







向量空间模型(Vector Space Model)
将文本看作是一个向量,向量中的每一维都代表某单词是否出现在文本中,使用向量空间模型的pca算法时并不做规约化,因为文本里的每一条不一定有同等的作用。向量空间中紧挨着的文本,我们认为他们讨论的是同一类的问题:
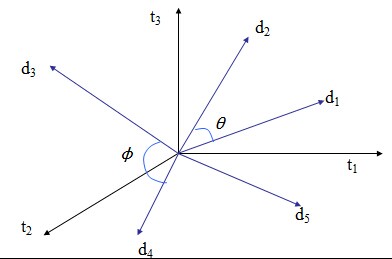
其中有三个基础的性质:
1. d1挨着d2,那么d2挨着d1
2. d1挨着d2,d2挨着d3,那么d1离d3不远
3. d离d最近
向量d1与d2的距离由他们的夹角的余弦值决定:
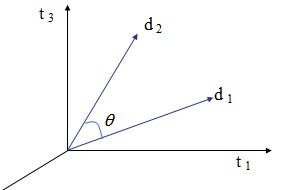
以长度为标准来区分向量的每一个成分,我们使用2阶范数:
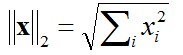
也就是讲向量映射到闭单位球里,然后:
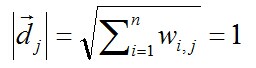
所以更长的文本不会有更多的权重。
我们定义两个向量的相似度:
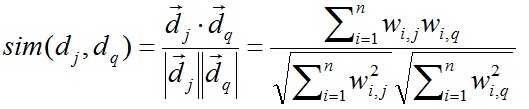

