







1.Spring中Bean的生命周期。
1)spring对bean进行实例化,默认bean是单例
2)spring对bean进行依赖注入
3)如果bean实现了BeanNameAware接口,spring将bean的id传给setBeanName()方法
4)如果bean实现了BeanFactoryAware接口,spring将调用setBeanFactory方法,将BeanFactory实例传进来
5)如果bean实现了ApplicationContextAware()接口,spring将调用setApplicationContext()方法将应用上下文的引用传入
6) 如果bean实现了BeanPostProcessor接口,spring将调用它们的postProcessBeforeInitialization接口方法
7) 如果bean实现了InitializingBean接口,spring将调用它们的afterPropertiesSet接口方法,类似的如果bean使用了init-method属性声明了初始化方法,改方法也会被调用
8)如果bean实现了BeanPostProcessor接口,spring将调用它们的postProcessAfterInitialization接口方法
9)此时bean已经准备就绪,可以被应用程序使用了,他们将一直驻留在应用上下文中,直到该应用上下文被销毁
10)若bean实现了DisposableBean接口,spring将调用它的distroy()接口方法。同样的,如果bean使用了destroy-method属性声明了销毁方法,则该方法被调用

https://blog.csdn.net/weixin_42762133/article/details/98459194
2. SpringMVC或Struts处理请求的流程。
SpringMVC请求流程
DispatcherServlet:前端控制器。是整个流程的控制中心,协调各个组件进行工作。
HandlerMapping:处理器映射器。内部维护了一些 <访问路径, 处理器> 映射,负责为请求找到合适的处理器。
根据用户请求的url找到Handler,springmvc中提供了不同的映射器实现不同的映射方式,例如:xml配置方式,实现接口方式,注解方式等。HandlerMapping 将会把请求映射为 HandlerExecutionChain 对象(包含一个 Handler 处理器(页面控制器)对象、多个 HandlerInterceptor 拦截器)对象,通过这种策略模式,很容易添加新的映射策略;
Handler:处理器。本质上是由实现 Controller 接口的类、实现 HttpRequestHandler 接口的类、注解@RequestMapping 的方法等封装而成的对象
HandlerAdapter:Spring 中的处理器的实现多变,比如用户处理器可以实现 Controller 接口,实现 HttpRequestHandler 接口,也可以用 @RequestMapping 注解将方法作为一个处理器等,这就导致 Spring 不知道怎么调用用户的处理器逻辑。所以这里需要一个处理器适配器,由处理器适配器去调用处理器的逻辑
ModelAndView:封装的模型数据和视图名称
ViewResolver:视图解析器,用于将视图名称解析为视图对象 View。
View:在视图对象用于将模板渲染成 html 或其他类型的文件。比如 InternalResourceView 可将 jsp 渲染成 html
整个流程:
- 请求达到 DispatcherServlet
- 获取可处理当前请求的一个处理器 Handler 和多个拦截器 HandlerInterceptor
- 为当前获取的 Handler 找到合适的适配器,适配器的作用是提供统一调用接口
- 执行拦截器 preHandle 方法
- 执行适配器 handle 方法,即调用 handler 的对应处理方法,返回 ModelAndView,里面包含了模型数据和视图名称
- 执行拦截器 postHandle 方法
- 解析视图,根据视图名找到对应 view 对象
- 渲染视图,view 对象根据传进来的模型和模型数据进行渲染,返回 html 或其他类型的文件
- 返回响应
3. Spring AOP解决了什么问题?怎么实现的?aop与cglib,与asm的关系。
(1)AOP可以说是OOP的一个补充和完善,OOP是一种纵向的结构,比如从controller->service->dao层,横向的关系就很难实现。AOP通过横切关注点,将影响多个类的公共行为封装到一个可重用模块。简单的说就是将那些与业务无关的公共逻辑封装起来,减少重复代码,降低模块之间的耦合度,有利于代码的可维护性。
(2)要理解aop的实现,首先要了解代理的原理和实现。
代理分为两种,静态代理和静态代理,静态代理就是为类增加一个实现该接口的代理类,比如学生交作业,可以由班长代理来完成。那么我们新增一个实现学生接口的学生代理类,代理学生来交作业。
其他类省略,看下代理类代码
package com.sighting.test;
public class Cinema implements Movie {
RealMovie movie;
public Cinema(RealMovie movie) {
super();
this.movie = movie;
}
@Override
public void play() {
guanggao(true);
movie.play();
guanggao(false);
}
public void guanggao(boolean isStart){
if ( isStart ) {
System.out.println("电影马上开始了!");
} else {
System.out.println("电影马上结束了,爆米花、可乐、口香糖9.8折,买回家吃吧!");
}
}
}动态代理是在程序运行时,通过反射机制动态生成,这样就不用为每一个类建一个代理类了。下面看一个具体的例子:
package test;
public interface Subject
{
public void doSomething();
}package test;
public class RealSubject implements Subject
{
public void doSomething()
{
System.out.println( "call doSomething()" );
}
}
package test;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class ProxyHandler implements InvocationHandler
{
private Object tar;
//绑定委托对象,并返回代理类
public Object bind(Object tar)
{
this.tar = tar;
//绑定该类实现的所有接口,取得代理类
return Proxy.newProxyInstance(tar.getClass().getClassLoader(),
tar.getClass().getInterfaces(),
this);
}
public Object invoke(Object proxy , Method method , Object[] args)throws Throwable
{
Object result = null;
//这里就可以进行所谓的AOP编程了
//在调用具体函数方法前,执行功能处理
result = method.invoke(tar,args);
//在调用具体函数方法后,执行功能处理
return result;
}
}public class TestProxy
{
public static void main(String args[])
{
ProxyHandler proxy = new ProxyHandler();
//绑定该类实现的所有接口
Subject sub = (Subject) proxy.bind(new RealSubject());
sub.doSomething();
}
}
动态代理和静态代理最大的不同:就是动态代理对象是在运行时生成的,而静态代理在编译期间代理对象就已经建好,且静态代理只能代理一个对象,动态代理可以代理多个对象。
动态代理有两种实现方式:JDK动态代理和CGLIB动态代理,JDK动态代理是对接口进行代理,是通过拦截器实现的(实现InvocationHandler接口),CGLIB是对类进行代理,是利用ASM开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。JDK 使用反射机制调用目标类的方法,CGLIB 则使用类似索引的方式直接调用目标类方法,所以 JDK 动态代理生成代理类的速度相比 CGLIB 要快一些,但是运行速度比 CGLIB 低一些,
JDK动态代理和CGLIB动态代理如何选择呢?
