







集群搭建完成后,性能调优是必不可少的,调优分为 硬件调优、组件调优、任务调优,本文档将这三部分调优的内容进行穿插讲解,是最全面的大数据调优文档,用了的都说爽,非常 nice !!!
1 HDFS
1.1 守护进程
1.1.1 namenode
1.1.1.1 内存
hadoop-env
- hadoop_namenode_heapsize
- 默认配置根据集群Master实例规格配置,比如128GB机型配置为 7GB 左右
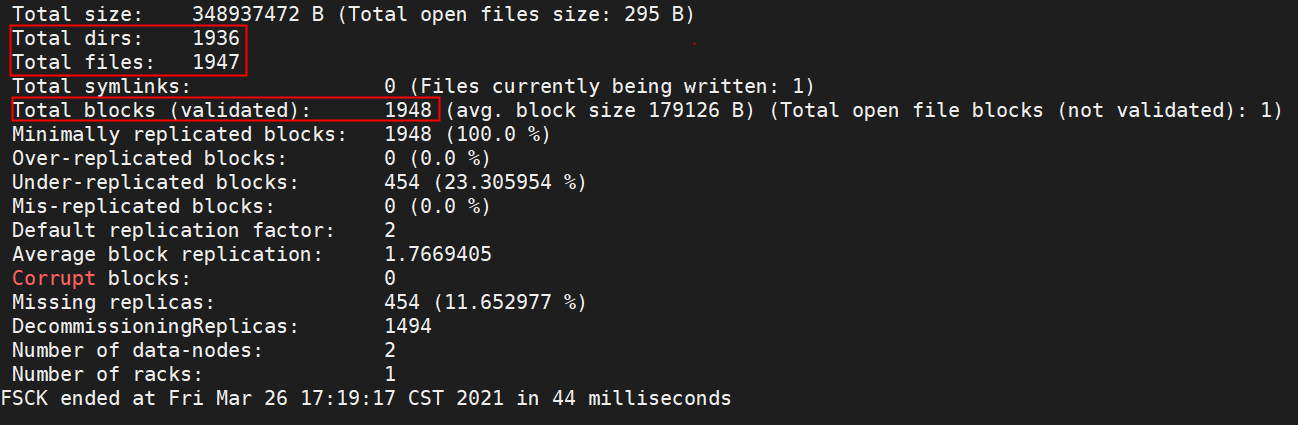
- 根据最大文件数和数据块(Block)数预估NameNode内存。NameNode Heap Size = (目录及文件数量 198 字节 + 数据块数量 176 字节) x 2
通过hdfs fsck / 获得dirs(目录),files(文件),block(数据块)具体的值
1.1.1.2 线程数
- dfs.namenode.handler.count
- 默认配置为10
- 实际可以根据集群规模扩展,Handler Count = DataNode Number x 5
1.1.1.3 rpc
1.1.2 datanode
1.1.2.1 内存
- hadoop-env
hadoop_datanode_heapsize
(数据块总数 x 3副本 / 集群Core节点数目) / 1000000 (GB)
1.1.2.2 线程数
dfs.datanode.max.transfer.threads
(1)、默认配置为4096
(2)、对于读写并发较大的集群(比如繁忙的HBase集群或者Hive动态分区作业可能出现写入QPS大于1000),可将配置调整为8192
dfs.datanode.max.xcievers
DataNode 如同 Linux 上文件 句柄限制。 当 DataNode 上面的连接数超过配置中的设置时, DataNode 就会拒绝 连接,修改设置为 65536
1.1.2.3 网络
dfs.datanode.balance.bandwidthPerse
执行 start-balancer.sh 的带宽,默认为 1048576 (1MB/s),将其调大,比如20MB/s。
1.2 存储优化
1.2.1 目录配置
dfs.namenode.edits.dir 与 dfs.namenode.name.dir 分开
dfs.datanode.data.dir
将数据存储分布在各个磁盘上
hadoop.tmp.dir
在每个磁盘上都建立一个临时目录
1.2.1.1 缓存
io.file.buffer.size
Hadoop 缓冲区大小用于 HDFS 的文件的读写和 map 过程的 中间结果输出,默认为 4KB,增加到 128KB。
1.2.1.2 小文件合并
har归档
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。
HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。具体说来,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。
使用命令进行小文件合并:
hadoop archive -archiveName input.har -p /input /output
CombineTextInputFormat
CombineTextInputFormat用于将多个小文件在切片过程中生成的一个单独切片或者少量的切片
开启uber模式,实现JVM重用(计算方向)
mapreduce.job.ubertask.enable
默认情况下,每个Task任务都需要启动一个JVM来运行,如果Task任务计算的数据量很小,可以让同一个JOB的多个Task运行在一个JVM中,不必为每个Task都开启一个JVM
2 Yarn
2.1 守护进程
2.1.1 resourcemanager
2.1.1.1 内存
yarn.nodemanager.resource.memory-mb
默认为 Worker 节点总内存减去其他应用的 Heap Size,并且为系统预留资源,可根据实际需求做调整
2.1.1.2 Cpu
yarn.nodemanager.resource.cpu-vcores
(1)、此参数在capacity-scheduler-yarn.scheduler.capacity.resource-calculator值为 DominantResourceCalculator 后生效。默认 resource-calculator 值为 DefaultResourceCalculator,此参数设置并不影响集群调度
(2)、默认值 = Worker节点CPU核数 x 2,对CPU密集型集群,可以将值调整为 Worker 节点 CPU核
2.1.2 nodemanager
2.1.2.1 内存
yarn.nodemanager.resource.memory-mb
表示物理节点有多少 内存加入资源池。设置该值时,注意为操作系统和其他服务预留资源
