







1 加载协处理器
1.1 将协处理器上传到hdfs:
hadoop fs -mkdir /hbasenew/usercoprocesser
hadoop fs -ls /hbasenew/usercoprocesser
hadoop fs -rm /hbasenew/usercoprocesser/coprocessor.jar
hadoop fs -copyFromLocal /home/hbase/coprocessor.jar /hbasenew/usercoprocessor
1.2 将协处理器加载到表中:
1)先卸载协处理器:
disable 'ns_bigdata:tb_test_coprocesser'
alter 'ns_bigdata:tb_test_coprocesser',METHOD => 'table_att_unset',NAME =>'coprocessor$1'
enable 'ns_bigdata:tb_test_coprocesser'
2)再加载协处理器:
disable 'ns_bigdata:tb_test_coprocesser'
alter 'ns_bigdata:tb_test_coprocesser',METHOD => 'table_att','coprocessor' => '/hbasenew/usercoprocesser/coprocessor.jar|com.suning.hbase.coprocessor.service.HelloWorldEndPoin|1001|'
enable 'ns_bigdata:tb_test_coprocesser'
注意:在加载协处理器是我特意将协处理器中的类名少写一个字母t,以重现将集群regionserver搞挂的现象以及表的状态不一致的现象。
2 出现的问题
以上操作会导致如下两个问题:
2.1 将集群的region server搞挂掉
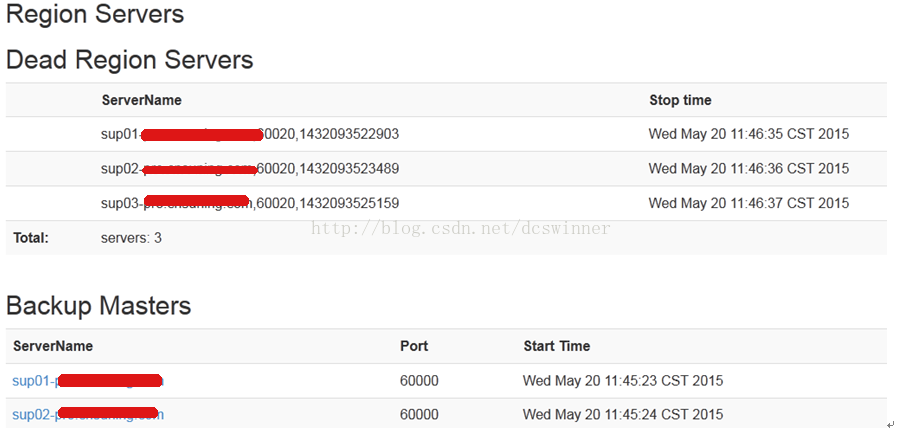
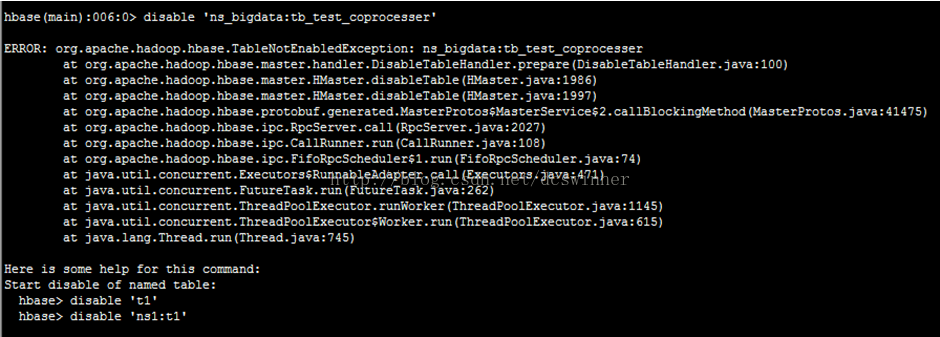
2.2 将加载协处理器的表的状态搞的不一致,一直处于enabling状态

对表做disable和enable操作均不可操作:


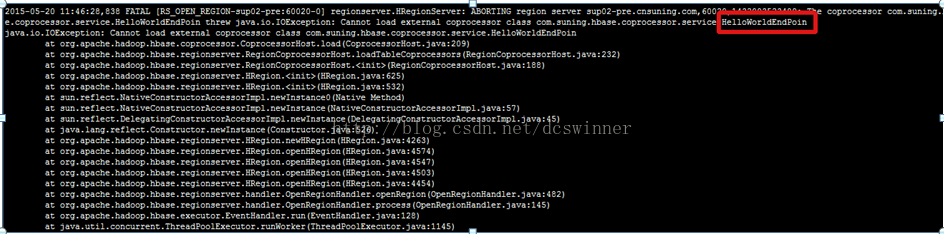
同时此表对应的regionserver上出现如下错误:
3 原因分析
3.1 关于协处理加载错误导致regionserver挂掉的原因分析
在hbase的源码中,参数:hbase.coprocessor.abortonerror的默认值是true:
public static final String ABORT_ON_ERROR_KEY = "hbase.coprocessor.abortonerror";
public static final boolean DEFAULT_ABORT_ON_ERROR = true;
下面查看此参数的含义:
<property>
<name>hbase.coprocessor.abortonerror</name>
<value>true</value>
<description>Set to true to cause the hosting server (master or regionserver)
to abort if a coprocessor fails to load, fails to initialize, or throws an
unexpected Throwable object. Setting this to false will allow the server to
continue execution but the system wide state of the coprocessor in question
will become inconsistent as it will be properly executing in only a subset
of servers, so this is most useful for debugging only.</description> </property>
因此,当加载错误的协处理器之后,会导致regionserver挂掉。
3.2 关于加载协处理器的表的状态不一致的原因分析:
相关错误日志:
查看enable的相关源码:
public void enableTable(final TableName tableName)
throws IOException {
enableTableAsync(tableName);
// Wait until all regions are enabled
waitUntilTableIsEnabled(tableName);
LOG.info("Enabled table " + tableName);
}
private void waitUntilTableIsEnabled(final TableName tableName) throws IOException {
boolean enabled = false;
long start = EnvironmentEdgeManager.currentTimeMillis();
for (int tries = 0; tries < (this.numRetries * this.retryLongerMultiplier); tries++) {
try {
enabled = isTableEnabled(tableName);
} catch (TableNotFoundException tnfe) {
// wait for table to be created
enabled = false;
}
enabled = enabled && isTableAvailable(tableName);
if (enabled) {
break;
}
long sleep = getPauseTime(tries);
if (LOG.isDebugEnabled()) {
LOG.debug("Sleeping= " + sleep + "ms, waiting for all regions to be " +
"enabled in " + tableName);
}
try {
Thread.sleep(sleep);
} catch (InterruptedException e) {
// Do this conversion rather than let it out because do not want to
// change the method signature.
throw (InterruptedIOException)new InterruptedIOException("Interrupted").initCause(e);
}
}
if (!enabled) {
long msec = EnvironmentEdgeManager.currentTimeMillis() - start;
throw new IOException("Table '" + tableName +
"' not yet enabled, after " + msec + "ms.");
}
}
===========================================================================
/**
* Brings a table on-line (enables it). Method returns immediately though
* enable of table may take some time to complete, especially if the table
* is large (All regions are opened as part of enabling process). Check
* {@link #isTableEnabled(byte[])} to learn when table is fully online. If
* table is taking too long to online, check server logs.
* @param tableName
* @throws IOException
* @since 0.90.0
*/
public void enableTableAsync(final TableName tableName)
throws IOException {
TableName.isLegalFullyQualifiedTableName(tableName.getName());
executeCallable(new MasterCallable<Void>(getConnection()) {
@Override
public Void call() throws ServiceException {
LOG.info("Started enable of " + tableName);
EnableTableRequest req = RequestConverter.buildEnableTableRequest(tableName);
master.enableTable(null,req);
return null;
}
});
}
发现在enable的过程中,首先是执行enable操作,操作完毕后需要等待各个regionserver反馈所有region的状态,由于此时regionserver已经挂掉,一直在连接重试等待,此时表的状态一直是ENABLING。
4 问题的处理
4.1 关于regionserver 挂掉的问题处理:
通过在hbase-site.xml文件中设置参数:
<property>
<name>hbase.coprocessor.abortonerror</name>
<value>false</value>
</property>
并启动region server可以解决,这样就忽略了协处理器出现的错误,保证集群高可用。
4.2 关于有协处理器的表的状态不一致,不能disable和enable问题的解决办法:
此问题可以通过切换master节点可以解决,将主停掉,backup-master会承担主master的任务,同时在切换的过程中,会将状态不一致的表的状态改为一致的:

切换后的master信息如下:


在切换的过程中调用了如下方法:
/**
* Recover the tables that are not fully moved to ENABLED state. These tables
* are in ENABLING state when the master restarted/switched
*
* @throws KeeperException
* @throws org.apache.hadoop.hbase.TableNotFoundException
* @throws IOException
*/
private void recoverTableInEnablingState()
throws KeeperException, TableNotFoundException, IOException {
Set<TableName> enablingTables = ZKTable.getEnablingTables(watcher);
if (enablingTables.size() != 0) {
for (TableName tableName : enablingTables) {
// Recover by calling EnableTableHandler
LOG.info("The table " + tableName
+ " is in ENABLING state. Hence recovering by moving the table"
+ " to ENABLED state.");
// enableTable in sync way during master startup,
// no need to invoke coprocessor
EnableTableHandler eth = new EnableTableHandler(this.server, tableName,
catalogTracker, this, tableLockManager, true);
try {
eth.prepare();
} catch (TableNotFoundException e) {
LOG.warn("Table " + tableName + " not found in hbase:meta to recover.");
continue;
}
eth.process();
}
}
}
在却换过程中,跟踪master和对应的regionserver的后台日志:
master日志:
其中的部分日志信息如下:
2015-05-20 10:00:01,398 INFO [master:nim-pre:60000] master.AssignmentManager: The table ns_bigdata:tb_test_coprocesser is in ENABLING state. Hence recovering by moving the table to ENABLED state.
2015-05-20 10:00:01,421 DEBUG [master:nim-pre:60000] lock.ZKInterProcessLockBase: Acquired a lock for /hbasen/table-lock/ns_bigdata:tb_test_coprocesser/write-master:600000000000002
2015-05-20 10:00:01,436 INFO [master:nim-pre:60000] handler.EnableTableHandler: Attempting to enable the table ns_bigdata:tb_test_coprocesser
2015-05-20 10:00:01,465 INFO [master:nim-pre:60000] handler.EnableTableHandler: Table 'ns_bigdata:tb_test_coprocesser' has 1 regions, of which 1 are offline.
2015-05-20 10:00:01,466 INFO [master:nim-pre:60000] balancer.BaseLoadBalancer: Reassigned 1 regions. 1 retained the pre-restart assignment.
2015-05-20 10:00:01,466 INFO [master:nim-pre:60000] handler.EnableTableHandler: Bulk assigning 1 region(s) across 3 server(s), retainAssignment=true
对应的regionserver的日志如下:
2015-05-20 14:39:56,175 INFO [master:sup02-pre:60000] master.AssignmentManager: The table ns_bigdata:tb_test_coprocesser is in ENABLING state. Hence recovering by moving the table to ENABLED state.
2015-05-20 14:39:56,211 DEBUG [master:sup02-pre:60000] lock.ZKInterProcessLockBase: Acquired a lock for /hbasen/table-lock/ns_bigdata:tb_test_coprocesser/write-master:600000000000031
2015-05-20 14:39:56,235 INFO [master:sup02-pre:60000] handler.EnableTableHandler: Attempting to enable the table ns_bigdata:tb_test_coprocesser
2015-05-20 14:39:56,269 INFO [master:sup02-pre:60000] handler.EnableTableHandler: Table 'ns_bigdata:tb_test_coprocesser' has 1 regions, of which 1 are offline.
2015-05-20 14:39:56,270 INFO [master:sup02-pre:60000] balancer.BaseLoadBalancer: Reassigned 1 regions. 1 retained the pre-restart assignment.
2015-05-20 14:39:56,270 INFO [master:sup02-pre:60000] handler.EnableTableHandler: Bulk assigning 1 region(s) across 3 server(s), retainAssignment=true
结论:
1. 为了提高集群的高可用性,应该将参数:hbase.coprocessor.abortonerror设置为false,这样即使加载的协处理器有问题,也不会导致集群的regionserver挂掉,也不会导致表不能enable和disable;
2.即使表出现不能enable和disable的现象后,也可以通过切换master来解决,因此在搭建集群时,一定要至少有一到两个backupmaster
5 全部master节点宕后集群的读写测试
1. 在集群都是正常的情况下,通过客户端往集群中插入2000000行数据,插入正常
2.将集群的所有master全部停掉:

3.监控客户端的数据插入情况,发现客户端的数据插入正常。持续让客户端继续插入20000000行数据,发现数据插入正常。
4.在客户端批量读取数据,发现数据读取正常。
结论:当hbase集群的master所有节点挂掉后(一定时间段,目前测试的是半小时内),客户端的数据读写正常。
zz:http://blog.csdn.net/dcswinner/article/details/46293041














 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









