







本文涉及的源码可从图神经网络长对话理解该文章下方附件获取
论文:Conversation Understanding using Relational Temporal Graph Neural Networks with Auxiliary Cross-Modality Interaction
原文链接
**ACL2023 **
概述
情感识别在促进人类对话深度理解中占据举足轻重的地位。随着多模态数据的崛起,这一领域的研究因融合了语言、声音和面部表情等多元化信息而面临前所未有的挑战。为了应对这一挑战,我们提出了一种创新方法,该方法充分利用全局和局部上下文信息来预测对话中每句话的情感标签。
具体而言,全局表示通过建模会话级别的跨模态交互得以捕获,从而深入洞察整个对话的情感脉络。相比之下,局部语义的推断通常基于说话者的时间信息或情感波动,却往往忽视了话语层面的核心要素。此外,当前主流方法虽尝试在统一输入中融合多模态特征,但未能充分利用特定模态的独特表征。
为解决上述问题,我们研发了关系时态图神经网络(correct),这一先进的神经网络框架能够高效地捕捉会话级别的跨模态交互和话语级别的时间依赖。特别的是,该框架以模态特定的方式实现会话理解,为情感识别提供了更为精细和准确的视角。
通过大量实验,我们在IEMOCAP和CMU-MOSEI等权威数据集上取得了最新成果,充分验证了correct框架在多模态情感识别任务中的卓越性能。
原理介绍
关系时态图神经网络(correct)原理介绍
关系时态图神经网络(correct)是一种创新的神经网络框架,专为多模态情感识别任务设计。该框架通过整合全局和局部上下文信息,以及有效地捕捉会话级别的跨模态交互和话语级别的时间依赖,显著提升了情感识别的准确性。
-
全局上下文信息的捕获
correct框架首先通过建模会话级别的跨模态交互来捕获全局上下文信息。这意味着,它不仅考虑了对话中的每一句话,还考虑了这些话语如何与语言、声音和面部表情等多模态数据相互交织、共同影响情感表达。通过这种方法,correct能够深入理解整个对话的情感脉络,为后续的局部情感分析提供坚实的基础。
-
局部语义的推断
在捕获全局上下文信息的基础上,correct进一步关注局部语义的推断。与以往方法不同,correct不仅考虑说话者的时间信息和情感变化,还特别关注话语层面的重要因素。通过对话语级别的细致分析,correct能够更准确地捕捉每个句子中的情感细节,并推断出相应的情感标签。
-
多模态特征的融合与利用
correct框架的另一个关键优势在于其对多模态特征的融合与利用。与大多数现有方法不同,correct并没有简单地将多个模态的特征融合到一个统一的输入中,而是采用了模态特定的表示方式。这意味着,对于语言、声音和面部表情等不同模态的数据,correct能够分别进行学习和建模,从而更充分地利用每种模态的独特信息。通过这种方式,correct能够更全面地理解对话中的情感表达,提高情感识别的准确性。
-
关系时态图神经网络的结构
correct框架的核心是其关系时态图神经网络的结构。该网络通过构建图结构来表示对话中的跨模态交互和时间依赖关系。图中的节点表示对话中的句子或话语,而边则表示这些句子或话语之间的关联和依赖。通过图卷积操作和时间序列分析,correct能够同时捕捉对话中的空间和时间信息,从而更准确地理解对话中的情感表达。
总之,关系时态图神经网络(correct)通过整合全局和局部上下文信息、有效捕捉跨模态交互和时间依赖以及利用模态特定的表示方式,为多模态情感识别任务提供了一种高效而准确的解决方案。
模型整体架构
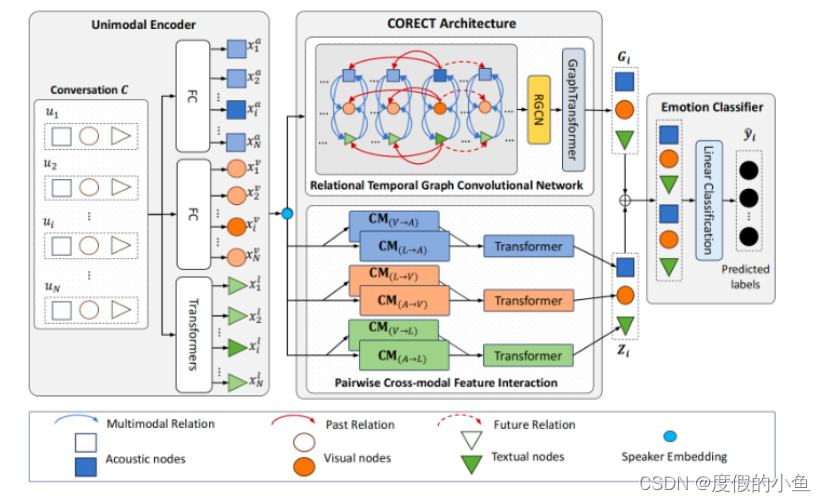
特征提取
文本采用transformerde方式进行编码
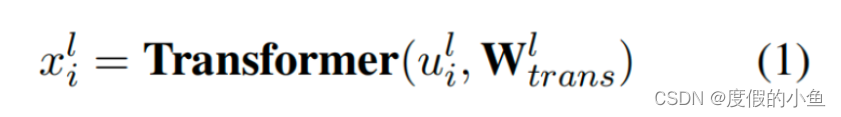
音频,视频都采用全连接的方式进行编码

