







1. Spark架构
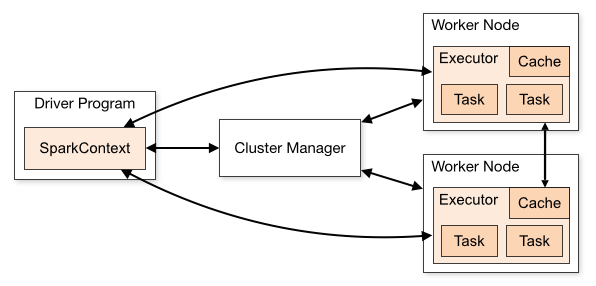
1. Driver Program
在集群模式下,用户编写的Spark程序称为Driver程序。每个Driver程序包含一个代表集群环境的SparkContext对象并与之连接,程序的执行从Driver程序开始,中间过程会调用RDD操作,这些操作通过集群资源管理器来调度执行,一般在Worker节点上执行,所有操作执行结束后回到Driver程序,在Driver程序中结束。
2. SparkContext
- SparkContext对象联系集群管理器(视部署不同而不同),分配CPU、内存等资源。
- 集群管理器在工作节点(Worker Node)上启动一个执行器(专属于本驱动程序)。
- 程序代码会被分发到相应的工作节点上。
- SparkContext分发任务(Task)至各执行器执行。
3. Cluster Manager
Spark支持3种集群部署方式:
- Standalone模式:资源管理器是Master节点。集群将以FIFO模式执行应用。默认使用所有可用节点,可以通过spark.cores.max限制节点数,或者修改spark.deploy.defaultCores配置。另外spark.executor.memory可以控制内存使用量。
- Apache Mesos:Mesos是一个专门用于分布式系统资源管理的开源系统,可以对集群中的资源做弹性管理。spark.mesos.coarse配置为true,实现静态分配。
YARN:主要用来管理资源。YARN支持动态资源管理,更适合多用户场景下的集群管理,而且YARN可以同时调度Spark计算和Hadoop MR计算,还可以调度其他实现了YARN调度接口的集群计算。
--num-executors(同spark.executor.instances)选项控制启动多少个executor。 --executor-memory (同spark.executor.memory):控制执行器的内存 --executor-cores (同spark.executor.cores):控制执行器使用的核数
4. Worker Node
集群上的计算节点,一般对应一台物理机器。
5. Executor
每个Spark程序在每个节点上启动一个进程,专属于一个Spark程序,与Spark程序有相同的生命周期,负责Spark在节点上启动的Task,管理内存和磁盘。如果一个节点上有多个Spark程序在运行,那么相应地就会启动多个执行器。
6. Cache
即RDD持久化。
持久化的方法是调用persist()函数,除了持久化到内存中,还可以在persist()中指定storage level参数使用其他的类型。
| storage level | 说明 |
|---|---|
| MEMORY_ONLY | 默认。以原始对象的形式持久化到内存。内存不足时,多余部分不会被持久化,访问时重新计算。 |
| MEMORY_AND_DISK | 内存不足时用磁盘代替 |
| MEMORY_ONLY_SER | 类似MEMORY_ONLY,格式是序列化后的数据。 |
| MEMORY_AND_DISK_SER | 类似MEMORY_ONLY_SER,内存不足时用磁盘代替 |
| DISK_ONLY | 只使用磁盘 |
| *_2, 比如MEMORY_ONLY_2和MEMORY_AND_DISK_2 | 与上面类似,但有两份副本。 |
RDD.unpersist()方法可以删除持久化。
7. Stage
Job在执行过程中被分为多个阶段。介于Job与Task之间,是按Shuffle分隔的Task集合。
8. Job
一次RDD Action对应一次Job,会提交至资源管理器调度执行。
9. Task
执行器上执行的最小单元。比如RDD Transformation操作时,对RDD内每个分区的计算都会对应一个Task。
2. Spark的工作机制
2.1 Standalone运行流程
- 用户启动客户端,提供Spark程序给Master;
- Master针对每个应用分发给指定的Worker启动Driver(即SchedulerBackend);
- Driver实例化创建SparkContext;
- SparkContext构建TaskScheduler和DAGScheduler;
- TaskScheduler通过自己的后台进程去连接Master,向Master发送注册申请;
