








Windows Performance Toolkit(Windows 性能工具包)
Windows Performance Toolkit 是 Windows 环境中的一组诊断工具。 我们最感兴趣的是他们收集和分析 ETW 数据的能力。 在 Windows 8 之前,用于此目的的主要工具是相当麻烦的 xperf 程序。 此外,它仍然存在于随 WPT 安装的文件中。 它用于设置和运行 ETW 会话以及稍后分析它们。 因此,在 ETW 命名法中,它具有 ETW 控制器和 ETW 消费者的功能。 我们经常可以在许多与 ETW 相关的旧文章和博客文章中见到他。 由于它是一个非常灵活的工具,因此偶尔仍使用它从命令行管理 ETW 会话。 然而,自 Windows 8 以来,Windows Performance Toolkit 引入了两个新工具:
- Windows Performance Recorder - 作为 ETW 控制器
- Windows 性能分析器 - 作为 ETW 使用者
Windows Performance Toolkit 中的这两个程序目前最常用。 我们将简要介绍一下使用这些程序的基础知识。
注意 Windows Performance Toolkit 可以通过两种方式安装。 两者都依赖于安装两个较大的软件包之一 - Windows 评估和部署工具包或 Windows SDK。
Windows Performance Recorder(Windows 性能记录器)
从用户的角度来看,Windows Performance Recorder 是一个充当 ETW 控制器的简单对话框(见图 3-15)。 将记录来自哪些提供者的哪些事件是由配置文件配置的。 图 3-15 中可见许多内置配置文件,这些配置文件是随该工具预安装的。
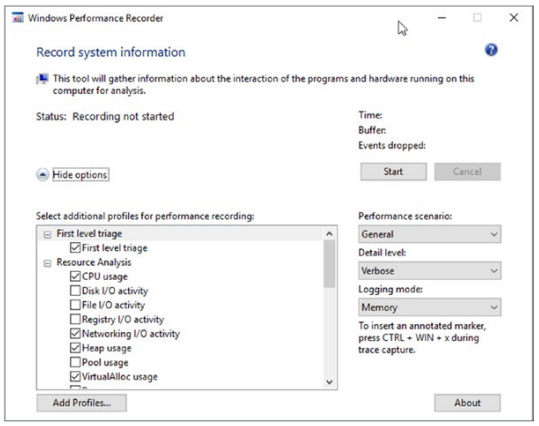
图 3-15。 Windows 性能记录器对话框
还有两个更重要的选项可用:
- 记录数据的详细级别 - 我们对详细级别最感兴趣。 除了事件发生的时间之外,它还说要记录附加的诊断信息。
- 日志模式 - 我们最常使用内存模式,它将事件记录到内存中的临时循环缓冲区。 这确保我们永远不会超过缓冲区的大小,并且不会通过创建太大的文件或内存缓冲区来严重影响整个操作系统和其他应用程序。
从用户界面中看不到配置文件中具体包含的内容。 但我们可以在程序的命令行版本中看到它。 可以使用 profile 命令开关获取 GUI 中可见的内置配置文件列表(参见清单 3-6)。
清单 3-6。 使用 wpr 命令行版本列出所有配置文件名称
> wpr -profiles
然后我们可以使用 profiledetails 命令开关询问单个配置文件的详细信息。 因此,我们可以看到 .NET Activity 配置文件启用了哪些提供程序和关键字(参见清单 3-7)。
清单 3-7。 使用 wpr 命令行版本列出给定的配置文件配置(为简洁起见,从输出中删除了仅按 Guid 列出的一些提供程序)
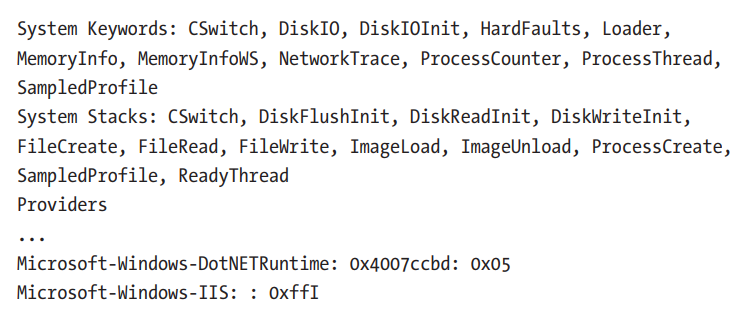
对于 .NET 运行时,提供程序选择的关键字掩码的值为 0x4007ccbd。 我们可以使用清单 3-4 中的值将其解码为选定关键字的列表。 我们很容易注意到,实际上并没有选择所有可能的关键字(包括与垃圾收集器相关的几个)。
还有 Windows 堆和虚拟分配的内置配置文件。 为了在进行 CLR 分析时获得全面的了解,可以决定选择所有这三个配置文件。
使用“添加配置文件”按钮,您可以添加手动定义的配置文件。 这是连接到我们感兴趣的唯一一组提供商并微调使用的关键字的唯一方法。 您可以在本书附带的 GitHub 存储库(NetMemoryManagement.wprp 文件)中找到“Pro .NET Memory Management with stacks”示例配置文件,它支持所有 .NET 事件以及调用堆栈记录(但请注意,在此类配置中,跟踪开销 会减慢 .NET 应用程序的速度,主要是由于栈收集)。
Windows Performance Analyzer(Windows 性能分析器)
Windows 性能分析器是一个强大的 ETW 使用者。 在那里可以进行非常先进的分析。 同时,它也是ETW数据便捷可视化的主要工具之一。 第一次接触这个工具可能会有点不知所措。 该界面是以非常通用的方式设计的。 如何适应它实际上取决于用户。 导致上手困难,乍一看很难看出这个工具休眠的威力。
使用 Windows 性能分析器界面的确切描述超出了本书的范围。 因为它是如此强大,描述它的所有功能可能需要另一本小书。 从我们的角度来看,我们将在这里集中讨论一些最有用的场景。 我们将使用一个名为 SuperBenchmarker 的开源负载测试程序示例,该程序是用 .NET 4.5 编写的,可在 GitHub 上找到:https://github.com/aliostad/SuperBenchmarker。 在负载测试期间,它会在目标 Web 应用程序上生成系统负载,因此非常适合实验。 本书附带一个 WPA-Tutorial.zip 文件,其中包含在负载测试期间使用以下参数进行的记录场景 WPA-Tutorial.ETL 的示例:
.\sb.exe -u http://localhost/LeakWebApi/values/concatenated/100 -c 10 -n 100000 -y 100
这意味着将进行 10 个并发调用,它们之间的间隔为 100 毫秒,总共将进行 100,000 个调用。 我们的 LeakWebApi 是一个托管在 IIS 上的非常简单的 ASP.NET MVC Web API 项目。 由于 ETW 的性质,显然还记录了许多其他进程,但我们将重点关注其中两个:sb.exe 本身和托管提到的 Web API 项目的 w3wp.exe。 该文件是使用 Windows Performance Recorder 使用配置文件创建的:CPU 使用情况、堆使用情况、VirtualAlloc 使用情况以及我们自定义的“.NET 内存管理与堆栈”。 如果您想要进行以下练习,请立即将 WPA-Tutorial.zip 解压缩到您选择的文件夹中。
现在让我们看一下使用 Windows 性能分析器的一些可能场景。 请记住这个工具的巨大灵活性。 因此,如果您按照下面描述的练习进行操作,并且某些结果看起来与所提供的屏幕截图不同,请仔细检查您的视图配置 - 特别是表中列的可见性和顺序。
打开文件和配置
启动程序后,我们将看到一个带有“Getting Started”选项卡的空窗口。 通过从菜单中选择“文件”➤“打开…”来打开录制文件。