如果代理对象实现了接口,默认情况是使用jdk动态代理实现,但是也可以强制使用cglib实现(添加CGLIB库,Spring配置文件中加入<aop:aspectj-autoproxy proxy-target-class="true"/>),如果代理对象没有实现接口,则必须使用cglib。
cglib和asm的关系:
Cglib是一个强大的、高性能的代码生成包,它广泛被许多AOP框架使用,为他们提供方法的拦截。下图是我网上找到的一张Cglib与一些框架和语言的关系:
对此图总结一下:
- 最底层的是字节码Bytecode,字节码是Java为了保证“一次编译、到处运行”而产生的一种虚拟指令格式,例如iload_0、iconst_1、if_icmpne、dup等
- 位于字节码之上的是ASM,这是一种直接操作字节码的框架,应用ASM需要对Java字节码、Class结构比较熟悉
- 位于ASM之上的是CGLIB、Groovy、BeanShell,后两种并不是Java体系中的内容而是脚本语言,它们通过ASM框架生成字节码变相执行Java代码,这说明在JVM中执行程序并不一定非要写Java代码----只要你能生成Java字节码,JVM并不关心字节码的来源,当然通过Java代码生成的JVM字节码是通过编译器直接生成的,算是最“正统”的JVM字节码
- 位于CGLIB、Groovy、BeanShell之上的就是Hibernate、Spring AOP这些框架了,这一层大家都比较熟悉
- 最上层的是Applications,即具体应用,一般都是一个Web项目或者本地跑一个程序
(3)aop的实现
https://blog.csdn.net/luanlouis/article/details/51155821
上面这篇文章写得特别详细,总的说来aop主要分为以下流程:创建代理对象(jdk动态代理,cglib动态代理), Advice链(即拦截器链)的构造过程以及执行机制,如何在advise上添加pointpoint,以及这个pointcut是如何实现的过滤的。
Aspect(切面):是通知和切入点的结合,通知和切入点共同定义
Joinpoint(连接点):所谓连接点是指那些被拦截到的点。在spring中,这些点指的是方法,因为spring只支持方法类型的连接点.
Pointcut(切入点):所谓切入点是指我们要对哪些joinpoint进行拦截的定义.
Advice(通知):所谓通知是指拦截到joinpoint之后所要做的事情就是通知.通知分为前置通知,后置通知,异常通知,最终通知,环绕通知(切面要完成的功能)
Target(目标对象):代理的目标对象
引入(Introduction):引用允许我们向现有的类添加新的方法或者属性;https://www.cnblogs.com/lcngu/p/6346777.html
Weaving(织入):是指把切面应用到目标对象来创建新的代理对象的过程.切面在指定的连接点织入到目标对象
@Pointcut("execution(* com.bytebeats.spring4.aop.annotation.service.BankServiceImpl.*(..))")
public void pointcut1() {
}
@Pointcut("execution(* com.bytebeats.spring4.aop.annotation.service.*ServiceImpl.*(..))")
public void myPointcut() {
}
/**
* 前置通知:在方法执行前执行的代码
* @param joinPoint
*/
@Before(value = "pointcut1() || myPointcut()")
//@Before("execution(* com.bytebeats.spring4.aop.annotation.service.BankServiceImpl.*(..))")
public void beforeExecute(JoinPoint joinPoint){
String methodName = joinPoint.getSignature().getName();
List<Object> args = Arrays.asList(joinPoint.getArgs());
System.out.println(this.getClass().getSimpleName()+ " before execute:"+methodName+ " begin with "+args);
}
4. Spring事务的传播属性是怎么回事?它会影响什么?
| 事务传播行为类型 | 说明 |
|---|---|
| PROPAGATION_REQUIRED | 如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择。 |
| PROPAGATION_SUPPORTS | 支持当前事务,如果当前没有事务,就以非事务方式执行。 |
| PROPAGATION_MANDATORY | 使用当前的事务,如果当前没有事务,就抛出异常。 |
| PROPAGATION_REQUIRES_NEW | 新建事务,如果当前存在事务,把当前事务挂起。 |
| PROPAGATION_NOT_SUPPORTED | 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 |
| PROPAGATION_NEVER | 以非事务方式执行,如果当前存在事务,则抛出异常。 |
| PROPAGATION_NESTED | 如果当前存在事务,则新建一个事物,嵌套在事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。 |
(1)PROPAGATION_REQUIRED
@Override
public void notransaction_exception_required_required(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addRequired(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addRequired(user2);
throw new RuntimeException();
}在外围方法未开启事务的情况下Propagation.REQUIRED修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
在外围方法开启事务的情况下Propagation.REQUIRED修饰的内部方法会加入到外围方法的事务中,所有Propagation.REQUIRED修饰的内部方法和外围方法均属于同一事务,只要一个方法回滚,整个事务均回滚。任一一个事务回滚,即使被try catch包裹也会导致其他所有事务回滚。
(2)PROPAGATION_REQUIRES_NEW
外围方法不论是否开启事务,Propagation.REQUIRES_NEW修饰的内部方法依然会单独开启独立事务,且与外部方法事务也独立,内部方法之间、内部方法和外部方法事务均相互独立,互不干扰。
(3)PROPAGATION_NESTED
外围方法未开启事务的情况下Propagation.NESTED和Propagation.REQUIRED作用相同
外围方法开启事务的情况下Propagation.NESTED修饰的内部方法属于外部事务的子事务,外围主事务回滚,子事务一定回滚,而内部子事务可以单独回滚而不影响外围主事务和其他子事务。
内部方法抛出异常回滚,且外围方法感知异常致使整体事务回滚 。
内部方法抛出异常回滚,对内部异常进行trycatch可以单独对子事务回滚,而不影响外围主事务和其他子事务
https://segmentfault.com/a/1190000013341344#comment-area
https://blog.csdn.net/wangen2010/article/details/100878836
顺便复习以下事物的隔离级别
什么是事务?
