







注:转自董西成的PPT,本文主要是通过PPT整理出来,具体文章的链接没有找到
前言:Yarn 是什么?
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop
资源管理器,它是一个
通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控 )分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。这里的应用程序是指传统的MapReduce作业或作业的DAG(有向无环图)。
一.Hadoop YARN产生背景
-
Mapreduce1.0版本固有的问题
- 扩展性受限
- 单点故障
- 难以支持MR之外的计算
- 资源利用率
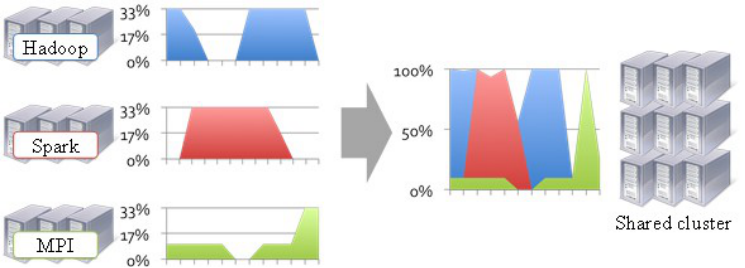
- 运维成本和数据共享【多计算框架各自为战,数据共享困难】
- MR:离线计算框架
Storm:实时计算框架
Spark:内存计算框架 - 运维成本 如果采用“一个框架一个集群”的模式,则可能需要多个管理员管理这些集群,进而增加运维成本, 而共享模式通常需要少数管理员即可完成多个框架 的统一管理。
- MR:离线计算框架
- 数据共享
- 随着数据量的暴增,跨集群间的数据移动不仅需花 费更长的时间,且硬件成本也会大大增加,而共享集群模式可让多种框架共享数据和硬件资源,将大大减小数据移动带来的成本。
Yarn 产生背景总结:
1) 源于MRv1的缺陷:
扩展性受限;
单点故障;
难以支持MR之外的计算框架;
2) 多计算框架各自为战,数据共享困难,资源利用率低;
MR: 离线计算框架
Storm:实时计算框架
Spark:内存计算框架
二. Hadoop YARN基本构成与资源调度
1.YARN基本架构
- YARN基本架构
- ResourceManager
- 整个集群只有一个,负责集群资源的统一管理和调度
- 详细功能
处理客户端请求
启动/监控ApplicationMaster
监控NodeManager
资源分配与调度
- NodeManager
- 整个集群有多个,负责单节点资源管理和使用
- 详细功能
单个节点上的资源管理和任务管理
处理来自ResourceManager的命令
处理来自ApplicationMaster的命令
- ApplicationMaster
- 每个应用有一个,负责应用程序的管理
- 详细功能
数据切分
为应用程序申请资源,并进一步分配给内部任务
任务监控与容错
- Container
- 对任务运行环境的抽象
- 描述一系列信息
任务运行资源(节点、内存、CPU)
任务启动命令
任务运行环境
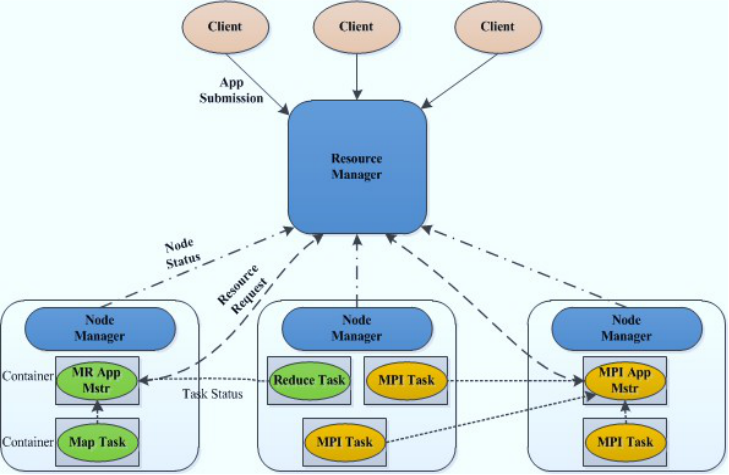
Yarn 的基本组成
Master/Slave结构,1个ResourceManager对应多个NodeManager;
YARN由Client、ResourceManager、NodeManager、ApplicationMaster组成;