2.1.2.2 Cpu
yarn.nodemanager.resource.cpu-vcores
(1)、此参数在 capacity-scheduler - yarn.scheduler.capacity.resource-calculator 值为DominantResourceCalculator 后生效。默认 resource-calculator 值为 DefaultResourceCalculator,此参数设置并不影响集群调度
(2)、默认值 = Worker节点CPU核数 x 2,对CPU密集型集群,可以将值调整为 Worker 节点 CPU核
2.1.3 Container
根据container实际内存需要调整
yarn.scheduler.maximum-allocation-mb
单个任务(容器)能够申请到的最大内存资源,根据容器内存总量进 行设置,默认为 8GB。 如果设定为和参数 yarn.nodemanager.resource.memory-mb 一样,那 么表示单个任务使用的内存资源不受限制。
yarn.scheduler.minimum-allocation-mb
单个任务(容器)能够申请到的最小内存资源,默认为 1GB。
yarn.scheduler.maximum-allocation-vcores
单个任务(容器)能够申请到的最大虚拟 CPU 数,根据容器虚拟 CPU 总数进行设置,默认为 4。 如果设定为和参数 yarn.nodemanager.resource.cpu-vcores 一样,那么表示单个任务使用的 CPU 资源不受限制。
yarn.scheduler.minimum-allocation-vcores
单个任务(容器)能够申请到的最小虚拟 CPU 资源,默认为 1。
2.2 mr作业调优
2.2.1 map调优
- 基础设置
mapreduce.map.memory.mb
mapreduce.map.cpu.vcores
map 任务的内存和 cpu 占用量
mapred.child.java.opts
表示执行 Map 任务和 Reduce 任务的 JVM 参数,该配置还可 以配置 GC 等常见的 Java 选项 该参数粒度过粗, Map 任务和 Reduce 任务的内存需求和堆大小一般 不同,所以这些参数一般单数设定
- 合理设置map数
在分布式计算系统中,决定map数量的一个因素就是原始数据,在不加干预的情况下,原始数据有多少个块,就可能有多少个起始的task,因为每个task对应要去读取一个块的数据;当然这个也不是绝对的,当文件数量特别多,并且每个文件的大小特别小,那么我们就可以限制减少初始map对相应的task的数量,以减少计算资源的浪费,如果文件数量较少,但是单个文件较大,我们就可以增加map的task的数量,以减小单个task的压力。
在hive里面有个决定mapper的task数量的参数:mapred.map.tasks,因为决定mapper的task的数量因素相对比较复杂,所以这个参数不一定起作用,具体决定mapper的task数量的过程如下:
(1)hive的文件基本上都是存储在HDFS上,而HDFS上的文件,都是分块儿的,所以具体的hive数据文件在HDFS上分多少块,就可能是默认的hive起始task的数量,我们记做:default_mapper_num。在网上还有人这么解释,就是用数据总大小除以dfs的默认最大块大小(total_size/dfs.block.size)来决定初始默认数据分区数。
default_mapper_num = total_size/dfs.block.size
(2)mapred.min.split.size和mapred.max.split.size分别就需要指定的是hive计算的时候的进行split的最大值和最小值,当然我们要根据这两个参数得出一个最终的split的size,具体公式:
default_split_size = max(mapred.min.split.size, min(mapred.max.split.size, dfs.block.size))。
(3)第二步中我们确定了数据的split的size,也就是说要将数据按照这个size划分为多少个block,具体计算方式:
split_num = total_size/default_split_size;
(4)接下来就是我们决定具体的mapper的task数量
map_task_num = min(split_num, max(mapred.map.tasks, default_mapper_num))
所以从上面的过程来看,task的数量通过各个方面的限制,不至于task的数量太多,也不至于task的数量太少。要想提高task数量,就要降低mapper.min.split.size的数值,在一定的范围内可以减小default_split_size的数值,从而增加split_num的数量,也可增大mapred.map.tasks的数量。如果要减少task的数量,我们就可以提高mapper.map.tasks的数量
