







为了学习和了解elasticsearch,我们可以使用docker来下载一个官方的elasticsearch和kibana镜像(可选)。镜像实例启动后,可以通kibana的console模块来执行或者使用curl命令发送需要的数据,为方便期间,我们使用kibana的console来展示命令执行。
系统信息打印
在Kibana console中执行下面的命令打印当前的系统信息
GET /?pretty
{
"name": "FMalT2E",
"cluster_name": "docker-cluster",
"cluster_uuid": "SDaNZV-jQNGNKaAG7OlYcg",
"version": {
"number": "6.2.2",
"build_hash": "10b1edd",
"build_date": "2018-02-16T19:01:30.685723Z",
"build_snapshot": false,
"lucene_version": "7.2.1",
"minimum_wire_compatibility_version": "5.6.0",
"minimum_index_compatibility_version": "5.0.0"
},
"tagline": "You Know, for Search"
}
elasticsearch为面向文档类型的存储,使用json结构存储数据,并且基于每个对象属性进行检索,与关系数据库的区别如下:
Relational DB ⇒ Databases ⇒ Tables ⇒ Rows ⇒Columns
Elasticsearch ⇒ Indices ⇒ Types ⇒ Documents ⇒ Fields
其中Indices可以看作是数据库,用于存储存在关系的文档,Types看作是表名称,用来存储和提取文档内容,当然这只是一种简单的比较,实现方面还存在很多差异。elasticsearch内部实现基于Lucence引擎实现,其中Lucence使用反向索引来实现文档内容的搜索,而传统的数据库一般使用B-Tree实现.
存储与提取数据
存储数据到Elasticsearch,只需要执行PUT操作,并将json数据传递过去即可,操作成功后返回200状态.
PUT /megacorp/employee/3
{
"firstname":"Alice",
"age":50,
"interests":["sleep"],
"about":"Hi i am Alice living at Japan"
}
提取数据使用GET即可
GET /megacorp/employee/3
{
"_index": "megacorp",
"_type": "employee",
"_id": "3",
"_version": 1,
"found": true,
"_source": {
"firstname": "Alice",
"age": 50,
"interests": [
"sleep"
],
"about": "Hi i am Alice living at Japan"
}
}
返回的数据内容将同时包含一些metadata,比如版本存储的id值,类型type和index.
搜索数据
GET /megacorp/employee/_search
执行上述语句将会返回所有类型为employee的文档, 返回数据如下图所示, 其中hits中包含了此次返回的数据的总数量和详细的文档列表结构.
{
"took": 57,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 1,
"_source": {
"firstname": "John",
"age": 30,
"interests": [
"music",
"sport"
],
"about": "Hi i am mike living at NewYork"
}
},
...
}
}
我们在执行搜索的时候可以同时指定搜索的详细字段,比如搜索”about”中包含有Beijing的文档,可以使用如下的方式:
GET /megacorp/employee/_search
{
"query": {
"match":
{
"about":"beijing"
}
}
}
返回结果如下:
{
"took": 16,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.2876821,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 0.2876821,
"_source": {
"firstname": "Mike",
"age": 20,
"interests": [
"music",
"traveling"
],
"about": "Hi i am mike living at Beijing"
}
}
]
}
}
复杂搜索实例
假如需要考虑多个条件的搜索,则需要使用过滤器等方式实现,比如下面搜索所有年龄大于25岁,同时喜欢音乐的用户, 可以使用range确定范围,使用match匹配符合条件的内容
GET /megacorp/employee/_search
{
"query": {
"bool":{
"filter": {
"range": {
"age": {
"gte": 25
}
}
},
"must":{
"match":{
"interests":"music"
}
}
}
}
}
全文检索