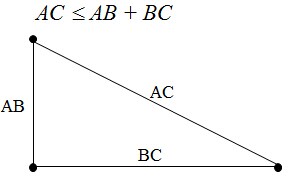
三角不等式:
在欧几里得空间:
但是在语义空间中这个法则不成立:
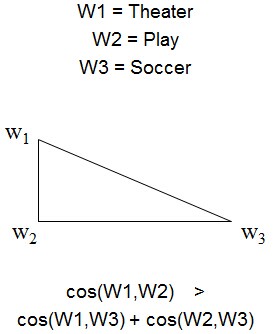
下面是三个例子:
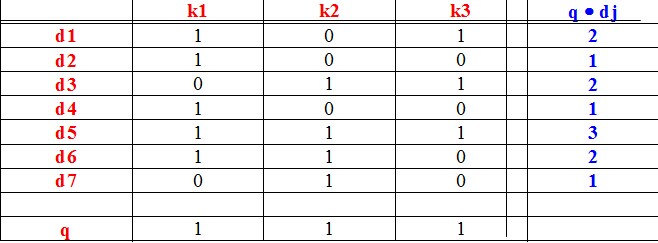
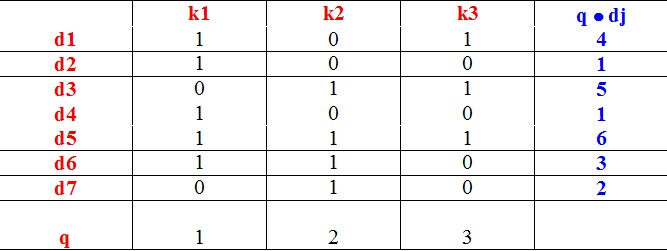
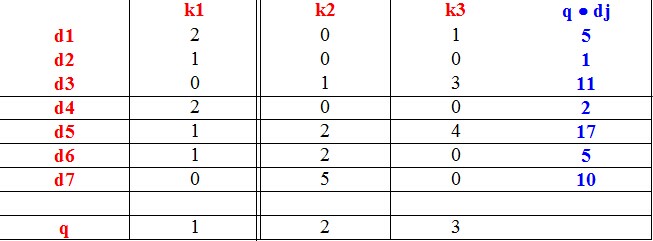
当然,将高维的特征空间映射到低维的特征空间使用的依然是SVD,设计一个映射来反应低维空间的语义关联,然后再通过度量文本的相似度进行学习。一个例子来阐述隐含语义空间:
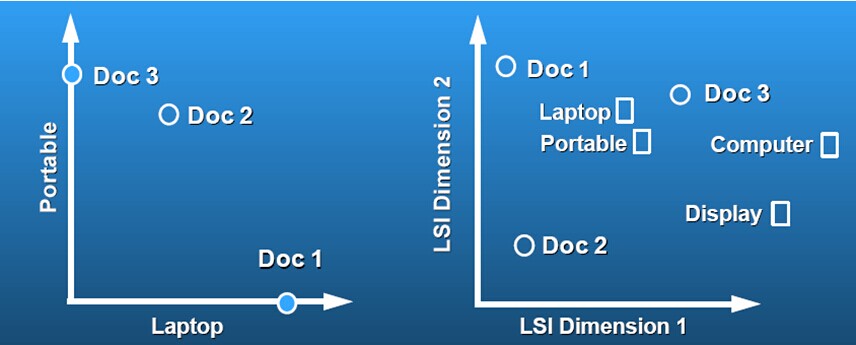
通过SVD,A的每一行每一列都映射到了k维的LSI空间了。我们的目标q也映射到这个空间里:
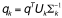
要注意q不是一个稀疏的向量。
下面是一个文档矩阵:
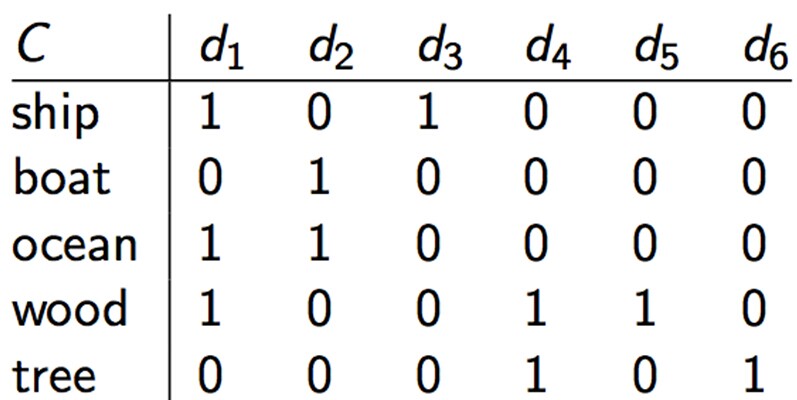
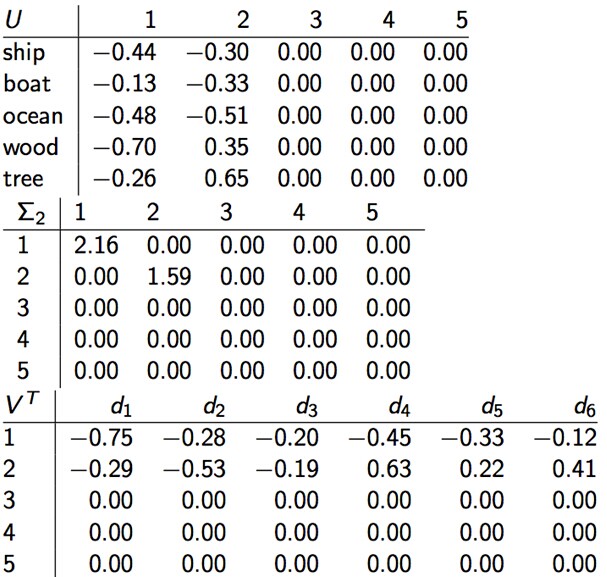
C = UΣVT,其中U Σ VT为:
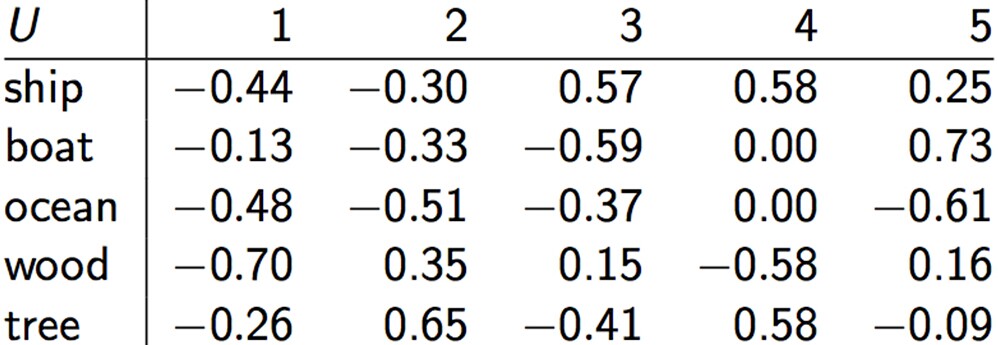
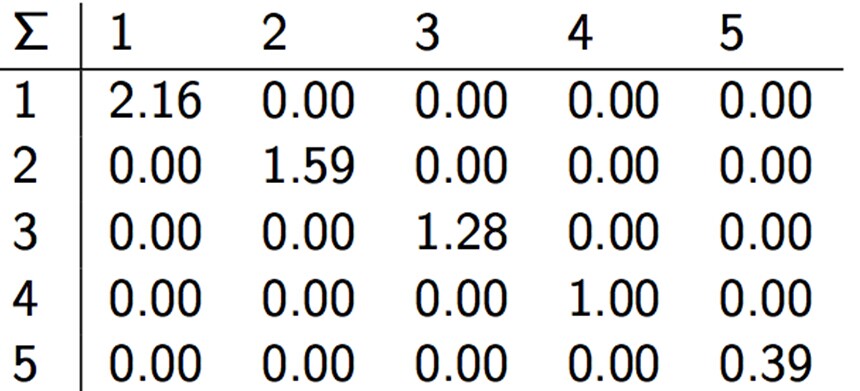
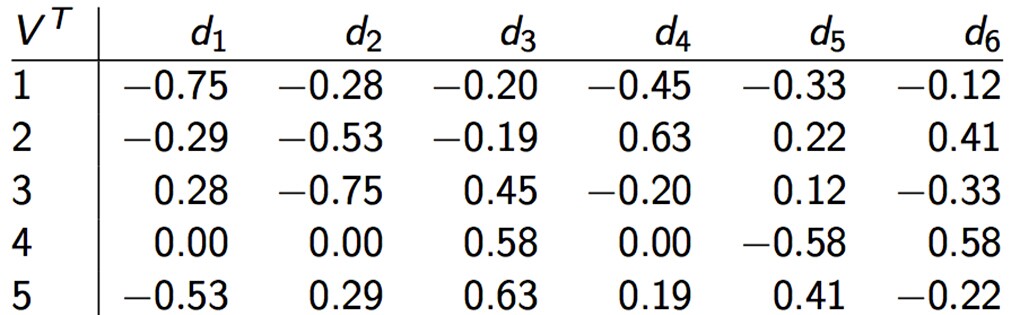
降维之后:
原始矩阵C与降维之后的C2进行对比:
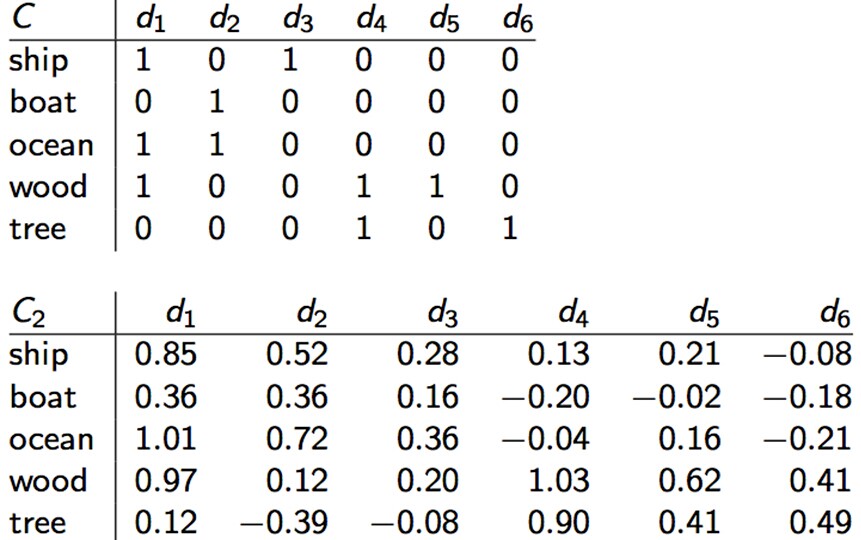
其中,d2与d3在原始空间的相似度为0,在降维空间的相似度为0.52 ∗ 0.28 + 0.36 ∗ 0.16 + 0.72 ∗ 0.36 + 0.12 ∗ 0.20 + −0.39 ∗ −0.08 ≈ 0.52
LSI提高了精度,然而却在否定句,布尔问句等问题中表现很差。















 6149
6149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