- spill文件输出数量
mapreduce.task.io.sort.mb
该参数表示 Map 任务的输出的环形缓冲区大小,默认为 100MB, 可以适当调大。
mapreduce.task.io.sort.factor
该参数为控制 Map 端和 Reduce 端的合并策略,表现为一次合并的文件数目,默认值为 10。该值如果过大会使合并时内存消耗过大,如果过小会增加合并次数。
mapreduce.map.sort.spill.percent(default:0.80)
该参数表示 Map 任务的输出的环形缓冲区的阈值,一旦缓存区 的内容占缓冲区的比例超过该值,则将缓冲区的内容刷写到mapreduce.cluster.local.dir 所配置的目录,默认为 0.8,建议不低于 0.5。
- combine(排序和合并/sort&merge)
min.num.spill.for.combine 默认是3
spill的文件数默认情况下有三个的时候就要进行combine操作,最终减少磁盘数据;
- 压缩设置
mapreduce.map.output.compress(default:false)
设置为true进行压缩,数据会被压缩写入磁盘,,压缩一般可以10倍的减少IO操作
mapreduce.map.output.compress.codec(default:org.apache.hadoop.io.compress.DefaultCodec)
压缩算法,推荐使用SnappyCodec;
2.2.1.1 reduce调优
mapreduce.reduce.memory.mb
该参数表示执行 Reduce 任务需要的内存大小。 它可以从 mapreduce.map.java.opts 参数设定的值继承,如果没有设 定,该值根据容器内存设置。 一般要大于mapreduce.map.memory.mb
mapreduce.reduce.cpu.vcores
该参数表示执行 Reduce 任务需要的虚拟 CPU 数,默认值为 1。根据容器虚拟 CPU 数设定,可以适当加大,并且该值与参数 mapreduce.reduce.memory.mb 成线性比例才不至于浪费资源。 一般要大于 mapreduce.map.cpu.vcores 。
mapreduce.reduce.merge.inmem.threshold
mapreduce.reduce.input.buffer.percent
在reduce端,如果能够让所有数据都保存在内存中,可以达到最佳的性能。通常情况下,内存都保留给reduce函数,但是如果reduce函数对内存需求不是很高,将(触发合并的map输出文件数)设为0,(用于保存map输出文件的堆内存比例)设为1.0,可以达到很好的性能提升。
mapreduce.reduce.shuffle.parallelcopies
默认5
对mapper端输出数据的获取。mr程序reducer copy数据的线程数。当map很多并且完成的比较快的job的情况下调大,有利于reduce更快的获取属于自己部分的数据。如果设置过高,会导致大量数据在网络同时传 输,引起 I/O 压力过大,可以设定方式为 4 * lgN ,其中 N 为集群容量大小。
数据合并(sort&merge)
mapreduce.reduce.shuffle.input.buffer.percent 默认0.70;
reduce复制map数据的时候指定的内存堆大小百分比,适当的增加该值可以减少map数据的磁盘溢出,能够提高系统能。
mapreduce.reduce.shuffle.merge.percent 默认0.66;
reduce进行shuffle的时候,用于启动合并输出和磁盘溢写的过程的阀值。如果允许,适当增大其比例能够减少磁盘溢写次数,提高系统性能。同mapreduce.reduce.shuffle.input.buffer.percent一起使用。
(4)合理设置reduce数
使用过多的Reduce任务则意味着复杂的shuffle,并使输出文件的数量激增。
在真正的集群环境下,如果默认,那么所有的中间数据会发送给唯一的Reducer,导致任务变得非常缓慢。通常reduce数量是0.95或者1.75*(nodes * mapreduce.tasktracker.reduce.tasks.maximum)。
2.2.1.2 整体
mapreduce.map.speculative
mapreduce.reduce.speculative
开启推测机制
mapreduce.cluster.local.dir
mr任务中间结果保存路径,配置多个目录可以提高io
mapred.child.java.opts
表示执行 Map 任务和 Reduce 任务的 JVM 参数,该配置还可 以配置 GC 等常见的 Java 选项 该参数粒度过粗, Map 任务和 Reduce 任务的内存需求和堆大小一般 不同,所以这些参数一般单数设定
3 Hive
3.1 守护进程
3.1.1 hiveserver
hive_server2_heapsize
