







 本文详细介绍了MapReduce的输入处理,包括InputFormat类、InputSplit类、RecordReader类的功能和实现,以及如何处理Hadoop的"小文件"问题。通过Hadoop Archive、Sequence file和CombineFileInputFormat三种策略解决小文件带来的效率问题。此外,还讨论了输入过滤和Mapper的工作流程。
本文详细介绍了MapReduce的输入处理,包括InputFormat类、InputSplit类、RecordReader类的功能和实现,以及如何处理Hadoop的"小文件"问题。通过Hadoop Archive、Sequence file和CombineFileInputFormat三种策略解决小文件带来的效率问题。此外,还讨论了输入过滤和Mapper的工作流程。
类图
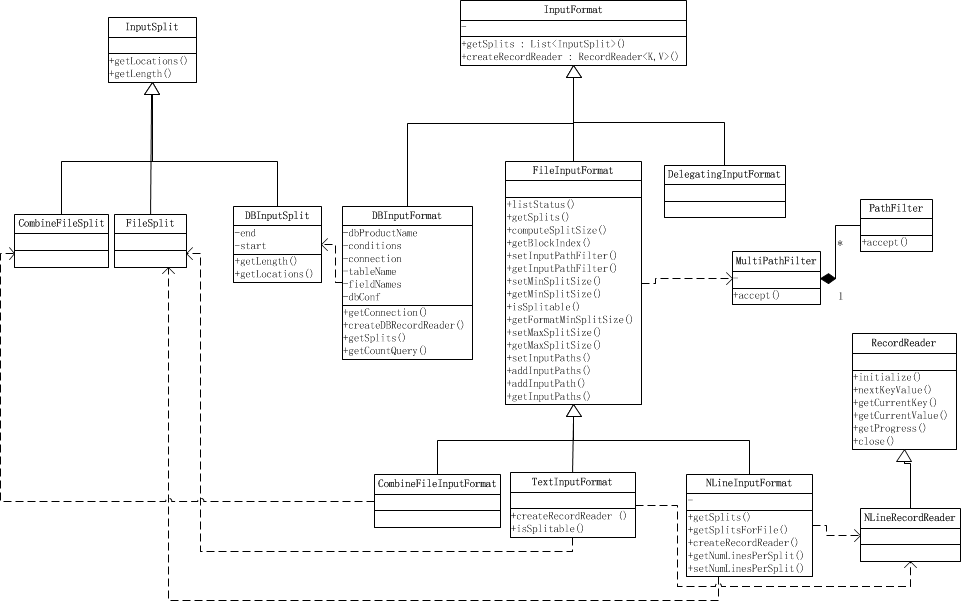
1. InputFormat类
MapReduce作业的输入数据的规格是通过InputFormat类及其子类给出的。有以下几项主要功能:
- 输入数据的有效性检测。
- 将输入数据切分为逻辑块(InputSplit),并把他们分配给对应的Map任务。
- 实例化一个能在每个InputSplit类上工作的RecordReader对象,并以键-值对方式生成数据,这些K-V对将由我们写的Mapper方法处理。
| 派生类 | 说明 |
|---|---|
| FileInputFormat | 从HDFS中获取输入 |
| DBInputFormat | 从支持SQL的数据库读取数据的特殊类 |
| CombineFileInputFormat | 将对各文件合并到一个分片中 |
其中TextInputFormat是Hadoop默认的输入方法,而这个是继承自FileInputFormat的。之后,每行数据都会生成一条记录,每条记录则表示成
public abstract class InputFormat<K, V> {
/**
* 仅仅是逻辑分片,并没有物理分片,所以每一个分片类似于这样一个元组 <input-file-path, start, offset>
*/
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
/**
* Create a record reader for a given split.
*/
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
}FileInputFormat子类
分片方法代码及详细注释如下:
public List<InputSplit> getSplits(JobContext job) throws IOException {
// 首先计算分片的最大和最小值。这两个值将会用来计算分片的大小。
// 由源码可知,这两个值可以通过mapred.min.split.size和mapred.max.split.size来设置
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// splits链表用来存储计算得到的输入分片结果
List<InputSplit> splits = new ArrayList<InputSplit>();
// files链表存储由listStatus()获取的输入文件列表
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
// 获取该文件所有的block信息列表[hostname, offset, length]
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
// 判断文件是否可分割,通常是可分割的,但如果文件是压缩的,将不可分割
// 是否分割可以自行重写FileInputFormat的isSplitable来控制
if (isSplitable(job, path)) {
// 计算分片大小
// 即 Math.max(minSize, Math.min(maxSize, blockSize));
// 也就是保证在minSize和maxSize之间,且如果minSize<=blockSize<=maxSize,则设为blockSize
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
// 循环分片。
// 当剩余数据与分片大小比值大于Split_Slop时,继续分片, 小于等于时,停止分片
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
// 处理余下的数据
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
// 不可split,整块返回
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
// 对于长度为0的文件,创建空Hosts列表,返回
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
// 设置输入文件数量
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
return splits;
}2. InputSplit类
抽象类InputSplit及其派生类有以下几个主要属性:
- 输入文件名。
- 分片数据在文件中的偏移量。
- 分片数据的长度(以字节为单位)。
- 分片数据所在的节点的位置信息。
在HDFS中,当文件大小少于HDFS的块容量时,每个文件将创建一个InputSplit实例。而对于被分割成多个块的文件,将使用更复杂的公式来计算InputSplit的数量。
基于分片所在位置信息和资源的可用性,调度器将决定在哪个节点为一个分片执行对应的Map任务,然后分片将与执行任务的节点进行通信。
InputSplit源码
public abstract class InputSplit {
/**
* 获取Split的大小,支持根据size对InputSplit排序.
*/
public abstract long getLength() throws IOException, InterruptedException;
/**
* 获取存储该分片的数据所在的节点位置.
*/
public abstract
String[] getLocations() throws IOException, InterruptedException;
/**
* 获取分片的存储信息(哪些节点、每个节点怎么存储等)
*/
@Evolving
public SplitLocationInfo[] getLocationInfo() throws IOException {
return null;
}
}FileSplit子类
public class FileSplit extends InputSplit implements Writable {
private Path file; // 文件路径
private long start; // 分片起始位置
private long length; // 分片长度
private String[] hosts; // 存储分片的hosts
private SplitLocationInfo[] hostInfos; // 存储分片的信息信息
public FileSplit() {}
/**
* Constructs a split with host information
*/
public  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









