









目录
决策树模型
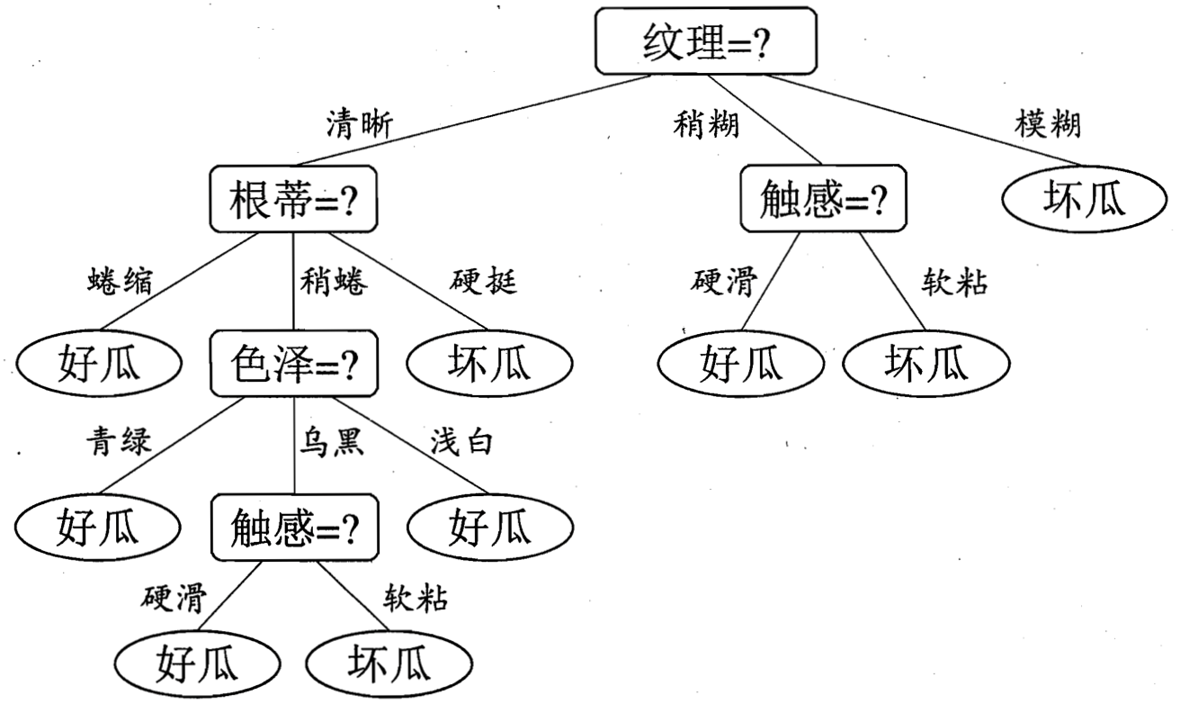
决策树是一种自上而下,对样本进行树形分类的过程,由结点和有向边组成。结点分为内部结点和叶结点,其中每个内部结点表示一个特征或属性,叶结点表示类别。从顶部根节点开始,所有样本聚在一起。经过根节点的划分,样本被分到不同的子结点中。再根据子结点的特征进一步划分,直至所有样本都被归到某一个类别(即叶结点)中。下图是周志华《机器学习》书中经典的例子。
关于决策树的学习:决策树学习的损失函数通常是正则化的极大似然函数。决策树学习的策略是以损失函数为目标函数的最小化。当损失函数确定以后,学习问题就变为在损失函数意义下选择最优决策树的问题。因为从所有可能的决策树种选取最优决策树是NP问题,所以现实中决策树学习通常采用启发式方法,近似求解这一问题。这样得到的决策树是次优化的。
输入:训练集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x m , y m ) } D=\{(x_1,y_1),(x_2,y_2),\dots,(x_m,y_m)\} D={(x1,y1),(x2,y2),…,(xm,ym)} ,属性集 A = { a 1 , a 2 , … , a d } A=\{a_1,a_2,\dots,a_d\} A={a1,a2,…,ad}
过程:函数 T r e e G e n e r a t e ( D , A ) TreeGenerate(D, A) TreeGenerate(D,A)生成结点 n o d e node node;
i f D if \ D if D中样本全属于同一类别 C t h e n C \ then C then
将 n o d e node node标记为 C C C类叶结点; r e t u r n return return
e n d i f end \ if end if
i f A = ∅ O R D if \ A = \emptyset\ OR\ D if A=∅ OR D中样本在 A A A上取值相同 t h e n then then
将 n o d e node node标记为叶结点,其类别标记为 D D D中样本最多的类; r e t u r n return return
从 A A A中选择较优划分属性 a ∗ a_* a∗;
f o r a ∗ for \ a_* for a∗的每一个值 a ∗ v d o a_*^v \ \ do a∗v do
为 n o d e node node生成一个分支;令 D v D_v Dv表示 D D D在 a ∗ a_* a∗上取值为 a ∗ v a_*^v a∗v的样本子集;
i f D v if \ D_v if Dv为空 t h e n then then
将分支结点标记为叶结点,其类别标记为D中样本最多的类; r e t u r n return return
e l s e else else
以 T r e e G e n e r a t e ( D v , A { a ∗ } ) TreeGenerate(D_v,A\ \{a_*\}) TreeGenerate(Dv,A {a∗})为分支结点
e n d i f end\ if end if
e n d f o r end \ for end for
输出:以 n o d e node node为根结点的一颗决策树
来自周志华《机器学习》
显然,决策树的生成是一个递归过程,在决策树算法中,有三种情形会导致递归返回:
1、当前结点包含的样本全属于同一类别,无需划分
2、当前结点属性集为空,或是所有样本在所有属性上取值相同,无法划分
3、当前结点包含的样本集合为空,不能划分
这里情形2是在是在利用当前结点的后验分布,情形3则是把父结点的样本分布作为当前结点的先验分布
模型与划分
从决策树学习的逻辑可以看出,第8行和第10行,即如何找到最优划分属性和这个属性的最优划分点最为关键。随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的”纯度“越来越高。
从样本类型的角度,ID3只能处理离散型变量,而C4.5和CART都可以处理连续型变量。C4.5处理连续型变量时,通过对数据排序之后找到类别不同的切割线作为切分点,根据切分点把连续属性转化为布尔型,从而将连续型变量转换多个取值区间的离散型变量。CART由于构建时每次都会对特征进行二值划分,因此可以很好地适用于连续型变量。
