








这篇文章发表在arXiv.org网站上,好像还没有论文发表,不过出了两个专利。
卷积神经网络里面有两个主要的操作,一个是卷积,另外一个是池化。本文主要研究的就是池化(pooling)。
作者在abstract里面指出,(现在的卷积层是学习得到的),而对于pooling层,现在两个主要的pooling方法,一个是average pooling, 另外一个是max pooling,都不是学习的到的。(average pooling是把所有样本取平均值,max pooling 是取所有样本的最大值。)
如果pooling层也是学习得到的,就可以提高深度学习网络的效果。
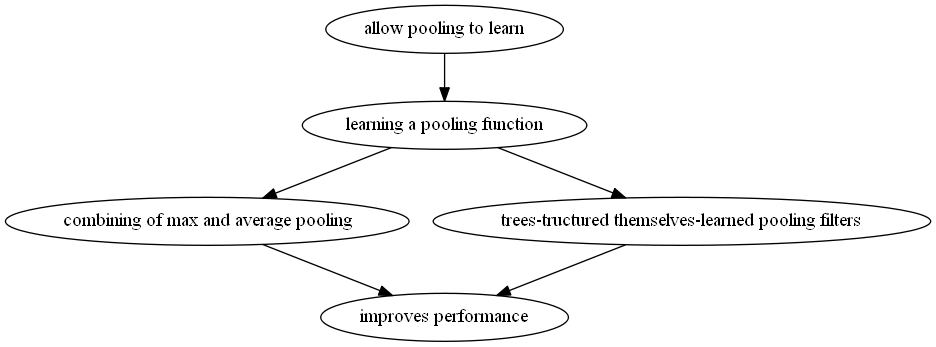
在这个基础上,作者提出了两个学习pooling的方法,一个是把average pooling和max pooling结合在一起学习一个池化的函数。
另外一个是构建一个树状的自学习池化滤波器。
作者把他们提出的池化方法称为generalized pooling operation,在实验中,所有的generalized pooling operation方法,得到的结果就比average pooling和max pooling好

实验表明,这种池化方法在不变性方面得到了“飞跃”(boost),在一系列benchmark 上刷新了state of the art,易于实现,适用于各种网络结构,而计算复杂度和参数只增加了一点点。
本文分为以下六个部分。

1. Introduction

在Introduction中,作者首先指出最近的研究集中在复杂的网络结构和非线性激活函数上,对pooling的修改比较少,所以作者觉得做一下pooling的改进可以提高网络的性能。

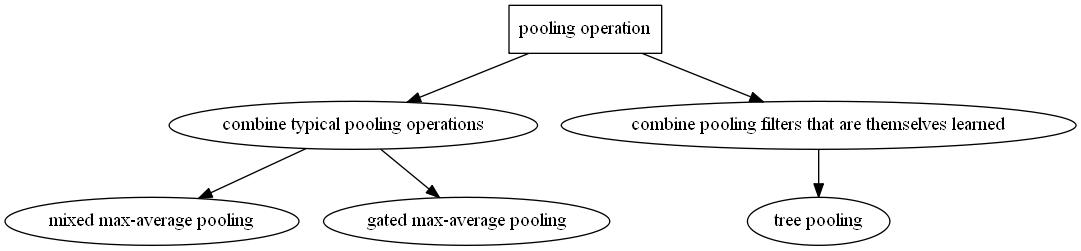
作者提出了两个pooling方法,一个是把传统的pooling方法组合起来,另外一个是组合一些学习到的pooling方法。
组合传统的pooling方法又包括两种,一个是单纯的把max pooling和average pooling组合起来,另外一个是把max pooling和average pooling组合起来再加一个门限。
组合学习到的pooling方法用到了二叉树,因此也称为“tree pooling”。
在Introduction里,作者还强调了tree pooling的几个特性。
首先就是树的层数是预先确定的
然后就是tree pooling可以从数据中直接学习到池化的滤波器
还有就是tree pooling将叶子节点的输出结合起来作为双亲结点的输入
最终达到——根据被池化区域的特征得到不同的池化的结果。

