








目录
前言:
常见的数据结构分为线性表与非线表,线性表有:数组、链表、队列、栈、哈希表(hash表),非线表有:树、堆、图等。
线性表的特点:以线的方式组织数据,每个线性表中的数据最多只有头和尾两个方向。
常见的线性表如下图所示:

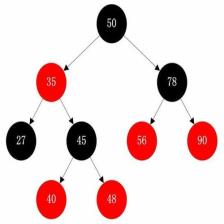
与之对应的为非线性表,数据之间不只有前后两种关系。如下图所示:

一. 数组的底层原理
数组:通过顺序存储方式将有限个相同类型的数据组织在一起的线性表数据结构。
数组的特点:最大的特点为随机读取。
1. 数组如何实现随机读取
内存存储原理简要说明:内存是由一个个连续的内存单元组成的,每一个内存单元都有自己的地址。在进行数据读取时,计算机就是通过寻址的方式找到对应的数据。这也是顺序存储能实现随机读取的直接原因。
详细Demo如下所示(引用专栏的例子):
我们拿一个长度为10的int类型的数组int[] a = new int[10]来举例。在我画的这个图中,计算机给数组a[10],分配了一块连续内存空间1000~1039,其中,内存块的首地址为base address = 1000。注意:数组在内存单元中必须是连续存储的,不能跳过某个存储单元进行存储。

由内存存储原理知道计算机会给每个内存单元分配一个地址,计算机可通过地址来访问内存中的数据。当计算机需要随机访问数组中的某个元素时,它会首先通过下面的寻址公式,计算出该元素存储的内存地址。
a[i]_address = base_address + i * data_type_size其中 data_type_size 表示数组中每个元素的大小。我们举的这个例子里,数组中存储的是int类型数据,所以 data_type_size 就为4个字节。
这里我要特别纠正一个"错误" 。我在面试的时候,常常会问数组和链表的区别,很多人都回答说, "链表适合插入、删除,时间复杂度O(1); 数组适合查找,查找时间复杂度为O(1)"实际上,这种表述是不准确的。数组是适合查找操作,但是查找的时间复杂度并不为O(1)。即便是排好序的数组,你用二分查找,时间复杂度也是O(logn),所以,正确的表述应该是,数组支持随机访问,根据下标随机访问的时间复杂度为O(1)。
上文讲述的顺序存储定义如下:
顺序存储:在计算机中用一组地址连续的存储单元依次存储线性表的各个数据元素,这些元素之间紧密排列,即不能打乱元素的存储顺序也不能跳过某个存储单元进行存储。这也是为什么数组在创建时要指定大小的原因了。如下图所示:

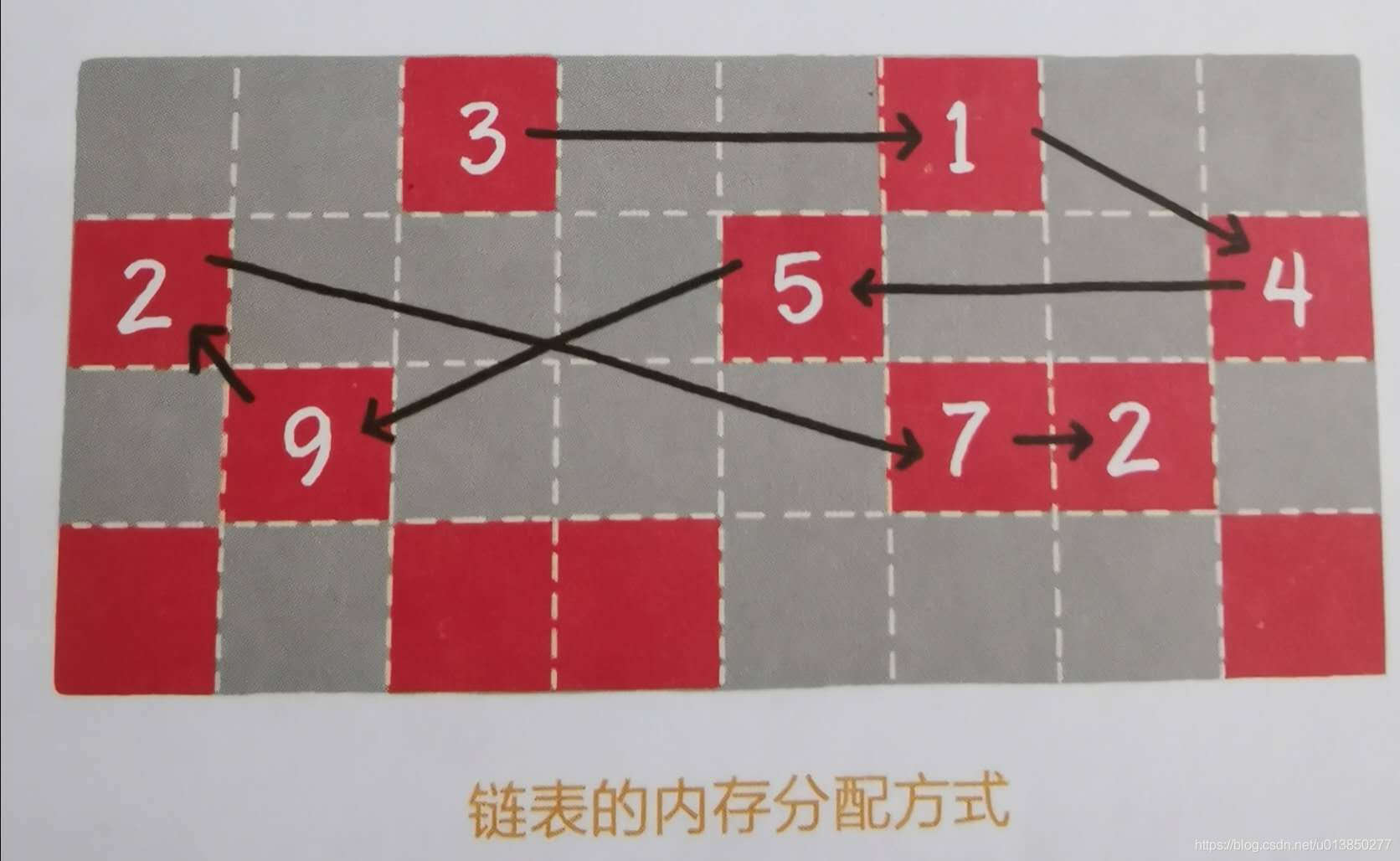
链式存储:(也可叫随机存储):在计算机中用一组任意的存储单元随机存储数据元素(这组存储单元可以是连续的,也可以是不连续的)。如下图链表通过见缝插针的方式,通过next节点灵活有效地利用零散的碎片空间。
2. 顺序存储的优缺点
优点:无需为表示表中数据之间的逻辑关系额外添加存储空间,例如链表需要额外空间存储数据与数据之间的指向。
方便通过数组下标实现快速随机读取。
缺点:数据的内存空间需要连续存储,故在删除或插入数据时需要移动元素;
同理链式存储的优缺点刚好与顺序存储的相反。总的来说,数组适合应用在读操作多,写操作少的场景中。
二. 数组的基本操作
读取元素:由于数组在内存中是顺序存储的,因此其通过下标的方式可实现时间复杂度为O(1)的高效随机读取。
更新操作:更新操作也与读取操作类似,通过下标随机读取的方式获取到对应的数据,再直接把新值赋给其便可。
插入操作:插入操作一般分为尾部插入、中间插入、超范围插入。
尾部插入:当对数组进行尾部插入时,当数组中还有空间,无需移动数据便可实现插入数据,等同于更新元素,因此对应的时间复杂度为O(1);
中间插入:由于数组在内存中是顺序存储的,因此为了保持这一特性,需将插入位置及其后面的元素全部往后移,因此对应的时间复杂度为O(n);
超范围插入:由于数组在初始化时就设置了大小,因此超范围插入时,数组需要进行扩容,扩容就需要重新为数组开辟一个更大的内存空间,此时需要将原数组全部copy到新的内存块,故此操作的时间复杂度为O(n)。由此可知插入操作,最好的时间复杂度为O(1), 最差为O(n),故其平均时间复杂度为O(n);
删除操作:同插入操作类似,如果删除的元素位于数组中间,其后的元素需要往前移一位,故其时间复杂度为O(n)。
删除操作的优化:
在数组时行删除操作时,只是将数据打上删除标记,此时并不进行真正的数据删除,因此这时不用进行数据的搬移。当内存空间不够的情况再一并将删除标记的元素进行一次性删除,这就大大减少了删除操作搬移数据的次数了。温馨提示:这也正是 JVM 标记清除垃圾回收算法的核心思想。
还有一种方式是当进行元素删除时,将数组中最后一位元素复制到删除元素的位置,然后清空最后一位元素的值,但这不是数组元素删除的主流方法,只供学习思路。
三. 数组常见的操作方法
温馨提示可结合LeetCode来实战练习
引用小灰漫画中的示例代码:
package chapter2.part1;
/**
* Created by weimengshu on 2018/8/24.
*/
public class MyArray {
private int[] array;
private int size;
public MyArray(int capacity){
this.array = new int[capacity];
size = 0;
}
/**
* 数组插入元素
* @param element 插入的元素
* @param index 插入的位置
*/
public void insert(int element, int index) throws Exception {
//判断访问下标是否超出范围
if(index<0 || index>size){
throw new IndexOutOfBoundsException("超出数组实际元素范围!");
}
//如果实际元素达到数组容量上限,数组扩容
if(size >= array.length){
resize();
}
//从右向左循环,逐个元素向右挪一位。
for(int i=size-1; i>=index; i--){
array[i+1] = array[i];
}
//腾出的位置放入新元素
array[index] = element;
size++;
}
/**
* 数组扩容
*/
public void resize(){
int[] arrayNew = new int[array.length*2];