Client向ResourceManager提交任务、杀死任务等;
ApplicationMaster由对应的应用程序完成;每个应用程序对应一个ApplicationMaster,
ApplicationMaster向ResourceManager申请资源用于在NodeManager上启动相应的Task;
NodeManager向ResourceManager通过心跳信息:汇报NodeManager健康状况、任务执行状况、领取任务等;
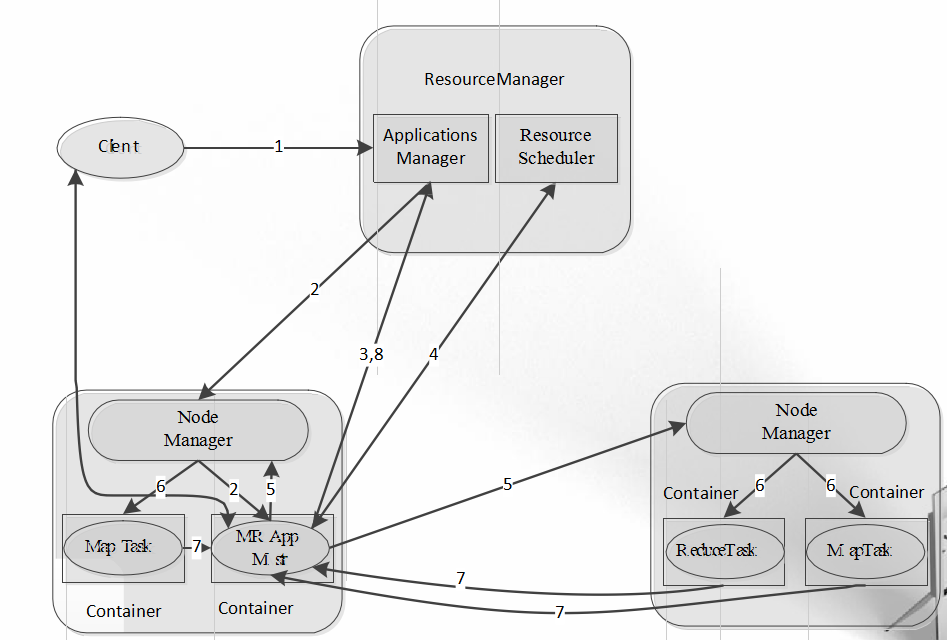
2.YARN运行过程
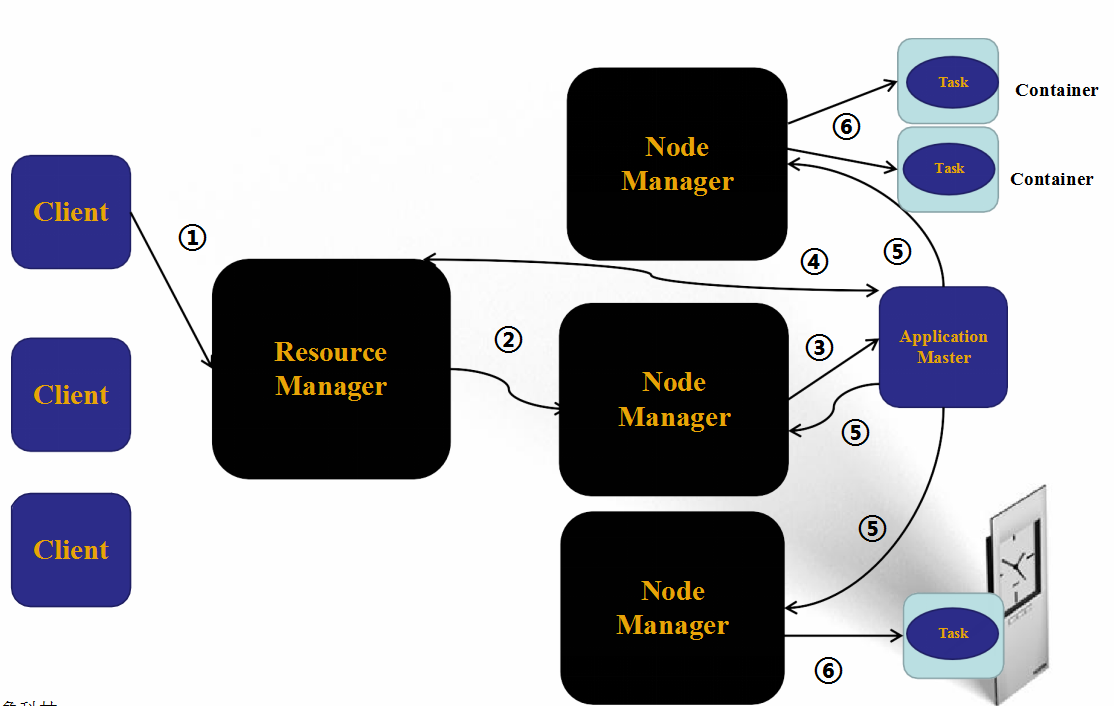
Yarn 工作原理解说:
1)用户向YARN中提交应用程序/作业,其中包括ApplicaitonMaster程序、启动ApplicationMaster的命令、用户程序等;
2)ResourceManager为作业分配第一个Container,并与对应的NodeManager通信,要求它在这个Containter中启动该作业的ApplicationMaster;
3)ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查询作业的运行状态;然后它将为各个任务申请资源并监控任务的运行状态,直到运行结束。即重复步骤4-7;
4)ApplicationMaster采用轮询的方式通过RPC请求向ResourceManager申请和领取资源;