当您打开文件时,在左侧我们将看到一个新的图形浏览器面板,其中包含多个图形组 - 取决于记录的数据。 对于我们的 WPATutorial.etl 文件,应该有五组图表:
- 系统活动 - 与系统、进程和线程操作相关的广泛数据。 这也是一个非常重要的通用事件图表,我们稍后会看到。
- 计算——CPU相关数据。
- 存储 - 与磁盘相关的数据,包括使用的磁盘偏移量等精确数据。
- 内存 - 与内存相关的数据。
- 电源 – 电源相关数据,包括 CPU 频率和状态
每个组名称旁边都有一个展开按钮,可让您浏览分组的图表。 每个可见图形都可以通过拖动或双击移动到“分析”选项卡。 您可以向其中添加许多不同的数据,这些数据将一个接一个地放置。 “分析”选项卡中添加的所有视图都是同步的(以及图形浏览器本身)。 因此,例如,如果您更改其中一个时间轴上的比例,则更改将反映在其他时间轴上。 这类似于当前调查数据的任何类型的过滤或下划线。
现在让我们创建第一个视图,它将使我们能够在实践中学习程序导航的基础知识。 从图形浏览器中,展开系统活动组。 让我们将进程图拖到工作区(或双击)。 它将出现在“分析”选项卡中。 然后展开计算组并双击 CPU 使用率图(采样)。 它应该出现在之前添加的下方。 应该达到如图3-16所示的效果。
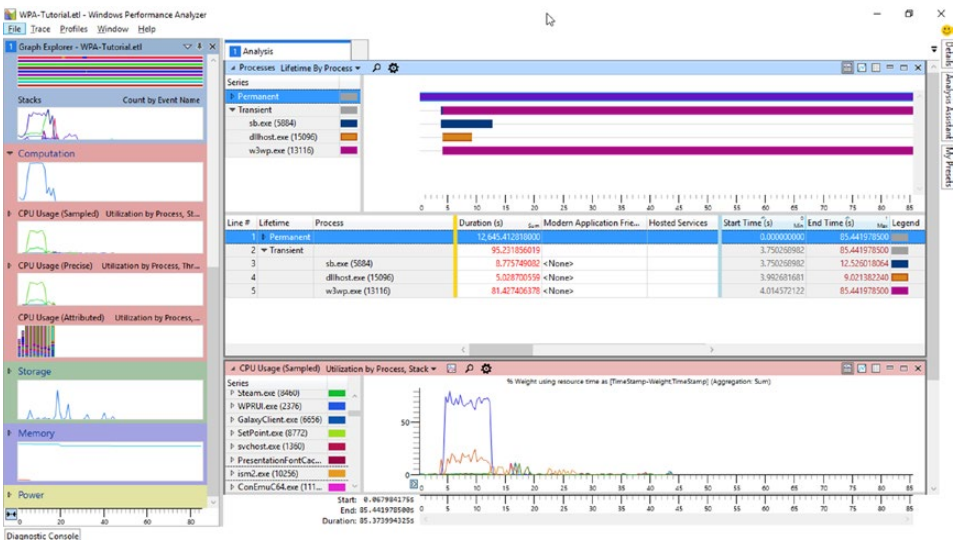
图 3-16。 带有进程和 CPU 使用率面板的示例视图
很快我们可能会发现很多元素都有包含附加信息的工具提示。 在“进程”窗格中,显示记录时正在运行的进程。 很容易找到sb.exe进程对应的块。 用鼠标左键单击它。 该过程的时间范围将在所有其他图表上自动突出显示。 这对于导航和相互引用数据非常有帮助。
有时,以图形或表格形式分析数据更方便。 因此,在每个面板的右上角放置了三个按钮:仅显示图表、仅显示表格和显示两种信息(默认情况下选择“显示图形和表格”选项)。 现在为两个显示面板选择“仅显示图形”选项。
从图形资源管理器中,从系统活动组中添加栈面板,并将其设置为“仅显示表”。 堆栈面板包含有关所有收集的堆栈跟踪的分组信息。
我们现在可以仔细看看 w3wp.exe 进程。 首先,从图表中,右键单击“进程”面板中的 sb.exe 块并选择“缩放”,选择与负载测试相对应的时间范围。 有了这样一个选择的时间范围,我们就可以过滤出数据,只显示我们感兴趣的Web应用程序进程。因此,选择w3wp。 从堆栈面板的列表中选择 .exe 进程,然后在其上下文菜单中选择“筛选到选择”选项。 接下来,展开(在 Stacks 面板中)Process 列中的 w3wp.exe、Event Name 列中的 Thread: CSwitch、Stack Tag 列中的 CLR 以及 Stack (Frame Tags) 下的 JIT 下的 [Root]。 在展开从元素 [Root] 开始的几个节点后,我们可能会注意到缺少有关调用的函数的信息(见图 3-17)。 其中大多数仅用模块名称和问号指定。 这是由于缺少符号 (PDB) 造成的。 我们现在将处理它们的配置。
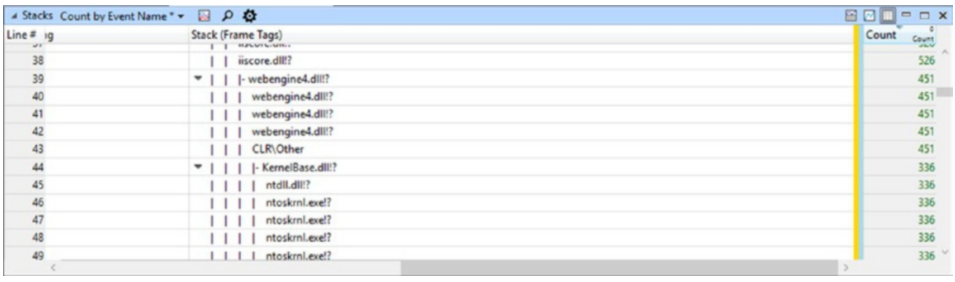
图 3-17。 缺少符号导致堆栈跟踪信息不完整
要配置 Windows 性能分析器使用的符号,请选择“跟踪”➤“配置符号路径”。 在此窗格中,我们配置搜索 PDB 的目录。 最好至少设置以下两个来源:
- 如果我们在上一节中设置了环境变量_NT_SYMBOL_PATH,那么默认会添加到这里。
- 我们的应用程序的符号文件的路径(也随 WPA-Tutorial.etl 文件一起提供)。
在同一窗口的 Symcache 选项卡中,您还应该特意设置一个目录,用于存储准备好的符号的本地副本。 完成上述配置后,我们可以关闭“配置符号”窗口。 当您从菜单中选择“Trace”➤“加载符号”时,将出现“加载符号”信息。 下载和加载(即使它们已经缓存)所有需要的符号可能需要相当长的时间,因此请耐心等待。
在该操作之后,我们将获得完整的栈跟踪信息。 我们可以通过使用面板栈中的“快速搜索”(显示为小放大镜)来看到这一点。 使用它并输入“LeakWebApi”来查找来自我们的测试应用程序的调用(见图 3-18)。
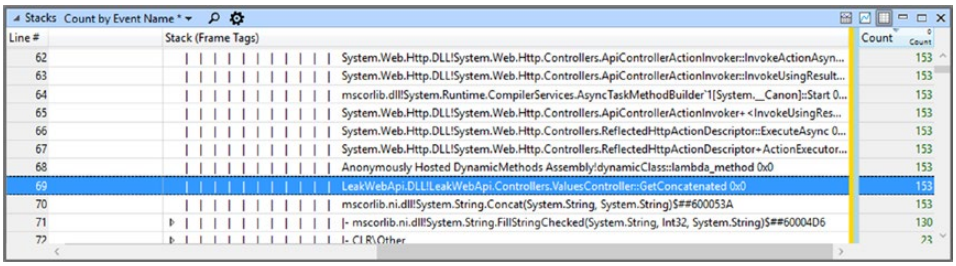
图 3-18。 加载符号的完整堆栈跟踪信息
Generic Events(通用事件)
在 WPA 中,相当多的事件以特殊方式进行解释,并通过这种方式创建专用面板,例如进程或 CPU 使用情况。 但是,当然不可能为 ETW 记录的任何可能事件准备此类视图。 为此,创建了一个名为“通用事件”的专用面板,其中包含所有已注册事件的视图。 让我们通过从“系统活动”组中选择它来将其添加到我们的视图中。 默认情况下,我们将看到按流程分组的所有事件。 我们可以通过从上下文菜单中选择“筛选到选择”来过滤除来自 sb.exe 进程的所有进程。2 通过展开“提供程序名称”列中的“Microsoft-Windows-DotNETRuntime”,然后展开“垃圾收集任务”和“win:Start”操作码,我们可以 可以创建图 3-19 中的视图(在适当放大感兴趣的时间区域后)。 请注意,要获得此类视图,必须设置正确的列顺序,从进程开始,通过提供者名称、任务名称和操作码名称。
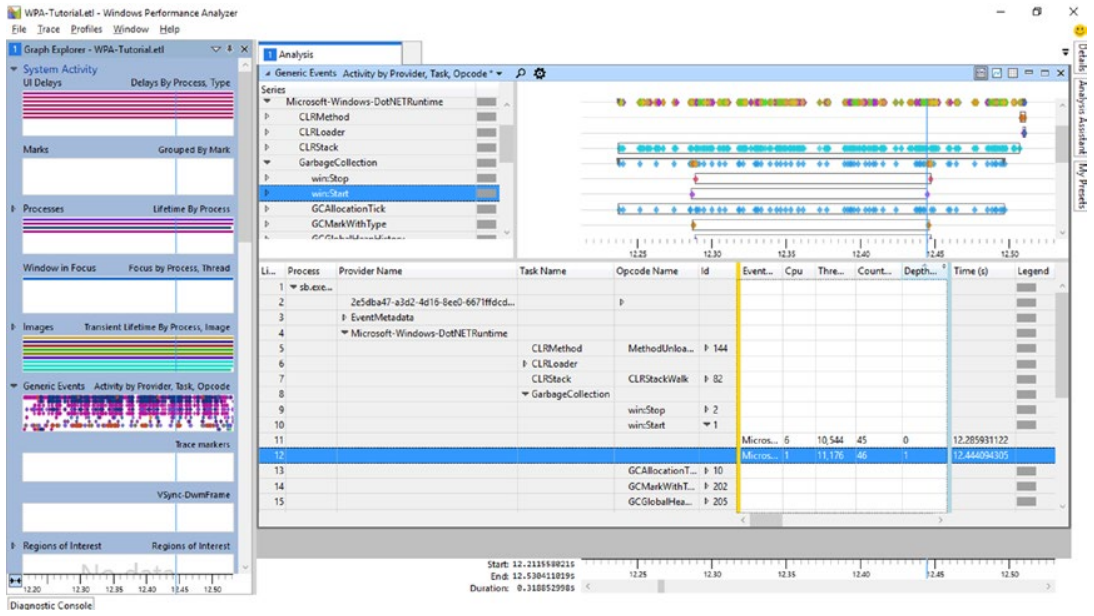
图 3-19。 进程 sb.exe 和 Microsoft-WindowsDotNETRuntime 相关事件的通用事件视图
我们设置了一个视图,其中重点关注 sb.exe 进程(第二列)、Microsoft-Windows-DotNETRuntime 提供程序(第三列)提供程序和 GarbageCollection 任务(第四列)。 例如,我们看到,在选定片段的近 0.5 秒内,有两个 GarbageCollection/Start 事件。
此外,我们可以看到与每个事件相关的数据。 为此,我们需要展开该组(在我们的例子中,通过展开 Id 列中的最后一个分组项目)并相应地滚动视图以显示黄色标记后面的列。 图 3-20 显示了 GCStart 和 GCEnd 事件的此类准备视图的示例。
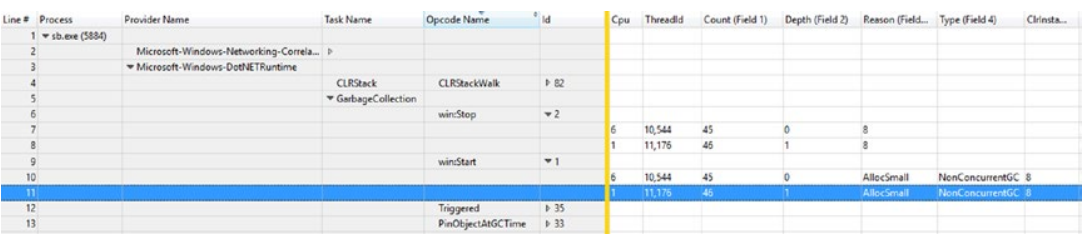
图 3-20。 垃圾收集启动和停止事件在通用事件表视图中可见
通过设置列可见性和排序以及所需的项目分组来调整视图是您在 Windows 性能分析器中必须处理的主要任务。 幸运的是,它在这方面确实很灵活。
可以对 Windows 性能分析器进行更多自定义,以便使分析变得更加容易。 由于我们自己的自定义感兴趣区域、堆栈标签和配置文件,这非常有帮助。
