




 本文探讨了使用CUDA进行分离卷积优化的方法,包括利用固定主机内存、常数内存、共享内存、读取纹理缓存等技术。通过具体实例展示了不同优化策略对性能的影响。
本文探讨了使用CUDA进行分离卷积优化的方法,包括利用固定主机内存、常数内存、共享内存、读取纹理缓存等技术。通过具体实例展示了不同优化策略对性能的影响。
※The code corresponding to this blog in here.
This post is focused on the generic separate convolution. If you are interested in how to optimize for a specified size, you ※could read my next post.
Compute United Device Architecture (CUDA) has been introduced by Nvidia on 2007, for general-purpose computing on graphics processing units(GPGPU). Before CUDA, if the user wants to use the graphics cards for non-3D issue, the only way is to convert their problems as 3D rendering. The entry barrier is very high, the user should know 3D vector-rendering libraries (like OpenGL), the shader programming, and GPU architectures; Due to there are so much prerequisite knowledge, the learning curve of those is steep. Besides, the users, in most cases, are far away from the 3D issues (c.g they engage in astronomy simulation, mechanical analysis), they are almost know nothing about GPU. Therefore, only a limited number of people use he graphics cards for GPGPU before 2007.
CUDA eases the pain of learning 3D rending for non-3D issue. Via CUDA, we could require GPU to solve non-3D problem directly instead to wrap that as a series of the 3D operations.
My previous post discussing how to use CPU's XXE/AVX to deal with separable convolution. In this post, I continue the same problem, but I use CUDA for the computing and the optimization.
The examples in most documents - including tutorials, blogs, and books -the input/output size , are all being a multiple of 32, and the numbers of thread in a block are the numbers able to divide 32 exactly. Their reason is a streaming multiprocessor (or called warp, from software perspective) containing 32 CUDA cores. Thus, if the size is a multiple of 32, it completely meets the GPU's nature.
But not all size in every problem are a multiple of 32. Hence, I emphasize that the optimization in this post is for any size.
零. The CPU serial.
In my previous post, the best result is the functions with the width-loop-in-inner. but due to the large scale memory accessing (non-localized) is bad for CUDA, I use the original functions, SeparableConvolutionRowSerial and SeparableConvolutionColumnSerial as the prototype for CUDA code.
一. Use pinned host memory.
Using pinned host memory is able to improve the data transmission between the host(CPU memory) and the device(GPU memory).
The runtime of a dummy copy, transmitting 7.80 MB from the host to the device, and take back 7.47MB, in my GTX 1060 3G :
Regular memory(cudaMallocHost/cudaFreeHost) : 5.29 ms
Pinned memory(malloc/free) : 155 ms
For the difference is so obvious,the later cases are all based on the pinned host memory.
二. Separable convolution implementation in CUDA.
It is straightforward, the code is as below :
For column:
j = blockDim.y*blockIdx.y + threadIdx.y;
for (; j < height; j += blockDim.y * gridDim.y) {
i = blockDim.x*blockIdx.x + threadIdx.x;
for (; i < width; i += blockDim.x * gridDim.x) {
int jj;
int x, y_mul_input_width;
float sum;
sum = 0;
x = kernel_radius + i;
y_mul_input_width = j*extended_width;
for (jj = 0; jj < kernel_length; jj++) {
sum += p_kernel_column_dev[jj]
* p_extended_input_dev[y_mul_input_width + x];
y_mul_input_width += extended_width;
}/*for kernel*/
p_column_done_extended_output_dev[j*extended_width + x]
= sum;
}/*for width*/
}/*for j*/
For row:
j = blockDim.y*blockIdx.y + threadIdx.y;
for (; j < height; j += blockDim.y * gridDim.y) {
i = blockDim.x*blockIdx.x + threadIdx.x;
for (; i < width; i += blockDim.x * gridDim.x) {
int x, y_mul_input_width;
int ii;
float sum;
sum = 0;
y_mul_input_width = j*extended_width;
x = i;
for (ii = 0; ii < kernel_length; ii++) {
sum += p_row_dev[ii]
* p_column_done_extended_input_dev[y_mul_input_width + x];
x += 1;
}/*for kernel_length*/
p_output_dev[j*width + i] = sum;
}/*for width*/
}/*for j*/
For choose block size = 32 x 32, grid size = 64 x 64, The runtime in my GTX1060 3G and i5-4570 is
| input = 1400x1400 kernel = 31 x 31 100 Rounds | Runtime, ms |
|---|---|
| CPU AVX † | 2023 ms |
| CUDA, pure copy | 161 ms |
| CUDA, simplest | 474 ms |
† CPU-AVX code is the best version from my previous post.
The runtime includes the transmission - copy the input data to GPU and copy the output back-, so I list the pure copy time for comparing. This case shows CUDA is applicable for the convolution problems, the performance of un-optimized GPU version, is 426% (or 643%, deducting the transmission) of that on CPU.
