







 本文介绍了BERT及其发展历程,包括Bert、XlNet、RoBERTa、T5、Electra和ALBERT等模型。BERT通过双向Transformer预训练策略实现了语言理解的突破,后续模型在预训练策略和模型优化上不断改进,如XlNet的Permutation Language Model和RoBERTa的去掉NSP损失等。这些发展展示了深度学习在自然语言处理领域的持续进步。
本文介绍了BERT及其发展历程,包括Bert、XlNet、RoBERTa、T5、Electra和ALBERT等模型。BERT通过双向Transformer预训练策略实现了语言理解的突破,后续模型在预训练策略和模型优化上不断改进,如XlNet的Permutation Language Model和RoBERTa的去掉NSP损失等。这些发展展示了深度学习在自然语言处理领域的持续进步。
1. introduction
Bert,目前nlp领域神器级模型,诞生于2018年,全称Bidirectional Encoder Representation from Transformers。该模型在其诞生时,在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等,引起了极大的轰动。经过2年的发展,在标准的Bert模型基础上又诞生了相当多的改进,十分有必要学习一下目前的进展。
2. 模型发展综述
2.1 Bert
Bert模型的开端,它在工程上没有什么特别大的创新,如果懂了transformer,那么基本上就懂了模型的大概,重要的理解其背后的思想。Bert的paper名字叫做:Pre-training of Deep Bidirectional Transformers for Language Understanding,papar name基本包含了所有的内容。
2.1.1 Deep Bidirectional Transformers
pre-training技术并不新鲜,在Bert之前的很多模型,比如ELMo和GPT上已经得到了应用,不过这些模型多少还存在不足。
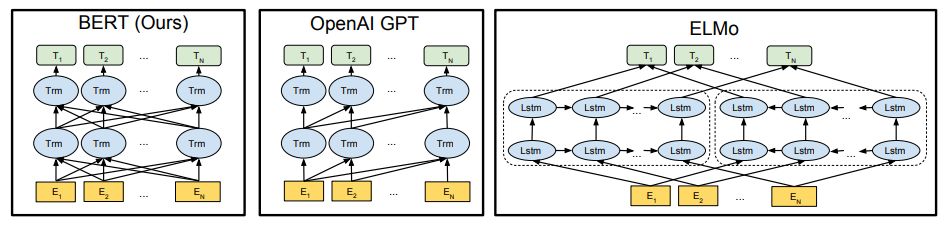
对比OpenAI GPT(Generative pre-trained transformer),Bert是双向的Transformer block连接;就像单向RNN和双向RNN的区别,这种结果能让模型获得更丰富的信息,从而获得更强的表达能力。
对比ELMo,虽然都是“双向”,但目标函数其实是不同的。ELMo是分别以[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ItGis3fB-1632813118432)(https://www.zhihu.com/equation?tex=P%28w_i%7C+w_1%2C+…w_%7Bi-1%7D%29)] 和 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H0Uo1Ech-1632813118433)(https://www.zhihu.com/equation?tex=P%28w_i%7Cw_%7Bi%2B1%7D%2C+…w_n%29)] 