Region of Interests(感兴趣的区域)
它们允许您定义出于某种原因我们感兴趣的领域。 这些区域的边界由指定的事件(打开和关闭事件)确定。 这是说明垃圾收集持续时间的理想机制,例如,初始事件是 win:Start(Id 为 1),最终事件是 win:Stop(Id 2)。 区域在单独的文件中定义,然后可以从菜单 Trace > Trace Properties 将其加载到程序中。 在出现的选项卡中,我们使用“感兴趣区域定义”部分中的“添加…”按钮加载区域文件。 之后,“兴趣区域”面板将在图形浏览器中可用。
我们需要自己创建这样的文件或者在互联网上搜索感兴趣的文件。 您还可以使用为本书准备的文件(位于随附的 GitHub 存储库):roi_dotnetfinalization.xml 和 roi_dotnetgc。 xml。 此类文件由以启动和停止事件表示的区域定义组成(参见清单 3-8)。
清单 3-8。 感兴趣区域文件定义示例
<Region Guid="{4fbb5999-8f4e-4900-9482-000000000001}" Name="DotNETRuntime-GarbageCollection-GC" FriendlyName="Garbage Collection">
<Start>
<Event Provider="{E13C0D23-CCBC-4E12-931B-D9CC2EEE27E4}" Id="1" Version="2" />
</Start>
<Stop>
<Event Provider="{E13C0D23-CCBC-4E12-931B-D9CC2EEE27E4}" Id="2" Version="1" />
</Stop>
<Match>
<Event TID="true" PID="true" >
</Event>
<Parent PID="true" />
</Match>
<Naming>
<PayloadBased NameField="ClrInstanceID" />
</Naming>
</Region>
正如您所看到的,我们需要一些知识来定义区域:我们感兴趣的提供者将生成哪些事件以及如何将它们配对。
根据垃圾收集器的事件,我们可以指定以下区域:
- 垃圾收集(GCStart 和 GCEnd 事件);
- 挂起运行时(事件GCSuspendEEBegin 和GCSuspendEEEnd);
- 重新启动运行时(事件 GCRestartEEBegin 和 GCRestartEEEnd);
- 终结(事件 GCFinalizersBegin 和 GCFinalizersEnd)。
这使您可以可视化并收集统计数据(发生的次数和持续时间),如图 3-21 所示。 请注意,设置了适当的缩放以产生这样的视图,以及对左侧列表中的项目(名为系列)进行了适当的取消分组。
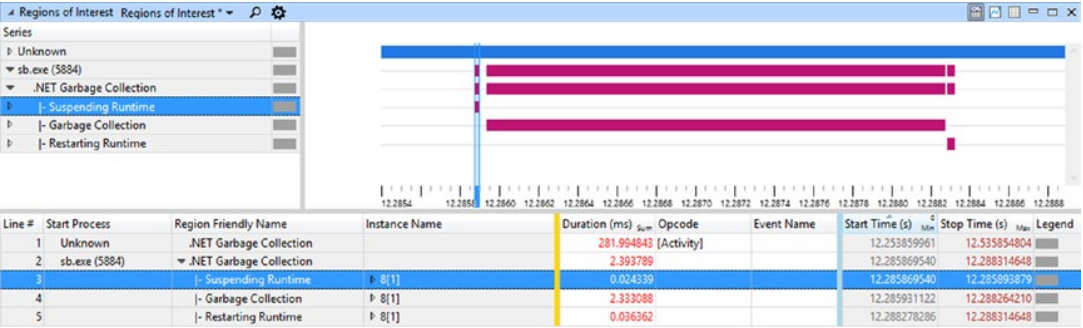
图 3-21。 在自定义感兴趣区域的帮助下查看垃圾收集周期
Flame Charts(Flame 图)
可以使用已经概述的机制进行性能分析 - 除其他外,还可以通过在堆栈面板中对调用进行分组。 还有另一种非常方便的机制——所谓的Flame 图。 CPU 使用率(采样)面板的“按进程Flame 、堆栈”视图可在计算组中找到。 我鼓励您将其用作我们的示例 ETL 文件的一部分。 通过使用以下步骤,您应该能够获得如图 3-22 所示的视图。
- 在“CPU 使用率”面板的表格部分中,使用上下文菜单中的“在列中查找…”选项并尝试查找 LeakWebApi 文本。 如果加载了符号,它应该指向我们的 WebAPI 控制器的 GetContatenate 方法。
- 选择其父方法(应为 lambda_method)并从其上下文菜单中使用 Filter To Selection。 这应该将视图放大到单个方法调用。

图 3-22。 Flame图示例
Flame 图以非常直观的方式显示了成堆的调用,但它需要一些同化。 其上可见的每个块代表单个函数的调用。 位于彼此之上的块代表一个函数调用另一个函数。 这样,图表就向上增长。 函数越高,调用栈越深。 块的宽度与特定函数调用(及其所有子调用)的总持续时间成正比。 这样我们就可以快速找出哪些函数与长时间执行相关。
例如,在图3-22中,我们看到WebAPI方法GetConcatened花费的绝大多数时间都是因为System.String。 Concat 调用,其中绝大多数时间花在 SVR::gc_ heap::fire_etw_allocation_event 调用上。 这是确实的证据,表明将 ETW 会话连接到我们的应用程序会导致大量开销。 这与在每个 CLR 事件中写入调用堆栈的选项有关 - 通过进一步研究 fire_etw_allocation_ 事件进行的方法调用,我们可以看到这一点。 大量时间花费在 clr.dll!ETW::SamplingLog::GetCurre ntThreadsCallStack 方法上。 这是因为为每个频繁分配事件获取调用堆栈不一定是个好主意。 然而,对于我们的学习目的来说,这是完全可以的。
Stack Tags(栈标签)
正如我们所看到的,ETW 事件可以在事件发生时与堆栈跟踪一起记录。 Windows 性能分析器允许您使用堆栈列查看此信息。 然而,对于比仅从堆栈跟踪进行更广泛的分析,更有价值的是聚合信息。 一种这样的聚合机制是所谓的堆栈标签。 它们允许您根据给定的模式对调用的方法进行分组。 这样,具有与模式匹配的堆栈跟踪的所有事件都将使用提供的堆栈标签进行标记。
默认堆栈标签位于 C:\Program Files (x86)\Windows Kits\10\ Windows Performance Toolkit\Catalog\default.stacktags 文件中,特别包括与 CLR 和 GC 相关的标签。 因此,当使用 Stack Tag 列时,我们将看到堆栈分为 CLR 和 GC 节点(而不是列出其中的所有方法)。
Custom Graphs(自定义图表)
从适用于 Windows 10 的 Windows Performance Toolkit 版本中,有一种方法可以根据事件负载绘制自己的图表。 换句话说,我们可以绘制 Y 轴来自选定事件字段之一的图表。 X 轴将自动成为事件的时间。 唯一的要求是所选字段具有整数值。
不幸的是,这个限制对我们来说非常不利。 垃圾收集器领域中的绝大多数有趣事件均以十六进制格式给出。 这适用于各种大小、内存使用等等。 这使得该机制目前没有多大用处,我们根本不会使用它。
Profiles(剖面)