三. Adopt the constant memory to contain the kernel data
Ideally, the constant memory suits this situation: all threads access the same address to fetch the value at the same time - Nvidia use the term broadcast to describe that. As the figure shows, the same address broadcasts its value to all the threads:

Observe the code about accessing the kernel data, we could find that all threads access the same address concurrently. As well, the kernel data is less than the capacity of the constant memory (8KB), so it is a good circumstance to use constant memory.
Set the constant memory in the host:
__constant__ float kernel_const_mem[1024];
:
HANDLE_ERROR(cudaGetSymbolAddress((void **)&p_kernel_const_dev,
kernel_const_mem));
HANDLE_ERROR(cudaMemcpy(p_kernel_const_dev, p_kernel_row_host,
kernel_length * sizeof(float), cudaMemcpyHostToDevice));
※ Do not use the function cudaMemcpytoSymbol, which is only able to set the constant memory once.
And replace the kernel data pointers, p_kernel_column_dev/p_kernel_row_dev, as kernel_const_mem :
:
sum += kernel_const_mem[ii]
* p_column_done_extended_input_dev[y_mul_input_width + x];
:
The result :
| input = 1400x1400 kernel = 31 100 Rounds | Runtime, ms | Computing time, ms |
|---|---|---|
| CUDA, pure copy | 161 ms | - |
| CUDA, simplest | 474 ms, 100% | 313 ms, 100% |
| CUDA, const kernel | 294 ms, 160% | 136 ms, 230% |
Use NVIDIA Visual Profiler(nvprof), it is easy to understand why the the constant kernel version get such better :
For row function, the times of global load transactions:
Simplest : 61107202
kernel in constant : 30553602
The global memory accessing speed is much slow than the constant memory, hence, the result makes sense.
四. Use the shared memory.
Scrutinize this session :
i = blockDim.x*blockIdx.x + threadIdx.x;
:
for (ii = 0; ii < kernel_length; ii++) {
sum += kernel_const_mem[ii]
* p_column_done_extended_input_dev[y_mul_input_width + i + ii];
}/*for kernel_length*/
:
Beware the behavior of the accessing : While thread 0 accesses the location [0], thread 1 would access the location [1], thread 2 would access the location [2]..etc. And the location[1] would be accesses by thread 0 and 1; the location[2] would accesses by thread 0, 1, 2.. the accessing is localized.
Localized accessing is, the accessing range is not large and be accessed for many times. For a block of threads, the range is kernel_length + (blockDim.x - 1). Typically, the size of blockDim is 32, kernel_length is less than 50. Thus, the accessing range of a block is pretty localized. It is good place to use the shared memory to improve the performance.
This is how the data are assigned to each block graphically. The block size is 4 x 4, kernel length = 7.

This shows how the threads in x dimension of a block move input data into the shared memory:

Below figure shows how the threads in x dimension in a block fetch the shared memory data (to multiply with the constant memory).
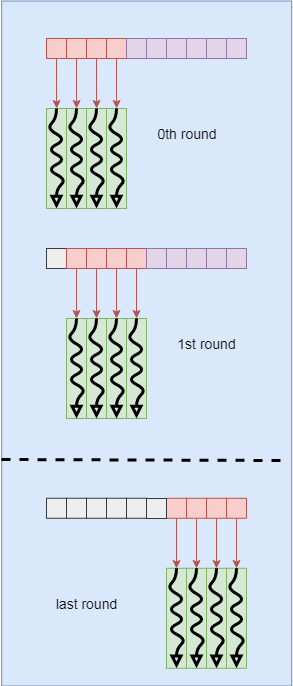
The code corresponding to the using share memory is:
For column:
block_height = num_threads.y + (kernel_length - 1);
shared_mem_size = sizeof(float)*(block_height)*(num_threads.x);
block_height = blockDim.y + (kernel_length - 1);
:
j = blockDim.y*blockIdx.y + threadIdx.y;
i = blockDim.x*blockIdx.x + threadIdx.x;
:
sum = 0;
x = kernel_radius + i;
jj = 0;
do {
p_input_in_block[(threadIdx.y + jj*blockDim.y)*blockDim.x
+ threadIdx.x]
= p_extended_input_dev
[ (j + jj*blockDim.y)*extended_width
+ kernel_radius + i];
jj++;
} while (threadIdx.y + jj * blockDim.y < block_height);
__syncthreads();
for (jj = 0; jj < kernel_length; jj++) {
sum += kernel_const_mem[jj]* p_input_in_block[
(threadIdx.y + jj)*blockDim.x + threadIdx.x];
}/*for kernel*/
p_column_done_extended_output_dev[j*extended_width + kernel_radius + i]
= sum;
__syncthreads();
:
For row:
block_width = num_threads.x + (kernel_length - 1);
shared_mem_size = sizeof(float)*(block_width)*(num_threads.y);
:
p_input_in_block = &shared_mem[0];
block_width = blockDim.x + (kernel_length - 1);
:
j = blockDim.y*blockIdx.y + threadIdx.y;
i = blockDim.x*blockIdx.x + threadIdx.x;
:
sum = 0;
ii = 0;
do {
p_input_in_block[threadIdx.y*block_width
+ ii*blockDim.x + threadIdx.x] =
p_column_done_extended_input_dev[j*extended_width
+ ii*blockDim.x + i];
ii++;
} while (threadIdx.x + ii* blockDim.x < block_width);
__syncthreads();
for (ii = 0; ii < kernel_length; ii++) {
sum += kernel_const_mem[ii]* p_input_in_block[
threadIdx.y*block_width + ii + threadIdx.x];
}/*for kernel_length*/
p_output_dev[j*width + i] = sum;
__syncthreads();
:
Beware that there is a thread-synchronization in the end : it is to keep all thread in the same block executes the same round. If there is no synchronization in the end, maybe some threads in the next round are renewing the shared memory content, meanwhile the others are fetching the data. In this condition, the fetching threads may get the wrong data, which are belong to the next round.
