







注:机翻,未校。
此系列文章整理自不同时期,生料有重叠,未整理去重。
Why Are There 8 Bits in a Byte?
为什么一个字节有 8 位?
Hello young explorers! Today, we’re diving into a digital mystery: Why are there 8 bits in a byte? This might sound like a simple question, but it takes us on an adventure through the history of computers and how they think!
你好,年轻的探索者们!今天,我们将深入一个数字谜团:为什么一个 字节 有 8 个 比特 ?这个问题听起来可能很简单,但它将带我们踏上一段探索计算机历史以及计算机思维方式的冒险之旅!
What’s a Bit? What’s a Byte?
什么是比特?什么是字节?
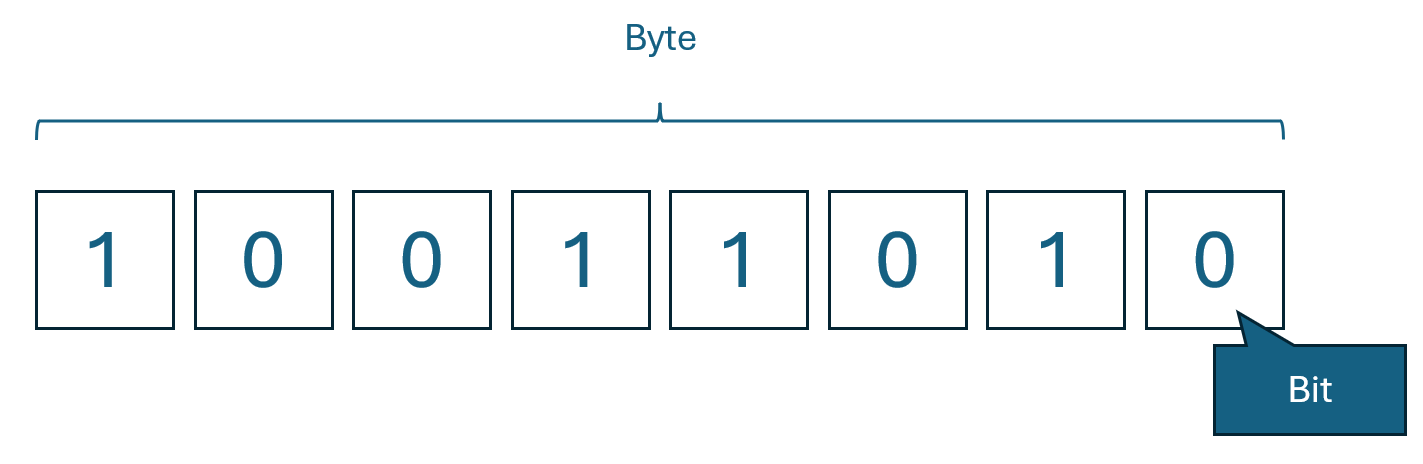
First, let’s talk about what bits and bytes are. A bit is the smallest unit of data in computing. It’s like a tiny light switch that can be either off (0) or on (1).
首先,我们来谈谈比特和字节是什么。比特是计算机中最小的数据单位。它就像一个微小的开关,可以处于关闭状态(0)或打开状态(1)。
A byte, on the other hand, is a group of bits that work together to represent something more significant, like a letter on your keyboard or a color in a picture.
而字节则是一组协同工作的比特,用来表示一些更有意义的东西,比如键盘上的一个字母或图片中的一种颜色。
The Journey to 8 Bits
Long ago, in the early days of computing, there wasn’t a standard size for these groups of bits. Different computers used different sizes, like 5, 6, 7, or even up to 12 bits per group!
很久以前,在计算机的早期,这些比特组合并没有一个标准的大小。不同的计算机使用不同的大小,比如每组 5 个、6 个、7 个,甚至多达 12 个比特!
So, why did 8 bits win the race? There are a few reasons:
那么,为什么 8 个比特最终胜出了呢?原因有以下几点:
Just Right for Characters: The English alphabet, numbers, and special characters like !, @, #, etc., can all be represented using different combinations of 8 bits. This size is perfect for creating a system (known as ASCII) that can represent up to 256 different characters or instructions, which was more than enough for English and basic symbols.
字符表示正合适:英文字母表、数字以及像 !、@、# 等特殊字符都可以通过 8 个比特的不同组合来表示。这种大小非常适合创建一个系统(即 ASCII),它可以表示多达 256 种不同的字符或指令,这对于英语和基本符号来说已经绰绰有余了。
Efficiency: 8 bits create a balance between not having enough options (which would limit what computers can do) and having too many options (which would make computers more complex and expensive). It’s the “just right” size for a wide range of tasks.
效率:8 个比特在选项不足(这将限制计算机的功能)和选项过多(这会使计算机更加复杂和昂贵)之间取得了平衡。它是适用于广泛任务的“恰到好处”的大小。
Power of 2: Computer scientists love numbers that are powers of 2 (like 2, 4, 8, 16…), because computers think in binary (the language of 0s and 1s). It makes calculations and data storage more efficient and simpler to design.
2 的幂:计算机科学家喜欢 2 的幂次方的数字(比如 2、4、8、16……),因为计算机是以二进制(0 和 1 的语言)来思考的。这使得计算和数据存储更加高效,设计也更加简单。
Technology Advances: As technology evolved, the benefits of using 8 bits became even clearer. It made it easier for different types of computers to talk to each other and share information, helping to create the connected world we live in today.
技术进步:随着技术的发展,使用 8 个比特的好处变得更加明显。它使得不同类型计算机之间的通信和信息共享变得更加容易,帮助我们构建了如今这个互联互通的世界。
The Legacy Continues
承先启后
The decision to standardize on 8 bits wasn’t made overnight. It was the result of trial, error, and a lot of smart thinking by the early computer scientists. And once it was set, it paved the way for the explosion of digital technology we rely on every day, from smartphones to the internet.
将 8 个比特作为标准的决定并非一蹴而就。这是早期计算机科学家们经过反复试验、错误以及大量智慧思考的结果。一旦确定下来,它就为如今我们每天依赖的数字技术的爆炸式增长铺平了道路,从智能手机到互联网,无一不是如此。
Beyond the Byte
超越字节
While the byte (8 bits) is still fundamental, the digital world has grown. Now, we talk about kilobytes, megabytes, gigabytes, and even terabytes to measure the vast amounts of data we use and create every day. But at the heart of it all, those 8-bit bytes are working tirelessly, helping us to write stories, share pictures, play games, and explore the vastness of the internet.
尽管字节(8 个比特)仍然是基础,但数字世界已经发展得更加庞大。如今,我们用千字节、兆字节、吉字节甚至太字节来衡量我们每天使用和创造的海量数据。但在这一切的核心,那些 8 个比特的字节仍在不知疲倦地工作,帮助我们撰写故事、分享图片、玩游戏以及探索互联网的浩瀚无垠。
Conclusion
So, why are there 8 bits in a byte? It’s a combination of practicality, efficiency, and a bit of historical happenstance. This choice helped shape the digital age, making technology accessible and useful for everyone. And who knows? Maybe one day, you’ll be part of the next big decision in computing history!
那么,为什么一个字节有 8 个比特呢?这是实用主义、效率以及一点历史偶然性的结合。这一选择帮助塑造了数字时代,使技术变得人人可及且有用。谁知道呢?也许有一天,你会成为计算机历史下一个重大决策的参与者!
Remember, every byte counts in the vast universe of computing, and now you know the story behind those 8-bit heroes that make up the digital world. Keep exploring, keep questioning, and who knows what mysteries you’ll uncover next!
记住,在浩瀚的计算机世界里,每一个字节都很重要,而如今你知道了那些构成数字世界的 8 个比特英雄背后的故事。继续探索,继续提问,谁知道你接下来又会发现什么秘密呢!
What’s So Special About 8 Bits? The Fascinating World of the Byte
字节的迷人世界:8 比特有什么特别之处?
on June 05, 2024
If you’ve ever dabbled in the world of computing, you’ve likely encountered the term “byte.” But what makes 8 bits—collectively known as a byte—so special that it deserves its own name? To understand this, we need to explore the historical roots, the significance of bytes in modern computing, and their versatile roles.
如果你曾经涉足计算机领域,那么你很可能遇到过“字节”这个术语。但是,为什么 8 个比特——合称为一个字节——如此特殊以至于它值得拥有自己的名字呢?为了理解这一点,我们需要探索它的历史渊源、字节在现代计算中的重要性以及它们的多功能角色。
A Byte-Sized Introduction
A byte is a group of 8 bits. Bits are the most fundamental units of data in computing, representing a binary value of either 0 or 1. When you string 8 of these bits together, you get a byte, which can represent a wide range of information, from numbers to letters, instructions, and more.
字节简介
字节是由 8 个比特组成的一个组。比特是计算机中最基本的数据单位,表示一个二进制值,要么是 0,要么是 1。当你把 8 个这样的比特连在一起时,你就得到了一个字节,它可以表示从数字到字母、指令等等各种各样的信息。
Why 8 Bits?
The concept of a byte was popularized by IBM in the 1960s. They chose 8 bits because it provided a practical balance between sufficient data representation and manageable hardware complexity. An 8-bit grouping allows for 256 unique combinations (from 0 to 255), which was ideal for many computing tasks at the time, and it has continued to be sufficient for many tasks today.
为什么是 8 个比特?
字节的概念是由 IBM 在 20 世纪 60 年代普及开来的。他们选择了 8 个比特,因为它在足够表示数据和可管理的硬件复杂性之间提供了一个实用的平衡。一个 8 个比特的组合可以有 256 种独特的组合(从 0 到 255),这在当时对于许多计算任务来说是理想的,而且直到今天,它仍然足以应对许多任务。
The Smallest Addressable Unit
In most modern computers, a byte is the smallest addressable unit of memory. This means that a computer’s architecture is designed to access data in chunks of 8 bits. Addressing individual bits would complicate hardware and software design, making bytes the most efficient choice.
最小可寻址单元
在大多数现代计算机中,字节是内存中最小的可寻址单元。这意味着计算机的架构被设计成以 8 个比特为一块来访问数据。如果要单独寻址每个比特,将会使硬件和软件的设计复杂化,因此字节成为了最高效的选择。
What’s in a Byte?
字节包含什么?
One of the most remarkable aspects of a byte is its versatility. Depending on the context, a byte can represent different types of information:
字节最显著的特点之一是它的多功能性。根据不同的上下文,一个字节可以表示不同种类的信息:
-
Numbers: A byte can store an unsigned integer value ranging from 0 to 255 or a signed integer from -128 to 127.
数字:一个字节可以存储一个无符号整数值,范围从 0 到 255,或者是一个有符号整数,范围从 -128 到 127。
-
Characters: In text processing, a byte can represent a single character in the ASCII encoding scheme, making it fundamental for storing and manipulating text.
字符:在文本处理中,一个字节可以表示 ASCII 编码方案中的一个单字符,使其成为存储和操作文本的基础。
-
Program Instructions: Bytes store machine instructions that a computer’s processor executes. Each instruction often occupies one or more bytes.
程序指令:字节存储计算机处理器执行的机器指令。每条指令通常占用一个或多个字节。
-
Multimedia Data: Bytes represent parts of an audio recording or a pixel in an image. For instance, an 8-bit audio sample can capture 256 levels of sound intensity, and an 8-bit color image can display 256 different colors.
多媒体数据:字节表示音频录制的一部分或图像中的一个像素。例如,一个 8 个比特的音频采样可以捕捉 256 个级别的声音强度,而一个 8 个比特的彩色图像可以显示 256 种不同的颜色。
Practical Implications
实际意义
The byte’s standardized size simplifies various aspects of computing, such as memory allocation, data transfer, and file storage. Software developers often think in terms of bytes to efficiently manage data structures and optimize performance. For example, knowing that a byte can store a single character helps in designing text editors, while understanding that a 4-byte integer can store a wide range of values aids in database management.
字节的标准化大小简化了计算的诸多方面,比如内存分配、数据传输和文件存储。软件开发者通常以字节为单位来思考,以便高效地管理数据结构并优化性能。例如,知道一个字节可以存储一个单字符有助于设计文本编辑器,而明白一个 4 个字节的整数可以存储一系列广泛的值有助于数据库管理。
Why Bytes Matter
为什么字节很重要
Bytes are fundamental to both hardware and software design. From representing simple numbers and letters to storing complex program instructions and multimedia data, bytes are the building blocks of all digital information. Their standardized size makes them essential for efficient computing, ensuring that everything from basic calculations to sophisticated data processing runs smoothly.
字节对于硬件和软件设计来说都是基础性的。从表示简单的数字和字母到存储复杂的程序指令和多媒体数据,字节是所有数字信息的构建模块。它们的标准化大小使它们成为高效计算的必备元素,确保从基本计算到复杂的数据处理都能顺利运行。
The byte’s significance in computing is profound. Its perfect balance between complexity and functionality makes it an ideal building block for digital information. Whether representing a simple number, a letter, or a pixel in an image, the byte’s versatility and utility ensure its continued importance in the digital age.
字节在计算中的重要性是深远的。它在复杂性和功能性之间达到了完美的平衡,使其成为数字信息的理想构建模块。无论是表示一个简单的数字、一个字母还是图像中的一个像素,字节的多功能性和实用性确保了它在数字时代持续的重要性。
So next time you come across the term “byte,” you’ll know that it’s not just a random grouping of bits. It’s a carefully chosen, essential unit that underpins the entire world of computing, making our digital lives possible.
所以,下次当你遇到“字节”这个术语时,你会明白它不仅仅是一组随机的比特。这是一个经过精心选择的、必不可少的单位,它支撑着整个计算机世界,使我们的数字生活成为可能。
篇外:相关讨论
Does a byte contain 8 bits, or 9?
58
I read in this assembly programming tutorial that 8 bits are used for data while 1 bit is for parity, which is then used for detecting parity error (caused by hardware fault or electrical disturbance).
我读了 这个汇编编程教程,上面说 8 个比特用于数据,而 1 个比特用于奇偶校验,然后用于检测奇偶校验错误(由硬件故障或电气干扰引起)。
Is this true?
这是真的吗?
edited Dec 21, 2016 at 9:45
icc97
asked Dec 20, 2016 at 16:44
xtt
6
See cs.stackexchange.com/a/19851/584 for a discussion of what a byte can be.