由于所有面板的配置可能非常耗时,因此 Windows 性能分析器提供了使用配置文件保存当前视图的功能。 现在,我们可以使用“Profiles”➤“Export…”选项保存当前视图。 我们使用“配置文件”➤“应用”选项加载它们。 除了配置视图本身(包括列的顺序和布局)之外,配置文件还可以定义定义感兴趣区域的文件等。
PerfView
Windows 性能工具包主要是为 Windows 和驱动程序开发人员设计的。 由于其高度可定制性,我们可以将其适应.NET环境,就像我们在上一子章节中所做的那样。 然而,还有另一个基于 ETW 的工具,最初是为了帮助分析 .NET 性能问题而设计的 - PerfView。 它的创建者和赞助者是 .NET 运行时性能架构师 Vance Morrison,.NET 团队使用该工具来处理框架本身和托管代码的总体性能。 所以我们显然也应该对此感兴趣。 更重要的是,所有性能和 CLR 内部极客最近很高兴听到 PerfView 已成为 GitHub 上提供的完全开源产品。
就 ETW 术语而言,PerfView 既是控制器又是消费者(提供广泛的分析功能)。 它被编写为一个非常非侵入性的工具。 它不需要任何安装。 它仅包含一个可执行文件 - perfview。 EXE文件。 这使得它可以轻松地在任何计算机上使用,包括生产服务器。 因此,要开始使用 PerfView,我们有两个选择:
- 第一个是从 https://www.microsoft.com/en-us/download/details.aspx?id=28567 下载 ZIP 文件,解压它,然后在您想要的任何地方运行。
- 第二种是从 GitHub 上的可用源编译程序:https://github.com/Microsoft/perfview。
需要注意的是,该工具还可以通过命令行和 PowerShell 进行控制,这可以实现自动化,并且在生产分析中特别有用(准备好的命令行可以传递给系统管理员以在受限环境中执行)。
虽然启动很简单,但第一次接触这个工具可能会吓到您。 该程序当之无愧地被称为有史以来最强大、但第一眼看上去最令人难以抗拒的工具。 界面不是很直观和漂亮,所以甚至不知道从哪里开始。 幸运的是,它有非常广泛的帮助。 每个选项和 GUI 元素都有一个指向文档的链接。 您可以在下面找到一些基本的使用场景,但我鼓励您经常访问帮助部分。 您会发现这里涵盖的主题的扩展和广泛的解释。 相信我,这个工具值得花每一分钟来学习。
注意 PerfView 基于 ETW 的分析中的大部分功能都基于库 TraceEvent。 我们将在第 15 章中回顾它,简要了解它的功能。 虽然 PerfView 主要基于 ETW,但它还内置了 ETWCLrProfiler(基于所谓的 CLR Profiling API),允许 PerfView 拦截 .NET 方法调用(在 Collect 对话框中启用 .NET Call 即可开始使用它) )。 作为 ETW 分析的轻量级工具,还可以考虑使用 Sasha Goldshtein 创建的 etrace 工具,该工具可在 https://github.com/goldshtn/etrace 上获取。 它允许您从命令行控制 ETW 会话,并提供各种过滤功能。
Windows 性能分析器在某种意义上基于图表的概念,而 Perfview 则侧重于表格视图。 实际上,我们在这个程序中看到的几乎所有内容都以表格形式呈现。 这有时可能会产生误导,因为以同样的方式,内存消耗、调用堆栈和其他所有内容都会被分析。
启动程序后,我们将看到一个包含大量帮助的窗口。 此时我们可以采取三个主要行动:
- 使用 Collect ➤ Collect 选项开始收集 ETW 数据
- 通过在菜单下方的文本框中输入目录路径并选择您感兴趣的 ETL 文件来开始数据分析。
- 使用选项 Memory ➤ Take Heap Snapshot 执行内存转储。
与其他工具一样,需要配置符号路径,这可以通过“文件”➤“设置符号路径”菜单完成。 最好设置三个来源:
- 公共 Microsoft 符号服务器,与 NT SYMBOL_PATH 环境变量中的相同。
- 打开的ETL 文件旁边带有NGEN 映像符号的子目录路径,但这并不是绝对必要的,因为PerfView 能够自动重新创建它们。
- 我们的应用程序的符号文件的路径
Data Collection(数据采集)
由于 PerfView 是 ETW 控制器,因此它允许您管理 ETW 跟踪会话。 选择“收集”选项后,我们将看到一个带有许多参数的新对话框(见图 3-23)。
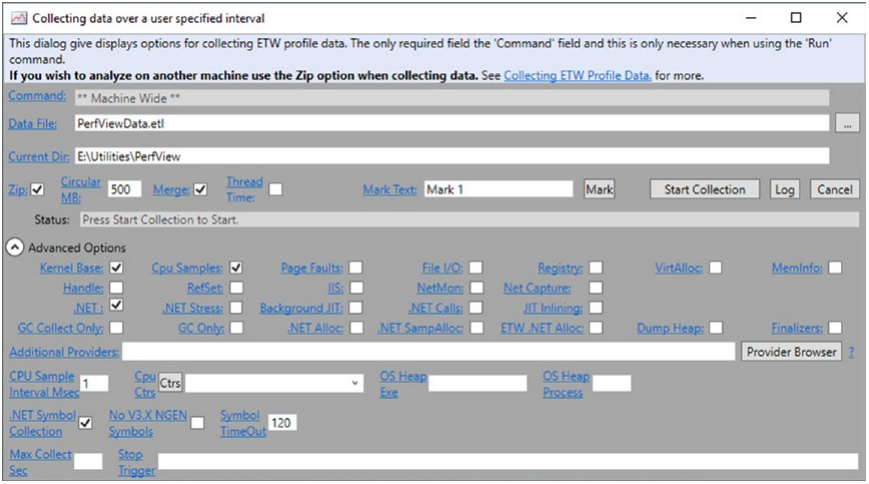
图 3-23。 PerfView 集合对话框,其中高级部分已展开
通过查看可能的选择选项,我们会遇到很多与.NET 相关的选项。 尽管程序帮助中也对它们进行了描述,但还是值得花点时间来解释它们。 从我们的角度来看,最有趣的选项位于“高级选项”下:
- .NET - 启用来自 .NET 提供程序的默认事件。
- .NET 压力 - 来自 .NET 提供程序的与压力测试运行时本身相关的启用事件。 这些是 CLR 团队内部使用的罕见事件。
- 仅 GC 收集 - 禁用所有其他提供程序并仅启用具有与 GC 进程关联的事件的 .NET 提供程序。 这是一个非常轻量级的选项,可以让您长时间收集基本的GC相关诊断信息。
- 仅 GC - 与上面类似,但还启用了用于对 GC 堆上的分配进行采样的堆栈(每次分配 100 kB 对象时)。
- .NET Alloc - 每次在 GC 堆上分配对象时都会启用堆栈事件。 这是一个非常昂贵的选择,并且可能会导致程序速度减慢数倍。 事实上,我们最近在图 3-21 中看到了这种开销。
- .NET SampAlloc - 每次在 GC 堆上分配 10KB 对象时都会生成事件。 这不是基于内置 ETW 事件,而是通过将 ETWClrProfiler 库注入进程来使用 CLR Profiler API。
- ETW .NET Alloc - 这支持分配采样事件,但不是注入基于 Profiler API 的库,而是基于 .NET 4.5.3 中提供的 GCSampledObjectAllocationHigh 关键字。
- Finalizers - 启用与 GC 内的终结过程相关的事件。
- 其他提供商 - 此字段允许您提供所需的任何其他提供商。 它还可以用于微调无论如何都会启用的提供程序。 例如,要启用 CLR 异常的堆栈捕获,我们可以键入 Microsoft-Windows-DotNETRuntime :ExceptionKeyword:Always:@StacksEnabled=true。 还提供了有关使用此字段的广泛帮助。
