







关键词:Scrapy spider pipeline xpath
参考文档
Scrapy 0.24中文版官方文档(PDF格式)
csdn下载Xpath教程
W3school-XPath
目标:将亚马逊的上的手机信息爬取下来,包括价格、描述信息、URL 。
新建一个项目:
scrapy startproject YamaxunPhone新建完项目后,该项目的目录结构如下:
YamaxunPhone
| scrapy.cfg
| YamaxunPhone
|_init_.py
|items.py
|piplines.py
|settings.py
|spiders
|_init_.py
|Phone.py项目新建完成后,先定义要爬取的内容(通过scrapy Items实现)
定义的Item:
Item.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# 我们只爬三项内容:手机商品的链接、价格、商品描述
import scrapy
class YamaxunItem(scrapy.Item):
price = scrapy.Field()
descript = scrapy.Field()
URL = scrapy.Field()编写spider:
初始URL 的获取:
亚马逊有一个热门手机品牌的页面,上面有品牌的链接,我们就把这些链接当作初始的URL 好了:
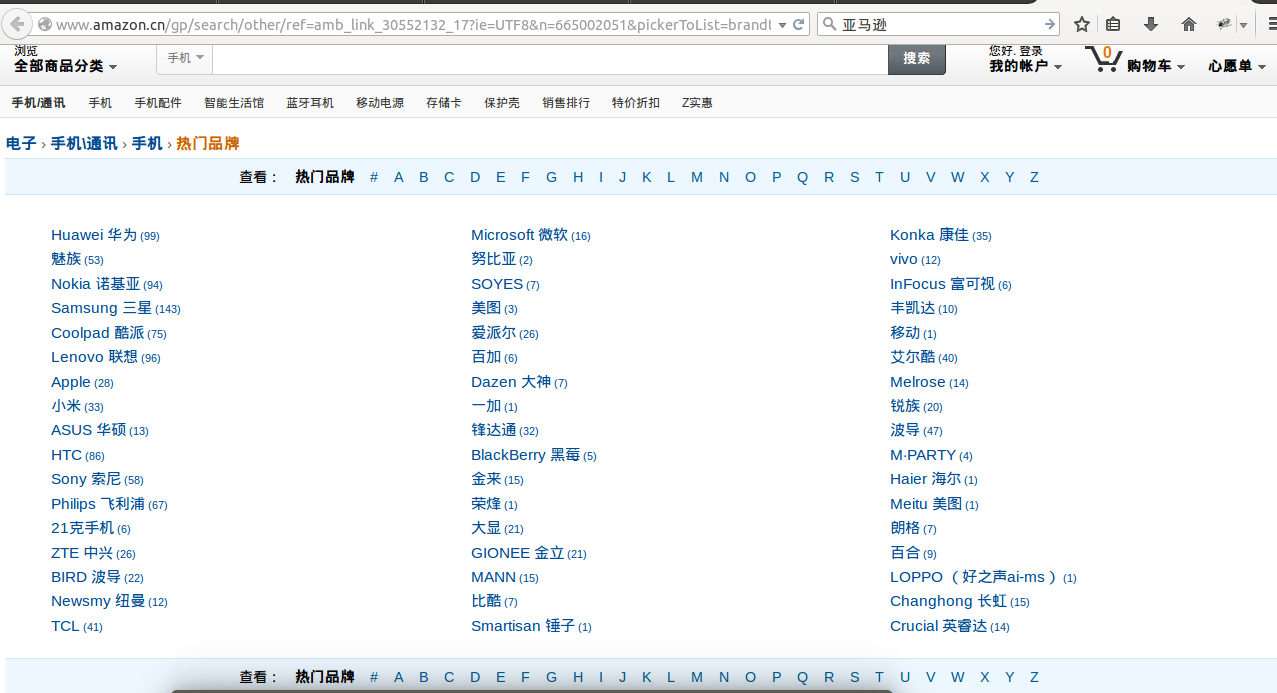
获取这些链接实际上已经相当于实现了一次爬虫,但我们就不用新建一个工程了,在终端输入以下命令:
scrapy shell 'http://www.amazon.cn/gp/search/other/ref=amb_link_30552132_17?ie=UTF8&n=665002051&pickerToList=brandtextbin&pf_rd_m=A1AJ19PSB66TGU&pf_rd_s=merchandised-search-left-4&pf_rd_r=1RR3NYZGNKTT02HCXYJT&pf_rd_t=101&pf_rd_p=249713272&pf_rd_i=664978051'scrapy shell + 要处理的URL =》得到一个response对象。我们直接用response.xpath()来获取这些链接。
xpath可以通过浏览器插件获得,我在这里用的是firePath,最后获得这些链接的命令是:
response.xpath("//div[@class='c3_ref refList']/ul/li/a/@href").extract() 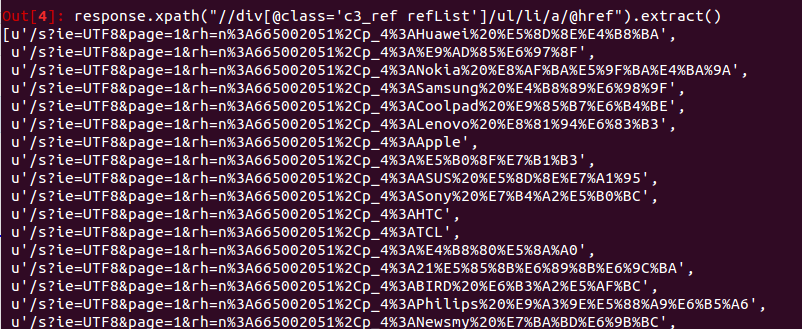
获取的链接是相对地址,前面加”http://www.amazon.cn“就好了。
将其复制下来存到s里面,然后在python命令行中用几行代码得到各个完整的链接:
URL_list=[]
for i in s:
i = 'http://www.amazon.cn'+i
URL_list.append(i)
print URL_list将上面代码的输出复制下来备用。
编写Spider:
在spider目录下新建一个Phone.py
# -*- coding: utf-8 -*-
from scrapy.selector import Selector
try:
from scrapy.spider import Spider
except:
from scrapy.spider import BaseSpider as Spider
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