Result :
| input = 1400x1400 kernel = 31 100 Rounds | Runtime, ms | Computing time, ms |
|---|---|---|
| CUDA, pure copy | 161 ms | - |
| CUDA, simplest | 474 ms, 100% | 313 ms, 100% |
| CUDA, const | 294 ms, 160% | 136 ms, 230% |
| CUDA, const + shared † | 258 ms, 183% | 104 ms, 289 % |
† the block size is 28x28 in const + shared, not 32x32. Because the procedure of shared memory storing, requires the block size being able to divide the input size exactly.
The performance gets better, of course. But use nvprof for inspecting, there is a bank conflict in row function:
shared memory load transaction per request : 1.871
shared memory store transaction per request : 1.435
Thos values means, in average, a thread needs to try 1.435 times to put a datum in the shared memory; and 1.871 times to get a datum. It is not a good situation, bank conflict slows the performance.
※ Over two threads accessing the same shared memory bank concurrently brings the accessing serialized, this condition is called bank conflict. The shared memory bank number could be derived the computing : (share memory address/sizeof(DWORD)) % (32), where DWORD is a 4 bytes-sized.
There is one more issue : the operations of thread.y dominates in the row function, but the accessing sequence is still thread.x major. If we swap the accessing sequence as thread.y-major in the row function, how about the performance?
I have implemented that, convert the column function as thread.y-major :
p_input_in_block = &shared_mem[0]; block_width = blockDim.x + (kernel_length - 1);:
p_input_in_block = &shared_mem[0];
block_width = blockDim.x + (kernel_length - 1);
:
j = blockDim.y*blockIdx.y + threadIdx.y;
i = blockDim.x*blockIdx.x + threadIdx.x;
:
sum = 0;
ii = 0;
do {
p_input_in_block[threadIdx.x * block_height
+ jj*blockDim.y + threadIdx.y]
= p_extended_input_dev
[(j + jj*blockDim.y)*extended_width
+ kernel_radius + i];
jj++;
} while (threadIdx.y + jj * blockDim.y < block_height);
__syncthreads();
for (jj = 0; jj < kernel_length; jj++) {
sum += kernel_const_mem[jj] * p_input_in_block[
threadIdx.x*block_height + jj + threadIdx.y];
}/*for kernel*/
:
But the result is worse.
shared memory store transaction per request : 1.954
shared memory load transaction per request : 1.968
For the other example, kernel size = 21
shared memory store transaction per request : 12.377
shared memory load transaction per request : 12.387
Why the bank conflict is so serious ? It is because for CUDA is thread.x-major, the thread.y value is fixed in a warp round. In the block_height = 48 case, thread.x 0, thread.x 2, thread.x 4, ... thread.x 32, and thread.x 34 would access the same bank concurrently.
四. Solve the bank conflict.
Put the padding in shared memory is the most simple way. While the data is float type(a kind of DWORD) and the threads number is 32 in a block, it could solve the most bank conflict to increase the row size of the shared memory as an integer multiple of 32.
But, how about the threads number is not 32 ?
Based on my study, the formula is :
WARP_SIZE*n = original_row_size + (WARP_SIZE - blockDim.x) + padding
Where n is an integer, WARP_SIZE is 32. blockDim.x is the number of threads in x dimension of a block. And beware that original_row_size (blockDim.x + (kernel_length - 1)) is always greater than blockDim.x.
The meaning of above formula is, ensuring the small id threads access the small id banks except in the last round of each column.