- CPU Ctrs - 此计数器允许您启用与 CPU 相关的低级计数器,例如分支预测错误或缓存未命中。 请记住,您必须禁用 Hyper-V 虚拟化才能访问这些事件。
注意:除了讨论的 .NET 选项之外,还有一些常规设置需要记住:
- Zip - 将文件打包成存档,以便轻松传输整个文件以便以后在另一台计算机上进行分析。
- Merge - 将文件合并为一个文件,但不创建单独的 ZIP 文件。
如果您不打算将分析发送给其他人,则可以忽略这两个选项。 但是,如果您计划在与收集数据的计算机不同的计算机上进行分析,则选中“合并”选项非常重要。 合并选项包括符号解析准备,因此如果省略它,则大多数收集的数据在另一台计算机上将毫无用处。
触发 ETW 数据收集的一种非常流行的方法是基于 PerfView 的命令行用法。 例如,通过这种方式,您可以要求支持团队通过向他们提供要执行的单个命令来轻松收集生产环境的数据。 例如,以下命令将触发 GC 相关事件的轻量级会话记录:perfview /GCCollectOnly /nogui /accepteula /NoV2Rundown /NoNGENRundown /NoRundown /merge:true /zip:truecollect 使用命令行我们还可以提供会话停止触发器 ,例如当 GC 发生时间超过特定毫秒数时停止会话。 请运行 perfview -? 有关命令行的更多帮助
Data Analysis(数据分析)
使用 PerfView,我们可以打开他自己和其他 ETW 工具记录的 ETL 文件。 打开示例 ETL 文件后,我们将看到如图 3-24 所示的视图。 在左侧,所有准备好的分析都可用 - 取决于会话录制期间选择的提供者和事件。
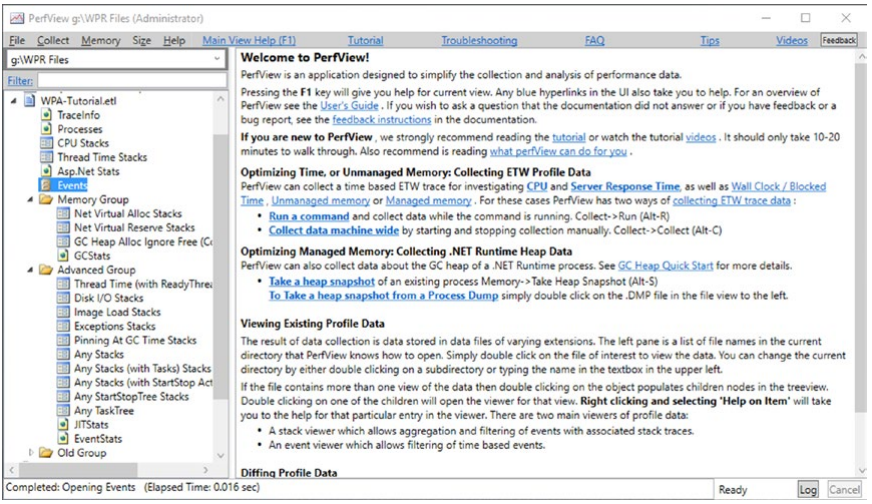
图 3-24。 在 PerfView 中打开的示例 ETL 文件
最基本的视图之一是通用事件面板,允许您查看所有记录事件的实例。 当你打开它并在 Filter 字段中输入 GC 时,我们将看到所有与 GC 相关的 DotNetRuntime 事件(见图 3-25)。
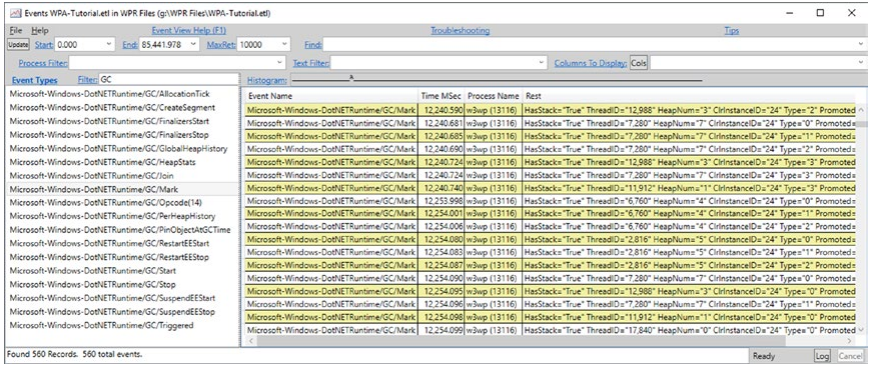
图 3-25。 PerfView - 事件面板中显示的与 GC 相关的事件
可以看到,除了与事件相关的标准列之外,还有一个包含事件所有详细信息的 Rest 列。 您还可以通过单击“列”按钮从事件中选择特定数据。 例如,通过在“过滤器”字段中键入事件名称的一部分(例如 GC/HeapStats),过滤除 Microsoft-Windows-DotNETRuntime/GC/HeapStats 事件之外的所有事件。 然后,使用 Cols 按钮选择所有 GenerationSize 字段。 此外,在“进程过滤器”中填写我们感兴趣的进程的独特部分。例如,我们应该创建一个 GC 统计数据表(参见图 3-26),该表可以粘贴到 Excel 中并进行可视化。
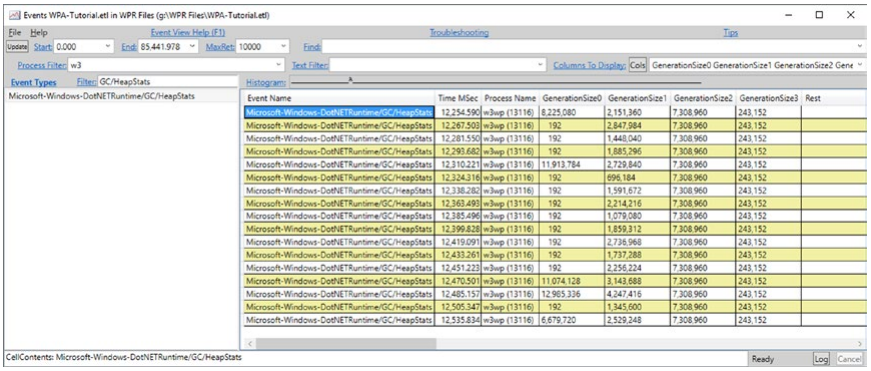
图 3-26。 PerfView - 与 GC 相关的事件的自定义视图
然而,查看和分析单个 ETW 事件非常乏味。 当谈到 .NET 内存分析时,最重要的视图无疑是主窗口内存组中的 GCStats 视图。 该视图包含有关 GC 行为的全面聚合信息,包括执行的 GC 的统计信息(见图 3-27)。 我们将在本书中经常回顾这一观点。
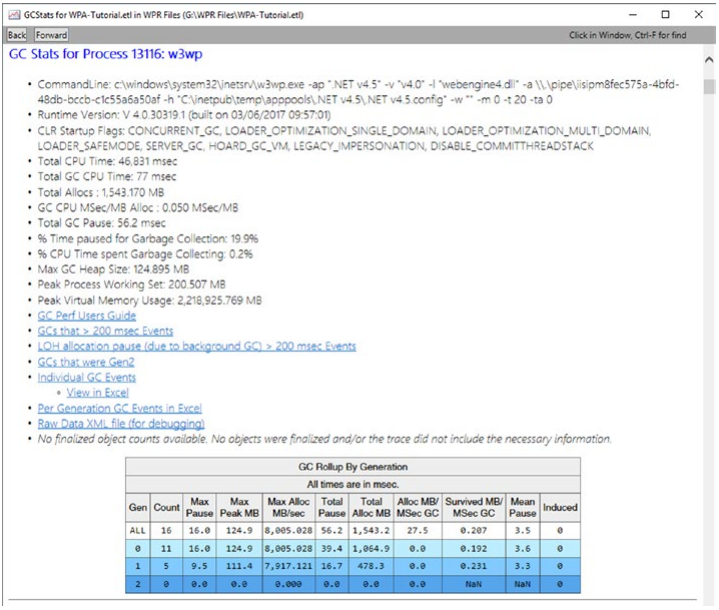
图 3-27。 PerfView - GCStats 视图
此外,如图 3-25 中的 Rest 列所示,所选事件具有 HasTrack = “True” 属性。 如果您想查看事件的堆栈跟踪,请选择其中一个,然后从其上下文菜单中选择“打开任何堆栈”(但要小心,您必须在“Time MSec”列的上下文中执行此操作)。 这将打开另一个非常流行的 PerfView 的调用树视图(见图 3-28)。
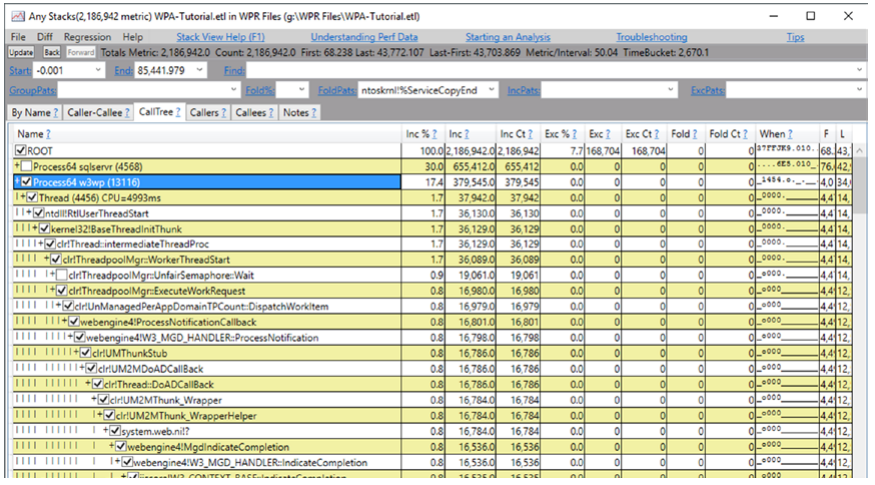
图 3-28。 PerfView - 任何栈视图
请记住,如果无法识别函数名称,请从上下文菜单中选择“查找符号”。 它应该触发读取适当的符号。
还有许多其他非常有用的观点。 我们会多次使用它们。 但现在我鼓励您四处看看,包括 CPU 堆栈、提到的 GC 统计信息或 Asp.Net 统计信息等视图。
Memory Snapshots(内存快照)
当您从菜单中选择“获取堆快照”时,我们将看到“收集内存数据”窗口。 最好立即使用 Filter 字段找到我们感兴趣的进程。选择进程并单击 Dump GC Heap 后,您将需要等待几秒或几十秒才能获得结果(见图 3) -29)。
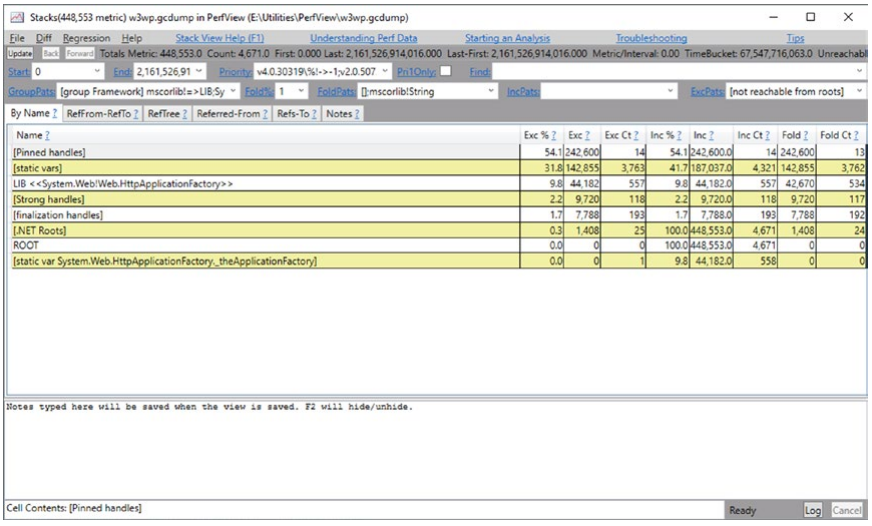
图 3-29。 PerfView - 内存快照视图
注意内存快照不是典型的内存转储 - 它不包含进程的所有内存。 它是进程状态的视图,存储预处理的对象图,但没有对象的内容,并忽略所有非托管内存区域。
结果窗口将显示我们已经看到的表,但这次它不代表调用树,而是代表引用树,其中节点是对象类型或类型类别。 例如,最初可见的“按名称”选项卡显示内存转储中找到的所有类型的摘要。 我们可以通过从上下文菜单中选择“内存”➤“查看对象”(或 Alt + O)来进一步研究给定条目。 让我们对“[static vars]”条目执行此操作,以查看内存转储中所有静态变量的列表(见图 3-30)。
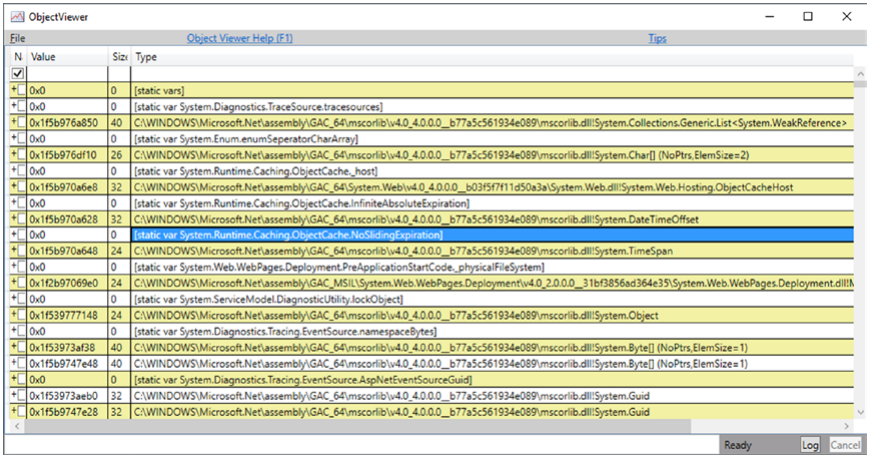
图 3-30。 PerfView - 所有静态变量的内存快照列表
我们在这里看到一对一的行 - 声明给定静态变量并为其分配一个对象。 如果我们扩展这个对象,我们可以通过导航它的所有子对象(字段)来进一步研究它。
还有一个更重要的内存快照功能——比较它们。 这使我们能够跟踪程序的趋势,例如快速识别内存泄漏的原因。 要比较两个快照(与之前创建的完全相同),请打开它们,然后从“差异”菜单中选择与第二个文件进行比较的选项。 我们将看到 Diff Stacks,它将以与单个快照类似的方式显示数据,但有一个重要的区别,即列值将指示两个文件之间的差异(见图 3-31)。
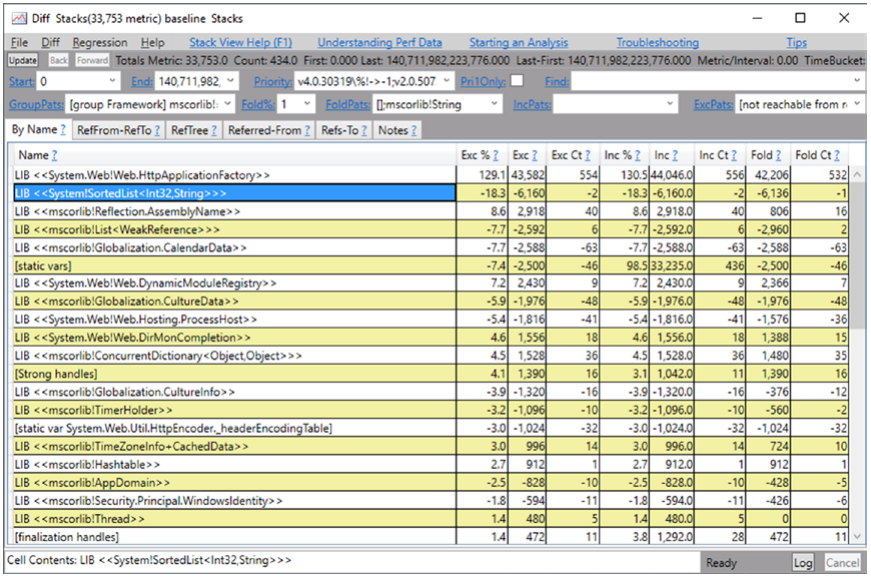
图 3-31。 PerfView - 内存快照差异
请注意,“收集内存数据”对话框中默认禁用“冻结”选项。 它控制我们是否要在制作堆快照时停止整个过程。 这显然是非常侵入性的,但也是非常精确的方法。 在生产环境中,您很可能对禁用“冻结”选项感兴趣,不幸的是,这可能会产生或多或少不一致的数据(因为快照是在正常应用程序工作期间创建的)。