从数据库的事务定义来看,其具备ACID特性(即Atomic,原子性,Consistency一致性,Isolation,隔离性,Duration,持久性) 。
一般意义上讲,所谓的事务,指的是一批操作,可以原子性的方式进行,要么全部成功,要么全部失败;
什么是隔离性,隔离的是什么?
隔离性,是指不同的客户端在做事务操作时,理想状态下,各个客户端之间不会有任何相互影响,好像感知不到对方存在一样。所谓的隔离,真正隔离的对象在实现上是数据库资源的互斥性访问,隔离性就是通过数据库资源划分的不同粒度体现的。
接下来,本文将通过数据库资源的不同粒度的划分,来阐述隔离性不同级别的实现。
(1)读未提交(READ_UNCONNITED):读取到其他事务未提交的数据,可能导致脏读、幻影读或不可重复读。
(2)读已提交(READ_COMMITTED):允许从已经提交的并发事务读取。可防止脏读,但幻影读和不可重复读仍可能会发生。
reader在一个事务中,相同的查询条件,返回的行记录是同一条,但是这一条的记录的AGE列值从18变成19,虽然是相同的行记录,但是内容不一致,这种现象叫做不可重复读(NO-REPEATABLE-READ)。

(3)可重复读(REPEATABLE_READ):客户端A和客户端B 同时尝试访问相同的行数据;而客户端C和客户端D也是同时尝试访问相同的行数据。在此竞争过程中,可以看到,最多可以有两个客户端可以同时访问表T_USER,和序列化读相比,整个客户端的并发量又提高了一个量级!虽然使用行锁互斥的方式进行数据库操作,但是会出现幻读的情况,避免幻读的方式,可以使用表级锁—即提高事务的隔离界别—序列化读(SERIALIZABLE READ)。对相同字段的多次读取的结果是一致的,除非数据被当前事务本身改变。可防止脏读和不可重复读,但幻读仍可能发生。
在同一个事务内,完全相同的两次查询,返回的记录数不一致,好像多读了数据一样,这种情况,称为幻读(Phantom Read)

(4)序列化读(SERIALIZABLE READ):规定同一时间内只能有一个客户端连接数据库进行事务操作,在这个客户端完成事务之前,其他客户端不能对数据库进行事务操作。
https://blog.csdn.net/luanlouis/article/details/95319795
5.Spring中BeanFactory和FactoryBean有什么区别?
(1)BeanFactory:负责生产和管理bean的工厂,是IOC容器的核心接口。它有很多实现,经常使用的有ApplicationContext,AnnotationConfigApplicationContext,DefaultListableBeanFactory等,这些实现都在原有的BeanFactory中添加了自己的功能,例如ApplicationContext中的AOP功能。
1 Resource resource = new FileSystemResource("beans.xml");
2 BeanFactory factory = new XmlBeanFactory(resource);
1 ClassPathResource resource = new ClassPathResource("beans.xml");
2 BeanFactory factory = new XmlBeanFactory(resource);
1 ApplicationContext context = new ClassPathXmlApplicationContext(new String[] {"applicationContext.xml", "applicationContext-part2.xml"});
3 BeanFactory factory = (BeanFactory) context;
//使用示例
//Object school= factory.getBean("factoryBeanPojo"); 

(2)FactoryBean: 通过实现该接口可以定制实例化Bean的逻辑。实现了FactoryBean<T>接口的Bean,根据该Bean的ID从BeanFactory中获取的实际上是FactoryBean的getObject()返回的对象,而不是FactoryBean本身,如果要获取FactoryBean对象,请在id前面加一个&符号来获取。
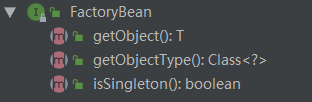
使用示例:
package com.baobaotao.factorybean;
import org.springframework.beans.factory.FactoryBean;
public class CarFactoryBean implements FactoryBean<Car> {
private String carInfo ;
public Car getObject () throws Exception {
Car car = new Car () ;
String [] infos = carInfo .split ( "," ) ;
car.setBrand ( infos [ 0 ]) ;
car.setMaxSpeed ( Integer. valueOf ( infos [ 1 ])) ;
car.setPrice ( Double. valueOf ( infos [ 2 ])) ;
return car;
}
public Class<Car> getObjectType () {
return Car. class ;
}
public boolean isSingleton () {
return false ;
}
public String getCarInfo () {
return this . carInfo ;
}
// 接受逗号分割符设置属性信息
public void setCarInfo ( String carInfo ) {
this . carInfo = carInfo;
}
}有了这个CarFactoryBean后,就可以在配置文件中使用下面这种自定义的配置方式配置CarBean了:
<bean d="car"class="com.baobaotao.factorybean.CarFactoryBean"
P:carInfo="法拉利,400,2000000"/>6.Spring框架中IOC的原理是什么?