作者进行的实验是在一个特定的网络结构上把他原来的pooling方法改成作者提出的pooling方法,然后在benchmark上做实验,都达到了state-of-the-art。

本篇论文中提出的pooling方法可以简单替代原来的池化方法,也可以与其他部分的改进串联应用,在DSN-style architecture, AlexNet and GoogLeNet结构上都提高了网络的性能。计算复杂度只提高了5%到15%,网络的参数也提高不多。

2.Related Work
关于池化方法,传统的主要有三种,取最大值的max pooling, 取平均值的average pooling, 以及根据feature map中的元素按照其概率值大小随机选择(即元素值大的被选中的概率也大)的stochastic pooling。
最近对于多尺度图片出了一个空间金字塔的池化方法,但是这个方法也没有对池化函数作深入的研究。学习池化函数与感受野学习(receptive field learning)有些相似,但是从这个角度出发设计的算法学习过程太过复杂,所以网络的性能并不好,在CIFAR10上只跑出了16.89%的成绩。

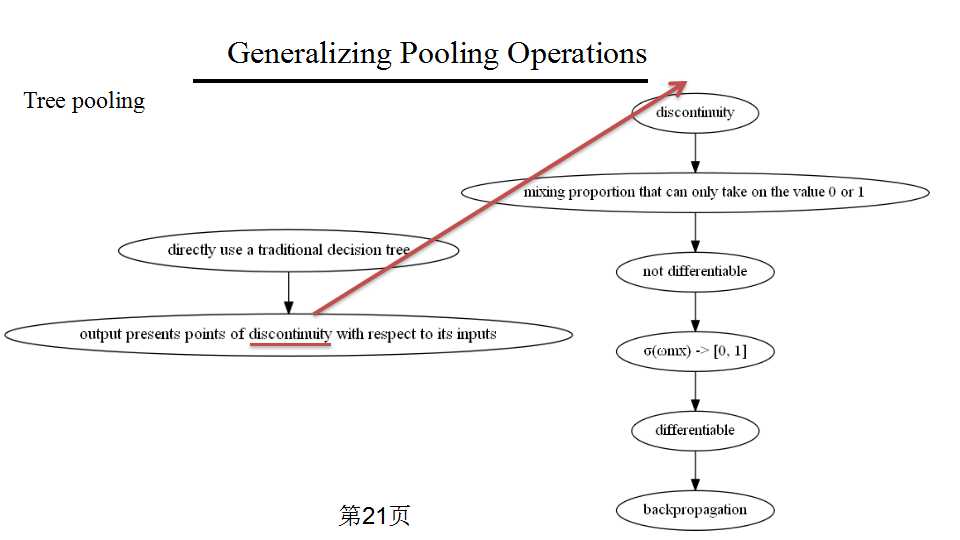
作者的tree pooling的思想来源于决策树,为什么以前没有人把决策树用在CNN里面呢?因为CNN训练的时候要用反向传播算法求导,但标准的决策树的输出没法对输入求导。作者提出的方法的一个重大贡献就是他的池化函数是可以求导的。

深度学习中的树型结构,必须得是可导的。在这个方面,有人提出了auto-encoder trees。但是这个方法与本方法的显著区别在于这个"auto-encoder trees"处理的是编码和解码的问题,本文方法处理的是pooling问题。这个"auto-encoder trees"用的是一个“soft”(连续的)决策树。还有人把多层感知机(MLP)放在决策树里面,但是训练的效果不好,而且也没能训练出一个池化滤波器来。

3.Generalizing Pooling Operations

一的典型的卷积神经网络由一系列卷积层和池化层构成,卷积层提取的是空间域的局部特征,池化层起到一个“压缩”的作用。
下面是论文的基本结构:

首先说这个“Mixed” max-average pooling。
average pooling是把池化区域的所有像素取平均值,max pooling是把所有像素取最大值。
这两种池化方法在不同的情况下各有优劣,有的时候这种方法好,有的时候那种方法好。
所以一个自然的想法就是把他们放在一起,根据不同的情况决定用哪种方法,或者说根据不同的情况决定用哪种方法多一些。
就是下面的这个式子,max pooling和average pooling前面乘以一个大于0小于1的系数。
这个系数可以是
(1)整个网络共用一个系数
(2)每层共用一个系数
(3)所有通道的同一区域共用一个系数
(4)某一区域的所有通道共用一个系数
(5)某个层、通道和区域的组合共用一个系数。

