






FastChat 部署服务的代码位于 fastchat/serve,核心的文件有 3 个:
- controller.py:实现了 Controller,它的功能包括注册新 Worker、删除 Worker、分配 Worker
- model_worker.py:实现了 Worker,它的功能是调用模型处理请求并将结果返回给 Server。每个 Worker 都单独拥有一个完整的模型,可以多个 Worker 处理同样的模型,例如 Worker 1 和 Worker 2 都处理 Model A,这样可以提高Model A 处理请求的吞吐量。另外,Worker 和 GPU 是一对多的关系,即一个 Worker 可以对应多个 GPU,例如使用了张量并行(Tensor Parallelism)将一个模型切分到多个 GPU 上
- openai_api_server.py:实现了 OpenAI 兼容的 RESTful API
它们的关系如下图所示:
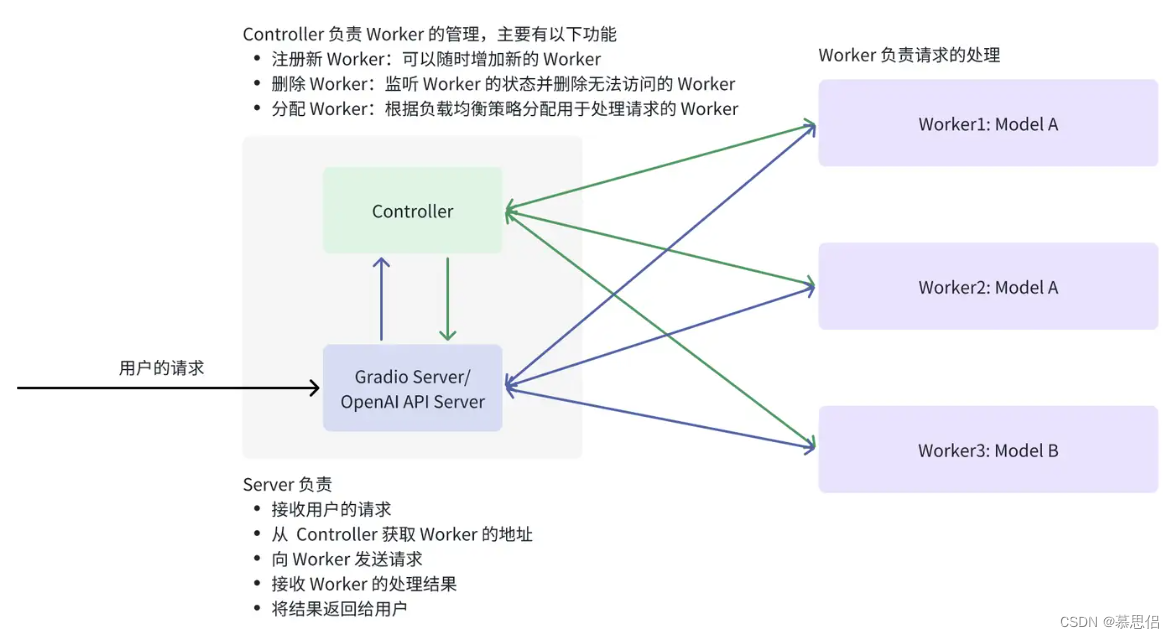
图 1:https://github.com/lm-sys/FastChat/blob/main/docs/server_arch.md
以处理一个请求为例介绍它的流程:
- 用户往 Server(例如 OpenAI API Server)发送请求,其中请求包含了模型名以及输入,例如:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Llama-3-8B-Instruct",
"messages": [{"role": "user", "content": "Hello! What is your name?"}]
}'2. Server 向 Controller 发送请求,目的是获取处理 model 的 Worker 地址
3. Controller 根据负载均衡策略分配 Worker
4. Server 向 Worker 发送请求
5. Worker 处理请求并将结果返回给 Server
6. Server 将结果返回给用户
以上就是 FastChat 处理一个请求的流程,接下来,我们将实现一个最小的 FastChat。
实现 Mini FastChat
Mini FastChat 支持的功能和实现方式和 FastChat 类似,但做了简化,代码修改自 FastChat。
Mini FastChat 的目录结构如下:
mini-fastchat
├── controller.py
├── worker.py
└── openai_api_server.py Controller
新建一个 controller.py 文件,主要实现了 Controller 类,它的功能是注册 Worker 以及为请求随机分配 Worker。同时,controller.py 提供了两个接口register_worker和get_worker_address,前者会被 Worker 调用以将 Worker 注册到 Controller 中,后者会被 API Server 调用以获得 Worker 的地址。
import argparse
import uvicorn
import random
from fastapi import FastAPI, Request
from loguru import logger
class Controller:
def __init__(self):
self.worker_info = {}
def register_worker(
self,
worker_addr: str,
model_name: str,
):
logger.info(f'Register worker: {worker_addr} {model_name}')
self.worker_info[worker_addr] = model_name
def get_worker_address(self, model_name: str):
# 为请求分配 worker
worker_addr_list = []
for worker_addr, _model_name in self.worker_info.items():
if _model_name == model_name:
worker_addr_list.append(worker_addr)
assert len(worker_addr_list) > 0, f'No worker for model: {model_name}'
# 使用随机的方式分配 worker
worker_addr = random.choice(worker_addr_list)
return worker_addr
app = FastAPI()
@app.post('/register_worker')
async def register_worker(request: Request):
data = await request.json()
controller.register_worker(
worker_addr=data['worker_addr'],
model_name=data['model_name'],
)
@app.post("/get_worker_address")
async def get_worker_address(request: Request):
data = await request.json()
addr = controller.get_worker_address(data['model'])
return {"address": addr}
def create_controller():
parser = argparse.ArgumentParser()
parser.add_argument('--host', type=str, default='localhost')
parser.add_argument('--port', type=int, default=21001)
args = parser.parse_args()
logger.info(f'args: {args}')