通过添加相应的讲话者嵌入来增强技术增强

关系时序图卷积网络(RT-GCN)
解读:RT-GCN旨在通过利用话语之间以及话语与其模态之间的多模态图来捕获对话中每个话语的局部上下文信息,关系时序图在一个模块中同时实现了上下文信息,与模态之间的信息的传递。对话中情感识别需要跨模态学习到信息,同时也需要学习上下文的信息,整合成一个模块的作用将两部分并行处理,降低模型的复杂程度,降低训练成本,降低训练难度。
建图方式,模态与模态之间有边相连,对话之间有边相连:

建图之后,用图transformer融合不同模态,以及不同语句的信息,得到处理之后特征向量:
核心逻辑
# start
#模型核心部分
import torch
import torch.nn as nn
import torch.nn.functional as F
from .Classifier import Classifier
from .UnimodalEncoder import UnimodalEncoder
from .CrossmodalNet import CrossmodalNet
from .GraphModel import GraphModel
from .functions import multi_concat, feature_packing
import corect
log = corect.utils.get_logger()
class CORECT(nn.Module):
def __init__(self, args):
super(CORECT, self).__init__()
self.args = args
self.wp = args.wp
self.wf = args.wf
self.modalities = args.modalities
self.n_modals = len(self.modalities)
self.use_speaker = args.use_speaker
g_dim = args.hidden_size
h_dim = args.hidden_size
ic_dim = 0
if not args.no_gnn:
ic_dim = h_dim * self.n_modals
if not args.use_graph_transformer and (args.gcn_conv == "gat_gcn" or args.gcn_conv == "gcn_gat"):
ic_dim = ic_dim * 2
if args.use_graph_transformer:
ic_dim *= args.graph_transformer_nheads
if args.use_crossmodal and self.n_modals > 1:
ic_dim += h_dim * self.n_modals * (self.n_modals - 1)
if self.args.no_gnn and (not self.args.use_crossmodal or self.n_modals == 1):
ic_dim = h_dim * self.n_modals
a_dim = args.dataset_embedding_dims[args.dataset]['a']
t_dim = args.dataset_embedding_dims[args.dataset]['t']
v_dim = args.dataset_embedding_dims[args.dataset]['v']
dataset_label_dict = {
"iemocap": {"hap": 0, "sad": 1, "neu": 2, "ang": 3, "exc": 4, "fru": 5},
"iemocap_4": {"hap": 0, "sad": 1, "neu": 2, "ang": 3},
"mosei": {"Negative": 0, "Positive": 1},
}
dataset_speaker_dict = {
"iemocap": 2,
"iemocap_4": 2,
"mosei":1,
}
tag_size = len(dataset_label_dict[args.dataset])
self.n_speakers = dataset_speaker_dict[args.dataset]
self.wp = args.wp
self.wf = args.wf
self.device = args.device
self.encoder = UnimodalEncoder(a_dim, t_dim, v_dim, g_dim, args)
self.speaker_embedding = nn.Embedding(self.n_speakers, g_dim)
print(f"{args.dataset} speakers: {self.n_speakers}")
if not args.no_gnn:
self.graph_model = GraphModel(g_dim, h_dim, h_dim, self.device, args)
print('CORECT --> Use GNN')
if args.use_crossmodal and self.n_modals > 1:
self.crossmodal = CrossmodalNet(g_dim, args)
print('CORECT --> Use Crossmodal')
elif self.n_modals == 1:
print('CORECT --> Crossmodal not available when number of modalitiy is 1')
self.clf = Classifier(ic_dim, h_dim, tag_size, args)
self.rlog = {}
def represent(self, data):
# Encoding multimodal feature
a = data['audio_tensor'] if 'a' in self.modalities else None
t = data['text_tensor'] if 't' in self.modalities else None
v = data['visual_tensor'] if 'v' in self.modalities else None
a, t, v = self.encoder(a, t, v, data['text_len_tensor'])
# Speaker embedding
if self.use_speaker:
emb = self.speaker_embedding(data['speaker_tensor'])
a = a + emb if a != None else None
t = t + emb if t != None else None
v = v + emb if v != None else None
# Graph construct
multimodal_features = []
if a != None:
multimodal_features.append(a)
