







第二个:识别原理
- 架构说明-Tesseract的识别步骤大致如下:
1. 连通区域分析,检测出字符区域区域(轮廓外形),以及子轮廓。在此阶段轮廓线集成为块区域。(it is simple to detect inverse text and recognize it as easily as black-on-white text,outlines are gathered together, purely by nesting, into Blobs.)
2. 由字符轮廓和块区域得出文本行(Blobs are organized into text lines),以及通过空格(字符间距)识别出单词。固定字宽文本(fixed pitch)通过字符单元分割出单个字符,而对百分号的文本(Proportional text)通过一定的间隔(空格)和模糊间隔(fuzzy spaces)来分割;
3. 两阶段识别过程之第一阶段:依次对每个单词进行分析,然后传递给自适应分类器,分类器有学习能力,先分析的且满足条件的单词也作为训练样本,所以后面的字符(比如页尾)识别更准确;两阶段识别过程之第二阶段:此时,页首的字符识别相对而言比较不准确,所以tesseract会再次对识别不太好的字符识别是其精度得到提高。
4.最后,识别含糊不清的空格,及用其他方法,如由笔画高度(x-height),识别小写字母(small-cap)的文本。
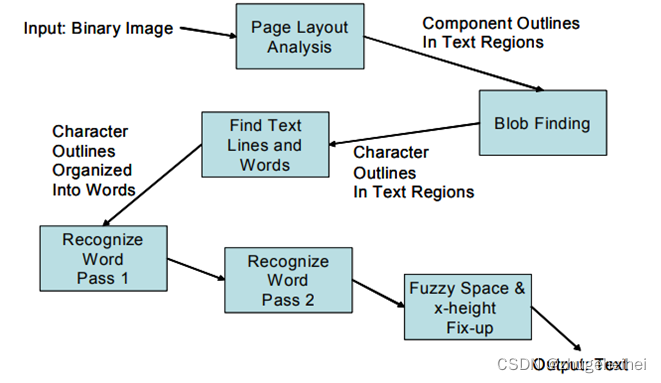
- 文本行和单词的查找技术(Blobs:连通区域、连通域、连通分量)
a. 连通域分析及过滤:假设页面布局分析(page layout analysis)大致确定了文本区域和文本尺寸,一个简单百分位高度过滤器(percentile height filter)可以将跨行大写字母及纵向粘连一起的字符过滤掉,利用字符的高度信息,选取所有字符的中值高度,通过高度的比例调节去掉一些无关的块,比如标点符号,变音符和噪声等;
b. 排序、创建初始行、基线拟合:对块区域的x坐标排序,运用α算法创建初始行,然后利用坐标拟合基线/直线(baseline),拟合方法:中位数最小方差拟合(least median of squares fit)à>二次线条+最小二乘法
c. 进一步,拟合文本行的形状,利用四次多项式,将文本行看成螺线形,采用最小二乘法拟合
d. 固定间隔检测和分割:检测出等距文本(fixed pitch text)并立刻分割为字符,中断之后的单词识别阶段的分割和分类操作,对粘连的文本进行分割(chopping)
e. 对非等距字体如百分号,斜体等问题,利用中线、基准线之间的空白大小,来分割字符,对接近阈值的空间被视为模糊空间,最后阶段进行处理。
注:相关函数:
页面结构分析:PageIterator * tesseract::TessBaseAPI::AnalyseLayout()
获取页面结构分析结果:Boxa * tesseract::TessBaseAPI::GetRegions(Pixa ** pixa)
连通域分析:Boxa * tesseract::TessBaseAPI::GetConnectedComponents;
获取每一块(block由页面结构分析获得)中的文字方向:
void tesseract::TessBaseAPI::GetBlockTextOrientations
获取Strip区域:Boxa * tesseract::TessBaseAPI::GetStrips
获取文本行:Boxa * tesseract::TessBaseAPI::GetTextlines
以Boxa格式获取文字:Boxa * tesseract::TessBaseAPI::GetWords(Pixa ** pixa)
- 单词识别
上面得到的字符送入分类器,反之非固定间隔的最后处理。
首先是分割粘连字符,将凹进去的轮廓点作为备选分割点,分割后,进行识别,如果都失败,就认为字符破损不全,修补字符(associator)。
然后对破碎的字符,放入associator,它采用利用A*算法搜索最优的字符组合,直到达到满意的识别结果。(识别成功的关键是字符分类器可以很好的识别破碎的字符)
(A*算法尽可能多的组合分割的字符,通过维护访问状态的哈希表隐藏分割,算法引入了优先级队列,存放候选的新状态/组合,并通过分类来评估当前操作)
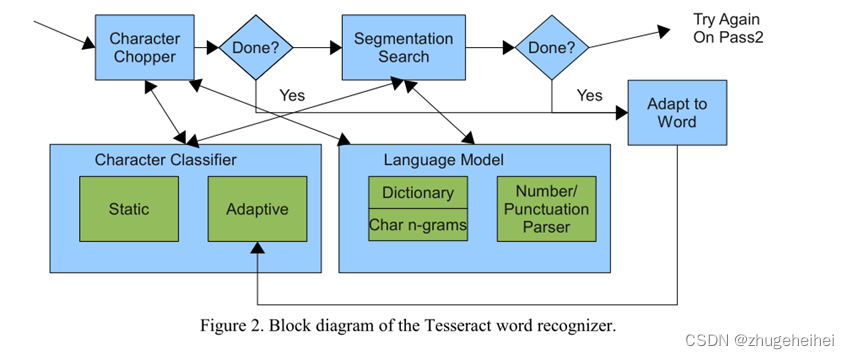
- 静态字符识别(分类器)
PART1:特征
最初:拓扑特征,但是不适用现实的图形
然后:将字符近似为多边形作为特征,但不适合于破碎字符
突破:训练阶段的特征不必和识别的特征相同。训练阶段用近似多边形作为特征,识别阶段,抽取字符的轮廓特征(固定的小的长度)并归一化,然后将训练集中的原型特征再与之进行多对一的方式匹配。(matched many-to-one against the clustered
prototype features of the training data.)
演示:如下图,待识别的短线和训练集提取的虚线特征。

优点:小特征匹配大原型可以适用于受损图像识别
缺点:二者直接的距离计算困难。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3419
3419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









