







JOIN
hive执行引擎会将HQL“翻译”成为map-reduce任务,如果多张表使用同一列做join则将被翻译成一个reduce,否则将被翻译成多个map-reduce任务。
如:
hive执行引擎会将HQL“翻译”成为map-reduce任务,如果多张表使用同一列做join则将被翻译成一个reduce,否则将被翻译成多个map-reduce任务。
eg:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)将被翻译成1个map-reduce任务
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
将被翻译成2个map-reduce任务
这个很好理解,一般来说(map side join除外),map过程负责分发数据,具体的join操作在reduce完成,因此,如果多表基于不同的列做join,则无法在一轮map-reduce任务中将所有相关数据shuffle到统一个reducer
对于多表join,hive会将前面的表缓存在reducer的内存中,然后后面的表会流式的进入reducer和reducer内存中其它的表做join.
为了防止数据量过大导致oom,将数据量最大的表放到最后,或者通过“STREAMTABLE”显示指定reducer流式读入的表
Join的实现原理
统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Join(Map阶段完成join)。本文简单介绍一下两种join的原理和机制。
Common Join
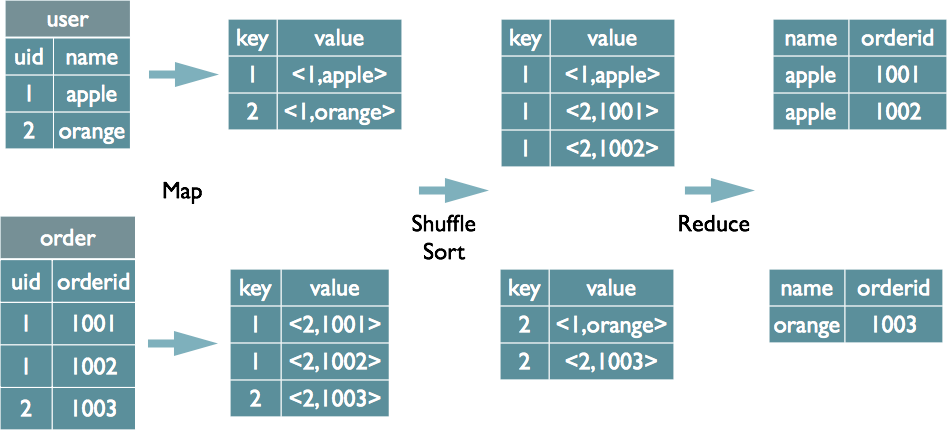
select u.name, o.orderid from order o join user u on o.uid = u.uid;
Map阶段
读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
按照key进行排序Shuffle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中Reduce阶段
根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
Map Join
MapJoin通常用于一个很小的表和一个大表进行join的场景,具体小表有多小,由参数hive.mapjoin.smalltable.filesize来决定,该参数表示小表的总大小,默认值为25000000字节,即25M。
Hive0.7之前,需要使用hint提示 /+ mapjoin(table) /才会执行MapJoin,否则执行Common Join,但在0.7版本之后,默认自动会转换Map Join,由参数hive.auto.convert.join来控制,默认为true.
仍然以9.1中的HQL来说吧,假设a表为一张大表,b为小表,并且hive.auto.convert.join=true,那么Hive在执行时候会自动转化为MapJoin。
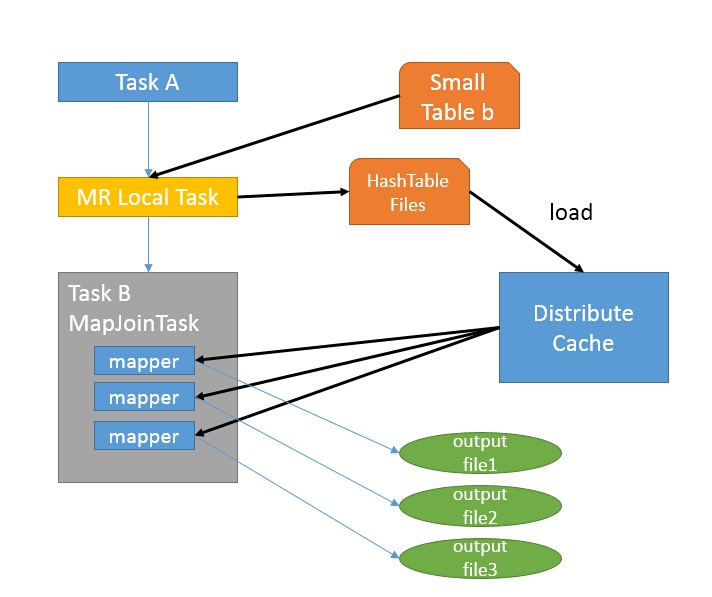
- 如图中的流程,首先是Task A,它是一个Local Task(在客户端本地执行的Task),负责扫描小表b的数据,将其转换成一个HashTable的数据结构,并写入本地的文件中,之后将该文件加载到DistributeCache中,该HashTable的数据结构可以抽象为:
| key | Value |
|---|---|
| 1 | 26 |
| 2 | 34 |

