







本篇介绍基于 Negative Sampling 的 CBOW和 Skip-gram模型。Negative Sampling(简称为 NEG)是 NCE(Noise Contrastive Estimation)的一个简化版本,目的是用来提高训练速度并改善所得词向量的质量。与 Hierarchical Softmax 相比,NEG 不再使用(复杂的)Huffman树,而是利用(相对简单的)随机负采样,能大幅度提高性能,因而可作为 Hierarchical Softmax 的一种替代。

1. CBOW模型
在 CBOW 模型中,已知词的上下文
,需要预测
,因此,对于给定的
,词
就是一个正样本,其它词就是负样本。负样本那么多,该如何选取呢?
假定现在已经选好了一个关于的负样本子集
。且对
,定义
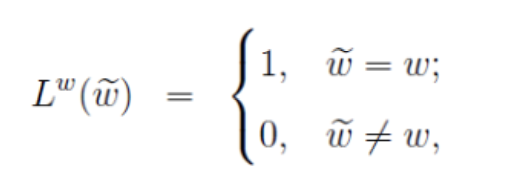
此公式定义了词的标签,即正样本的标签为 1,负样本的标签为 0。
对于一个给定的正样本,我们希望最大化。
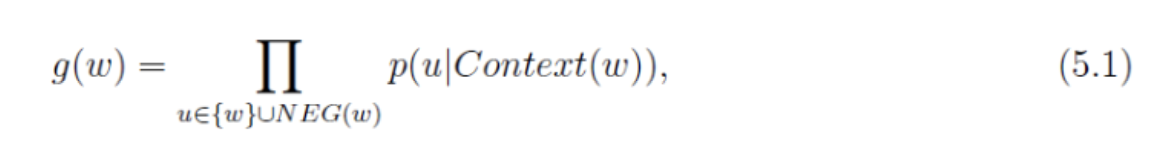
其中
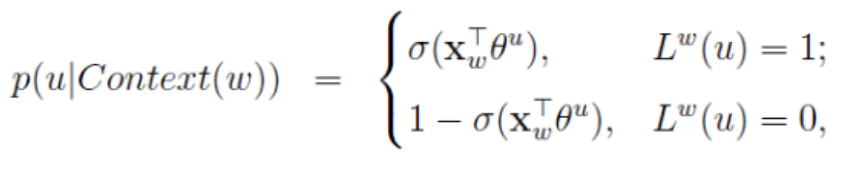
或者写作整体表达式
![]()
这里仍任然表示中
各词的词向量之和,而
表示词
对应的一个辅助向量,为待训练参数。
为什么要最大化,让我们先来看看
的表达式,将公式(5.2)代入(5.1)可得:
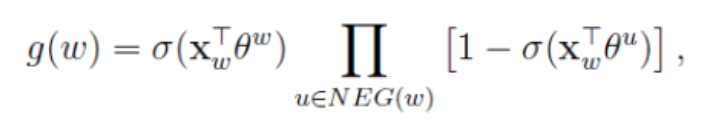

给定一个词,怎样生成
呢?
词典中的词在语料
中出现的次数有高有低,对于那些高频词,被选为负样本的概率就应该比较大,反之,对于那些低频词,其被选中的概率就应该比较小。这就是我们对采样过程的一个大致要求,本质上就是一个带权采样的问题。
下面先用一段通俗的描述来帮助读者理解带权采样的机理:
设词典中的每一个词
对应一个线段
,长度为
这里的counter(w)表示一个词在语料中出现的次数(分母中的求和项用来做归一化)。现在将这些线段首尾相连拼接在一起,形成一个长度为1的单位线段.如果随机地往这个单位线段上打点,则其中长度越长的线段(对应高频词)被打中的概率就越大。(例如有4个词,出现的次数是 1 2 2 5,每个词出现归一化次数是0.1 0.2 0.2 0.5)
接下来谈谈 word2vec 中的具体做法:记,
,这里
表示词典中的第j个词,















 1578
1578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