controller = Controller()
return args, controller
if __name__ == '__main__':
args, controller = create_controller()
uvicorn.run(app, host=args.host, port=args.port, log_level='info')Worker
新建一个 worker.py 文件,主要实现了 Worker 类,同时提供了api_generate接口将会被 API Server 调用以处理用户的请求。
import argparse
import asyncio
from typing import Optional
import requests
import uvicorn
import torch
from loguru import logger
from transformers import AutoTokenizer, AutoModelForCausalLM
from fastapi import FastAPI, Request
def load_model(model_path: str) -> None:
logger.info(f'Load model from {model_path}')
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map='auto',
)
logger.info(f'model device: {model.device}')
return model, tokenizer
def generate(model, tokenizer, params: dict):
input_ids = tokenizer.apply_chat_template(
params['messages'],
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids("<|eot_id|>")]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
return tokenizer.decode(response, skip_special_tokens=True)
class Worker:
def __init__(
self,
controller_addr: str,
worker_addr: str,
model_path: str,
model_name: Optional[str] = None,
) -> None:
self.controller_addr = controller_addr
self.worker_addr = worker_addr
self.model, self.tokenizer = load_model(model_path)
self.model_name = model_name
self.register_to_controller()
def register_to_controller(self) -> None:
logger.info('Register to controller')
url = self.controller_addr + '/register_worker'
data = {
'worker_addr': self.worker_addr,
'model_name': self.model_name,
}
response = requests.post(url, json=data)
assert response.status_code == 200
def generate_gate(self, params: dict):
return generate(self.model, self.tokenizer, params)
app = FastAPI()
@app.post("/worker_generate")
async def api_generate(request: Request):
params = await request.json()
output = await asyncio.to_thread(worker.generate_gate, params)
return {'output': output}
def create_worker():
parser = argparse.ArgumentParser()
parser.add_argument('model_path', type=str, help='Path to the model')
parser.add_argument('model_name', type=str)
parser.add_argument('--host', type=str, default='localhost')
parser.add_argument('--port', type=int, default=21002)
parser.add_argument('--controller-address', type=str, default='http://localhost:21001')
args = parser.parse_args()
logger.info(f'args: {args}')
args.worker_address = f'http://{args.host}:{args.port}'
worker = Worker(worker_addr=args.worker_address, controller_addr=args.controller_address, model_path=args.model_path, model_name=args.model_name)
return args, worker
if __name__ == '__main__':
args, worker = create_worker()
uvicorn.run(app, host=args.host, port=args.port, log_level='info')Server
