









 本文介绍Elasticsearch 5.0版本引入的新脚本语言Painless的特点及应用场景,对比Groovy脚本,Painless更安全高效。文章通过实例演示如何使用Painless进行文档查询与更新。
本文介绍Elasticsearch 5.0版本引入的新脚本语言Painless的特点及应用场景,对比Groovy脚本,Painless更安全高效。文章通过实例演示如何使用Painless进行文档查询与更新。
记得以前写过一个postman的最强教程,只可惜因为工作的原因,没再继续做测试,最终也没有写完。有点丧。。。这段时间在研究实时日志分析系统ELK,发现围绕ES这个搜索引擎或者说document数据库而开发的各种工具和周边居然是令人震惊的完善。ES真的不单单是一个分词,搜索的引擎,在各种功能和应用场景的完备性上已经不输很多数据库产品,比如mongoDB。本文着重介绍的ES 5.0版本后推出painless。(不过看来是个冷门,没人用啊)
何为painless
ElasticStack在升级到5.0版本之后,带来了一个新的脚本语言,painless。这里说“新的“是相对与已经存在groove而言的。还记得Groove脚本的漏洞吧,Groove脚本开启之后,如果被人误用可能带来各种漏洞,为什么呢,主要是这些外部的脚本引擎太过于强大,什么都能做,用不好或者设置不当就会引起安全风险,基于安