参见 cs.stackexchange.com/a/19851/584,讨论了 字节 可以是什么。
– AProgrammer
Commented Dec 20, 2016 at 18:27
65
That article is filled with nonsense and you should ignore it.
这篇文章充满了胡说八道,你应该忽略它。
– David Schwartz
Commented Dec 20, 2016 at 20:51
12
If you want to be pedantic, just call them “octets”. That article is either written with a very specific processor in mind (one that must keep parity bits in ROM for some reason…) or is just wack. Microchip PICs, for example, use a 14-bit word length. The entire program memory is organized in a N x 14 bit array.
如果你想较真的话,干脆就叫它们“八位组”。那篇文章要么是针对某种特定的处理器写的(不知什么原因,这种处理器必须把奇偶校验位保留在只读存储器中……),要么就是瞎扯。例如,Microchip 的 PIC 微控制器采用 14 个比特的字长。整个程序存储器被组织成一个 N×14 个比特的数组。
– Nick T
Commented Dec 20, 2016 at 23:49
13
@NickT: they’re not the same thing, though. An octet is always 8 bits, a byte may be anything.
@NickT:不过,它们并不是同一样东西。八位组总是 8 个比特,而字节可以是任何东西。
– Jörg W Mittag
Commented Dec 20, 2016 at 23:49
4
The article may have been referencing the memory correction mechanisms used in some early IBM PCs, but stating that “byte is 8 bits data + 1 bit parity” is utter nonsense. As an example, CD-ROMs usually use error correction mechanisms that are much more greedy - a typical audio CD will use 8 bytes per 24 bytes of audio data. But the most important part is that you don’t care. At all. It’s exclusive to the actual memory storage mechanism - the CPU doesn’t care, your code doesn’t care.
这篇文章可能是在引用某些早期 IBM 个人电脑中使用的内存校正机制,但说“字节是 8 个比特的数据 + 1 个比特的奇偶校验”简直是无稽之谈。举个例子,CD - ROM 通常使用的纠错机制要贪婪得多——一张典型的音频 CD 会用 8 个字节来对应 24 个字节的音频数据。但最重要的是,你根本不用关心。这完全是实际的内存存储机制的事——CPU 不关心,你的代码也不关心。
– Luaan
Commented Dec 22, 2016 at 20:16
12 Answers
77
A byte of data is eight bits, there may be more bits per byte of data that are used at the OS or even the hardware level for error checking (parity bit, or even a more advanced error detection scheme), but the data is eight bits and any parity bit is usually invisible to the software. A byte has been standardized to mean ‘eight bits of data’. The text isn’t wrong in saying there may be more bits dedicated to storing a byte of data of than the eight bits of data, but those aren’t typically considered part of the byte per se, the text itself points to this fact.
一个数据字节是 8 个比特,可能在操作系统甚至硬件级别上,每字节数据会使用更多的比特来进行错误检查(奇偶校验位,甚至是一种更先进的错误检测方案),但数据本身是 8 个比特,任何奇偶校验位通常对软件来说是不可见的。字节已经被标准化为“8 个比特的数据”。文本说可能会有比 8 个比特的数据更多的比特用于存储一个字节的数据,这并没有错,但那些通常不被认为是字节本身的组成部分,文本本身也指出了这一事实。
You can see this in the following section of the tutorial:
你可以从教程的以下部分看出这一点:
Doubleword: a 4-byte (32 bit) data item
双字:一种 4 字节(32 位)的数据项
4*8=32, it might actually take up 36 bits on the system but for your intents and purposes it’s only 32 bits.
4×8 = 32,它实际上可能在系统中占用 36 个比特,但就你的意图和目的而言,它只有 32 个比特。
answered Dec 20, 2016 at 17:18
JustAnotherSoul
5
Well, if the hardware implements error detection it would probably do so with bigger chunks of memory than a byte, like with 512-byte sectors or so… in this way you can reduce the overhead of extra memory needed. Just to clarify: even with error correction the hardware still uses 8-bit per byte plus some bits for each “chunk” of data, which is probably much bigger than a single byte.
如果硬件实现了错误检测,它可能会以比字节更大的内存块来实现,比如 512 字节的扇区……通过这种方式,你可以减少所需的额外内存量。需要澄清的是:即使有错误校正,硬件仍然使用每字节 8 个比特,再加上每个“数据块”的一些比特,这可能比单个字节大得多。
– Bakuriu
Commented Dec 20, 2016 at 19:45
11
Note that there are systems with software-visible non-8-bit bytes. See What platforms have something other than 8-bit char? question at StackOverflow.
请注意,有些系统的软件可见字节不是 8 位的。参见 StackOverflow 上的 哪些平台的 char 不是 8 位的?
– Ruslan
Commented Dec 21, 2016 at 19:32
3
Yes, they do indeed exist. Though that particular link is talking about non-8-bit chars. As it were: byte used to simply refer to the number of bits that a given system took to store a ‘char’, which was as low as six bits. But IIRC it is standardized in the IEC-80000 specification that a byte is 8-bits. As you move away from mainstream systems, you do find oddities of course, and standards aren’t laws.
是的,它们确实存在。尽管那个特定的链接在谈论非 8 位的字符。正如所说的那样:字节过去只是指一个给定系统用来存储一个“字符”的比特数,这个数最低可达 6 位。但据我所记得,在 IEC - 80000 规范中已经标准化了字节是 8 位的。当然,当你远离主流系统时,你确实会发现一些奇特的东西,而且标准并非法定。
– JustAnotherSoul
Commented Dec 22, 2016 at 16:28
4
@JustAnotherSoul: And there are competing standards, that define byte as “at least 8 bit” or in other ways. It is interesting to see how decades later the definition of byte changes in the minds of people. Back in the time of much more architectural heterogeneity byte was simply the smallest addressable unit of your architecture (look at various PDPs for examples). This is also the reason that in the advent of the internet the term octet was used to describe the data on wire, as byte was not a universal word for a chunk of 8 bit data.
@JustAnotherSoul:还有相互竞争的标准,它们将字节定义为“至少 8 位”或以其他方式定义。看到几十年后人们对字节的定义发生了怎样的变化,这是很有趣的。在架构更加多样化的时代,字节仅仅是你的架构中最小的可寻址单元(可以看看各种 PDP 作为例子)。这也是在互联网兴起时,用“八位组”一词来描述线上的数据的原因,因为“字节”并不是一个表示 8 位数据块的通用词汇。
– PlasmaHH
Commented Dec 23, 2016 at 9:10
3
@JustAnotherSoul note that char in C (which is what the link is about) is exactly the smallest addressable unit of memory. It’s just called char, but the C Standard makes it synonymous to byte.
@JustAnotherSoul 请注意,C 语言中的 char(链接中所涉及的内容)正是内存中最小的可寻址单元。它只是被称为“字符”,但 C 标准使其与“字节”同义。
– Ruslan
Commented Dec 24, 2016 at 18:58
51
Traditionally, a byte can be any size, and is just the smallest addressable unit of memory. These days, 8 bit bytes have pretty much been standardized for software. As JustAnotherSoul said, the hardware may store more bits than the 8 bits of data.
传统上,字节可以是任何大小,它只是内存中最小的可寻址单元。如今,8 位字节在软件中已经被基本标准化了。正如 JustAnotherSoul 所说的,硬件可能会存储比 8 位数据更多的比特。
If you’re working on programmable logic devices, like FPGAs, you might see that their internal memory is often addressable as 9-bit chunks, and as the HDL author, you could use that 9th bit for error checking or just to store larger amounts of data per “byte”. When buying memory chips for custom hardware, you generally have the choice of 8 or 9 bit addressable units (or 16/18, 32/36, etc), and then it is up to you whether you have 9 bit “bytes” and what you do with that 9th bit if you choose to have it.
如果你正在从事可编程逻辑设备(如 FPGA)的工作,你可能会发现它们的内部存储器通常可以作为 9 位的数据块进行寻址,而作为硬件描述语言的作者,你可以使用那个第 9 位来进行错误检查,或者只是用来在每个“字节”中存储更多的数据。在购买定制硬件的存储芯片时,你通常可以选择 8 位或 9 位的可寻址单元(或 16/18、32/36 等),然后就取决于你是否选择有 9 位的“字节”,以及如果你选择有它的话,你打算用那个第 9 位来做什么。
answered Dec 20, 2016 at 18:11
Extrarius
10
Generally when there’s a group of data that is logically a single unit but contains more/less than 8 bits, it is called a “word.” For example, some processors use a 40-bit instruction word.
一般来说,当一组数据在逻辑上是一个单独的单元,但包含的比特数多于或少于 8 位时,它被称为一个“字”。例如,有些处理器使用一个 40 位的指令字。
– Devsman
Commented Dec 20, 2016 at 19:36
3
+1. Incidentally, there have been architectures with both “bit pointers” and “byte pointers”. In such architectures, a byte is technically not “the smallest addressable unit of memory” (since you can address each bit independently), though it’s hard to succinctly say what it is. I guess it’s an “I know it when I see it” sort of thing.
+1。顺便说一下,曾经有过既有“比特指针”又有“字节指针”的架构。在这样的架构中,字节从技术上来说并不是“内存中最小的可寻址单元”(因为你能够独立地寻址每个比特),尽管很难简洁地说出它到底是什么。我想这是一种“我看到就知道是什么”的东西。
– ruakh
Commented Dec 20, 2016 at 19:56
19
“Octet” was the traditionally used word to mean “I’d call it a byte, but I really do mean exactly 8 bits” for various communication protocols between systems that may have different byte sizes. But these days, using byte to mean anything but 8 bits is anachronistic.
“八位组”是传统上用来表示“我会称之为字节,但我确实是指正好 8 位”的词,用于各种通信协议,这些协议是在可能具有不同字节大小的系统之间使用的。但在如今,把字节理解为除 8 位以外的其他东西是过时的。
– wnoise
Commented Dec 21, 2016 at 1:12
@Devsman Not necessarily. x86 chips have 32 bit words and 8 bit bytes, for example. A byte is the smallest addressable size. The word is a bit more vaguely defined, but tends to be the size that is most convenient to work with; i.e. the expected operand length of most instructions.
@Devsman 不一定。例如,x86 芯片有 32 位的字和 8 位的字节。字节是最小的可寻址大小。字的定义稍显模糊,但通常是使用起来最方便的大小,即大多数指令所期望的操作数长度。
– Ray
Commented Dec 22, 2016 at 1:09
This should be marked as the correct answer, it is more correct.
这个回答应该被标记为正确答案,因为它更正确。
– awiebe
Commented Dec 30, 2016 at 9:20
32
That text is extremely poorly worded. He is almost certainly talking about ECC (error-correcting code) RAM.
这段文字表述得非常糟糕。他几乎肯定是在谈论 ECC(错误校正码)RAM。
ECC ram will commonly store 8-bits worth of information using 9-bits. The extra bit-per-byte is used to store error correction codes.
ECC 内存通常会使用 9 位来存储价值 8 位的信息。每字节额外的那 1 位用于存储错误校正码。

(In both cases, every byte is spread across every chip. Image courtesy of Puget Systems)
(在这两种情况下,每个字节都分布在每个芯片上。图片由 Puget Systems 提供)
This is all completely invisible to users of the hardware. In both cases, software using this RAM sees 8 bits per byte.
所有这些对硬件的使用者来说都是完全不可见的。在这两种情况下,使用这种 RAM 的软件看到的都是每字节 8 位。
As an aside: error-correcting codes in RAM typically aren’t actually 1 bit per byte; they’re instead 8 bits per 8 bytes. This has the same space overhead, but has some additional advantages. See SECDED for more info.
顺便说一下:RAM 中的错误校正码通常实际上并不是每字节 1 位,而是每 8 字节 8 位。这具有相同的存储开销,但有一些额外的优势。更多信息请查看 SECDED。
edited Dec 23, 2016 at 17:15
answered Dec 20, 2016 at 21:48
BlueRaja - Danny Pflughoeft
12
-
Parity RAM and ECC RAM are different things. Parity RAM stores one additional bit per error domain, can detect all single-bit errors and no double-bit errors, and can fix nothing. ECC stores a number of additional bits per error domain, can detect and fix all single-bit errors, can detect but not fix all double-bit errors, and can catch some larger errors. Parity RAM is rare these days, having been almost entirely replaced by ECC RAM.
奇偶校验 RAM 和 ECC RAM 是不同的东西。奇偶校验 RAM 每个错误域存储一个额外的比特,可以检测所有单比特错误,但无法检测双比特错误,也无法修复任何错误。ECC 每个错误域存储多个额外的比特,可以检测并修复所有单比特错误,可以检测但无法修复所有双比特错误,并且可以捕获一些更大的错误。如今,奇偶校验 RAM 已经很少见了,几乎完全被 ECC RAM 替代了。
– Mark
Commented Dec 20, 2016 at 21:54
1
@Mark: I hinted at that in my last paragraph, there are more details in the link. Parity RAM is basically non-existent these days because a (72,64) error-correction code has the same overhead as a (9,8) parity code.
@Mark:我在最后一段中暗示了这一点,链接中有更多细节。如今,奇偶校验 RAM 基本上已经不存在了,因为 (72,64) 错误校正码与 (9,8) 奇偶校验码具有相同的开销。
– BlueRaja - Danny Pflughoeft
Commented Dec 20, 2016 at 22:20
7
While you hint at it, you also state things that make it imprecise/confusing. ECC RAM does not “store 8-bits worth of information using 9-bits”. Stating that implies you can do ECC for 8 bits using 9 bits, which is not possible. For 8 bits of discrete information 1 extra bit is enough to detect, not correct, single bit errors. ECCs use larger numbers of bits, or bytes, to contain data sufficient to correct errors for groups of data, usually larger than a single byte. While this might average an extra bit per 8 bits, it can not be broken down to associating only 1 bit with each 8 bits.
尽管你暗示了这一点,但你也说了一些使它不精确/令人困惑的话。ECC RAM 并不会“使用 9 位来存储价值 8 位的信息”。这样说会让人以为可以用 9 位来为 8 位做 ECC,这是不可能的。对于 8 位离散信息,1 个额外的比特足以检测(而非纠正)单比特错误。ECC 使用更多的比特数或字节数来包含足够的数据,以便纠正数据组(通常大于单字节)的错误。尽管这可能平均下来是每 8 位多 1 位,但它不能被分解为仅将 1 位与每个 8 位关联起来。
– Makyen
Commented Dec 21, 2016 at 19:16
There is a 36-bit scheme (32 bit word + 4 bit ECC) which permits single bit error correction and two bit error detection. While you can arithmetically divide it down to 8 data bits + 1 ECC bit, it cannot/does not work that way. The full 4 bits of ECC are required, which covers 32 data bits.