PerfView 的真正强大之处在于其低开销和分析生产环境的能力。 我们可以用它来进行持续的性能监控或生产故障排除。 它可以为我们提供大量数据,并且大多数性能或内存相关问题都可以使用此工具进行诊断。 唯一的缺点是使用其用户界面和隐藏在这里或那里的所有可用选项的所有可能性相当陡峭的学习曲线。
当然,我们应该谨慎对待我们想要通过这种机制收集的信息量。 尽管工具的开销很低,但如果夸大收集的信息量,则它不适合生产使用。 从多个提供商和几个选定的关键字收集信息应该不成问题。 然而,正如我们所看到的,收集有关每个对象分配的调用堆栈的信息会导致不可接受的开销。 最简单的原则始终是最好的 - 在我们运行在生产环境中收集的所需数据集之前,让我们在任何较低的预生产环境中测试它如何影响应用程序和整个系统。
ProcDump, DebugDiag(过程转储、调试诊断)
当需要分析内存问题时,通常会晚在生产系统上发生。 然后,最简单的可能性之一是获取有问题的应用程序的内存转储并离线分析它。 存在用于获取内存转储的各种工具。 我想提一下其中两个,因为它们可能涵盖了所有最标准的需求。 这两个工具都作为独立工具安装,可以从以下 Microsoft 站点下载:
- ProcDump - https://docs.microsoft.com/en-us/sysinternals/downloads/procdump
- DebugDiag - https://blogs.msdn.microsoft.com/debugdiag/
ProcDump 是一个命令行工具,它允许我们仅通过一个临时命令来进行内存转储:
procdump -ma <process_pid>
但是,还有许多其他选项,例如当内存使用量或 CPU 超过给定阈值以及任何其他给定性能计数器值时进行内存转储。 还可以定期进行一些内存转储等。查看 ProcDump 的综合命令行帮助以获取所有可用选项的列表。
您还可以考虑使用 Sasha Goldshtein 创建的优秀 Minidumper 工具,可在 https://github.com/goldshtn/minidumper 上获取。 它具有强大的能力,可以节省 .NET 内存分析所需的最小内存量(因此排除可执行文件和 DLL 文件、非托管内存区域等形式的大量开销)。 然后,可以像任何其他内存转储一样分析这种“小型转储”,但甚至可能比常规内存转储小几倍。 因此,它在对大型进程进行内存转储时可能特别有用。
WinDbg
在本章我们所了解的各种工具中,WinDbg无疑是最低级的。 我们几乎可以在其中完成所有操作:从调试 .NET 应用程序开始,通过本机 Windows 应用程序,以及调试内核本身。 通用性和一点刚性是这个工具的力量。 它可以让你真正深入并在单个位的层面上展示事物。 例如,该工具的严重性允许对某些情况进行相当快速的分析,而无需花费其他工具中提供的多个分析结果的精美绘图的开销。 因此,从我的实践来看,我有时更喜欢使用 WinDbg,而不是等待更高级的工具以自己的方式处理数据。
幸运的是,自 2017 年中期以来,WinDbg 推出了全新的、完全更新的新版本。 这使得用户界面更加令人愉快并且可定制。
目前有两种安装 WinDbg 的方法 - 作为 Windows 驱动程序工具包 (WDK) 或 Windows 软件开发工具包(对于旧版本)的一部分,或者从 Windows 应用商店(最新版本)安装。 安装 SDK 时,您只需取消选择除 Windows 组件的调试工具(包括 WinDbg)之外的任何组件。 安装旧版本后,该工具将有两个版本 - 一种用于 32 位分析,一种用于 64 位分析。 我们应该使用哪一个取决于我们想要调试的内容 - 是 32 位还是 64 位进程还是内存转储。 从 Windows 应用商店安装的最新版本是单一通用版本(但在撰写本文时,仅提供预览版)。
WinDbg 是一个很好的实验工具,有助于理解 .NET 运行时。 我们可以附加到我们的托管程序,并且可以像我们在 Visual Studio 中习惯的那样调试它(以及运行时本身)。 但在日常工作中,如果我们需要使用WinDbg,我们可能会用它来分析以前制作的内存转储。 下面我们将使用新的WinDbg版本。
注意 WinDbg 实际上是 DbgEng 库的一个非常简单的包装器,它负责 Windows 上的调试平台。 它在 .NET 分析环境中的真正威力在于专门为 .NET 制作的扩展,如下所列。
运行WinDbg时,我们将看到一个窗口(见图3-32),在其中我们可以执行一些不同的操作:
- 再次使用任何最近的活动 - 这在一次又一次附加或运行同一进程时特别有用;
- 启动或附加到进程 - 通过选择“附加到进程”选项,将显示所有正在运行的进程的列表;
- 打开转储文件
图 3-32。 WinDbg 主窗口
还有其他可用选项,例如使用时间调试(当前不适用于托管代码)或远程连接到另一个调试器等。
默认情况下,WinDbg 作为本机调试器工作,因此它不理解 .NET 相关的结构和概念。 我们必须使用 WinDbg 扩展来为他提供此类知识。 有许多可能的扩展,其中最流行的是:
- SOS - 这是 .NET 运行时本身附带的基本但非常强大的扩展。 这个名字是“Son of the Strike”的缩写。 这是因为它是 .NET 框架开发过程中使用的名为 Strike 的调试工具的继承者。
- SOSEX - 这是 SOS 的扩展(因此得名),可以从其作者 Steve Johnson 的页面免费下载:http://www.stevestechspot.com/default.aspx。 在调试托管代码和内存转储方面,它添加了更强大的功能。
- NetExt(来自 Rodney Viana,可从 https://github.com/ rodneyviana/netext 获取)和 MEX(托管代码调试扩展,可从 https://www.microsoft.com/en-us/download/details.aspx 获取) ?id=53304) - 还有两个扩展允许我们做比上面两个更复杂的事情。
要加载扩展,我们应该使用.load <文件路径>命令。例如,.load g:\Tools\Sosex\64bit\sosex.dll。 如果是 SOS 内置的 .NET,您还可以手动键入 sos.dll 扩展路径,如下所示。 或者您可以使用方便的 .loadby 方法,它允许您根据第二个参数位置来定位路径。 这意味着您可以从 clr.dll(主 .NET 运行时库)所在的同一路径加载 sos.dll:
> .loadby sos clr