从应用角度,ID3和C4.5只能用于分类任务,而CART(Classification and Regression Tree)不仅可以用于分类,还可以应用于回归任务。
从其他角度,ID3对样本特征缺失值敏感,而C4.5和CART可以对缺失值进行不同方式的处理;ID3和C4.5可以在每个结点上产生出多叉分支,且每个特征在层级之间不会复用,而CART每个结点只会产生两个分支(二叉树),且每个特征可以被重复使用;ID3和C4.5通过剪枝来权衡树的准确性和泛化能力,而CART直接利用全部数据发现所有可能的树结构进行对比。
以下为三个模型举例数据(buys_computer为类别):

ID3 信息增益(Information Gain)
信息熵(信息熵越高说明不确定性越高)
D k D_k Dk是样本集合 D D D 中属于第 k k k 类的样本子集, ∣ D k ∣ |D_k| ∣Dk∣ 该子集的元素个数, ∣ D ∣ |D| ∣D∣ 样本集合的元素个数:
H ( D ) = − ∑ k = 1 K p k l o g 2 ( p k ) = − ∑ k = 1 K ∣ D k ∣ ∣ D ∣ l o g 2 ∣ D k ∣ ∣ D ∣ H(D)=-\sum \limits_{k=1}^Kp_klog_2(p_k)=-\sum \limits_{k=1}^K\frac{|D_k|}{|D|}log_2\frac{|D_k|}{|D|} H(D)=−k=1∑Kpklog2(pk)=−k=1∑K∣D∣∣Dk∣log2∣D∣∣Dk∣
经验条件熵(按特征A划分)
D i D_i Di表示 D D D 中特征 A A A 取第 i i i 个值的样本子集, D i k D_{ik} Dik 表示 D i D_i Di 中属于第 k k k 类的样本子集:
H ( D ∣ A ) = ∑ i = 1 n p ( i ) H ( D ∣ A = i ) = ∑ i = 1 n ∣ D i ∣ ∣ D ∣ × H ( D i ) = ∑ i = 1 n ∣ D i ∣ ∣ D ∣ ( − ∑ k = 1 K ∣ D i k ∣ ∣ D i ∣ l o g 2 ∣ D i k ∣ ∣ D i ∣ ) H(D|A)=\sum\limits_{i=1}^np(i)H(D|A=i)=\sum\limits_{i=1}^n\frac{|D_i|}{|D|}\times H(D_i)=\sum\limits_{i=1}^n\frac{|D_i|}{|D|}(-\sum \limits_{k=1}^K\frac{|D_{ik}|}{|D_i|}log_2\frac{|D_{ik}|}{|D_i|}) H(D∣A)=i=1∑np(i)H(D∣A=i)=i=1∑n∣D∣∣Di∣×H(Di)=i=1∑n∣D∣∣Di∣(−k=1∑K∣Di∣∣Dik∣log2∣Di∣∣Dik∣)
信息增益(Information Gain):
G
a
i
n
(
A
)
=
H
(
D
)
−
H
(
D
∣
A
)
Gain(A)=H(D)-H(D|A)
Gain(A)=H(D)−H(D∣A)
示例:
H
(
D
)
=
I
(
9
,
5
)
=
−
9
14
l
o
g
2
(
9
14
)
−
5
14
l
o
g
2
(
5
14
)
=
0.940
H(D) = I(9,5) = -\frac{9}{14}log_2(\frac{9}{14})-\frac{5}{14}log_2(\frac{5}{14}) = 0.940
H(D)=I(9,5)=−149log2(149)−145log2(145)=0.940
H ( D ∣ a g e ) = 5 14 I ( 2 , 3 ) + 4 14 I ( 4 , 0 ) + 5 14 I ( 3 , 2 ) = 0.694 H(D|age)=\frac{5}{14}I(2,3)+\frac{4}{14}I(4,0)+\frac{5}{14}I(3,2)=0.694 H(D∣age)=145I(2,3)+144I(4,0)+145I(3,2)=0.694 , 5 14 I ( 2 , 3 ) \frac{5}{14}I(2,3) 145I(2,3) 代表 a g e < = 30 age<=30 age<=30 的14个中有5个,且2个yes,3个no,同理剩下两项各代表4个 31 < = a g e < = 40 31<=age<=40 31<=age<=40 和5个 a g e > 40 age>40 age>40的样本