默认配置 512(MB):适合测试和小规模集群
连接数 5 -10:4GB - 6GB
连接数 11 - 20:6GB - 12GB
连接数 21 - 40:12GB - 20GB
连接数 41 - 80:20GB - 30GB
- 超时时间
hive.server2.idle.session.timeout 社区版本默认7d,EMR默认改为6h
hive.server2.idle.operation.timeout 社区版本默认5d,EMR默认改为6h
hive.server2.session.check.interval 社区版本默认6h,EMR默认改为1h
3.1.2 metastore
hive_metastore_heapsize
默认配置 512(MB):适合测试和小规模集群
连接数 5- 10:4GB
连接数 11 - 20:4GB - 10GB
连接数 21 - 40:10GB - 15GB
连接数 41 - 80:15GB - 20GB
3.1.3 Hive Cli 内存
根据实际情况进行内存大小调整,客户默认4G。
export HADOOP_CLIENT_OPTS=“-Xmx4096m $HADOOP_CLIENT_OPTS”
3.2 作业参数调优
3.2.1 Fetch task
将只有SELECT, FILTER, LIMIT转化为FETCH,不执行mapreduce, 减少等待时间
set hive.fetch.task.conversion=more;
3.2.1.1 JVM重用
hive语句最终要转换为一系列的mapreduce job的,而每一个mapreduce job是由一系列的map task和Reduce task组成的,默认情况下,mapreduce中一个map task或者一个Reduce task就会启动一个JVM进程,一个task执行完毕后,JVM进程就退出。这样如果任务花费时间很短,又要多次启动JVM的情况下,JVM的启动时间会变成一个比较大的消耗,这个时候,就可以通过重用JVM来解决。这个设置就是制定一个jvm进程在运行多次任务之后再退出,这样一来,节约了很多的 JVM的启动时间。
–JVM重用特别是对于小文件场景或者task特别多的场景
set mapred.job.reuse.jvm.num.tasks=10;
3.2.1.2 并行化
让多个并不相互依赖stage并发执行,这样就节约了时间,提高了执行速度,但是如果集群资源匮乏时,启用并行化反倒是会导致各个job相互抢占资源而导致整体执行性能的下降。
开启任务并行执行
set hive.exec.parallel=true;
-同一个sql允许并行任务的最大线程数
set hive.exec.parallel.thread.number 默认为8;
3.3 HiveQL调优
3.3.1 利用分区表优化
分区表是在某一个或者某几个维度上对数据进行分类存储,一个分区对应于一个目录。在这中的存储方式,当查询时,如果筛选条件里有分区字段,那么hive只需要遍历对应分区目录下的文件即可,不用全局遍历数据,使得处理的数据量大大减少,提高查询效率。
当一个hive表的查询大多数情况下,会根据某一个字段进行筛选时,那么非常适合创建为分区表。
3.3.1.1 利用桶表优化
就是指定桶的个数后,存储数据时,根据某一个字段进行哈希后,确定存储再哪个桶里,这样做的目的和分区表类似,也是使得筛选时不用全局遍历所有的数据,只需要遍历所在桶就可以了。
hive.optimize.bucketmapJOIN=true;
hive.input.format=org.apache.hadoop.hive.ql.io.bucketizedhiveInputFormat;
hive.optimize.bucketmapjoin=true;
hive.optimize.bucketmapjoin.sortedmerge=true;
3.3.1.2 对于整个sql的优化
- where 条件优化
wher 只在 map 端阶段执行,不会在 reduce 阶段执行,尽早地过滤数据,减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段。 - join 优化
① 优先过滤后再 join,最大限度地减少参与 join 的数据量。
② 小表 join 大表原则
应该遵守小表 join 大表原则,原因是join操作的 reduce 阶段,位于 join 左边的表内容会被加载进内存,将条目少的表放在左边,可以有效减少发生内存溢出的几率。join 中执行顺序是从做到右生成 job,应该保证连续查询中的表的大小从左到右是依次增加的。
③ join on 条件相同的放入一个 job
hive 中,当多个表进行 join 时,如果 join on 的条件相同,那么他们会合并为一个 mapreduce job,所以利用这个特性,可以将相同的 join on 的放入一个job来节省执行时间。
select pt.page_id,count(t.url) PV
from rpt_page_type pt
