







大语言模型发展历程

当前国内外主流LLM模型
一、国外主流LLM
-
LLaMA2
- Meta推出的开源模型,参数规模涵盖70亿至700亿,支持代码生成和多领域任务适配57。
- 衍生版本包括Code Llama(代码生成优化)和Llama Chat(对话场景)56。
-
GPT系列(GPT-3.5/GPT-4)
- OpenAI开发的闭源模型,以多模态能力和长文本生成为核心优势,广泛应用于对话、代码生成等场景38。
-
BLOOM
- 由Hugging Face联合多国团队开发,1760亿参数,支持46种自然语言和13种编程语言,强调透明度和开源协作5。
-
PaLM & Claude
- Google的PaLM和Anthropic的Claude均为闭源模型,前者侧重科学计算,后者强化了推理和多模态能力37。
-
BERT
- Google早期基于Transformer架构的模型,虽参数较小(约3.4亿),但在自然语言理解任务中仍具影响力5。
二、国内主流LLM
-
文心一言(ERNIE Bot)
- 百度研发的知识增强模型,融合万亿级数据和千亿级知识图谱,支持复杂问答和创意生成37。
-
通义千问
- 阿里巴巴推出的开源模型(7B版本),基于Transformer架构,优化中英文混合任务处理36。
-
ChatGLM系列
- 包括ChatGLM-6B(62亿参数)和ChatGLM2-6B,支持双语对话,通过量化技术降低部署成本14。
- 衍生模型VisualGLM-6B(78亿参数)整合视觉与语言模态,实现图文交互46。
-
盘古大模型
- 华为开发的多模态模型,覆盖自然语言处理(NLP)、计算机视觉(CV)及科学计算领域7。
-
MiLM-6B
- 小米研发的64亿参数模型,在C-Eval和CMMLU中文评测中表现优异,尤其擅长STEM科目1。
-
MOSS
- 支持中英双语的开源对话模型,通过强化学习优化生成质量,适用于通用问答场景14。
三、其他特色模型
- CodeFuse-13B:专精代码生成,预训练数据覆盖40+编程语言,HumanEval评测准确率达37.1%1。
- 鹏程·盘古α:中文预训练模型,参数规模达千亿级,侧重长文本生成和领域适配6。
- LaWGPT:基于中文法律知识微调的模型,适用于法律咨询和文书生成6。
大模型分类
按照输入数据类型的不同,大模型主要可以分为以下三大类
语言大模型
指在自然语言处理(NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。
视觉大模型
指在计算机视觉(CV)领域中使用的大模型,通常用于图像处理和分析。
多模态大模型
指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。
按照应用领域的不同,大模型主要可以分为 L0、L1、L2 三个层级:
L0 通用大模型
指可以在多个领域和任务上通用的大模型。通用大模型就像完成了大学前素质教育阶段的学生,有基础的认知能力,数学、英语、化学、物理等各学科也都懂一点。
L1 行业大模型
指那些针对特定行业或领域的大模型。它们通常使用行业相关的数据进行预训练或微调,以提高在该领域的性能和准确度。行业大模型就像选择了某一个专业的大学生,对自己专业下的相关知识有了更深入的了解。
L2 垂直大模型
指那些针对特定任务或场景的大模型。它们通常使用任务相关的数据进行预训练或微调,以提高在该任务上的性能和效果。垂直大模型就像研究生,对特定行业下的某个具体领域有比较深入的研究。
大模型不足

