









英文原文:https://www.stevejgordon.co.uk/an-introduction-to-sequencereader
在这篇文章中,我想探索 .NET Core 3.0 的一项新功能,它简化了 ReadOnlySequence 的使用。如果您使用 System.IO.Pipelines 中的 PipeReader,您可能会发现自己使用的是 ReadOnlySequence。在 .NET Core 3.0 之前,需要从 ReadResult 的 Buffer 属性中手动对 ReadOnlySequence 进行切片。有了SequenceReader,我们可以简化这些任务,让框架以最优化的方式为我们做一些重复性的工作。
在撰写本文时,SequenceReader 尚未在任何地方记录,因此我想在这里介绍一个示例用例来帮助人们入门。我们不会接触整个 API 界面,但希望这里有足够的内容可以帮助您快速掌握核心功能。
什么是 ReadOnlySequence?
可能值得首先解决这个问题,因为这是 .NET Core 中相当新的类型,并且您会遇到它的情况有限。
不久前,添加了 Span<T> 和 Memory<T> 类型。它们都支持通过一致的 API 处理各种类型的连续内存区域。从那时起,许多新的构造都建立在这些类型提供的基础上。 System.IO.Pipelines 就是一个这样的例子,它是一种用于处理 IO 的高性能 API。
传统上,许多 IO 操作都使用流。流的一个问题是,它们让你负责管理缓冲区和在缓冲区之间复制数据。Pipelines在这两种情况下都能帮上忙,它在内部为你处理缓冲区,尽可能地暴露内存而无需复制。在简化的概念层面上,Pilelines从内存池中请求一些内存,然后管理这些内存,允许写入管道的数据存储在内存中,然后从内存中读取。如果我们事先知道内容的长度,这种简单的方法就能很好地发挥作用,但我们往往无法事先知道将要写入的数据量。
因此,Pipelines 依赖于内存段序列的概念。这由 PipeReader 作为 ReadOnlySequence<T> 公开。这本质上只是 Memory<T> 实例的链接列表。首次写入数据时,将使用单个 Memory<T> 缓冲区。如果已满,则可以请求新的 Memory<T> 段。数据写入可以继续到第二段。虽然每个 Memory<T> 实例都是一个连续的内存区域;每个实例可能会引用内存中的不同区域。为了跨这些 Memory<T> 段访问内存,会形成一个序列,以正确的顺序将它们链接在一起。
通过这个序列,我们现在有了一个可以读取的虚拟连续内存块。
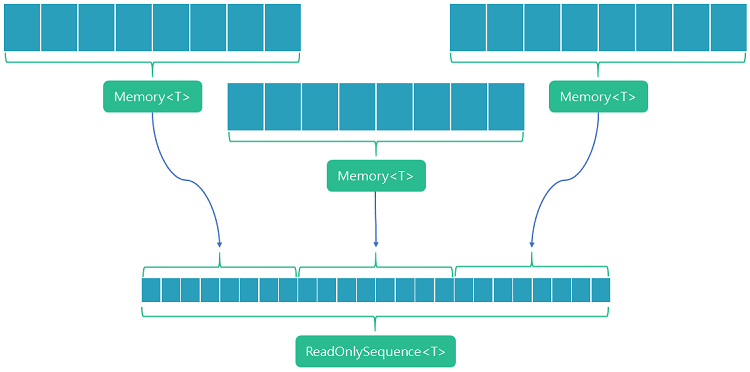
在此图中,我们通过 Memory<T> 引用了三个连续的内存块。它们可以存在于三个不同的内存位置。 ReadOnlySequence 在逻辑上组合了这些,以便可以跨段使用数据。
介绍示例场景
在本文的其余部分中,我将使用一个简单的示例来演示 SequenceReader 的使用。您可以在我的 GitHub 存储库中找到完整的示例代码。
注意:此示例经过简化,并跳过了您在使用管道和 ReadOnlySequence 时可能想要应用的一些步骤。这里的重点是查看 SequenceReader API,而不是最终的性能优化。例如,我们可以在以后的文章中重新审视这一点,并讨论我们可能会做的一些事情来增强此示例,以处理序列包含单个片段的情况。
这里的场景是,我们有一个字节流,我们知道它包含 UTF8 数据,它是一个以逗号分隔的值列表。在本例中,我手动构建了流,但实际场景是从 HTTP 端点接收这些字节。在这种情况下,您可能会从 HttpResponseMessage 获取内容流。设置代码包含在“CreateStreamOfItems 方法”中。我不会在这里展示该代码,因为它对于描述 SequenceReader API 来说并不是太重要。如果您有兴趣,可以在 GitHub 存储库中查看它。
与 Pipereader 一起工作
现在我们有了一个流,我们希望通过管道功能来使用它。在 .NET Core 3.0 中,引入了便捷方法,使将流转换为 PipeReader 变得简单。
var pipeReader = PipeReader.Create(stream, new StreamPipeReaderOptions(bufferSize: 32));
PipeReader 现在包含一个名为 Create 的静态工厂方法,它接受流和可选的 StreamPipeReaderOptions。我们可以传入我们的样本流。对于此演示,我传递了一个 StreamPipeReaderOptions,它设置了一个较小的缓冲区大小。这不是必需的,在本演示中使用它是为了确保我们不会将整个字节流返回到单个缓冲区中。这使我们能够演示将管道部分读取为跨越内存缓冲区的不同序列的方法。同样,您不需要在生产中执行此操作,并且默认值可能就可以了。
Main 方法中的其余代码处理从管道读取数据。
while (true)
{