使用全文检索可以用来检索整个文本中符合的内容,比如单词(match)或者短语(match_phrase),甚至可以使用高亮来自动的生成符合要求的内容的高亮html版本,用于展示在前端页面中.
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "at NewYork"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}
返回结果如下所示
{
"took": 38,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.5753642,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 0.5753642,
"_source": {
"firstname": "John",
"age": 30,
"interests": [
"music",
"sport"
],
"about": "Hi i am mike living at NewYork"
},
"highlight": {
"about": [
"Hi i am mike living <em>at</em> <em>NewYork</em>"
]
}
}
]
}
}
数据分析和聚合操作
统计所有用户的兴趣类别,并返回所有的文档数量,对于统计由于需要消耗大量的资源,因此在设计的时候默认是关闭的,比如执行如下的命令, 将导致错误发生:
Fielddata is disabled on text fields by default. Set fielddata=true on [interests] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.
GET /megacorp/employee/_search
{
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
}
}
}
}
可以使用下面的命令开启对于个别属性的配置:
PUT /megacorp/_mapping/employee
{
"employee": {
"properties": {
"intrests": {
"type": "text",
"fielddata": true
}
}
}
}
配置完成后既可以针对该属性的实现统计功能,另外统计的时候还可以加入其他的聚合参数比如下面统计兴趣以及所有人的平均年龄:
GET /megacorp/employee/_search
{
"aggs" : {
"all_interests" : {
"terms" : { "field" : "interests" },
"aggs" : {
"avg_age" : {
"avg" : { "field" : "age" }
}
}
}
}
}
另外对于Elasticsearch在使用的时候,特别是分布式还需要考虑:
- 文档的分片以及存储
- 节点访问之间的负载均衡
- 路由制定的查询到存储节点
- 自动扩展节点容量和数据恢复
- 复制数据集合 提供冗余机制
ElasticSearch本身原生支持分布式,内置了多节点的管理和高可用机制. 应用开发不需要关系内部数据的分布式存储.在ElasticSearch**node**代表了一个运行了ElasticSearch的实例的机器,cluster则代表了拥有相同cluster.name的一个或者多个节点组成.
正常工作时候会选举其中一个node作为master管理集群的数据变更(index管理),节点管理, 但是不需要参与文档级别内的数据管理.
GET /_cluster/health
{
"cluster_name": "docker-cluster",
"status": "yellow",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 5,
"active_shards": 5,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 5,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 50
}
其中状态含义如下:
- green : 所有主和复制分片均ok
- yellow : 所有主分片运行正常,复制分片状态未激活
- red : 主和复制分片均存在问题
Shards
index 指的是存储相关数据的逻辑命名空间, 而实际指向了物理存储单元shards中(所有数据的分片存储单元),文档实际存储和检索在shards中,但是我们使用的话直接面先的是index级别.shards实际是一个lucene实例.ElasticSearch自动分配shards在所有节点中存储.
shard可以是主shard和复制shard. 每一个文档都属于一个主shard,复制shard保存一份主shard的复制,除了提供冗余外,还可以直接用于读取和搜索使用, 复制shards的数量可以任意变化.而主shard的数量则比较固定.
创建一个index, 默认会将所有数据存储在5个主shard上,但是可以配置比如下面的命令创建
PUT /blogs
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3
}
}
当有任何的新的node加入到集群中的时候,自动调整replicas的分配,当存在多个节点的时候,其中一个被作为master, 同时数据的主shard和复制shard将自动调整分配位置

