







哈夫曼编码是哈夫曼树的一个应用。哈夫曼编码应用广泛,如JPEG中就应用了哈夫曼编码。 首先介绍什么是哈夫曼树。哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的 路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的带权路径长度记为WPL= (W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,...n)。可以证明哈夫曼树的WPL是最小的。
其压缩率通常在20%~90%之间。哈夫曼编码算法用字符在文件中出现的频率表来建立一个用0,1串表示各字符的最优表示方式。一个包含100,000个字符的文件,各字符出现频率不同,如下表所示。

有多种方式表示文件中的信息,若用0,1码表示字符的方法,即每个字符用唯一的一个0,1串表示。若采用定长编码表示,则需要3位表示一个字符,整个文件编码需要300,000位;若采用变长编码表示,给频率高的字符较短的编码;频率低的字符较长的编码,达到整体编码减少的目的,则整个文件编码需要(45×1+13×3+12×3+16×3+9×4+5×4)×1000=224,000位,由此可见,变长码比定长码方案好,总码长减小约25%。
前缀码:对每一个字符规定一个0,1串作为其代码,并要求任一字符的代码都不是其他字符代码的前缀。这种编码称为前缀码。编码的前缀性质可以使译码方法非常简单;例如001011101可以唯一的分解为0,0,101,1101,因而其译码为aabe。
译码过程需要方便的取出编码的前缀,因此需要表示前缀码的合适的数据结构。为此,可以用二叉树作为前缀码的数据结构:树叶表示给定字符;从树根到树叶的路径当作该字符的前缀码;代码中每一位的0或1分别作为指示某节点到左儿子或右儿子的“路标”。