5)一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务;
6)NodeManager启动任务;
7)各个任务通过RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicaitonMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
在作业运行过程中,用户可随时通过RPC向ApplicationMaster查询作业当前运行状态;
8)作业完成后,ApplicationMaster向ResourceManager注销并关闭自己;
3.YARN的容错性
- ResourceManager
存在单点故障;
正在基于ZooKeeper实现HA。 - NodeManager
失败后,RM将失败任务告诉对应的AM;
AM决定如何处理失败的任务。 - ApplicationMaster
失败后,由RM负责重启;
AM需处理内部任务的容错问题;
RMAppMaster会保存已经运行完成的Task,重启后无需重新运行。
4.YARN调度框架
- 双层调度框架
RM将资源分配给AM
AM将资源进一步分配给各个Task - 基于资源预留的调度策略
资源不够时,会为Task预留,直到
资源充足
与“all or nothing”策略不同(Apache Mesos)
5.YARN资源调度器
- 多类型资源调度
- 采用DRF算法
(论文:“Dominant Resource Fairness: Fair Allocation of Multiple Resource Types”)
目前支持CPU和内存两种资源
- 采用DRF算法
- 提供多种资源调度器
- FIFO
- Fair Scheduler
- Capacity Scheduler
- 多租户资源调度器
- 支持资源按比例分配
- 支持层级队列划分方式
- 支持资源抢占
6.YARN资源隔离方案
- 支持内存和CPU两种资源隔离
- 内存是一种“决定生死”的资源
- CPU是一种“影响快慢”的资源
- 内存隔离
- 基于线程监控的方案
- 基于Cgroups的方案
- CPU隔离
- 默认不对CPU资源进行隔离
- 基于Cgroups的方案
7.YARN支持的调度语义
- 支持的语义
- 请求某个特定节点/机架上的特定资源量
- 将某些节点加入(或移除)黑名单,不再为自己分配这些节点上的资源
- 请求归还某些资源
- 不支持的语义
- 请求任意节点/机架上的特定资源量
- 请求一组或几组符合某种特质的资源
- 超细粒度资源
- 动态调整Container资源
三.Hadoop YARN上的计算框架
1.YARN设计目标
- 通用的统一资源管理系统
- 同时运行长应用程序和短应用程序
- 长应用程序
- 通常情况下,永不停止运行的程序
- Service、HTTP Server等
- 短应用程序
- 短时间(秒级、分钟级、小时级)内会运行结束的程序
- MR job、Spark Job等
2.以YARN为核心的生态系统