(1)思想:IOC(inverse of control )控制反转,java中一个对象引用另一个对象的时候,是由程序员new完成的,现在spring会主动帮我们创建对象,所以说是创建对象的方式反转了。IOC是思想,DI是主要技术,spring创建的对象是放到IOC容器中的,通过DI即可注入需要的对象。
(2)原理:
BeanFactory:只对IOC容器的基本行为作了定义,根本不关心你的bean是如何定义怎样加载的。正如我们只关心工厂里得到什么的产品对象,至于工厂是怎么生产这些对象的,这个基本的接口不关心。 而要知道工厂是如何产生对象的,我们需要看具体的IOC容器实现,spring提供了许多IOC容器的实现。比如XmlBeanFactory,ClasspathXmlApplicationContext等。其中XmlBeanFactory就是针对最基本的ioc容器的实现,这个IOC容器可以读取XML文件定义的BeanDefinition(XML文件中对bean的描述)
BeanDefinition:SpringIOC容器管理了我们定义的各种Bean对象及其相互的关系,Bean对象在Spring实现中是以BeanDefinition来描述的。
设置资源加载器和资源定位
spring IoC容器对Bean定义资源的载入是从refresh()函数开始的
Spring IoC容器将载入的Bean定义资源文件转换为Document对象之后,是如何将其解析为Spring IoC管理的Bean对象并将其注册到容器中的。其实代码大部分都是对xml转换成的resource文件进行解析,封装成带有BeanDefinition属性的BeanDefinitionHold对象,最后向容器中注册beanDefinition(当调用BeanDefinitionReaderUtils向IoC容器注册解析的BeanDefinition时,真正完成注册功能的是DefaultListableBeanFactory。DefaultListableBeanFactory中使用一个HashMap的集合对象存放IoC容器中注册解析的BeanDefinition)
https://www.cnblogs.com/siriusckx/articles/4778407.html
7.spring的依赖注入有哪几种方式
(1)set 方法注入
通过 property 标签来配置属性,基本数据类型使用 value 属性即可,若是引用类型则使用 ref 。注意,User 对象中要有 Car 引用并且提供其 set 方法。
(2)构造方法注入
这个配置看一眼就基本理解了,非常简单,说个小细节,对象的创建需要执行构造器,我们在初始化对象的时候会使用反射通过全类名得到对象,而这时就需要一个空参的构造器,我们不提供构造器的情况下,程序会自动为我们提供一个空参构造器,但是一旦重写构造器,我们就需要提供空参构造器,不然就报错。
(3)@Autowired注解装入
<!-- 使用注解时必须启动注解驱动 --> <context:annotation-config />
public class UserServiceImpl implements UserService {
//标注成员变量
@Autowired
private UserDao userDao;
//标注构造方法
@Autowired
public UserServiceImpl(UserDao userDao){
this.userDao=userDao;
}
//标注set方法
@Autowired
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
@Override
public void done(){
userDao.done();
}
}
8.用Spring如何实现一个切面?
(1)切面类上添加注解@Aspect@Component
(2)配置文件中配置切面类,并配置aop:pointcut和advisor
<aop:config>
<aop:pointcut id="beforeMethod"
expression="execution(public * com.DemoClass.*(..))" />
<aop:aspect id="myAspect" ref="acpectInterceptor">
<aop:pointcut id="afterMethod"
expression="execution(public * com.DemoClass.*(..))" />
<aop:before method="before" pointcut-ref="beforeMethod"/>
<aop:after-returning method="after" pointcut-ref="afterMethod"/>
</aop:aspect>
</aop:config>9.Spring 如何实现数据库事务?
Spring的事务管理:使用AOP技术,通过对Service层设置切面,注入事务管理的逻辑。
这篇文章讲了声明式和编程式事物的详细内容,可以参考一下
https://juejin.im/post/5b010f27518825426539ba38#heading-6
<!-- 配置c3po连接池 -->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<!-- 注入属性值 -->
<property name="driverClass" value="com.mysql.jdbc.Driver"></property>
<property name="jdbcUrl" value="jdbc:mysql://localhost:3306/wangyiyun"></property>
<property name="user" value="root"></property>
<property name="password" value="153963"></property>
</bean>
<!-- 第一步:配置事务管理器 -->
<bean id="dataSourceTransactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<!-- 注入dataSource -->
<property name="dataSource" ref="dataSource"></property>
</bean>
<!-- 第二步:配置事务增强 -->
<tx:advice id="txadvice" transaction-manager="dataSourceTransactionManager">
<!-- 做事务操作 -->
<tx:attributes>
<!-- 设置进行事务操作的方法匹配规则 -->
<!-- account开头的所有方法 -->
<!--
propagation:事务传播行为;
isolation:事务隔离级别;
read-only:是否只读;
rollback-for:发生那些异常时回滚
timeout:事务过期时间
-->
<tx:method name="account*" propagation="REQUIRED"
isolation="DEFAULT" read-only="false" rollback-for="" timeout="-1" />
</tx:attributes>
</tx:advice>
<!-- 第三步:配置切面 切面即把增强用在方法的过程 -->
<aop:config>
<!-- 切入点 -->
<aop:pointcut expression="execution(* cn.itcast.service.OrdersService.*(..))"
id="pointcut1" />
<!-- 切面 -->
<aop:advisor advice-ref="txadvice" pointcut-ref="pointcut1" />
</aop:config>
<!-- 对象生成及属性注入 -->
<bean id="ordersService" class="cn.itcast.service.OrdersService">
<property name="ordersDao" ref="ordersDao"></property>
</bean>
<bean id="ordersDao" class="cn.itcast.dao.OrdersDao">
<property name="jdbcTemplate" ref="jdbcTemplate"></property>
</bean>
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSource"></property>
</bean>
- DataSource配置:设置当前应用所需要连接的数据库,包括链接,用户名,密码等;
- JdbcTemplate声明:封装了客户端调用数据库的方式,用户可以使用其他的方式,比如JpaRepository,Mybatis等等;
- TransactionManager配置:指定了事务的管理方式,这里使用的是DataSourceTransactionManager,对于不同的链接方式,也可以进行不同的配置,比如对于JpaRepository使用JpaTransactionManager,对于Hibernate,使用HibernateTransactionManager;
- tx:annotation-driven:主要用于事务驱动,其会通过AOP的方式声明一个为事务支持的Advisor,通过该Advisor和事务的相关配置进行事务相关操作。
那么spring是如何解析标签,封装相关bean,封装数据库事物的呢?