我们可以通过修改配置新的复制的数量
PUT /blogs/_settings
{
"number_of_replicas" : 2
}

配置更多的复制集合,可以允许我们容忍更多节点的失效.但是如果想要更快的处理效率,还是需要增加跟多的硬件资源.
失效
当单一节点失效的时候,假如主节点,则新的主节点将被选举出来,同时数据主shard的失效,将通过复制shard来补充(转变状态)

但是此时的状态仍不会变为green,因为我们要求的三份复制集合,现在只有两份了.所以不是所有的复制集合都是可用的.
当node1重新启动的时候,数据将会重新被复制,并且复制shard使得满足条件,集群状态重新变为green.
文档存储
存储
正常情况下我们存储一个文档对象,可以声明他的ID值(如果已经存在,则更新)
POST /website/blog/123
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
但是当我们不去考虑ID的时候,ElasticSearch将会自动帮助生成一个20字符长度的URL安全的GUID(多节点同时生成防止冲突)
{
"_index": "website",
"_type": "blogs",
"_id": "U8jyQWIBQOPNwDp6PeAA",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
如果我们仅想在不存在该ID对象的时候执行插入操作,则可以使用使用带有标记的插入命令
PUT /website/blog/123?op_type=create
或者
PUT /website/blog/123/_create
如果项目已经存在则返回409 Conflict,以及错误消息,代表文档已经存在.
提取文档的时候我们可以使用_source来定义返回的内容字段包含,类似与mysql中select title from blogs
GET /website/blogs/VMjyQWIBQOPNwDp6hOAR?_source=title
查看是否存在
HEAD /website/blogs/VMjyQWIBQOPNwDp6hOAR
修改内容
PUT /website/blog/123
{
"title": "My first blog entry",
"text": "I am starting to get the hang of this...",
"date": "2014/01/02"
}
这里的PUT将会替换所有的文档内容,如果需要部分更新的话则使用POST 实现,另外还支持脚本修改,比如自增或者批处理,详见官方文档
POST /website/blogs/U8jyQWIBQOPNwDp6PeAA/_update
{
"doc" : {
"tags" : [ "testing" ],
"views": 0
}
}
如果删除文档的话则直接使用如下的语法即可,如果内容不存在,则返回404代码.
DELETE /website/blog/123
处理冲突与版本
当有多个客户端连接elasticsearch时候, 由于数据存储和检索位置不同,可能导致冲突的发生如下图所示
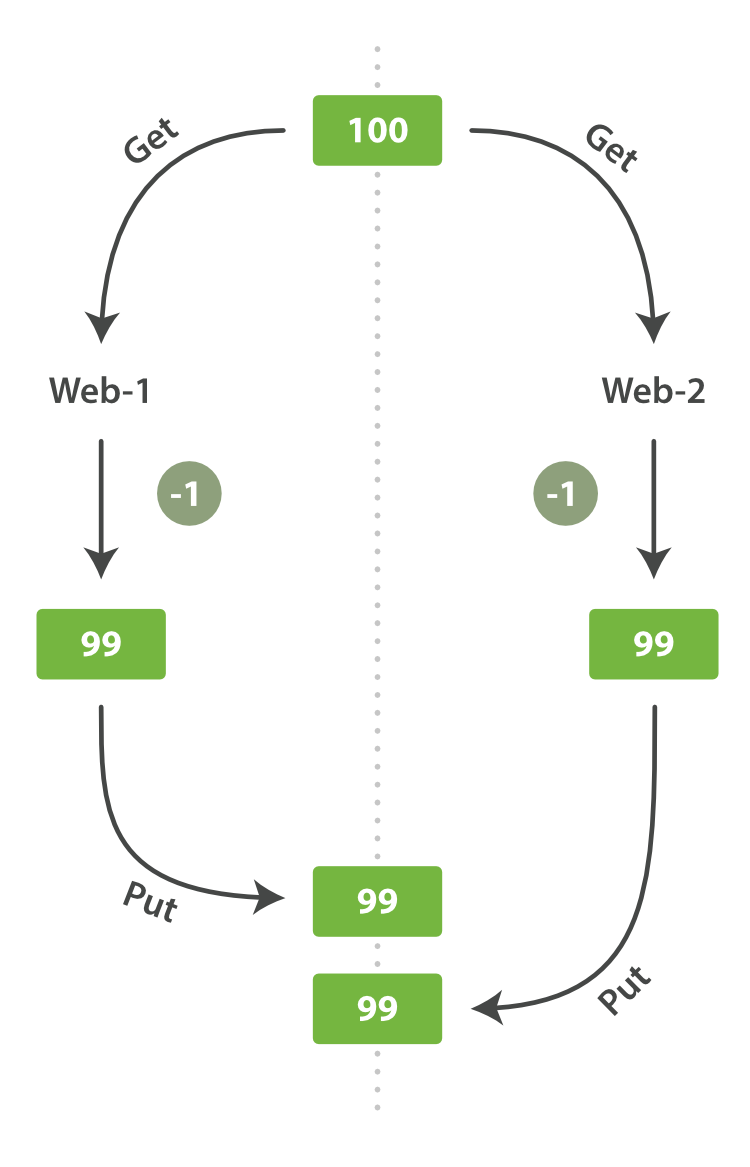
对于上述问题的处理方案,有两种:
- 乐观型并发控制: 假设这种情况发生概率较低,所以不会阻塞任何人的操作,如果数据出现修改(在一次读和写之间),由应用决定怎样去解决冲突,重新尝试或者刷新数据.
- 悲观型并发控制: 主要是用在关系型数据库, 提供锁来避免冲突的发生.
ElasticSearch使用版本_version字段控制,来防止旧数据对于新的数据的覆盖(特别是多node的时候,数据传播到其他节点是无序的)
PUT /website/blog/1?version=1
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}
仅当版本号为1的时候进行更新.
外部版本
如果我们数据来自与其他地方,比如其他的数据库,如果数据库包含一个更新时间,我们可以使用这个更新时间作为外部版本,比如
PUT /website/blog/2?version=5&version_type=external
{
"title": "My first external blog entry",
"text": "Starting to get the hang of this..."
}
同时获取多个文档我们可以借助与_mget方法实现
POST /_mget
{
"docs" : [
{
"_index" : "website",
"_type" : "blogs",
"_id" : 1
},
{
"_index" : "website",
"_type" : "pageviews",
"_id" : 1,
"_source": "views"
}
]
}
批量操作,如果需要同时执行多个操作的时候,可以使用_bulk来实现批量的操作
POST /_bulk
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }
{ "doc" : {"title" : "My updated blog post"} }















 181
181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