从上图可以看出,表示最优前缀码的二叉树总是一棵完全二叉树,即树中任意节点都有2个儿子。图a表示定长编码方案不是最优的,其编码的二叉树不是一棵完全二叉树。在一般情况下,若C是编码字符集,表示其最优前缀码的二叉树中恰有|C|个叶子。每个叶子对应于字符集中的一个字符,该二叉树有|C|-1个内部节点。
给定编码字符集C及频率分布f,即C中任一字符c以频率f(c)在数据文件中出现。C的一个前缀码编码方案对应于一棵二叉树T。字符c在树T中的深度记为dT(c)。dT(c)也是字符c的前缀码长。则平均码长定义为: 使平均码长达到最小的前缀码编码方案称为C的最优前缀码。
使平均码长达到最小的前缀码编码方案称为C的最优前缀码。
哈夫曼编码步骤:
一、对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合F= {T1,T2,T3,...,Ti,...,Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结点,它的左右子树均为空。(为方便在计算机上实现算 法,一般还要求以Ti的权值Wi的升序排列。)
二、在F中选取两棵根结点权值最小的树作为新构造的二叉树的左右子树,新二叉树的根结点的权值为其左右子树的根结点的权值之和。
三、从F中删除这两棵树,并把这棵新的二叉树同样以升序排列加入到集合F中。
四、重复二和三两步,直到集合F中只有一棵二叉树为止。
简易的理解就是,假如我有A,B,C,D,E五个字符,出现的频率(即权值)分别为5,4,3,2,1,那么我们第一步先取两个最小权值作为左右子树构造一个新树,即取1,2构成新树,其结点为1+2=3,如图:
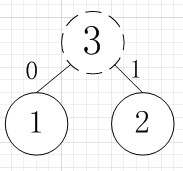
虚线为新生成的结点,第二步再把新生成的权值为3的结点放到剩下的集合中,所以集合变成{5,4,3,3},再根据第二步,取最小的两个权值构成新树,如图:
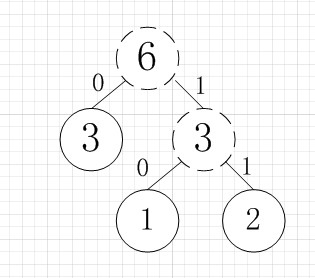
再依次建立哈夫曼树,如下图:
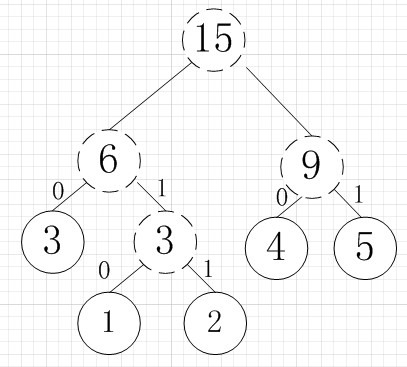
其中各个权值替换对应的字符即为下图:
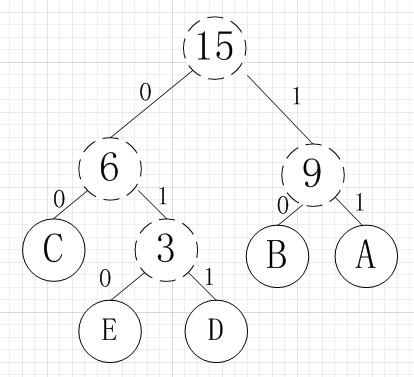
所以各字符对应的编码为:A->11,B->10,C->00,D->011,E->010
霍夫曼编码是一种无前缀编码。解码时不会混淆。其主要应用在数据压缩,加密解密等场合。
python实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
设计算法,给一个字符串进行二进制编码,使得编码后字符串的长度最短。
ord()函数就是用来返回单个字符的ascii值(0-255)或者unicode数值()
chr()函数是输入一个整数【0,255】返回其对应的ascii符号
"""
def CalFrequency(src, pWeight):
if len(src) == 0:
return
for i in range(len(src)):
if ord(src[i]) is not None:
pWeight[ord(src[i])] += 1
# print('origin pWeight', pWeight)
def GetCharFreqs(pWeight,chars_frequs):
for j in range(len(pWeight)):
if pWeight[j] != 0:
# print('字符:', chr(j), '--ASCII:', j, '--频数', pWeight[j])
chars_frequs.append(tuple((chr(j), pWeight[j])))
print('字符出现频数:', chars_frequs)
return chars_frequs
#Tree-Node Type
class Node:
def __init__(self,freq):
self.left = None
self.right = None
self.father = None
self.freq = freq
def isLeft(self):
return self.father.left == self
#create nodes创建叶子节点
def CreateNodes(freqs):
return [Node(freq) for freq in freqs]
#create Huffman-Tree创建Huffman树
def CreateHuffmanTree(nodes):
queue = nodes[:]
while len(queue) > 1:
queue.sort(key=lambda item: item.freq)
node_left = queue.pop(0)
node_right = queue.pop(0)
node_father = Node(node_left.freq + node_right.freq)
node_father.left = node_left
node_father.right = node_right
node_left.father = node_father
node_right.father = node_father
queue.append(node_father)
queue[0].father = None
return queue[0]
#Huffman编码
def HuffmanCoding(nodes,root):
codes = [''] * len(nodes)
for i in range(len(nodes)):
node_tmp = nodes[i]
while node_tmp != root:
if node_tmp.isLeft():
codes[i] = '0' + codes[i]
else:
codes[i] = '1' + codes[i]
node_tmp = node_tmp.father
return codes
if __name__ == '__main__':
MAX_SIZE = 256
src = 'When u r old and grey and full of sleep,' \
'And nodding by the fire, take down this book,' \
'And slowly read, and dream of the soft look' \
'Your eyes had once, and of their shadows deep;' \
'How many loved ur moments of glad grace,' \
'And loved ur beauty with love false or true,' \
'But one man loved the pilgrim soul in u,' \
'And loved the sorrows of ur changing face;' \
'And bending down beside the glowing bars,' \
'Murmur, a little sadly, how Love fled' \
'And paced upon upon the mountains overhead' \
'And hid his face amid a crowd of stars.'
pWeight = [0] * MAX_SIZE # 声明权重数组
CalFrequency(src, pWeight) # 计算每个字符出现次数
chars_frequs = []
chars_frequs = GetCharFreqs(pWeight,chars_frequs) # 计算出现字符频数
nodes = CreateNodes([item[1] for item in chars_frequs])
root = CreateHuffmanTree(nodes)
codes = HuffmanCoding(nodes, root)
for item in zip(chars_frequs, codes):
print('Character:%s freq:%-2d encoding: %s' % (item[0][0], item[0][1], item[1]))

















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









