







1.KNN算法介绍。
KNN算法即k~近邻算法,通过计算测试数据与已知分类的样本数据集的相似度,选择相似度最高的前k条数据。统计k个数据中分类出现最高的分类,做为测试数据的分类。
2.算法特点
优点:精度高、对异常值不敏感 缺点:时间复杂度和空间复杂度高 适用数据:数据型和标称型
下面的相似度计算采用欧式距离:
两个n维向量x(x1,x2,...,xn),y(y1,y2,...,yn)的欧式距离公式
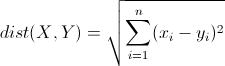
用Java实现KNN算法
首先定义用于存储数据的结点Node类,包含三个属性,1.样本数据属性 2.距离 3.分类类型。Node实现了Comparable接口,方便后续的求最相似的k条数据记录;给出了calDistance方法,用于计算结点间的距离。
</pre><pre name="code" class="java">package KNN;
import java.util.List;
public class Node implements Comparable<Node> {
private List<Double> data;
private double distance;
private int type;
public Node() {
super();
// TODO Auto-generated constructor stub
}
public Node(List<Double> data, double distance, int type) {
super();
this.data = data;
this.distance = distance;
this.type = type;
}
public List<Double> getData() {
return data;
}
public void setData(List<Double> data) {
this.data = data;
}
public double getDistance() {
return distance;
}
public void setDistance(double distance) {
this.distance = distance;
}
public int getType() {
return type;
}
public void setType(int type) {
this.type = type;
}
public int compareTo(Node arg0) {
if(this.distance>=arg0.getDistance())
return 1;
else
return -1;
}
public double calDistance( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