全和性能方面,所以elastic.co开发了一个新的脚本引擎,名字就叫Painless,顾名思义,简单安全,无痛使用,和Groove的沙盒机制不一样,Painless使用白名单来限制函数与字段的访问,针对es的场景来进行优化,只做es数据的操作,更加轻量级,速度要快好几倍,并且支持Java静态类型,语法保持Groove类似,还支持Java的lambda表达式。
painless的特性
painless可以用在所有可以使用script的场景下,并具有以下特性:
- 高性能。painless在es的运行速度是其他语言的数倍。
- 安全。使用白名单来限制函数与字段的访问,避免了可能的安全隐患
- 可选类型。你可以在脚本当中使用强类型的编程方式或者动态类型的编程方式。
- 语法。扩展了java的基本语法以兼容groove风格的脚本语言特性,使得plainless易读易写
- 有针对的优化。这门语言是为elasticsearch专门定制的。
简单的例子
要了解这门东西,肯定要先看看它能做到什么才能激发起兴趣。先简单看一下例子,和各种groove,python,js们,没有什么区别,但要特别注意,使用强类型编程方式可以极大的加快运行速率
#动态类型的写法
def first = input.doc.first_name.0;
def last = input.doc.last_name.0;
return first + " " + last;
#强类型(10倍速度于上面的动态类型)
String first = (String)((List)((Map)input.get("doc")).get("first_name")).get(0);
String last = (String)((List)((Map)input.get("doc")).get("last_name")).get(0);
return first + " " + last;具体例子
初始化数据
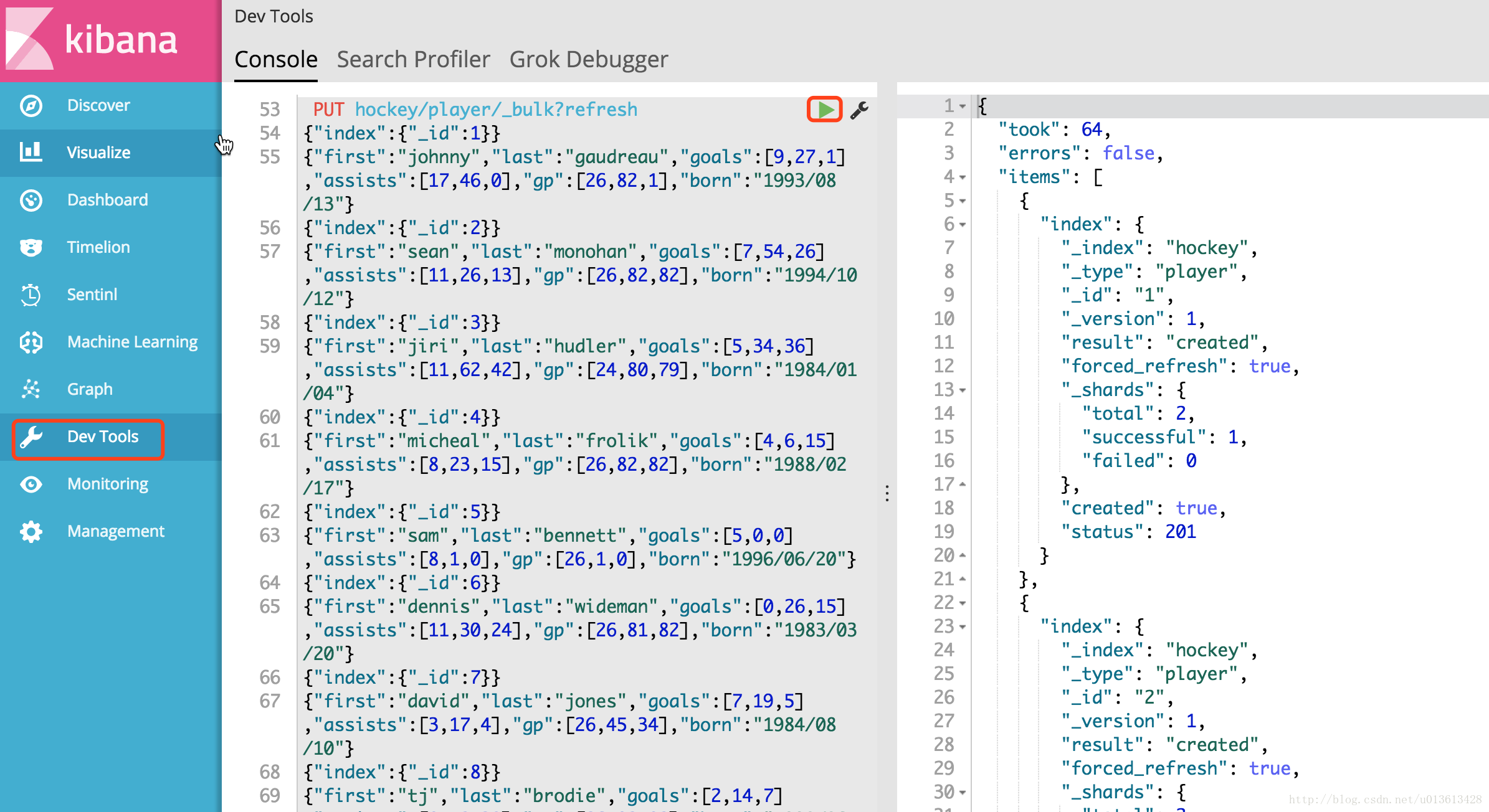
我们先输入一串曲棍球的数据到ES当中。
PUT hockey/player/_bulk?refresh
{"index":{"_id":1}}
{"first":"johnny","last":"gaudreau","goals":[9,27,1],"assists":[17,46,0],"gp":[26,82,1],"born":"1993/08/13"}
{"index":{"_id":2}}
{"first":"sean","last":"monohan","goals":[7,54,26],"assists":[11,26,13],"gp":[26,82,82],"born":"1994/10/12"}
{"index":{"_id":3}}