join (select url_page_id,url from trackinfo where ds='2016-10-11' ) t on pt.page_id=t.url_page_id
join (select page_id from rpt_page_kpi_new where ds='2016-10-11' ) r on t.url_page_id=r.page_id group by pt.page_id;
④Common/shuffle/Reduce JOIN
发生在reduce 阶段, 适用于大表连接大表(默认的方式)
⑤Map JOIN
连接发生在map阶段 ,适用于小表 连接 大表,大表的数据从文件中读取,小表的数据存放在内存中(hive中已经自动进行了优化,自动判断小表,然后进行缓存)
set hive.auto.convert.join=true;
⑥SMB JOIN,Sort -Merge -Bucket Join 对大表连接大表的优化,用桶表的概念来进行优化。在一个桶内发送生笛卡尔积连接(需要是两个桶表进行join)
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
- Group By 数据倾斜优化
Group By很容易导致数据倾斜问题,因为实际业务中,通常是数据集中在某些点上,这样会造成对数据分组后,某一些分组上数据量非常大,而其他的分组上数据量很小,而在mapreduce程序中,同一个分组的数据会分配到同一个reduce操作上去,导致某一些reduce压力很大,其他的reduce压力很小,这就是数据倾斜,整个job 执行时间取决于那个执行最慢的那个reduce。
解决这个问题的方法是配置一个参数:set hive.groupby.skewindata=true。 当选项设定为true,生成的查询计划会有两个MR job。第一个MR job 中,map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。 - Order By 优化
因为order by只能是在一个reduce进程中进行的,所以如果对一个大数据集进行order by,会导致一个reduce进程中处理的数据相当大,造成查询执行超级缓慢。 - 减少子查询内的 group by 、 COUNT(DISTINCT)、MAX、MIN,可以减少job的数量。
- 不要使用count (distinct cloumn),改使用子查询。
- 如果union all的部分个数大于2,或者每个union部分数据量大,应该拆成多个insert into 语句,这样会提升执行的速度。尽量不要使用union (union 去掉重复的记录)而是使用 union all 然后在用group by 去重。
- 中间临时表使用orc、parquet等列式存储格式。
- 单个SQL所起的JOB个数尽量控制在5个以下。
4 Spark
4.1 Thrift server
4.1.1 基础配置
spark_thrift_daemon_memory
默认配置 512(MB):适合测试和小规模集群
连接数 5 -10:4GB - 6GB
连接数 11 - 20:6GB - 12GB
连接数 21 - 40:12GB - 20GB
连接数 41 - 80:20GB - 30GB
spark.executor.memory
spark.executor.cores
单个execcutor资源,建议核数和内存比按照 1
c:4g-1c:8g 进行配置
4.1.2 动态资源分配
Spark thrift serve r的资源可以通过动态资源分配增加 executor 的数量。具体配置如下:
4.1.2.1 必要配置
spark.dynamicAllocation.enabled 设置为true
spark.shuffle.service.enabled 设置为true
yarn-site.xml
yarn.nodemanager.aux-services
yarn.nodemanager.aux-services.spark_shuffle.class org.apache.spark.network.yarn.YarnShuffleService
spark.shuffle.service.port 7337
4.1.2.2 扩缩策略
当有被挂起的任务(pending task)的时候,也就表示当前的executor数量还不足够所有的task并行运行,这时候spark会申请增加资源,
但是并不是出现pending task就立刻请求增加executor。由下面两个参数决定,如下:
- spark.dynamicAllocation.schedulerBacklogTimeout:
如果启用了动态资源分配功能,如果有pending task并且等待了一段时间(默认1秒),则增加executor
- spark.dynamicAllocation.sustainedSchedulerBacklogTimeout:
随后每隔N秒(默认1秒),再检测pending task,如果仍然存在,增加executor。
此外每轮请求的executor数量是指数增长的。 比如,在第一轮中添加1个executor,然后在随后的轮中添加2、4、8,依此类推。
- spark.dynamicAllocation.executorIdleTimeout:默认60秒
如果某executor空闲超过了一段时间,则remove此executor:
4.1.2.3 扩缩容资设定
- spark.dynamicAllocation.initialExecutors:
初始executor数量,如果–num-executors设置的值比这个值大,那么将使用–num-executors设置的值作为初始executor数量。
- spark.dynamicAllocation.maxExecutors:
executor数量的上限,默认是无限制的。
- spark.dynamicAllocation.minExecutors:
executor数量的下限,默认是0个
- spark.dynamicAllocation.cachedExecutorIdleTimeout:
如果executor内有缓存数据(cache data),并且空闲了N秒。则remove该executor。默认值无限制。也就是如果有缓存数据,则不会remove该executor
4.2 作业基本参数
4.2.1 提高并发度
适当提高并发度可以提升spark的处理性能,设置参数 spark.defalut.parallelism 来设置task数量
可以设置task的数量
- 至少设置成与spark Application 的总cpu core 数量相同。官方推荐的task数量,可以设置成spark Application 总cpu core数量的2~3倍。
- 给RDD重新设置partition的数量
使用rdd.repartition 来重新分区,该方法会生成一个新的rdd,使其分区数变大。一个partition对应一个task。
- 适当提高sparksql运行的task数量
通过设置参数 spark.sql.shuffle.partitions, 默认为200;可以适当增大,来提高并行度。比如设置为 spark.sql.shuffle.partitions=500
4.2.2 调节本地化等待时长
Spark 作业运行过程中,Driver 会对每一个 stage 的 task 进行分配。根据 Spark 的 task 分配算法,Spark 希望 task 能够运行在它要计算的数据算在的节点(数据本地化思想),这样就可以避免数据的网络传输。通常来说,task 可能不会被分配到它处理的数据所在的节点,因为这些节点可用的资源可能已经用尽,此时,Spark 会等待一段时间,默认 3s,如果等待指定时间后仍然无法在指定节点运行,那么会自动降级,尝试将 task 分配到比较差的本地化级别所对应的节点上,比如将 task 分配到离它要计算的数据比较近的一个节点,然后进行计算,如果当前级别仍然不行,那么继续降级。
Spark 本地化等待时长的设置如下:
val conf = new SparkConf().set("spark.locality.wait", "6")
4.3 shuffle相关参数调优
- spark.shuffle.file.buffer
默认值:32k
参数说明:该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
调优建议:可以适当增加这个参数的大小(比如64k),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。
- spark.reducer.maxSizeInFlight
默认值:48m
参数说明:该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。
调优建议:适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。
- spark.shuffle.io.maxRetries
默认值:3
参数说明:shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。
调优建议:对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。
- spark.shuffle.io.retryWait
默认值:5s
参数说明:具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是5s。
调优建议:建议加大间隔时长(比如60s),以增加shuffle操作的稳定性。
- spark.shuffle.manager
默认值:sort
参数说明:该参数用于设置ShuffleManager的类型
