







简介
这篇文章主要讲解 Sync.Cond和Sync.Rwmutex
Sync.Cond
简介 sync.Cond 经常用来处理 多个协程等待 一个协程通知 这种场景, 主要 是阻塞在某一协程中 等待被另一个协程唤醒 继续执行 这个协程后续的功能。cond经常被用来协调协程对某一资源的访问 ants协程池就用了这种机制
本文主要讲解Cond 的源码 ,关于其使用已经有许多例子了 本文直接略过
cond 的结构体如下
type Cond struct {
noCopy noCopy // 告诉编译器 本结构体不能复制
// L is held while observing or changing the condition
L Locker
notify notifyList // 在 Wait 上阻塞的线程 这边只记录 阻塞携程的 指针 真正阻塞是调用的GMP模型 相关功能
checker copyChecker // 复制检查
}
//使用时 需要 新建一个Cond变量 入参必须有一个锁 用来 锁定 Cond 的 Wait()调用所涉及的资源
func NewCond(l Locker) *Cond {
return &Cond{L: l}
}
其 主要有三个函数 如下
Wait()
用来阻塞 协程
其源码如下
func (c *Cond) Wait() {
c.checker.check() // 复制检查
t := runtime_notifyListAdd(&c.notify) // 等待数量+1; 其使用了 汇编的 LOCK 命令来实现加1的原子性操作
c.L.Unlock() // 解锁 ;Wait()代码调用之前必须有 Lock ,可以看到 锁c.L 的作用域直接到了这里
// 因为 Wait() 一般用在 协程中 且共享内存(也就是变量等)
runtime_notifyListWait(&c.notify, t) // 所有协程都阻塞在这里; 大概功能是 首先将本协程指针放入notifyList等待队列
// 然后进行GMP模型调度 释放当前M 将当前 G指针加入等待队列等待被唤醒 M开始等待可用的G
// 所以 g指针存在于两个地方 一个 notifyList 列表 一个 等待队列 这样方便唤醒
c.L.Lock() // 解锁
}
实现wait 效果的 是 runtime_notifyListWait(…)函数 我们来研究下 其代码位置是 runtime/runtime2.go/notifyListWait
源码如下
func notifyListWait(l *notifyList, t uint32) {
// 上锁 细节可以自行研究
lockWithRank(&l.lock, lockRankNotifyList)
// Return right away if this ticket has already been notified.
if less(t, l.notify) {
unlock(&l.lock)
return
}
// Enqueue itself.
// sudog 是某个协程的 阻塞状态信息
s := acquireSudog()
// 获取当前协程的指针
s.g = getg()
// 可以看做 当前协程在 等待列表中的索引
s.ticket = t
s.releasetime = 0
t0 := int64(0)
if blockprofilerate > 0 {
t0 = cputicks()
s.releasetime = -1
}
// 将协程信息 插入 尾部
if l.tail == nil {
l.head = s
} else {
l.tail.next = s
}
l.tail = s
// 这里涉及到 GMP模型调度 大概功能是 释放当前M 将当前 G加入等待队列等待被唤醒 M开始等待可用的G
goparkunlock(&l.lock, waitReasonSyncCondWait, traceBlockCondWait, 3)
if t0 != 0 {
blockevent(s.releasetime-t0, 2)
}
// 释放当前 sudog结构体
releaseSudog(s)
}
Signal()
唤醒 某一个 调用 Wait()阻塞的协程 继续执行其后续代码
其源码如下
func (c *Cond) Signal() {
c.checker.check()
runtime_notifyListNotifyOne(&c.notify) // link runtime/sema.go/notifyListNotifyOne
// notifyListNotifyOne 主要使用了GMP调度器的唤醒功能(runtime/proc.go/goready(...)):从notifyList获取某个需要唤醒的g协程指针,
// 使用GMP调度算法 唤醒这个g协程
// 将它(g)放入(使用M 操作)运行队列中 必要时唤醒处理器(p)处理这个协程
}
其中runtime_notifyListNotifyOne的唤醒功能使用的是 GMP调度算法 的 ready 调用链 如下
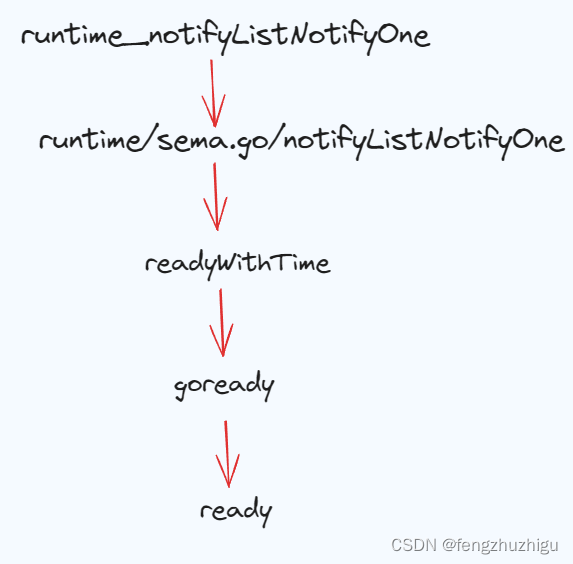
ready源码如下
func ready(gp *g, traceskip int, next bool) {
if traceEnabled() {
traceGoUnpark(gp, traceskip)
}
// 获取 当前协程状态
status := readgstatus(gp)
// Mark runnable.