{"first":"jiri","last":"hudler","goals":[5,34,36],"assists":[11,62,42],"gp":[24,80,79],"born":"1984/01/04"}
{"index":{"_id":4}}
{"first":"micheal","last":"frolik","goals":[4,6,15],"assists":[8,23,15],"gp":[26,82,82],"born":"1988/02/17"}
{"index":{"_id":5}}
{"first":"sam","last":"bennett","goals":[5,0,0],"assists":[8,1,0],"gp":[26,1,0],"born":"1996/06/20"}
{"index":{"_id":6}}
{"first":"dennis","last":"wideman","goals":[0,26,15],"assists":[11,30,24],"gp":[26,81,82],"born":"1983/03/20"}
{"index":{"_id":7}}
{"first":"david","last":"jones","goals":[7,19,5],"assists":[3,17,4],"gp":[26,45,34],"born":"1984/08/10"}
{"index":{"_id":8}}
{"first":"tj","last":"brodie","goals":[2,14,7],"assists":[8,42,30],"gp":[26,82,82],"born":"1990/06/07"}
{"index":{"_id":39}}
{"first":"mark","last":"giordano","goals":[6,30,15],"assists":[3,30,24],"gp":[26,60,63],"born":"1983/10/03"}
{"index":{"_id":10}}
{"first":"mikael","last":"backlund","goals":[3,15,13],"assists":[6,24,18],"gp":[26,82,82],"born":"1989/03/17"}
{"index":{"_id":11}}
{"first":"joe","last":"colborne","goals":[3,18,13],"assists":[6,20,24],"gp":[26,67,82],"born":"1990/01/30"}
这里极其建议在练习的时候使用kibana上的Dev Tools,这个东西有多好用谁用谁知道,它可以自动补齐es的各种query语法,牛不牛?而且就像markdown一样,做到左右分屏,所见即所得。