调优建议:由于SortShuffleManager默认会对数据进行排序,因此如果你的业务逻辑中需要该排序机制的话,则使用默认的SortShuffleManager就可以;而如果你的业务逻辑不需要对数据进行排序,那么建议参考后面的几个参数调优,通过bypass机制或优化的HashShuffleManager来避免排序操作,同时提供较好的磁盘读写性能。
- spark.shuffle.sort.bypassMergeThreshold
默认值:200
参数说明:当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
调优建议:当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量(200)。那么此时就会自动启用bypass机制,map-side就不会进行排序了,减少了排序的性能开销。
- spark.storage.memoryFraction(具体参见统一内存模型)
默认值:0.6
参数说明:该参数用于设置RDD持久化数据在executor内存中的占比,默认是0.6,根据你选择的不同的持久化数据策略级别,如果内存不够了时,可能数据就不会持久化或者数据会写入到内存中。
调优建议:如果spark任务中,有较多的RDD持久化数据操作,这个值可以适当提高一些,保证持久化的数据在能够容乃在内存中。如果spark任务中shuffle操作较多,那么这个参数的值适当降低一些比较合适,更多的内存空间给shuffle操作。
4.4 开发调优
- 重用RDD
把多次使用到的rdd,也就是公共rdd进行持久化,避免后续需要,再次重新计算,提升效率。
- 引入广播变量
spark中分布式执行的代码需要传递到各个executor的task上运行。对于一些只读、固定的数据,每次都需要Driver广播到各个Task上,这样效率低下。广播变量允许将变量只广播给各个executor。
- 尽量避免使用shuffle类算子
shuffle涉及到数据要进行大量的网络传输。
使用reduceByKey、join、distinct、repartition等算子操作,这里都会产生shuffle。
避免产生shuffle:Broadcast+map的join操作,不会导致shuffle操作。
使用map-side预聚合的shuffle操作,减少数据的传输量,提升性能。
建议使用reduceByKey或者aggregateByKey算子来替代掉groupByKey算子。因为reduceByKey和aggregateByKey算子都会使用用户自定义的函数对每个节点本地的相同key进行预聚合。
- 使用高性能的算子
1)使用reduceByKey/aggregateByKey替代groupByKey;
2)使用mapPartitions替代普通map;mapPartitions一次函数调用会处理一个partition所有的数据。
3)使用foreachPartitions替代foreach;一次函数调用处理一个partition的所有数据。
4)使用filter之后进行coalesce操作;
使用coalesce算子,手动减少RDD的partition数量;
5)使用repartitionAndSortWithinPartitions替代repartition与sort类操作;如果需要在repartition重分区之后,还要进行排序,建议直接使用repartitionAndSortWithinPartitions算子。因为该算子可以一边进行重分区的shuffle操作,一边进行排序。
set hive.execution.engine=tez;
--查询时必须使用的配置文件 勿删
-- 打开笛卡尔积
set hive.strict.checks.cartesian.product=false;
set hive.exec.parallel=TRUE;
set hive.exec.parallel.thread.number=8;
set hive.exec.input.listing.max.threads=50;
set mapreduce.input.fileinputformat.list-status.num-threads=50;
-- mapreduce
set mapreduce.map.memory.mb=4096;
set mapreduce.map.java.opts=-Xmx3700m -XX:ParallelGCThreads=2 -XX:CICompilerCount=2 -XX:+UseParallelOldGC;
set mapreduce.reduce.memory.mb=4096;
set mapreduce.reduce.java.opts=-Xmx3700m -XX:ParallelGCThreads=2 -XX:CICompilerCount=2 -XX:+UseParallelOldGC;
set yarn.app.mapreduce.am.resource.mb=3072;
set yarn.app.mapreduce.am.command-opts=-Xmx2457m;
-- tez
set hive.tez.container.size=4096;