有一个 36 位的方案(32 位字 + 4 位 ECC),它允许进行单比特错误纠正和双比特错误检测。尽管你可以从算术上将其分解为 8 个数据位 + 1 个 ECC 位,但它并不能/不是那样工作的。完整的 4 位 ECC 是必需的,它可以覆盖 32 个数据位。
– Zenilogix
Commented Dec 23, 2016 at 16:56
@Zenilogix and others who repeated the same thing: I understand very well how ECC works, and nothing I said was incorrect. I never claimed 8-bit ECC can be done with 9 bits, I said ECC RAM uses 9-bits-per-byte of storage. How ECC works is completely out-of-scope for this question, which is why I left the details as an aside with a link. Please stop all the pedantic comments.
@Zenilogix 以及那些重复同样说法的人:我非常清楚 ECC 是如何工作的,而且我所说的并没有错误。我从未声称可以用 9 位来完成 8 位的 ECC,我说的是 ECC RAM 使用每字节 9 位的存储空间。ECC 的工作原理完全超出了这个问题的范围,这也是为什么我把细节作为旁白并附上了链接。请停止这些过于苛求的评论。
– BlueRaja - Danny Pflughoeft
Commented Dec 23, 2016 at 17:12
18
Generally speaking, the short answer is that a byte is 8 bits. This oversimplifies the matter (sometimes even to the point of inaccuracy), but is the definition most people (including a large number of programmers) are familiar with, and the definition nearly everyone defaults to (regardless of how many differently-sized bytes they’ve had to work with).
一般来说,简短的回答是字节是 8 位。这种说法过于简化了问题(有时甚至到了不准确的地步),但它却是大多数人(包括大量程序员)所熟悉的定义,也是几乎每个人在默认情况下所采用的定义(不管他们曾经使用过多少种不同大小的字节)。
More specifically, a byte is the smallest addressable memory unit for the given architecture, and is generally large enough to hold a single text character. On most modern architectures, a byte is defined as 8 bits; ISO/IEC 80000-13 also specifies that a byte is 8 bits, as does popular consensus (meaning that if you’re talking about, say, 9-bit bytes, you’re going to run into a lot of trouble unless you explicitly state that you don’t mean normal bytes).
更具体地说,字节是给定架构中最小的可寻址内存单元,通常足够大以容纳一个文本字符。在大多数现代架构中,字节被定义为 8 位;ISO/IEC 80000 - 13 也规定字节是 8 位,这同样也是大众共识(也就是说,如果你在谈论,比如说,9 位的字节,除非你明确说明你指的不是普通的字节,否则你会遇到很多麻烦)。
However, there are exceptions to this rule. For example:
然而,也有例外。例如:
-
The Sperry 1100/2200 systems had 9-bit bytes._
The Sperry 1100/2200 系统有 9 位的字节。 -
The PDP-10 didn’t directly support bytes; rather, it had 36-bit words, and a “byte” was any number of contiguous bits within a single word._
PDP - 10 并不直接支持字节;相反,它有 36 位的字,而一个“字节”是一个单词内任何数量的连续比特。 -
The Control Data 6600 had 60-bit words, with no way to address smaller units of memory; effectively, it had 60-bit bytes. Programmers had a tendency to store 10 characters per word, so it could also be seen as having 6-bit bytes._
Control Data 6600 有 60 位的字,没有方法来寻址更小的内存单元;实际上,它有 60 位的字节。程序员倾向于每个字存储 10 个字符,因此它也可以被视为有 6 位的字节。 -
The C and C++ programming languages define “byte” as (very heavily paraphrased)
sizeof(char), while also indirectly stating that acharmust be a minimum of 8 bits, each byte must have a unique address, and there mustn’t be any spaces between contiguous bytes in memory.
C 和 C++ 编程语言将“字节”定义为(非常简化地转述)sizeof(char),同时间接表明一个char必须至少有 8 位,每个字节必须有一个唯一的地址,而且在内存中连续的字节之间不能有任何间隔。This is to make the languages more portable than they would be if they explicitly required 8-bit bytes. [The number of bits in a byte is specified as
CHAR_BIT, in C library header “limits” (limits.h), in C,climitsin C++).]这是为了使这些语言比明确要求 8 位字节时更具可移植性。[字节中的比特数被指定为 CHAR_BIT,在 C 标准库头文件 “limits” 中指定为
limits.h,在 C 中,climits 在 C++ 中)。]- There is at least one C++ implementation with 64-bit bytes.
至少有一种 C++ 实现使用 64 位字节。
- There is at least one C++ implementation with 64-bit bytes.
So, in most cases, a byte will generally be 8 bits. If not, it’s probably 9 bits, and may or may not be part of a 36-bit word.
因此,在大多数情况下,字节通常是 8 位。如果不是,它可能是 9 位,并且可能是也可能不是 36 位字的一部分。
edited May 23, 2017 at 12:37
answered Dec 21, 2016 at 3:28
Justin Time - Reinstate Monica
8
Note that the term byte is not well-defined without context. As far as computer architectures are concerned, you can assume that a byte is 8-bit, at least for modern architectures. This was largely standardised by programming languages such as C, which required bytes to have at least 8 bits but didn’t provide any guarantees for larger bytes, making 8 bits per byte the only safe assumption.
请注意,如果没有上下文,字节这一术语是定义得不太好的。就计算机架构而言,你可以假设字节是 8 位的,至少对于现代架构来说是这样。这主要是由 C 等编程语言所标准化的,这些语言要求字节至少有 8 位,但没有对更大的字节提供任何保证,从而使每个字节 8 位成为唯一安全的假设。
There are computers with addressable units larger than 8 bits (usually 16 or 32), but those units are usually called machine words, not bytes. For example, a DSP with 32K 32-bit RAM words would be advertised as having 128 KB or RAM, not 32 KB.
有计算机的可寻址单元大于 8 位(通常是 16 位或 32 位),但这些单元通常被称为机器字,而不是字节。例如,一个具有 32K 32 位 RAM 字的数字信号处理器会被宣传为拥有 128 KB 的 RAM,而不是 32 KB。
Things are not so well-defined when it comes to communication standards. ASCII is still widely used, and it has 7-bit bytes (which nicely fit in 8-bit bytes on computers). UART transceivers are still produced to have configurable byte size (usually, you get to pick at least between 6, 7 and 8 bits per byte, but 5 and 9 are not unheard of).
在通信标准方面,情况就没有那么明确了。ASCII 仍然被广泛使用,它有 7 位的字节(这在计算机的 8 位字节中非常合适)。UART 收发器仍然被生产为具有可配置的字节大小(通常,你可以至少选择每字节 6 位、7 位和 8 位,但 5 位和 9 位也并非闻所未闻)。
answered Dec 21, 2016 at 14:13
Dmitry Grigoryev
6
A byte is usually defined as the smallest individually addressable unit of memory space. It can be any size. There have been architectures with byte sizes anywhere between 6 and 9 bits, maybe even bigger. There are also architectures where the only addressable unit is the size of the bus, on such architectures we can either say that they simply have no byte, or the byte is the same size as the word (in one particular case I know of that would be 32 bit); either way, it is definitely not 8 bit. Likewise, there are bit-addressable architectures, on those architectures, we could again argue that bytes simply don’t exist, or we could argue that bytes are 1 bit; either way is a sensible definition, but 8 bit is definitely wrong.
字节通常被定义为内存空间中最小的可单独寻址的单元。它可以是任何大小。曾经有字节大小在 6 到 9 位之间的架构,也许还有更大的。也有一些架构中唯一的可寻址单元是总线的大小,在这样的架构中,我们可以说它们根本没有字节,或者字节与字的大小相同(我知道的一个特定例子是 32 位);不管怎样,它肯定不是 8 位。同样地,也有按位寻址的架构,在那些架构中,我们同样可以认为字节根本不存在,或者认为字节是 1 位;这两种说法都是合理的定义,但 8 位肯定错了。
On many mainstream general purpose architectures, one byte contains 8 bit. However, that is not guaranteed. The further away you stray from the mainstream and/or from general purpose CPUs, the more likely you will encounter non-8-bit-bytes. This goes so far that some highly-portable software even makes the size configurable. E.g. older versions of GCC contained a macro called BITS_PER_BYTE (or something like that), which configured the size of a byte for a particular architecture. I believe some older versions of NetBSD could be made to run on non-8-bit-per-byte architectures.
在许多主流的通用架构中,一个字节包含 8 位。然而,这并不是有保证的。你离主流越远,或者离通用 CPU 越远,你就越有可能遇到非 8 位的字节。这甚至到了一些高度可移植的软件甚至使大小可配置的程度。例如,GCC 的旧版本包含一个名为 BITS_PER_BYTE(或者类似的东西)的宏,它为特定架构配置字节的大小。我相信 NetBSD 的一些旧版本可以在非 8 位每字节的架构上运行。
If you really want to stress that you are talking about an exact amount of 8 bit rather than the smallest addressable amount of memory, however large that may be, you can use the term octet, which is for example used in many newer RfCs.
如果你真的想强调你谈论的是正好 8 位,而不是最小的可寻址的内存量(不管它有多大),你可以使用 八位组 这个术语,例如在许多新的 RfC 中就使用了它。
answered Dec 20, 2016 at 23:32
Jörg W Mittag
2
Standard C and C++ have a predefined macro CHAR_BIT (found in limits.h), I am not aware of BITS_PER_BYTE
标准 C 和 C++ 有一个预定义的宏 CHAR_BIT(在 limits.h 中找到),我不了解 BITS_PER_BYTE
– njuffa
Commented Dec 21, 2016 at 21:30
-
CHAR_BIT describes the bits per byte; it can’t configure it.
CHAR_BIT 描述的是每字节的比特数;它不能配置这个。
– MSalters
Commented Jan 27 at 13:33
4
When I started programming in 1960, we had 48 bit words with 6 bit bytes - they ware not called that name then, they were called characters. Then I worked on the Golem computer with 75 bit words and 15 bit bytes. Later, 6 bit bytes were the norm, until IBM came out with the 360, and nowadays a byte is commonly equivalent to an octet, i.e. 8 bits of data. Some hardware had additional bits for error detection and possibly for error correction, but these were not accessible by the software.
1960 年我刚开始编程的时候,我们有 48 位的字和 6 位的字节——当时它们还不叫这个名字,它们被称为字符。后来我参与了 Golem 计算机的工作,它有 75 位的字和 15 位的字节。再后来,6 位的字节成为了常态,直到 IBM 推出了 360,如今字节通常等同于八位组,即 8 位的数据。一些硬件有额外的比特用于错误检测,可能还有用于错误纠正的,但这些是软件无法访问的。
edited Jan 1, 2019 at 21:32
answered Dec 23, 2016 at 16:56
Jonathan Rosenne
3
First, the tutorial that you are referencing seems to be quite outdated, and seems to be directed at outdated versions of x86 processors, without stating it, so lots of the things you read there will not be understood by others (for example if you claim that a WORD is 2 bytes, people will either not know what you are talking about, or they will know that you have been taught based on very outdated x86 processors and will know what to expect).
首先,你引用的教程似乎相当过时,而且似乎是针对过时的 x86 处理器版本的,却没有说明这一点,所以你在那上面读到的很多东西,其他人可能无法理解(例如,如果你声称一个 WORD 是 2 个字节,人们要么不知道你在说什么,要么会知道你是根据非常过时的 x86 处理器接受的教育,并且会知道该期待什么)。
A byte is whatever number of bits someone decides it should be. It could be 8 bit, or 9 bit, or 16 bit, anything. In 2016, in most cases a byte will be eight bit. To be safe you can use the term octet - an octet is always, always, eight bits.
字节就是某人决定它应该是的比特数。它可以是 8 位,也可以是 9 位,或者是 16 位,随便什么都可以。在 2016 年,大多数情况下字节是八位的。为了安全起见,你可以使用八位组这个术语——八位组总是、总是八位的。
The real confusion here is confusing two questions: 1. What is the number of bits in a byte? 2. If I wanted to transfer one byte from one place to another, or if I wanted to store a byte, using practical physical means, how would I do that? The second question is usually of little interest to you, unless you work at a company making modems, or hard drives, or SSD drives. In practice you are interested in the first question, and for the second one you just say “well, someone looks after that”.
这里真正的混淆在于混淆了两个问题:1. 一个字节有多少位?2. 如果我想把一个字节从一个地方转移到另一个地方,或者我想存储一个字节,使用实际的物理手段,我该怎么做?通常情况下,第二个问题对你来说没什么兴趣,除非你在一家制造调制解调器、硬盘或固态驱动器的公司工作。实际上,你感兴趣的是第一个问题,对于第二个问题,你只需说“好吧,有人会处理这个的”。
The parity bit that was mentioned is a primitive mechanism that helps detecting that when a byte is stored in memory, and later the byte is read, the memory has changed by some accident. It’s not very good at that, because it won’t find that two bits have been changed so a change is likely to go undetected, and it cannot recover from the problem because there is no way to find out which of the 8 bits have changed, or even if the parity bit has changed.
提到的奇偶校验位是一种原始的机制,它有助于检测一个字节存储在内存中,后来读取这个字节时,内存由于某种意外而发生了变化。它在这方面不太好,因为它无法发现两个比特发生了变化,所以变化很可能会被忽略掉,而且它无法从问题中恢复过来,因为没有办法知道是 8 个比特中的哪一个发生了变化,甚至奇偶校验位是否发生了变化。
Parity bits are practically not used in that primitive form. Data that is stored permanently is usually protected in more complicated ways, for example by adding a 32 bit or longer checksum to a block of 1024 bytes - which takes much less extra space (0.4% in this example instead of 12.5%) and is much less likely to not find out when something is wrong.
实际上,奇偶校验位几乎不用那种原始的形式。通常用更复杂的方式保护永久存储的数据,例如给 1024 个字节的一个数据块添加一个 32 位或更长的校验和——这会占用更少的额外空间(在这个例子中是 0.4%,而不是 12.5%),而且当出现问题时,更不可能发现不了。
answered Dec 21, 2016 at 9:38
gnasher729
-
Really outdated: the 16-byte “paragraph” hasn’t been a meaningful unit of memory since the switch from real mode and segmented addressing.
