







第十三天
随机森林
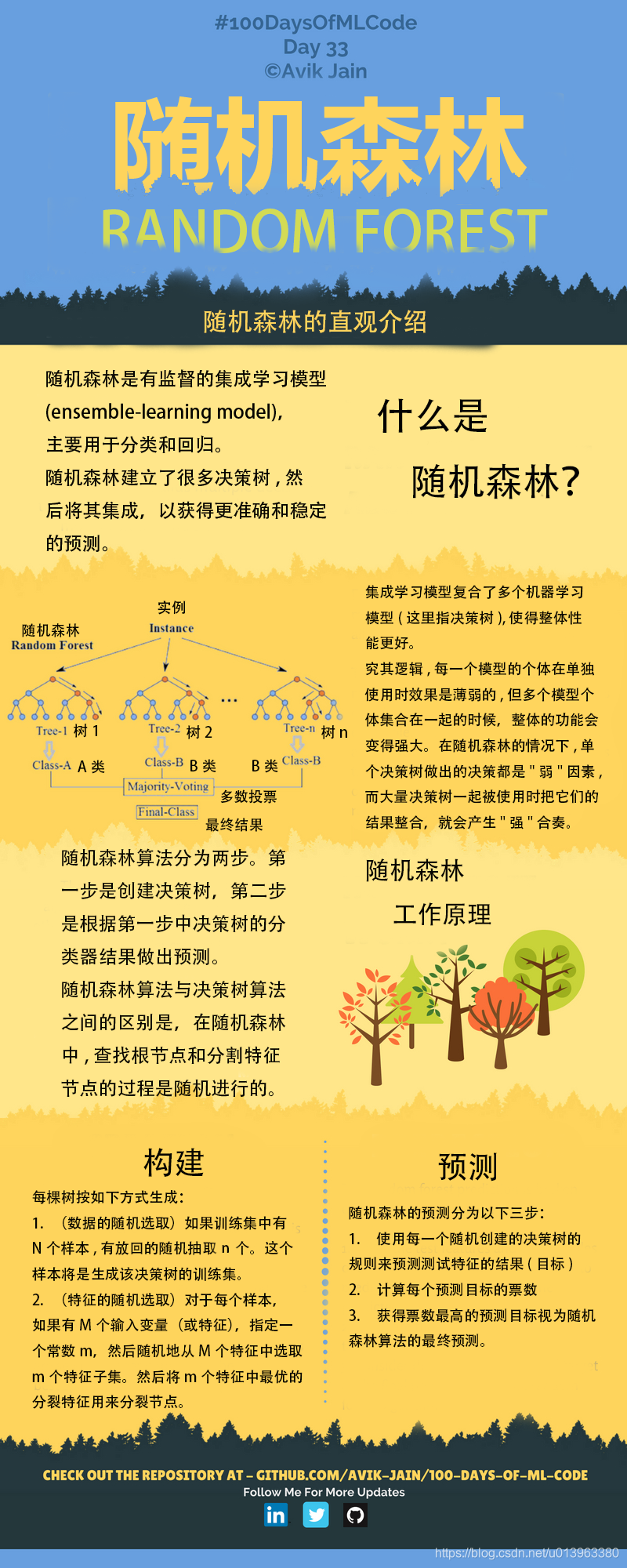
随机森林是有监督学习的集成学习模型,主要用于分类和回归。随机森林集成了很多的决策树模型,然后将其每颗树的预测结果组合以获得更加准确和稳定的预测结果。
第一步:导入库并加载数据集
import numpy as np
import pandas as pd
dataset = pd.read_csv('../datasets/Socail_Network_Ads.csv')
X = dataset.iloc[ : , [2, 3]].values
Y = dataset.iloc[ : , 4].values
---------------------------------------------------------
打印数据集查看结果
print(X[0])
print(Y[0])
第二步:划分数据集
from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.25, random_state = 0)
第三步:特征缩放
from sklearn.preprocessing import StandardScaler sc = Stand
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