- Master收到Driver的申请之后,会连接Worker,通过资源调度算法,在Worker上分配Executor;
- Worker收到Master的连接后,启动Executor(线程ExecutorRunner);
- Executor启动之后,向Driver的SchedulerBackend注册;
- 当执行action算子时,会触发job提交,DAGScheduler解析应用中的RDD,并生成相应的Stage,然后生成TaskSet;
- TaskScheduler会将TaskSet中的task任务发送到Executor;
- Executor接收到task之后,会从线程池中取出线程,执行task(即RDD中定义的算子);
- 返回结果到Driver。
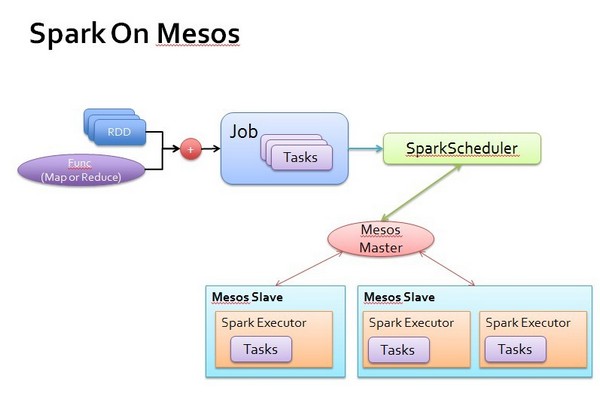
2.2 Spark On Mesos
为了在Mesos框架上运行,安装Mesos的规范和设计,Spark实现两个类,一个是SparkScheduler,在Spark中类名是MesosScheduler;一个是SparkExecutor,在Spark中类名是Executor。有了这两个类,Spark就可以通过Mesos进行分布式的计算。
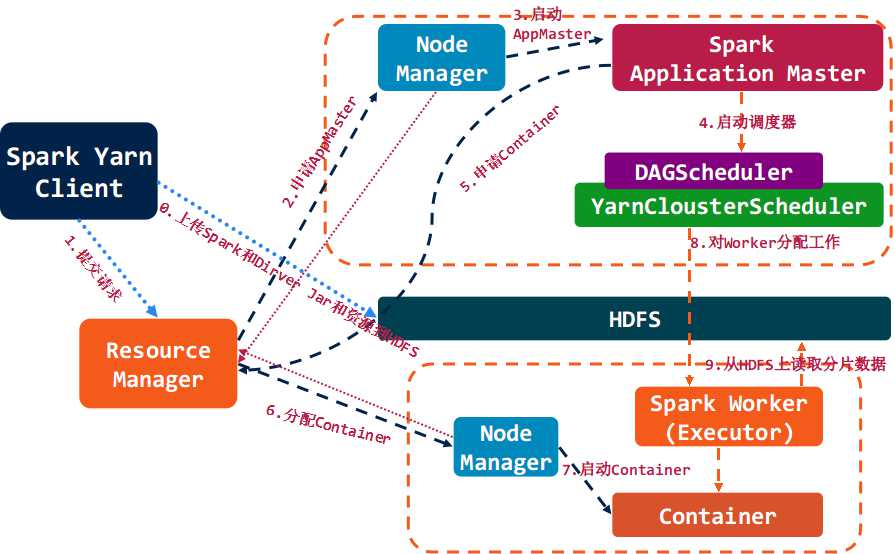
2.3 Spark On YARN
基于YARN的Spark作业首先由客户端生成作业信息,提交给ResourceManager,ResourceManager在某一NodeManager汇报时把AppMaster分配给NodeManager,NodeManager启动SparkAppMaster,SparkAppMaster启动后初始化作业,然后向ResourceManager申请资源,申请到相应资源后,SparkAppMaster通过RPC让NodeManager启动相应的SparkExecutor,SparkExecutor向SparkAppMaster汇报并完成相应的任务。此外,SparkClient会通过AppMaster获取作业运行状态。
3. Spark的计算模型
3.1 RDD定义
RDD:弹性分布式数据集,是一种内存抽象,可以理解为一个大数组,数组的元素是RDD的分区Partition,分布在集群上;在物理数据存储上,RDD的每一个Partition对应的就是一个数据块Block,Block可以存储在内存中,当内存不够时可以存储在磁盘上。
一个RDD对象,包含以下5个核心属性:
- 一个分区列表,每个分区里是RDD的部分数据(或称数据块)。
- 一个依赖列表,存储依赖的其他RDD。
- 一个名为compute的计算函数,用于计算RDD各分区的值。
- 分区器(可选),用于键值类型的RDD,比如某个RDD是按散列来分区。
- 计算各分区时优先的位置列表(可选),比如从HDFS上文件生成RDD时,RDD分区的位置优先选择数据所在的节点,这样可以避免数据移动带来的开销。
// 分区依赖:
// 依赖关系定义在一个Seq数据集中,类型是Dependency
// 有检查点时,这些信息会被重写,指向检查点
private var dependencies_ : Seq[Dependency[_]] = null
// 分区定义在Array集合中,类型是Partition,没有Seq,这主要考虑到
// 随时需要通过下标来访问或更新分区内容,而dependencies_使用
// Seq是因为它的使用场景一般是取第一个成员或遍历
@transient private var partitions_ : Array[Partition] = null
// 计算函数:由子类来实现,对输入的RDD分区进行计算
def compute(split: Partition, context: TaskContext): Iterator[T]
// 分区器(可选):子类可以重写以指定新的分区方式。Spark支持两种分区方式:Hash和Range
@transient val partitioner: Option[Partitioner] = None
// 优先计算位置(可选):子类可以指定分区优先的位置,
// 比如HadoopRDD会重写此方法,让分区尽可能与数据在相同节点上。
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
// RDD提供统一的调用方法,统一处理检查点问题
