,“蟹堡王”和“比奇堡”高度关联,而与“深度学习”关联度很低。Embedding模型就是在构建这些概念的向量表示,从而方便系统进行相似度匹配和检索。
(注:由于无法直接展示图片,请参考相关文档或资料中的向量相似示意图来更好地理解这一过程。)
5.2 Embedding模型的训练与优化
Embedding模型的训练和优化是RAG技术中的关键环节。一个优秀的Embedding模型应该能够准确地捕获文本背后的语义信息,并生成具有区分性的向量表示。为了训练和优化Embedding模型,我们可以采用多种方法和技术,如深度学习、自然语言处理、词向量表示等。
六、模型的分类与协同工作
在RAG技术中,我们主要涉及到三类模型:Chat模型、推理模型和Embedding模型。
-
Chat模型:负责生成自然语言回复,与用户进行交互。它需要具备强大的自然语言生成能力和对话管理能力,以便能够准确、流畅地回应用户的问题。
-
推理模型:负责进行逻辑推理和决策,根据用户的问题和上下文信息来推断出最合适的回答。它需要具备强大的逻辑推理能力和决策能力,以便能够处理复杂的问题和情境。
-
Embedding模型:如前所述,负责将自然语言转化为高维向量,并捕获文本背后的语义信息。它是检索过程的基础,也是RAG技术中的核心模型之一。
这三类模型在RAG技术中协同工作,共同完成了从用户提问到最终回答的全过程。它们相互依存、相互补充,共同构成了RAG技术的核心架构。
七、总结与展望
本文深入剖析了AI幻觉的缘起、挑战与影响,以及解决AI幻觉的技术路径——RAG技术。我们详细介绍了RAG技术的原理与实现过程,以及Embedding模型在其中的角色与作用。通过本文的阐述,我们可以清晰地看到RAG技术在解决AI幻觉问题方面的优势和潜力。
未来,随着AI技术的不断发展和完善,我们相信RAG技术将会得到更广泛的应用和推广。同时,我们也期待更多的研究者和开发者能够加入到这一领域中来,共同推动RAG技术的进步和发展。相信在不久的将来,RAG技术将会成为AI领域中的一项重要技术,为我们的生活和工作带来更多的便利和惊喜。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