//从旧数组拷贝到新数组
System.arraycopy(array, 0, arrayNew, 0, array.length);
array = arrayNew;
}
/**
* 数组删除元素
* @param index 删除的位置
*/
public int delete(int index) throws Exception {
//判断访问下标是否超出范围
if(index<0 || index>=size){
throw new IndexOutOfBoundsException("超出数组实际元素范围!");
}
int deletedElement = array[index];
//从左向右循环,逐个元素向左挪一位。
for(int i=index; i<size-1; i++){
array[i] = array[i+1];
}
size--;
return deletedElement;
}
/**
* 输出数组
*/
public void output(){
for(int i=0; i<size; i++){
System.out.println(array[i]);
}
}
public static void main(String[] args) throws Exception {
MyArray myArray = new MyArray(4);
myArray.insert(3,0);
myArray.insert(7,1);
myArray.insert(9,2);
myArray.insert(5,3);
myArray.insert(6,1);
myArray.insert(8,5);
myArray.delete(3);
myArray.output();
}
}
四. 可否用容器替代数组
这里以Java ArrayList容器ArrayList来分析其与数组的关系,ArrayList是否可替代数组
很多语言都提供了容器类来更加方便地进行数组类型的数据结构进行操作,例如Java中有ArrayList容器,
其可自动实现动态扩容(注意:就像是ArrayList容器的动态扩容实际也是需要像数组那样将大量数据进行复制的,
因此相对来说这一操作是很耗性能的)以及封装好了相关增删api,如果有兴趣可查看其对应的源码会发现其实底层也是封装了数组的相关操作,比如如下代码就是 ArrayList 删除指定下标元素的部分源码。
Java中的一个数组拷贝内容到另一个数组经常使用System.arraycopy()方法,但是查看源代码可以发现该方法声明为native,也就是说是本地方法,不是用Java写的。如需要看其源码可以通过比较麻烦,我们知道其是整块复制便可。

那么如何选择使用容器还是数组呢?
- 1. 像ArrayList存储的只能是对象,如希望存储基本类型数据,可选用数组;
- 2. 事先知道数据大小,并且操作简单,可选用数组;
- 3. 直观表示多维,可选用数组;
- 4. 业务开发,使用容器足够,开发框架,追求性能,优先考虑数组。
总的来说,如果不是对性能要求特别高的,用容器开发更加方便。
五. 数组为啥在很多语言中都是以0为开始下标呢
第一个原因:数组是通过寻址公式计算出该元素存储的内存地址:
a[i]_address = base_address + i * data_type_size如上公式如果数组是从 1 开始计数,那么就会变成:
a[i]_address = base_address + (i-1)* data_type_size对于CPU来说,多了一次减法的指令。
第二个原因:有一定的历史原因,很多语言用C语言衍生而来,而C的数组下标也是以0开始的,个人认为这是主要原因。
注:该系列博文为笔者学习《数据结构与算法之美》的个人笔记小结















 631
631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