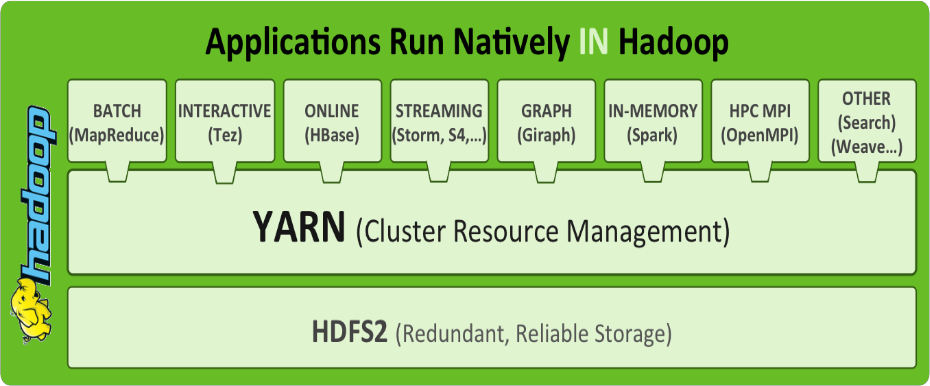
【1】离线计算框架:MapReduce
- 将计算过程分为两个阶段,Map和Reduce
- Map 阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
- Shuffle连接Map和Reduce两个阶段
- Map Task将数据写到本地磁盘
- Reduce Task从每个Map Task上读取一份数据
- 仅适合离线批处理
- 具有很好的容错性和扩展性
- 适合简单的批处理任务
- 缺点明显
- 启动开销大、过多使用磁盘导致效率低下等
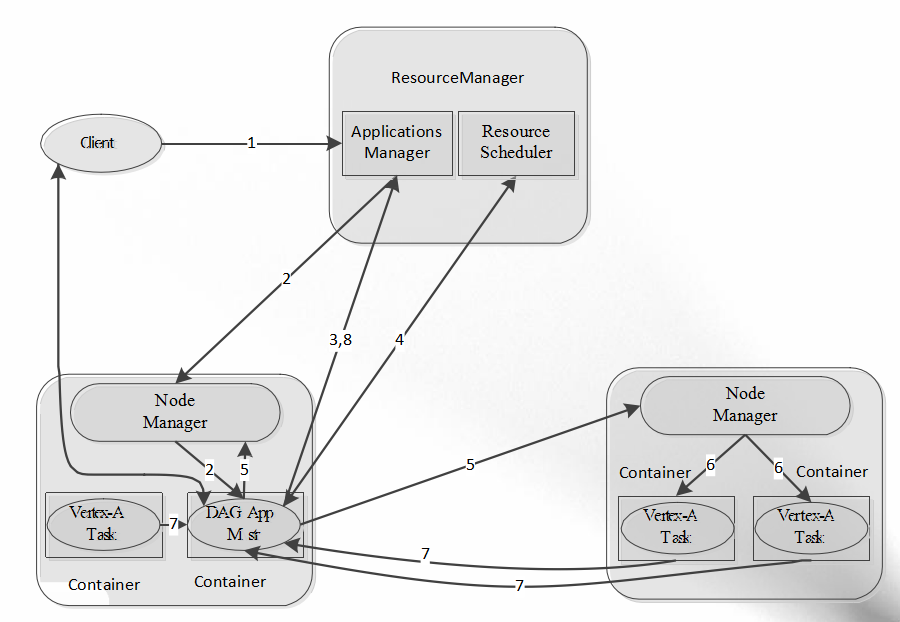
【2】DAG计算框架:Tez
- 多个作业之间存在数据依赖关系,并形成一个依赖关系有向 图( Directed Acyclic Graph),该图的计算称为“DAG计算”
- Apache Tez:基于YARN的DAG计算框架
- 运行在YARN之上,充分利用YARN的资源管理和容错等功能;
- 提供了丰富的数据流(dataflow)API;
- 扩展性良好的“Input-Processor-Output”运行时模型;
- 动态生成物理数据流关系。
未使用Tez
使用Tez
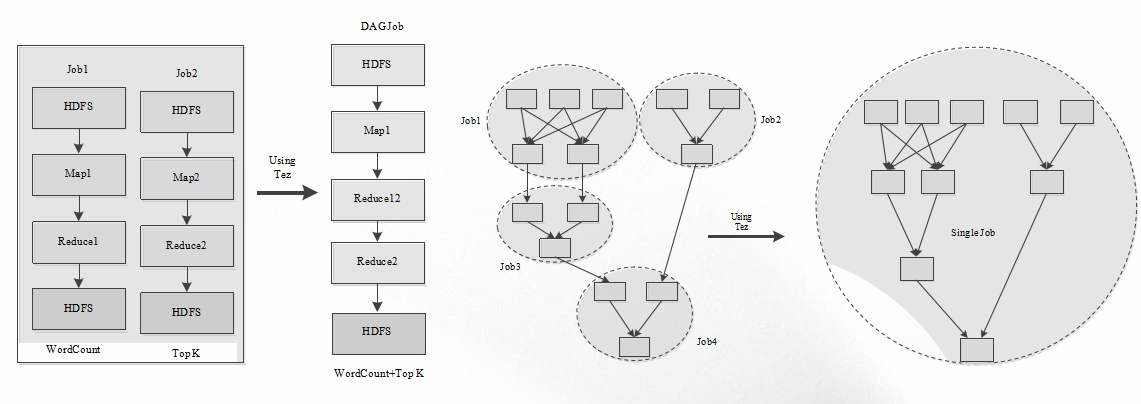
Tez 应用场景
- 直接编写应用程序
- Tez提供了一套通用编程接口
- 适合编写有依赖关系的作业