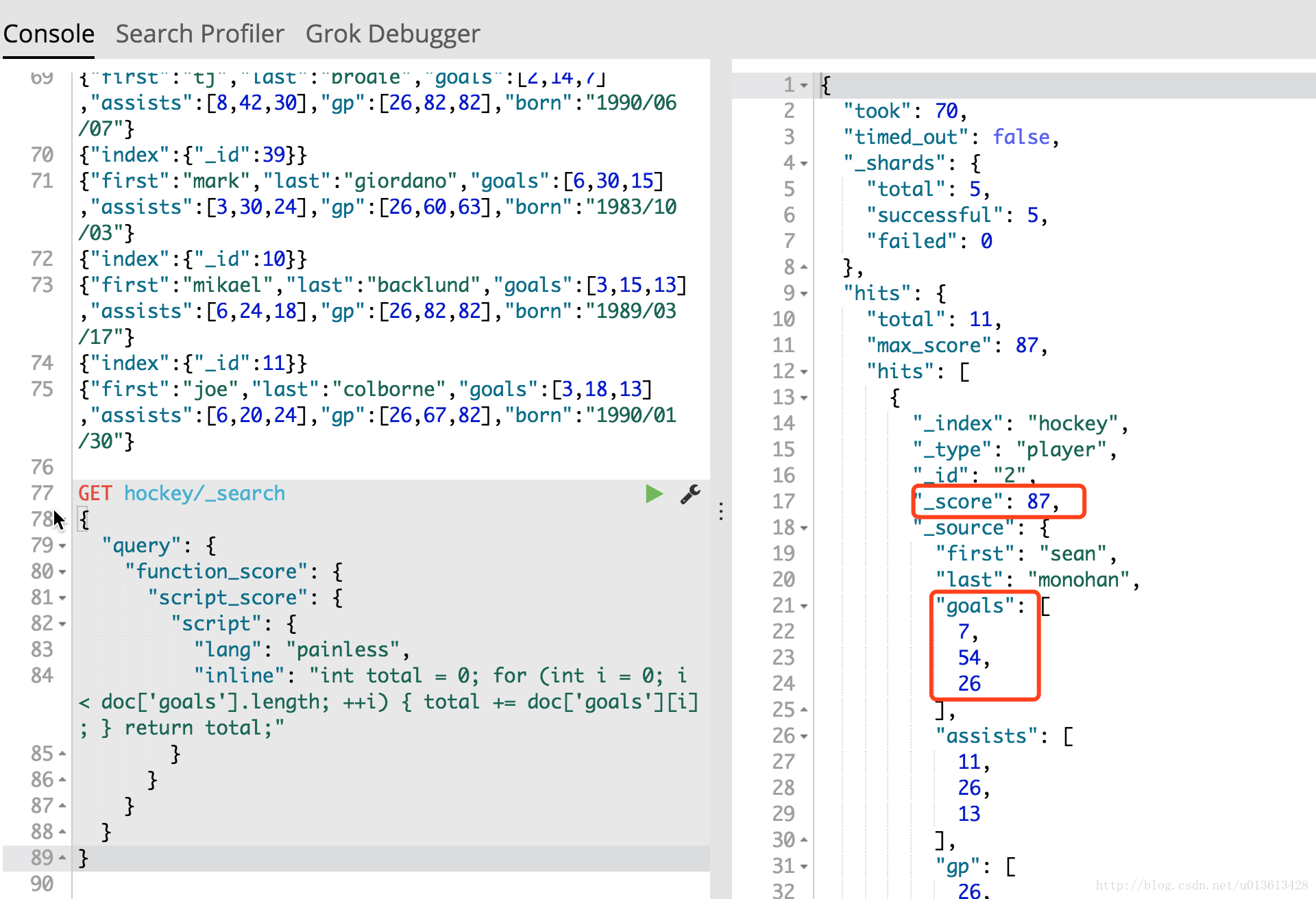
用painless获取doc的值
下面的例子中,我们通过function_score::script_score更新每个document的score。其中用到了for循环,和强类型定义int。
可以看到运行之后,_score的值,编程了goals值的sum。
以下是更多的取值的例子:
GET hockey/_search
{
"query": {
"match_all": {}
},
"script_fields": {
"total_goals": {
"script": {
"lang": "painless",
"inline": "int total = 0; for (int i = 0; i < doc['goals'].length; ++i) { total += doc['goals'][i]; } return total;"
}
}
}
}GET hockey/_search
{
"query": {
"match_all": {}
},
"sort": {
"_script": {
"type": "string",
"order": "asc",
"script": {
"lang": "painless",
"inline": "doc['first.keyword'].value + ' ' + doc['last.keyword'].value"