过时得厉害:自从从实模式和分段寻址切换过来以后,16 字节的“段落”就不再是一个有意义的内存单位了。
– Mark
Commented Dec 24, 2016 at 21:21
-
Personally, I would assume “WinAPI” when someone talks about 2-byte WORDs, which… kinda proves your point, since a lot of the WinAPI type names are outdated but kept for backwards-compatibility. xP
个人而言,当有人提到 2 字节的 WORD 时,我会认为是“WinAPI”——这有点证明了你的观点,因为很多 WinAPI 类型名称都过时了,但为了向后兼容而保留了下来。xP
– Justin Time - Reinstate Monica
Commented Oct 26, 2019 at 19:37
2
Despite the really excellent answers given here, I’m surprised that no one has pointed that parity bits or error correction bits are by definition ‘metadata’ and so not part of the byte itself.
尽管这里给出了非常出色的答案,但我惊讶地发现没有人指出奇偶校验位或错误校正位按定义是“元数据”,因此不是字节本身的组成部分。
A byte has 8 bits!
一个字节有 8 位!
answered Dec 26, 2016 at 0:35
user34445
2
A byte is 8 bits.
一个字节是 8 位。
In the distant past, there were different definitions of a memory word and of a byte. The suggestion that this ambiguity is widespread or is prevalent in today’s life is false.
在遥远的过去,内存字和字节有不同的定义。认为这种模糊性是广泛存在或在当今生活中很普遍的说法是错误的。
Since at least the late 1970’s, a byte has been 8 bits. The mass populace of home computers and PCs have all unambiguously used a byte as an 8-bit value in their documentation, as have all of the data sheets and documentation for floppy disk drives, hard disk drives and PROM/EPROM/EEPROM/Flash EPROM/SRAM/SDRAM memory chips that I have read in that time period. (And I have personally read a great deal of them right across that time period.) Ethernet and a couple of other communications protocols stand out to me as unusual in talking about octets.
至少从 20 世纪 70 年代末以来,字节就是 8 位。在那个时期,家用电脑和 PC 的大众群体都在他们的文档中毫不含糊地将字节用作 8 位的值,我所阅读过的软盘驱动器、硬盘驱动器以及 PROM/EPROM/EEPROM/Flash EPROM/SRAM/SDRAM 内存芯片的所有数据表和文档也是如此。(而且在那个时期,我确实阅读了大量的这类资料。)以太网和一些其他通信协议在我看来比较特别,它们提到的是八位组。
The ambiguity of the term byte is itself a rare and obscure thing. Very, very few of the population of programmers, design engineers, test engineers, salespeople, service engineers or average punters in the last 30 years or more would think it meant something other than an 8-bit value, if they recognised the word at all.
“字节”这一术语本身的模糊性是一种罕见且晦涩的事情。在过去 30 多年里,非常非常少的程序员、设计工程师、测试工程师、销售人员、服务工程师或普通用户会认为它代表的不是 8 位的值,前提是他们能认出这个词。
When a byte is handled by hardware, such as when stored in memory chips or communicated along wire, the hardware may add redundant data to the byte. This may later assist in detecting hardware errors so that unreliable data can be recognised and discarded (e.g. parity, checksum, CRC). Or it may allow errors in the data to be corrected and the data recovered (e.g. ECC). Either way, the redundant data will be discarded when the byte has been retrieved or received for further processing. The byte remains the central 8-bit value and the redundant data remains redundant data.
当硬件处理字节时,例如存储在内存芯片中或通过电线传输时,硬件可能会向字节添加冗余数据。这可能有助于后续检测硬件错误,以便识别并丢弃不可靠的数据(例如奇偶校验、校验和、CRC)。或者它可能允许纠正数据中的错误并恢复数据(例如 ECC)。无论哪种方式,当字节被检索或接收以便进一步处理时,冗余数据将被丢弃。字节仍然是中心的 8 位值,而冗余数据仍然是冗余数据。
edited Feb 17, 2019 at 7:33
answered Dec 23, 2016 at 22:37
Word- or byte-addressable? Correct terminology
11
Seemingly, a byte has established itself to be 8bit (is that correct?). RAM and NOR-flash can be normally accessed on a quite granular level, but it is up to the system architecture to determine if the smallest addressable unit is 8bit, 16bit or any other power of two bit number. Would the correct terminology be to call this word-addressable? Or asked differently, is a word the size of smallest addressable unit? Or is there some other term to describe this? Are mabye nibble, byte, word, double word all variable in bit-length and only defined by the architecture? And it is therefore only coincidence that a byte is always 8 bit? E.g. someone could design some new CPU and memory type and define her byte to be 16bit?
看起来,字节已经确立为 8 位(是这样吗?)。RAM 和 NOR - flash 通常可以在相当细致的级别上被访问,但由系统架构来决定最小可寻址单元是 8 位、16 位还是其他 2 的幂次位数。正确的术语是称其为字寻址的吗?或者换一种问法,字是最小可寻址单元的大小吗?还是有其他术语来描述这个?也许半字节、字节、字、双字的位长度都是可变的,仅由架构定义?因此,字节总是 8 位只是一个巧合?例如,有人可以设计一种新的 CPU 和内存类型,并定义其字节为 16 位?
Main question: What is the precise term for the smallest addressable memory block?
主要问题:最小可寻址内存块的精确术语是什么?
Side question: What is the antonym to this word I’m looking for (e.g. used in NAND-flash)? Page-addressable, block-addressable? Are both correct or is one inprecise?
次要问题:我要找的这个术语的反义词是什么(例如在 NAND - flash 中使用)?页面寻址的、块寻址的?两者都正确还是有一个不精确?
edited Jan 20, 2014 at 16:42
asked Jan 20, 2014 at 12:16
Franz Kafka
4 Answers
9
From a computer architecture point of view, and with the caveat that nomenclature sometimes varies, especially when there is a family of related architectures which has evolved for a long time, or when the marketing department decides to that the usual terms have to used in another way (either to put the product in better light by using a bigger number, or to have a simple number to differentiate more or less related products).
从计算机架构的角度来看,并且要考虑到术语有时会有所不同,特别是当有一系列相关的架构已经演变了很长时间,或者当市场部门决定以另一种方式使用通常的术语时(无论是通过使用更大的数字来把产品说得更好些,还是为了用一个简单的数字来区分或多或少相关的产品)。
A word has the size normally used for integer operations (often expressed as size of the integer or the general purpose registers, i.e. not address or data, internal or external buses, not address registers, not index registers). A common issue is that when an architecture is an evolution of a previous one, one often keep the term word for the initial size and one use “double word” or “quad word” for what is a word if you look at the architecture in isolation. Historically words have not always been a power of two (I know of sizes: 12, 16, 18, 24, 32, 36, 60, 64 and I don’t think my knowledge is exhaustive).
一个字通常是用于整数运算的大小(通常表示为整数或通用寄存器的大小,即不是地址或数据,不是内部或外部总线,不是地址寄存器,不是索引寄存器)。一个常见的问题是,当一个架构是前一个架构的演变时,人们通常会保留字这个术语来表示最初的大小,而使用“双字”或“四字”来表示如果你单独看这个架构的话就是字的大小。从历史上看,字并不总是 2 的幂(我知道的大小有:12、16、18、24、32、36、60、64,而且我认为我的知识并不是全面的)。
Word addressable means that the memory is considered as arrays of words, and thus no smaller unit has an individual addresses.
字寻址的意味着内存被视为字的数组,因此没有更小的单元有单独的地址。
A byte has various definitions. The term was introduced to mean the unit used in character encoding at a time where multi-byte encoding didn’t exist. It is often used to means the smallest addressable unit for machine which are not word addressable (well as long at it is not one bit). I don’t think those two definitions have ever given a different size. (nor a size different from 6 or 8 bits). For word addressable machine it often means some unit smaller than a word that the machine has some support for (for instance the PDP-10 – a 36 bits word addressable computer – had byte instructions which could manipulate any size from 1 to 35 or 36 bits). Nowadays it is also often 8 bits. Often several of those definitions are practically equivalent.
字节有各种定义。这个术语是在多字节编码不存在的时候引入的,用来表示字符编码中使用的单位。它通常用来表示不是字寻址的机器的最小可寻址单元(当然,只要它不是一位)。我认为这两个定义从来没有给出过不同的大小(也没有给出过不同于 6 或 8 位的大小)。对于字寻址的机器,它通常意味着机器有一定支持的、比字小的某种单位(例如 PDP - 10——一个 36 位的字寻址计算机——有字节指令,可以操作从 1 到 35 或 36 位的任何大小)。如今,它通常也是 8 位。通常,这些定义在实践中是等价的。
Byte addressable characterizes machines where the memory is considered as arrays of bytes in one of the above meaning.
字节寻址的用来描述内存被视为上述意义中的字节数组的机器。
AFAIK nibble has only been used for 4 bits quantities.
据我所知,半字节只用于表示 4 位的数量。
E.g. someone could design some new CPU and memory type and define her byte to be 16bit?
例如,有人可以设计一种新的 CPU 和内存类型,并定义其字节为 16 位吗?
Yes, but I’m not sure if it would make much sense to do so if one keeps the CA usage to use byte for something smaller than the word. Having a word addressable 16-bit processor with no support for something smaller than a word may be a good choice for a special purpose processor.
是的,但如果按照 CA 的用法把字节用于比字小的东西,那么这样做可能不太合理。对于一个特殊的处理器来说,拥有一个 16 位的字寻址处理器且不支持比字小的东西可能是一个不错的选择。
Secondarily, what is the antonym to this word I’m looking for? Page-addressable, block-addressable?
其次,我要找的这个术语的反义词是什么?页面寻址的、块寻址的?
Bit-addressable, byte-addressable and word-addressable are the only terms I’ve seen use. It doesn’t make much sense to address only units bigger than the word at the architectural level. Word-addressable is nowadays only used for special purpose processors such as DSP. I don’t think bit-addressability has been used for anything else than special purpose one excepted the IBM Stretch.
位寻址的、字节寻址的和字寻址的是我所见过的唯一使用的术语。在架构级别上,只寻址比字大的单元是没有太多意义的。如今,字寻址的只用于特殊的处理器,如 DSP。除了 IBM Stretch 这种特殊用途的处理器外,我认为位寻址并没有用于其他任何东西。
About your new main question
关于你的新主要问题
What is the precise term for the smallest addressable memory block?
最小可寻址内存块的精确术语是什么?
I know of none used in Computer Architecture (byte has been used for something smaller in word adressable machines), but is the definition used by C for byte.
在计算机架构中,我不知道有哪个术语被使用过(在字寻址的机器中,字节被用于表示比字小的东西),但这是 C 语言中对字节的定义。
edited Jan 20, 2014 at 14:53
answered Jan 20, 2014 at 14:14
AProgrammer
Thanks for the elaborate answer. As I reread my question I noticed I was a bit vague, therefore I’m still looking for a definite answer that you could maybe still add to your answer: What is the precise term for the smallest addressable memory block? Or is there none? Furthermore, I changed the sentence that you quoted. Thanks so much.
感谢你的详细答案。当我重新阅读我的问题时,我注意到我有点含糊,因此我仍然在寻找一个明确的答案,也许你可以将其添加到你的答案中:最小可寻址内存块的精确术语是什么?还是没有呢?此外,我改变了你引用的那句话。非常感谢。
– Franz Kafka
Commented Jan 20, 2014 at 14:46
1
Bit-banding regions on some microcontroller ISAs might count as bit addressing. A portion of the address space translates word addresses (at least in ARM Cortex-M) to bit addresses. Obviously this only supports bit-addressing for a small portion of the total address space (only 2MiB out of 4GiB for Cortex-M3). Also instruction set addressability is distinct from hardware addressability (e.g., NAND flash is page addressable, DRAM is often addressable at cache block granularity, L1 cache is typically maximum load size addressable [with smaller writes ECC requires RMW].)
一些微控制器的指令集架构中的位带区域可能算作位寻址。地址空间的一部分将字地址(至少在 ARM Cortex - M 中)转换为位地址。显然,这仅支持总地址空间的一小部分的位寻址(对于 Cortex - M3,只有 4GiB 中的 2MiB)。此外,指令集的寻址能力与硬件的寻址能力是不同的(例如,NAND 闪存是页面寻址的,DRAM 通常可以在缓存块粒度上寻址,L1 缓存通常是最大加载大小可寻址的[对于较小的写入,ECC 需要读 - 修改 - 写])。
– user4577
Commented Jan 20, 2014 at 15:40
@PaulA.Clayton I didn’t knew the term bit banding but I knew of the 8051 which provides it as well. I’d not consider an ISA which provides it as bit-addressable no more than I consider the PDP-10 as byte-addressable, it seems too distinct of usual datapath.
@PaulA.Clayton 我不知道“位带”这个术语,但我知道 8051 也提供了它。我不会把提供它的指令集架构视为位寻址的,就像我不把 PDP - 10 视为字节寻址的一样,它似乎与通常的数据通路太不相同了。
– AProgrammer
Commented Jan 20, 2014 at 15:53
1
@PaulA.Clayton, I tried to stick to what seemed established practice in the field, but it is a field which loves intermediate states and I’ve neither Andy Glew’s talent nor culture to be able to give an exhaustive yet understandable description.
@PaulA.Clayton,我尽量遵循该领域中看似既定的做法,但这是一个喜欢中间状态的领域,而且我既没有安迪·格鲁的天赋,也没有他的文化,无法给出一个既全面又易于理解的描述。
– AProgrammer
Commented Jan 20, 2014 at 16:35
1
9-bit bytes (smallest addressable unit) with 6-bit characters and 36-bit words was a combination that happened on the UNIVAC systems Unisys made, if I remember right.
如果我没记错的话,9 位字节(最小的可寻址单元)、6 位字符和 36 位字是 Unisys 制造的 UNIVAC 系统中的一种组合。
– mtraceur
Commented May 15, 2022 at 8:31
2
The Burroughs B1700 was bit addressable (actually the address referred to the space between the bits from which you could read forward or backward an arbitrary number of bits). (So it was not only IBM’s Stretch, which was a failure.)