JdbcTemplate和TransactionManager分别封装了数据库连接和事物管理相关内容,事物驱动主要是由tx:annotation-driven实现的。
tx:annotation-driven是一个自定义标签,我们根据其命名空间(www.springframework.org/schema/tx)在全局范围内搜索,可以找到其处理器指定文件spring.handlers,该文件内容如下:
http\://www.springframework.org/schema/tx=org.springframework.transaction.config.TxNamespaceHandlerTxNamespaceHandler就是标签解析的相关代码。

可以看到解析注解的驱动在AnnotationDrivenBeanDefinitionParser中,parse()方法就是解析标签,并且注册相关bean的方法,如下是该方法的实现:
public BeanDefinition parse(Element element, ParserContext parserContext) {
// 注册事务相关的监听器,如果某个方法标注了TransactionalEventListener注解,
// 那么该方法就是一个事务事件触发方法,即发生某种事务事件后,将会根据该注解的设置,回调指定
// 类型的方法。常见的事务事件有:事务执行前和事务完成(包括报错后的完成)后的事件。
registerTransactionalEventListenerFactory(parserContext);
String mode = element.getAttribute("mode");
// 获取当前事务驱动程序的模式,如果使用了aspectj模式,则会注册一个AnnotationTransactionAspect
// 类型的bean,用户可以以aspectj的方式使用该bean对事务进行更多的配置
if ("aspectj".equals(mode)) {
registerTransactionAspect(element, parserContext);
} else {
// 一般使用的是当前这种方式,这种方式将会在Spring中注册三个bean,分别是
// AnnotationTransactionAttributeSource,TransactionInterceptor
// 和BeanFactoryTransactionAttributeSourceAdvisor,并通过Aop的方式实现事务
AopAutoProxyConfigurer.configureAutoProxyCreator(element, parserContext);
}
return null;
}接下来看一下AopAutoProxyConfigurer.configureAutoProxyCreator(element, parserContext);方法
public static void configureAutoProxyCreator(Element element,
ParserContext parserContext) {
// 这个方法主要是在当前BeanFactory中注册InfrastructureAdvisorAutoProxyCreator这个
// bean,这个bean继承了AbstractAdvisorAutoProxyCreator,也就是其实现原理与我们前面
// 讲解的Spring Aop的实现原理几乎一致
AopNamespaceUtils.registerAutoProxyCreatorIfNecessary(parserContext, element);
// 这里的txAdvisorBeanName就是我们最终要注册的bean,其类型就是下面注册的
// BeanFactoryTransactionAttributeSourceAdvisor,可以看到,其本质是一个
// Advisor类型的对象,因而Spring Aop会将其作为一个切面织入到指定的bean中
String txAdvisorBeanName = TransactionManagementConfigUtils
.TRANSACTION_ADVISOR_BEAN_NAME;
// 如果当前BeanFactory中已经存在了目标bean,则不进行注册
if (!parserContext.getRegistry().containsBeanDefinition(txAdvisorBeanName)) {
Object eleSource = parserContext.extractSource(element);
// 注册AnnotationTransactionAttributeSource,这个bean的主要作用是封装
// @Transactional注解中声明的各个属性
RootBeanDefinition sourceDef = new RootBeanDefinition(
"org.springframework.transaction.annotation.AnnotationTransactionAttributeSource");
sourceDef.setSource(eleSource);
sourceDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
String sourceName = parserContext.getReaderContext()
.registerWithGeneratedName(sourceDef);
// 注册TransactionInterceptor类型的bean,并且将上面的封装属性的bean设置为其一个属性。
// 这个bean本质上是一个Advice(可查看其继承结构),Spring Aop使用Advisor封装实现切面
// 逻辑织入所需的所有属性,但真正的切面逻辑却是保存在其Advice属性中的,也就是说这里的
// TransactionInterceptor才是真正封装了事务切面逻辑的bean
RootBeanDefinition interceptorDef =
new RootBeanDefinition(TransactionInterceptor.class);
interceptorDef.setSource(eleSource);
interceptorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registerTransactionManager(element, interceptorDef);
interceptorDef.getPropertyValues().add("transactionAttributeSource",
new RuntimeBeanReference(sourceName));
String interceptorName = parserContext.getReaderContext()
.registerWithGeneratedName(interceptorDef);
// 注册BeanFactoryTransactionAttributeSourceAdvisor类型的bean,这个bean实现了
// Advisor接口,实际上就是封装了当前需要织入的切面的所有所需的属性
RootBeanDefinition advisorDef =
new RootBeanDefinition(BeanFactoryTransactionAttributeSourceAdvisor.class);
advisorDef.setSource(eleSource);
advisorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
advisorDef.getPropertyValues().add("transactionAttributeSource",
new RuntimeBeanReference(sourceName));
advisorDef.getPropertyValues().add("adviceBeanName", interceptorName);
if (element.hasAttribute("order")) {
advisorDef.getPropertyValues().add("order", element.getAttribute("order"));
}
parserContext.getRegistry().registerBeanDefinition(txAdvisorBeanName, advisorDef);
// 将需要注册的bean封装到CompositeComponentDefinition中,并且进行注册
CompositeComponentDefinition compositeDef =
new CompositeComponentDefinition(element.getTagName(), eleSource);
compositeDef.addNestedComponent(
new BeanComponentDefinition(sourceDef, sourceName));
compositeDef.addNestedComponent(
new BeanComponentDefinition(interceptorDef, interceptorName));
compositeDef.addNestedComponent(
new BeanComponentDefinition(advisorDef, txAdvisorBeanName));
parserContext.registerComponent(compositeDef);
}
}Spring事务相关的标签即解析完成,这里主要是声明了一个BeanFactoryTransactionAttributeSourceAdvisor类型的bean到BeanFactory中,其实际为Advisor类型,这也是Spring事务能够通过Aop实现事务的根本原因。
Aop在进行解析的时候,最终会生成一个Adivsor对象,这个Advisor对象中封装了切面织入所需要的所有信息,其中就包括最重要的两个部分就是Pointcut和Adivce属性。这里Pointcut用于判断目标bean是否需要织入当前切面逻辑;Advice则封装了需要织入的切面逻辑。如下是这三个部分的简要关系图:
同样的,对于Spring事务,其既然是使用Spring Aop实现的,那么也同样会有这三个成员。我们这里我们只看到了注册的Advisor和Advice(即BeanFactoryTransactionAttributeSourceAdvisor和TransactionInterceptor),那么Pointcut在哪里呢?这里我们查看BeanFactoryTransactionAttributeSourceAdvisor的源码可以发现,其内部声明了一个TransactionAttributeSourcePointcut类型的属性,并且直接在内部进行了实现,这就是我们需要找的Pointcut。这里这三个对象对应的关系如下:
这样,用于实现Spring事务的Advisor,Pointcut以及Advice都已经找到了。关于这三个类的具体作用,我们这里进行整体的上的讲解,后面我们将会深入其内部讲解其是如何进行bean的过滤以及事务逻辑的织入的。
- BeanFactoryTransactionAttributeSourceAdvisor:封装了实现事务所需的所有属性,包括Pointcut,Advice,TransactionManager以及一些其他的在Transactional注解中声明的属性;
- TransactionAttributeSourcePointcut:用于判断哪些bean需要织入当前的事务逻辑。这里可想而知,其判断的基本逻辑就是判断其方法或类声明上有没有使用@Transactional注解,如果使用了就是需要织入事务逻辑的bean;
- TransactionInterceptor:这个bean本质上是一个Advice,其封装了当前需要织入目标bean的切面逻辑,也就是Spring事务是如果借助于数据库事务来实现对目标方法的环绕的。
https://my.oschina.net/zhangxufeng/blog/1935556
Spring是通过Aop实现切面逻辑织入的,这里TransactionInterceptor实现了MethodInterceptor接口,这个接口则继承了Advice接口,也就是说,本质上TransactionInterceptor是只是Spring Aop中需要织入的切面逻辑的一部分。以下为invoke方法中调用的主要代码逻辑。
protected Object invokeWithinTransaction(Method method, Class<?> targetClass, final InvocationCallback invocation)
throws Throwable {
// If the transaction attribute is null, the method is non-transactional.
