






什么是负载均衡
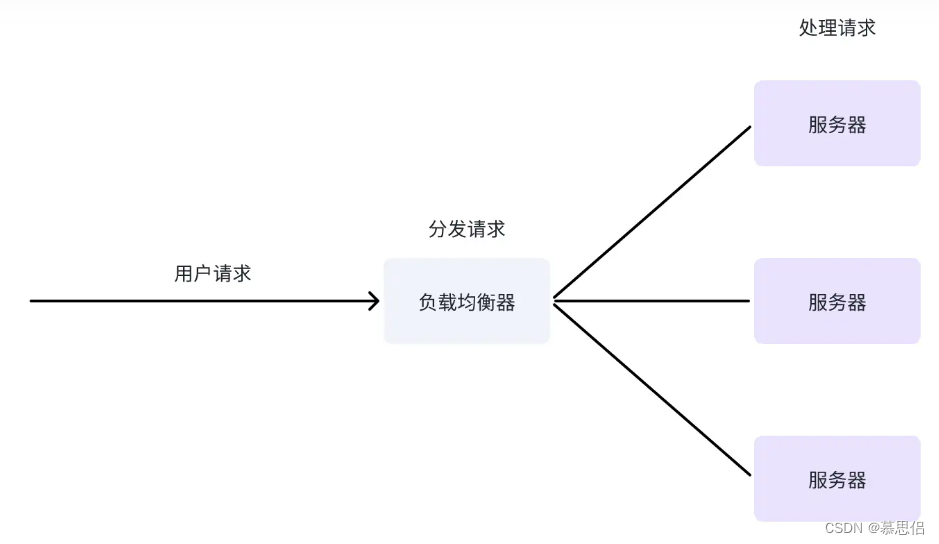
负载均衡指的是将用户请求分摊到不同的服务器(worker)上处理,以提高系统整体的并发处理能力以及可靠性。负载均衡的示意图如图 1 所示:
常见的负载均衡算法(参考自《负载均衡原理及算法详解》):
- 随机法:随机分配一台服务器。如果没有配置权重的话,所有的服务器被访问到的概率都是相同的。如果配置权重的话,权重越高的服务器被访问的概率就越大。
- 轮询法:挨个轮询服务器处理
- 两次随机法:随机选择两台服务器,并根据着两台服务器的负载情况选择其中一台
- 哈希法:将请求的参数信息通过哈希函数转换成一个哈希值,然后根据哈希值来决定请求被哪一台服务器处理
- 最小连接法:当有新的请求出现时,遍历服务器节点列表并选取其中连接数最小的一台服务器来响应当前请求
- 最少活跃法:最少活跃法以活动连接数为标准,活动连接数可以理解为当前正在处理的请求数
- 最快响应时间法:最快响应时间法以响应时间为标准来选择具体是哪一台服务器处理
接下来介绍 FastChat 中使用的两种负载均衡策略,它的实现位于 controller.py 文件。
LOTTERY
LOTTERY 策略是加权随机法,即每个 worker 都会有一个权重(在 FastChat 中指 speed),根据权重随机选择,权重越大,被选择的可能性越大,不过目前 FastChat 的 speed 值为 1 且不可配置。
# https://github.com/lm-sys/FastChat/blob/main/fastchat/serve/controller.py
class Controller:
def get_worker_address(self, model_name: str):
if self.dispatch_method == DispatchMethod.LOTTERY:
worker_names = []
worker_speeds = []
for w_name, w_info in self.worker_info.items():
if model_name in w_info.model_names:
worker_names.append(w_name)
worker_speeds.append(w_info.speed)
worker_speeds = np.array(worker_speeds, dtype=np.float32)
norm = np.sum(worker_speeds)
if norm < 1e-4:
return ""
worker_speeds = worker_speeds / norm
if True: # Directly return address
pt = np.random.choice(np.arange(len(worker_names)), p=worker_speeds)
worker_name = worker_names[pt]
return worker_nameSHORTEST_QUEUE
SHORTEST_QUEUE 是 FastChat 默认的负载均衡策略,它的原理和最小连接法类似,即选择请求数/speed最小的 worker,其中请求数包括正在处理以及未处理的请求,speed 即上面 LOTTERY 提到的权重。请求数的计算方法见 BaseModelWorker 的get_queue_length方法。
class Controller:
def get_worker_address(self, model_name: str):
if self.dispatch_method == DispatchMethod.LOTTERY:
...
elif self.dispatch_method == DispatchMethod.SHORTEST_QUEUE:
worker_names = []
worker_qlen = []
for w_name, w_info in self.worker_info.items():
if model_name in w_info.model_names:
worker_names.append(w_name)
worker_qlen.append(w_info.queue_length / w_info.speed)
if len(worker_names) == 0:
return ""
# 选择 请求数/speed 最小的 worker
min_index = np.argmin(worker_qlen)
w_name = worker_names[min_index]
self.worker_info[w_name].queue_length += 1
logger.info(
f"names: {worker_names}, queue_lens: {worker_qlen}, ret: {w_name}"
)
return w_name
# https://github.com/lm-sys/FastChat/blob/main/fastchat/serve/base_model_worker.py
class BaseModelWorker:
def get_queue_length(self):
# semaphore 用于控制 worker 最多能同时接收的请求数
if self.semaphore is None:
return 0
else:
sempahore_value = (
self.semaphore._value
if self.semaphore._value is not None
else self.limit_worker_concurrency
)
waiter_count = (
0 if self.semaphore._waiters is None else len(self.semaphore._waiters)
)
return self.limit_worker_concurrency - sempahore_value + waiter_count














 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