作为目标函数,独立训练处两个representation然后拼接,而Bert则是以 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DLzwW8DK-1632813118437)(https://www.zhihu.com/equation?tex=P%28w_i%7Cw_1%2C++…%2Cw_%7Bi-1%7D%2C+w_%7Bi%2B1%7D%2C…%2Cw_n%29)] 作为目标函数训练LM,所以Bert在信息融合层面显然要比ELMo更强大,效果也更好。
2.1.2 Pre-training
这里应该就是Bert比较有创新的地方了,论文中,作者使用了两种预训练策略:
- Masked Language Modeling
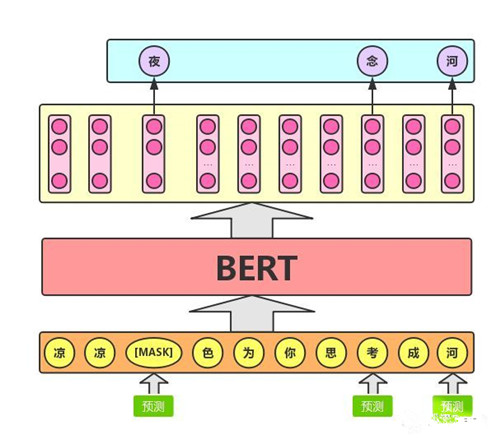
假设有这样一个句子:“我喜欢阅读Analytics Vidhya上的数据科学博客”。想要训练一个双向的语言模型,可以建立一个模型来预测序列中的遗漏单词,而不是试图预测序列中的下一个单词。将“Analytics”替换为“[MASK]”,表示丢失的标记。然后,以这样的方式训练模型,使其能够预测“Analytics”是本句中遗漏的部分:“我喜欢阅读[MASK]Vidhya上的数据科学博客。”。这样处理后,预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇(10%概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
这是Masked Language Model的关键。BERT的开发者还提出了一些进一步改进该技术的注意事项:
1)为了防止模型过于关注特定的位置或掩盖的标记,研究人员随机掩盖了15%的词(个人认为这里设为15%有加速收敛的效果,毕竟mask比例越大则信息损失越多,模型从未mask的token中恢复信息需要的训练轮次也越多),这样的处理使得模型只会预测语料库中的15%单词,而不会预测所有的单词。
2)掩盖的词并不总是被[MASK]替换,因为在微调时不会出现[MASK]。
研究人员使用了以下方法:
o [MASK]替换的概率为80%
o 随机词替换的概率为10%
o 不进行替换的概率为10%
这种策略就是普通语言模型。
- Next Sentence Prediction
Masked Language Model是为了理解词之间的关系。BERT还接受了Next Sentence Prediction训练,来理解句子之间的关系。
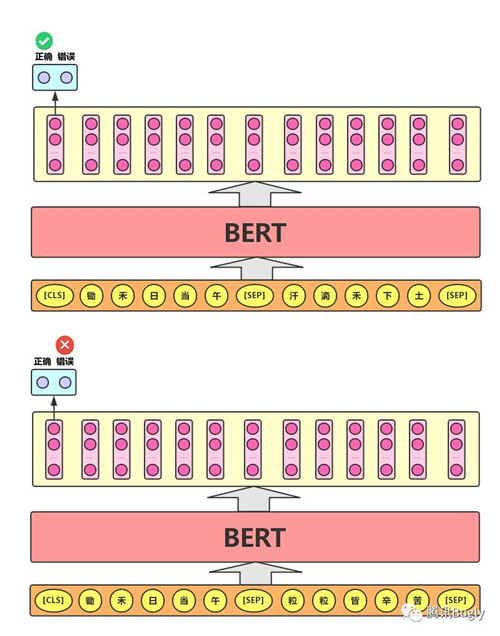
问答系统 question answering systems是一个不错的例子。该任务十分简单。给定两个句子,句A和句B,B是语料库中在A后面的下一个句子,还是只是一个随机的句子?
由于它属于到二分类任务,通过将数据拆分为句子对,就可以很容易地从任何语料库中生成数据。就像Masked Language Model一样,研发者也在这里添加了一些注意事项。例如:
假设有一个包含100,000个句子的文本数据集。因此,将有5万个训练样本或句子对作为训练数据。