final TransactionAttribute txAttr = getTransactionAttributeSource().getTransactionAttribute(method, targetClass);
final PlatformTransactionManager tm = determineTransactionManager(txAttr);
final String joinpointIdentification = methodIdentification(method, targetClass, txAttr);
if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) {
// Standard transaction demarcation with getTransaction and commit/rollback calls.
TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification);
Object retVal = null;
try {
// This is an around advice: Invoke the next interceptor in the chain.
// This will normally result in a target object being invoked.
retVal = invocation.proceedWithInvocation();
}
catch (Throwable ex) {
// target invocation exception
completeTransactionAfterThrowing(txInfo, ex);
throw ex;
}
finally {
cleanupTransactionInfo(txInfo);
}
commitTransactionAfterReturning(txInfo);
return retVal;
}
else {
// It's a CallbackPreferringPlatformTransactionManager: pass a TransactionCallback in.
try {
Object result = ((CallbackPreferringPlatformTransactionManager) tm).execute(txAttr,
new TransactionCallback<Object>() {
@Override
public Object doInTransaction(TransactionStatus status) {
TransactionInfo txInfo = prepareTransactionInfo(tm, txAttr, joinpointIdentification, status);
try {
return invocation.proceedWithInvocation();
}
catch (Throwable ex) {
if (txAttr.rollbackOn(ex)) {
// A RuntimeException: will lead to a rollback.
if (ex instanceof RuntimeException) {
throw (RuntimeException) ex;
}
else {
throw new ThrowableHolderException(ex);
}
}
else {
// A normal return value: will lead to a commit.
return new ThrowableHolder(ex);
}
}
finally {
cleanupTransactionInfo(txInfo);
}
}
});
// Check result: It might indicate a Throwable to rethrow.
if (result instanceof ThrowableHolder) {
throw ((ThrowableHolder) result).getThrowable();
}
else {
return result;
}
}
catch (ThrowableHolderException ex) {
throw ex.getCause();
}
}
}这段代码主要完成的是:使用TransactionManager创建Connection,并将Connection相关信息存储在TransactionInfo中。
10.Hibernate和Ibatis这类ORM框架的区别?什么是ORM,解决的痛点是什么?
区别
ibatis是半自动的需要开发人员写sql语句。iBatis 支持通过 XML 或注解的方式来配置需要运行的 SQL 语句,并且,最终由框架本身将 Java 对象和 SQL 语句映射生成最终执行的 SQL ,执行后,再将结果映射成 Java 对象返回。因此比较灵活。
但是 MyBatis 无法做到数据库无关性,如果需要实现支持多种数据库的软件则需要自定义多套 SQL 映射文件,工作量大。
再来说说 Hibernate, 它对象/关系映射能力强,能做到数据库无关性。如果用 Hibernate 开发,无需关系 SQL 编写(不会写 SQL 的人都可以操作数据库),能节省很多代码,提高效率。但是 Hibernate 的缺点是学习门槛高,要精通门槛更高,而且怎么设计 O/R 映射,在性能和对象模型之间如何权衡,以及怎样用好 Hibernate 需要具有很强的经验和能力才行。ps: JPA 是基于 Hibernate 的一层封装,也就是说底层还是 Hibernate。
什么是ORM(Object Relationship Mapping)呢?
对象关系映射 是通过使用描述对象和数据库之间映射的元数据,将面向对象程序中的对象自动持久化到数据库中。那么持久化是什么意思呢?它源于在对象的生命周期之外也可以使用的一种数据特性。例如传统的解决方法是使用文件系统将信息存储在文件中,但是这种方式会影响数据一致性,而且查找文件内的内容是很耗时。因此出现了使用数据库存储的方式。
ORM在应用层和数据库层中间充当桥梁。它采用元数据来描述对象关系的映射。
Java中ORM的原理: 实现JavaBean的属性到数据库表的字段的映射,首先读某个配置文件把JavaBean的属 性和数据库表的字段自动关联起来,当从数据库Query时,自动把字段的值塞进JavaBean的对应属性里,当做INSERT或UPDATE时,自动把 JavaBean的属性值绑定到SQL语句中。
ORM解决了什么问题?
解决了对象和关系的映射。java中entity对象和数据表的映射,当应用程序访问数据库时,能像使用对象一样使用数据库数据。
11.spring ioc的生命周期
(1)InitializingBean接口的作用:实现该接口的类,在初始化bean的时候会执行afterPropertiesSet方法
public interface InitializingBean {
/**
* Invoked by a BeanFactory after it has set all bean properties supplied
* (and satisfied BeanFactoryAware and ApplicationContextAware).
* <p>This method allows the bean instance to perform initialization only
* possible when all bean properties have been set and to throw an
* exception in the event of misconfiguration.