Burroughs B1700 是按位寻址的(实际上,地址指的是位之间的空间,你可以从中向前或向后读取任意数量的位)。所以,它不仅仅是失败的 IBM Stretch。
The B1700 was designed to be the most flexible machine. Applications were not meant to be written at the bit level, but different environments built for different application styles. These environments were programmed in microcode, providing the virtual machine engines. Each language (systems SDL for OS, COBOL for business, FORTRAN for COBOL) runtime was written as a separate microcoded environment. Thus the architecture could be tailored to any future application styles.
B1700 被设计成最灵活的机器。应用程序并不是用位来编写的,而是为不同的应用程序风格构建不同的环境。这些环境是用微代码编程的,提供了虚拟机引擎。每种语言(系统 SDL 用于操作系统,COBOL 用于商业,FORTRAN 用于 COBOL)的运行时都被编写为一个单独的微代码环境。因此,这种架构可以适应任何未来的应用程序风格。
Wayne Wilner, one of the designers, made the point that other machines of the time forced programmers to lie in the Procrustean bed of fixed-sized bytes and words. Really what each runtime environment required was data structures that suited the application. Unfortunately, most current machine architectures are still Procrustean (and thus programmed in languages like C that expose this machine structure, rather than supporting problem-oriented structures).
它的设计者之一韦恩·威尔纳指出,当时的其他机器强迫程序员躺在固定大小的字节和字的普罗克鲁斯特床上。实际上,每个运行时环境所需要的,是适合应用程序的数据结构。遗憾的是,大多数现代机器架构仍然是普罗克鲁斯特式的(因此用像 C 这样的语言编程,这种语言暴露了这种机器结构,而不是支持面向问题的结构)。
Further readings on this fascinating machine and its philosophy are available at:
关于这台迷人的机器及其哲学的进一步阅读材料可以在以下网址找到:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.590.2624&rep=rep1&type=pdf(链接已沉寂.)
and in more detail:
以及更详细的内容:
http://ianjoyner.name/Files/Wilner.pdf(链接已沉寂.)
So why is the B1700 no longer made?
那么,为什么不再生产 B1700 了呢?
Burroughs had three main ranges of computers, the large systems B5000-B7000 (ALGOL architecture), medium systems B2000-B4000 (COBOL architecture), and small systems B1000 (anything-you-like architecture).
Burroughs 有三大系列的计算机,大型系统 B5000 - B7000(ALGOL 架构)、中型系统 B2000 - B4000(COBOL 架构)和小型系统 B1000(随心所欲架构)。
The large systems were really expensive, until the B5900 which was microcoded on a cheap processor to provide the ALGOL stack machine. Jack Allweis, the designer of the B5900 has pointed out that the large system architecture thus scaled down into small computers, but the B1700 was designed to be cheap and did not scale up.
大型系统非常昂贵,直到 B5900,它是在一个廉价处理器上微代码化的,以提供 ALGOL 栈机器。B5900 的设计者杰克·奥尔韦斯指出,大型系统架构因此被缩小到小型计算机中,但 B1700 被设计成廉价的,并没有向上扩展。
Thus the B1700 to B1900, while very successful at the time, died for commercial reasons.
因此,B1700 到 B1900,尽管在当时非常成功,但最终因商业原因而停产。
Burroughs large systems are still available as Unisys ClearPath MCP and even runs on your PC as an emulation.
Burroughs 的大型系统仍然作为 Unisys ClearPath MCP 提供,并且甚至可以在你的 PC 上作为仿真运行。
As another footnote, IPC on the B1700 was a pain between different virtual machines, but very secure (like today’s microkernels). The large systems all ran processes in the same environment where data could be shared in a secure way, but IPC was direct. This is somewhat between microkernel architectures (Mach) and non-kernel (Linux). However, the B5000 is a very secure machine, but also performs well.
另一个注脚是,B1700 上不同虚拟机之间的进程间通信很痛苦,但非常安全(就像今天的微内核一样)。大型系统都在同一个环境中运行进程,数据可以在安全的方式下共享,但进程间通信是直接的。这有点介于微内核架构(Mach)和非内核(Linux)之间。然而,B5000 是一台非常安全的机器,而且性能也很好。
Security is the biggest problem in the industry now, and really these machines should be revived and studied to show the way forward.
安全是目前行业最大的问题,这些机器真的应该被复兴和研究,以指明前进的方向。
answered Dec 27, 2016 at 23:45
user3717661
2
Main question: What is the precise term for the smallest addressable memory block?
主要问题:最小可寻址内存块的精确术语是什么?
I’ll add another answer to address that in a different way. In electronic hardware, we call it the bit - binary digit. That is an entity that can represent any two values. We usually think in terms of 0 and 1, but it could be 3 or 4, 365 or 266, -3 or -4, even 25 or 37.
我将再添加一个答案,以不同的方式来回答这个问题。在电子硬件中,我们称之为位——二进制数字。这是一个可以表示任意两个值的实体。我们通常用 0 和 1 来表示,但它也可以是 3 或 4、365 或 266、-3 或 -4,甚至是 25 或 37。
Any signalling system can be used to represent these values - flag up, flag down, eyes open, eyes closed, +5v, -5v. That is not important.
任何信号系统都可以用来表示这些值——旗子升起、旗子放下、眼睛睁开、眼睛闭上、+5v、-5v。这并不重要。
What is important is that philosophically we are representing the smallest distinguishing amount of information. This could be on, off, or true, false, or up, down, or 0, 1 - anything that distinguishes two separate states. We can map these values onto any of the above signalling systems and many others.
重要的是,从哲学上讲,我们正在表示最小的可区分信息量。这可以是开、关,或者真、假,或者上、下,或者 0、1——任何能区分两个不同状态的东西。我们可以将这些值映射到上述任何信号系统以及许多其他系统上。
Now the question is, how can we test and set such a small amount of information individually? As I said in previous answer, the B1700 chose to address that smallest amount of information directly.
现在的问题是,我们如何分别测试和设置这么小的信息量呢?正如我在前面的答案中所说,B1700 选择直接寻址那最小的信息量。
However, most machines decided to only address larger amounts of information. Let’s consider a group of four bits with a single address. So if we get the value of 1011 in our location, how do we test the second bit from the left. We use a mask: 1011 and 0100 tests just the second bit. So how do we set second bit to 1? A little CPU arithmetic says the value will be 15 or 1111, so that entire four bits is written back to memory, even though we have really only set one bit.
然而,大多数机器决定只寻址更大的信息量。让我们考虑一个有单个地址的四位组。那么,如果我们在我们的位置得到 1011 的值,我们如何测试从左边数起的第二位呢?我们使用一个掩码:1011 和 0100 只测试第二位。那么,我们如何将第二位设置为 1 呢?一点 CPU 算术表明,该值将是 15 或 1111,因此整个四位组被写回内存,尽管我们实际上只设置了一个比特。
Now this is not useful for most applications. Most applications are representing data or information, up, down, true, false, open, shut.
现在,这并不适用于大多数应用程序。大多数应用程序都在表示数据或信息,上、下、真、假、开、关。
We want to say things like:
我们想说的是:
if open then … else … end
如果打开则……否则……结束
or more likely apply that to a larger entity:
或者更有可能将其应用于一个更大的实体:
if door is open then – most likely ‘door.open’ … else … end
如果门是开着的,那么——很可能“门.打开”……否则……结束
‘door is open’ illustrates hierarchical addressing. The main system addressing gives the entity door, and door has its own addressing which gives access to open (and maybe other attributes).
“门是开着的”说明了层次化寻址。主系统寻址给出了实体门,而门有自己的寻址,它提供了对打开(以及可能的其他属性)的访问。
Most sets also have more than two possible values (a set with one value never changes and therefore does not even need representation, so zero bits). For these we have enumerated sets, like (yellow, green, blue, purple haze, red). These define sets and types and the exact number of bits required is given by the number of values (log2 (number of values)).
大多数集合也有超过两个可能的值(一个只有一个值的集合永远不会改变,因此甚至不需要表示,即零比特)。对于这些,我们有枚举集合,如(黄色、绿色、蓝色、紫色烟雾、红色)。这些定义了集合和类型,所需的精确比特数由值的数量给出(log2(值的数量))。
Thus the optimal addressing really depends on the entity size used in the application - maybe even variable sized entities. But in most hardware such addresses must be translated to the fixed size the hardware defines. This of course could cost in terms of time. It should also be something that an automatic translator does (compiler or interpreter), not a programmer, just as such a system would generate code to test and set bits as above (if bits aren’t directly addressable).
因此,最优寻址实际上取决于应用程序中使用的实体大小——甚至可能是大小可变的实体。但在大多数硬件中,这样的地址必须被转换为硬件定义的固定大小。当然,这可能会在时间上付出代价。这也应该是自动翻译器(编译器或解释器)做的事情,而不是程序员,就像这样的系统会生成上面测试和设置比特的代码一样(如果比特不是直接可寻址的)。
An important point here is not to think in terms of electronics - electronics is just a really good and fast way of processing computations. There is nothing magic about electronic computation that makes it possible to do computations you couldn’t do otherwise. The magic is only in the speed. That is why low-level abstractions such as bit, byte, word, or hardware addressing mechanisms (pointers) are really not that useful.
这里的一个重要观点是不要用电子学的思维方式来思考——电子学只是处理计算的一种非常好且快速的方法。电子计算并没有什么神奇之处,使得它能够进行你否则无法进行的计算。它的神奇之处仅仅在于速度。这也是为什么像位、字节、字或硬件寻址机制(指针)这样的低级抽象实际上并不那么有用。
edited Dec 28, 2016 at 4:55
answered Dec 28, 2016 at 2:44
user3717661
What platforms have something other than 8-bit char?
168
Every now and then, someone on SO points out that char (aka ‘byte’) isn’t necessarily 8 bits _.
每隔一段时间,就有人在 SO 上指出 char(即“字节”)并不一定是 8 位 。
It seems that 8-bit char is almost universal. I would have thought that for mainstream platforms, it is necessary to have an 8-bit char to ensure its viability in the marketplace.
8 位的 char 似乎已经非常普遍了。我本以为对于主流平台来说,拥有 8 位的 char 是确保其在市场上可行的必要条件。
Both now and historically, what platforms use a char that is not 8 bits, and why would they differ from the “normal” 8 bits?
无论是现在还是历史上,有哪些平台使用的 char 不是 8 位的,它们为什么会与“正常”的 8 位不同呢?
When writing code, and thinking about cross-platform support (e.g. for general-use libraries), what sort of consideration is it worth giving to platforms with non-8-bit char?
在编写代码时,考虑到跨平台支持(例如,对于通用库),值得给予那些非 8 位 char 的平台什么样的考虑呢?
In the past I’ve come across some Analog Devices DSPs for which char is 16 bits. DSPs are a bit of a niche architecture I suppose. (Then again, at the time hand-coded assembler easily beat what the available C compilers could do, so I didn’t really get much experience with C on that platform.)
过去我遇到过一些 Analog Devices 的 DSP,其 char 是 16 位的。DSP 是一种比较小众的架构,我想。 (不过话说回来,在那个时代,手工编写的汇编代码轻松地超过了可用的 C 编译器的性能,所以我并没有在那个平台上积累太多使用 C 的经验。)
edited May 23, 2017 at 11:54
asked Jan 20, 2010 at 0:03
Craig McQueen
-
10
The CDC Cyber series had a 6/12 bit encoding. The most popular characters were 6 bits. The remaining characters used 12 bits.CDC Cyber 系列采用了 6/12 位编码。最受欢迎的字符是 6 位的。其余字符使用 12 位。
– Thomas Matthews
Commented Jan 20, 2010 at 0:07 -
3
The PDP-11 nailed it down. The notion that a character can be encoded in a char is seriously obsolete.PDP-11 确定了这一点。认为一个字符可以编码在 char 中的想法已经严重过时了。
– Hans Passant
Commented Jan 20, 2010 at 1:38 -
11
“The PDP-11 nailed it down” – You mean because C was first implemented for the PDP-11 with 8 bit bytes? But C was next implemented for Honeywell machines with 9 bit bytes. See K&R version 1. Also, the question asked about char (i.e. byte) not about character (one or more bytes encoding something that wasn’t asked about).“PDP-11 确定了这一点”——你的意思是 C 最初是在具有 8 位字节的 PDP-11 上实现的吗?但接下来 C 又在具有 9 位字节的 Honeywell 机器上实现了。参见 K&R 第一版。此外,问题问的是 char(即字节),而不是关于字符(一个或多个字节编码的内容,这并不是问题所涉及的)。
– Windows programmer
Commented Jan 20, 2010 at 3:407
DEC-10 and DEC-20 had 36-bit words. Five 7-bit ASCII characters per word was quite common. Also six 6-bit characters were used.DEC-10 和 DEC-20 有 36 位的字。每个字包含五个 7 位的 ASCII 字符是很常见的。此外,也使用了六个 6 位的字符。
– David R Tribble
Commented Jan 20, 2010 at 17:12 -
3
@CraigMcQueen : If I remember correctly, CodeVision for Atmel microcontrollers lets one choose the size of char@CraigMcQueen :如果我没记错的话,用于 Atmel 微控制器的 CodeVision 允许用户选择 char 的大小。
– vsz
Commented Feb 20, 2016 at 10:10
14 Answers
113
char is also 16 bit on the Texas Instruments C54x DSPs, which turned up for example in OMAP2. There are other DSPs out there with 16 and 32 bit char. I think I even heard about a 24-bit DSP, but I can’t remember what, so maybe I imagined it.
char 在德州仪器的 C54x DSP 上也是 16 位的,这种 DSP 例如出现在 OMAP2 中。还有其他 DSP 的 char 是 16 位和 32 位的。我想我甚至听说过有一种 24 位的 DSP,但我记不起是什么了,所以也许是我自己想象出来的。
Another consideration is that POSIX mandates CHAR_BIT == 8. So if you’re using POSIX you can assume it. If someone later needs to port your code to a near-implementation of POSIX, that just so happens to have the functions you use but a different size char, that’s their bad luck.
另一个需要考虑的是,POSIX 规定 CHAR_BIT == 8。因此,如果你使用的是 POSIX,你可以假设它。如果有人后来需要将你的代码移植到一个接近 POSIX 的实现上,而这个实现恰好有你使用的函数,但 char 的大小不同,那么这就是他们的不幸了。
In general, though, I think it’s almost always easier to work around the issue than to think about it. Just type CHAR_BIT. If you want an exact 8 bit type, use int8_t. Your code will noisily fail to compile on implementations which don’t provide one, instead of silently using a size you didn’t expect. At the very least, if I hit a case where I had a good reason to assume it, then I’d assert it.
