







Collection框架介绍
1.概述
java为用户提供了方便的集合操作类,这些集合类是各类数据结构的实现,例如链表,队列,堆栈等,有了这些集合类,用户可以很方便的在内从中操作数据。
Collection接口是我们要介绍的集合框架的核心接口,在这个接口中定义了集合的本质特性。而本次我们重点关注它的两个子接口:
-. LiST
-. Set
-. Queue(以后再讨论)
2.List接口
List接口是对Collection接口的扩展,其实现类可以存放有序,可重复的数据元素。其重要的实现类:
-. ArraryLiST
-. LinkedList
-. Vector
下面主要来讨论一下这几类:
(1)ArraryList
ArrayList其实是实现了一个按需增长的动态数组,当新建一个ArrayList对象时,如果没有指定大小,那么它实际上是创建了一个默认大写的对象数组,默认大小是10(从源码中分析得出),当对这个集合对象添加数据元素时,如果超出了其内部的数组的大小,那么这个数组会自动扩容,每次扩容的数量为原来容量的1.5倍,这大概就是ArrayList的基本实现原理了。
(2)LinkedList
LinkedList是个双向链表,它同样可以被当作栈、队列或双端队列来使用。
(3)两者区别
- ArrayList是实现了基于动态数组的数据结构,而LinkedList是基于链表的数据结构;
- 对于随机访问get和set,ArrayList要优于LinkedList,因为LinkedList要移动指针;
- 对于添加和删除操作add和remove,一般大家都会说LinkedList要比ArrayList快,因为ArrayList要移动数据。
总结:
ArrayList和LinkedList在性能上各有优缺点,都有各自所适用的地方,总的说来可以描述如下:
1.对ArrayList和LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对 ArrayList而言,主要是在内部数组中增加一项,指向所添加的元素,偶尔可能会导致对数组重新进行分配;而对LinkedList而言,这个开销是 统一的,分配一个内部Entry对象。 但是向ArrayList添加数据时,如果超出了其容量,其会自动扩容,这个过程是很消耗性能的
2.在ArrayList的 中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在LinkedList的中间插入或删除一个元素的开销是固定的。
3.LinkedList不支持高效的随机元素访问。
4.ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
可以这样说:当操作是在一列数据随机查询比较多时使用ArrayList会提供比较好的性能;当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
所以,如果只是查找特定位置的元素或只在集合的末端增加、移除元素,那么使用Vector或ArrayList都可以。如果是对其它指定位置的插入、删除操作,最好选择LinkedList
(2)Vector
&emsp:对于Vector,它是jdk1.0就留下来的,它和ArrayList是类似的,不同点就是,它是线程安全的,在多线程的环境下使用其可能有好处,但是非多线程情况下使用效率会很低。
3.Set接口
Set接口所描述的集合是不可重复的集合,其中我们主要了解它的两个实现类:
-. HashSet
-. LinkedHashSet
-. TreeSet
(1)HashSet
HashSet是基于HashMap实现的,底层都是使用的HashMap中方法,是通过数组和链表来实现对数据的存储(1.8加入了红黑树,当链表过长的时候就使用红黑树)。存储过程就是将要存储的元素作为HashMap的KEY存储,而value统一存储为一个虚拟的Object对象。所以在存储元素时需要遵循HashMap存储key的规则。使用HashSet存储数据元素需要注意一点,它存储数据内部是基于对象的hashCode方法和eques方法的,基本类和String类都实现了这两个方法,而如果要将自定义对象存到HashSet中时就必须让自定义类也实现hashCode和eques方法。具体过程是这样的:
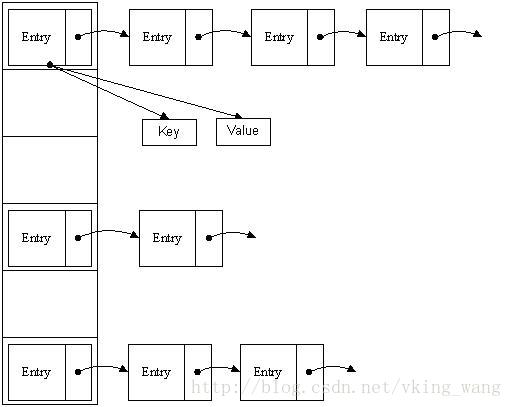
当存储一个对象时,会调用这个对象的hashCode方法得到这个对象hash值,然后通过高位运算和取模运算得到这个对象的存储位置,如果这个存储位置上已经有值了,这种情况是可能发生的,也就是两个对象的hash值是相同,这时就会调用equals方法比较两个值是否相等,如果相等,就不作存储,如果不相等就存储在同一个数组地址链表上。其数据结构如图所示:
(2)TreeSet
这里必须提到,与HashSet类似,TreeSet也是基于TreeMap实现的,不同的是它是有序的,关于它的实现用到了红黑树这种数据结构,所以,当需要向TreeSet中存储对象时,这个对象必须实现Comparable接口,并复写里面的comparaTo方法,TreeSet就是根据这个来排序的。或者在新建TreeSet对象的时候,传入一个特定的比较器,这样它就知道根据什么进行排序了。
(3)LinkedHashSet
LinkedHashSet也是基于LinkedHashMap实现的,它时HashSet的子类,它的实现过程就是HashSet加双向链表的结构,也就是说其内部又加入了一个链表结构,可以记录其插入顺序,所以其是有序的,遍历的时候会按照插入顺序进行遍历。















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









