







我简洁明了的说:解决办法有换手机版进行爬取
我没有尝试,是搜索得到的结果
用这个urlhttps://fanyi.baidu.com/v2transap?爬取需要完整的data
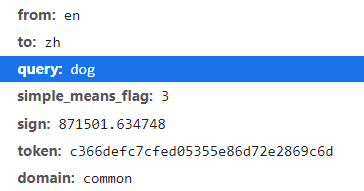
并且sign是翻译内容不同而改变的,并且,在headers伪装时,除了user-agent,还要post cookies,而cookies很长,并且时变化的,我也没有仔细的看,(主要我也初学,不太会i😜)
所有我采用的方法时用这个接口
https://fanyi.baidu.com/sug
这个接口不需要cookies,也不需要很多data,只需要'kw':'需要翻译的内容'
下面我贴下我的代码,因为这个接口,检测很少,所以代码很简单
import requests
import json
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/88.0.4324.146 Safari/537.36'
}
url = 'https://fanyi.baidu.com/sug'
query = input("请输入需要翻译的内容")
data = {
'kw': query
}
response = requests.post(url=url, headers=headers, data=data)
dic_obj = response.json()
fileName = query + '.json'
fp = open(fileName, 'w', encoding='utf-8')
json.dump(dic_obj, fp=fp, ensure_ascii=False)
print('over')














 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









