







My first (at all!) post was devoted to 2 basic questions of training detection models using TensorFlow Object Detection API: how are negative examples mined and how the loss for training is chosen. This time I’d like to cover 3 more questions regarding the following:
- How are bounding boxes handled?
- How are duplicate boxes removed?
- How can I speed up the model?
As before, I totally recommend to recap the SSD architecture features following the same links as were provided in my previous post.
Trending AI Articles:
1. Text Classification using Algorithms
2. Regularization in deep learning
3. An augmentation based deep neural network approach to learn human driving behavior
How are bounding boxes handled?
In SSD, there is no region-proposal step (in contrast with R-CNN models) and the set of regions to be considered by the model is completely predefined by the configuration. In short, the features from the feature-head of the network are passed to a pipeline of the detection blocks. Every detection block receives a reduced in spatial size tensor (which is still a somewhat representation of input image) and overlays it with a regular grid which nodes are later used as centers for the set of assumed bounding boxes. Each set consists of rectangles with various aspect ratios: 1:1, 2:1, 1:2, 3:1, 1:3, etc. All of these boxes are sent to both the classification and localization blocks, then the corresponding loss components are calculated and so on.
In our case, the code for generating the boxes (or, how they’re named after the R-CNN papers, anchors) is stored in anchor_generator modules. To customize your choice of generator you can edit the config file at field model/ssd/anchor_generator (lines 31–41 in example config):
As you can figure out, we have 5 default boxes for each grid node: the square one (ratio of 1.0) and the elongated ones (the rest 4 ratios).
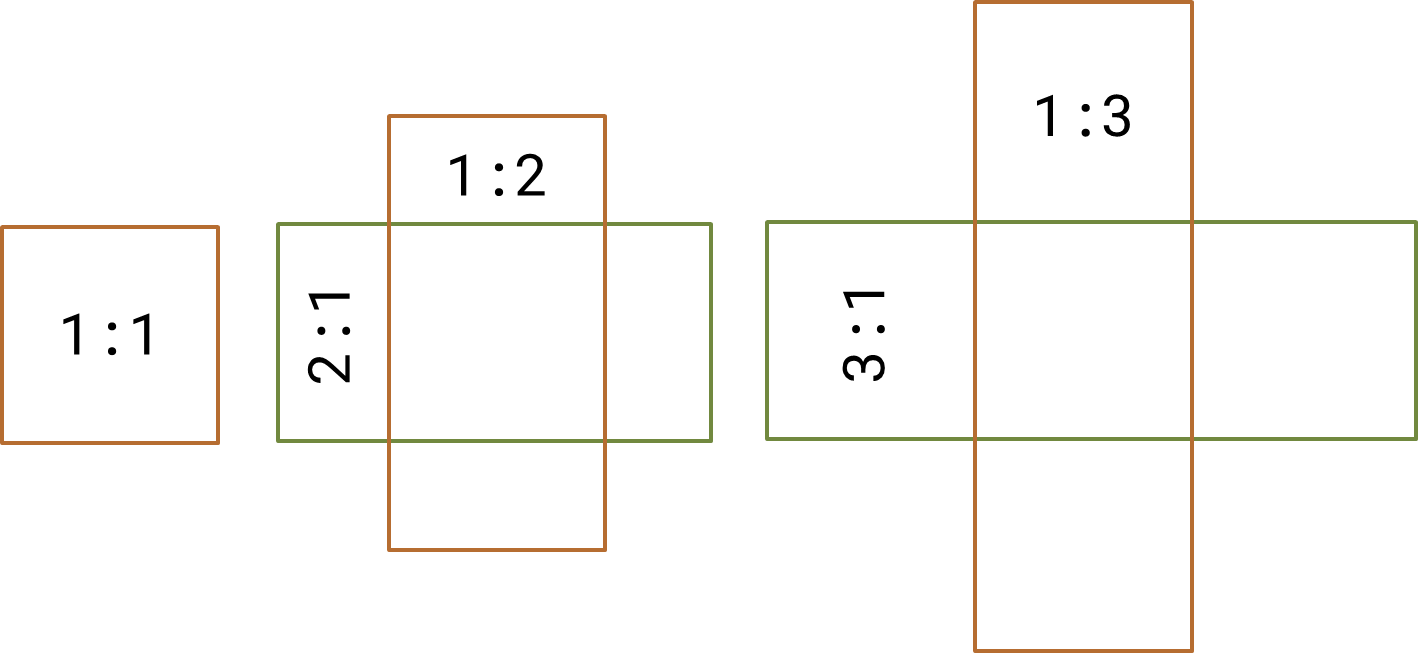
5 types of default boxes
Of course, the bounding boxes that you actually get when you run your model may have different aspect ratio as long as the localization block calculates the deltas (for both size and position) for every matched box in order to “fit” the detected object. The more aspect ratios you use, the slower your model is and the more work is done in post-processing steps, but we will talk about it later in this post.