}
}
}
}这里需要注意几点:
- 这里都是_search操作,多个操作之间会形成管道,既
query::match_all的输出会作为script_fields或者sort的输入。 - _search操作中所有的返回值,都可以通过一个
map类型变量doc获取。和所有其他脚本语言一样,用[]获取map中的值。这里要强调的是,doc只可以在_search中访问到。在下一节的例子中,你将看到,使用的是ctx。 - _search操作是不会改变document的值的,即便是
script_fields,你只能在当次查询是能看到script输出的值。 doc['first.keyword']这样的写法是因为doc[]返回有可能是分词之后的value,所以你想要某个field的完整值时,请使用keyword
通过painless更新对象值
上一节讲了如何读取值,在读取值的时候,query的response虽然能够读到一个新值,但这个值并没有写入document当中。要更新值,需要通过_updateAPI。
单条记录更新
如下图,通过_updateAPI的script,我们可以增加一个新的field:nick:
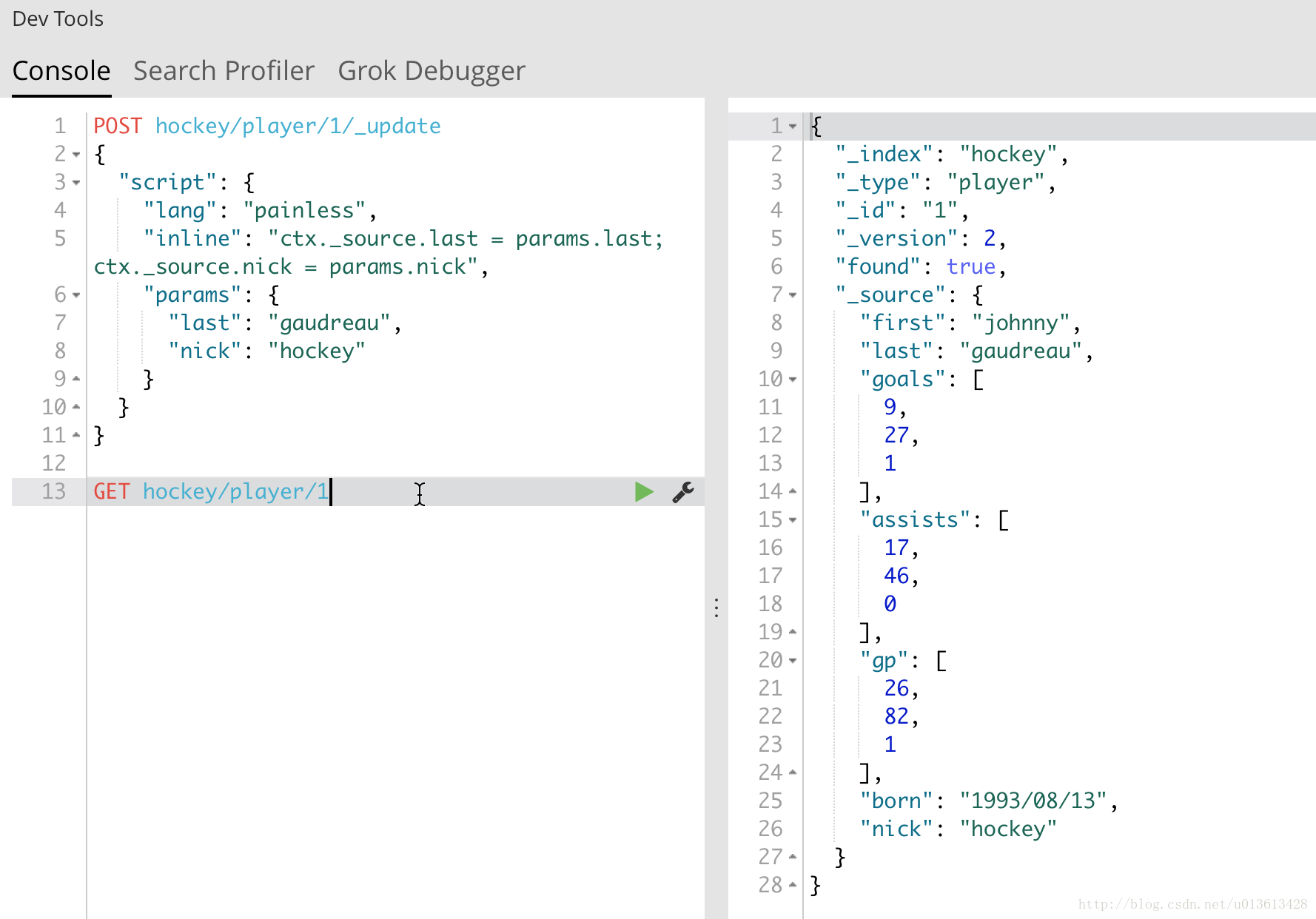
可以更改一个值:
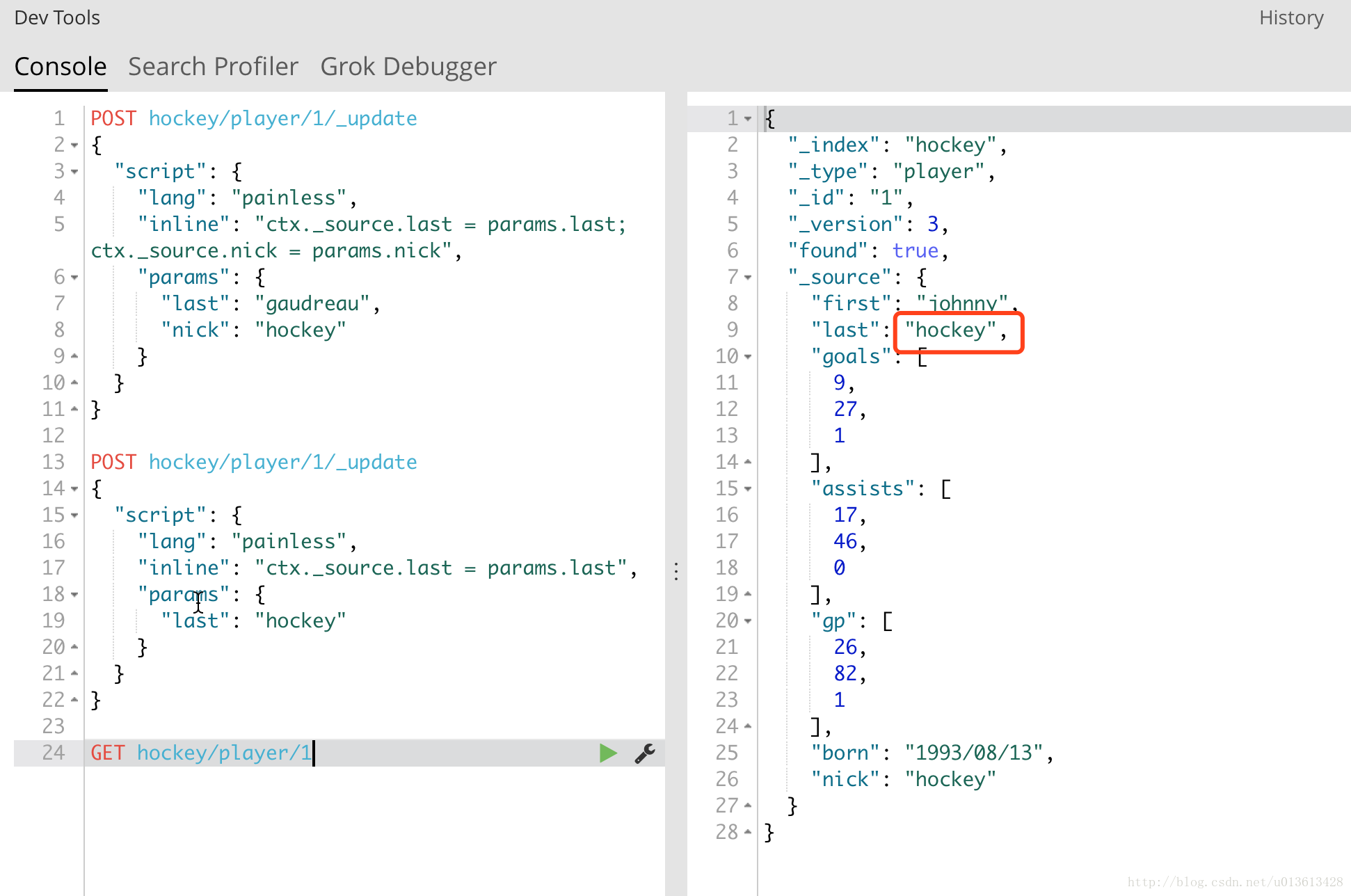