- 优化Pig、Hive等引擎
- 下一代Hive:Stinger
- 好处1:避免查询语句转换成过多的MapReduce作业后产 生大量不必要的网络和磁盘IO
- 好处2:更加智能的任务处理引擎
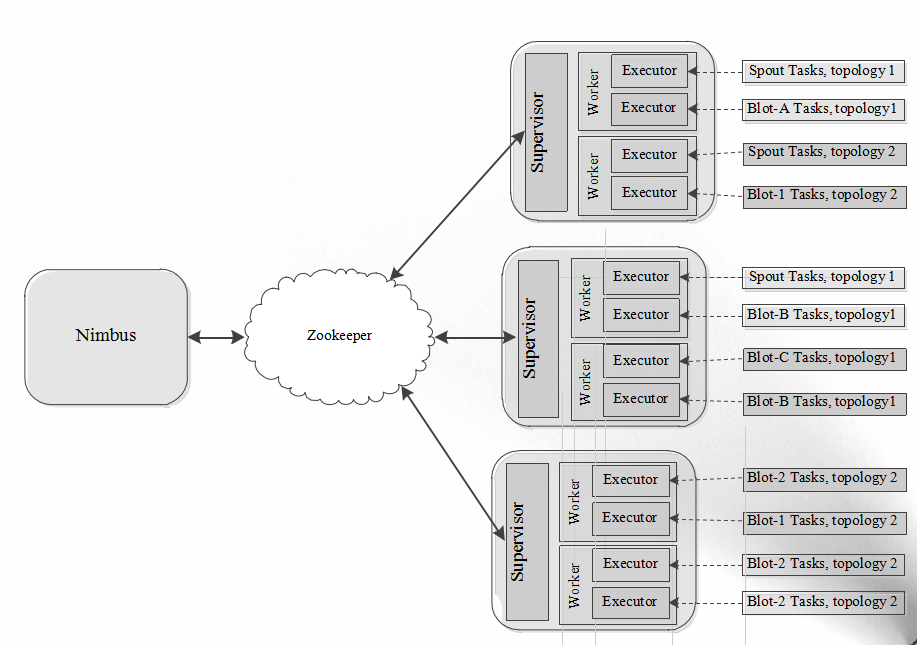
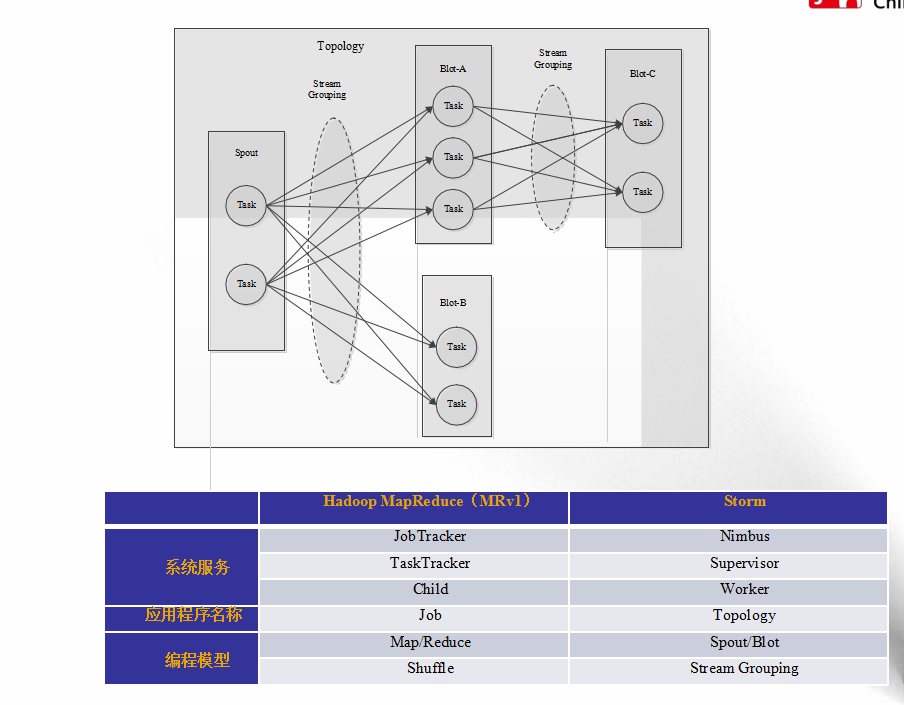
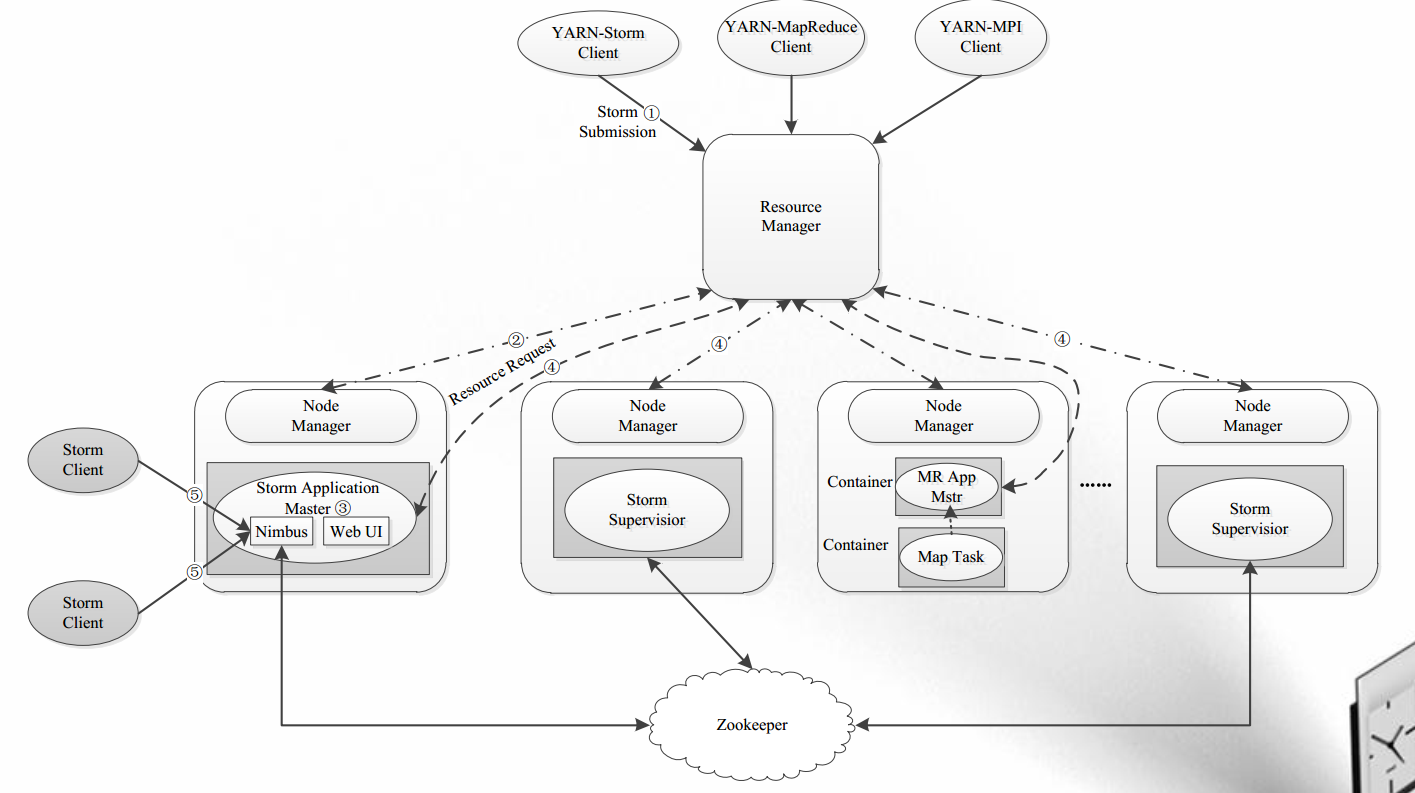
【3】流式计算框架:Storm
- 流式(Streaming)计算,是指被处理的数据像流水一样不断流入系统,而系统需要针对每条数据进行实时处理和计算,并永不停止(直到用户显式杀死进程);
- 传统做法:由消息队列和消息处理者组成的实时处理网络 进行实时计算;
- 缺乏自动化
- 缺乏健壮性
- 伸缩性差
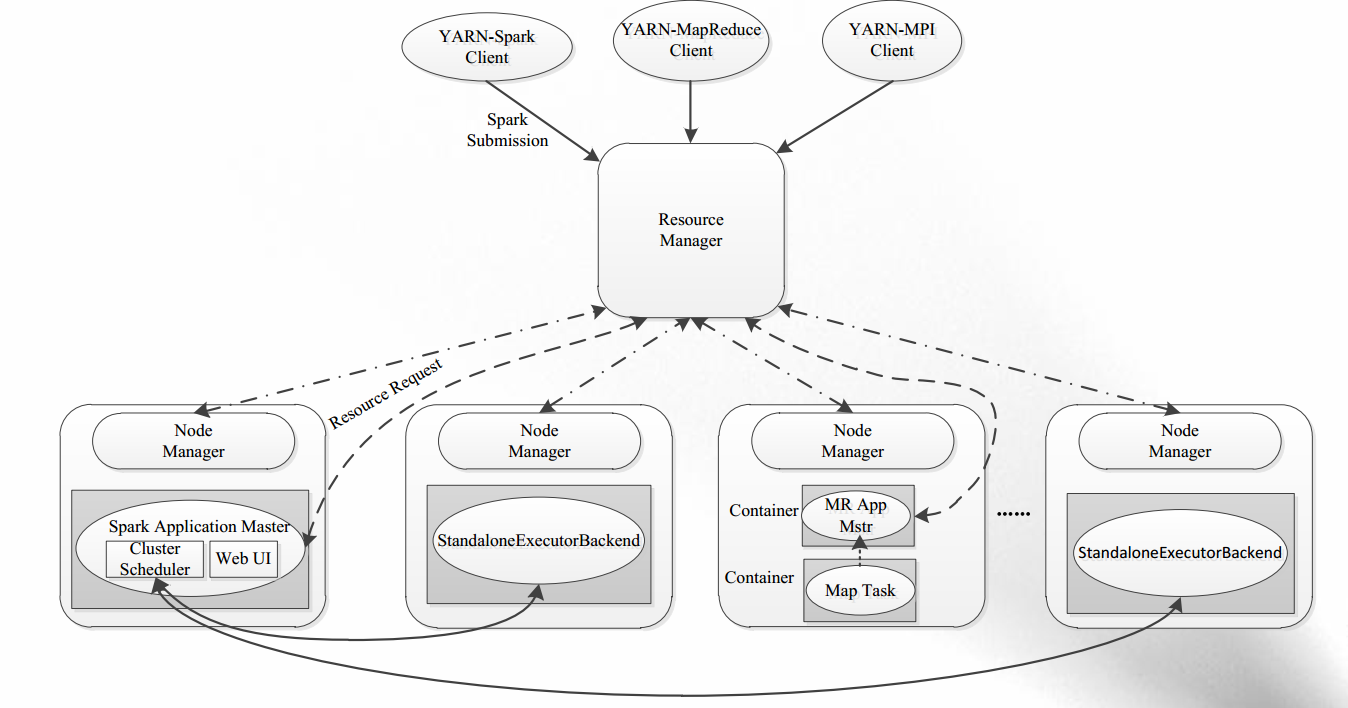
【4】内存计算框架:Spark
- 克服MapReduce在迭代式计算和交互式计算方面的不足;
- 引入RDD( Resilient Distributed Datasets)数据表示模型;
- RDD是一个有容错机制,可以被并行操作的数据集合,能够被缓存到内存或磁盘上。
spark on yarn
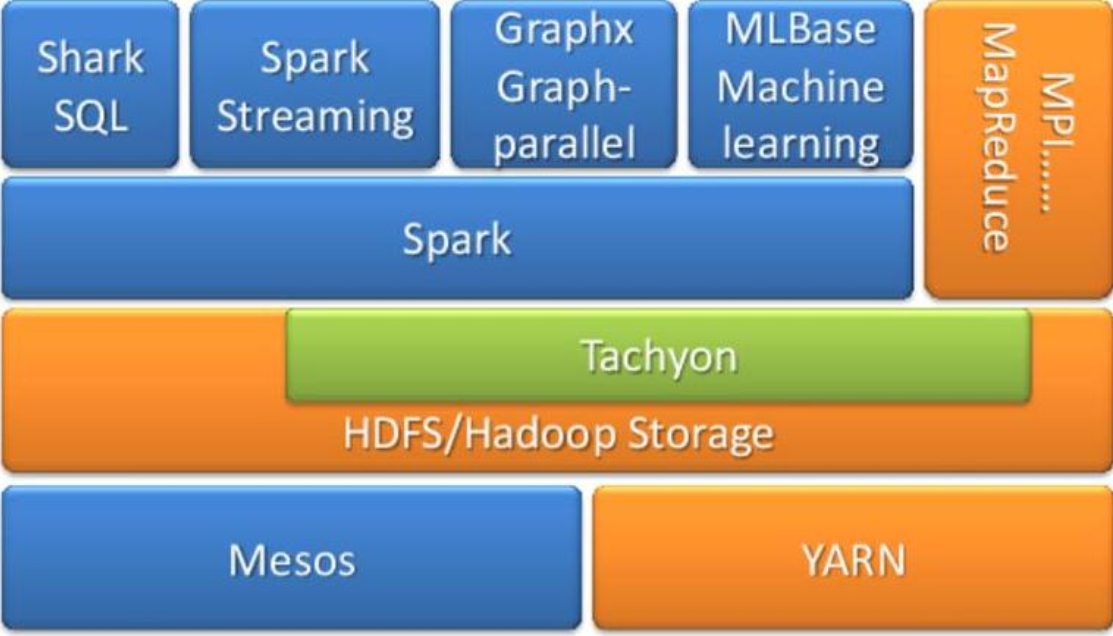
四.MapReduce 2.0与YARN
- 一个MR应用程序的成功运行需要若干模块:
- 任务管理和资源调度
- 任务驱动模块(MapTask、ReduceTask)
- 用户代码(Mapper、Reducer…)
- MapReduce 2.0和YARN区别:
- YARN是一个资源管理系统,负责资源管理和调度
- MapReduce只是运行在YARN上的一个应用程序
- 如果把YARN看做“ android”,则MapReduce只是一个“ app”
- MapReduce2.0组成:
- YARN(整个集群只有一个)
- MRAppMaster(一个应用程序一个)
- 用户代码( Mapper、 Reducer…)
- MapReduce 1.0和MapReduce 2.0区别:
- MapReduce 1.0是一个独立的系统,直接运行在Linux之上
- MapReduce 2.0则是运行YARN上的框架,且可与多种框架一起 运行在YARN上
五.总结
本博客主要介绍了YARN的产生背景,整体架构,运行在yarn上面的hadoop生态系统,最后介绍了Mapreduce2.0与YARN的区别。YARN是一个资源调度的框架和平台,可以理解为一个操作系统,在这个“操作系统上面可以安装运行N多个软件,比如storm,spark等系统,完成某一项特定的功能。YARN的功能就是为这些应用提供资源和任务调动,HDFS就相当于一块硬盘,用来存储软件系统所需要的数据。















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