* @throws Exception in the event of misconfiguration (such
* as failure to set an essential property) or if initialization fails.
*/
void afterPropertiesSet() throws Exception;
}
那麽,实现InitializingBean接口与在配置文件中指定init-method有什么不同?
如果该bean是实现了InitializingBean接口,并且同时在配置文件中指定了init-method,系统则是先调用afterPropertiesSet方法,然后在调用init-method中指定的方法。
<bean id="testInitializingBean" class="com.TestInitializingBean" init-method="testInit"></bean>
通过查看spring的加载bean的源码类(AbstractAutowireCapableBeanFactory)可看出其中奥妙
AbstractAutowireCapableBeanFactory类中的invokeInitMethods讲解的非常清楚,源码如下:
protected void invokeInitMethods(String beanName, final Object bean, RootBeanDefinition mbd)
throws Throwable {
//判断该bean是否实现了实现了InitializingBean接口,如果实现了InitializingBean接口,则只掉调用bean的afterPropertiesSet方法
boolean isInitializingBean = (bean instanceof InitializingBean);
if (isInitializingBean && (mbd == null || !mbd.isExternallyManagedInitMethod("afterPropertiesSet"))) {
if (logger.isDebugEnabled()) {
logger.debug("Invoking afterPropertiesSet() on bean with name '" + beanName + "'");
}
if (System.getSecurityManager() != null) {
try {
AccessController.doPrivileged(new PrivilegedExceptionAction<Object>() {
public Object run() throws Exception {
//直接调用afterPropertiesSet
((InitializingBean) bean).afterPropertiesSet();
return null;
}
},getAccessControlContext());
} catch (PrivilegedActionException pae) {
throw pae.getException();
}
}
else {
//直接调用afterPropertiesSet
((InitializingBean) bean).afterPropertiesSet();
}
}
if (mbd != null) {
String initMethodName = mbd.getInitMethodName();
//判断是否指定了init-method方法,如果指定了init-method方法,则再调用制定的init-method
if (initMethodName != null && !(isInitializingBean && "afterPropertiesSet".equals(initMethodName)) &&
!mbd.isExternallyManagedInitMethod(initMethodName)) {
//进一步查看该方法的源码,可以发现init-method方法中指定的方法是通过反射实现
invokeCustomInitMethod(beanName, bean, mbd);
}
}
}总结:
1:spring为bean提供了两种初始化bean的方式,实现InitializingBean接口,实现afterPropertiesSet方法,或者在配置文件中同过init-method指定,两种方式可以同时使用
2:实现InitializingBean接口是直接调用afterPropertiesSet方法,比通过反射调用init-method指定的方法效率相对来说要高点。但是init-method方式消除了对spring的依赖
3:如果调用afterPropertiesSet方法时出错,则不调用init-method指定的方法。
4:TransactionTemplate实现InitializingBean接口,主要是判断transactionManager是否已经初始化,如果没有则抛出异常。源码如下:
@Override
public void afterPropertiesSet() {
if (this.transactionManager == null) {
throw new IllegalArgumentException("Property 'transactionManager' is required");
}
}12.Hbernate对一二级缓存的使用,Lazy-Load的理解
(1)一级缓存
Hibernate一级缓存是Session缓存(内置缓存),一级缓存在Session中实现,当Session关闭一级缓存即失效。
使用:
数据库数据

public class NewManager {
public static void main(String[]args){
NewManager newManager=new NewManager();
newManager.secondCache();
}
public void secondCache(){
//获取Session
Session session=HibernateUtil.currentSession();
//开启事务
Transaction tx=session.beginTransaction();
//获取数据,并将数据放入session缓存即一级缓存
List list=session.createQuery("from News news")
.list();
//获取缓存数据
News news =(News) session.load(News.class, 2);
System.out.println(news.getTitle()+"\t"+news.getContent());
tx.commit();
System.out.println("-------------------");
//开启一个新的事务
tx=session.beginTransaction();
//从一级缓存中获取数据
News newse=(News) session.load(News.class, 3);
System.out.println(newse.getTitle()+"\t"+newse.getContent());
tx.commit();
}
}
一级缓存中常用其他方法:
session.evit(Object obj) 将指定的持久化对象从一级缓存中清除,释放所占用的内存资源,该对象从持久化状态变为脱管状态,从而成为游离对象
session.clear() 将一级缓存中的所有持久化对象清除,释放其占用的内存资源。
session.contains(Object obj) 判断指定的对象是否存在于一级缓存中。
session.flush() 刷新一级缓存区的内容,使之与数据库数据保持同步。
(2)二级缓存
Hibernate二级缓存是SessionFactory级的缓存。在Hibernate中二级缓存在SessionFactory中实现,由一个SessionFactory的所有Session实例所共享。
Session在查找一个对象时,会首先在自己的一级缓存中进行查找,如果没有找到,则进入二级缓存中进行查找,如果二级缓存中存在,则将对象返回,如果二级缓存中也不存在,则从数据库中获得。
Hibernate并未提供对二级缓存的产品化实现,而是为第三方缓存组件的使用提供了接口,当前Hibernate支持的第三方二级缓存的实现如下:
• EHCache
• Proxool
• OSCache
• SwarmCache
• JBossCache
下面介绍一下EHCache的使用:
a.导入jar包
b.添加ehcache.xml,并在配置文件中配置二级缓存
<!-- ehcache.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<ehcache>
<!--
缓存到硬盘的路径
-->
<diskStore path="d:/ehcache"></diskStore>
<!--
默认设置
maxElementsInMemory : 在內存中最大緩存的对象数量。
eternal : 缓存的对象是否永远不变。
timeToIdleSeconds :可以操作对象的时间。
timeToLiveSeconds :缓存中对象的生命周期,时间到后查询数据会从数据库中读取。
overflowToDisk :内存满了,是否要缓存到硬盘。
-->
<defaultCache maxElementsInMemory="200" eternal="false"
timeToIdleSeconds="50" timeToLiveSeconds="60" overflowToDisk="true"></defaultCache>
<!--
指定缓存的对象。
下面出现的的属性覆盖上面出现的,没出现的继承上面的。
-->
<cache name="com.suxiaolei.hibernate.pojos.Order" maxElementsInMemory="200" eternal="false"
timeToIdleSeconds="50" timeToLiveSeconds="60" overflowToDisk="true"></cache>
</ehcache>
<!-- 开启二级缓存 -->
<property name="hibernate.cache.use_second_level_cache">true</property>
<!-- 设置缓存区的实现类,类型为内存、磁盘、事务性、支持集群 -->
<property name="hibernate.cache.region.factory_class">
org.hibernate.cache.ehcache.EhCacheRegionFactory
</property>
<!-- 二级缓存配置文件的位置 -->
<property name="hibernate.cache.provider_configuration_file_resource_path">ehcache.xml</property>
<!-- 指定根据当前线程来界定上下文相关Session -->
<property name="hibernate.current_session_context_class">thread</property>
c.通过使用@Cache注解修饰需要启用二级缓存的实体类、实体的那些集合属性.