所以, G a i n ( a g e ) = H ( D ) − H ( D ∣ a g e ) = 0.246 Gain(age)=H(D)-H(D|age)=0.246 Gain(age)=H(D)−H(D∣age)=0.246 ,同理得 G a i n ( i n c o m e ) = 0.029 Gain(income)=0.029 Gain(income)=0.029 , G a i n ( s t u d e n t ) = 0.151 Gain(student)=0.151 Gain(student)=0.151 , G a i n ( c r e d i t r a t i n g ) = 0.048 Gain(credit_rating)=0.048 Gain(creditrating)=0.048, G a i n ( a g e ) Gain(age) Gain(age) 最高,所以按年龄划分
C4.5 增益率(Gain ratio)
ID3采用信息增益作为评价标准,会倾向于取值较多的特征。因为信息增益反应的是给定条件不确定性减少的程度,特征取值越多就意味着确定性高,也就是条件熵越小,信息增益越大。这在实际应用中是一个缺陷。比如我们引入“DNA”特征,每个人的“DNA”都不同,如果ID3按照“DNA"特征进行划分一定是最优的,但这种泛化能力非常弱。因此,C4.5实际上是对ID3进行优化,通过引入信息增益比,一定程度上对取值比较多的特征进行惩罚,避免ID3出现的过拟合的特性,提升决策树的泛化能力。
G a i n R a t i o ( A ) = G a i n ( A ) S p l i t I n f o A ( D ) GainRatio(A)=\frac{Gain(A)}{SplitInfo_A(D)} GainRatio(A)=SplitInfoA(D)Gain(A) ,其中 S p l i t I n f o A ( D ) = − ∑ j = 1 v ∣ D j ∣ D × l o g 2 ( ∣ D j ∣ ∣ D ∣ ) SplitInfo_A(D)=-\sum\limits_{j=1}^v\frac{|D_j|}{D}\times log_2(\frac{|D_j|}{|D|}) SplitInfoA(D)=−j=1∑vD∣Dj∣×log2(∣D∣∣Dj∣)
求得各特征增益率,选出信息增益率最大的特征进行切分
示例:
S
p
l
i
t
I
n
f
o
i
n
c
o
m
e
(
D
)
=
−
4
14
×
l
o
g
2
(
4
14
)
−
6
14
×
l
o
g
2
(
6
14
)
−
4
14
×
l
o
g
2
(
4
14
)
=
1.557
SplitInfo_{income}(D)=-\frac{4}{14}\times log_2(\frac{4}{14})-\frac{6}{14}\times log_2(\frac{6}{14})-\frac{4}{14}\times log_2(\frac{4}{14})=1.557
SplitInfoincome(D)=−144×log2(144)−146×log2(146)−144×log2(144)=1.557
G a i n R a t i o ( i n c o m e ) = 0.029 1.557 = 0.019 GainRatio(income)=\frac{0.029}{1.557}=0.019 GainRatio(income)=1.5570.029=0.019
CART 基尼指数(Gini index)
基尼指数描述数据的纯度,对于数据集 D D D ,有 n n n 个类别的话,则:
G
i
n
i
(
D
)
=
1
−
∑
j
=
1
n
p
j
2
=
1
−
∑
j
=
1
n
(
∣
D
j
∣
∣
D
∣
)
2
Gini(D)=1-\sum\limits_{j=1}^np_j^2=1-\sum\limits_{j=1}^n(\frac{|D_j|}{|D|})^2
Gini(D)=1−j=1∑npj2=1−j=1∑n(∣D∣∣Dj∣)2
CART的特征可以重复使用,每次只产生两个分支,设根据特征
A
A
A 将数据集分为
D
1
D_1
D1 和
D
2
D_2
D2 ,则:
G
i
n
i
A
(
D
)
=
∣
D
1
∣
∣
D
∣
G
i
n
i
(
D
1
)
+
∣
D
2
∣
∣
D
∣
G
i
n
i
(
D
2
)
Gini_A(D)=\frac{|D_1|}{|D|}Gini(D_1)+\frac{|D_2|}{|D|}Gini(D_2)
GiniA(D)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
求得各特征所有切分点的Gini index后,找到最小的进行切分
示例:
G
i
n
i
(
D
)
=
1
−
(
9
14
)
2
−
(
5
14
)
2
=
0.459
Gini(D)=1-(\frac{9}{14})^2-(\frac{5}{14})^2=0.459
Gini(D)=1−(149)2−(145)2=0.459
例子中有9个有电脑5个没有(类别)按收入low,medium一组(10个样本在
D
1
D_1
D1 ),high一组(4个在
D
2
D_2
D2 )切分的话:
G
i
n
i
l
o
w
,
m
e
d
i
u
m
∈
i
n
c
o
m
e
(
D
)
=
G
i
n
i
h
i
g
h
∈
i
n
c
o
m
e
(
D
)
Gini_{{low,medium}\in income}(D)=Gini_{{high}\in income}(D)
Ginilow,medium∈income(D)=Ginihigh∈income(D)
=
10
14
G
i
n
i
(
D
1
)
+
4
14
G
i
n
i
(
D
2
)
=\frac{10}{14}Gini(D_1)+\frac{4}{14}Gini(D_2)
=1410Gini(D1)+144Gini(D2)
=
10
14
(
1
−
(
7
10
)
2
−
(
3
10
)
2
)
+
4
10
(
1
−
(
2
4
)
2
−
(
2
4
)
2
)
=
0.443
=\frac{10}{14}(1-(\frac{7}{10})^2-(\frac{3}{10})^2)+\frac{4}{10}(1-(\frac{2}{4})^2-(\frac{2}{4})^2)=0.443
=1410(1−(107)2−(103)2)+104(1−(42)2−(42)2)=0.443
同理得各特征所有切分的Gini Index,找到最小的那个进行切分最优
剪枝处理
一颗完全生长的决策树很容易出现过拟合问题,除了常规的机器学习解决过拟合的方法外,我们可以对决策树进行剪枝,常用的剪枝方法有预剪枝(Pre-Pruning)和后剪枝(Post-Pruning)。
预剪枝
预剪枝的核心思想是在树中结点进行扩展之前,先计算当前的划分能否带来模型泛化能力的提升,如果不能,则不再继续生长子树。预剪枝对于何时停止决策树的生长有以下几种方法:
1、当树到达一定深度的时候,停止树的生长
2、当到达当前结点的样本数量小于某个阈值的时候,停止树的生长
3、计算每次分裂对测试集的准确度提升,当小于某个阈值的时候,不再继续拓展
预剪枝具有思想直接、算法简单、效率高等特点,适合解决大规模问题。但如何准确地估计何时停止树的生长(即上述方法中的深度或阈值),针对不同问题会有很大差别,需要一定经验判断。且预剪枝存在一定局限性,有欠拟合风险,虽然当前的划分会导致测试集准确率降低,但在之后的划分中,准确率可能会有显著上升。
后剪枝
后剪枝的核心思想是让算法生成一颗完全生长的决策树,然后从最底层向上计算是否剪枝。剪枝过程将子树删除,用一个叶子结点替代,该节点的类别按多数投票原则进行判断。同样地,后剪枝也可以通过在测试集上的准确率进行判断,如果剪枝过后准确率有所提升,则进行剪枝。相比于预剪枝,后剪枝方法通常可以得到泛化能力更强的决策树,但时间开销会更大。
常见的后剪枝方法包括错误率降低剪枝 (Reduced Error Pruning, REP),悲观剪枝(Pessimistic Error Pruning, PEP)、代价复杂度剪枝(Cost Complexity Pruning, CCP)、最小误差剪枝(Minimum Error Pruning, MEP)、CVP(Critical Value Pruning)、OPP(Optimal Pruning)。















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