图中红框圈出了执行Local Task的信息。
- 接下来是Task B,该任务是一个没有Reduce的MR,启动MapTasks扫描大表a,在Map阶段,根据a的每一条记录去和DistributeCache中b表对应的HashTable关联,并直接输出结果。
由于MapJoin没有Reduce,所以由Map直接输出结果文件,有多少个Map Task,就有多少个结果文件。
总的来说,因为小表的存在,可以在Map阶段直接完成Join的操作,为了优化小表的查找速度,将其转化为HashTable的结构,并加载进分布式缓存中。
Hive 在倾斜表的Join优化
Join的过程中,Map结束之后,会将相同的Key的数据shuffle到同一个Reduce中,如果数据分布均匀的话,每个Reduce处理的数据量大体上是比较均衡的,但是若明显存在数据倾斜的时候,会出现某些Reducer处理的数据量过大,从而使得该节点的处理时间过长,成为瓶颈。
在已经知道数据的情况下,可以人为的进行语句的拆分。
如:表A与表B进行Join,在明知Id=1的数据明显的存在数据倾斜,可以将语句select A.id from A join B on A.id = B.id拆分为以下两条:
select A.id from A join B on A.id = B.id where A.id <> 1;
select A.id from A join B on A.id = B.id where A.id = 1 and B.id = 1;优点:
针对只有少量的Key会产生数据倾斜的场景下非常的有用。
缺点:
表A和表B需要被读和处理两次。处理的结果也需要读和写两次。
需要人为的去找出这些产生数据倾斜的Key,并手动拆分处理。
Hive优化的方法:
首先读取表B,并将key为1的行存储为HashTable,放入到分布式缓存中(为了使用MapJoin),然后运行一些Map任务去读表A,并按照以下流程进行处理:
If it has key 1, then use the hashed version of B to compute the result.
For all other keys, send it to a reducer which does the join. This reducer will get rows of B also from a mapper.这种方法可以避免读取B两次,表A中的倾斜Key会使用MapJoin方式进行处理。
以上的这些假设是针对B有少量的行的key与表A中的倾斜Key相同,因此这些行可以加载进内存中。
Hive的实现
Hive 0.10.0开始,Hive表可以被创建为倾斜表或这是更改为倾斜表(in which case partitions created after the ALTER statement will be skewed)。In addition, skewed tables can use the list bucketing feature by specifying the STORED AS DIRECTORIES option。
Hive可以从倾斜表中读取出产生数据倾斜的Key(这些都是创建或更改为倾斜表时手动指定的倾斜Key).
本文参考以下内容:
- https://cwiki.apache.org/confluence/display/Hive/Skewed+Join+Optimization
- http://www.aboutyun.com/thread-20461-1-1.html
- http://lxw1234.com/archives/2015/06/313.htm















 4182
4182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