还有另一种可以与 WinDbg 一起使用的有用工具 - 命令树窗口。 由于一次又一次地输入所有命令非常麻烦,您可以创建一个包含可用命令的结构化列表的文件。 然后,通过使用 .cmdtree < file > 命令,您只需单击即可创建包含所有可用命令的专用窗口
注意 还可以通过连接到远程计算机或分析系统故障转储来获取操作系统内核本身的内存转储。 我们不需要它来实现我们的目的,但请记住 WinDbg 的强大功能。
此外,对于 WinDbg,您可以考虑使用 Sasha Goldshtein 创建的 msos 工具,可在 https://github.com/goldshtn/msos 上找到,该工具被描述为“a-la WinDbg 命令行环境,用于在没有 SOS 的情况下执行 SOS 命令” 可用的。” 我们可以将其视为 SOS 功能的命令行包装器,无需安装 WinDbg 并搜索适当的 SOS 扩展。 除此之外,它还添加了一些附加功能,例如解释堆对象和类上的任意动态查询。
Disassemblers and Decompilers(反汇编器和反编译器)
&esmp; 虽然与内存管理主题没有直接关系,但有时了解非您的应用程序的片段可能会很有用——我们只在二进制版本中拥有该片段。 正如我们很快就会看到的,.NET 二进制代码相当透明。 有一些工具可以让您以方便的方式查看其他程序的代码。 我将使用的最好的工具之一是由 0xd4d 用户在 GitHub 上创建的免费开源 dnSpy 工具,可从 https://github.com/0xd4d/dnSpy 获取。 它不仅是一个允许我们查看代码的工具,而且还可以调试和修改它。 我们将使用它来显示 .NET 标准库代码本身以及为该框架编译的程序。
&esmp; 还有其他流行的工具,如 ILSpy、JetBrains dotPeek 和 Redgate .NET Reflector,但 dnSpy 由于其编辑功能而特别有用,并且足以满足我们的目的。
BenchmarkDotNet
我们经常需要测量某些代码片段的性能。 这在本书中特别有用,因为我们将比较不同优化技术的效果。 如果通过测量代码本身的性能(其执行时间),还可以测量所需的内存量,那就太理想了。
BenchmarkDotNet 库正是如此,甚至更强大。 有了它我们可以测试每种方法的性能。 我们可以方便地比较它们的性能,例如,相对于各种参数。 我们可以针对各种 .NET 版本、JIT 和 GC 配置等进行测试。
更重要的是,这个库通过编写类似的微基准来避免我们自己可能犯的任何错误。 它对每个测试都有经过深思熟虑的阶段,例如预热或冷却。 测试是在多次迭代中进行的。 所有测量值均经过统计处理。 计算百分位数并检测数据的多模态分布(包括直观地呈现简化的直方图)。 结果,我们得到了一个功能强大但非常易于使用的工具。
清单 3-9 说明了简单测试的准备工作。 这实际上取决于我们感兴趣的类和方法的属性。如前所述,我们还可以针对提供的一些附加参数进行测试(例如我们示例基准测试中的 N)。
清单 3-9。 BenchmarkDotNet 测试示例
[BenchmarkDotNet.Attributes.Jobs.ShortRunJob]
[MemoryDiagnoser]
public class TailCallTest
{
[Params(5, 10, 20)]
public int N { get; set; }
[Benchmark]
public long FibonacciRecursive()
{
return FibonacciRecursiveHelper(N);
}
private long FibonacciRecursiveHelper(long n)
{
if (n < 3)
return 1;
return FibonacciRecursiveHelper(n - 2) + FibonacciRecursiveHelper(n - 1);
}
}
执行清单 3-9 中的测试就像调用 BenchmarkRunner 一样简单。 在我们的程序中运行< TailCallTest >()。 该测试的结果(见图 3-33)显示了每个参数和两个不同 JIT(Just In Time)编译器的每个方法的平均执行时间,从而产生了有关结果的丰富统计数据。
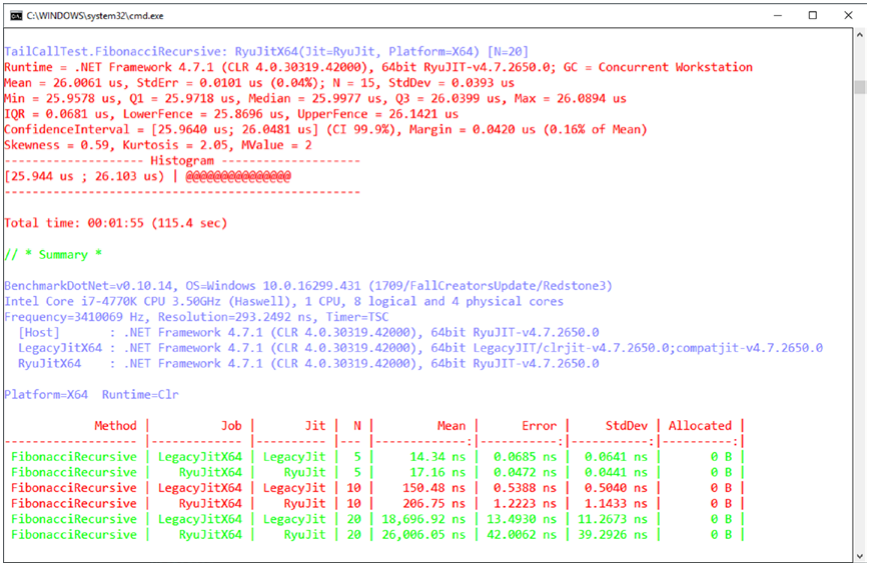
图 3-33。 BenchmarkDotNet 测试示例的结果
您还可以通过额外的记录器、分析器、诊断器等来扩展该库。 有两个对我们来说特别有趣。 GC 和内存分配诊断器 (MemoryDiagnoser) 分析测试期间发生了多少次垃圾收集以及进行了多少次分配。 还有硬件计数器诊断程序(HardwareCounters),它仅在 Windows 上可用,可以让我们深入了解与硬件相关的统计信息,例如 CPU 缓存未命中。
商业工具
到目前为止讨论的工具都是免费的。 尽管它们提供了强大的功能,但有时它们的使用相当麻烦。 另一方面,商业程序从一开始就是为了提供令人愉悦的用户界面而编写的。 下面您将找到可能使用的工具的简短列表。 我无法向您保证此列表是完整的。 从写书到出版,很多事情可能会发生变化。 我提到的工具只是在写这本书时使用的,也是我自己多年的经验。
使用这些工具时,您的里程可能会有所不同。 我鼓励您在阅读本书期间和之后尝试其中的每一个。 您将决定哪一个最适合您。 它们使用起来非常方便,特别是在非常了解该主题的专家手中(我希望您在读完本书后也能成为这样的人)。
在本书中只关注其中一种工具是没有意义的(那么我应该选择哪一个?)。 相反,我在免费、开源的替代方案上投入了更多的精力。
Visual Studio
很难想象 .NET 开发人员从未使用过 Visual Studio。 它确实是一个强大而健壮的编程工具。 除了众所周知的功能外,它还提供监控和内存分析选项:
-
打开内存转储文件并分析它们的对象使用情况(参见图 3-34),包括统计信息、单个对象实例以及它们之间的引用。
-
实时分析也是可能的。 我们当然对“内存使用情况”工具感兴趣,但还有“CPU 使用情况”和“GPU 使用情况”工具(见图 3-35)。 在使用它时,我们可以预览当前的内存消耗和 GC 的发生情况。 我们还可以随时拍摄快照,以便深入了解托管对象的统计信息。
Visual Studio 没有此处列出的其他商业程序那样广泛的诊断选项。 然而,它的巨大优势无疑是,你很有可能已经在使用这个工具了。
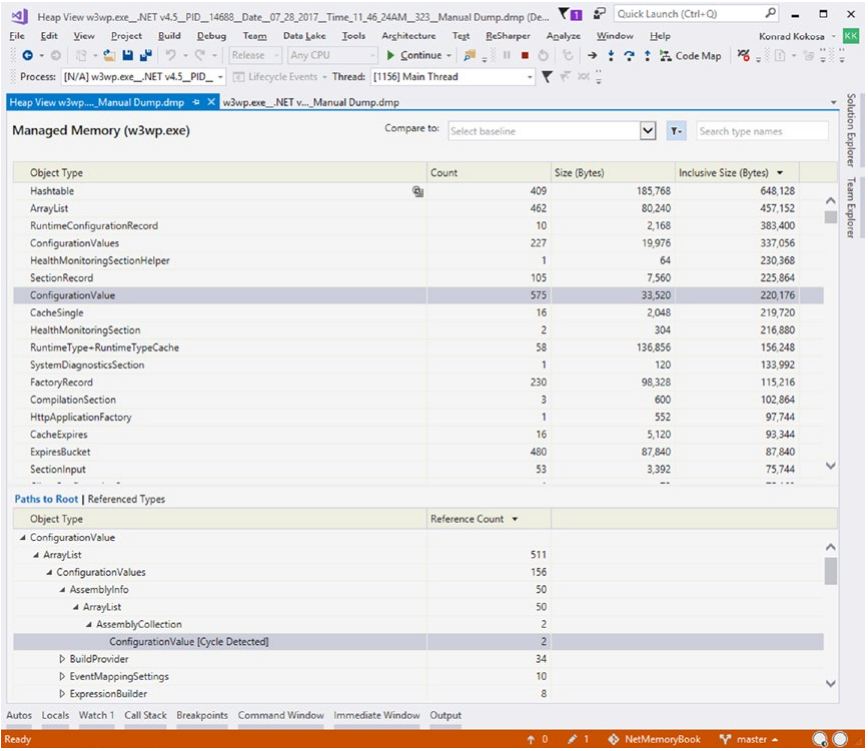
图 3-34。 Visual Studio 快照视图
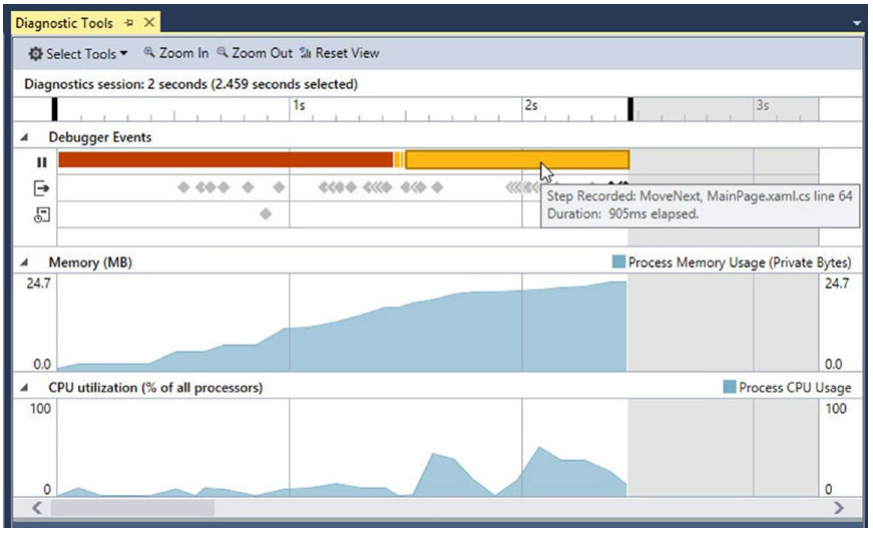
图 3-35。 Visual Studio 实时视图
