







做过Java或者Android开发的肯定使用过HashMap。最基本的就是HashMap维护了一个key, value表,可以实现数据的快速存储和读取。本篇文章就来揭开HashMap的面纱,从其源码来回答如下问题,
1. HashMap如何实现快速存储?其数据结构是什么?
2. HashMap的长度是固定的么?
3. HashMap的key是自定义对象时,有什么需要注意的?
equal和hashCode
如果你对类的equal和hashCode不熟悉的话,请参考之前的博客,Java equal和Java hashCode。
简言之,equal就是判断两个实例是否一致。hashCode就是返回该实例的唯一标识码。
什么是HashMap
根据Java Doc,HashMap的继承及实现关系如下,

1. HashMap继承了AbstractMap
2. HashMap实现了Serializable, cloneable和Map接口
HashMap有两个参数,一个是容量,一个是负载因子。容量就是该HashMap的大小,负载因子是一个临界值,如果HashMap当前的装载状态(当前容量/最大容量)超过了负载因子,该HashMap的容量就会翻倍。
HashMap提供了以下构造方法,
1. HashMap() 该方法会返回一个初始容量为16,负载因子是0.75的HashMap。
2. HashMap(int initialCapacity) 该方法返回一个指定初始容量的HashMap,同样,其负载因子是0.75.
3. HashMap(int initialCapacity, float loadFactor) 返回一个指定初始容量和负载因子的HashMap。
4. HashMap(Map
HashMap<String, String> mHashMap = new HashMap<>();
mHashMap.put("key1", "value1");
mHashMap.put("key2", "value2");
mHashMap.put("key3", "value3");
System.out.println(mHashMap.size());
System.out.println(mHashMap.get("key1"));HashMap源码分析
可以从这个网站下载HashMap源码。HashMap源码
我们首先来看其构造函数,
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}MAXIMUM_CAPACITY是HashMap定义的一个最大长度,大小是2^30 = 1073741824。 上述的代码很容易理解,然而,这四行是什么鬼?
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;这四行代码的意思就是找到一个2的幂,使得其大于指定的长度。比如,你指定15,那么返回的HashMap的长度不是15,而是16!为什么是这样呢?我们将该疑问留到下面回答。得到计算的长度后,
table = new Entry[capacity];该语句是新建一个长度为capacity的线性表。线性表的类型是Entry,Entry类定义如下,
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}于是我们知道,HashMap的基础是线性表(别急,当然不只线性表,还有链表哦,下面会分析)。
put方法
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}我们知道,HashMap是允许key或者value为null的。如果key不为空,则计算key的hashCode,然后对hashCode进行hash,最后indexFor得到该数据插入的索引。
hash和indexFor代码如下,
/**
* Applies a supplemental hash function to a given hashCode, which
* defends against poor quality hash functions. This is critical
* because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*/
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}我们首先分析下hash函数,我们由其注释可以知道,该方法是用来改善hash值的,防止不同的hash被索引到同一个位置的概率。
indexFor函数,它是计算给定hash code的索引值。其实h & (length-1)的结果就是h%length,当然,前提是length是2的幂。我们知道,位运算对于计算机来说是最快的一种运算,所以hashmap为了提高运算速度,就要求其的长度都是2的幂。
得到插入的索引值后,HashMap判断,
1. 如果插入的key存在于当前map中,则更新其对应的value。
2. 如果插入的可以不存在,则将该项加入到map中索引为i的位置。
addEntry方法代码如下,
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}Entry的结构上面提过,其实Entry是个链表单位,注意到其含有一个Entry的成员变量。而且分析addEntry代码,发现,当我们插入新的Entry时,其实是插入到了链表的开始节点。分析到此,我们发现,其实hashmap的结构就是线性表+链表,如下图所示。
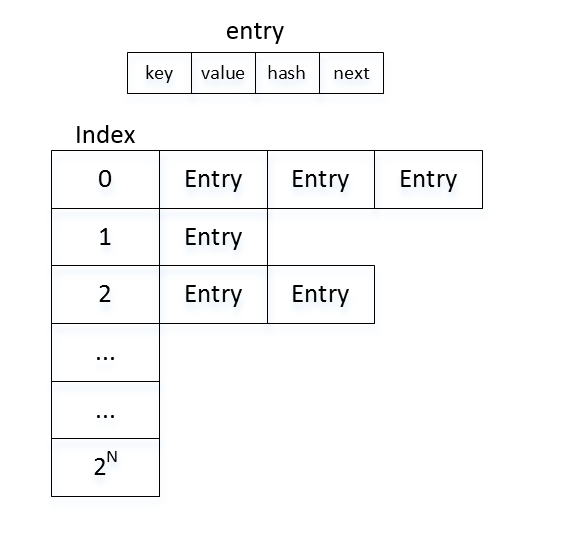
1. 纵向看,hashmap是一个线性表,其实也就是一个数组啦,分配一段连续的内存。
2. 横向看,线性表是由链表组成的。每个链表的index都是一样的,其实hash也是一样的。但是key不一样哦,因为相同key的都被覆盖掉了。
3. 如果我们的hash算法选择的好的话,那么每个链表的长度将会是1
在每次插入新的entry后,我们判断,当前链表的数量是否超过了阈值(容量*负载因子),如果超过的话,就将该hashmap的尺寸double。
接下来,我们分析下get方法
get(Object key)
get方法用来返回指定key的value。
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
* <p>A return value of {@code null} does not <i>necessarily</i>
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*
* @see #put(Object, Object)
*/
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}我们来看其源码,首先得到key的两次hash值,然后得到其索引值indexFor(hash, table.length),然后遍历该链表,当链表中的key和参数key相等时,就返回value。否则,返回null。
由hashmap的put和get方法,我们可以了解到,其实现快速读取的原理就是将key进行hash来存储。在读取记录的时候,我们并不需要来一个一个判断key是否相等,而是先计算其对应的索引值,然后判断key是否相等。我们知道线性表的查询复杂度是O(1),而链表的查询时间是O(n), n为链表的长度,在好的hash算法下,hashmap完全退化为线性表,这样,每次查询的时间为计算hash的时间(只需要计算一次)和查询线性表时间,如果hash算法选取得当或者hashmap大小比较大,则查询的复杂度为O(1),小于逐个比较的时间(复杂度为O(N),N为hashmap长度)。
key为自定义对象的注意事项
由上面的分析,我们知道,在存储key,value的时候,使用到了key对象的equal和hashCode方法。这也要求我们当key是自定义类型的时候,我们要复写该类的equal和hashCode方法。可以参考Java equal和Java hashCode。















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









