







本节所有属性会被mapred-default.xml或mapred-site.xml文件中设定的该属性值覆盖。
1. dfs.blocksize属性
HDFS文件的块默认容量可以被配置文件(hdfs-site.xml)覆盖。某些情况下,Map任务可能只需要几秒时间就可以处理一个块,所以,最好让Map任务处理更大的块容量。通过以下方法达到此目的:
- 增加参数mapreduce.input.fileinputformat.split.minsize,使其大于块容量;
- 增加文件存储在HDFS中的块容量。
前者导致数据本地化问题,例如InputSplit可能会包含其他主机的块;后者能够维持数据都在本地节点,但要求重新加载HDFS中的文件。例如文件tiny.data.txt以块容量512MB的方式上传HDFS中:
hdfs dfs -D dfs.blocksize=536870912 -put province.txt /hw/hdfs/mr/task由于CPU的约束,有时可以减少fileinputformat.split.minsize属性值,使它小于HDFS的块容量,从而提高资源的利用率。
2. 中间输出结果的排序与溢出
流程图
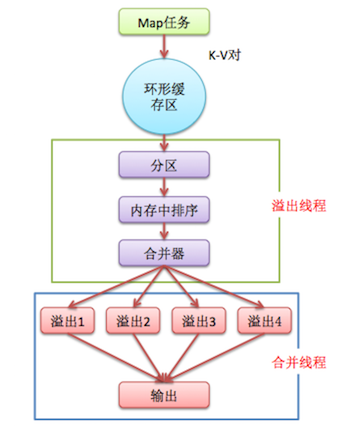
- Map任务的中间输出使用环形缓冲区缓存在本地内存(大小通过mapreduce.task.io.sort.mb设置,默认100M)。被缓冲的K-V对记录已经被序列化,但没有排序。而且每个K-V对都附带一些额外的审计信息。
- 使用率有一个软阈值(mapreduce.map.sort.spill.percent,默认0.80),当超过阈值时,溢出行为会在一个后台线程执行。Map任务不会因为缓存溢出而被阻塞。但如果达到硬限制,Map任务会被阻塞,直到溢出行为结束。
- 线程会将记录基于键进行分区(通过 mapreduce.job.partitioner.class设置分区算法的类),在内存中将每个分区的记录按键排序(通过map.sort.class指定排序算法,默认快速排序org.apache.hadoop.util.QuickSort),然后写入一个文件。每次溢出,都有一个独立的文件存储。
- Map任务完成后,缓存溢出的各个文件会按键排序后合并到一个输出文件(通过mapreduce.cluster.local.dir指定输出目录,值为${hadoop.tmp.dir}/mapred/local)。合并文件的流的数量通过mapreduce.task.io.sort.factor指定,默认10,即同时打开10个文件执行合并。
根据上面步骤,最好仅在Map任务结束的时候才能缓存写到磁盘中。
可以采用以下方法提高排序和缓存写入磁盘的效率:
- 调整mapreduce.task.io.sort.mb大小,从而避免或减少缓存溢出的数量。当调整这个参数时,最好同时检测Map任务的JVM的堆大小,并必要的时候增加堆空间。
- mapreduce.task.io.sort.factor属性的值提高100倍左右,这可以使合并处理更快,并减少磁盘的访问。
- 为K-V提供一个更高效的自定义序列化工具,序列化后的数据占用空间越少,缓存使用率就越高。
- 提供更高效的Combiner(合并器),使Map任务的输出结果聚合效率更高。
- 提供更高效的键比较器和值的分组比较器。
3. 本地Reducer和Combiner
Combiner在本地节点将每个Map任务输出的中间结果做本地聚合,即本地Reducer,它可以减少传递给Reducer的数据量。可以通过setCombinerClass()方法来指定一个作业的combiner。
mapreduce.map.java.opts参数设置Map任务JVM的堆空间大小,默认-Xmx1024m
如果指定了Combiner,可能在两个地方被调用。
- 当为作业设置Combiner类后,缓存溢出线程将缓存存放到磁盘时,就会调用;
- 缓存溢出的数量超过mapreduce.map.combine.minspills(默认3)时,在缓存溢出文件合并的时候会调用Combiner。
4. 获取中间输出结果(Map侧)
Reducer需要通过网络获取Map任务的输出结果,然后才能执行Reduce任务,可以通过下述Map侧的优化来减轻网络负载:
- 通过压缩输出结果,mapreduce.map.output.compress设置为true(默认false),mapreduce.map.output.compress.codec指定压缩方式。
- Reduce任务是通过HTTP协议获取输出分片的,可以使用mapreduce.tasktracker.http.threads指定执行线程数(默认40)。
5. 参考
《精通Hadoop》 [印] Sandeep Karanth著 刘淼等译















 1486
1486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