不过,总的来说,我认为几乎总是绕过这个问题比去思考它要容易得多。只需键入 CHAR_BIT。如果你想要一个精确的 8 位类型,就使用 int8_t。如果你的代码在没有提供这种类型实现上编译失败,那会发出很大的噪音,而不是默默地使用一个你没有预料到的大小。至少,如果我遇到一个我有充分理由假设它的情况,那么我会断言它。
edited Jul 6, 2012 at 13:54
answered Jan 20, 2010 at 1:22
Steve Jessop
-
2
TI C62xx and C64xx DSPs also have 16-bit chars. (uint8_t isn’t defined on that platform.)TI C62xx 和 C64xx DSP 也有 16 位的 char。(在该平台上没有定义 uint8_t。)
– myron-semack
Commented Jan 20, 2010 at 2:35
-
8
Many DSPs for audio processing are 24-bit machines; the BelaSigna DSPs from On Semi (after they bought AMI Semi); the DSP56K/Symphony Audio DSPs from Freescale (after they were spun off from Motorola).许多用于音频处理的 DSP 是 24 位的机器;来自 On Semi(在他们收购了 AMI Semi 之后)的 BelaSigna DSP;来自 Freescale(在他们从 Motorola 分拆出来之后)的 DSP56K/Symphony Audio DSP。
– David Cary
Commented Jul 6, 2012 at 13:52 -
3
@msemack C64xx has hardware for 8/16/32/40, and 8bit char
@msemack C64xx 有支持 8/16/32/40 位的硬件,以及 8 位的 char。
– user3528438
Commented Apr 16, 2015 at 20:45 -
5
Rather thanassert()(if that’s what you meant), I’d use#if CHAR_BIT != 8…#error "I require CHAR_BIT == 8"…#endif
与其使用assert()(如果你是指这个的话),我建议使用#if CHAR_BIT != 8…#error "I require CHAR_BIT == 8"…#endif
– Keith Thompson
Commented Oct 2, 2015 at 20:52 -
2
@KeithThompson Is there any reason not to usestatic_assert()?
@KeithThompson 使用static_assert()有什么理由吗?
– Qix - MONICA WAS MISTREATED
Commented Feb 17, 2017 at 4:35
44
When writing code, and thinking about cross-platform support (e.g. for general-use libraries), what sort of consideration is it worth giving to platforms with non-8-bit char?
在编写代码时,考虑到跨平台支持(例如,对于通用库),值得给予那些非 8 位 char 的平台什么样的考虑呢?
It’s not so much that it’s “worth giving consideration” to something as it is playing by the rules. In C++, for example, the standard says all bytes will have “at least” 8 bits. If your code assumes that bytes have exactly 8 bits, you’re violating the standard.
这并不是说“值得考虑”某件事,而是要遵守规则。例如,在 C++ 中,标准规定所有字节都将有“至少”8 位。如果你的代码假设字节正好有 8 位,那么你就是在违反标准。
This may seem silly now – “of course all bytes have 8 bits!”, I hear you saying. But lots of very smart people have relied on assumptions that were not guarantees, and then everything broke. History is replete with such examples.
这听起来可能很愚蠢——“当然 所有字节都有 8 位!”,我听到你在说。但是,许多非常聪明的人依赖于并非有保证的假设,然后一切都崩溃了。历史上充满了这样的例子。
For instance, most early-90s developers assumed that a particular no-op CPU timing delay taking a fixed number of cycles would take a fixed amount of clock time, because most consumer CPUs were roughly equivalent in power. Unfortunately, computers got faster very quickly. This spawned the rise of boxes with “Turbo” buttons – whose purpose, ironically, was to slow the computer down so that games using the time-delay technique could be played at a reasonable speed.
例如,大多数 90 年代初的开发人员都认为,一个特定的无操作 CPU 定时延迟占用固定数量的周期,就会占用固定数量的时钟时间,因为大多数消费级 CPU 的性能大致相当。不幸的是,计算机很快就变得更快了。这促成了带有“Turbo”按钮的盒子的兴起——讽刺的是,这些按钮的目的是减慢计算机的速度,以便使用时间延迟技术的游戏能够以合理的速度运行。
One commenter asked where in the standard it says that char must have at least 8 bits. It’s in section 5.2.4.2.1. This section defines CHAR_BIT, the number of bits in the smallest addressable entity, and has a default value of 8. It also says:
一位评论者问标准在哪里规定 char 必须至少有 8 位。它在 5.2.4.2.1 节。这一节定义了 CHAR_BIT,即最小可寻址实体中的位数,并且默认值为 8。它还说:
Their implementation-defined values shall be equal or greater in magnitude (absolute value) to those shown, with the same sign.
它们的实现定义值应等于或大于所示值的绝对值,并且符号相同。
So any number equal to 8 or higher is suitable for substitution by an implementation into
CHAR_BIT.edited Jan 20, 2010 at 14:50
因此,任何等于或大于 8 的数字都适合由实现替换到
CHAR_BIT中。answered Jan 20, 2010 at 0:19
John Feminella
-
6
I haven’t seen a Turbo button in at least 20 years - do you really think it’s germane to the question?至少 20 年没看到过 Turbo 按钮了——你真的认为它与问题相关吗?
– Mark Ransom
Commented Jan 20, 2010 at 3:30 -
34
@Mark Ransom: That’s the whole point. Developers often rely on assumptions which seem to be true at the moment, but which are much shakier than they initially appear. (Can’t count the number of times I’ve made that mistake!) The Turbo button should be a painful reminder not to make unnecessary assumptions, and certainly not to make assumptions that aren’t guaranteed by a language standard as if they were immutable facts.
@Mark Ransom:这就是重点所在。开发人员常常依赖于那些看似在当时为真的假设,但这些假设实际上比它们最初看起来要脆弱得多。(我犯过这种错误的次数数都数不过来!)Turbo 按钮应该是一个痛苦的提醒,告诫我们不要做出不必要的假设,当然更不要把那些并非由语言标准所保证的假设当作不可改变的事实。
– John Feminella
Commented Jan 20, 2010 at 3:33 -
6
Section 18.2.2 invokes the C standard for it. In the C standard it’s section 7.10 and then section 5.4.2.4.1. Page 22 in the C standard.
第 18.2.2 节引用了 C 标准。在 C 标准中,它是第 7.10 节,然后是第 5.4.2.4.1 节。在 C 标准的第 22 页。
– Windows programmer
Commented Jan 21, 2010 at 3:48 -
3
@JerryJeremiah: You can run C on a machine whose hardware datum unit is less than 8 bits, but then a C “byte” will be multiple datum units. Your physical pointers will have a step size less than a byte, but the C program will never use that granularity. (And note there won’t be any C data type for a sub-byte datum)
@JerryJeremiah:你可以在硬件数据单元小于 8 位的机器上运行 C,但此时 C 中的“字节”将由多个数据单元组成。你的物理指针将有一个小于字节的步长,但 C 程序永远不会使用这种粒度。(请注意,不会有用于亚字节数据的 C 数据类型)
– Ben Voigt
Commented Jan 17, 2019 at 21:50 -
4
Saying that code that assumes thatcharis 8 bits is “violating the standard” isn’t really accurate–the standard does not mandate that your code be portable. Your code is just implementation-specific but still valid; perhaps (purposefully) “ignorant of the C/C++ language standards”. (If POSIX is the standard you care about, this is not just valid but guaranteed).
说假设char是 8 位的代码“违反了标准”并不完全准确——标准并没有要求你的代码必须是可移植的。你的代码只是特定于实现的,但仍然是有效的;也许(故意地)是“不了解 C/C++ 语言标准的”。(如果你关心的是 POSIX 标准,那么这不仅是有效的,而且是有保证的)。
– saagarjha
Commented Sep 2, 2020 at 22:34
40
Machines with 36-bit architectures have 9-bit bytes. According to Wikipedia, machines with 36-bit architectures include:具有 36 位架构的机器有 9 位字节。根据维基百科,具有 36 位架构的机器包括:
Digital Equipment Corporation PDP-6/10
IBM 701/704/709/7090/7094
UNIVAC 1103/1103A/1105/1100/2200,
answered Jan 20, 2010 at 0:20
R Samuel Klatchko
-
7
Also Honeywell machines, such as maybe the second machine where C was implemented. See K&R version 1.
还有 Honeywell 机器,例如可能是 C 实现的第二台机器。参见 K&R 第一版。
– Windows programmer
Commented Jan 20, 2010 at 3:44 -
6
Actually, the Dec-10 had also 6-bit characters - you could pack 6 of these into a 36-bit word (ex-Dec-10 programmer talking)
实际上,Dec-10 也有 6 位字符——你可以将 6 个这样的字符打包到一个 36 位的字中(一个曾经的 Dec-10 程序员在说话)
– anon
Commented Jan 20, 2010 at 14:52 -
3
That joke was actually implemented for supporting Unicode on this architecture.
那个玩笑实际上是为了在这个架构上支持 Unicode 而实现的。
– Joshua
Commented Dec 14, 2011 at 7:31 -
10
I imagine that the reason octal was ever actually used was because 3 octal digits neatly represent a 9-bit byte, just like we usually use hexadecimal today because two hexadecimal digits neatly represent an 8-bit byte.
我想,八进制被真正使用的原因是因为 3 个八进制数字可以整齐地表示一个 9 位字节,就像我们今天通常使用十六进制一样,因为两个十六进制数字可以整齐地表示一个 8 位字节。
– bames53
Commented Jul 11, 2012 at 0:20 -
3
The PDP-6/PDP-10/DEC-10/DEC-20 did not have just 6-bit bytes, or 7-bit bytes, or 8-bit bytes, or 9-bit bytes. It had an arbitrary byte size from 1 to 36 bits.
PDP-6/PDP-10/DEC-10/DEC-20 并不只有 6 位字节,或 7 位字节,或 8 位字节,或 9 位字节。它的字节大小是任意的,从 1 到 36 位。
– Lars Brinkhoff
Commented May 7, 2015 at 6:53
20
A few of which I’m aware:
我所知道的一些情况如下: -
DEC PDP-10: variable, but most often 7-bit chars packed 5 per 36-bit word, or else 9 bit chars, 4 per word
DEC PDP-10:可变的,但通常是 7 位字符,每 36 位字包含 5 个,或者 9 位字符,每字 4 个 -
Control Data mainframes (CDC-6400, 6500, 6600, 7600, Cyber 170, Cyber 176 etc.) 6-bit chars, packed 10 per 60-bit word.
Control Data 主机(CDC-6400、6500、6600、7600、Cyber 170、Cyber 176 等):6 位字符,每 60 位字包含 10 个。 -
Unisys mainframes: 9 bits/byte
Unisys 主机:每字节 9 位 -
Windows CE: simply doesn’t support the
chartype at all – requires 16-bit wchar_t insteadWindows CE:根本不支持
char类型——需要使用 16 位的 wchar_t 代替
answered Jan 20, 2010 at 0:38
Jerry Coffin -
2
@ephemient:I’m pretty sure there was at least one (pre-standard) C compiler for the PDP-10/DecSystem 10/DecSystem 20. I’d be very surprised at a C compiler for the CDC mainframes though (they were used primarily for numeric work, so the Fortran compiler was the big thing there). I’m pretty sure the others do have C compilers.@ephemient:我相当肯定至少有一个(非标准的)C 编译器用于 PDP-10/DecSystem 10/DecSystem 20。不过,对于 CDC 主机来说,我将会非常惊讶于存在一个 C 编译器(它们主要用于数值计算,所以 Fortran 编译器才是主要的)。我相当肯定其他的机器确实有 C 编译器。
– Jerry Coffin
Commented Jan 20, 2010 at 1:28 -
4
Did the Windows CE compiler really not support thechartype at all? I know that the system libraries only supported the wide char versions of functions that take strings, and that at least some versions of WinCE removed the ANSI string functions like strlen, to stop you doing char string-handling. But did it really not have a char type at all? What wassizeof(TCHAR)? What type did malloc return? How was the Javabytetype implemented?Windows CE 编译器真的根本不支持
char类型吗?我知道系统库只支持接收字符串的宽字符版本的函数,而且至少有一些 WinCE 版本移除了像 strlen 这样的 ANSI 字符串函数,以阻止你进行 char 字符串处理。但它真的没有 char 类型吗?sizeof(TCHAR)是多少?malloc 返回的是什么类型?Java 的byte类型是如何实现的?
– Steve Jessop
Commented Jan 20, 2010 at 1:33 -
13
Windows CE supports char, which is a byte. See Craig McQueen’s comment on Richard Pennington’s answer. Bytes are needed just as much in Windows CE as everywhere else, no matter what sizes they are everywhere else.Windows CE 支持 char,它是一个字节。参见 Craig McQueen 对 Richard Pennington 的回答的评论。Windows CE 需要字节,就像其他地方一样,不管其他地方的字节大小如何。
– Windows programmer
Commented Jan 20, 2010 at 3:44 -
2
There are (were?) at least two implementations of C for the PDP-10: KCC and a port of gcc (pdp10.nocrew.org/gcc).对于 PDP-10 至少有(曾经有?)两个 C 的实现:KCC 和一个 gcc 的移植版本(pdp10.nocrew.org/gcc)。
– AProgrammer
Commented Jan 21, 2010 at 12:43 -
3
The C standard would not allow 7-bit chars packed 5 per 36-bit word (as you mentioned for the PDP-10), nor would it allow 6-bit chars, as you mentioned for the Control Data mainframes. See parashift.com/c+±faq-lite/intrinsic-types.html#faq-26.6C 标准既不允许(像你提到的 PDP-10 那样)将 5 个 7 位字符打包进一个 36 位字中,也不允许(像你提到的 Control Data 大型机那样)使用 6 位字符。
– Ken Bloom
Commented Aug 7, 2011 at 23:58
19
There is no such thing as a completely portable code. 😃根本不存在完全可移植的代码。 😃
Yes, there may be various byte/char sizes. Yes, there may be C/C++ implementations for platforms with highly unusual values of CHAR_BIT and UCHAR_MAX. Yes, sometimes it is possible to write code that does not depend on char size.