if t != None:
multimodal_features.append(t)
if v != None:
multimodal_features.append(v)
out_encode = feature_packing(multimodal_features, data['text_len_tensor'])
out_encode = multi_concat(out_encode, data['text_len_tensor'], self.n_modals)
out = []
if not self.args.no_gnn:
out_graph = self.graph_model(multimodal_features, data['text_len_tensor'])
out.append(out_graph)
if self.args.use_crossmodal and self.n_modals > 1:
out_cr = self.crossmodal(multimodal_features)
out_cr = out_cr.permute(1, 0, 2)
lengths = data['text_len_tensor']
batch_size = lengths.size(0)
cr_feat = []
for j in range(batch_size):
cur_len = lengths[j].item()
cr_feat.append(out_cr[j,:cur_len])
cr_feat = torch.cat(cr_feat, dim=0).to(self.device)
out.append(cr_feat)
if self.args.no_gnn and (not self.args.use_crossmodal or self.n_modals == 1):
out = out_encode
else:
out = torch.cat(out, dim=-1)
return out
def forward(self, data):
graph_out = self.represent(data)
out = self.clf(graph_out, data["text_len_tensor"])
return out
def get_loss(self, data):
graph_out = self.represent(data)
loss = self.clf.get_loss(
graph_out, data["label_tensor"], data["text_len_tensor"])
return loss
def get_log(self):
return self.rlog
#图神经网络
import torch
import torch.nn as nn
from torch_geometric.nn import RGCNConv, TransformerConv
import corect
class GNN(nn.Module):
def __init__(self, g_dim, h1_dim, h2_dim, num_relations, num_modals, args):
super(GNN, self).__init__()
self.args = args
self.num_modals = num_modals
if args.gcn_conv == "rgcn":
print("GNN --> Use RGCN")
self.conv1 = RGCNConv(g_dim, h1_dim, num_relations)
if args.use_graph_transformer:
print("GNN --> Use Graph Transformer")
in_dim = h1_dim
self.conv2 = TransformerConv(in_dim, h2_dim, heads=args.graph_transformer_nheads, concat=True)
self.bn = nn.BatchNorm1d(h2_dim * args.graph_transformer_nheads)
def forward(self, node_features, node_type, edge_index, edge_type):
if self.args.gcn_conv == "rgcn":
x = self.conv1(node_features, edge_index, edge_type)
if self.args.use_graph_transformer:
x = nn.functional.leaky_relu(self.bn(self.conv2(x, edge_index)))
return x
环境配置/部署方式
安装pytorch:
请到pytorch官网找安装命令,尽量不要直接pip install
https://pytorch.org/get-started/previous-versions/
图神经网络的包版本要求很苛刻,版本对应不上很容易报错
只要环境配置好了,找到这个文件,里面的代码粘贴到终端运行即可
小结
图神经网络(GNN)在长对话中的应用,对当今社会的作用和意义主要体现在以下几个方面:
- 提升智能对话系统的性能:图神经网络可以学习并理解对话中的上下文关系,使得对话系统能够更准确地理解用户的意图,并给出更恰当的回应。在智能客服、在线教育、智能助手等领域,图神经网络的应用可以提升用户体验,减少误解和沟通障碍。
- 优化推荐系统:图神经网络通过分析用户-物品关系图(如用户-电影、用户-商品),可以学习用户和物品的嵌入,从而更好地捕捉用户的兴趣和物品的特征,用于个性化推荐。这种能力在电商、视频、音乐等平台上尤为重要,可以帮助用户快速找到他们感兴趣的内容,提高用户满意度和平台活跃度。
- 助力社交网络分析:在社交网络中,图神经网络可以用于节点分类、链接预测和社群检测等任务。通过识别社交网络中的用户类别、预测未来可能的连接以及发现社群或群体,图神经网络可以帮助我们更好地理解用户群体的行为和互动模式,为社交网络平台的运营和决策提供支持。
- 推动生物信息学和生物医疗领域的发展:图神经网络在生物信息学和生物医疗领域的应用广泛,包括蛋白质相互作用预测、药物发现、基因表达分析等。这些应用有助于揭示生物学过程中的关键信息,加速药物发现和疾病治疗的过程,对人类健康和医学发展具有重要意义。
- 优化交通网络管理:图神经网络可以应用于交通流量预测、路线规划和交通信号优化等任务。通过分析道路网络中的交通流量数据,图神经网络可以帮助预测交通拥堵和优化交通管理,提高交通流畅度和减少交通拥堵,对城市交通规划和管理具有重要意义。
总的来说,图神经网络在长对话中的应用对当今社会的作用和意义在于提升智能对话系统的性能、优化推荐系统、助力社交网络分析、推动生物信息学和生物医疗领域的发展以及优化交通网络管理等方面。这些应用不仅提高了人们的生活质量和工作效率,还推动了科技进步和社会发展。

















 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











