









操作系统:
计算机程序运行:
进程:QQ.exe双机之后加载到内存,分配资源的最基本单位。
运行:CPU从内存中找到程序的main函数开始的位置把指令和数据读出来,把数据放在registers,把指令用pc保存起来,读一条指令执行一条指令。
多线程:进程运行的时候,程序的主线程和fork出来的子线程一起执行。
线程:资源调度的基本单位。
alu计算单元:保存现场到cache
线程切换:单核cpu,第一个线程执行,时间片到了之后,alu会把现场存储在cache中,切换第二个线程。如果再切换回来第一个线程,就用cache恢复现场继续执行。
注意:io中不占用cpu,只有计算才使用cpu。
摩尔定律:CPU18个月性能增强一倍
线程撕裂者(超线程):一个计算单元对应两组或多组寄存器
线程可见性:
CPU速度比内存快100倍,所以在Cpu和内存之间有多级缓存,每个核有两个缓存。每CPU有一个多核共享缓存。
局部性原理:空间局部性和时间局部性。CPU在读取内存的时候会一次卖取一块数据,或叫一行数据cacheline作为缓存,工业标准大小是64个字节。
缓存一致性协议:当某一个cpu修改了缓存行中某个数据的时候,就要通知其他的cpu改变缓存行.
保证可见性:volatile
volatile修饰的内存的修改会通知所有用到这块内存的所有线程重新读取
线程有序性:
指令重排序:单线程中的指令看上去是顺序执行的,实际未必(as-if-serial).
指令重排序原因:提高执行效率,压榨CPU,流水线执行,提高CPU效率.
什么情况下可以重排序:指令乱序之后不影响最终一致性(不论指令如何乱序都不会影响最终结果).
指令重排序后果:会产生不希望看到的结果
对象创建过程:new一块内存空间设置默认值->构造方法设置初始值->栈中指针和堆中对象建立关联
线程调用方式:
new Thread().run();
new Thread().start();
start和run的区别:
run方法会阻塞主线程,执行子线程
start开启子线程,跟主线程一起运行
线程创建的三种方式:
-
继承Thread:new MyThread().start
-
实现Runnable接口:new Thread(new Runnable()).start();
-
Lambda:new Thread(()->{
执行内容
}).start();
-
线程池:Excutor.newCacheThread()
Sleep:
线程睡眠指定时间,让给其他线程执行
Yeild:
离开运行状态,进入就绪状态,进入竟态,从running状态进入ready状态
Join:
线程A中调用线程B.Join(),挂起当前线程,执行B线程,B线程执行完毕后继续运行线程A
线程六个状态(八种):

-
new:new一个线程没有调用start
-
runnable:
-
ready:线程进入CPU等待队列
-
running:线程正在运行
-
terminated:线程运行结束
-
blocked:阻塞状态,没有获得锁
-
waiting:调用join或者wait之后,进入的状态
-
timedWaiting:调用sleep,wait(time)之后,进入带有等待时间的的状态
线程关闭:线程正常结束
stop:直接关闭线程(不建议用)
interrupted:打断线程并且catch住exception(通常可能在interrupt,sleep,wait(time)之后也会得到这个exception.),然后执行一些逻辑(不建议用),使用时机是结束一个睡眠时间特别长的线程.
JVM线程和OS线程是否是一一对应的:
是一一对应的,包含main线程、GC线程、其他线程
获得线程状态:Thread.getState();
锁:
为什么上锁:多线程执行任务的时候造成的被操作内容读写不一致的问题
sychronized:
通常使用方式:
Sychronized(this){
}
public sychronized void methodName(){
}
Sychronized两种锁:
一种是普通方法和代码块使用的this,就是当前对象
另一种是static修饰的方法,锁是当前对象的Class
*不能使用基本类型作为锁,不能使用String常量,因为这些都在方法区中.可能会出现奇怪的现象
同步方法和非同步方法是否可以同同时调用?可以,参考厕所理论
如果有多线程写入以及多线程读取都有的场景下,是否可以只给写加锁?看业务场景,如果读取到脏数据没问题,就可以,因为加锁效率低.但是通常不会这么做(脏读)
Sychronized可重入:
一个线程在Sychronized方法A调用Sychronized方法B,Sychronized会判断当前锁是否一致,如果一致就可重入
Sychronized锁升级:
偏向锁:第一个访问锁的线程在锁头中写入这个线程的id,如果这个线程继续进来执行,此时不会加锁,多个线程竟态的时候,没有偏向锁.
自旋锁:如果这时候有线程竞争,且偏向锁已经有了线程id,其他的锁就都会while(true)自旋,次数为10次.
重量级锁:
重量级锁是依赖对象内部的monitor锁来实现的,而monitor又依赖操作系统的MutexLock(互斥锁)来实现的,所以重量级锁也称为互斥锁, 当系统检查到锁是重量级锁之后,会把等待想要获得锁的线程进行阻塞,被阻塞的线程不会消耗cpu。但是阻塞或者唤醒一个线程时,都需要操作系统来帮忙,这就需要从用户态转换到内核态,而转换状态是需要消耗很多时间的,有可能比用户执行代码的时间还要长。
*什么情况下用重量级锁,什么情况下用自旋锁?
执行时间长,线程数比较多使用系统锁;线程数量不多,执行时间比较短使用自旋锁.
异常和锁:
程序中出现异常,锁会被释放