var result = await pipeReader.ReadAsync(); // read from the pipe
var buffer = result.Buffer;
var position = ReadItems(buffer, result.IsCompleted); // read complete items from the current buffer
if (result.IsCompleted)
break; // exit if we've read everything from the pipe
pipeReader.AdvanceTo(position, buffer.End); //advance our position in the pipe
}
pipeReader.Complete(); // mark the PipeReader as complete
我们使用无限循环,一旦管道被完全读取,我们就会中断该循环。要开始读取,我们可以在 PipeReader 上调用 ReadAsync,它会返回 ReadResult。在 ReadResult 中,我们可以访问 Buffer 属性。这给了我们ReadOnlySequence。我将其传递到一个名为“ReadItems”的方法中,我们稍后将更深入地探讨该方法。我们还传递一个布尔值来指示结果是否已完成,这表明我们在缓冲区中拥有来自管道的最后一个数据。
在处理完最后一个数据后,我们会使用这个 bool 值中断循环。如果仍有更多数据,我们将推进 PipeReader。该方法获取消耗的 SequencePosition,即我们已成功读取并使用的字节的位置。它还会获取检查过的 SequencePosition,表示我们已读取但尚未消耗的数据。我们可能有一个包含不完整项目的缓冲区,因此虽然我们可以检查该数据,但在获得完整项目之前,我们无法使用它。一旦所有数据都被读取完毕,保存已读取字节的缓冲区就会被释放。而保存已检查数据的缓冲区则保持可用,这样在下一次通过时,一旦我们向内部缓冲区读取了更多数据,就有望处理现在完整的项目。
当我们读取完所有数据并退出此循环时,我们会将 PipeReader 标记为完成。
使用 SequenceReader<T>
最后,我们到达了这篇博文的重点!让我们看看 SequenceReader 如何帮助使用 ReadOnlySequence。
我已将大部分代码分解到名为“ReadItems”的方法中。有两个原因。首先,它将代码分解为更具可读性的单元,这是我更喜欢的。其次,也是最重要的,我们必须在这个演示中这样做。
SequenceReader 类型与 Span<T> 一样,是一个 ref 结构,它的使用有一些限制。这些限制之一是它不能是异步方法或 lambda 表达式的方法参数。它需要被定义为 ref struct 的原因是它在内部具有 ReadOnlySpan<T> 属性,这强制了 ref struct 规则的级联,即实例只能存储在栈上;不是堆。
我的“Main”方法是异步的,因此我不能直接在那里使用 SequenceReader。相反,通过将代码分解为非异步方法,我们现在可以使用 SequenceReader 并从异步方法调用此同步方法。
让我们探索一下代码…
private static SequencePosition ReadItems(in ReadOnlySequence<byte> sequence, bool isCompleted)
{
var reader = new SequenceReader<byte>(sequence);
while (!reader.End) // 循环直到我们读完整个序列
{
if (reader.TryReadTo(out ReadOnlySpan<byte> itemBytes, Comma, advancePastDelimiter: true)) // 我们有一个item要处理
{
var stringLine = Encoding.UTF8.GetString(itemBytes);
Console.WriteLine(stringLine);
}
else if (isCompleted) // 读取没有最终分隔符的最后一项
{
var stringLine = ReadLastItem(sequence.Slice(reader.Position));
Console.WriteLine(stringLine);
reader.Advance(sequence.Length); // 将 reader 推进到最后
}
else // 此序列中不再有项目
{
break;
}
}
return reader.Position;
}
我们首先创建一个 SequenceReader,传入当前的 ReadOnlySequence。
我们开始一个循环,如果 reader.End 属性为 true,则该循环将退出。当序列中没有更多数据可供消耗时,就会出现这种情况。
SequenceReader 上存在各种方法来支持读取和/或推进序列。我们可以使用 TryReadTo 方法尝试读取指定分隔符之前的数据。在本例中,我们正在解析逗号分隔的数据,因此我们提供逗号的字节作为分隔符参数。
