







1基本概念
| 输入 | 定义在输入(特征空间)随机变量取值 | 输入变量习惯用大写字母X,输入变量所取的值用小写字母x | 可以是标量或向量 |
| 输出 | 定义在输出空间的随机变量取值 | 输出变量习惯用大写字母Y,输出变量所取的值用小写字母y | 可以是标量或向量 |
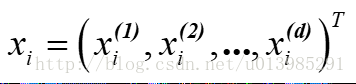
训练数据:由输入(特征向量)与输出对组成;训练集T={(x1,y1),...(Xn,yn)}
测试数据:由相应的输入与输出对组成
输入与输出对成为样本或样本点
| 输入空间 | 输入的所有可能取值的集合 | 有限元素的集合、整个欧式空间 |
| 输出空间 | 输出的所有可能取值的集合 | 有限元素的集合、整个欧式空间 |
| 特征空间 | 特征向量的所有可能取值(特征空间的每一维对应于一个特征) | |
| 假设空间 | 输入到输出的映射集 |
区别:
输入空间、输出空间、特征空间可以是相同空间,也可以不是同一空间。
通常输出空间远远小于输入空间。
模型定义在特征空间上,一个实例由特征向量表示。2机器学习分类:
按输出空间分类:分类(离散)、回归(连续)、结构化学习
按数据标记分类:半监督、监督、无监督、强化学习(?)
按目标函数学习策略:在线学习、批量式、主动学习
按目标函数的模型:产生式(对p(X,y)进行建模,朴素贝叶斯、HMM)、判别式(直接学习p(y|X);k近邻、感知机、决策树、logistic分类器、SVM、Boosting、CFR)
方法=模型h+策略Loss+算法(求grad)
基本概念:
输入与输出的随机变量遵循联合概率分布P(X,Y)
X和Y有联合概率分布的假设就是监督学关于数据的基本假设
训练数据与测试数据是依据P(X,Y)独立同分布产生的
独立
同分布















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