How are duplicate boxes removed?
Once we got a ton of bounding boxes for our image, we have to get rid of the multiple detections of the same object.

Multiple detections example (from https://stackoverflow.com/questions/45691417/faster-r-cnn-how-to-avoid-multiple-detections-in-same-area)
These detections may take place due to the same mechanism as we have just discussed: the default boxes. While training, the loss is calculated only for those default boxes that overlap with any of the ground truth boxes more than specified in configuration file (see below); the rest default boxes are used for negative examples mining (see previous post). But when we use our model for inference, we are not interested in every box (like in motorcycle image above), we will be fine with one box per object.
In order to filter the duplicate boxes the postprocessing is required and the procedure for that is called non-maxima suppresion. In short, it works the simple way:
- Sort all of the candidate bboxes by their predicted score.
- Take the one with the highest score, send it to resulting output. Look through the other boxes in order to find ones that have and overlap with the chosen one more than some threshold. All of such bboxes are removed from the candidate list.
- Repeat step 2 until the candidate list is empty.
- Yield the result.
This greedy procedure allows to remove the boxes that overlap too much and keep the not-so-close ones. The only thing you have to take care of is choosing the threshold value, and this can be done using the configuration file (130–136):
score_threshold allows to filter boxes with low score values (the higher the threshold, the more not-so-sure detections will be removed without a trial). iou_threshold (intersection-over-union) is the overlapping threshold which we mentioned above. Other two params are self-explanatory: the filtering stops when the number of already-found detections is higher than the specified numbers (per class and at all, respectively).
How can I speed up the model?
The final part of the 2-post story will be devoted to the problem that I still work on for my own purpose. In this case feel free to add your ideas of how can speeding up for inference be done in comments. Now I will list my own approaches.
Let’s recap the main steps of detection inference:
- Features extraction in convolutional head
- Default box generation for every feature map inside the detection blocks and prediction of score and position of bounding boxes at many scales
- Greedy filtering of the duplicates
So, how can we really speed up the model on each step?
Of course, we can use a simpler and/or shorter convolutional network for feature extraction. For SSD in TFODAPI choices are mobilenet_v1 and inception_v2 by default, but you are free to contribute your own architecture based on your favourite network ( vgg/ resnet/…). The other option is to resize input images to smaller size (lines 43–47 of config example), this can bring you a huge boost in speed but can lower the quality of the model.
The machinery inside the detection blocks can be simplified by reducing the number of default boxes types. For example, if your model is supposed to detect the ball on the football field, you probably don’t need to use the elongated (1:3, 3:1 and so) boxes, but the close-to-central-symmetric boxes will do. Also, playing around with the num_layers / min_scale / max_scale in ssd_anchor_generator of config file affects the grid size for the generation of the boxes that can be tuned as well (see multiple_grid_anchor_generator for details).
In order to speed up the greedy-nms you can simply change the score/ iou thresholds to some higher values (then the model will consider much less boxes in the first place) and two integer thresholds to lower values; in my case, this results in a huge speed up and a small lose of accuracy, but in my case the number of objects on every image is always less then 4–5. If you have a lot of objects normally, you should be careful at tuning these options.
Congratulations on finishing this short tutorial, hope you will find it useful for your own cases. Thanks for your time, and happy new year!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