import argparse
import asyncio
import aiohttp
import uvicorn
from fastapi import FastAPI, Request
from loguru import logger
app = FastAPI()
app_settings = {}
async def fetch_remote(url, payload):
async with aiohttp.ClientSession() as session:
async with session.post(url, json=payload) as response:
return await response.json()
async def generate_completion(payload, worker_addr: str):
return await fetch_remote(worker_addr + "/worker_generate", payload)
async def get_worker_address(model_name: str) -> str:
controller_address = app_settings['controller_address']
res = await fetch_remote(
controller_address + "/get_worker_address", {"model": model_name}
)
return res['address']
@app.post('/v1/chat/completions')
async def create_chat_completion(request: Request):
data = await request.json()
worker_addr = await get_worker_address(data['model'])
response = asyncio.create_task(generate_completion(data, worker_addr))
await response
return response.result()
def create_openai_api_server():
parser = argparse.ArgumentParser()
parser.add_argument('--host', type=str, default='localhost')
parser.add_argument('--port', type=int, default=8000)
parser.add_argument('--controller-address', type=str, default='http://localhost:21001')
args = parser.parse_args()
logger.info(f'args: {args}')
app_settings['controller_address'] = args.controller_address
return args
if __name__ == '__main__':
args = create_openai_api_server()
uvicorn.run(app, host=args.host, port=args.port, log_level='info')运行 Mini FastChat
配置环境
- 创建 conda
conda create -n fastchat python=3.10 -y conda activate fastchat- 安装 torch2.2.1
conda install pytorch==2.2.1 pytorch-cuda=12.1 -c pytorch -c nvidia- 安装依赖
pip install requests aiohttp uvicorn fastapi loguru transformers运行
- 启动 controller
python mini-fastchat/controller.py- 启动 worker
python mini-fastchat/worker.py meta-llama/Meta-Llama-3-8B-Instruct Llama-3-8B-Instruct
# 如果环境中还有多余的 GPU,可以再起一个 worker
CUDA_VISIBLE_DEVICES=1 python mini-fastchat/worker.py meta-llama/Meta-Llama-3-8B-Instruct Llama-3-8B-Instruct --port 21003- 启动 API server
python mini-fastchat/openai_api_server.py- 测试
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Llama-3-8B-Instruct",
"messages": [{"role": "user", "content": "Hello! What is your name?"}]
}'如果上面的命令可以看到输出,则说明成功运行了。
可以改进的点
Mini FastChat 简单实现了类 FastChat 部署服务,但相比于 FastChat,还有很多可以改进的点,例如:
- 负载均衡策略:Mini FastChat 的 Controller 只支持了随机分配 Worker,而 FastChat Controller 支持 LOTTERY 和 SHORTEST_QUEUE 策略
- 代码不够鲁棒:为了简化实现,Mini FastChat 没有处理可能出现的异常情况,例如输入有误、网络异常
根据自己学习情况,整理了一个流程图
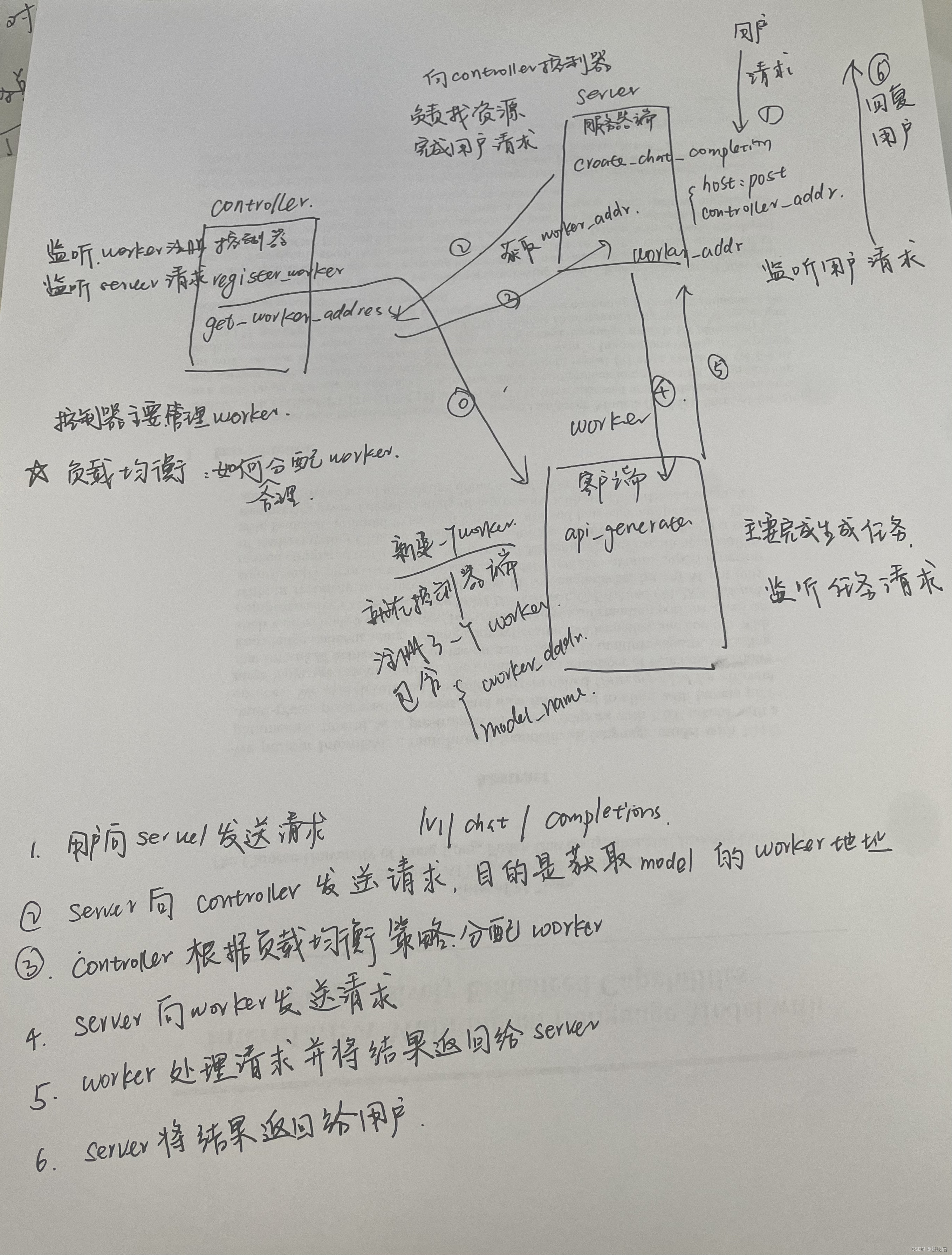
下一篇文章
参考链接:

















 128
128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