// 获取当前协程 所属的 M
mp := acquirem() // disable preemption because it can be holding p in a local var
if status&^_Gscan != _Gwaiting {
dumpgstatus(gp)
throw("bad g->status in ready")
}
// status is Gwaiting or Gscanwaiting, make Grunnable and put on runq
// 将当前协程状态 由等待中 变为可运行
casgstatus(gp, _Gwaiting, _Grunnable)
// 通过 M 将协程 G 放入可运行队列
runqput(mp.p.ptr(), gp, next)
// 唤醒一个 P
wakep()
releasem(mp)
}
可以看到 这段代码 有了我们熟悉的G、M 和P
Broadcast()
唤醒所有 调用 Wait()阻塞的协程 继续执行其后续代码
其源码如下
func (c *Cond) Broadcast() {
c.checker.check()
runtime_notifyListNotifyAll(&c.notify) // 主要功能跟 runtime_notifyListNotifyOne 一样 但这个函数 调用的for循环 遍历 整个notifyList列表 唤醒所有协程
}
其底层也就相当 for 循环 执行 了 ready函数
Sync.Rwmutex
读写锁 是为了 解决 mutex的严格互斥的缺点,读读可以并发、读写有条件互斥、写写严格互斥
有争议的就是 读写有条件互斥 这是什么意思呢 我们首先 介绍下 读和写的两种优先模式
- 读写时 读优先
只要有读操作来写操作就阻塞,一直到没有读操作为止,可能会造成写锁饥饿, 这种适合读操作远远大于写操作的场景 - 读写时 写优先
写操作来时 后续的读操作全部阻塞 但是 写操作前的读操作需要完成
rwmutex 就是采用写优先 所以 有条件互斥 是 写之前的读操作 可以继续完成 写之后的读操作就需要阻塞了
接下来我们来看源码
RWMutex 结构体如下:
type RWMutex struct {
w Mutex // held if there are pending writers // 当有写操作挂起时 起作用 控制写操作的时 悲观锁
writerSem uint32 // semaphore for writers to wait for completing readers // 写操作等待完成读操作的信号量
readerSem uint32 // semaphore for readers to wait for completing writers // 读操作等待完成写操作的信号量
readerCount atomic.Int32 // number of pending readers // 当前挂起的读操作数,也就是写操作之前和之后发生的 在执行中的总的读操作。readerCount 并发安全 使用 Lock 锁总线
readerWait atomic.Int32 // number of departing readers // 比写操作早到的读操作的数量 执行了 RLock() 但是没执行 RUnlock
// 执行链路 Rlock--->Lock()-->Runlock()
}
其重要的 函数有四个 RLock()、Runlock()、Lock()、Unlock(),其中前两个是控制读操作的,后两个控制写。
- RLock():根据一定条件来使得读协程阻塞
- Runlock():根据一定条件来唤醒写协程
- Lock(): 根据一定条件来阻塞写协程
- Unlock():根据一定条件来唤醒其后到达的读协程 并释放写锁
我们分别来看下其代码:
RLock()
func (rw *RWMutex) RLock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
if rw.readerCount.Add(1) < 0 { // 小于0 证明前方有写操作(因为写操作会首先readerCount置为小于0) 则后来的读操作阻塞
// A writer is pending, wait for it.
runtime_SemacquireRWMutexR(&rw.readerSem, false, 0) // 写之后的读操作阻塞,采用GMP模型 中的功能 将当前G 睡眠 释放 M
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
}
}
Runlock()
func (rw *RWMutex) RUnlock() { // 执行这个函数 有两种情况
if race.Enabled {
_ = rw.w.state
race.ReleaseMerge(unsafe.Pointer(&rw.writerSem))
race.Disable()
}
if r := rw.readerCount.Add(-1); r < 0 { // 挂起的数量-1 如果挂起的协程数量是负数 说明 有写操作阻塞 则需要检查是否唤起写操作
// 如果r>=0 : 可能是 Rlock-->Runlock() --->Lock()-->Unlock() 这种情况 readerCount不为负值
// Outlined slow-path to allow the fast-path to be inlined
// r<0 开始递减 在写操作之前挂起的读操作数 也就是 readerWait 数 什么情况下会造成这种情况呢 在写操作之前执行 这种情况是 执行完毕 Rlock() 后 写操作 Lock() Runlock()
// 也就是 Rlock--->Lock()-->Runlock() 这种顺序 这种情况会造成 readerCount为负值
rw.rUnlockSlow(r)
}
if race.Enabled {
race.Enable()
}
}
其中 rw.rUnlockSlow( r)的作用是 readerWait数量-1 达到条件后 唤醒写操作 代码如下
func (rw *RWMutex) rUnlockSlow(r int32) {
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
race.Enable()
fatal("sync: RUnlock of unlocked RWMutex")
}
// A writer is pending.