• 其中50%的句子对的第二句就是第一句的下一句。
• 剩余50%的句子对,第二句从语料库中随机抽取。
• 第一种情况的标签为‘IsNext’ ;第二种情况的标签为‘NotNext’。
这就是BERT为什么能够成为一个真正的任务无关模型。因为它结合了Masked Language Model (MLM)和Next Sentence Prediction (NSP)的预训练任务。
2.1.3 超强的通用性
如果Bert只是性能好而通用性欠佳,那么大概也不会导致这么大的反响,不过Bert在性能强的同时又保证了良好的通用性,这就没有不火的理由了。Bert通过良好的预处理方式,保证了自己的良好通用性。
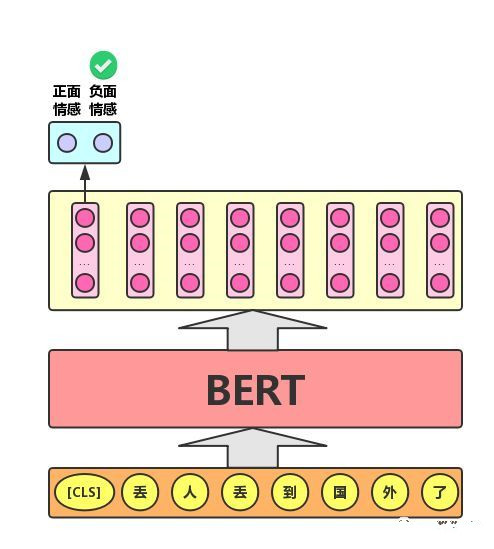
1)文本分类任务
单文本分类任务:对于文本分类任务,Bert模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如下图所示。可以理解为:与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。
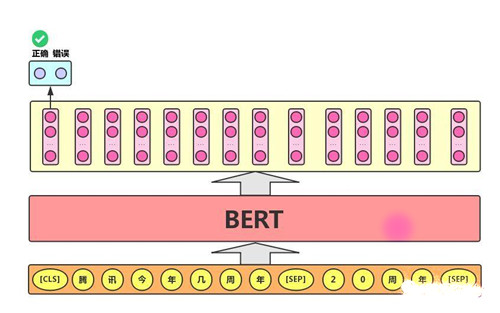
2)语句对分类任务
语句对分类任务:该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务,BERT模型除了添加[CLS]符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个[SEP]符号作分割,并分别对两句话附加两个不同的文本向量以作区分,如下图所示:
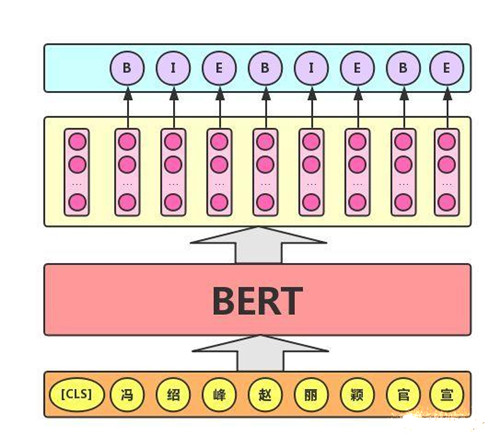
3)序列标注任务
该任务的实际应用场景包括:中文分词&新词发现(标注每个字是词的首字、中间字或末字)、答案抽取(答案的起止位置)等。对于该任务,BERT模型利用文本中每个字对应的输出向量对该字进行标注,如下图所示(B、I、E分别表示一个词的第一个字、中间字和最后一个字)。
Bert模型整体输入/输出:
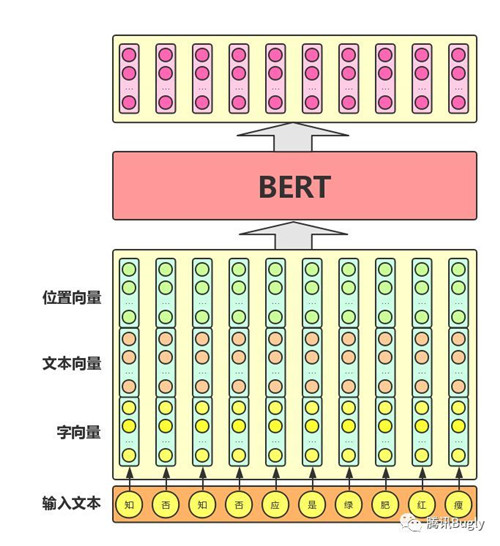
从图可以看出,其混合了三种向量:
- 字向量:普通的Embedding输出。
- 文本向量:该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合,适用于语句对分类任务,表示word属于哪个句子。
- 位置向量:同标准的transformer。
2.2 XlNet
Bert的引入为nlp打开了一道新的大门,不过不代表其就是完善的,分别看一下Bert的两个重要机制:
- Masked
Bert在做pre-train的时候,是预测被那些被[MASK]替换的token,而在fine-tuning的时候,输入文本中是没有[MASK]的,这很显然就会导致一个bias的问题,尽管作者也意识到了这个问题,并设计了一些替换策略,比如用替换为其他正常词而非[MASK],不过在pre-train的时候只有15%的词会被替换,然后替换的词中只有10%的词会被替换为其他正常词,这个比例这是一下只有1.5%,是非常低的。