如果在序列中找到提供的分隔符,则 out 参数将包含从当前位置开始直至(但不包括)分隔符的 ReadOnlySpan。在此演示中,这将是一个item的字节。默认情况下,TryReadTo 还会将序列读取器位置提前超过分隔符,但这可以使用 advancePastDelimiter 参数进行控制。
当 TryReadTo 返回 true 时,表示读取器找到了分隔符,现在我们在 itemBytes 变量中拥有了字节。我们现在可以使用这些字节。对于这个简单的演示,我们将它们转换为字符串并将其写入控制台。
当在序列中找不到分隔符的字节值时,TryReadTo 将返回 false。这可能发生在两种情况之一。
Pipe 现在可能包含所有可用数据并且 PipeWriter 已完成。在这种情况下,所有剩余字节都将存在于 ReadResult 缓冲区中。在这种情况下,ReadResult.IsCompleted 属性将为 true。我们的方法接受它作为参数,这样我们就可以处理这种特殊情况。
由于数据中的最后一项后面不包含逗号分隔符,因此我们需要以稍微不同的方式处理数据。我们在序列中的位置将位于项目的开头,因此我们可以假设剩余的字节代表整个项目。我们有一个单独的私有方法来处理剩余的数据,称为“ReadLastItem”。我们将当前序列传递给此方法,从当前位置对其进行切片,以确保我们只传递剩余的、未处理的字节。
在较高级别上,此方法将序列中的剩余字节复制到临时缓冲区中,然后可以使用该临时缓冲区来获取这些字节的字符串表示形式。 “ReadLastItem”方法使用两种可能的方法来实现这一点。
预期的情况是,我们通过使用在栈上创建的字节的临时缓冲区来避免任何堆分配。这是可能的,这要归功于 Span,它支持以安全的方式引用栈内存。由于在栈上工作存在一些达到栈内存限制的风险,因此我们确保剩余字节的长度小于我们的安全限制 128。根据我们的示例数据,我们知道这是真的,但我们永远不应该假设有些东西不会改变,尤其是在从外部端点检索此数据的现实情况下。
仅当数据长度超出栈安全限制时才会发生第二个流程。它使用 ArrayPool 来获取临时字节缓冲区。这也避免了分配,因为我们使用的是可重用数组池。它的性能比栈方法稍差,但总体上仍然相当高效。我们租用一个数组,其容量至少与序列中字节的长度一样大。请注意,该数组可能比我们需要的要大。
在这两种情况下,我们都可以使用 CopyTo 方法将序列中的字节复制到临时缓冲区中。然后,我们使用 Encoding.UTF8.GetString 方法将字节转换为字符串表示形式。对于 ArrayPool 代码路径,我们必须确保将数组切片为正确的长度,因为 ArrayPool 可能返回的数组比我们的数据长。我们不想尝试转换超出我们复制的字节。
“ReadLastItem”方法返回最后一项的字符串值。回到 ReadItems 方法,该字符串被写入控制台。然后读者可以根据序列的长度前进。这应该将我们置于序列的末尾,这将导致 while 循环退出。我们可以在这里轻松地使用break关键字,但我想在Reader上演示Advance方法。
回到 TryReadTo 调用周围的条件,第二种可能性是 PipeReader 当前缓冲的字节包含不完整的项目。例如,在我们的例子中,我们可以将表示“Ite”的字节放在序列的末尾。在 PipeReader 缓冲该项目的剩余部分之前,我们无法对这部分项目执行任何操作。在本例中,我们到达最后一个条件块并从 while 循环中中断。 “ReadItems”方法返回 SequenceReader 在序列中已到达的当前 SequencePosition。请记住,只有当我们成功读取完整的项目后,序列中的位置才会前进。在这种情况下,该位置将指示我们在序列中找到的不完整项目的开始。
‘ReadItems’返回到我们从 PipeReader 读取数据的 while 循环。此循环将继续,直到管道中的所有数据都已成功使用。
总结
我认为这是结束这篇文章的好地方。我们探索了 .NET Core 3.0 中的一些较新的 API,并借此机会了解了 System.IO.Pipelines 和新的流连接器,它可以轻松地通过 PipeReader 获取流并使用它。除非您进行大量 IO 工作,否则您可能永远不会发现自己使用 Pipelines,因此 ReadOnlySequence 和 SequenceReader 可能也不是您使用的类型。
对于此示例案例,SequenceReader 使得使用 PipeReader 中的 ReadOnlySequence 变得非常简单。如果您想高效地处理字节数据,用尽可能少的分配来解析它,Pipelines 和 SequenceReader 的结合可以使这成为可能。我有兴趣查看利用 SequenceReader 的用例和方法的其他示例。















 2295
2295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