if rw.readerWait.Add(-1) == 0 { // 写之前的读协程数量-1
// The last reader unblocks the writer. // 写之前的最后一个 读操作 解锁 写操作
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
Lock()
func (rw *RWMutex) Lock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// First, resolve competition with other writers.
rw.w.Lock() // 将写操作跟其他写操作 进行互斥
// Announce to readers there is a pending writer.
r := rw.readerCount.Add(-rwmutexMaxReaders) + rwmutexMaxReaders // 将 readerCount 置为负数 用于阻塞后续 读操作;r是readerCount原始值
// Wait for active readers.
if r != 0 && rw.readerWait.Add(r) != 0 { // 将现有 写协程之前的读数量 加入到 等待数量中去 翻译成人话 比写操作早到的 读操作数量 如果不是0 也就是大于0 则写操作需要挂起
runtime_SemacquireRWMutex(&rw.writerSem, false, 0) // 写协程挂起;GMP 模型 G进入等待队列休眠 M释放 注意:这里是获得写锁的协程睡眠
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
race.Acquire(unsafe.Pointer(&rw.writerSem))
}
}
其中 const rwmutexMaxReaders = 1 << 30 为什么是这个数 不是 1<<31-1
解答:readerCount 高31位表示是否有写锁,高32表示是否有写锁在等待 则最大就是 1<<30-1 为了使得 其操作后为确定为负数 所以取值 1<<30
Unlock()
func (rw *RWMutex) Unlock() {
if race.Enabled {
_ = rw.w.state
race.Release(unsafe.Pointer(&rw.readerSem))
race.Disable()
}
// Announce to readers there is no active writer.
r := rw.readerCount.Add(rwmutexMaxReaders) // 将readerCount 还原为原始值 说明没有 写操作了,这时 其值是 写操作后续的读操作
if r >= rwmutexMaxReaders {
race.Enable()
fatal("sync: Unlock of unlocked RWMutex")
}
// Unblock blocked readers, if any.
for i := 0; i < int(r); i++ { // 将读操作挨个唤醒
runtime_Semrelease(&rw.readerSem, false, 0)
}
// Allow other writers to proceed.
rw.w.Unlock() // 允许其他的写操作继续拥有锁
if race.Enabled {
race.Enable()
}
}
无论是mutex还是rwmutex 其代码量都不大 但是逻辑都比较复杂 需要反复研读大神的代码
下面我们来看下 各种情况的 readCount 和 readWait 的数量 如下图
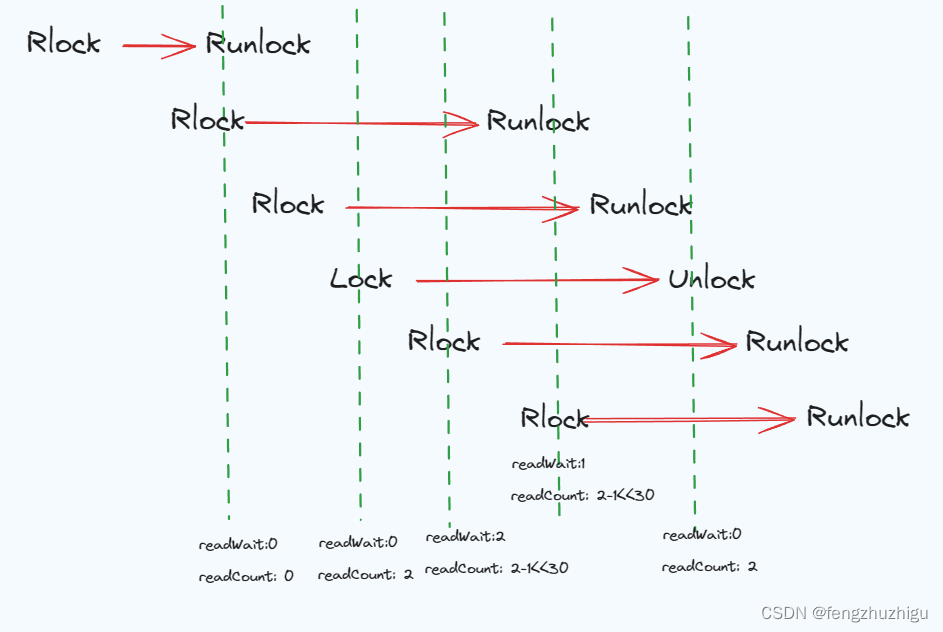
大家思考下 引入 rwmutex时能不能仅仅使用RLock()和Runlock()或者Lock()和Unlock()















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