- Parallel
这是Bert相比于RNN的一个优势,但是有得必有失,并行的加入是以失去部分序列依赖性为代价的,而对于RNN系列模型,由于每次都是从左向右或者从右向左,所以可以明显捕捉到依赖性。
Bert取得的重大进步就是通过捕捉双向语境来获得的,代价就是上面两个,那么问题就变成了,如果在保持Bert优势的基础上,克服上面的两个问题呢?XlNet给出了自己的答案。
在介绍XlNet以前,有必要了解两个概念:自回归语言模型(Autoregressive LM)和自编码语言模型(Autoencoder LM):
- 自回归语言模型(Autoregressive LM)
自回归模型(英语:Autoregressive model,简称AR模型),是统计上一种处理时间序列的方法,用同一变数例如[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GfxjhA3f-1632813118444)(https://wikimedia.org/api/rest_v1/media/math/render/svg/87f9e315fd7e2ba406057a97300593c4802b53e4)]的之前各期,亦即 x 1 x_{1} x1至 x t − 1 x_{t-1} xt−1来预测本期 x t x_{t} xt的表现,并假设它们为一线性关系。因为这是从回归分析中的线性回归发展而来,只是不用 x x x预测[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I2l0EQHT-1632813118445)(https://wikimedia.org/api/rest_v1/media/math/render/svg/b8a6208ec717213d4317e666f1ae872e00620a0d)],而是用[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LEToP6kv-1632813118446)(https://wikimedia.org/api/rest_v1/media/math/render/svg/87f9e315fd7e2ba406057a97300593c4802b53e4)]预测[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mU2eIjgk-1632813118447)(https://wikimedia.org/api/rest_v1/media/math/render/svg/87f9e315fd7e2ba406057a97300593c4802b53e4)](自己),所以叫做自回归(摘自wiki)。从这个定义来看,可以发现ELMo/Bert以前的诸多模型基本都是自回归模型,因为他们就是对一个句子从左向右或者从右向左,利用前面token的信息来预测本时间步的token。GPT 就是典型的自回归语言模型。ELMO尽管看上去利用了上文,也利用了下文,但是本质上仍然是自回归LM,因为虽然ELMO是做了两个方向(从左到右以及从右到左两个方向的语言模型),但是是分别有两个方向的自回归LM,然后把LSTM的两个方向的隐节点状态拼接到一起,来体现双向语言模型这个事情的。所以其实是两个自回归语言模型的拼接,本质上仍然是自回归语言模型。