然后,就像related work里面讲到的,这个fmix(x)函数应该既可以对参数a求导,又可以对样本xi求导的。前者用来学习参数xi,后者用来学习得到权重。
损失函数E的这两个导数如下所示,根据的是求偏导数的链式法则,第一个导数可以直接看出来,第二个导数的1[]函数表示,如果被求导的参数xi是最大的就取1,反之就取0;
这个池化方法的示意图如下图所示,拿一个3乘3的区域来看,就是对被池化区域的9个像素点取平均值和最大值,然后计算出一个fmix(x):

但是这个方法有个问题,就是这个参数a一旦学习之后就保持不变了,如果a是每一层共用一个的话,就意味着一旦训练结束这个a就不变了,也就意味着池化的方法与被池化区域的特性无关,这样不太好,最好是有一个类似自适应的池化方法,根据被池化区域的特征确定池化方法。在这个方法中,我们并不是直接学习出一个确定的池化公式,而是学习出一个“门限模板”(“gating mask”),它的大小正好是被池化区域的大小。
可以比较一下这两种方法,可以看出来第二种方法是第一种方法的改进,就是把第一种方法的权值变成了门限权值矩阵与被池化区域的像素值的内积,然后映射到【0,1】内。第一种方法学习的是a,第二种方法学习的是权值矩阵w,这样的话第一种方法的池化函数的参数完全是训练出来的,与被池化区域无关,而第二种方法的池化函数与训练和被池化区域都有关系,这样比较合理。也就是说,一个完成训练的网络处理一张图片的时候,池化的权值是固定的,不携带这张图片本身的信息,但是被池化区域矩阵x携带了这张特定图片自身的信息。

然后跟第一种方法一样,也是将损失函数对w和x分别求导。上面的是用来学习权值矩阵w的,下面的是用来学习卷积层的权重的。

然后作者将这两个方法进行了对比。
这些实验用的是同一个网络模型,baseline是max pooling
第二行是stochastic pooling,根据feature map中的元素按照其概率值大小随机选择。
第三行是a值为0.5的mix pooling
第三行是每层共用一个a值的mix pooling。
第四行是每一层的每个通道的每个区域用一个a值的mix pooling,可以看出他的效果有明显的提高,但是多出来的参数实在是太多了。
第五行是第二种方法,每层共用一个w,可以看出他和上一个的效果差不多,但是参数少很多,所以这个最好。

Tree pooling 的池化方法
首先,用一个池化滤波器与被池化区域做内积,比如我们有四个池化滤波器,分别做完内积就是四个叶子节点。
然后,用gated pooling的思路,四个叶子节点的数值分别乘以gated pooling的权重再相加,得到两个节点。
最后,这两个节点再做一次gated pooling,得到根节点,根节点的值就是这个区域池化得到的结果。
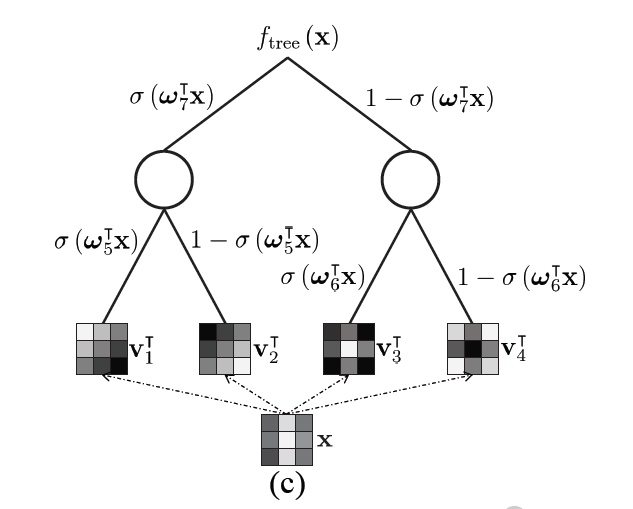