final def preferredLocations(split: Partition): Seq[String] = {
checkpointRDD.map(_.getPreferredLocations(split)).getOrElse {
getPreferredLocations(split)
}
}3.2 Transformation和Action
对于RDD,有两种类型的动作,一种是Transformation,一种是Action。它们本质区别是:
Transformation返回值还是一个RDD。它使用了链式调用的设计模式,对一个RDD进行计算后,变换成另外一个RDD,然后这个RDD又可以进行另外一次转换。这个过程是分布式的Action返回值不是一个RDD。它要么是一个Scala的普通集合,要么是一个值,要么是空,最终或返回到Driver程序,或把RDD写入到文件系统中
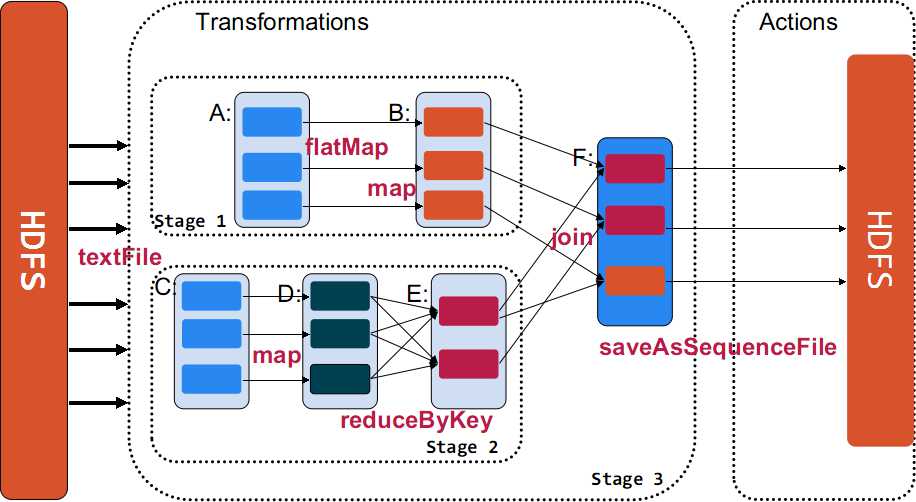
在Spark中,RDD是有依赖关系的,分两种类型:
- 窄依赖:依赖上级RDD的部分分区,例如上图的B依赖A。
- Shuffle依赖(宽依赖):依赖上级RDD的所有分区,例如E依赖D。
3.3 Shuffle
Shuffle的概念来自Hadoop的MapReduce计算过程。当单进程空间无法容纳所有计算数据进行计算时,通过Shuffle将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。数据倾斜是Spark性能优化的一个重大课题。
可能会触发shuffle操作的算子 :distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。
4. 容错机制
4.1 容错体系概述
Spark RDD是一个有向无环图(DAG),每个RDD都会记住创建该数据集需要哪些操作,跟踪记录RDD的继承关系,这个关系在Spark里面叫lineage。由于创建RDD的操作是相对粗粒度的变换(如map、filter、join),即单一的操作应用于许多数据元素,而不需存储真正的数据,该技巧比通过网络复制数据更高效。当一个RDD的扣个分区丢失时,RDD有足够的信息记录其如何通过其他RDD进行计算,且只需重新计算该分区。
Spark Streaming计算的应用场景中,系统的上游不断产生数据,容错过程可能造成数据丢失。为了解决这些问题,Spark也提供了预写日志(也称为journal),先将数据写入支持容错的文件系统中,然后才对数据施加这个操作。
4.2 Master节点失效
容错分为两种情况:Standalone集群模式和单点模式。
Standalone集群模式使用ZooKeeper来完成。
conf/spark-env.sh中为SPARK_DAEMON_JAVA_OPTS添加一些选项:
| 系统属性 | 说明 |
|---|---|
| spark.deploy.recoveryMode | 默认NONE,设置为ZOOKEEPER后,可以在Active Master异常后,重新选择一个Active Master |
| spark.deploy.zookeeper.url | ZooKeeper集群地址 |
| spark.deploy.zookeeper.dir | 用于恢复的ZooKeeper目录,默认”/spark” |
单点模式:
spark.deploy.recoveryMode=FILESYSTEM
spark.deploy.recoveryDirectory="本地目录,用于存储必要的信息来进行错误恢复"4.3 Slave节点失效
| 角色 | 容错过程 |
|---|---|
| Worker | 先将自己启动的执行器停止,Driver需要有相应的程序来启动Worker进程 |
| 执行器 | Driver没有在规定时间内收到执行器的StatusUpdate,Driver会将注册的执行器移除,Worker收到LaunchExecutor指令,再次启动执行器 |
| Driver程序 | 一般要使用检查点启动Driver,重新构造上下文并重启接收器。第一步,恢复检查点记录的元数据块。第二步,未完成作业的重新形成。由于失败而没有处理完成的RDD,将使用恢复的元数据重新生成RDD,然后运行后续的Job重新计算后恢复 |















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