自回归语言模型有优点有缺点,缺点是只能利用上文或者下文的信息,不能同时利用上文和下文的信息,当然,貌似ELMO这种双向都做,然后拼接看上去能够解决这个问题,因为融合模式过于简单,所以效果其实并不是太好。它的优点,其实跟下游NLP任务有关,比如生成类NLP任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。而Bert这种DAE模式,在生成类NLP任务中,就面临训练过程和应用过程不一致的问题,导致生成类的NLP任务到目前为止都做不太好。
- 自编码语言模型(Autoencoder LM)
自回归语言模型只能根据上文预测下一个单词,或者反过来,只能根据下文预测前面一个单词。相比而言,Bert通过在输入中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,如果你对Denoising Autoencoder比较熟悉的话,会看出,这确实是典型的DAE的思路。那些被Mask掉的单词就是在输入侧加入的所谓噪音。类似Bert这种预训练模式,被称为DAE LM。
这种DAE LM的优缺点正好和自回归LM反过来,它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文,这是好处。缺点嘛,就是上面提到的两个。
XLNet的出发点就是:能否融合自回归LM和DAE LM两者的优点。就是说如果站在自回归LM的角度,如何引入和双向语言模型等价的效果;如果站在DAE LM的角度看,它本身是融入双向语言模型的,如何抛掉表面的那个[Mask]标记,让预训练和Fine-tuning保持一致。问题有了,接下来就是解决了。
XLNet仍然遵循两阶段的过程,第一个阶段是语言模型预训练阶段;第二阶段是任务数据Fine-tuning阶段。它主要希望改动第一个阶段,就是说不像Bert那种带Mask符号的Denoising-autoencoder的模式,而是采用自回归LM的模式。就是说,看上去输入句子X仍然是自左向右的输入,看到 w t w_{t} wt单词的上文Context_before,来预测 w t w_{t} wt这个单词。但是又希望在Context_before里,不仅仅看到上文单词,也能看到 w t w_{t} wt单词后面的下文Context_after里的下文单词,这样的话,Bert里面预训练阶段引入的Mask符号就不需要了,于是在预训练阶段,看上去是个标准的从左向右过程,Fine-tuning当然也是这个过程,于是两个环节就统一起来。那么,应该如何修改呢?说起来也很简单,那就是我随机重排输入的单词序列不就行了么,这样后面的单词有概率被分到前面去,这不就相当于看到上下文了么?XLNet正是这么做的,在论文中被称为Permutation Language Model。
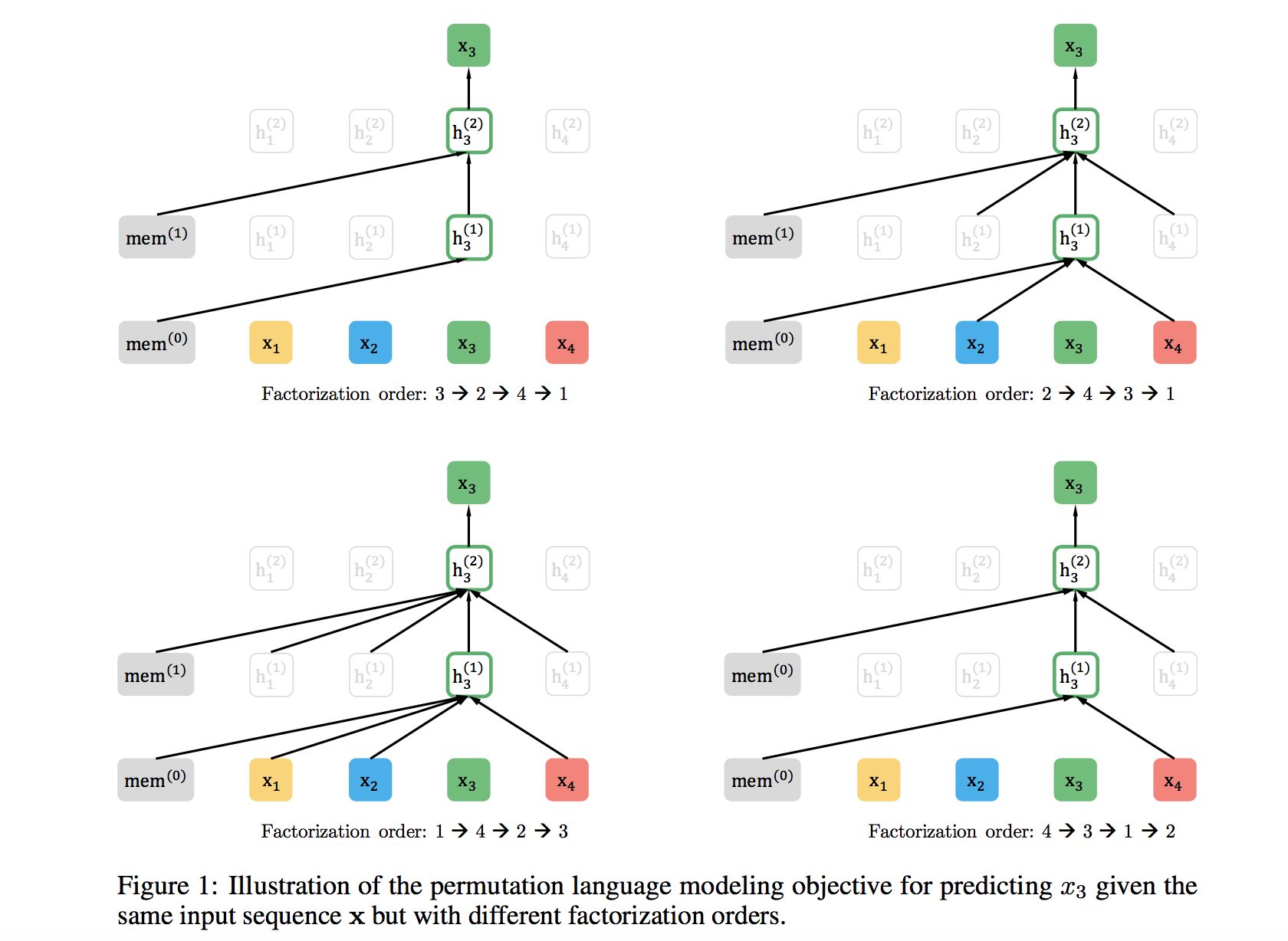
以上图为例,输入序列为 x 1 , x 2 ,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