作者分析了传统的二叉决策树为什么不能直接用在CNN里,就是因为标准二叉决策树的输出对于输入来说是离散的,所以不可导。用本文中的思想可以理解为在fmix(x)函数里的权值只能取0或1.所以作者很自然地想到把决策树的权值变成【0,1】区间,这样决策树对各种参数都可导,就可以用反向传播算法训练了。
作者照例求了损失函数对各种参数的导数,前三个偏导数分别是用来学习两个池化滤波器和gated pooling里面的权重矩阵的,最后的一个偏导数是反向传播算法中那个反向传播的误差。

然后作者对tree pooling的效果也做了实验。
结论是基本上tree pooling的层数多一点比较好,实验效果最好的是用两个pooling层,第一个pooling层用tree pooling,第二个pooling层用gated max-avg。
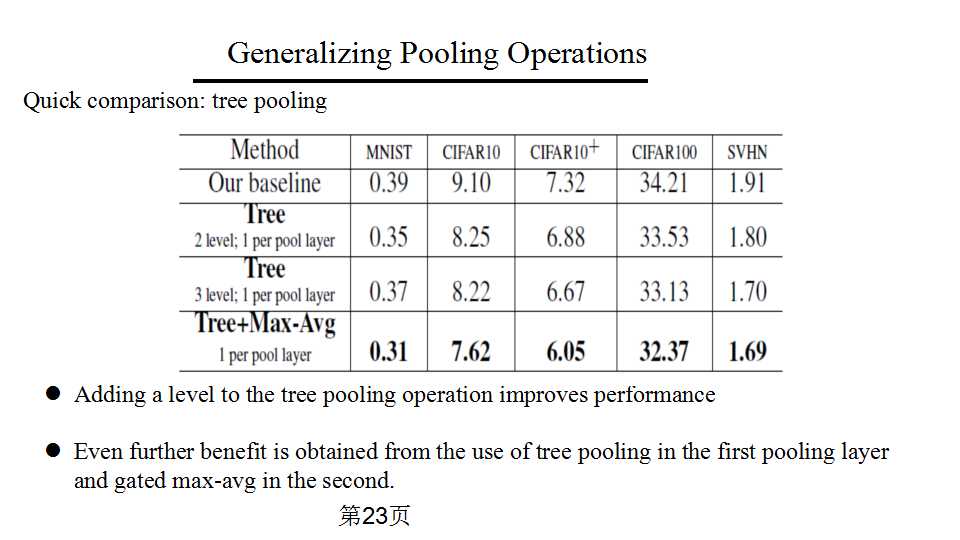
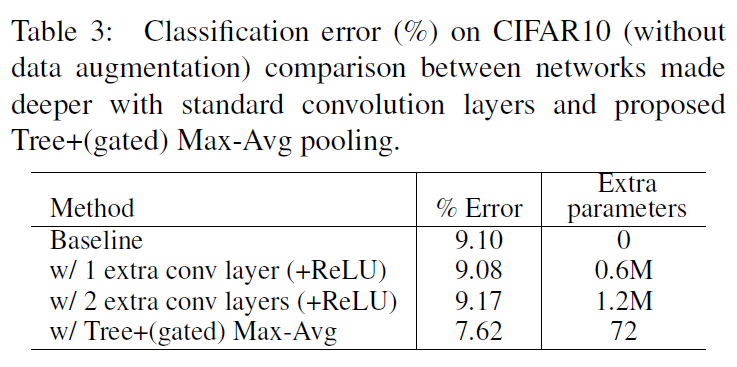
作者对比了单纯增加卷积层和增加一个tree pooling层和一个gated max-avg pooling层的效果,结论是如果采用tree pooling + gated max-avg pooling,只增加72个参数,但是提升的效果远远超过单纯增加两个卷积层。
4.Quick Performance Overview