级缓存的使用策略一般有这几种:read-only、nonstrict-read-write、read-write、transactional。注意:我们通常使用二级缓存都是将其配置成 read-only ,即我们应当在那些不需要进行修改的实体类上使用二级缓存,否则如果对缓存进行读写的话,性能会变差,这样设置缓存就失去了意义。
@Entity
@Table(name="new_inf")
@Cache(usage=CacheConcurrencyStrategy.READ_ONLY)
public class News {
@Id
@Column(name="new_id")
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
private String title;
private String content;
测试的主程序
public class NewManager {
public static void main(String[]args){
NewManager newManager=new NewManager();
newManager.secondCache();
}
public void secondCache(){
//获取Session
Session session=HibernateUtil.currentSession();
//开启事务
Transaction tx=session.beginTransaction();
//获取数据
List list=session.createQuery("from News news")
.list();
//通过id查找数据
News news =(News) session.load(News.class, 2);
System.out.println(news.getTitle()+"\t"+news.getContent());
tx.commit();
//关闭Session
HibernateUtil.closeSession();
System.out.println("-----------关闭Session,启用二级缓存查询------------");
session=HibernateUtil.currentSession();
session.beginTransaction();
//通过二级缓存查询数据
News news2 =(News) session.load(News.class, 3);
System.out.println(news2.getTitle()+"\t"+news2.getContent());
}
}
Lazy-Load(懒加载)就是访问对象时,如果没有访问到对象的属性,当前查询不会返回这个对象,一般在一对多,多对多的数据关系中都会用到。
13.Spring IoC AOP自己用代码如何实现
https://xilidou.com/2018/01/13/spring-aop/
14.RPC的负载均衡、服务发现怎么做的
RPC(Remote Procedure Call)远程过程调用就是本地动态代理隐藏通信细节,通过组件序列化请求,走网络到服务端,执行真正的服务代码,然后将结果返回给客户端,反序列化数据给调用方法的过程。
负载均衡是指将前端请求根据一定算法策略来分发到不同机器上,使得集群中机器资源得到充分均衡的利用,此外还可以将不可用机器剔出请求列表。
RPC服务一般是以集群的方式部署,所以需要在客户端维持一个服务调用地址列表,而且在rpc服务集群有机器增加或迁移时,要实时更新集群机器列表。这就是服务发现的两个主要功能:服务地址存储和服务状态感知
https://ketao1989.github.io/2016/12/10/rpc-theory-in-action/
15.几种推送模型的区别,long polling,websocket
(1)ajax轮询 ,ajax轮询 的原理非常简单,让浏览器隔个几秒就发送一次请求,询问服务器是否有新信息。
(2)long poll ,其实原理跟 ajax轮询 差不多,都是采用轮询的方式,不过采取的是阻塞模型(一直打电话,没收到就不挂电话),也就是说,客户端发起连接后,如果没消息,就一直不返回Response给客户端。直到有消息才返回,返回完之后,客户端再次建立连接,周而复始。
场景再现
client: 啦啦啦, 有没有新的信息(Request)
server: 没有(Request)
client: 啦啦啦, 有没有新的信息(Request)
server: 没有没有没有(Request)
client: 啦啦啦, 有没有新的信息(Request)
server: 没有没有没有没有没有没有(Request)
从上面可以看出其实这两种方式,都是在不断地建立HTTP连接,然后等待服务端处理,可以体现HTTP协议的另外一个特点,被动性。
何为被动性呢,其实就是,服务端不能主动联系客户端,只能有客户端发起。
而且这两种方式是有很大的缺陷的:ajax轮询,需要服务器有很快的处理速度和资源,long pool需要有高并发的能力(同时接待客户的能力)
(3)因此出现了WebSocket,首先,解决了被动型的问题。当服务器协议完成升级后(http->webSocket),服务端可以主动推送消息给客户端。这样只需要一次http请求,就可以做到源源不断的信息传送了。然后,传统方式中要不断的建立和关闭http协议,由于http协议是非状态型的,每次都要传输identity info(鉴别信息)来告诉服务端你是谁。webSocket只需要建立一次连接,就可以实现多次请求。
背景:WebSocket 看成是 HTTP 协议为了支持长连接所打的一个大补丁,它和 HTTP 有一些共性,是为了解决 HTTP 本身无法解决的某些问题而做出的一个改良设计。在以前 HTTP 协议中所谓的 keep-alive connection 是指在一次 TCP 连接中完成多个 HTTP 请求,但是对每个请求仍然要单独发 header;所谓的 polling 是指从客户端(一般就是浏览器)不断主动的向服务器发 HTTP 请求查询是否有新数据。这两种模式有一个共同的缺点,就是除了真正的数据部分外,服务器和客户端还要大量交换 HTTP header,信息交换效率很低。它们建立的“长连接”都是伪.长连接,只不过好处是不需要对现有的 HTTP server 和浏览器架构做修改就能实现。
场景再现
client: 啦啦啦,我要建立Websocket协议, 需要的服务:chat, Websocket协议版本:17(Http Request)
service: OK, 已经升级为Websocket协议(HTTP ProtocolsSwitched)
client: 有新消息时候告诉我
service: ok















 1747
1747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