set hive.tez.java.opts=-Xmx4096m -XX:CICompilerCount=2 -XX:ParallelGCThreads=2 -XX:+UseParallelOldGC;
set tez.am.resource.memory.mb=2800;
-- set orc.compress.size = 8192;
set mapreduce.task.io.sort.mb = 1024;
-- counters
set mapreduce.job.counters.max=10000;
-- timeout
set mapred.task.timeout=6000000;
-- common settings
set hive.exec.reducers.bytes.per.reducer=256000000;
set hive.exec.reducers.max=400;
-- dynamic partitions
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=100000;
set hive.exec.max.dynamic.partitions=100000;
set hive.exec.max.created.files=1000000;
set hive.optimize.dynamic.partition.hashjoin=TRUE;
set hive.optimize.sort.dynamic.partition=true;
set hive.tez.dynamic.partition.pruning=true;
-- hive map aggr
set hive.map.aggr=true;
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
set hive.map.aggr.hash.min.reduction=0.5;
set hive.map.aggr.hash.percentmemory=0.5;
set hive.mapjoin.followby.map.aggr.hash.percentmemory=0.3;
-- fewer files for the NULL partition
set tez.runtime.empty.partitions.info-via-events.enabled=true;
set tez.runtime.report.partition.stats=true;
set hive.auto.convert.join=true;
set hive.fetch.task.conversion=minimal;
-- improved args for hive&tez
set tez.am.container.reuse.enabled=true;
set hive.auto.convert.join.noconditionaltask=true;
set hive.auto.convert.join.noconditionaltask.size=300000000;
set hive.auto.convert.sortmerge.join=true;
set hive.map.aggr=true;
set tez.runtime.io.sort.mb=727;
set tez.runtime.unordered.output.buffer.size-mb=727;
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;
set hive.mapjoin.hybridgrace.hashtable=false;
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
--set hive.stats.fetch.column.stats=false;
set hive.tez.auto.reducer.parallelism=true;
-- parallel exec
set hive.exec.parallel=TRUE;
set hive.exec.parallel.thread.number=8;
set hive.exec.input.listing.max.threads=50;
set mapreduce.input.fileinputformat.list-status.num-threads=50;
set hive.stats.fetch.bitvector=true;
set tez.runtime.pipelined.sorter.lazy-allocate.memory=true;
set mapred.max.split.size=128000000;
set tez.grouping.split-waves=4.0f; |















 2518
2518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