当前大模型的不足主要体现在以下方面:
一、技术架构缺陷
-
数据与算力依赖过高
大模型训练需消耗海量多模态数据及算力,万亿级参数规模导致资源投入呈指数级增长12。此外,海量小文件存储面临元数据管理挑战,需平衡扩展性与访问延时1。 -
逻辑推理能力薄弱
在处理需逻辑推理、数值计算的复杂问题时表现较差,尤其在多步骤推理场景中准确率显著下降23。例如20步推理后准确率可能低于36%4。 -
灾难性遗忘与无记忆性
训练新任务会损害原有任务性能,且在推理阶段无法记忆历史数据或场景(如自动驾驶需反复重新计算路况)23。多数大模型不具备持续记忆能力,依赖有限上下文窗口38。
二、知识与应用局限
-
知识时效性与领域局限
大模型知识库仅覆盖训练数据截止时间点内容,无法实时更新5。同时缺乏特定领域(如企业私有数据)的专业知识,影响垂直场景应用效果5。 -
幻觉问题频发
生成内容存在事实性错误或虚构信息,例如伪造参考文献、错误解答数学题等。这与基于概率预测的Transformer架构特性直接相关45。
三、模型可控性不足
-
自我纠错能力缺失
无法识别错误来源(如训练数据缺陷或算法漏洞),更缺乏自主修正机制。典型案例包括GPT-4算术错误后无法定位问题根源23。 -
黑箱模型可解释性差
决策过程不透明,导致医疗、法律等关键领域应用受限。调试困难进一步加剧优化挑战46。
四、资源与安全风险
-
计算成本高昂
训练与部署需超大规模算力支持,对普通机构形成技术壁垒16。 -
数据偏见与标注错误
训练数据隐含社会偏见可能被放大,人工标注错误易导致模型认知偏差6。
AIGC产业解析

AIGC基础层
算力基础 数据基础 算法基础
AIGC大模型层
通用基础大模型 行业垂直型基础大模型 业务垂直基础大模型
AIGC工具层
AI Agents 模型平台 模型服务 AutoGPT LangChain
AIGC应用层
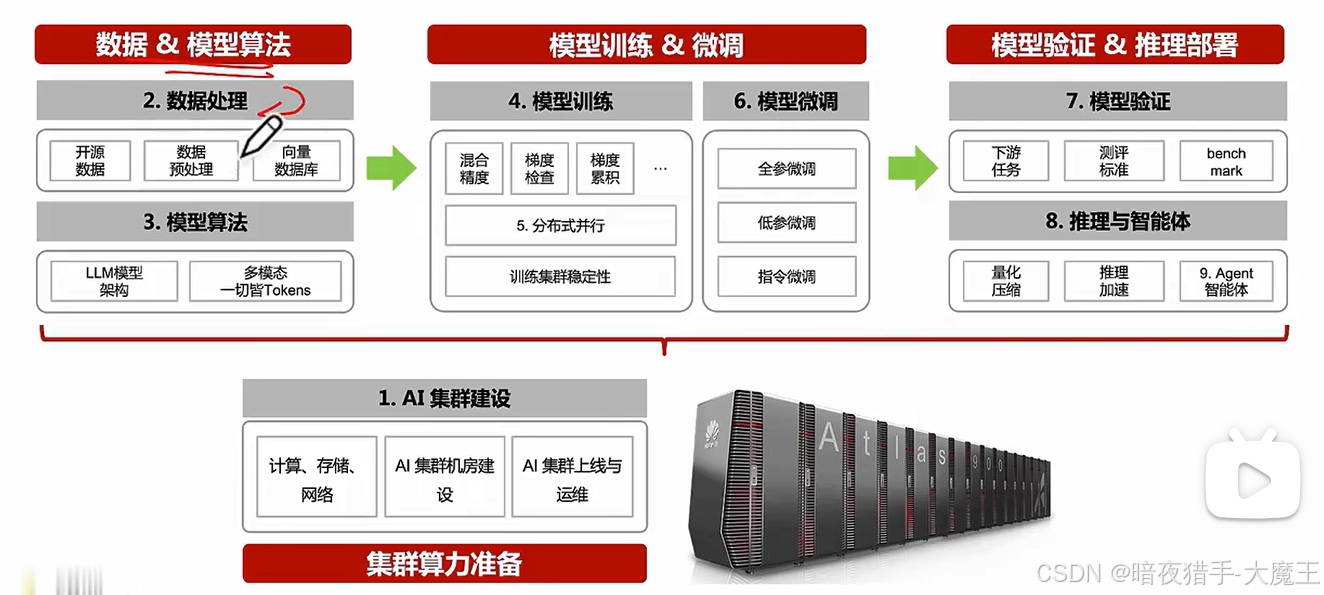
大模型业务流程


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