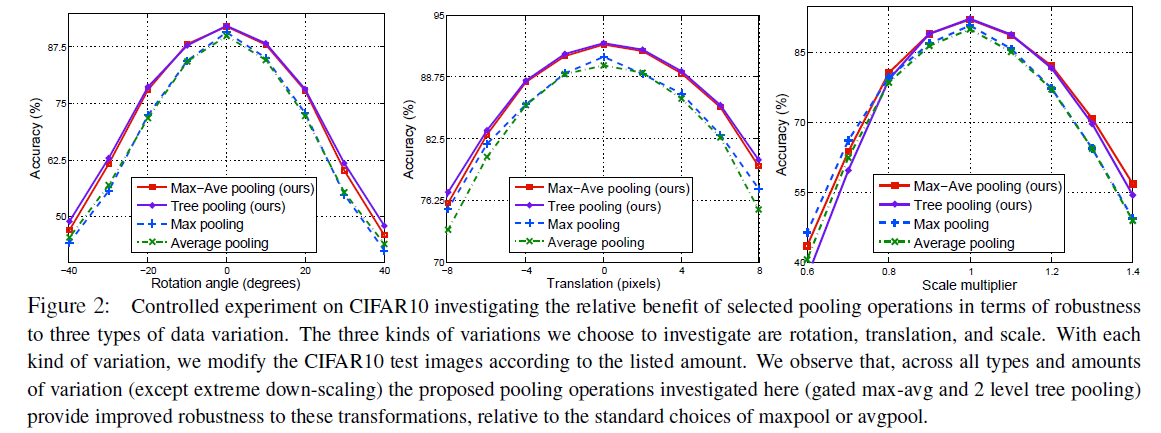
因为池化主要提高了网络对图片的各种变换的鲁棒性,作者做了几种池化方法对旋转、平移和缩放三种变换的鲁棒性的实验,结果是gated max-avg和 2 level tree pooling的效果差不多好, 2 level tree pooling的效果稍微好一点,gated max-avg和 2 level tree pooling的效果远好于单纯的maxpool 或 avgpool
作者随后又做了时间的实验,在CIFAR10上统计了平均用时。

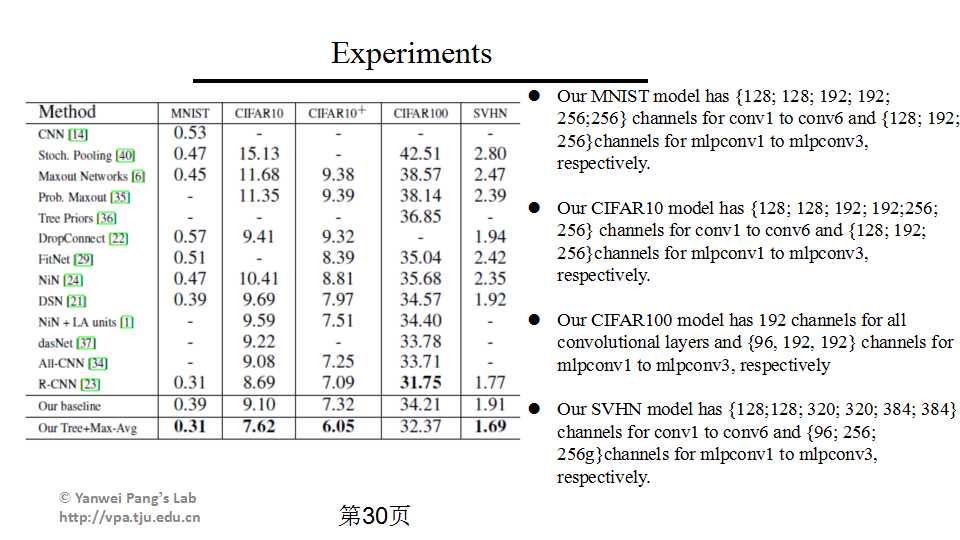
作者在minist cifar10 cifar100 SVHN 上都做了实验,除了CIFAR100都刷新了state-of-the-art。
此外,作者在Imagenet 2012上对Alexnet和Googlenet应用了论文中提出的方法,结果都有提高。
最后的Observations from Experiments基本上就是一个conclusion,结论就是本文提出的方法适用于各种图片数据库和各种网络结构,可以显著地提高网络的分类效果。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