这里需要注意的是:我们不再使用doc来访问对象,而是用ctx。
批量更新
在大多数应用场景下,我们是很少用到_updateAPI的。(当然,这里不包括你用python, java等语言用for循环多条更新)。在批量更新的场景,我推荐的是_update_by_queryAPI。
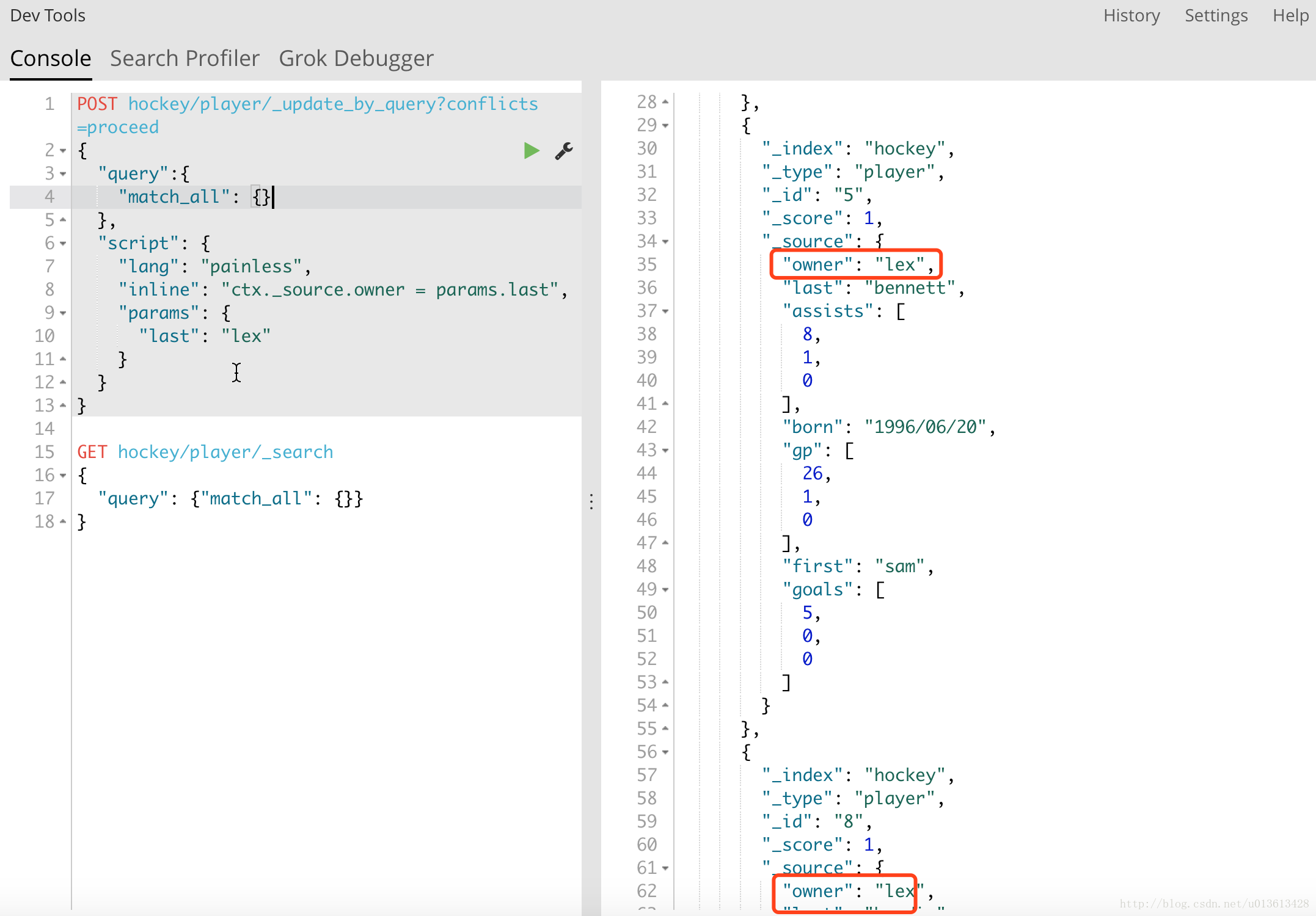
这里需要注意的是:
- 虽然
_update_by_queryAPI在批量更新时,和我们第一个例子很像,先query,再update,通过管道修改全部的值。但这里仍然只能用ctx,而不是doc。如果用doc,会抛出nullpointerException。 - 另外,在例子中,我用的是match_all query,但实际上你可以用各种query,来划定精确的query范围,只修改你想修改的值。
Dates
Date类型的field会被解析成ReadableDateTime。所以它可以支持 getYear, getDayOfWeek等方法。 例如,要取milliseconds,就屌用getMillis方法。下面的例子,取每个球员是哪年出生的:
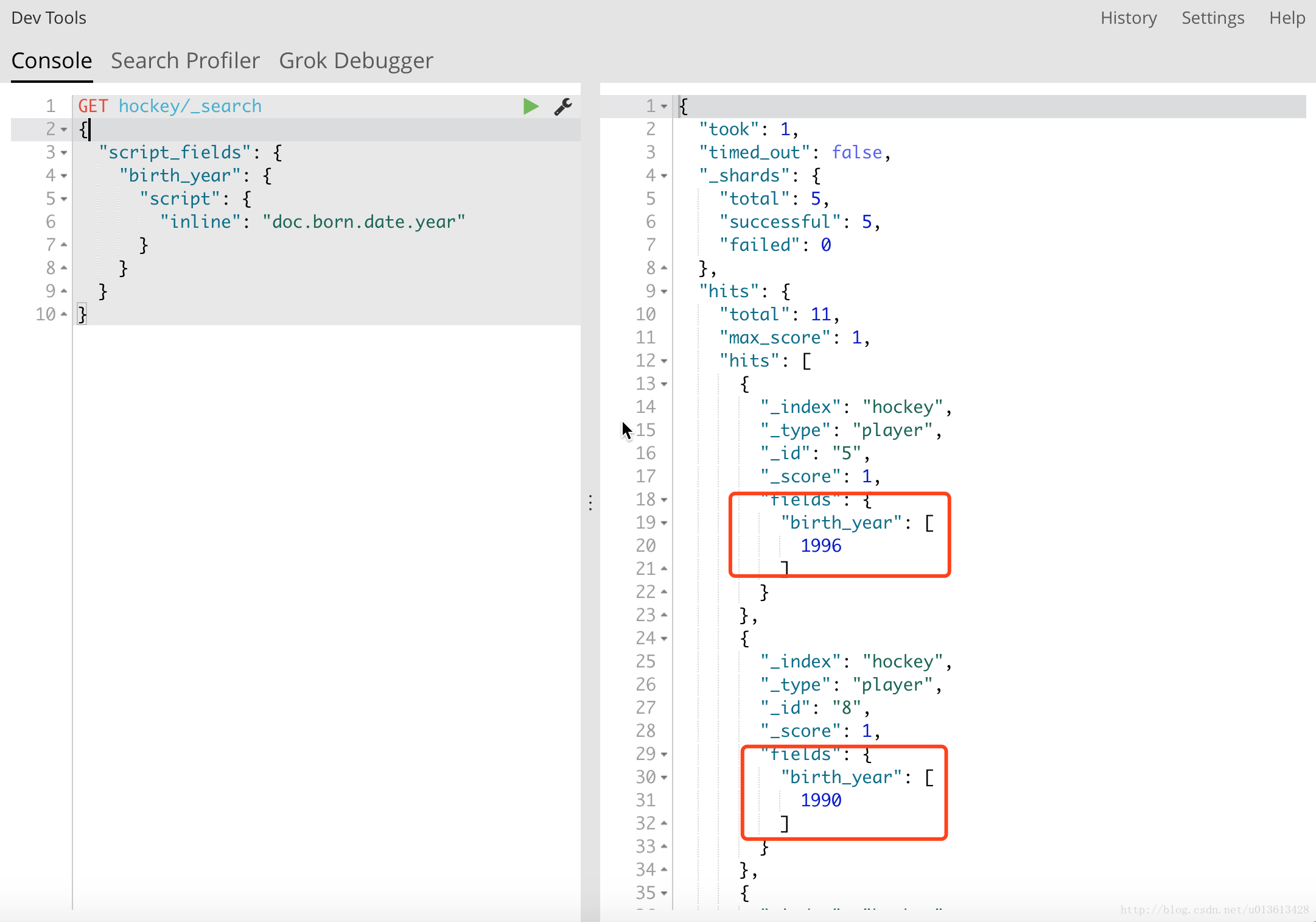

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