Scitech .NET 内存分析器
Scitech 的工具是用于分析 .NET 的可用专用工具之一。 它提供了非常强大的选项来查看对象的状态,包括不同代的细分、对象的可达性等。 您可以使用它来显示非常复杂的参考图。
在每个视图中,您都可以使用各种过滤器,从而大大缩小研究范围。 举个例子,我们只需点击两次就可以在第 2 代中找到所有内置字符串(我们将在第 4 章中了解)。 该界面经过深思熟虑,我们将轻松开始使用该程序。 该应用程序在许多地方都会提示我们(在图标和工具提示的帮助下)可能出现的问题和问题,例如大量重复字符串或大量固定实例。 同时,界面并不太简单,允许使用我们选择的方法深入分析情况(见图 3-36 和 3-37)。
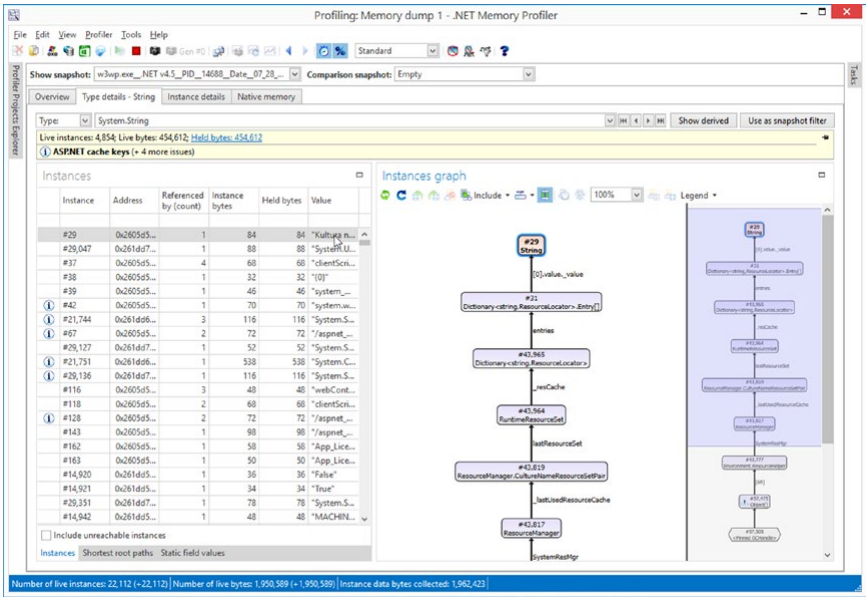
图 3-36。 .NET Memory Profiler 快照视图和参考图
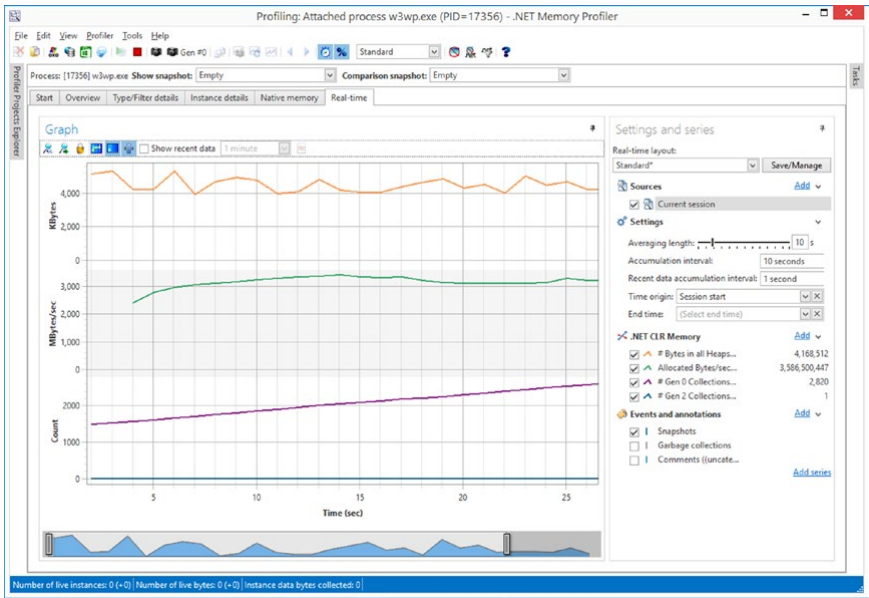
图 3-37。 .NET Memory Profiler 快照实时视图
通过该程序,我们可以使用.NET Memory Profiler API来研究内存使用情况或检测内存泄漏。 免费的命令行 NmpCore 程序允许您执行诊断会话,包括生产环境。 我们稍后可以在 .NET Memory Profiler 中分析它们。
JetBrains DotMemory
JetBrains 因其 ReSharper 工具而被 .NET 世界的很多人所熟知。 然而,该公司还拥有用于 CPU (dotTrace) 和内存 (dotMemory) 分析的优秀产品。 当然,我们对第二个感兴趣。 dotMemory 专为实时应用程序分析而设计,还提供内存转储分析的可能性。 可以在另一台计算机上远程分析应用程序,这在高于开发的环境中非常有用。
与 .NET Memory Profiler 相比,dotMemory 接口明显简化(但这可能是一个优势)。 界面本身就建议了许多可能的分析,甚至在我们询问之前就给出了结果(见图 3-38 和 3-39)。
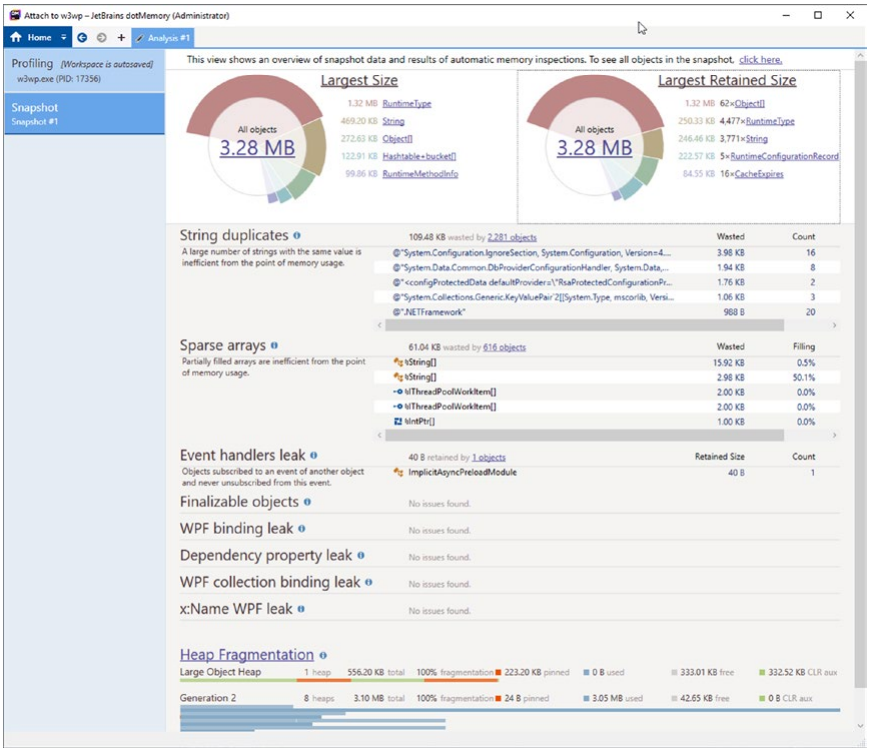
图 3-38。 带有参考图的 JetBrains DotMemory 快照视图
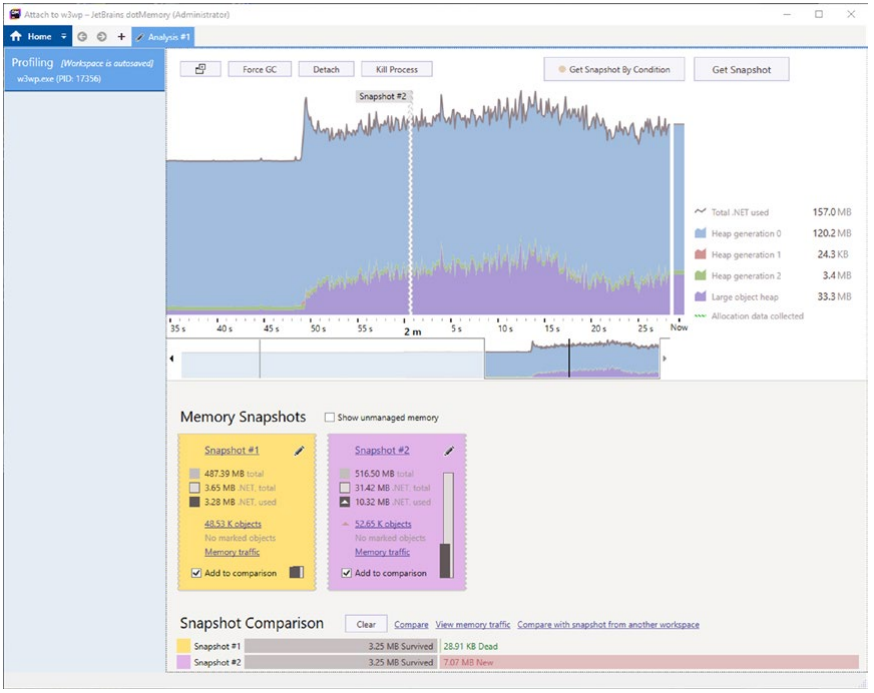
图 3-39。 JetBrains DotMemory 实时视图
DotMemory 提供了一些有趣的可视化效果,包括堆碎片。 我们还将快速了解哪些对象具有最大的保留大小。
还值得一提的是两个相邻的工具。 dotMemory Unit 允许您执行考虑内存消耗的单元测试。 它可以作为单元测试框架的一部分包含在 Visual Studio 中,也可以包含在持续集成过程中。 第二个工具是上述 ReSharper Visual Studio 扩展的堆分配查看器扩展。 它支持对我们的代码进行关于不需要的隐藏分配的静态分析(我们将在第 5 章中讨论它们)。
RedGate ANTS 内存分析器
RedGate 工具是我个人接触过的第一批此类产品之一。 至于用户体验,它与JetBrains工具非常相似。 它很容易使用,不会被太多的选项淹没,并且在询问用户之前尝试获得尽可能多的响应。 在撰写本文时,只能进行实时代码分析,无法加载内存转储(见图 3-40 和 3-41)。
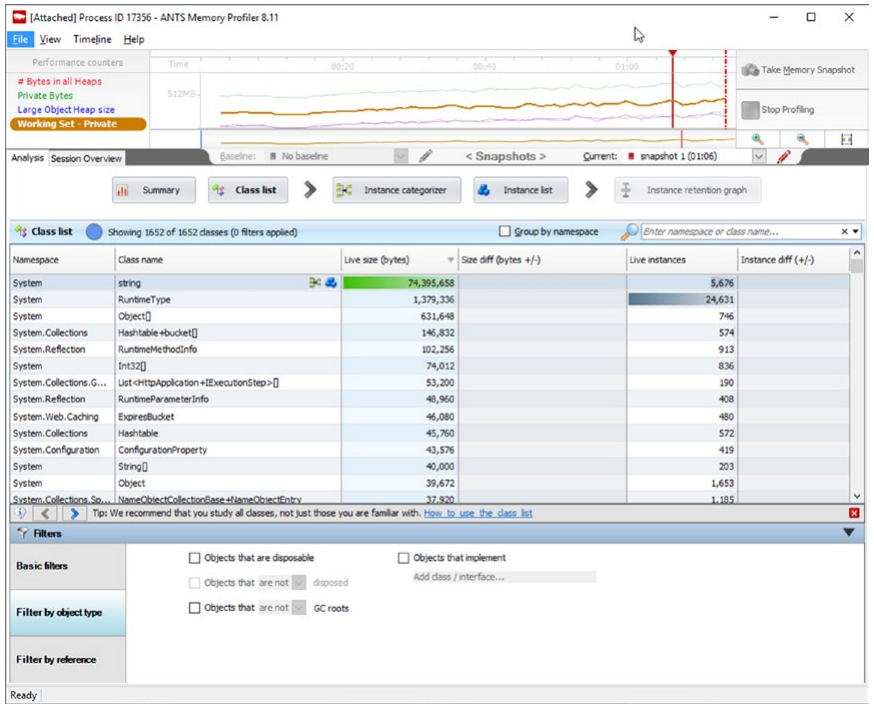
图 3-40。 ANTS 内存分析器快照视图
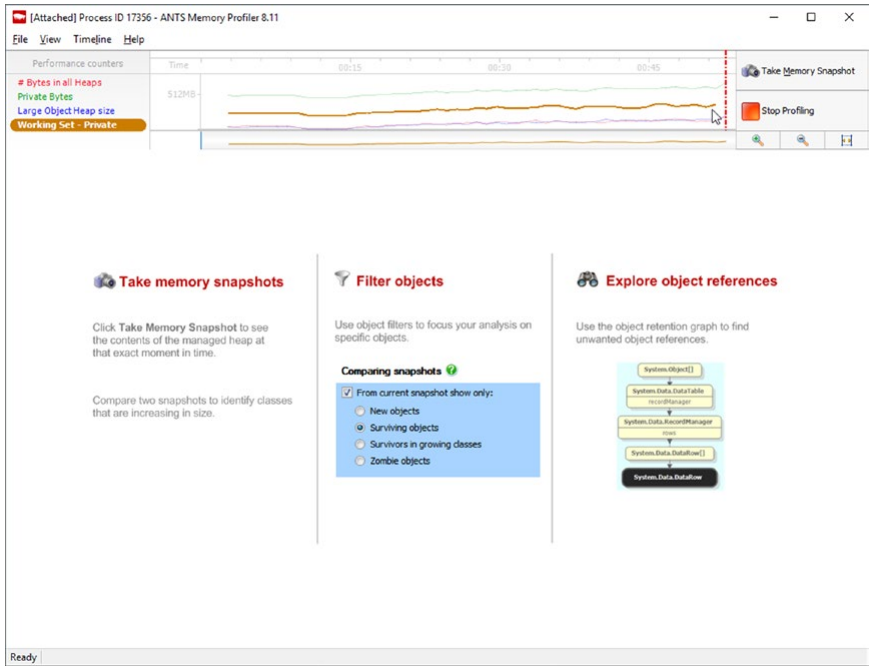
图 3-41。 ANTS 内存分析器实时视图
Intel VTune Amplifier 和 AMD CodeAnalyst 性能分析器
除了典型的代码和内存分析器之外,还有一些专用于对代码进行基于硬件的低级分析的工具,这些工具通常由处理器制造商提供。 标题中提到的两个主要选项由 AMD 和 Intel 作为商业付费工具提供。 他们提供了比经典的代码分析更深入的分析,指出哪些方法执行时间最长。 我们可以从硬件(处理器、显卡)内置的硬件计数器获取有关其内部行为的信息 - 缓存和内存利用率、管道停顿等等。
在 .NET 开发人员的日常工作中,我们对讨论这些细节不感兴趣。 然而,在微调应用程序时,它们可能非常有用,特别是当我们考虑优化热路径和执行数百万次的紧密循环时。
事实上,只有这样的低级工具才能清楚地向我们指出像第 2 章中所示的错误共享这样的问题。让我们看一下使用 Intel VTune Amplifier 对第 2 章中的清单 2-6 进行的示例分析的结果(见图 3-) 42)。 它清楚地表明发生了一些错误 - 我们的代码高度受内存限制,并且指出了 100% 竞争访问。
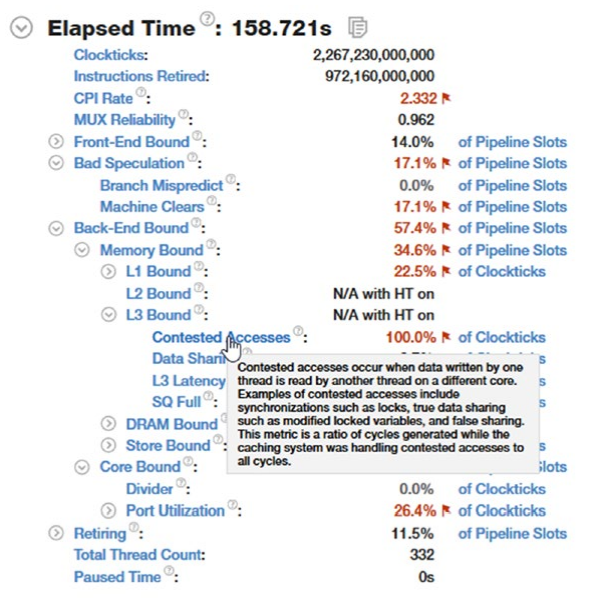
由于此类工具在最低级别跟踪硬件计数器,因此我们甚至可以计算出每行程序的统计数据,以找出问题的精确根源。 对于清单 2-6 中的程序,这样的分析确实指出了有争议的访问的来源。 显然,因为在 .NET 应用程序下面,它作为本机代码执行(感谢第 4 章中解释的 JIT 编译器),VTune 向我们指出了 JIT 汇编代码的具体行。 通过对 JIT 和英特尔汇编代码的总体了解,我们可以将这些行与 .NET 代码的具体行相匹配。 例如,在我们的结果中,有两行特别有问题(见图 3-43):
- 检查数组的大小(第一行突出显示),
- 访问旧计数器数据(第二个突出显示的行)。
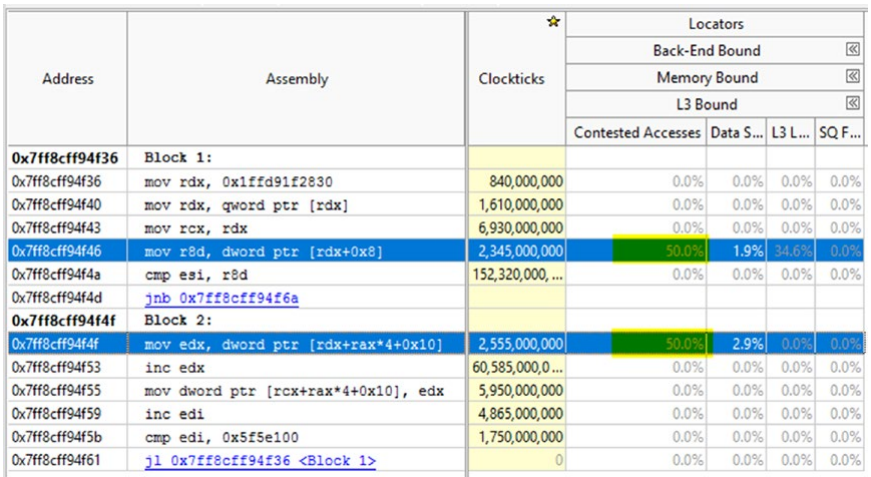
图 3-43。 英特尔 VTune Amplifier 的示例结果 - 汇编代码视图
因此,显然,使用此类工具需要对所用硬件、.NET 运行时甚至汇编语言有相当低级的了解。 还值得注意的是,这两个工具都适用于 Windows 和 Linux。
Dynatrace 和 AppDynamics
除了许多专门用于 .NET 内存管理的工具之外,还有许多用于一般应用程序性能监控的高级工具。 它们提供了对应用程序的深入了解,特别适合生产或预生产环境。 由于内存管理是 .NET 应用程序的一个重要方面,因此支持该平台的工具还可以方便地了解应用程序内存使用情况。
标题中列出的两家领先供应商提供的所谓应用程序性能管理 (APM) 工具就是这种方法的绝佳示例。 持续监控应用程序的问题及其对最终用户的影响甚至比仅在本地开发人员计算机上运行的最复杂的工具更有价值。 与现实和用户产生的真实流量根本没有对抗。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