是的,可能会有各种不同的字节/字符大小。是的,可能会有一些针对 CHAR_BIT 和 UCHAR_MAX 有非常不寻常值的平台的 C/C++ 实现。是的,有时确实可以编写不依赖于字符大小的代码。
However, almost any real code is not standalone. E.g. you may be writing a code that sends binary messages to network (protocol is not important). You may define structures that contain necessary fields. Than you have to serialize it. Just binary copying a structure into an output buffer is not portable: generally you don’t know neither the byte order for the platform, nor structure members alignment, so the structure just holds the data, but not describes the way the data should be serialized.
然而,几乎任何真正的代码都不是独立的。例如,你可能正在编写一个向网络发送二进制消息的代码(协议并不重要)。你可以定义包含必要字段的结构体。然后你需要序列化它。简单地将一个结构体二进制复制到输出缓冲区是不可移植的:通常你既不知道平台的字节序,也不知道结构体成员的对齐方式,所以结构体只是持有数据,但并没有描述数据应该如何被序列化。
Ok. You may perform byte order transformations and move the structure members (e.g. uint32_t or similar) using memcpy into the buffer. Why memcpy? Because there is a lot of platforms where it is not possible to write 32-bit (16-bit, 64-bit – no difference) when the target address is not aligned properly.
好的。你可以进行字节序转换,并使用 memcpy 将结构体成员(例如 uint32_t 或类似的类型)移动到缓冲区。为什么是 memcpy?因为有很多平台在目标地址没有正确对齐时,无法写入 32 位(16 位、64 位——没有区别)数据。
So, you have already done a lot to achieve portability.
所以,你已经做了很多工作来实现可移植性。
And now the final question. We have a buffer. The data from it is sent to TCP/IP network. Such network assumes 8-bit bytes. The question is: of what type the buffer should be? If your chars are 9-bit? If they are 16-bit? 24? Maybe each char corresponds to one 8-bit byte sent to network, and only 8 bits are used? Or maybe multiple network bytes are packed into 24/16/9-bit chars? That’s a question, and it is hard to believe there is a single answer that fits all cases. A lot of things depend on socket implementation for the target platform.
现在是最后一个问题。我们有一个缓冲区。该缓冲区中的数据将被发送到 TCP/IP 网络。这种网络假设字节是 8 位的。问题是:缓冲区应该是什么类型?如果你的字符是 9 位的呢?如果是 16 位的呢?24 位呢?也许每个字符对应一个发送到网络的 8 位字节,而且只使用 8 位?或者也许是多个网络字节被打包到 24/16/9 位的字符中?这是一个问题,很难相信有一个答案能适用于所有情况。很多事情取决于目标平台的套接字实现。
So, what I am speaking about. Usually code may be relatively easily made portable to certain extent. It’s very important to do so if you expect using the code on different platforms. However, improving portability beyond that measure is a thing that requires a lot of effort and often gives little, as the real code almost always depends on other code (socket implementation in the example above). I am sure that for about 90% of code ability to work on platforms with bytes other than 8-bit is almost useless, for it uses environment that is bound to 8-bit. Just check the byte size and perform compilation time assertion. You almost surely will have to rewrite a lot for a highly unusual platform.
所以,我在说的是。通常代码可以相对容易地做到一定程度的可移植性。如果你希望在不同平台上使用代码,这是非常重要的。然而,将可移植性提高到那个程度以上是一件需要付出很多努力而且往往收益很少的事情,因为真正的代码几乎总是依赖于其他代码(上面例子中的套接字实现)。我敢肯定,对于大约 90% 的代码来说,在非 8 位字节的平台上运行的能力几乎是没用的,因为它使用的是绑定到 8 位的环境。只需检查字节大小并执行编译时断言即可。你几乎肯定需要为一个非常不寻常的平台重写很多代码。
But if your code is highly “standalone” – why not? You may write it in a way that allows different byte sizes.
但是如果你的代码高度“独立”——为什么不呢?你可以以一种允许不同字节大小的方式编写它。
answered Nov 28, 2013 at 17:14
Ellioh
-
5
If one stores one octet perunsigned charvalue there should be no portability problems unless code uses aliasing tricks rather than shifts to convert sequences of octets to/from larger integer types. Personally, I think the C standard should define intrinsics to pack/unpack integers from sequences of shorter types (most typicallychar) storing a fixed guaranteed-available number of bits per item (8 perunsigned char, 16 perunsigned short, or 32 perunsigned long).如果每个
unsigned char值存储一个八位字节,那么应该不存在可移植性问题,除非代码使用别名技巧而不是移位来将八位字节序列转换为/从更大的整数类型转换。我个人认为 C 标准应该定义内联函数,从较短类型的序列(通常是char)中打包/解包整数,每项存储一个固定且保证可用的位数(unsigned char每个 8 位,unsigned short每个 16 位,或者unsigned long每个 32 位)。
– supercat
Commented Jul 25, 2015 at 19:42
10
It appears that you can still buy an IM6100 (i.e. a PDP-8 on a chip) out of a warehouse. That’s a 12-bit architecture.看起来你仍然可以从仓库中 购买 IM6100(即芯片上的 PDP-8)。这是一个 12 位的架构。
answered Jan 20, 2010 at 1:02
dmckee — ex-moderator kitten9
Many DSP chips have 16- or 32-bitchar. TI routinely makes such chips for example.许多 DSP 芯片的
char是 16 位或 32 位的。TI 通常会制造这样的芯片。
answered Jan 20, 2010 at 3:18
Alok Singhal
6
The C and C++ programming languages, for example, define byte as “addressable unit of data large enough to hold any member of the basic character set of the execution environment” (clause 3.6 of the C standard). Since the C char integral data type must contain at least 8 bits (clause 5.2.4.2.1), a byte in C is at least capable of holding 256 different values. Various implementations of C and C++ define a byte as 8, 9, 16, 32, or 36 bits
例如,C 和 C++ 编程语言将字节定义为“足够大以容纳执行环境的基本字符集的任何成员的可寻址数据单位”(C 标准的第 3.6 条)。由于 C 的 char 整数数据类型必须至少包含 8 位(第 5.2.4.2.1 条),因此 C 中的字节至少能够容纳 256 个不同的值。C 和 C++ 的各种实现将字节定义为 8、9、16、32 或 36 位。
Quoted from http://en.wikipedia.org/wiki/Byte#History
引用自 <http://en.wikipedia.org/wiki/Byte#History
Not sure about other languages though.
不过,我不确定其他语言的情况。
<http://en.wikipedia.org/wiki/IBM_7030_Stretch#Data_Formats
Defines a byte on that machine to be variable length
在该机器上定义字节为可变长度
edited Jan 20, 2010 at 0:17
answered Jan 20, 2010 at 0:08
petantik
-
1
“Not sure about other languages though” – historically, most languages allowed the machine’s architecture to define its own byte size. Actually historically so did C, until the standard set a lower bound at 8.“不过,我不确定其他语言的情况。”——从历史上来看,大多数语言都允许机器的架构定义自己的字节大小。实际上,C 也是这样,直到标准将下限设定为 8。
– Windows programmer
Commented Jan 20, 2010 at 3:45
5
The DEC PDP-8 family had a 12 bit word although you usually used 8 bit ASCII for output (on a Teletype mostly). However, there was also a 6-BIT character code that allowed you to encode 2 chars in a single 12-bit word.DEC PDP-8 系列有一个 12 位的字,尽管你通常使用 8 位 ASCII 进行输出(主要是在电传打字机上)。然而,还有一个 6 位字符代码,允许你在单个 12 位字中编码 2 个字符。
edited Apr 18, 2010 at 17:21
answered Mar 10, 2010 at 13:46
PrgTrdr
3
For one, Unicode characters are longer than 8-bit. As someone mentioned earlier, the C spec defines data types by their minimum sizes. Use sizeof and the values in limits.h if you want to interrogate your data types and discover exactly what size they are for your configuration and architecture.
bta
首先,Unicode 字符的长度超过 8 位。正如前面有人提到的,C 规范通过最小尺寸来定义数据类型。如果你想查询你的数据类型,并了解它们在你的配置和架构中的确切大小,请使用 sizeof 和 limits.h 中的值。
For this reason, I try to stick to data types like uint16_t when I need a data type of a particular bit length.
因此,当需要特定比特长度的数据类型时,我尽量使用像 uint16_t 这样的数据类型。
Edit: Sorry, I initially misread your question.
编辑:抱歉,我最初误解了你的问题。
The C spec says that a char object is “large enough to store any member of the execution character set”. limits.h lists a minimum size of 8 bits, but the definition leaves the max size of a char open.
Thus, the a char is at least as long as the largest character from your architecture’s execution set (typically rounded up to the nearest 8-bit boundary). If your architecture has longer opcodes, your char size may be longer.
C 规范指出,char 对象“足够大,能够存储执行字符集的任何成员”。limits.h 列出了 8 位的最小尺寸,但定义中没有明确 char 的最大尺寸。
Historically, the x86 platform’s opcode was one byte long, so char was initially an 8-bit value. Current x86 platforms support opcodes longer than one byte, but the char is kept at 8 bits in length since that’s what programmers (and the large volumes of existing x86 code) are conditioned to.
从历史上看,x86 平台的操作码是一个字节长,因此 char 最初是一个 8 位的值。当前的 x86 平台支持超过一个字节的操作码,但由于程序员(以及大量的现有 x86 代码)已经习惯了 8 位的 char,所以 char 的长度仍然保持为 8 位。
因此,char 至少与你的架构执行集中最大的字符一样长(通常向上舍入到最近的 8 位边界)。如果你的架构有更长的操作码,那么你的 char 大小可能会更长。
When thinking about multi-platform support, take advantage of the types defined in stdint.h. If you use (for instance) a uint16_t, then you can be sure that this value is an unsigned 16-bit value on whatever architecture, whether that 16-bit value corresponds to a char, short, int, or something else. Most of the hard work has already been done by the people who wrote your compiler/standard libraries.
在考虑多平台支持时,可以利用 stdint.h 中定义的类型。如果你使用(例如)uint16_t,那么你可以确信这个值在任何架构上都是一个无符号的 16 位值,无论这个 16 位值对应于 char、short、int 还是其他类型。大多数艰苦的工作已经由编写你的编译器/标准库的人完成了。
If you need to know the exact size of a char because you are doing some low-level hardware manipulation that requires it, I typically use a data type that is large enough to hold a char on all supported platforms (usually 16 bits is enough) and run the value through a convert_to_machine_char routine when I need the exact machine representation. That way, the platform-specific code is confined to the interface function and most of the time I can use a normal uint16_t.
如果你需要知道 char 的确切大小,因为你正在进行一些需要它的低级硬件操作,我通常会使用一个足够大以容纳所有支持平台上 char 的数据类型(通常 16 位就足够了),并在需要精确的机器表示时,将值通过一个 convert_to_machine_char 常规。这样,特定于平台的代码就被限制在接口函数中,而大多数时候我可以使用普通的 uint16_t。
-
2
The question didn’t ask about characters (whether Unicode or not). It asked about char, which is a byte.
问题问的不是字符(无论是 Unicode 还是其他字符)。它问的是 char,这是一个字节。 -
– Windows programmer
Commented Jan 20, 2010 at 3:41 -
1
Also, the execution character set has nothing to do with opcodes, it’s the character set used at execution, think of cross-compilers.
此外,执行字符集与操作码无关,它是执行时使用的字符集,想想交叉编译器。
– ninjalj
Commented Jul 8, 2010 at 20:15
- 1
“Historically, the x86 platform’s opcode was one byte long” : how sweet. Historically, C was developed on a PDP-11 (1972), long before x86 had been invented (1978).
“从历史上看,x86 平台的操作码是一个字节长”:这太好了。从历史上看,C 是在 PDP-11(1972 年)上开发的,远远早于 x86 的发明(1978 年)。
– Martin Bonner supports Monica
Commented Mar 27, 2018 at 7:54
3
what sort of consideration is it worth giving to platforms with non-8-bit char?
非 8 位 char 的平台值得给予什么样的考虑呢?
magic numbers occur e.g. when shifting;
例如在移位操作中会出现神奇的数字;
most of these can be handled quite simply by using CHAR_BIT and e.g. UCHAR_MAX instead of 8 and 255 (or similar).