临界区:被sychronized修饰的方法区或代码区
*将多线程变成单线程线性执行
*临界区应该尽可能的小
DCL单例(double check lock):判断是否为空->上锁->再次判断是否为空
DCL单例是否需要volatile?
第一个线程执行的之后遇到了指令重排,出现了半初始化对象,第二个线程判断instance不是空的,但其实没有初始化完成
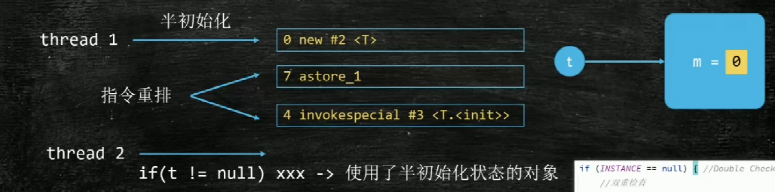
sychronized保证线程有序性,不保证代码块内语句有序性
哪些指令可以重排:8种happens-before
volatile怎么阻止指令重排的:
JVM规定,fence/barrier上面和下面的指令不能换顺序(内存屏障),每个CPU有不同的屏障指令,JVM有四条屏障(CPU原语):
LoadLoad读读
StoreStore写写
LoadStore读写
StoreLoad写读
指的是fence/barrier的上面的Load,下面是Store的时候算是屏障
执行过程是如图
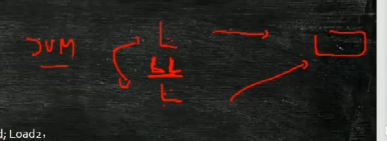
上面的Load操作读取了右侧数据,下面的Load也读取了右侧数据的时候,中间加LoadLoad.虚拟机发现了这种情况的时候就会阻止指令重排
*不用volatile修饰,就不加
volatile加屏障的原理

JVM几种实现:hosport openJDK Z9 Zing 阿里龙井
CAS(CompareAndSet 比较并且设定)
对常见操作的无锁线程安全优化
V代表要改的值
Expected代表期望的值
NewValue代表新值
如果要改的值和期望值相同,就把期望值改成新值
ABA问题:
描述:V是引用类型,引用对象A,但是在引用的过程中,A的内部逻辑改变了,但是V的引用没有改变,就会导致ABA问题
解决:在Atomic类中使用加入版本号方法
atomic包(原子操作包)
AtomicInteger使用:
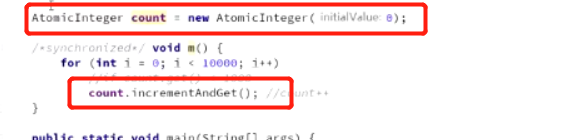
创建一个AtomicInteger,使其线程安全的自增
LongAdder由来
LongAdder类是JDK1.8新增的一个原子性操作类。AtomicLong通过CAS算法提供了非阻塞的原子性操作,相比受用阻塞算法的同步器来说性能已经很好了,但是JDK开发组并不满足于此,因为非常搞并发的请求下AtomicLong的性能是不能让人接受的。
如下AtomicLong 的incrementAndGet的代码,虽然AtomicLong使用CAS算法,但是CAS失败后还是通过无限循环的自旋锁不多的尝试,这就是高并发下CAS性能低下的原因所在.
高并发下N多线程同时去操作一个变量会造成大量线程CAS失败,然后处于自旋状态,导致严重浪费CPU资源,降低了并发性。既然AtomicLong性能问题是由于过多线程同时去竞争同一个变量的更新而降低的,那么如果把一个变量分解为多个变量,让同样多的线程去竞争多个资源。
ReentrantLock:可重入锁(可以替代Sychronize)
使用方法:
Lock lock = new ReentrantLock();
try{
//在需要使用的地方调用
lock.lock();
}finally{
//在结束时
lock.unlock();
}
与Sychronized差别:
-
lock.tryLock()方法是有返回值的,它表示用来尝试获取锁,如果获取成功,则返回true,如果获取失败(即锁已被其他线程获取),则返回false,这个方法无论如何都会立即返回。在拿不到锁时不会一直在那等待自旋.
-
lock.lockInterruptibly:设置可以被打断的
-
可以设置为公平锁 Sychronized只有非公平锁
公平锁和非公平锁
公平锁:线程争抢资源前会判断等待加锁的队列,并加入队列
非公平锁:线程争抢资源,不管先来后到















 292
292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