To here, the share memory size for row is :
:
block_width = num_threads.x + (kernel_length - 1);
/*
padding
= WARP_SIZE*n - (block_size + (WARP_SIZE - num_threads))
*/
{
int temp = block_width + (WARP_SIZE - num_threads.x);
padding = WARP_SIZE*((temp + (WARP_SIZE - 1)) / WARP_SIZE)
- temp;
}/*local variable*/
shared_mem_size = sizeof(float)
* (block_width + padding) *(num_threads.y);
:
The row function needs to be modified to follow the padding in the shared memory :
:
p_input_in_block = &shared_mem[0];
block_width = blockDim.x + (kernel_length - 1);
shared_mem_pitch = block_width;
shared_mem_pitch += padding;
:
j = blockDim.y*blockIdx.y + threadIdx.y;
i = blockDim.x*blockIdx.x + threadIdx.x;
:
sum = 0;
ii = 0;
do {
p_input_in_block[threadIdx.y*shared_mem_pitch
+ ii*blockDim.x + threadIdx.x] =
p_column_done_extended_input_dev[j*extended_width
+ ii*blockDim.x + i];
ii++;
} while (threadIdx.x + ii * blockDim.x < block_width);
__syncthreads();
for (ii = 0; ii < kernel_length; ii++) {
sum += kernel_const_mem[ii] * p_input_in_block[
threadIdx.y*shared_mem_pitch + ii + threadIdx.x];
}/*for kernel_length*/
p_output_dev[j*width + i] = sum;
__syncthreads();
For column function, there is no bank conflict innately, so we leave it out.
Result :
| input = 1400x1400 kernel = 31 100 Rounds | Runtime, ms | Computing time, ms |
|---|---|---|
| CUDA, pure copy | 161 ms | - |
| CUDA, simplest | 474 ms, 100% | 313 ms, 100% |
| CUDA, const | 294 ms, 160% | 136 ms, 230% |
| CUDA, const + shared | 254 ms, 183% | 103 ms, 304 % |
| CUDA, const + shared + padding | 242 ms, 198% | 81 ms, 386 % |
nvprof shows there is not bank conflict.
shared memory store transaction per request : 1
shared memory load transaction per request : 1
Thus, avoiding bank conflict is able to improve performance.
五. Use read-only texture cache
※ Require the compute capability capability is 3.5 or higher (~ GT 7XX and later).
Besides using the shared memory, there is another way to improve the performance. Review the simplest CUDA functions -all data are in global memory-, we could find the kernel data and input data would be loaded many times, as the requires of using constant and using shared memory:
:
for (; j < height; j += blockDim.y * gridDim.y) {
:
for (; i < width; i += blockDim.x * gridDim.x) {
:
:
for (ii = 0; ii < kernel_length; ii++) {
sum += p_kernel_row_dev[ii]
* p_column_done_extended_input_dev[y_mul_input_width + x];
:
}/*for kernel_length*/
:
}/*for width*/
}/*for j*/
:
It is a good condition to store the kernel and input data into the L2 read-only cache :: the intrinsic function __ldg(&VAR) :
:
sum += __ldg(&p_kernel_row_dev[ii])
* __ldg(&p_column_done_extended_input_dev[y_mul_input_width + x]);
:
Result :
| input = 1400x1400 kernel = 31 x 31 100 Rounds | Runtime, ms | Computing time, ms |
|---|---|---|
| CUDA, pure copy | 161 ms | - |
| CUDA, simplest | 474 ms, 100% | 313 ms, 100% |
| CUDA, const | 297 ms, 160% | 136 ms, 230% |
| CUDA, const + shared | 254 ms, 183% | 103 ms, 304 % |
| CUDA, const + shared + padding | 242 ms, 198% | 81 ms, 386 % |
| CUDA, simplest + ldg | 298 ms, 159% | 135 ms, 229% |
| CUDA, const + ldg | 252 ms,, 182% | 101 ms, 302% |
nvprof shows why there is the improvement, the values in the brace correspond to column/row function respectively:
Unified cache hit rate :
simplest : 51.3%/50.9%
const : 42.7%/41.7%
--------------------------------------------
simplest + ldg : 83.5%/95.9%
const + ldg : 80%/94.5%
High hit rate means the high performance.
六. Summary
0. USE nvprov to inspect why the performance is bad/good.
1. Use Pinned host memory to boost the transmission.
2. If all threads in a block fetch the value from the same global memory address, the data should be place in the constant memory.
3. Use shared memory as many as possible for its high speed, but the bank conflict issue must be solved, at less it be mitigated.
4. __ldg is able to improve the loading data speed from global memory while the same addresses would be accessed many times.
Reference :
Professional CUDA C Programming, by John Cheng Max Grossman , Ty McKercher, Wrox, 2014

















 4979
4979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