大多数这些情况可以通过使用 CHAR_BIT 和例如 UCHAR_MAX(而不是 8 和 255 或类似的值)来相当简单地处理。
hopefully your implementation defines those
希望你的实现定义了这些
those are the “common” issues…
这些都是“常见”的问题…
another indirect issue is say you have:
另一个间接问题是比如说你有:
struct xyz {
uchar baz;
uchar blah;
uchar buzz;
}
this might “only” take (best case) 24 bits on one platform, but might take e.g. 72 bits elsewhere…
这在某个平台上“可能”只需要(最好情况)24 位,但在其他地方可能需要例如 72 位…
if each uchar held “bit flags” and each uchar only had 2 “significant” bits or flags that you were currently using, and you only organized them into 3 uchars for “clarity”, then it might be relatively “more wasteful” e.g. on a platform with 24-bit uchars…
如果每个 uchar 都包含“位标志”,并且每个 uchar 只有 2 个“重要”的位或标志是你当前正在使用的,并且你只是将它们组织成 3 个 uchars 以“更清晰”,那么在 24 位的 uchar 平台上,这可能相对“更浪费”…
nothing bitfields can’t solve, but they have other things to watch out for …
位字段可以解决这个问题,但它们还有其他需要注意的地方 …
in this case, just a single enum might be a way to get the “smallest” sized integer you actually need…
在这种情况下,一个单一的枚举可能是获得你实际需要的“最小”整数大小的方法…
perhaps not a real example, but stuff like this “bit” me when porting / playing with some code…
也许这不是一个真正的例子,但当我移植/玩一些代码时,类似这样的问题“困扰”了我…
just the fact that if a uchar is thrice as big as what is “normally” expected, 100 such structures might waste a lot of memory on some platforms… where “normally” it is not a big deal…
仅仅因为如果 uchar 比“正常”期望的要大三倍,那么 100 个这样的结构在某些平台上可能会浪费很多内存…而在“正常”情况下,这不是什么大不了的事…
so things can still be “broken” or in this case “waste a lot of memory very quickly” due to an assumption that a uchar is “not very wasteful” on one platform, relative to RAM available, than on another platform…
所以,由于假设 uchar 在一个平台上“不那么浪费”,与另一个平台上的可用 RAM 相比,事情仍然可能“出错”,或者在这种情况下,“非常迅速地浪费大量内存”…
the problem might be more prominent e.g. for ints as well, or other types, e.g. you have some structure that needs 15 bits, so you stick it in an int, but on some other platform an int is 48 bits or whatever…
这个问题在例如 int 或其他类型中可能更加突出,例如你有一些结构需要 15 位,所以你把它放在一个 int 中,但在其他某个平台上,int 是 48 位或别的什么…
“normally” you might break it into 2 uchars, but e.g. with a 24-bit uchar you’d only need one…
“正常情况下”,你可能会把它分成 2 个 uchars,但如果是一个 24 位的 uchar,你只需要一个…
so an enum might be a better “generic” solution …
所以,枚举可能是一个更好的“通用”解决方案 …
depends on how you are accessing those bits though :
这取决于你如何访问这些位 :
so, there might be “design flaws” that rear their head… even if the code might still work/run fine regardless of the size of a uchar or uint…
所以,可能会出现“设计缺陷”…即使代码可能仍然可以正常运行,不管 uchar 或 uint 的大小如何…
there are things like this to watch out for, even though there are no “magic numbers” in your code …
即使你的代码中没有“神奇的数字”,也有像这样的东西需要注意 …
hope this makes sense :
希望这讲得通 :
answered Aug 24, 2012 at 7:46
dd ee
-
1
…what? Why do you thinkenumis likely to be smaller than other native types? Are you aware it defaults to the same storage asint? “you have some structure that needs 15 bits, so you stick it in an int, but on some other platform an int is 48 bits or whatever…” - so#include <cstdint>and make it anint16_tfor the best chance of minimising bit usage. I’m really not sure what you thought you were saying among all those ellipses.……什么?你为什么认为
enum可能比其他本地类型更小?你知道它默认使用与int相同的存储空间吗?“你有一些结构需要 15 位,所以你把它放在一个 int 中,但在其他某个平台上,int 是 48 位或别的什么……”——那么#include <cstdint>,并将其设为int16_t,以最大程度地减少位的使用。我真的不确定你在这么多省略号中到底想说什么。– underscore_d
Commented Nov 22, 2015 at 0:40
2
The weirdest one I saw was the CDC computers. 6 bit characters but with 65 encodings. [There were also more than one character set – you choose the encoding when you install the OS.]
我见过的最奇怪的是 CDC 计算机。6 位字符,但有 65 种编码。[还有不止一种字符集——你在安装操作系统时选择编码。]
If a 60 word ended with 12, 18, 24, 30, 36, 40, or 48 bits of zero, that was the end of line character (e.g. '\n').
如果一个 60 位的字以 12、18、24、30、36、40 或 48 位的零结尾,那么这就是行结束字符(例如 '\n')。
Since the 00 (octal) character was : in some code sets, that meant BNF that used ::= was awkward if the :: fell in the wrong column. [This long preceded C++ and other common uses of ::.]
由于在某些代码集中 00(八进制)字符是 :,这意味着如果 :: 出现在错误的列中,使用 ::= 的 BNF 将会很尴尬。[这远远早于 C++ 和其他常见的 :: 用法。]
answered Sep 24, 2021 at 18:51
Steve Glaser
1
ints used to be 16 bits (pdp11, etc.). Going to 32 bit architectures was hard. People are getting better: Hardly anyone assumes a pointer will fit in a long any more (you don’t right?). Or file offsets, or timestamps, or …
整数曾经是 16 位的(pdp11 等)。转向 32 位架构很难。人们正在进步:几乎没有人再假设指针可以放入长整型中(你不这么认为吗?)。或者文件偏移量、时间戳,或者……
8 bit characters are already somewhat of an anachronism. We already need 32 bits to hold all the world’s character sets.
8 位字符已经有点过时了。我们已经需要 32 位来容纳世界上所有的字符集。
answered Jan 20, 2010 at 0:42
Richard Pennington
-
2
True. The name char is a bit quaint now in Unicode days. I care more about 8-bit units (octets) when dealing with binary data, e.g. file storage, network communications. uint8_t is more useful.
没错。在 Unicode 时代,char 这个名字有点过时了。在处理二进制数据时,例如文件存储、网络通信,我更关心 8 位的单位(八位字节)。uint8_t 更有用。 -
– Craig McQueen
Commented Jan 20, 2010 at 0:48 -
3
Unicode never needed a full 32 bits, actually. They originally planned for 31 (see the original UTF-8 work), but now they’re content with only 21 bits. They probably realized they wouldn’t be able to print the book any more if they actually needed all 31 bits: P
实际上,Unicode 从未需要过完整的 32 位。他们最初计划使用 31 位(参见原始的 UTF-8 工作),但现在他们只用 21 位就满足了。他们可能意识到,如果真的需要全部 31 位,他们就无法再出版那本书了:P
– me22
Commented Aug 30, 2013 at 4:34
- 2
@me22, Unicode originally planned for 16 bits. “Unicode characters are consistently 16 bits wide, regardless of language…” Unicode 1.0.0. unicode.org/versions/Unicode1.0.0/ch01.pdf.
@me22,Unicode 最初计划使用 16 位。“Unicode 字符的宽度始终为 16 位,无论语言如何……” Unicode 1.0.0。unicode.org/versions/Unicode1.0.0/ch01.pdf。
– Shannon Severance
Commented Jan 18, 2016 at 22:27
- 1
ISO 10646 was originally 31 bits, and Unicode merged with ISO 10646, so it might be sloppy to say that Unicode was 31 bits, but it’s not really untrue. Note they don’t actually print the full code tables any more.
ISO 10646 最初是 31 位的,Unicode 与 ISO 10646 合并了,所以说 Unicode 是 31 位的可能有点不严谨,但也不是完全错误。请注意,他们现在不再打印完整的代码表了。
– prosfilaes
Commented Jan 24, 2020 at 15:15
1
The Univac 1100 series had two operational modes: 6-bit FIELDATA and 9-bit ‘ASCII’ packed 6 or 4 characters respectively into 36-bit words. You chose the mode at program execution time (or compile time.) It’s been a lot of years since I actually worked on them.
3
Univac 1100 系列有两种操作模式:6 位的 FIELDATA 和 9 位的“ASCII”,分别将 6 个或 4 个字符打包到 36 位的字中。你在程序执行时(或编译时)选择模式。我已经很多年没有实际操作过它们了。
answered May 28, 2022 at 18:17
dabble5
为什么 1B 等于 8b?
wmttom
25 人赞同了该回答
昨日阅读书籍时,偶然间产生了同样的疑问:为何规定 1 Byte = 8 bits,而非其他数量。
查阅相关资料后发现,中文资料中几乎没有关于此问题的讨论,维基百科(wiki)上对于 byte 的解释也不够详尽,在 quora 上也存在类似问题。
最终找到这篇文章:WHY IS A BYTE 8 BITS? OR IS IT? ,作者是被誉为“ASCII 码之父”的 Bob Bemer,其解释具有相当的权威性与可靠性。
简单来说,这是编码发展的过程。从最早的打孔输入/输出(I/O)到后来的键盘显示器,我们所处理的数据不断演变,涵盖了数字、控制符、符号、英文字符以及多国语言字符等。
在处理整数运算时,仅需对 0 - 9 这十个数字和符号进行编码,4 bits 便已足够;随后,为处理英文字符,需对 52 个大小写字母进行编码;再后来,随着高级语言的出现,又要为高级语言的符号编码。表示每个单元的 bit 数量不断增加,直至增加到 8 bits,从而诞生了 ASCII 编码标准,该标准已能涵盖日常使用的所有编码,于是给每个单元命名为“Byte”。
实际上,1 Byte = 8 bits 是一个历史习惯问题。在当今国际化的 unicode 编码环境下,1 byte 已难以作为表示一个字符的单元。在上文中,Bob Bemer 建议不再使用“byte”这个名称来表示 8 bits,而是采用“octet”(八位组),因为部分设备的基本字符单元并非 8 bits。在通信与网络的相关资料中,经常能够看到“octet”的使用。
此外,在许多入门书籍中,仍存在“1 个英文字母占用 1 字节,1 个汉字占用 2 字节”这种不负责任的说法,且完全不提编码条件(编码字符集 & 字符编码方案),误导了众多读者。
发布于 2013-03-16 15:14
字和字节的区别?
字节是计算机中常用的存储单位,而字是自然的存储单位。几乎所有计算机的一个字节均为 8 位,一般所说的机器参数(如 xx 位机)中的“位”通常是指字。
在 C 语言中,整数存储于字中,那么字节用于存储什么?
字和字节在本质和用途上有何区别?
Acceyuriko
105 人赞同
字节(byte)包含 8 个二进制位;字(word)的长度与计算机架构相关,例如在 MIPS 架构中,字包含 32 个二进制位,即 1 个字等于 4 个字节。它们的区别主要在于长度不同。
内存按字节寻址,即每 8 位(每 byte)存储一个数值。当需要取出一个 word 时,需连续取出 4 个 byte 并拼成一个 word。
xx 位机中的“xx 位”指的是字长,这里的“字”与 word 有所不同,它指的是这种 CPU 一次能够运算的数据长度。例如,32 位机一次能运算 32 个二进制位,64 位机一次能运算 64 个二进制位。
总体而言,字节和字仅在长度上存在差异。
字的定义是:对于特定的计算机设计,字是用于表示其自然数据单位的术语。因此,不同架构下字的长度不同。上述提到一个 word 为 32 位是在 MIPS 指令集中,而在 x86 指令集中,一个 word 被定义为 16 位,尽管其运行起来更接近 32 位。
维基百科中提到:字长对计算机构架的存储器模式有显著影响。具体而言,通常选择字作为存储器的编址方案,即地址码能够指定的最小存储单位。采用这种方法时,相邻编号的内存字组,其地址编号相差 1。在计算机中,这样做较为自然,因为计算机通常处理以字为单位(或字的倍数)的数据,并且具有使指令能够以最小长度指定地址的优点,从而可以减少指令长度或定义更多的指令条数。
举例来说,x86 架构较为复杂,其指令长度可变。以 MIPS 架构为例,其指令为 32 位定长,一次从内存中取出 32 位(即 4 个 byte),然后进行运算。定义的变量也以 32 位为单位,例如定义 char c; 虽然 char 类型仅占 1 个 byte,但在内存中会申请 4 个 byte 的空间来存储它。所以,在 MIPS 中,字被“自然”地定义为 32 位。
通常所说的 CPU 字长,与这里的“字”略有不同,它指的是计算机一次能够操作的最大数据长度。
---------------------------------------update-----------------------------------------
在 MIPS 中,变量在内存中申请的空间是按照 32 位对齐的。例如,假设一行表示 32 位,申请 char a, int i. 时,会占用两行,如下:
a
i
申请 char a,b,c,d int i 时,同样占用两行,如下:
a b c d
i
因为 MIPS 从内存中取数据时一次按 32 位取出,即只能一行一行地取,不能跨行。所以,申请的变量都以 32 位对齐。若不进行内存对齐,而是直接填充空位,在第一个例子中,char a 占用 8 位,int i 占用 32 位,那么 int i 的高 24 位会在第一行,低 8 位在第二行,CPU 将无法正确读取和运算。因此,内存对齐是必要的。
在 C 语言中,int 与 long int 在 32 位机上均为 32 位,在 64 位机上,int 是 32 位,long int 是 64 位。C 语言中的 char 是一个字节,由于 C 语言出现较早,8 位足以表示 ASCII 码。但后来加入了其他语言的字符,出现了能表示更多字符的 unicode 编码。C 语言沿用了以往的方式,char 仍为一个字节,对于一些扩充的字符集(如 unicode),则用两个 char 来表示。而在某些语言(如 java)中,char 是 16 位,即两个字节。
编辑于 2014-07-05 00:08
翰者学堂
65 人赞同
字节并非天生就是 8 个位,在历史上 1 至 48 位都曾被使用过。现代计算机最终选择 8 个位作为一个字节,一方面是因为 8 是 2 的幂;然而,16 和 4 同样是 2 的幂,为何未被选中呢?更重要的原因是,这是商业竞争中自然选择的结果。
同理,字的长度也曾多种多样,但目前主流的是 32 位和 64 位。
那么,字节和字的本质是什么呢?
字节是内存寻址的最小单位。内存中相邻的两个字节,其内存地址相差 1。但一个字节内的位,不存在地址的概念。当然,也可以定义一种计算机,使每个位对应一个内存地址,但在现代计算机中,这种方式过于另类,几乎没有人会为这样的计算机编写程序。
字是计算机一次处理数据的最大单位。在多数情况下,这包含以下几个含义:
- CPU 寄存器的长度为一个字;
- CPU 的一条指令最多从内存中读取的数据量为一个字;
- 最大寻址空间为 2 的字长次方(例如,如果一个字是 64 位,那么最大寻址空间就是 2 的 64 次方)。
需要注意的是,以上是多数情况,也存在不一致的情形。
以上。
编辑于 2019-04-23 08:18
via:
-
Why Are There 8 Bits in a Byte?
https://codeguppy.com/blog/why-are-there-8-bits-in-a-byte/index.html -
What’s So Special About 8 Bits? The Fascinating World of the Byte
https://www.techbasicsexplained.com/2024/06/whats-so-special-about-8-bits.html -
computer architecture - Does a byte contain 8 bits, or 9? - 2016
https://cs.stackexchange.com/questions/67684/does-a-byte-contain-8-bits-or-9 -
c++ - What platforms have something other than 8-bit char?
https://stackoverflow.com/questions/2098149/what-platforms-have-something-other-than-8-bit-char
— -
Design of the Burroughs B1700, by W. T. WILNER
https://safari.ethz.ch/digitaltechnik/spring2018/lib/exe/fetch.php?media=microprogramming1972wilner.pdf -
B1700 Design and Implementation by Wayne T. Wilner, Ph.D
https://treasures.scss.tcd.ie/hardware/TCD-SCSS-T.20121208.032/Wilner_B1700designImp_May72-formatted.pdf -
为什么 1B 等 8b? - 知乎 2013
https://www.zhihu.com/question/20241445 -
字和字节的区别? - 知乎 2014
https://www.zhihu.com/question/24346126


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









